前言 SAM 是一种在自然图像分割方面取得成功的模型,但在医学图像分割方面表现不佳。MedSAM 首次尝试将 SAM 的成功扩展到医学图像,并成为用于分割各种医学图像的通用工具。为了开发 MedSAM,首先需要一个大型医学图像数据集,其中包括来自 11 种不同模态的超过 20 万个 Mask。该数据集用于训练和微调 MedSAM 模型。最重要的是,提供了一种简单的微调方法,使 SAM 适应一般的医学图像分割。
通过对 21 项三维分割任务和 9 项二维分割任务进行综合实验,对 MedSAM 的性能进行了评估。结果显示,在三维和二维分段任务中,MedSAM 的表现优于默认的 SAM 模型。为了方便理解 MedSAM,下面先来看下 SAM 的流程。
本文转载自GiantPandaCV
作者 | 李响
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

目录
- 前言
- SAM 拆解分析
- 从医学角度理解 SAM 的效用
- MedSAM
- 实验
- 总结
- 参考
SAM 拆解分析
基础模型有很强的泛化能力,这种能力通过提示工程(prompt engineering)实现,想要实现提示分割任务,需要解决三个问题:任务目标、模型结构和数据。
分割提示指的是完成图像分割需要的 prompt 或者提示语,最常见的 prompt 包括点、bbox(框)、掩模图和文本描述。任务要求收到任意提示符时均需要输出至少一个有效 mask,即使提示符存在歧义。比如衣服上的点可能是想分割衣服,也可能是想区分人体。这两者至少需要输出一个。
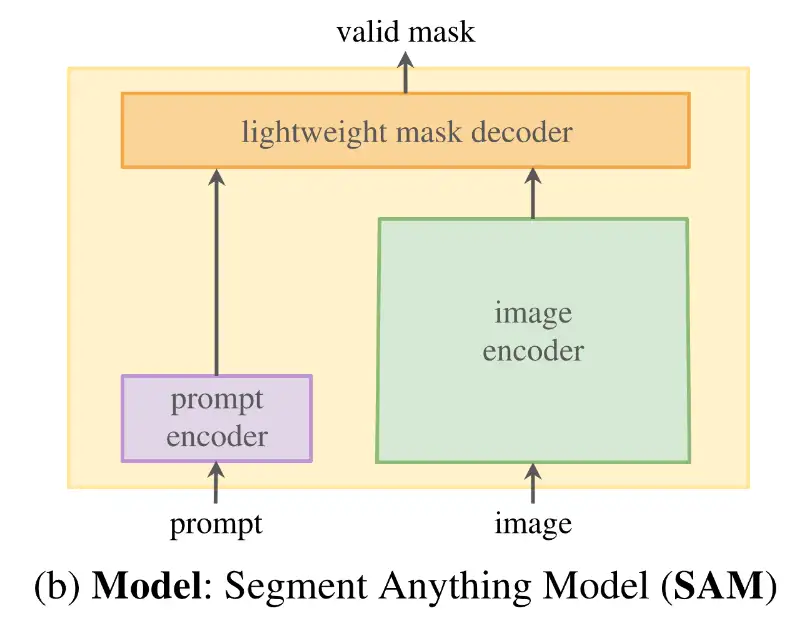
如下图所示,SAM 结构简单,包括一个图像编码器,一个 prompt 编码器和一个轻量级的解码器。
此外,一个大规模的数据集是必不可少的,现有的数据集无法胜任这个任务。故设计了一个数据引擎去制造大量的高质量数据来解决这个问题,通过数据引擎可以得到数据集 SA-1B,总共包含了 1100 万张高分辨率图片和 11 亿个 mask。
关于 Image encoder,输入图像输入前被预处理为 1024*1024,Image encoder 采用MAE VIT-H/16,是经典的视觉 Transformer 结构,最后输出(256,64,64)的图像 embedding。
关于 Prompt encoder,根据不同的 prompt 会有不同的编码方式,点和框的 embedding 通过位置编码获得,Mask 的 embedding 通过卷积操作获得,文本的 embedding 则是通过 Clip 的 encoder 获得。
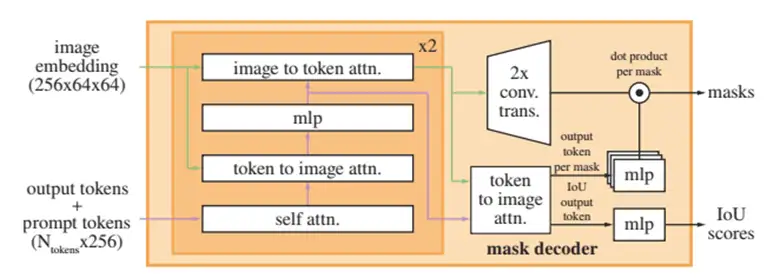
关于 Mask decoder,首先做 prompt 的 self-attention, prompt 到图像 embedding 的 Cross-attention。Cross-attention 是指在有两个相同维度序列的情况下,而其中一个序列用作查询 Q 输入,而另一个序列用作键 K 和值 V 输入。将两个相同维度的嵌入序列不对称地组合在一起。然后,右侧 MLP 均为三层,输出维度与图像 embedding channel 相同的向量,左侧 MLP 为 2048 个神经元,主要作用为聚合全局特征。使用 MLP 更新 token,再做图像 embedding 到 prompt 的 Cross-attention。经过两轮 decode layer 之后,token 再次与图像 embedding 进行 Cross-attention,output token 作为可训练参数在 decoder 前加入到 prompt 中,分别通过两个 MLP,得到 mask 和 mask 的 IOU。
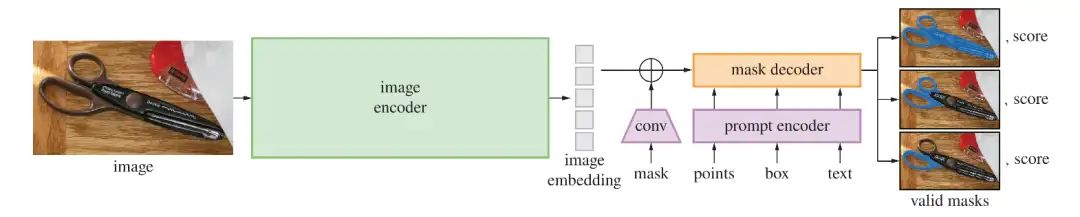
从医学角度理解 SAM 的效用
SAM 支持三种主要的分割模式:全自动分割模式、边界框模式和点模式,下图是腹部 CT 在不同 Prompt 下 SAM 的分割结果:
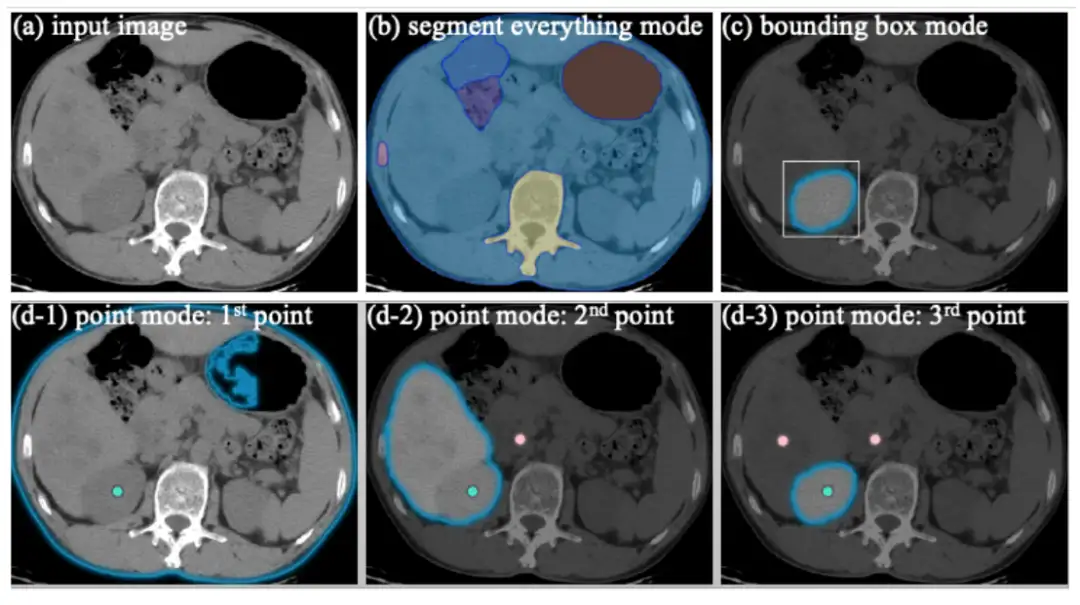
全自动分割模式根据图像强度将整个图像划分为六个区域。然而,由于两个主要原因,这种分割结果的实用性有限。一方面,分割结果没有语义标签。另一方面,在临床情景中,医生主要关注有意义的感兴趣区域,如肝脏、肾脏、脾脏和病变。基于边界框的分割模式仅需给出右肾的左上和右下点,就可以生成较好的结果。对于基于点的分割模式,我们首先在右肾中心给出一个前景点,但分割结果包括整个腹部组织。然后,我们在过度分割区域添加一个背景点。分割掩码收缩到肝脏和右肾。在肝脏上添加另一个背景点后,我们最终获得了预期的肾脏分割。总之,当将 SAM 应用于医学图像分割时,全自动分割模式容易产生无用的区域划分,基于点的模式模糊不清且需要多次预测-校正迭代。相比之下,基于边界框的模式可以明确指定感兴趣区域,无需多次尝试和错误即可获得合理的分割结果。此外,常用的标注方法之一是在放射学中标注最长直径,如固态肿瘤的反应评估标准(RECIST)。基于 RECIST 标注,可以轻松获得目标的边界框提示。因此,我们认为在使用 SAM 进行医学图像分割时,基于边界框的分割模式比全自动分割和基于点的模式具有更广泛的实用价值。
MedSAM
MedSAM 的目标是创建一种用于细分各种医疗图像的通用工具。为了使 SAM 适应医学图像分割,需要选择适当的用户 Prompt 和网络组件进行微调。SAM 的网络架构包含三个主要组件:图像编码器、提示编码器和掩码解码器。
MedSAM 选择微调掩码解码器组件。图像编码器基于 VIT,它在 SAM 中具有最大的计算开销。为了最大限度地降低计算成本,冻结了图像编码器。提示编码器对边界框的位置信息进行编码,可以从 SAM 中预先训练的边界框编码器中重复使用,因此也会冻结该组件。其余需要微调的部分是掩码解码器。
此外,预先计算了所有训练图像的图像嵌入,以避免重复计算每个提示的图像嵌入,这显著提高了训练效率。掩码解码器只需要生成一个掩码而不是三个掩码,因为在大多数情况下,边界框提示符可以清楚地指定预期的分割目标。
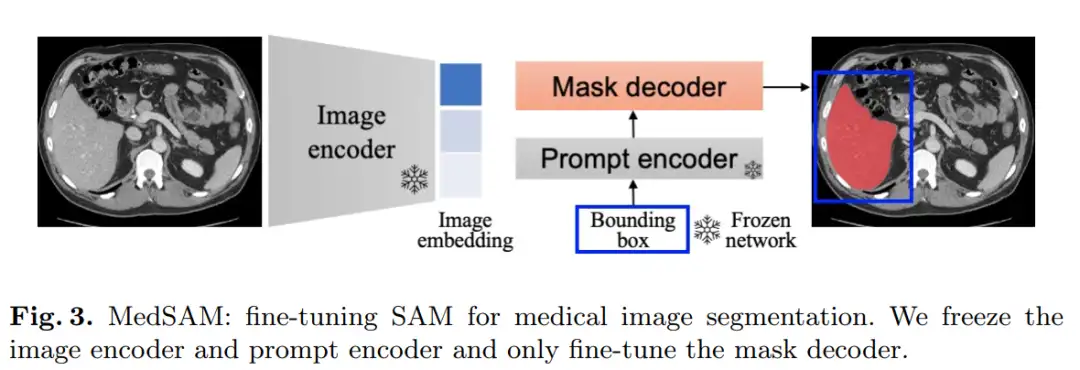 请添加图片描述
请添加图片描述
实验
整理了一个包含 33 个分割任务的大型多样化数据集,包括各种分割目标,例如脑心室、脑瘤、小脑、胆囊、心脏左心室、肝脏、胰腺、前列腺、腹部肿瘤、COVID-19 感染、头颈部肿瘤、胸腔积液、胃、乳腺肿瘤、血管、心脏和肺部、息肉、视网膜图像中的血管和图像中的结肠腺分割。
医学图像的强度值范围很广,这会使训练变得不稳定。为了解决这个问题,将所有图像标准化到相同的强度范围。对于 CT 图像,他们将强度值限制在 [-500,1000] 的范围,因为该范围涵盖了大多数组织。对于其他图像,他们将强度值削减到 0.95 到 99. 5百分位之间。然后,他们将所有强度值标准化到 [0,255] 范围,并将图像大小调整为 256 × 256 × 3 的统一大小。总而言之,整理了一个庞大而多样的数据集并对图像进行了预处理,以确保MedSAM 模型的稳定训练。
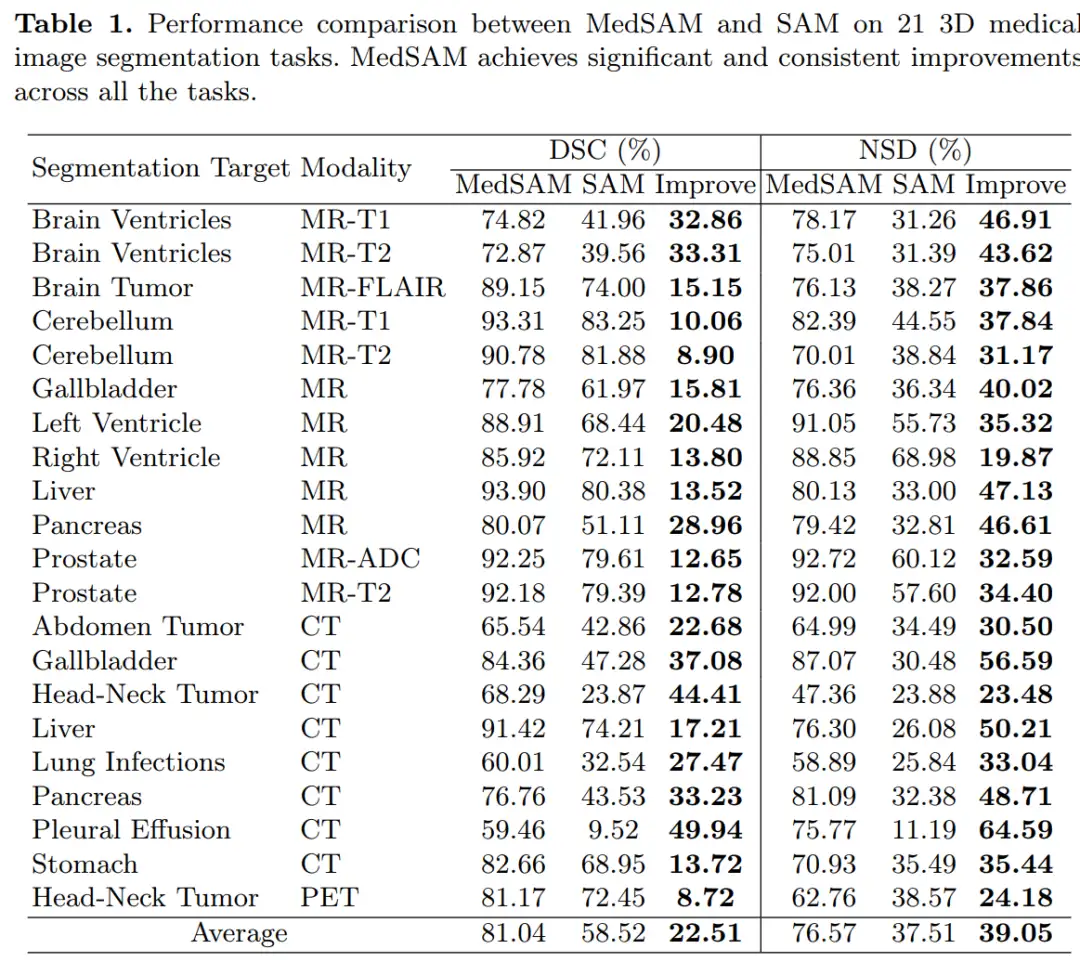
下表是在 3D 的不同模态数据上,MedSAM 和 SAM 的对比结果:
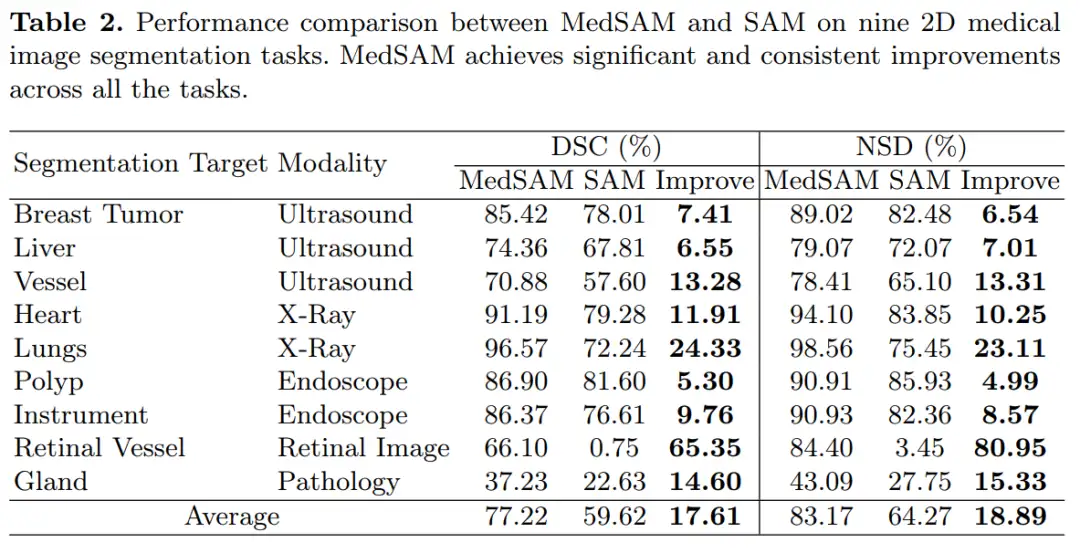
下表是在 2D 的不同模态数据上,MedSAM 和 SAM 的对比结果:
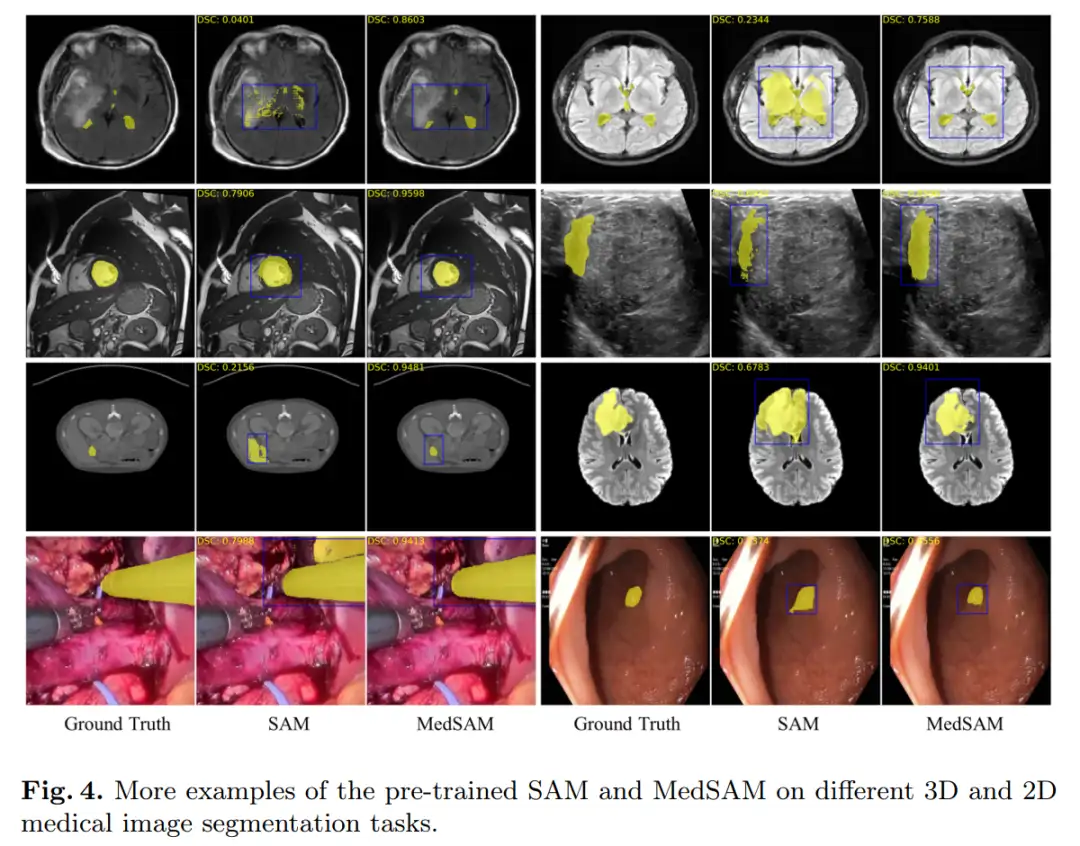
下图分别在 3D 和 2D 数据上做 MedSAM 和 SAM 的分割结果可视化,在同一个 Prompt 下,MedSAM 效果要好很多。
 请添加图片描述
请添加图片描述
总结
MedSAM 支持用户在自定义数据集上微调 SAM,提供带有小型数据集(包括 2D 和 3D)的分步教程,链接在:https://drive.google.com/file/d/1EvVBTSa9L7pDTmUOp-MHXxGD1lrU9Txk/view?usp=share_link。
参考
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
一次性分割一切,比SAM更强,华人团队的通用分割模型SEEM来了
CVPR'23|向CLIP学习预训练跨模态!简单高效的零样本参考图像分割方法
CVPR23 Highlight|拥有top-down attention能力的vision transformer
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:分割,prompt,Anything,SAM,AI,MedSAM,图像,Segment,CV From: https://www.cnblogs.com/wxkang/p/17391348.html