前言 本文介绍了实现统一、通用和开放词汇图像分割的新框架FreeSeg,它能够灵活地完成任意类别的不同分割任务,处理一个模型中的所有任务和类别。
本文转载自极市平台
作者 | CV开发者都爱看的
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

原文链接:https://arxiv.org/abs/2303.17225
代码链接:https://freeseg.github.io/
1. 引言
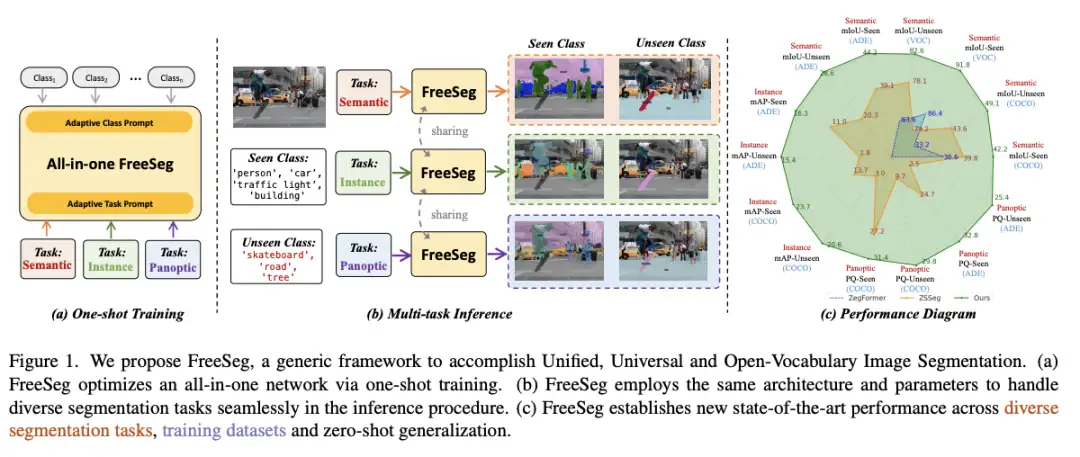
图像分割一直是计算机视觉中研究最广泛的课题之一,旨在同时对图像中的对象像素进行分组和分类。在最近的论文中,利用大规模的数据,图像分割取得了重大的进展。其中对object用像素级mask和label进行了详尽的注释。然而,由于标注费时费力,现有分割任务的模板类别大小仍然局限于10或100个数量级,远小于人类描述现实世界的词汇量。.这种学习目标将分割器的可扩展性绑定到一个有限的认知空间中,并且当该系统被推广以处理更丰富和更通用的语义时,就会成为一个关键的瓶颈。
作为处理训练数据集之外的自定义规范类别的可行途径,open-vocabulary learning利用大规模视觉语言预训练模型(例如 CLIP 、ALIGN)来计算视觉概念之间的匹配相似度 和文本语料库。最近,出现了一系列基于分段的开放式词汇研究 [1, 37, 38],用于为单个分段任务设计任务特定的架构和参数。例如,ZSSeg [38] 利用现成的预训练 CLIP 模型,在开放词汇语义分割方面取得了有竞争力的表现。然而,当前的工作在推广到一般分割场景时存在两个明显的缺点:i)任务不敏感:它们无法捕获任务感知特征并有效推广到不同的分割任务;ii)资源不友好:切换任务时需要从头开始训练模型,多样化的任务需要部署多个定制模型。尽管 MaskFormer [6] 成功地将多个分割任务集成到一个紧凑的系统中,但它仍然需要为每个任务训练一个定制的模型,并且它不是为开放词汇任务设计的。这些观察促使我们提出一个问题:如何设计一个统一的开放式词汇框架来完成通用的分割任务?
为了解决上述问题,如图所示,作者提出了 FreeSeg,这是一种实现统一、通用和开放词汇图像分割的新框架。在 FreeSeg 中,新的框架目标主要有三个方面:i) Unified:FreeSeg 设计了一个统一的(一体式)网络,该网络采用相同的架构和推理参数来处理多个分割任务;ii) Universal:FreeSeg 适应各种任务,即语义、实例和全景分割;iii) Open-Vocabulary:FreeSeg 能够泛化到任意分割类别。
总的来说,FreeSeg提出了一个两阶段的分割框架,第一阶段提取通用的proposals,第二阶段对这些masks完成零样本分类。具体来说,FreeSeg 进行一次性训练程序来优化具有多任务标签的统一分割模型,这有助于捕获任务特殊特征以进行通用分割。引入自适应提示学习方案以将任务感知和类别敏感的概念编码到文本抽象中。它使 FreeSeg 能够灵活地完成任意类别的不同分割任务,处理一个模型中的所有任务和类别。综上所述,FreeSeg是一个任务灵活、非指定类别、性能卓越的框架。
2. 方法
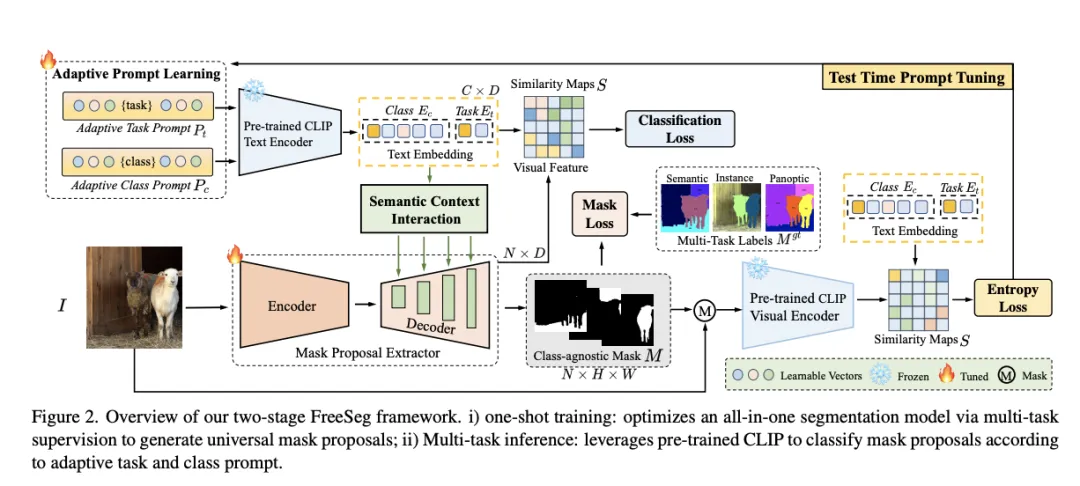
2.1 Framework
所提出的FreeSeg目标是在优化完整的模型以获得任意类别的语义、实例和全景分割结果。为了解决这个新任务,作者在本文中提出了一个新的框架来完成统一和通用的开放词汇分割,称为 FreeSeg。FreeSeg 提倡两阶段框架,第一阶段提取 universe mask proposals,第二阶段利用 CLIP 对第一阶段生成的 masks 进行零样本分类。
在训练阶段,FreeSeg 的训练数据包含图像、可见类别、任务名称和多任务标签。掩码提案提取器将图像编码为视觉概念和与类别无关的面具,由特定任务的标签监督。自适应提示学习用于将任务和类别概念嵌入到联合文本嵌入中,从而使 FreeSeg 能够根据任意文本对生成的掩码进行分类。总训练损失公式为交叉熵损失和mask损失。其中mask的loss为:
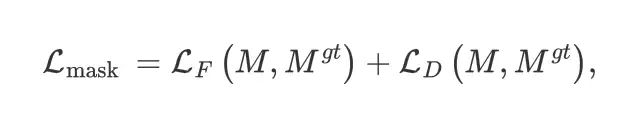
然后再用余弦相似度对prompts的matching score进行计算。然后就是加权求和。
在测试阶段,FreeSeg 使用文本指导生成二进制的mask,并计算掩码表示和紧凑文本嵌入之间的相似度,以输出可见和不可见类的面向任务的分割结果。
2.2 Adaptive Prompt Learning
Adaptive Prompt Learning是论文中提出的一种技术,用于将任意任务和类别编码为紧凑的文本抽象。它将多粒度概念(任务、类别)显式编码为紧凑的文本抽象,并帮助统一模型概括为任意文本描述。自适应即时学习在FreeSeg中起着至关重要的作用,它建立了语义上下文交互和测试时间提示调整机制,以改善看不见的类的跨模型对齐和泛化。它将任务感知和类别敏感的概念编码到文本抽象中,这有助于捕捉任务特殊特征以实现通用分割。
具体来说,Adaptive Task Prompt用于捕捉特定任务的特征,避免不同任务之间的训练冲突。同时也引入了Adaptive Class Prompt来提高开放域性能并将其推广到看不见的类别。将类和任务文本嵌入融为一体,以创建多粒度嵌入。
2.3 Semantic Context Interaction
Semantic Context Interaction的目的是通过将文本信息与视觉信息相结合,来改善跨模态特征匹配和对齐的效果,从而提高图像分割的性能。该模块采用了交叉注意力机制,可以有效地将文本特征与多尺度视觉特征进行关联,从而捕获任务和类别信息,并为全面推断提供更可靠的线索。此外,该模块还具有测试时间提示调整机制,可以帮助改善看不见的类的跨模型对齐和泛化能力。总的来说,语义上下文交互模块是FreeSeg算法中至关重要的一部分,可以提高分割性能并提供更准确的结果。
2.4 Test Time Prompt Tuning
Test Time Prompt Tuning致力于在测试过程中改善看不见的类别的跨模态对齐性。该机制在 FreeSeg 算法中起着至关重要的作用,它利用Test Time Adaptation (TTA) 算法根据未见类的余弦相似度分数更新自适应类提示符。具体来说,TTA 算法计算未知类的余弦相似度分数的熵,并过滤掉具有高熵的分数,剩余的分数用于更新自适应类别提示。这样可以改善看不见类别的跨模态对齐性,从而提高 FreeSeg 对未见类别的泛化能力。总之,测试时间提示调整机制是一种有效的方法,可以在测试期间优化自适应类提示符,从而提高算法的性能。
3. 实验
FreeSeg 通过仅使用一个统一模型来完成不同层级的任务,从而降低了推理过程的计算成本。这是通过对所有不同设定的任务(包括开放词汇语义、实例和全景分割)使用相同的训练模式和参数设定来实现的。与单项任务训练相比,这种方法可将训练成本降低约三分之二。通过一次性训练优化这种一体网络一体化网络,FreeSeg 在各种设定的分割任务、训练数据集和zero-shot泛化方面都取得了最好的性能。
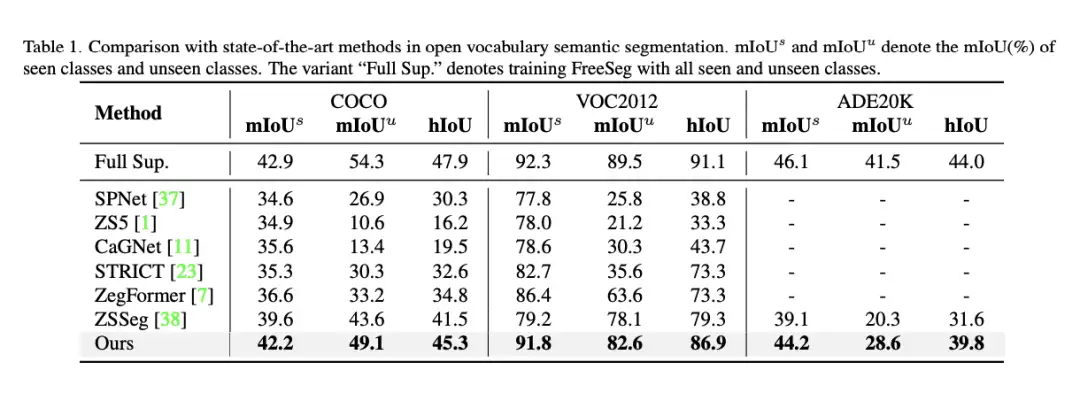
将 FreeSeg 的性能与其他最先进的open set下的语义分割方法进行了比较。该表显示了看见和看不见的类别的交叉点 over Union (miOU) 的平均分数。联合交集 (iOU) 是图像分割任务中常用的评估指标。它测量预测的分割mask和ground-truth mask之间的重叠程度。
表 1 将 FreeSeg 与其他最先进的开放词汇语义分割方法进行了比较,包括 SPNet、ZS5、CagNet、STRICT、ZegFormer 和 zsSeg。该表显示,与之前的最佳方法 zsSeg 相比,FreeSeg 在 COCO 和 ADE20K 数据集上对看不见的类别获得的 miOU 分数更高。还将 FreeSeg 与全监督的baseline方法进行了比较,后者表示为 “Full Sup”。“,它接受过看见类别和看不见类别的训练。值得注意的是,在COCO这些数据集上,FreeSeg 只比全监督的baseline稍差一点。该表还显示了FreeSeg的hiOU分数,其setting与之前的工作保持一致,其表现明显优于zSSeg。该表显示 FreeSeg 在处理各种分割任务的时候,有非常出色的表现。
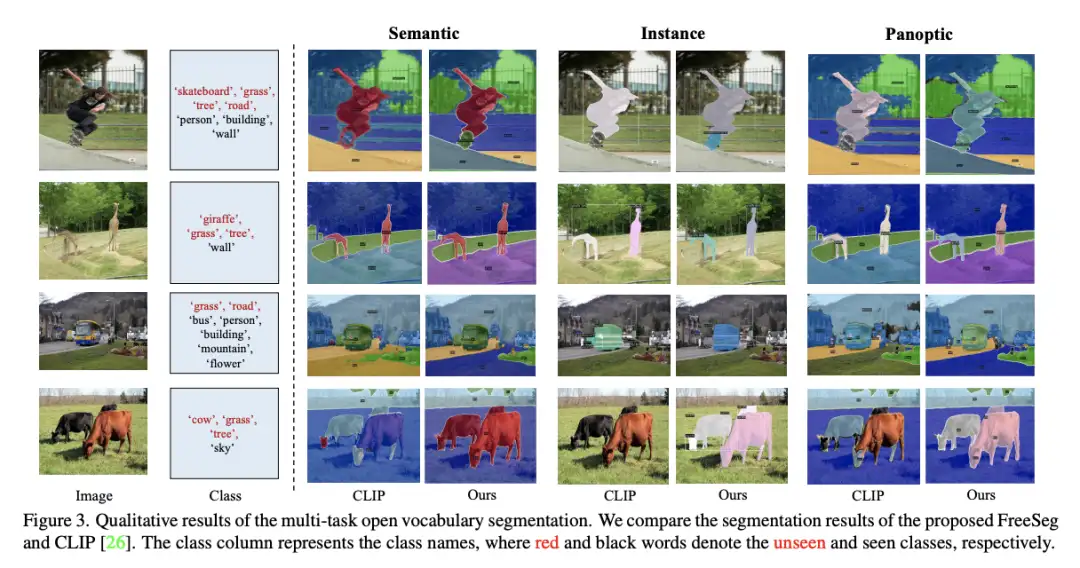
可视化的统一开放词汇分割的定性结果
CLIP 未能在第一张和第四张图像中分割一些看不见的类的实例,如“牛”和“滑板”,然而 FreeSeg 对看不见的类别区域(例如 “长颈鹿” 或 “草”)进行了准确的语义分割。
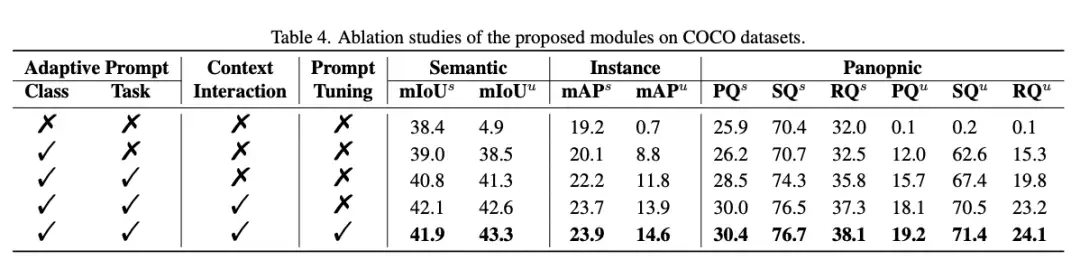
对于不同的数据集,具体而言FreeSeg的优势也是相当明显的:COCO 数据集:FreeSeg 在看不见的职业中获得了 49.1% 的miOU,比之前的最佳方法 zsSeg 高出 +5.5%。ADE20K 数据集:FreeSeg 在看不见的类别中中达到了 28.6% 的miOU,比之前的最佳方法 zsSeg 高出 +8.3%。Pascal VOC 2012 数据集:FreeSeg 达到了 85.7% 的miOU,这是所有开放词汇方法中报告的表现最高的。Cityscapes 数据集:FreeSeg 达到了 80.1% 的miOU,这是所有开放词汇方法中报告的表现最高的。这些结果证明了FreeSeg在处理各种分割任务时的有效性。
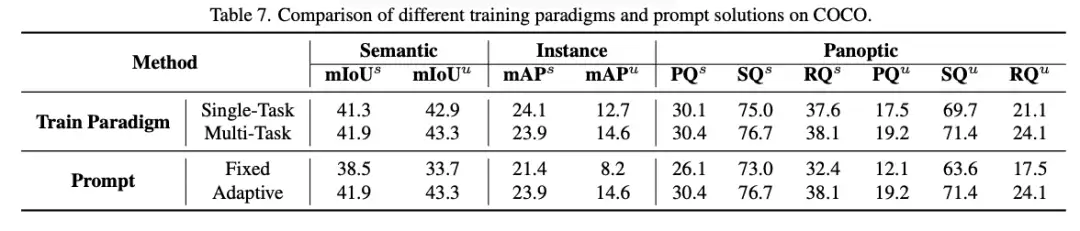
在降低训练成本和提高泛化性能方面,FreeSeg 的表现都优于单任务训练方法。与单任务训练相比,FreeSeg 将训练成本降低了约三分之二,并实现了更好的泛化性能。这是因为 FreeSeg 采用具有相同架构和推理参数的单一模型来完成开放词汇语义、实例和全景分割,这使模型能够学习更多可泛化的特征并减少对特定任务训练的需求。
4. 讨论
对于本文提出方法可能的应用场景,
- 自动驾驶:FreeSeg 可用于自动驾驶场景中的道路分段、物体检测和实例分割,在这些场景中,准确有效的分段对于确保安全至关重要。
- 医学成像:FreeSeg 可用于分割医学图像,例如 MRI 和 CT 扫描,以帮助医生诊断疾病和规划治疗。
- 机器人:FreeSeg 可用于仓库自动化和制造等机器人应用中的对象检测和分割,以提高效率和准确性。
- 农业:FreeSeg 可用于精准农业中的作物分割和病害检测,在精准农业中,准确、及时的分割可以帮助农民优化作物产量并减少浪费。
这些只是FreeSeg方法潜在应用的几个例子。FreeSeg 的灵活性和泛化能力使其成为不同领域的各种图像分割任务的有前途的框架。
本文有一些局限性,例如:
- 提出的框架依赖于预先训练的模型,例如 CLIP,这些模型可能并不可用或适用于所有应用方法。
- 对于某些需要特定任务架构或训练策略的特定分段任务,拟议的框架可能不是最佳的。
- 由于内存和计算限制,拟议的框架可能无法扩展到大型数据集或高分辨率图像。-提议的框架可能无法处理带有遮挡、重叠对象或细粒度细节的复杂场景,这可能需要更高级的技术。
5. 结论
本文提出了一个名为FreeSeg的通用框架,用于实现统一、open-vocabulary的图像分割。FreeSeg 采用具有相同架构和推理参数的单一模型来完成开放词汇语义、实例和全景分割。拟议的框架在不同的分段任务、训练数据集和零点泛化方面确立了新的先进性能。与单任务训练相比,FreeSeg 成功地将训练成本降低了约三分之二,并实现了更好的泛化性能。作者认为,他们的工作可以提供启发性的见解,并为开放词汇分割提出一条新的前进道路。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR'23|泛化到任意分割类别?FreeSeg:统一、通用的开放词汇图像分割新框架
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
通用AI大型模型Segment Anything在医学图像分割领域的最新成果!
可复现、自动化、低成本、高评估水平,首个自动化评估大模型的大模型PandaLM来了
实例:手写 CUDA 算子,让 Pytorch 提速 20 倍
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary
标签:分割,泛化,训练,任务,FreeSeg,类别 From: https://www.cnblogs.com/wxkang/p/17400226.html