当企业需要建设独立的数据仓库系统来支撑BI和业务分析业务时,有了“数据湖+数据仓库”的混合架构。但混合架构带来了更高的建设成本、管理成本和业务开发成本。随着大数据技术的发展,通过在数据湖层增加分布式事务、元数据管理、极致的SQL性能、SQL和数据API接口能力,企业可以基于统一的架构来同时支持数据湖和数据仓库的业务,这就是湖仓一体架构。

— 湖仓一体架构简介—
传统的企业数据湖大多是基于Hadoop或云存储来建设,为数据科学和机器学习任务提供半结构化和非结构化的数据能力。企业的BI和业务分析等需要数据的加工过程有严格的一致性保障,在分析过程中有优秀的SQL性能,而开源Hadoop或云存储并不具备这些能力,因此企业需要建设独立的数据仓库系统来支撑这类业务,从而就有了“数据湖+数据仓库”的混合架构。混合架构带来了更高的建设成本、管理成本和业务开发成本。随着大数据技术的发展,通过在数据湖层增加分布式事务、元数据管理、极致的SQL性能、SQL和数据API接口能力,企业可以基于统一的架构来同时支持数据湖和数据仓库的业务。工业界和开源社区都在陆续探索相关的技术,星环科技于2014开始基于Hadoop研发相关技术,并于2016年在关系型分析引擎Inceptor内提供了分布式事务等能力。2017年Uber工程师开始研发Apache Hudi项目,2019年Netflix开源了Iceberg项目,2020年Databricks在其云服务上推出了Delta Lake,这些项目都尝试来解决在数据湖上提供数据仓库能力的需求并且得到了技术界的广泛参与和大力推动。
赛迪顾问在2022年7月发布的《湖仓一体技术研究报告》中指出,湖仓一体架构的主要关键特征包括:
- 支持多模型数据的分析和探索,包括结构化、半结构化(如JSON)以及非结构化数据
- 事务支持,保证数据并发操作下的一致性和准确性。
- BI支持,可以直接在源数据上使用BI工具,无需通过复杂的从数据仓库建模到数据集市对接业务分析这样长的数据链路,业务响应时效性高。
- 一份数据存储,数据湖内直接做数据治理,减少数据副本和冗余流动导致的算力和存储成本。
- 存算分离,数据存储全局公用并按容量要求扩缩容,而算力可以根据计算需求做弹性伸缩,计算和存储按照各自需求独立扩展。
- 业务开放性,支持标准化的SQL和API,可以灵活的支持各种机器学习语言和框架。
《湖仓一体技术研究报告》也指出,在技术实现路径上,湖仓一体的落地路径有三种方式:
第一种方式是基于Hadoop体系的数据湖向数据仓库能力扩展,直接在数据湖中建设数据仓库,从而最终演进到湖仓一体,这样可以在比较低成本的数据湖的存储上构建数据仓库体系,需要有比较好的事务支持和SQL性能。国外的一些数字化比较成功的企业如Uber在使用这些技术路线,在Hadoop上采用Hudi等新的存储格式来支持数据仓库的业务需求。国内星环科技是这类技术的主要推动者,星环科技在2015年就已经基于HDFS和ORC文件格式实现了分布式事务的支持和SQL能力,因此星环产品已经经过了数百个客户的生产实践和打磨,相比开源技术框架具备了比较好的成熟度,已经帮助很多客户落地了湖仓一体架构。
第二种方式是基于云平台的存储或者第三方对象存储,在此之上构建Hadoop或者其他自研技术来搭建湖仓一体架构,一些云厂商在推进该路线。该路线在存储层基于云服务来实现存算分离,而分布式事务、元数据管理等能力则依赖自研技术框架或整合开源Iceberg。
第三种方式是基于数据库技术做深度研发,进一步支持多种数据模型和存算分离技术来支持数据湖类的需求,以Snowflake 和Databricks为代表。下面我们将分两篇来阐述Apache Hudi、Iceberg、Delta Lake和星环Inceptor的实现原理和差异性。
— Apache Hudi—
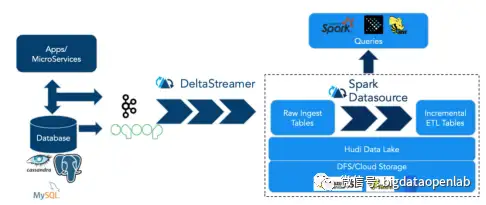
Hudi 是Hadoop Upserts Deletes and Incrementals的简写,顾名思义,是为了在Hadoop上提供update、delete和incremental数据处理能力。Hudi是由 Uber 的工程师为满足其内部数据分析的需求而设计的数据湖项目,业务场景主要是将线上产生的行程订单数据,同步到一个统一的数据中心,然后供上层各个城市运营同事用来做分析和处理。在 2014 年的时候,Uber 的数据湖架构相对比较简单,业务日志经由 Kafka 同步到 S3 上,上层用 EMR 做数据分析;线上的关系型数据库以及 NoSQL 则会通过 ETL任务同步到闭源的 Vertica 分析型数据库,城市运营同学主要通过 Vertica SQL 实现数据聚合,但是系统扩展成本高导致业务发展受限。Uber团队后来迁移到开源的 Hadoop 生态,解决了扩展性问题等问题,但原生Hadoop并不提供高并发的分布式事务和数据修改删除能力,因此Uber的ETL 任务每隔 30 分钟定期地把增量更新数据同步到分析表中,全部改写已存在的全量旧数据文件,导致数据延迟和资源消耗都很高。此外在数据湖的下游,大量流式作业会增量地消费新写入的数据,数据湖的流式消费对他们来说也是必备的功能。所以,他们就希望通过Hudi项目不仅解决通用数据湖需求,还能实现快速的 update/delete以及流式增量消费。这样Uber的数据链路就可以简化为下图的形式,其中DeltaStreamer是一个独立的data ingestion服务,专门负责从上游读取数据并写入Hudi。
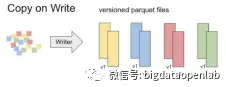
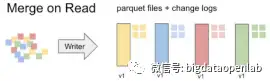
快速的update和delete是核心诉求,因此Hudi项目针对这个需求做了大量的系统设计。如果需要对数据文件内的数据修改,最原始的方式是将初始数据文件的数据读入内存,再与内存中待修改的数据合并,之后再将数据写入数据文件。这就导致所有的数据被读一遍写一遍,如果文件较大,这个性能就极慢。MVCC机制可以解决这个问题,每次增量更新的数据会独立写入一个delta文件中而不是修改初始数据文件,而在读数据的时候,将初始数据和delta文件中的数据都读入内存,再按照数据的版本和新旧情况进行合并。Hudi进一步细化了MVCC的设计,针对不同场景设计了Copy on Write和Merge on Read两种数据表格式,其中Copy on Write格式的表每个事务操作后会将全量的新数据生成一个版本,这样后续的读数据表的速度就比较快但是事务事务操作慢,适合一些低频修改但是高频读取的中小数据量表,譬如码表;Merge on Read格式的数据表在修改操作时写入一个独立的delta/delete文件中,而在读取的时候再将base文件和delta文件一起读入内存并按照记录进行merge合并,这种方式修改速度快而读取速度相对慢,比较适合大数据量或修改较为频繁的表。开发者可以按照业务需求为每个表选择合适的模式。值得一提的是,大部分存储引擎的实现都默认采用Merge on Read的格式。
列式存储有比较好的数据分析性能,但是因为无法精准定位到某个记录行,点查性能普遍不佳。Hudi为了更好的查询性能而设计了类似主键的HoodieKey,并且在HoodieKey上提供了BloomFilter等功能,这样无论是点查还是精准的数据delete,都可以更快的找到需要修改的数据区域,从而提升事务操作的性能。
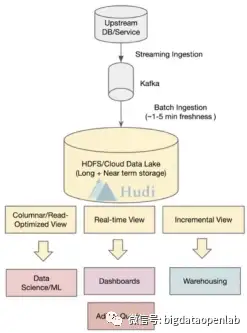
此外,为了支持增量的流式数据读取,Hudi支持给上层分析引擎提供三种不同的读取视角:仅读取增量文件(Incremental View)、仅读取初始数据(Read-Optimized View)以及合并读取全量数据(Real-time View),对于实时数据分析可以仅仅读取增量文件,一些对数据准确性要求不高的业务,如对机器学习,可以采用读取初始数据的方式来提速,而对数据仓库类要求数据一致性的任务需要采用合并读取全量数据方式。
与Delta Lake为了更好的服务机器学习类业务不同,Apache Hudi主要是为了结构化数据的ETL和统计分析,以及更好的实时计算效果,都是围绕着SQL业务展开,因此其在设计上没有太多考虑机器学习类编程语言和框架的需求。
— Apache Iceberg —
Netflix的数据湖最早采用Apache Hive来建设,底层数据存储基于HDFS,而Hive提供了数据表schema的保证和有限的ACID功能支持。由于Hive需要基于独立的metastore来提供数据表元信息查询,在数据分区特别大的情况下metastore的性能不足,这导致一些分区多的数据表上的查询分析性能不能满足业务需求,这是当时Netflix团队面临的最大问题。另外Hive的ACID实现不够完整,一个事务写HDFS和metastore会存在原子性不足问题,一些故障情况下数据会存在一定的不一致问题,引入一些额外的数据校验工作。此外Netflix希望能够拓展到对象存储上,从而能够实现存算分离。基于以上原因,Netflix建了Iceberg项目来期望解决构建数据湖出现的各种问题。需要特别指出的是,Iceberg是一个面向数据湖系统设计的一个数据表的存储格式,不是一个独立的进程或服务,这是和Delta Lake和Hudi最大的区别,它需要计算引擎加载Iceberg library。
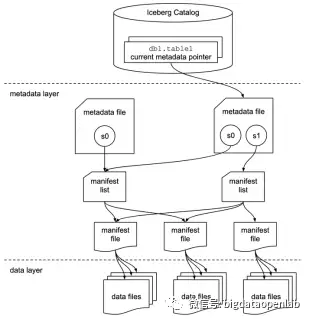
由于Iceberg要解决Netflix遇到分区多导致的各种问题,它重点设计了数据表的元数据管理和分区相关的功能。与其他各种引擎依靠一个meta服务不同,Iceberg将元数据直接存在文件中,如上图所示。表的所有状态都保存在metadata文件中,对表的新修改都会产生一个新的metadata文件,这里面保存了表schema、partition、snapshot和一些其他表属性信息。这个设计是Iceberg为了解决其他引擎需要额外依赖一个独立meta服务,而meta服务可能存在性能瓶颈问题。
Iceberg表的物理数据存储是以数据文件方式保存的,这与其他系统(如Hive、Hudi等)都采用“目录-文件”两层结构不同,因为其他系统依靠文件目录做partition切分,SQL优化器做partition pruner优化的时候,需要多次调用文件系统的remote API以确定各个目录情况,从而确定分区并按执行计划做裁剪,由于文件系统的API调用相对内存计算偏慢,尤其是在partition数量比较大的情况下往往需要非常多的时间,Iceberg的方法是采用多个manifest 文件来直接管理数据文件,这样计算引擎可以直接将manifest文件加载进内容,从而在优化过程中只需要在内存中计算partition pruner,无需多次文件系统的访问,从而提高访问速度。由manifest文件记录并指向对应的数据文件,manifest文件中为每个数据文件都记录一行信息,包括partition信息和一些metrics数据,这为后续的partition优化提供数据支撑。
基于这一的架构设计,每次对数据表做一个事务操作,就会产生一个新的metadata文件,每次commit之后Iceberg catalog会通过一个原子操作将metadata pointer指向这个新的metadata文件。因此,在事务隔离级别上,Iceberg只能提供Serializable隔离级别,不能提供其他更高的隔离级别,并且所有的事务操作都是全表级别的,而其他存储引擎大部分可以做到分区级。这个设计会导致实际生产业务中Iceberg更容易在并发操作情况下遇到锁冲突问题,譬如数仓中间层的宽表由于会有多个数据流同时加工,就会出现比较多的锁冲突。Iceberg采用了乐观并发控制(optimistic concurrency)策略,出现冲突后就会基于新的事务数据来重试当前session的SQL事务操作。这个方式的好处是事务协议实现的比较简化,但是坏处就是对同一个表的并发事务操作越多,事务abort率就会迅速提升,并且浪费SQL计算资源。因此在事务的支持上,Iceberg相对其他项目要偏弱一些。
在MVCC的实现上,Iceberg也采用了Merge on Read的实现。一个事务内所有的修改操作都独立存储在delete file中,在设计上Iceberg充分借鉴了数据库binlog的思路,delete file中记录行为有两种方式,一个是position deletes,即详细记录哪个数据文件的哪一行被删除了,主要用于一些精准的少量数据删除;还有一个方式是Equality deletes,它无法记录哪些明确的行被删除,但是会记录是通过什么样的表达式来选择到这些数据行并执行删除,主要用于一些批量删除操作。由于不需要在数据文件中直接去修改数据,也不需要random access文件,因此Iceberg对底层文件系统的要求比较低,不需要文件系统层面的事务、random access以及POSIX接口,即使是最简单的S3对象存储也可以支持,这也保证了Netflix后续可以基于对象存储来构建数据湖。
综上所述,Iceberg采用了一个非常不同的架构设计来解决Netflix遇到的一些问题,因为其核心在于解决了数据查询场景下遇到的meta数据的性能和可扩展性问题,尤其是partition过多情况下的性能问题;在数据操作上能够提供ACID功能但是事务并发性能较弱;可以基于对象存储来做数据湖建设。此外,Iceberg本身不是存储引擎,因此也无法提供类似主键等功能,需要跟Spark、Presto等计算引擎配合使用。因此,Iceberg适合的企业群体的特征也非常鲜明,比较典型的在线互联网企业的营销和风控场景,有大量类似实时数据或日志类数据,都是按照时间轴来做精细化的数据分析,近期数据价值高而中远期数据价值不大,数据分区数量特别多,并且有计算引擎的开发和优化能力。由于其设计上事务能力比较弱,并不太适合高并发的数据批处理和数据仓库建模工作。此外,在数据安全管理上需要额外重视,metadata文件的损坏就可能导致数据的丢失。
— 小结—
本文介绍了Apache Hudi和Apache Iceberg两个湖仓一体架构,下篇将继续介绍星环科技Inceptor和Delta Lake两个技术。
标签:数据分析,存储,Iceberg,数据仓库,事务,湖仓,Hudi,数据,存算 From: https://www.cnblogs.com/Transwarp/p/17325679.html