【博学谷IT技术支持】
一、介绍
概念
Apache™ Hadoop® 项目为可靠、可扩展的分布式计算开发开源软件。允许简单的编程模型在大量计算机集群上对大型数据集群进行分布式处理。
项目包含以下模块:
Common: 支持其他hadoop模块的通用实用程序HDFS(分布式文件系统): 可提供对应用程序数据的高吞吐量访问YAN(作业调度和集群资源管理框架): 解决资源任务调度问题MapReduce (分布式运算编程框架): 基于YARN的系统,用于并行处理大型数据集
生态圈
Hadoop的核心是HDFS、YARN、MapReduce。随着处理任务不同,各种组件相继出现,丰富了Hadoop的生态圈。
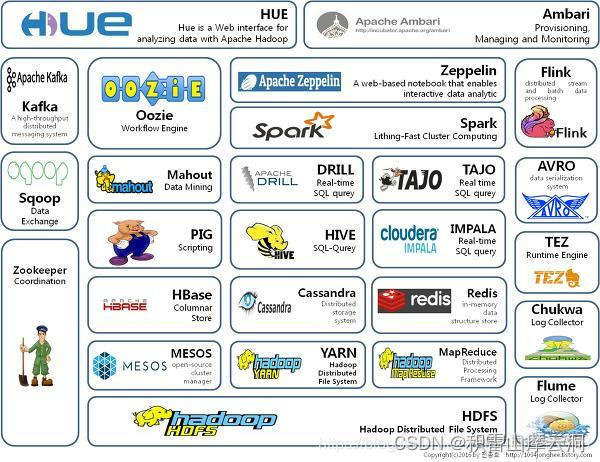
ZooKeeper: 分布式协调服务基础组件HDFS: 分布式文件系统MapReduce: 分布运算程序开发框架HBase: 分布式列存储数据库YARN: 作业调度和集群资源管理框架MESOS: 分布式资源管理器HIVE: 基于HADOOP的分布式数据仓库,提供基于SQL的查询数据操作FLUME: 日志数据采集框架OOZIE: 工作流程调度框架SQOOP:数据导入导出工具(比如用于mysql和HDFS之间)IMPALA: 基于HIVE的实时SQL查询分析MAHOUT: 基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
特点
高效性:通过并发数据,hadoop可以在节点之间动态并行的移动数据,使得速度非常快可靠性: 自动维护数据的多份复制。并且在任务失败后能自动的重新部署计算任务。扩容能力:hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可方便的扩展到数以千计的节点中成本低:hadoop可通过廉价的机器组成服务器集群来分发以及处理数据,降低了成本。
二、hadoop集群搭建
部署方式
Hadoop的部署模式有三种:独立模式、伪分布式模式、集群模式。
standalone mode
独立模式又称单机模式,仅一个机器运行java进程。本地模式下调试Hadoop集群的MapReduce程序非常方便,所以一般情况下,该模式适合在快速安装体验Hadoop、开发阶段进行本地调试使用。
Pseudo-Distributed mode
伪分布模式也是在一个机器上运行HFDS的NameNode和DataNode、YARN的ResourceManager和NodeManager,但分别启动单独的java进程,主要用于调试。
Cluster mode
集群模式主要用于生产环境部署。会使用n台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
集群架构模型
NameNode和ResourceManager单节点架构模型NameNode高可用与ResourceManager单节点构架模型NameNode单节点和ResourceManager高可用架构模型Namenode与ResourceManager高可用架构模型
相同点:
NameNode是集群中的主节点,主要用于管理集群中的各种数据。DataNode:集群中的从节点,主要用于存储集群当中的各种数据ResourceManager:接受用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分NodeManager: 负责执行主节点分配的任务
不同点:
NameNode可以有两个,形成高可用状态。ResourceManager通过两个,构建高可用- 在
NameNode单节点中,会有secondaryNameNode作为hadoop当中元数据信息的辅助管理,在高可用则有JournalNode作为文件系统元数据信息管理,一般都是奇数个。
搭建
- 下载并解压安装
下载地址:https://hadoop.apache.org/releases.html
下载并解压到指定目录
mkdir -p /export/server/hadoop-3.1.4/data
- 配置NameNode
cd /hadoop-3.1.4/etc/hadoop
vim core-site.xml
<!-- 设置默认使用的文件系统 Hadoop 支持 file、HDFS、GFS、Ali Cloud、Amazon Cloud 等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- hadoop本地数据存储目录 format时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/hadoop-3.1.4/data</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
- 配置HDFS路径
vim hdfs-site.xml
<!-- 设定SNN运行主机和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
- 配置yarn
vim yarn-site.xml
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
- 配置MapReduce
vim mapred-site.xml
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 配置nameNode的主机名
vim workers
删除第一行localhost,然后添加以下内容
node1
node2
node3
- 配置环境变量
vim hadoop-env.sh
export JAVA_HOME=/export/server/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.1.4
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
source /etc/profile
- 配置windows域名映射
C:\Windows\System32\drivers\etc目录下的hosts
node1的ip node1
node2的ip node2
node3的ip node3
- 分发安装文件和环境变量
分发hadoop-3.1.4和/etc/profile到node2和node3。
刷新配置文件:source /etc/profile
- 格式化HDFS
在node1执行
cd /export/server/hadoop-3.1.4
hdfs namenode -format
启动与关闭
- 启动HDFS集群
-- 选择node1节点启动NameNode节点
hdfs --daemon start namenode
-- 在所有节点上启动DataNode
hdfs --daemon start datanode
-- 在node2启动Secondary NameNode
hdfs --daemon start secondarynamenode
- 启动YARN集群
-- 选择node1节点启动ResourceManager节点
yarn --daemon start resourcemanager
-- 在所有节点上启动NodeManager
yarn --daemon start nodemanager
- 关闭HDFS集群
# 关闭NameNode
hdfs --daemon stop namenode
# 每个节点关闭DataNode
hdfs --daemon stop datanode
# 关闭Secondary NameNode
hdfs --daemon stop secondarynamenode
- 关闭YARN集群
# 每个节点关闭ResourceManager
yarn --daemon stop resourcemanager
# 每个节点关闭NodeManager
yarn --daemon stop nodemanager
- 脚本式操作
// HDFS
start-dfs.sh
stop-dfs.sh
// YARN
start-yarn.sh
stop-yarn.sh
// 一键启动HDFS、YARN
start-all.sh
// 一键关闭HDFS、YARN
stop-all.sh