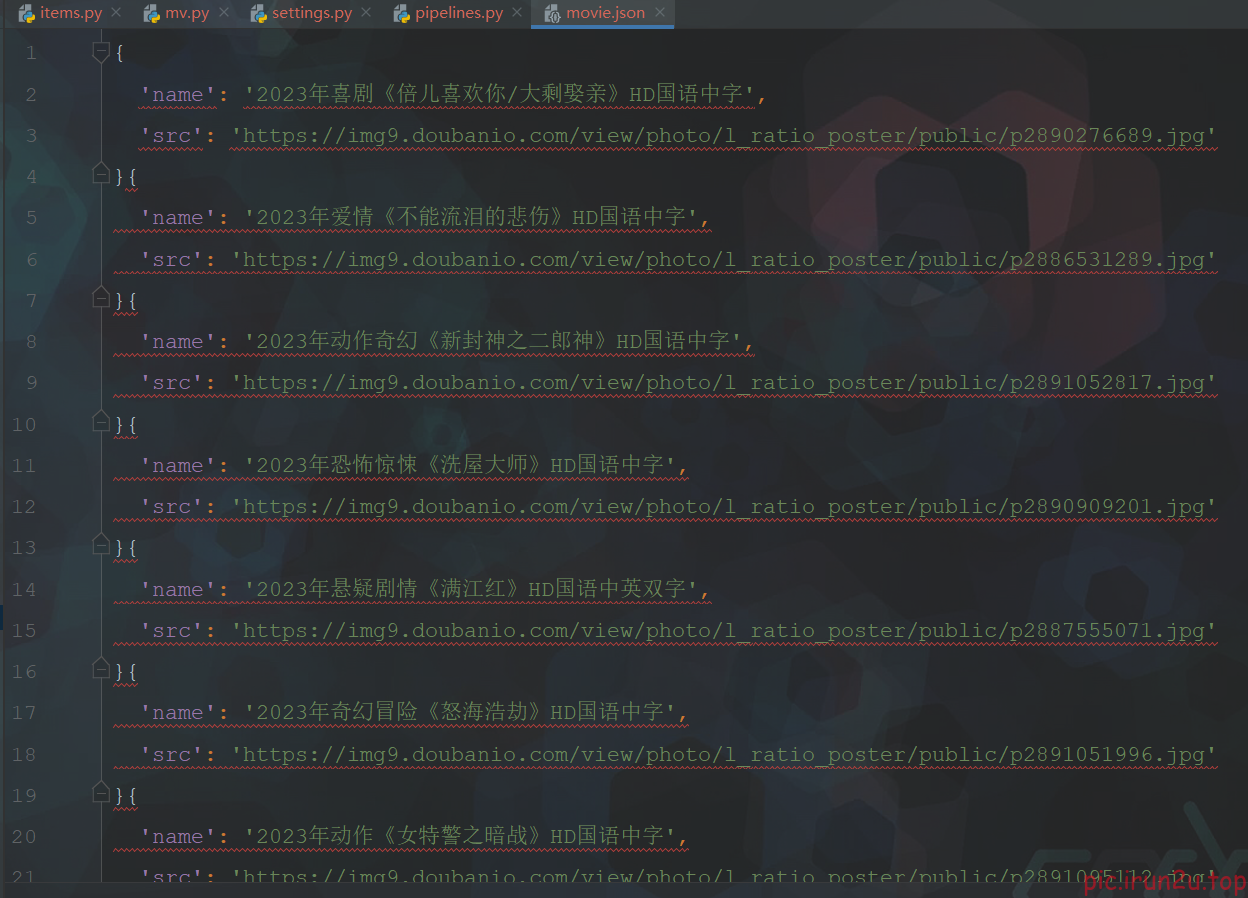
嵌套数据封装成一个item(一个item包含多级页面的数据):每条记录的名称+点进去之后第二页中的图片
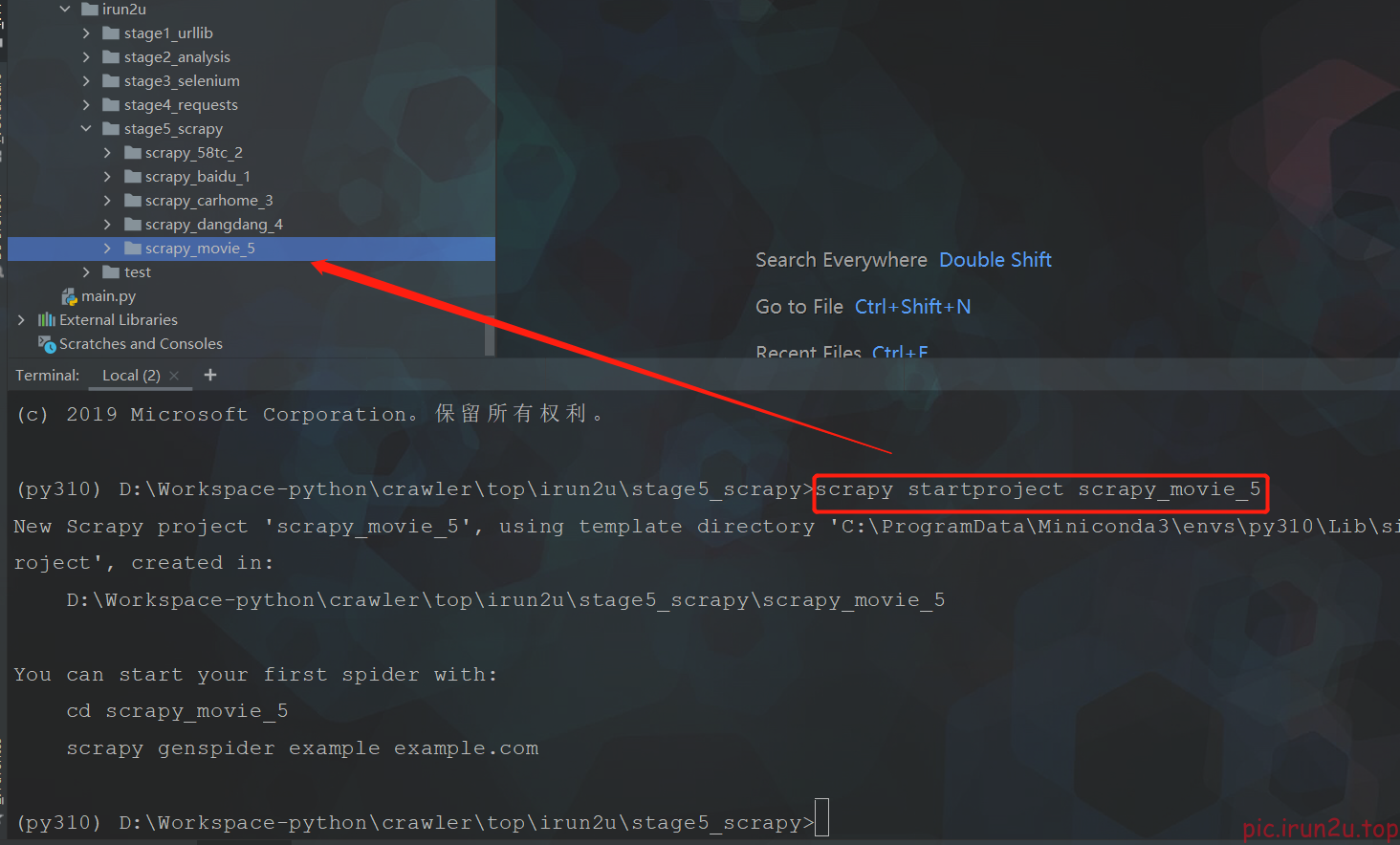
1. 创建爬虫项目
scrapy startproject scrapy_movie_5
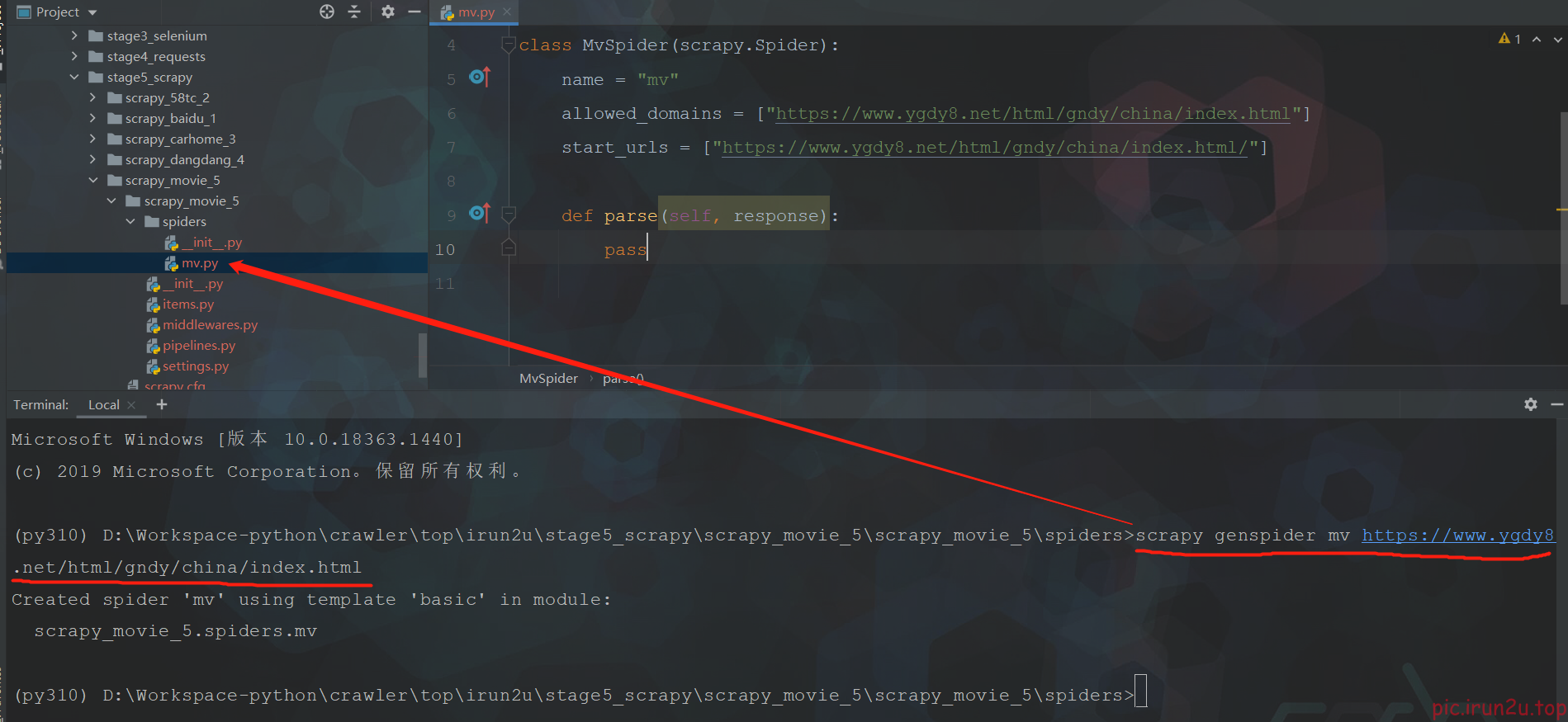
2. 创建爬虫文件
scrapy genspider mv https://www.ygdy8.net/html/gndy/china/index.html
3. 实现爬虫
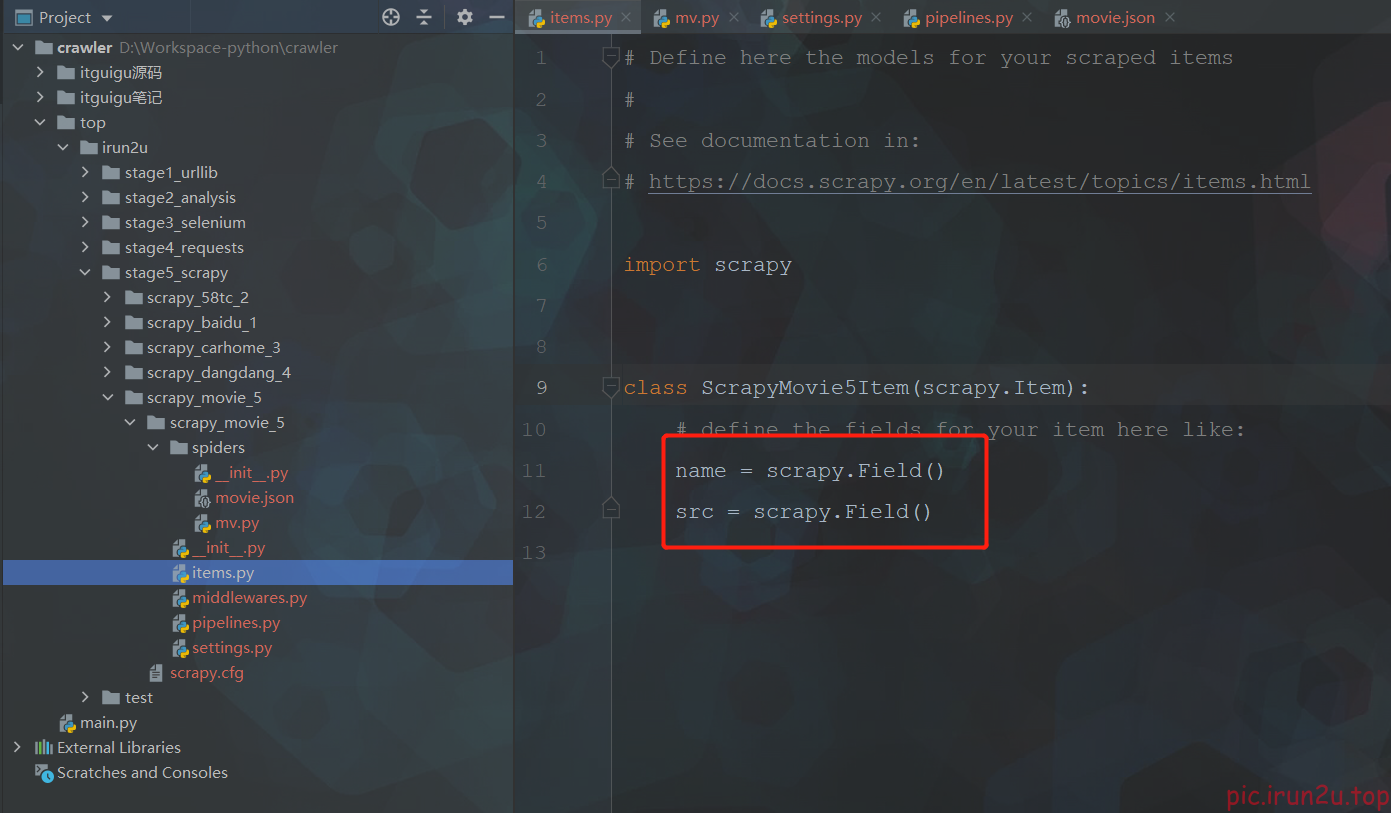
import scrapy
from scrapy_movie_5.items import ScrapyMovie5Item
class MvSpider(scrapy.Spider):
name = "mv"
# allowed_domains = ["https://www.ygdy8.net/html/gndy/china/index.html"]
allowed_domains = ['www.dytt8.net']
start_urls = ['https://www.dytt8.net/html/gndy/china/index.html']
def parse(self, response):
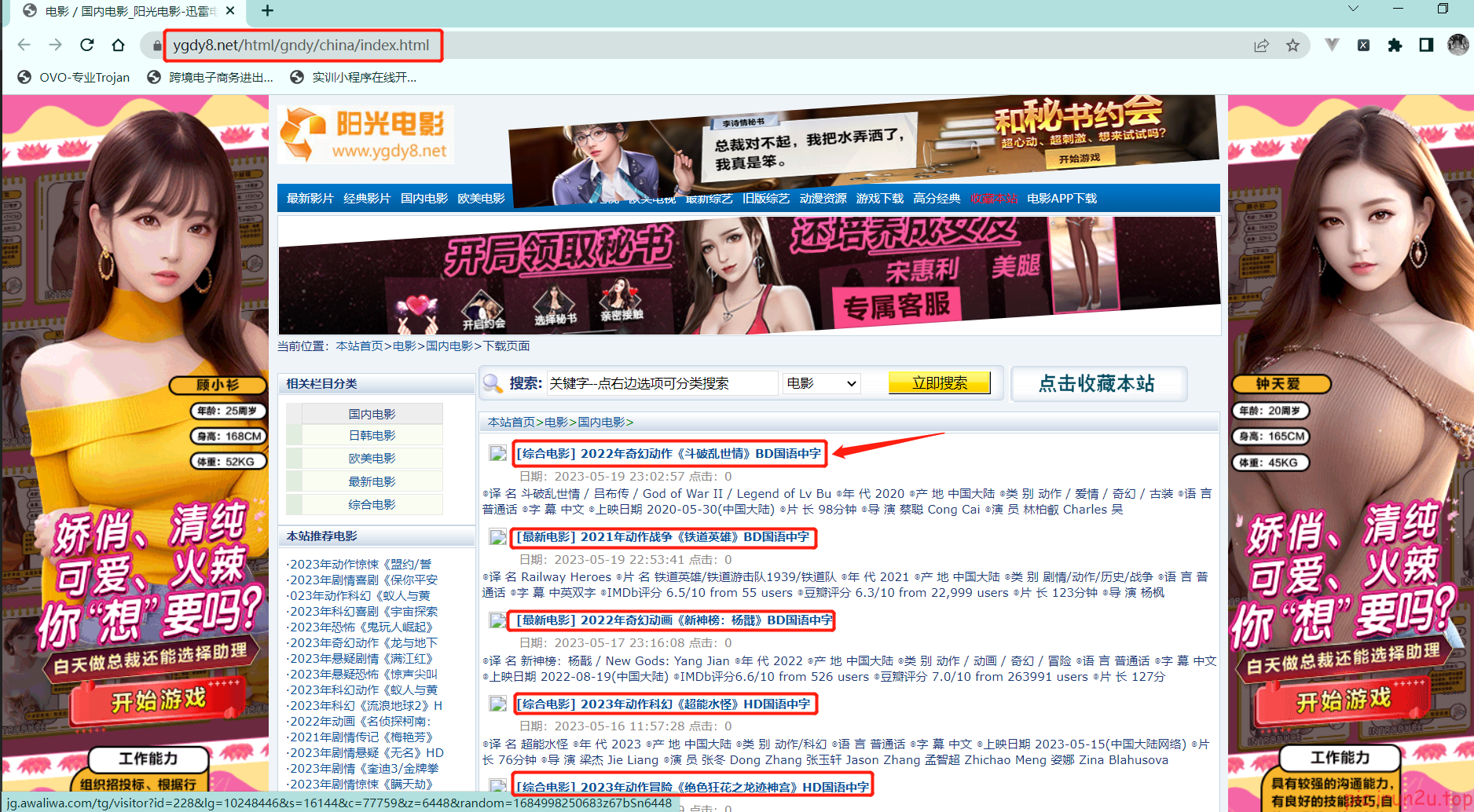
# 第一页的名字和第二页的图片
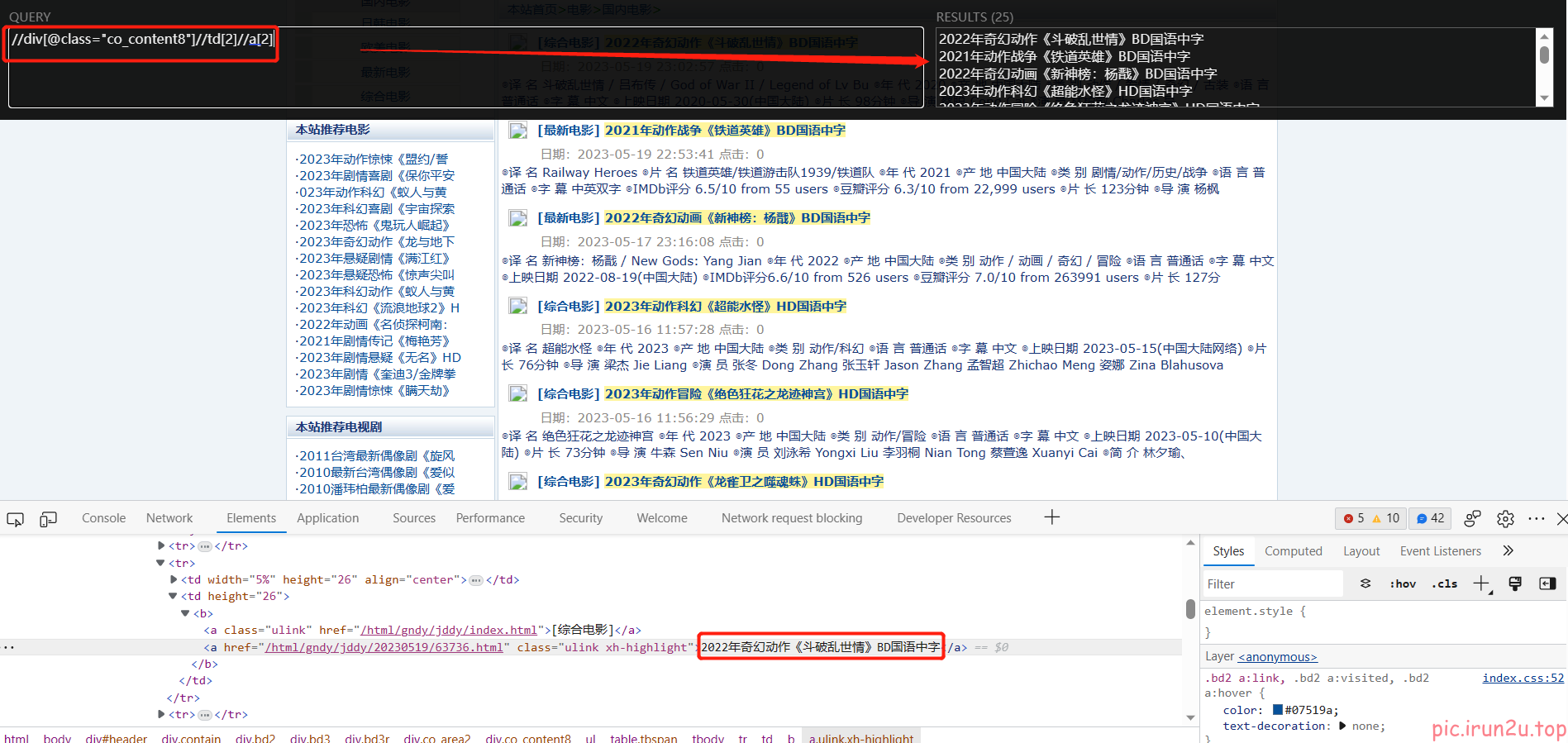
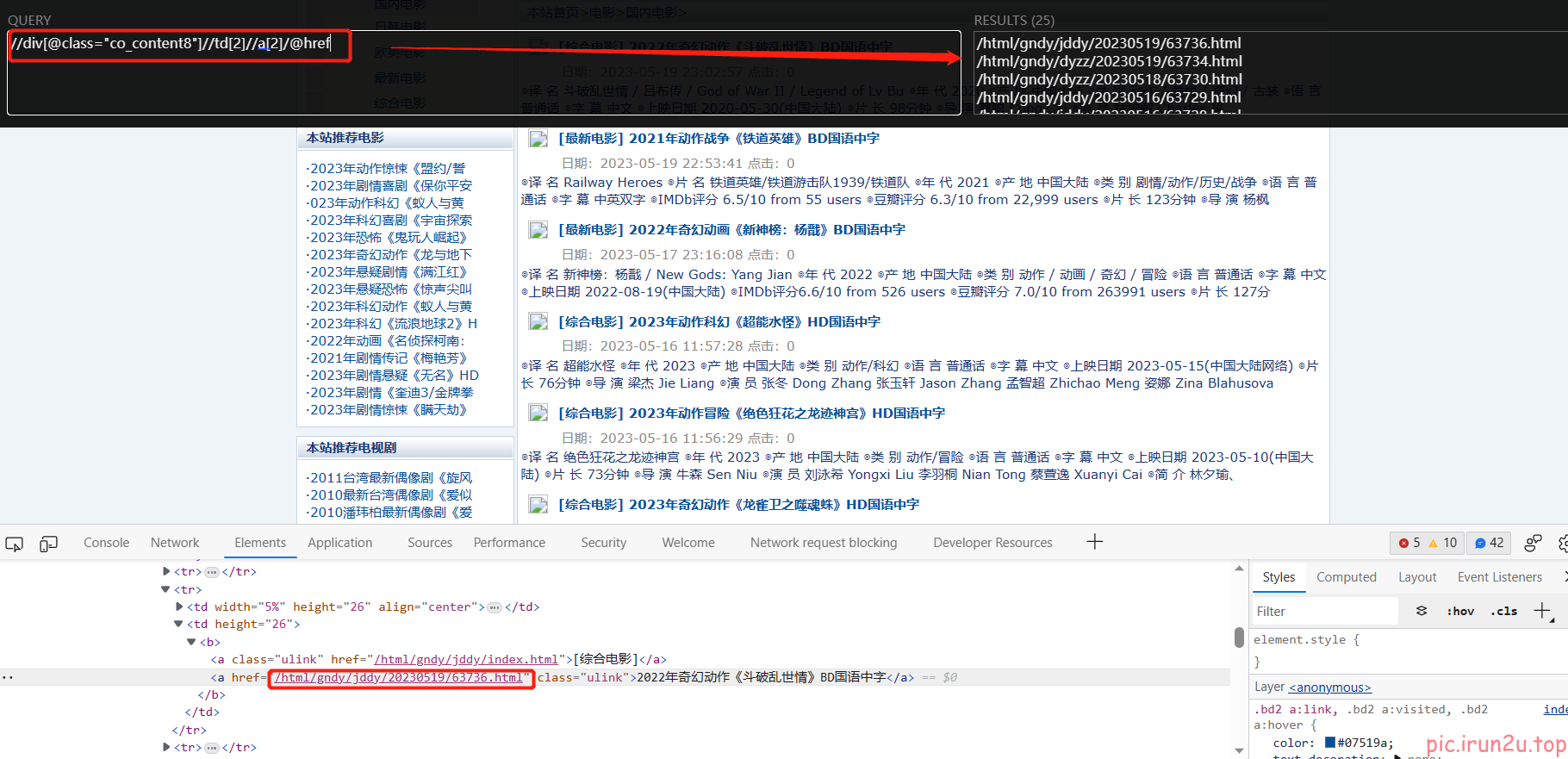
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a_list:
# 获取第一页的name 和 要点击的链接
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 第二页的地址
url = 'https://www.dytt8.net' + href # 注意要修改allowed_domains,因为需要访问的第二页不再原范围内
# 对第二页的链接发起访问
yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})
# 注意当涉及多级页面时,要用meta来存参数
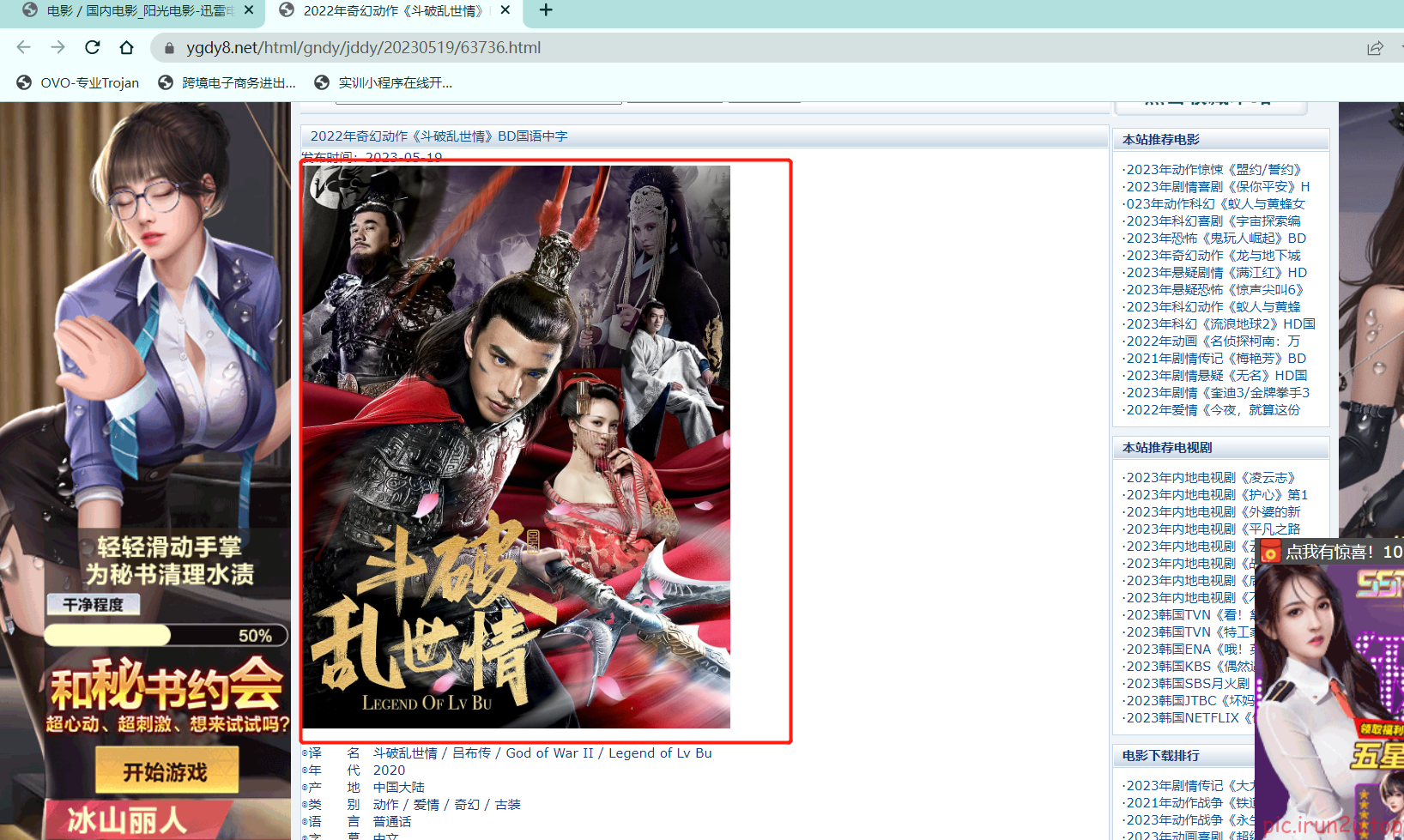
def parse_second(self, response):
# 注意 如果拿不到数据的情况下 一定检查你的xpath语法是否正确
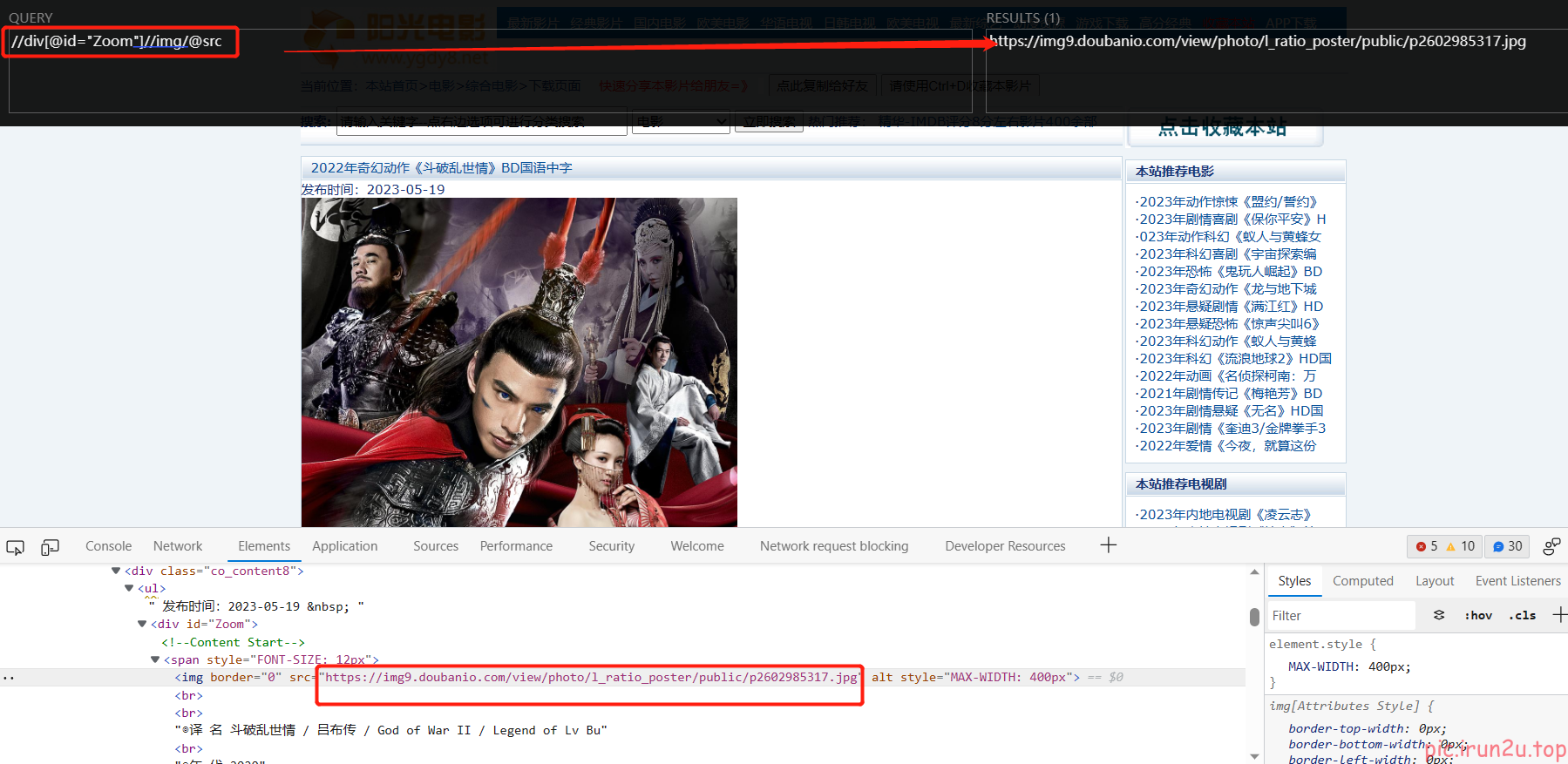
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# 接受到请求的那个meta参数的值
name = response.meta['name']
movie = ScrapyMovie5Item(src=src, name=name)
yield movie
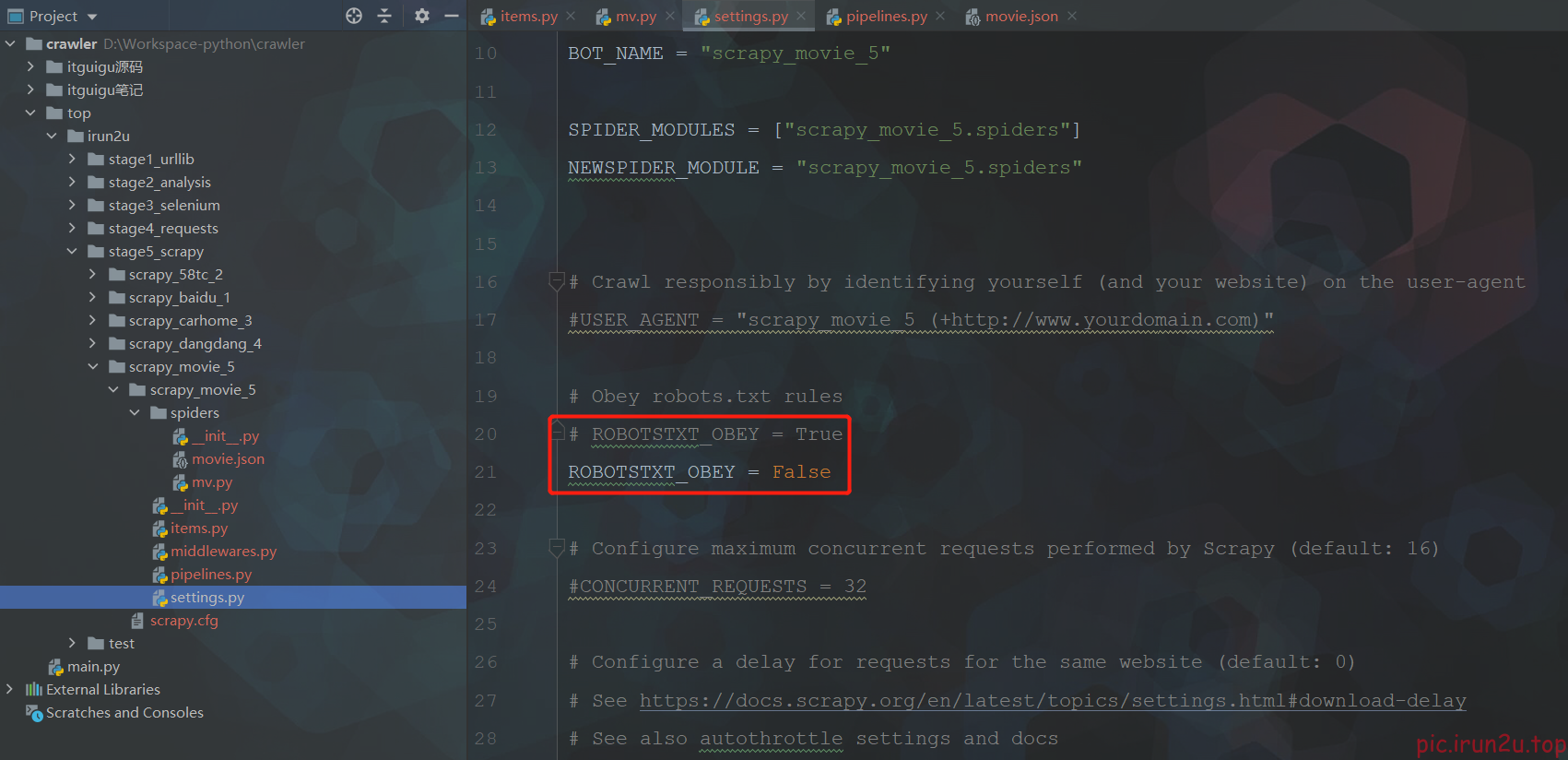
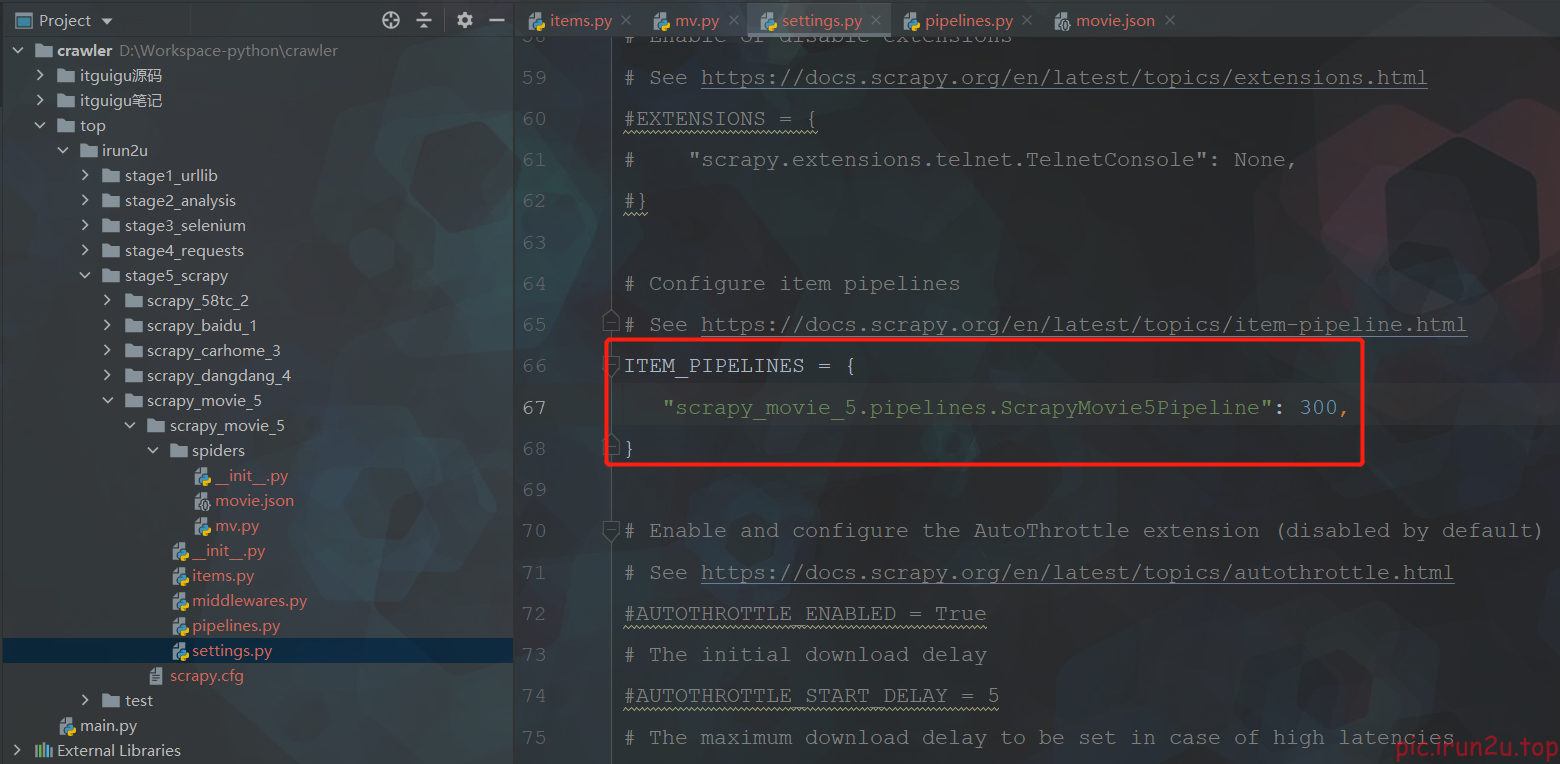
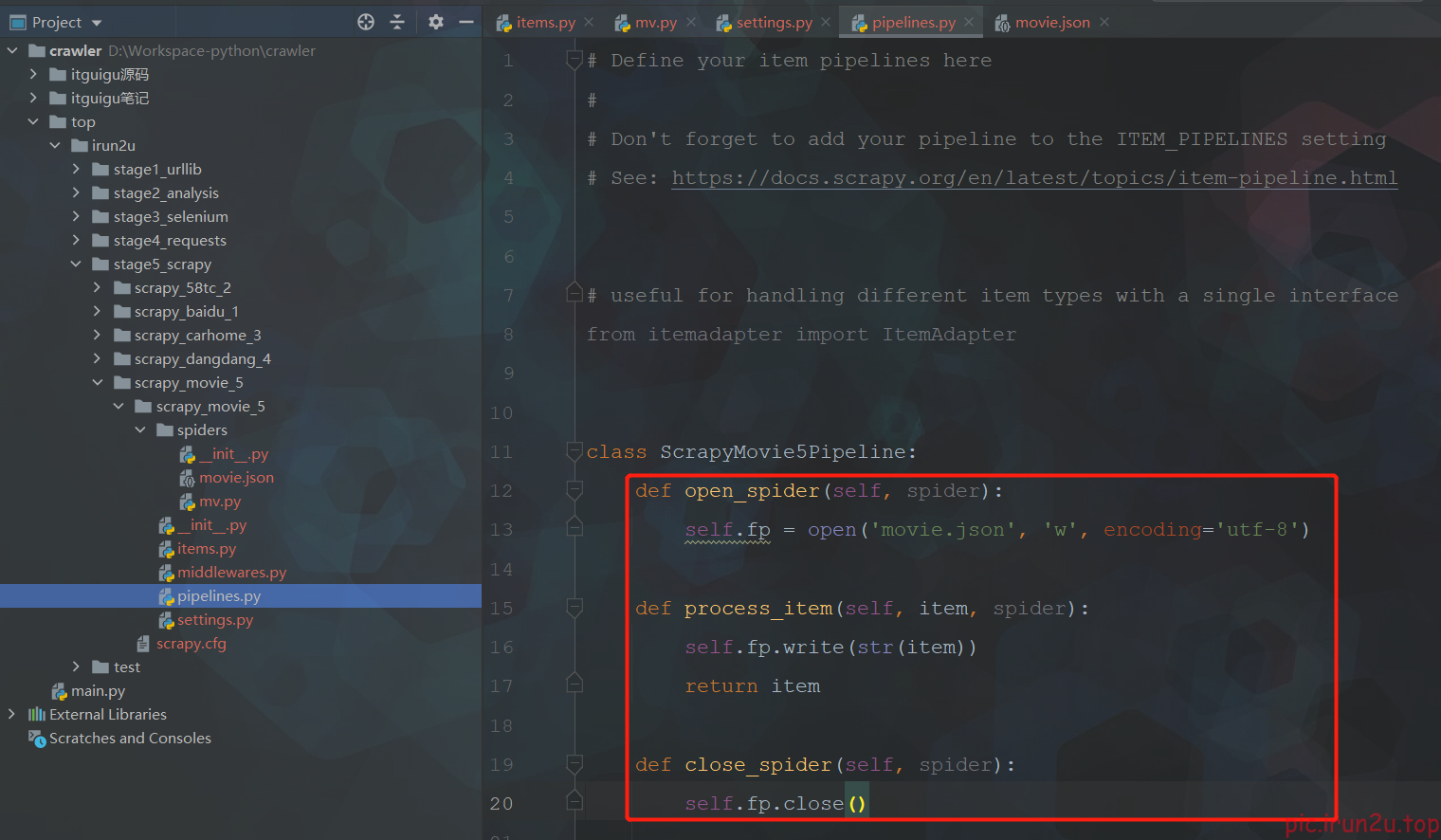
scrapy crawl mv