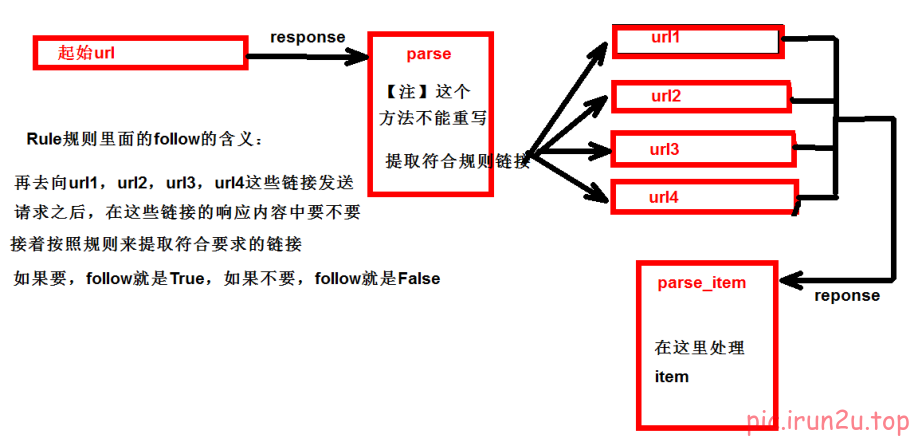
1. CrawSpider介绍

运行原理:
2. pymysql

conda install pymysql
3. 案例-读书网爬虫&数据入库
3.1 案例需求

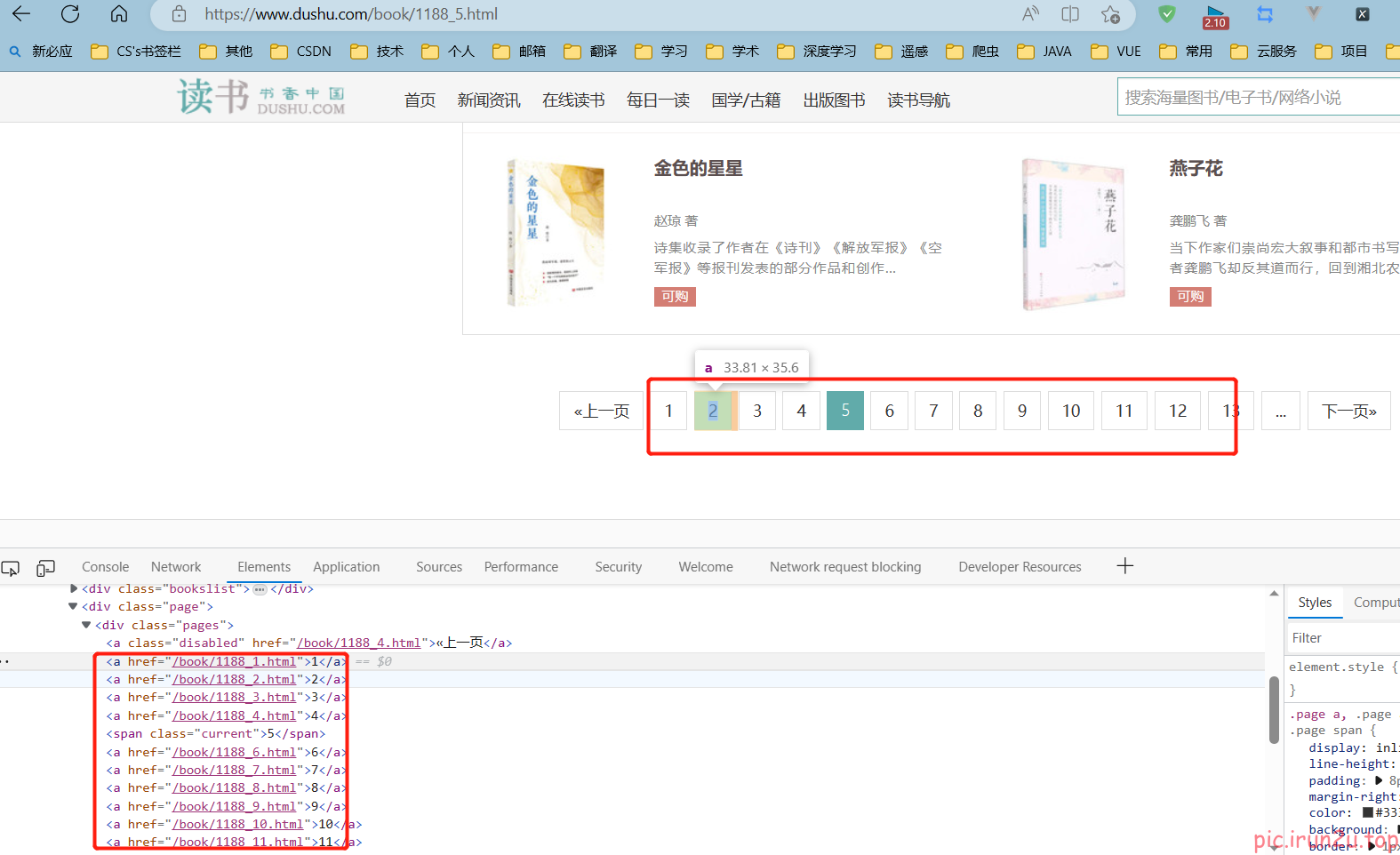
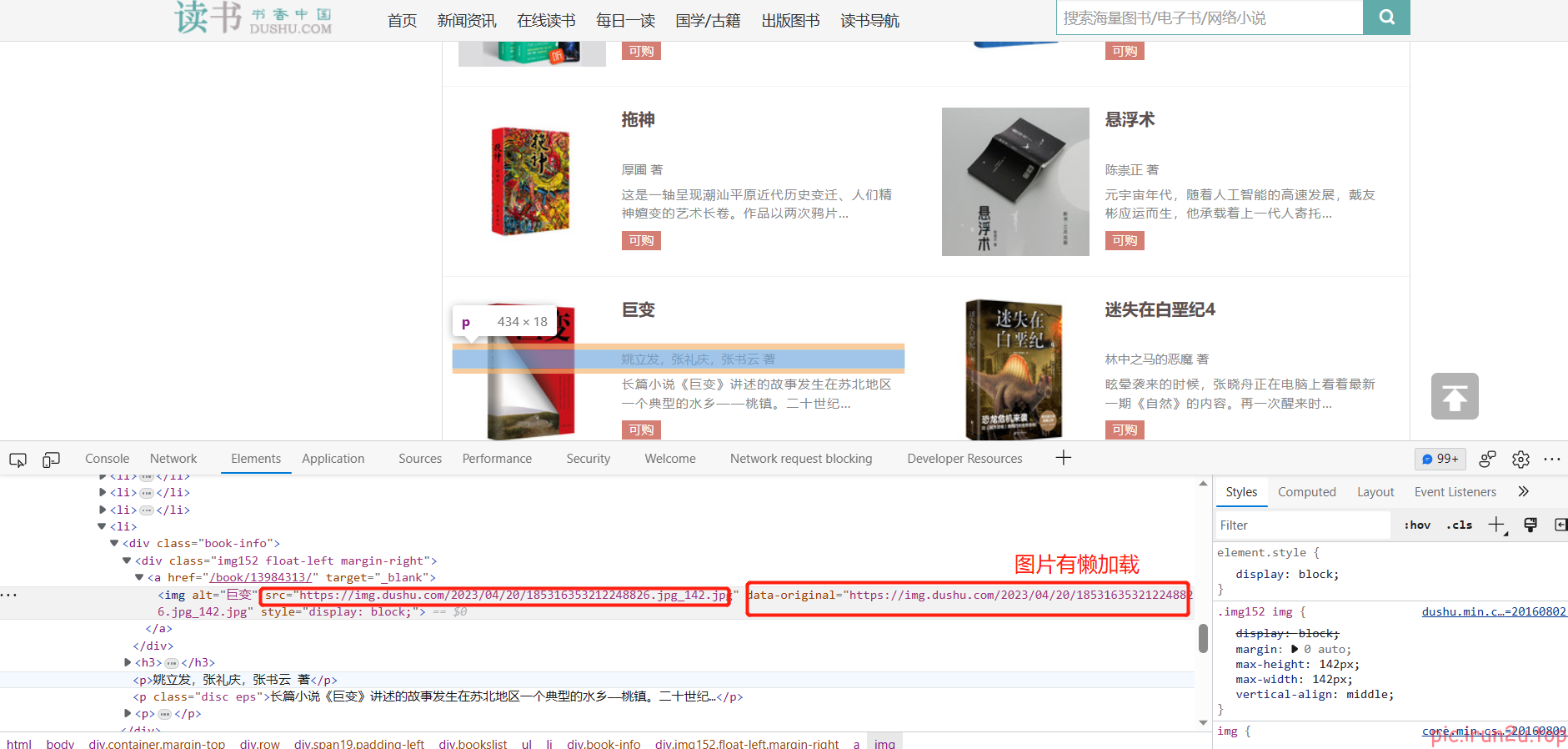
3.2 网页分析
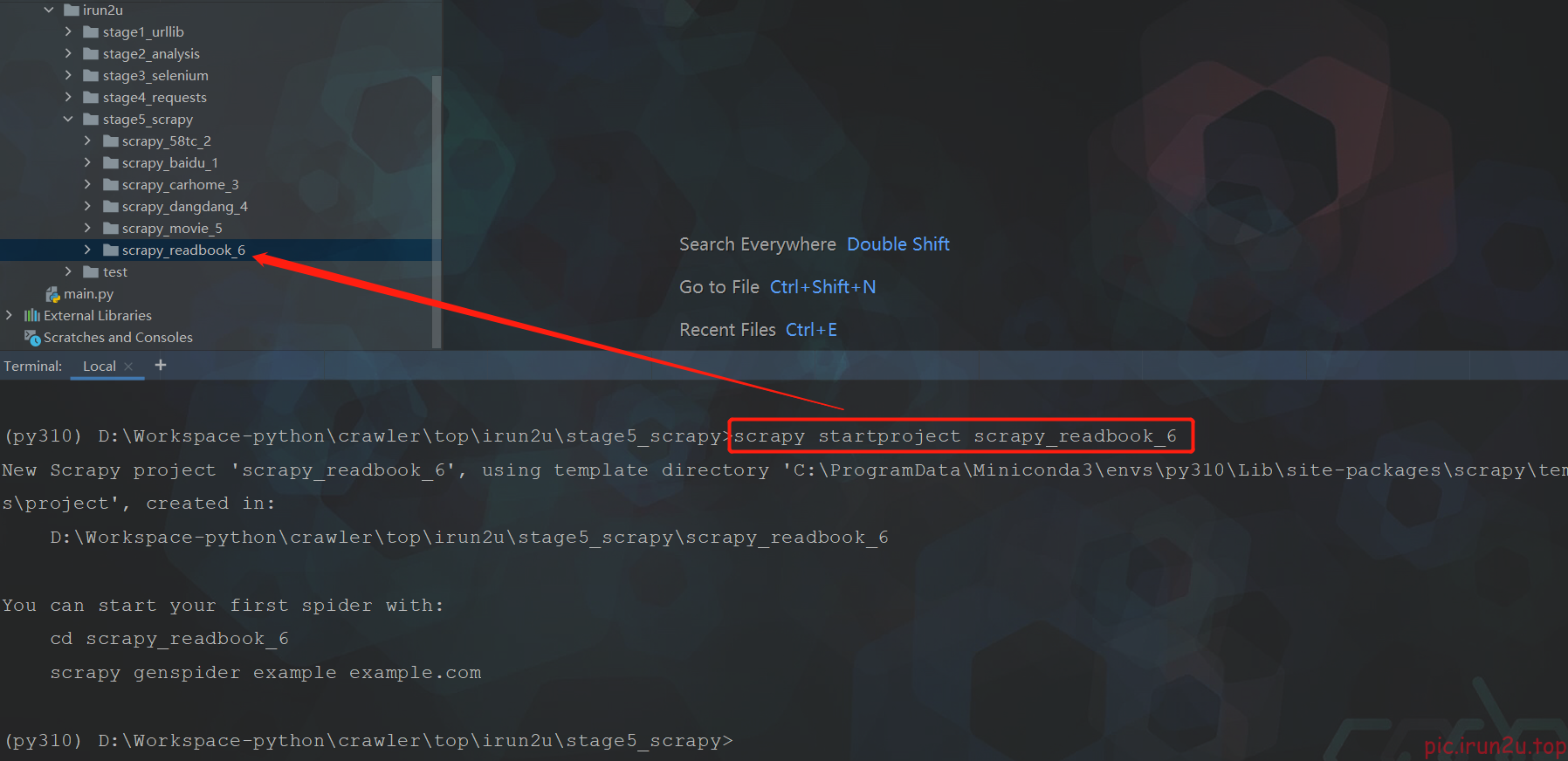
3.3 创建爬虫项目
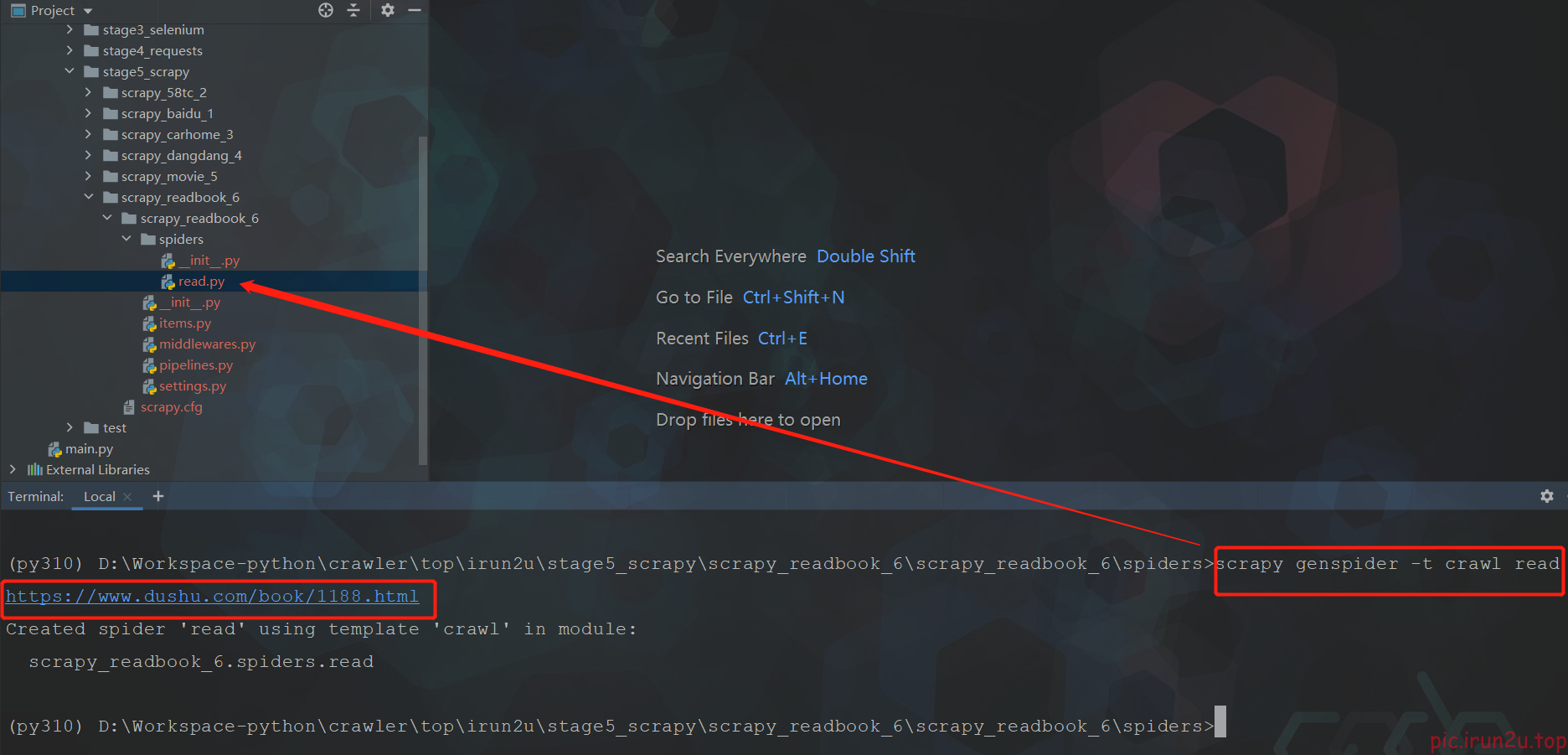
3.4 创建爬虫文件(与之前有区别)
scrapy genspider -t crawl read https://www.dushu.com/book/1188.html
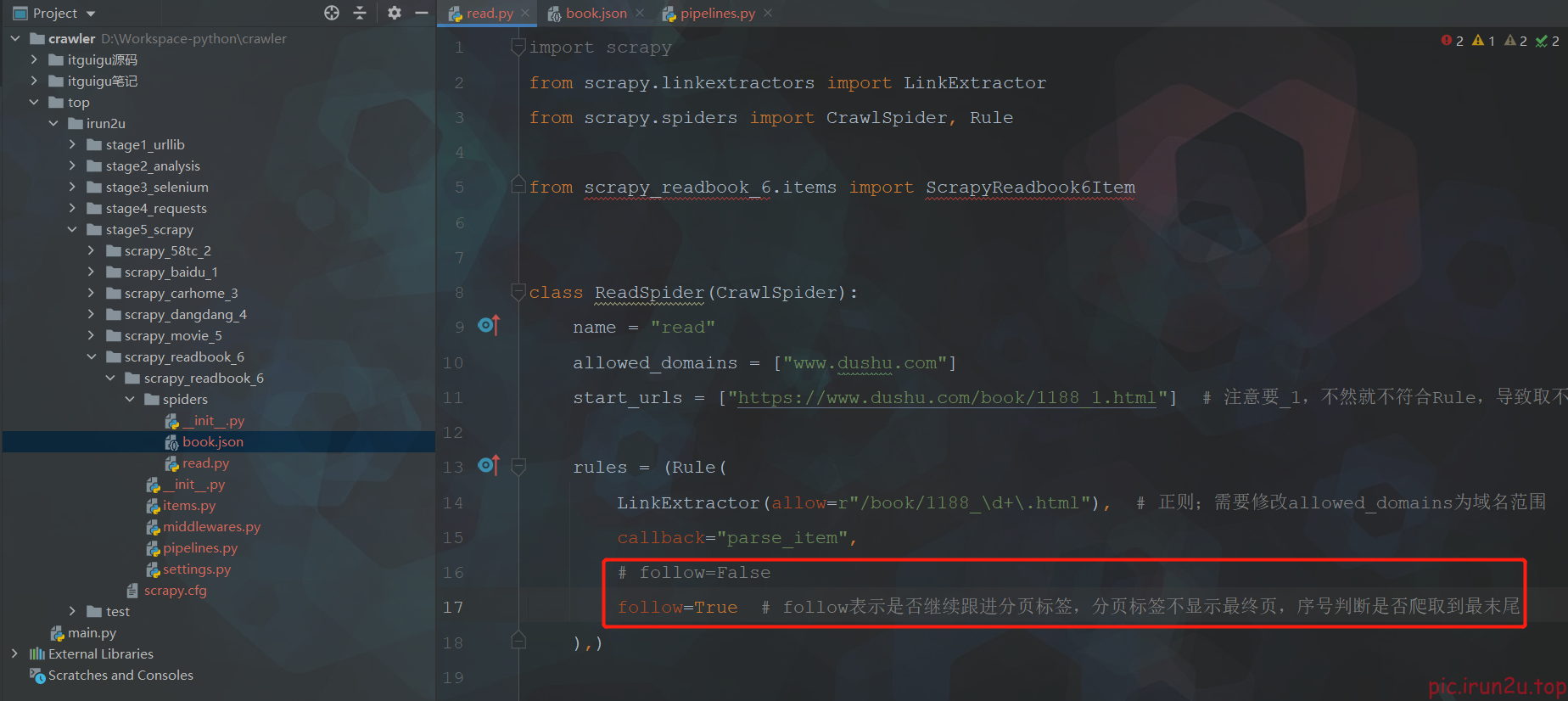
3.5 实现爬虫
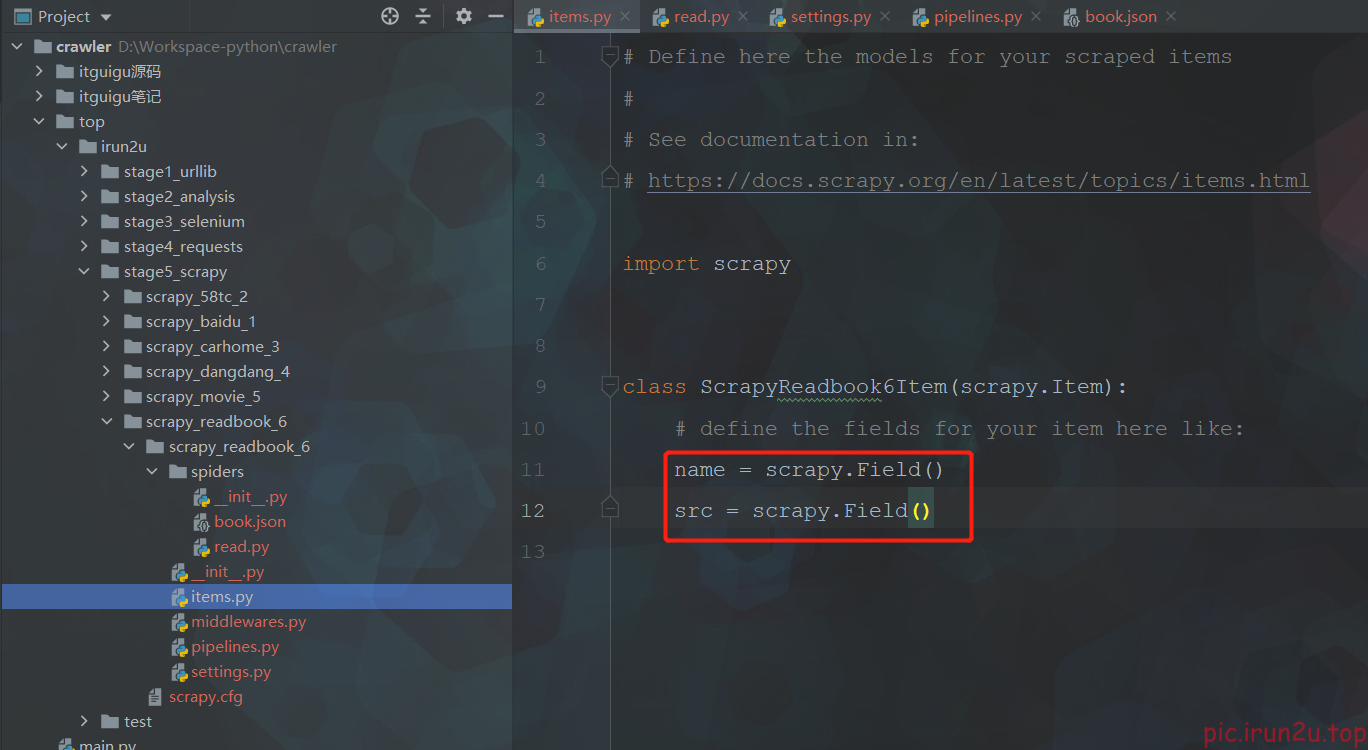
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook_6.items import ScrapyReadbook6Item
class ReadSpider(CrawlSpider):
name = "read"
allowed_domains = ["www.dushu.com"]
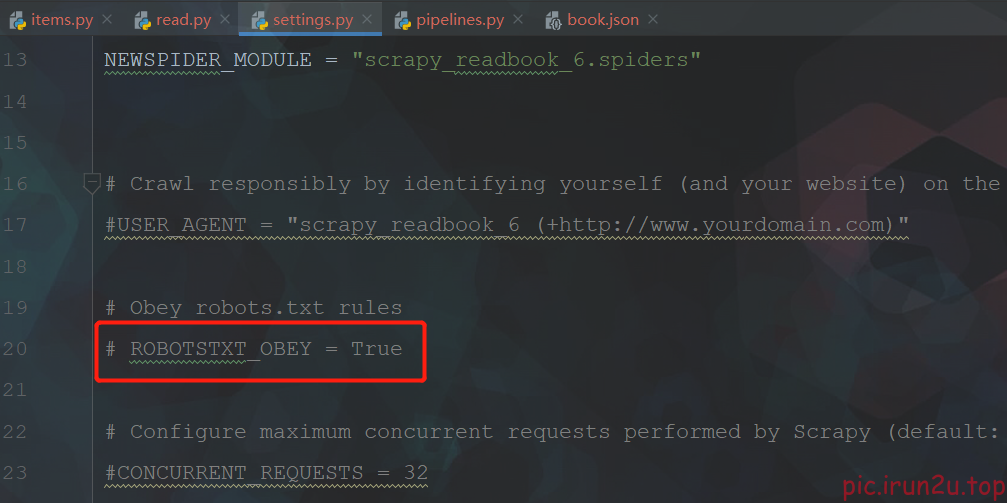
start_urls = ["https://www.dushu.com/book/1188_1.html"] # 注意要_1,不然就不符合Rule,导致取不到第一页
rules = (Rule(
LinkExtractor(allow=r"/book/1188_\d+\.html"), # 正则;需要修改allowed_domains为域名范围
callback="parse_item",
follow=False
),)
def parse_item(self, response):
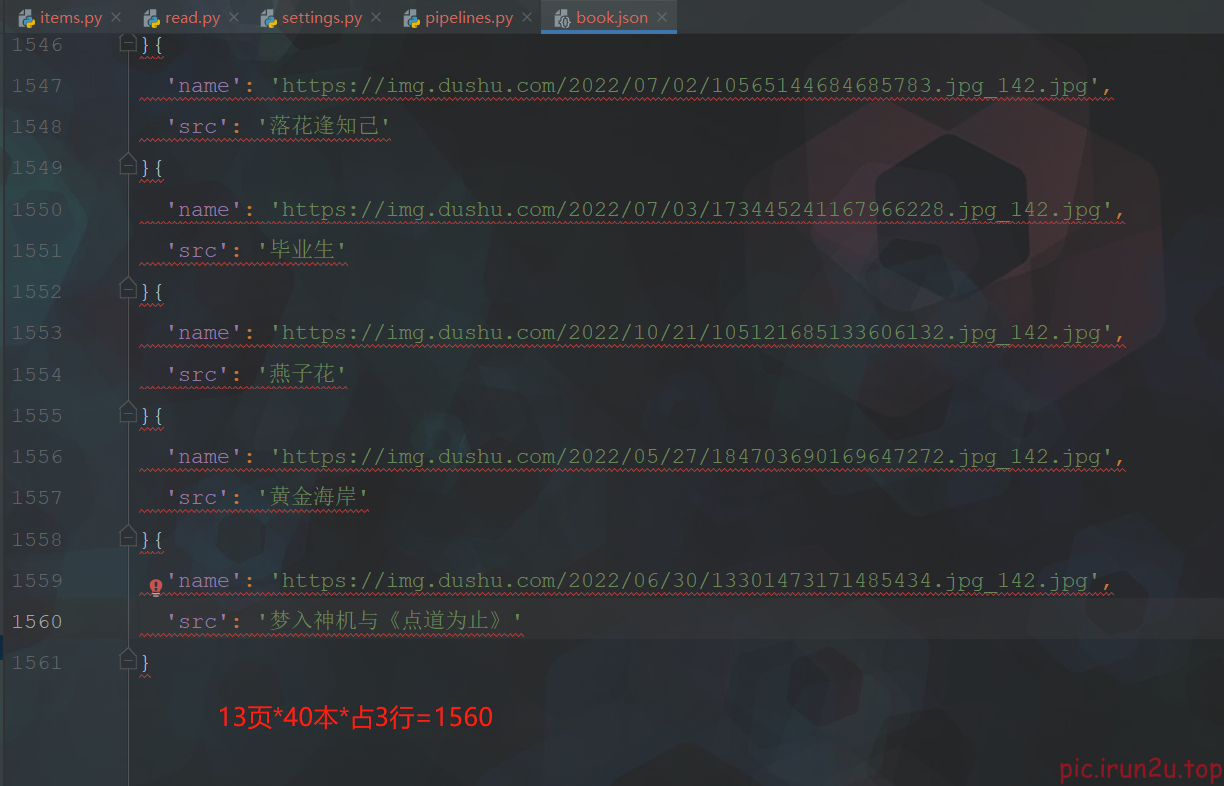
# 爬取图片和书名
img_list = response.xpath('//div[@class="bookslist"]//img')
for img in img_list:
name = img.xpath('./@data-original').extract_first()
src = img.xpath('./@alt').extract_first()
book = ScrapyReadbook6Item(name=name, src=src)
yield book
scrapy crawl read
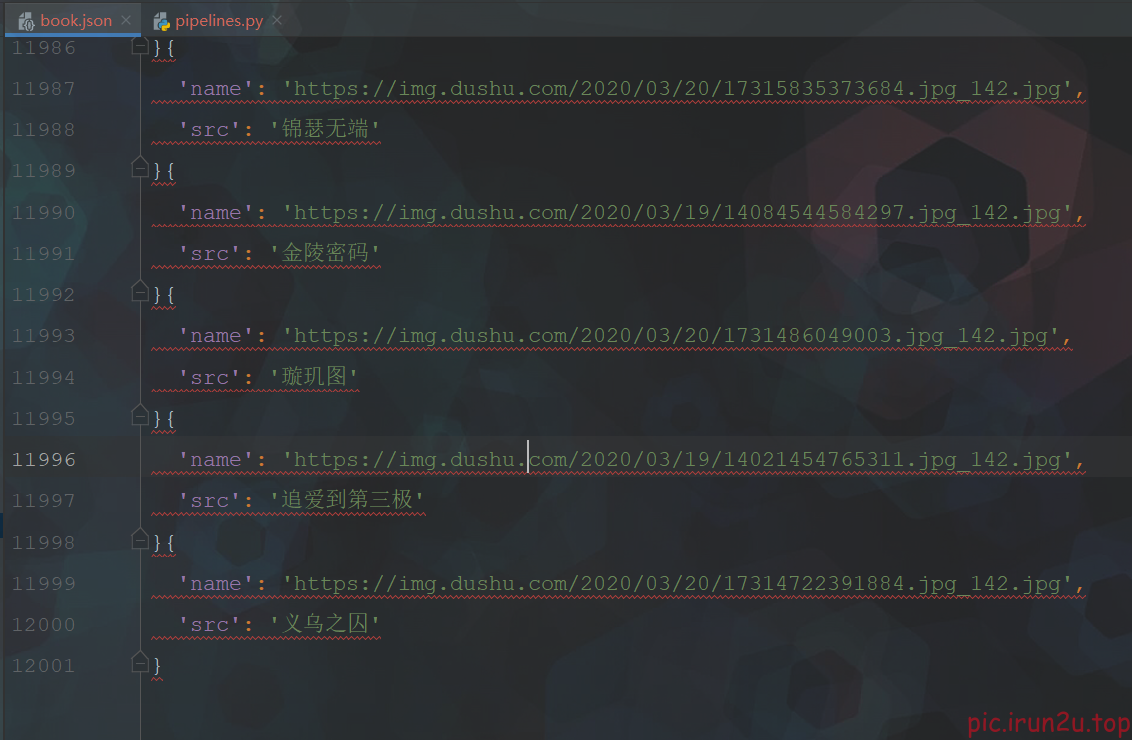
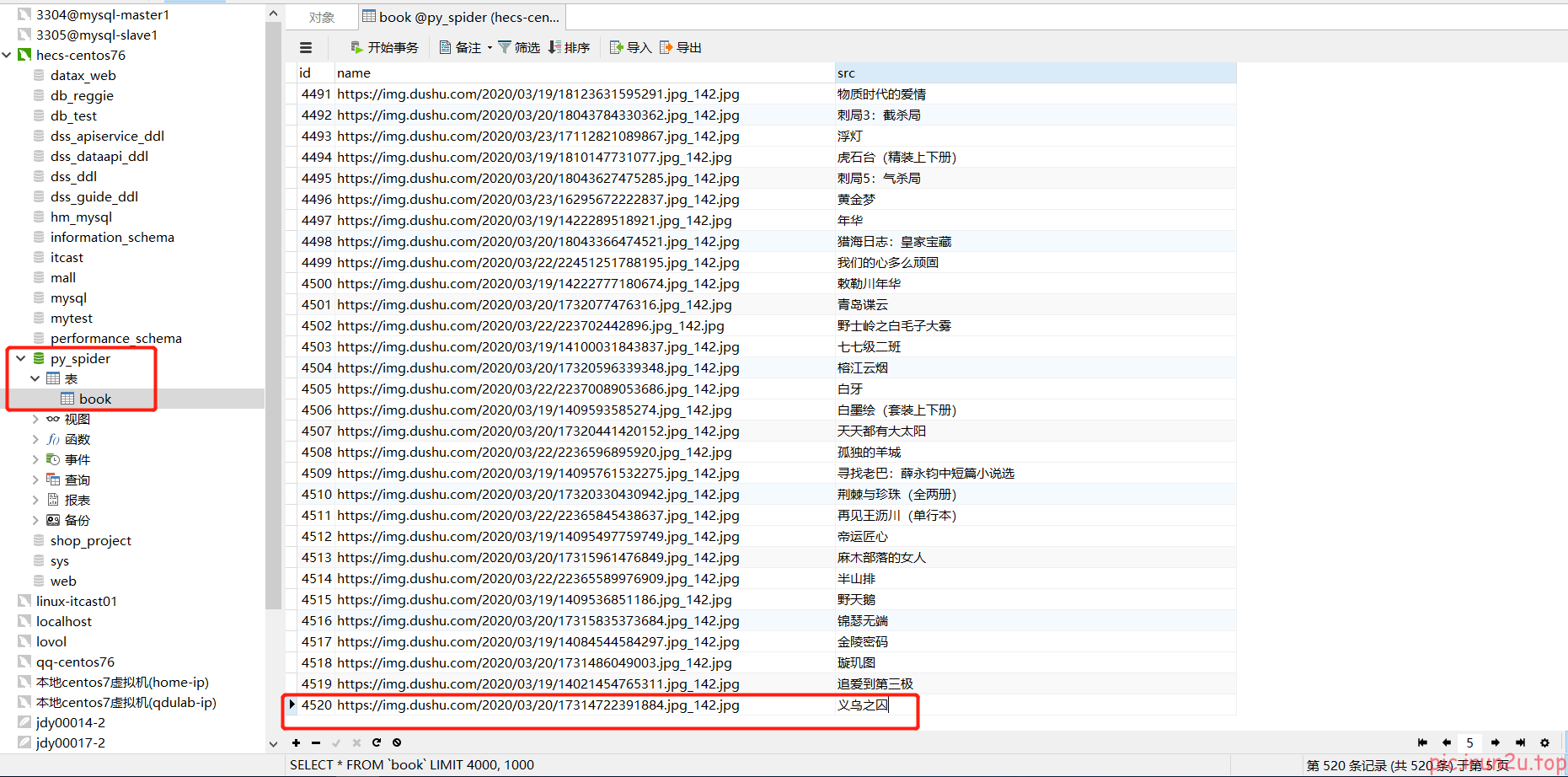
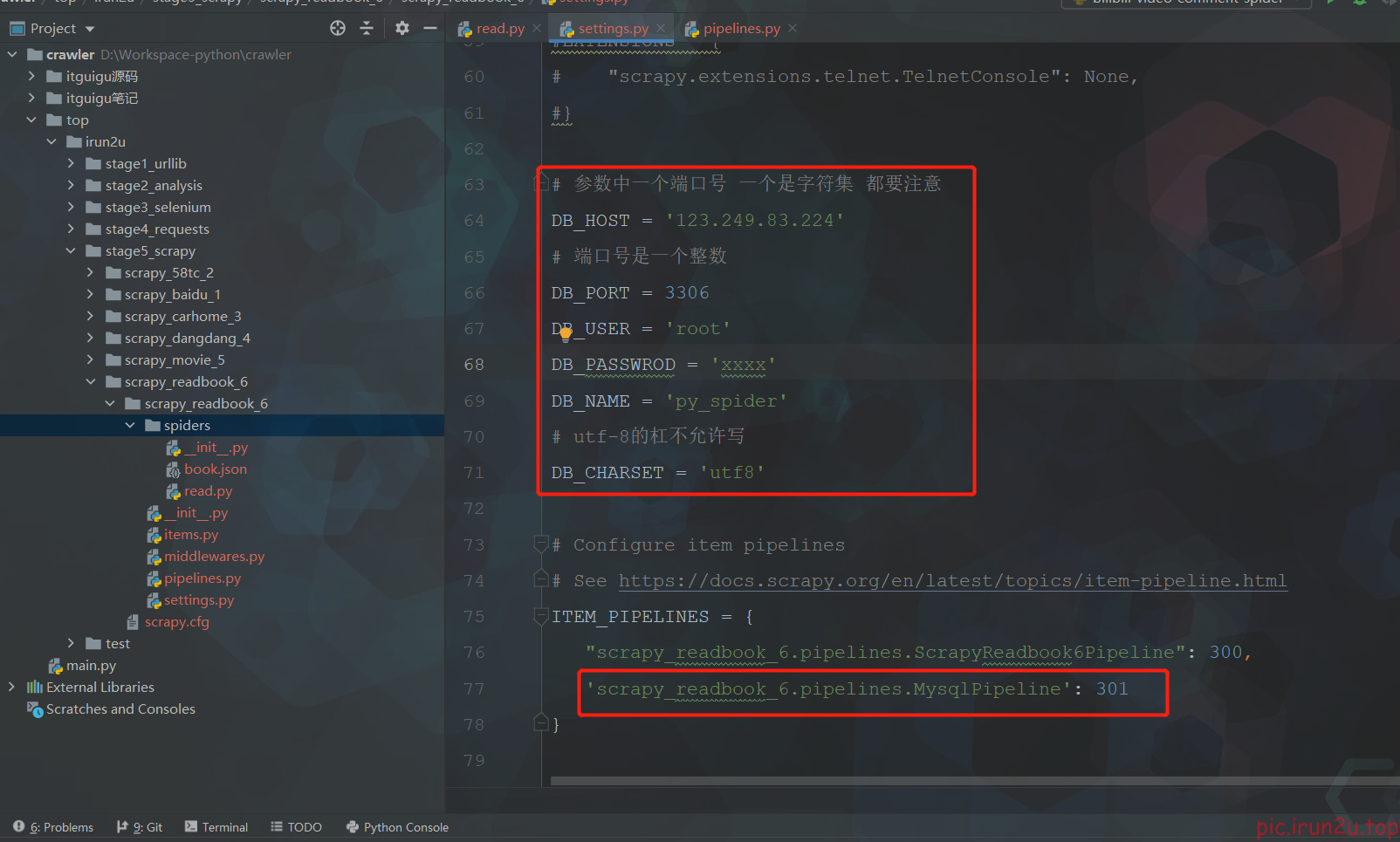
3.6 实现入库
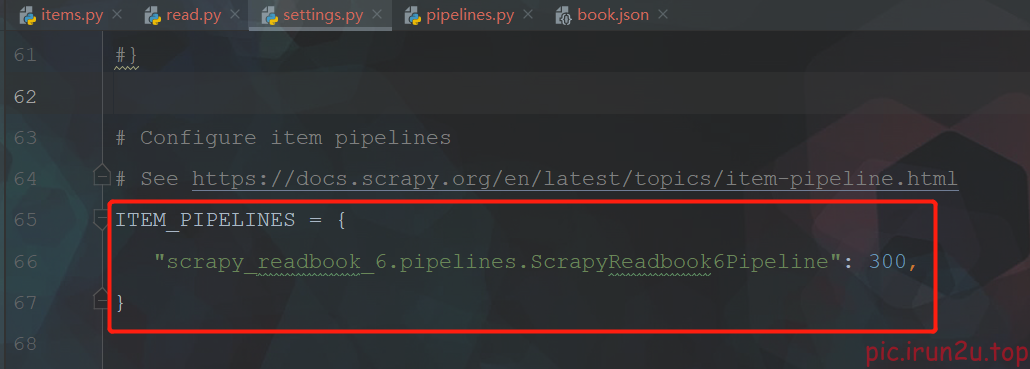
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
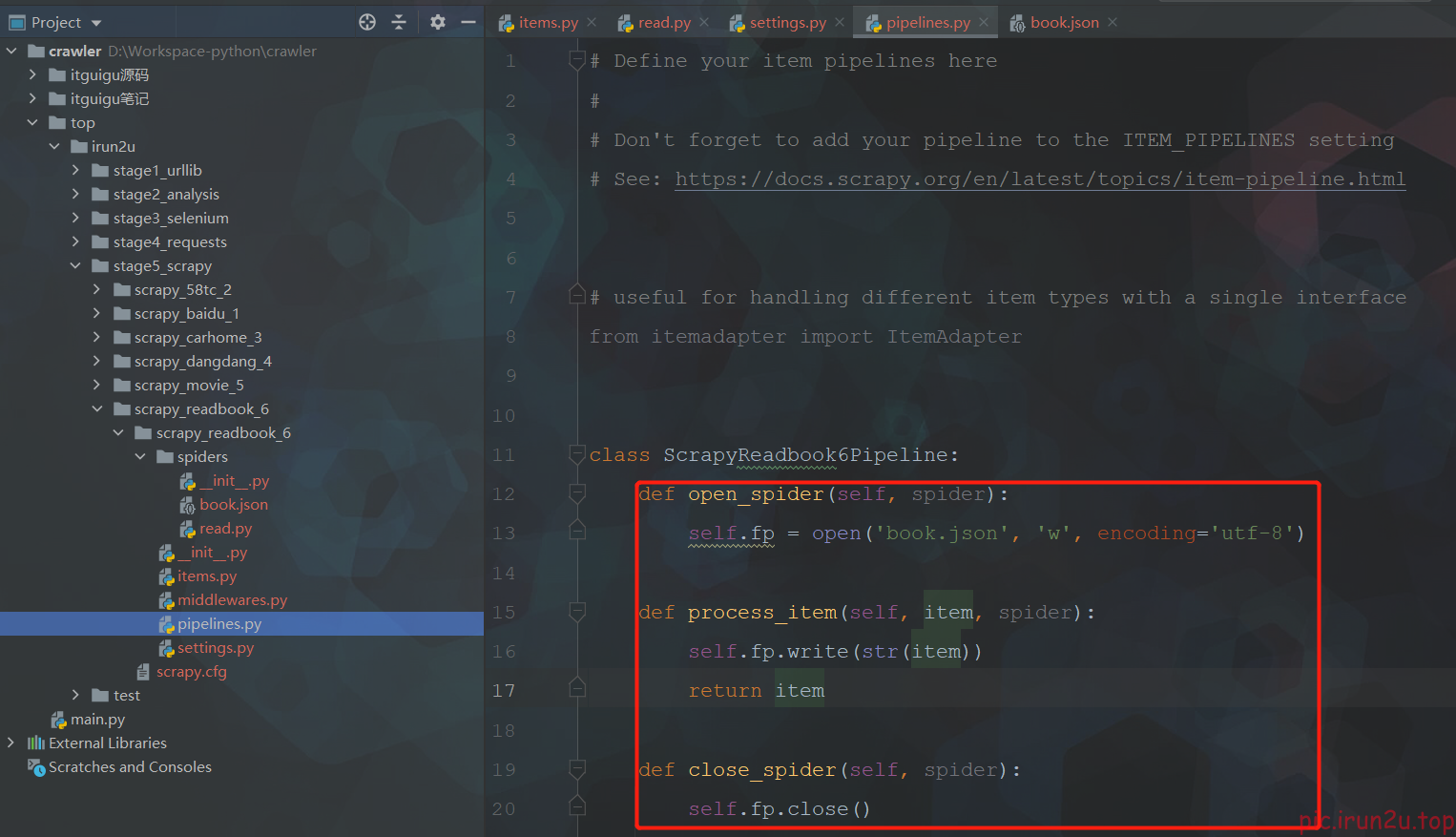
class ScrapyReadbook6Pipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
from scrapy.utils.project import get_project_settings # 加载settings文件
import pymysql
class MysqlPipeline:
def open_spider(self, spider):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port =settings['DB_PORT']
self.user =settings['DB_USER']
self.password =settings['DB_PASSWROD']
self.name =settings['DB_NAME']
self.charset =settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'], item['src'])
# 执行sql语句
self.cursor.execute(sql)
# 提交
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
scrapy crawl read