CNN小结:VGG & GoogleNet & ResNet & MobileNet..
目录
VGG
VGG 之名从哪里来:

深度学习模型不同于机器学习中的强分类器开箱即用,很多时候,需要根据任务和数据集调整网络结构。
VGG 强调了一个基本的共识:加深网络深度可以增强模型的表征能力
- 更强大的表达能力:如果将深度学习模型视为一个函数拟合过程,那么更深的模型会包含更多的线性变换和非线性变换,可以拟合更复杂的函数映射,拟合更复杂的特征。
- 逐层的特征学习:低层网络学习关于目标的浅层信息,深层网络基于浅层网络进行特征组合和变换,从而模型可以表达更复杂的数据模式。
核心想法
构造"n 个卷积 + 池化"的基本块结构(block),重复这种 block 结构加深网络深度。其中,池化层主要做两倍的下采样,整个网络结构是一个重复架构。
- 考察卷积神经网络的深度对模型表现能力的影响。
- 通过 3x3 卷积层将模型深度推到 19 层。
网络结构


-
全程 3x3 卷积,没有用到其他尺寸的卷积:大卷积层可以用多个小卷积层堆叠,得到相近的感受野和表现能力。一个 5x5 用两个 3x3 替代,一个 7x7 用三个 3x3 替代,优点:
- 减少了参数量。
- 增加线性变换的次数。
-
没有使用 LRN(Local Response Normalization,局部响应归一层)
一般在卷积和池化后加这个层,但 VGG 的实验表明,这个层对提高模型精度没有什么帮助,反而增加了计算量。故而近些年主干视觉模型几乎没用到该层。
-
引入 1x1 卷积层,如果没有做升降维,那么只是在同一维度下的空间投影,此时用 1x1 卷积层是希望引入更多的非线性变换(激活函数)。
VGG16(图中 C)用到了,但是实验表明,效果没有 D 好。
Q
为什么加深深度可以提高模型表现?
- 更强大的表达能力:如果将深度学习模型视为一个函数拟合过程,那么更深的模型会包含更多的线性变换和非线性变换,可以拟合更复杂的函数映射,可以拟合更复杂的特征。
- 逐层的特征学习:低层网络学习关于目标的浅层信息,深层网络基于浅层网络进行特征组合和变换,从而模型可以表达更复杂的数据模式。
为什么要控制模型的参数量?
- 缓解过拟合。
- 参数量也会带来模型体积增大。
- 参数越多,参数空间也会更复杂,训练开销和对优化算法的要求也会提高。
- 通常在同性能下,模型参数量越少越好。
GoogLeNet
2012 年提出的 AlexNet 参数量大概在 6000 万,2014 年发表的 VGG 网络 16 层的参数量在 1.38 亿上下。GoogLeNet 的目标:网络更宽更深,但参数量更少。如何减少参数量,在 GoogLeNet 之前已经有许多尝试,包括用全局平均池化层取代全连接层、使用分组卷积、引入 dropout 等。GoogLeNet 充分借鉴了 NiN 网络使用 1x1 卷积的尝试,寻求在架构设计层面减少参数量。
核心想法
用卷积、池化等稠密元素构成的块(inception)去逼近一个稀疏结构,从而构造一个在参数量上与稀疏网络相近的稠密网络(GoogLeNe)。把网络做宽做深,保持模型容量的同时,减少参数量。
网络结构
Inception Module
串联的网络结构(类似 VGG)设计中,某一个具体的层,卷积和池化的大小(kernel size)通常是固定的,这个时候就要纠结,用一个 3x3 的卷积好,还是一个 5x5 的卷积好。
Inception Module 将各种卷积尺寸和池化层并联设计:
- 不纠结
- 可以抓取输入的各个层次的信息,较为全面地捕获特征。

原始的 Inception Module 缺点在于一个输入同时经过多个卷积层,计算开销大。
基于原始的 Module 改进的 Inception Module:
- 首要考虑怎么降低 Module 的计算量和参数量。
- 加 1x1 的卷积进行降维:3x3, 5x5 卷积前的 1x1 卷积降维是为了减少参数量。
- 最大池化层之后的 1x1 卷积降维是为了统一尺寸,方便进行特征融合。
辅助分类器
浅层卷积层抓取的更多是图像表面信息,深层卷积抓取的图像特征会更抽象。论文认为中间层的特征比较有辨别力(比较重要)。那就把中层特征拿出来再用一用,相当于加强中层特征的权重,提高模型性能。
- 将中间层结果用辅助分类器导出,辅助分类器的 loss 和最后主干网络的 loss,加权求和得到最后损失。基于最后损失进行反向传播,有助于帮助梯度回传,缓解梯度消失。
- provide additional regularization
GoogLeNet
Inception Module 是一个并联结构,GoogLeNet 是 Inception Module 和卷积、池化等层串联得到的网络。
- 全局平均池化代替全连接层:减少参数量,缓解过拟合。
- 保留最后的全连接层,方便根据分类的类别数进行调整。

Reference
https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202
https://sheng-fang.github.io/2020-05-05-review-googlenet-v1-v4/#1
Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
深度残差网络
深度残差网络(Deep Residual Learning for Image Recognition)。
vgg 最深 19 层,GoogLeNet 最深也没有超过 25 层,这些网络都在加深网络深度上一定程度受益。但从理论上来讲,CNN 还有巨大潜力可以挖掘。
但从实践的结果上看,简单堆叠卷积(VGG)或 inception 结构(GoogLeNet)并不能让网络实际表现更好,传统卷积模型堆叠思路遇到了瓶颈。

如上图,纵轴为训练误差,56 层网络在训练集和测试集上的表现都不如 20 层网络:
-
过拟合?
- 显然不是,如果过拟合,深层网络在训练集上的表现会更好,测试集上的表现会变差。
-
随着深度的增加造成更加明显的梯度消失和梯度爆炸?
- “This problem, however, has been largely addressed by normalized initialization [23, 8, 36, 12] and intermediate normalization layers [16], which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22].”(He 等, 2016, p. 1)
- 论文指出也不是这个原因,但这里可能也有争议(残差假设)。
-
深层网络更加难以优化。
- 文章指出:随着深度的增加,深层网络拟合的函数关系更加复杂。现有的训练流程和优化算法无法支持网络很好地训练,无法支持网络很好地收敛。
由此,对于一个已经具有良好表现的浅层网络,向其后继续叠加卷积、inception 等具有学习能力的层会使其表现能力变差,那么加深深度而不损失精度增大损失的最好方法,就只有在网络之后添加恒等函数。
这说明了一个惊人的、与直觉相悖的事实:在现有优化算法、优化思路下,在浅层网络后增加恒等函数很可能就是最优的(optimal)加深网络深度的方式。即便这种方式看起来是无效的操作,但我们确实无法通过实验找出比这种操作效果更好的架构,而从理论上来证明这一点就更加不可能。

VGG 堆叠卷积层,GoogLeNet 堆叠 inception 块,而残差网络堆叠以加深网路深度的结构是残差单元。理想情况下,经过适当训练,残差单元近似一个恒等函数。

- H(x) = F(x) + x
- 理想情况下有:H(x) = x
- 由以上两点:F(x) = 0
根据以上推导:理想情况下的训练过程在强迫中间层向 0 的方向拟合。对比通过堆叠非线性层拟合一个恒等函数,强迫向 0 方向拟合更加容易,更好优化。
“We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.”(He 等, 2016, p. 2, Introduction)
从直观角度理解:中间层运算的结果可能变差(信息损失),但有跳跃连接在,总归不会比原始输入差。
从另外两个角度解释:
- 可视化的 loss surface
- 残差网络是多个浅层网络的 ensemble
残差块的优点:
- 一种加深网络深度的合理方法。
- 残差连接几乎没有参数,不会增加网络的参数量。
- 残差块运算很快:强迫向 0 方向拟合。
- 很大程度上缓解了梯度消失。
缺点
- 对比没有跳跃连接的网络,显然显存要求更高。
resnet 到底带来了什么?
- 退化问题的原因:跟梯度消失关系不大,原因在于网络难以优化(resnet 假说)。
- 一种简单的加深网络深度的办法:用上跳跃连接。
- 让网络更深的同时更加易于训练。
下一步能干什么
- 跳跃连接的按元素加,如果改为在维度上拼接,是否有更优秀的表现 -> densenet.
网络结构
残差块
motivation
- 从理论上讲,模型越深,学习能力越强,模型表现越好。但实践结果并非如此,对适当深度的模型,继续增加其深度,模型表现反而变差。这就是退化问题(degradation problem)。
- 退化问题表明:如果对适当深度的模型继续添加带有学习能力的层,模型表现反而会变差。那么继续加深模型深度,而不影响模型表现的最优解,可能就是添加恒等函数的映射关系。这就是残差学习的想法的由来。
- 残差仍然延续了之前网络的基本思想,通过堆叠某种结构(block),加深网络深度。
一般残差块
一般网络结构拟合的底层映射:

残差块拟合的底层映射:

权重层的拟合目标从 H(x)变为 H(x) -x,拟合更加容易。
近似于恒等映射的残差块

足够深度之后,残差块整体趋向于拟合一个恒等函数,权重层向 0 的方向拟合。
We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.”(He 等, 2016, p. 2)
The degradation problem suggests that the solvers might have difficulties in approximating identity mappings by multiple nonlinear layers. With the residual learning reformulation, if identity mappings are optimal, the solvers may simply drive the weights of the multiple nonlinear layers toward zero to approach identity mappings.
瓶颈结构

在深层残差网络(50/101/152 层)中用上了瓶颈结构,主要目的是为了减少参数量,同时观察到模型效果并没有明显变差。参数量减少的收益大于性能衰减的程度。
Q:残差到底解决了一个什么问题?
参考该文:
- 从集成模型的角度解释残差的有效性。
- 从梯度破碎的角度。
- 该回答也是从梯度破碎的角度解释,可参考回答中列举的论文。
对具有跳跃连接的网络的可视化:

该图出自 NIPS 2018 讨论关于损失函数可视化方法的一篇文章(Li, Hao, et al. "Visualizing the loss landscape of neural nets." Advances in neural information processing systems 31 (2018).):
- 从图中可以看出,具有跳跃连接的残差网络损失函数表面更加平滑。
- 根据以上得出一个大致结论, 跳跃连接确实有效降低了网络训练和优化的难度。
那么残差是否完全解决了训练难的问题?
- 并没有,下图取自论文原文,将网络层数上探到千层,仍然出现了退化问题。

但不可否认,残差用一个非常简洁有效的方法,拉高了 CNN 的上限。或许正如何恺明所言,复杂的东西往往得不到本质。
Reference
Veit, Andreas, Michael J. Wilber, and Serge Belongie. "Residual networks behave like ensembles of relatively shallow networks." Advances in neural information processing systems 29 (2016).
Li, Hao, et al. "Visualizing the loss landscape of neural nets." Advances in neural information processing systems 31 (2018).
https://www.cnblogs.com/boligongzhu/p/15085678.html
https://blog.csdn.net/qq184861643/article/details/89438047
MobileNet
为移动和嵌入式设备设计的网络结构,网如其名,应用场景决定了网络的特点。
- 轻参数的网络结构
- 更加考虑效率和准确率的平衡,控制参数量
网络结构
深度可分离卷积
简单来说就是把特征图先过一个逐通道卷积,再过1x1卷积。
常规卷积
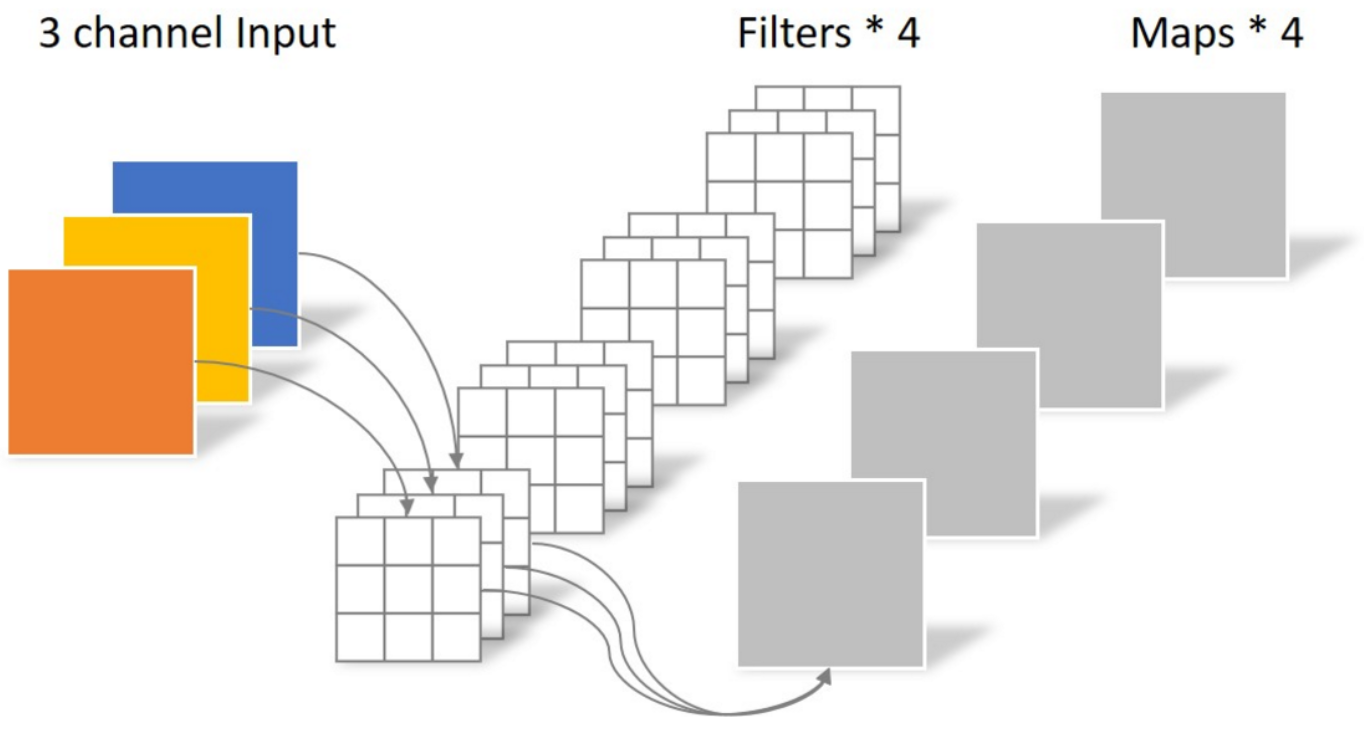
- 卷积核的维度和输入通道数(in_channels)有关,卷积核的个数和输出通道数(out_channels)有关。
- out_channels = kernel_size
- in_channels = kernel_channels
- N_std = 4 × 3 × 3 × 3 = 108
卷积核的参数量


-
Channel_in/Channel_out: 输入和输出的通道数
-
由上式知:要控制卷积层的参数量
- 小尺寸卷积核参数量小于大尺寸卷积核参数量 → 小尺寸卷积核的堆叠替代大尺寸卷积核、逐点卷积
- 控制输入通道数(卷积核的维度)和输出通道数(卷积核的个数)→ 分组卷积、逐通道卷积、深度可分离卷积
逐点卷积(Pointwise Convolution)
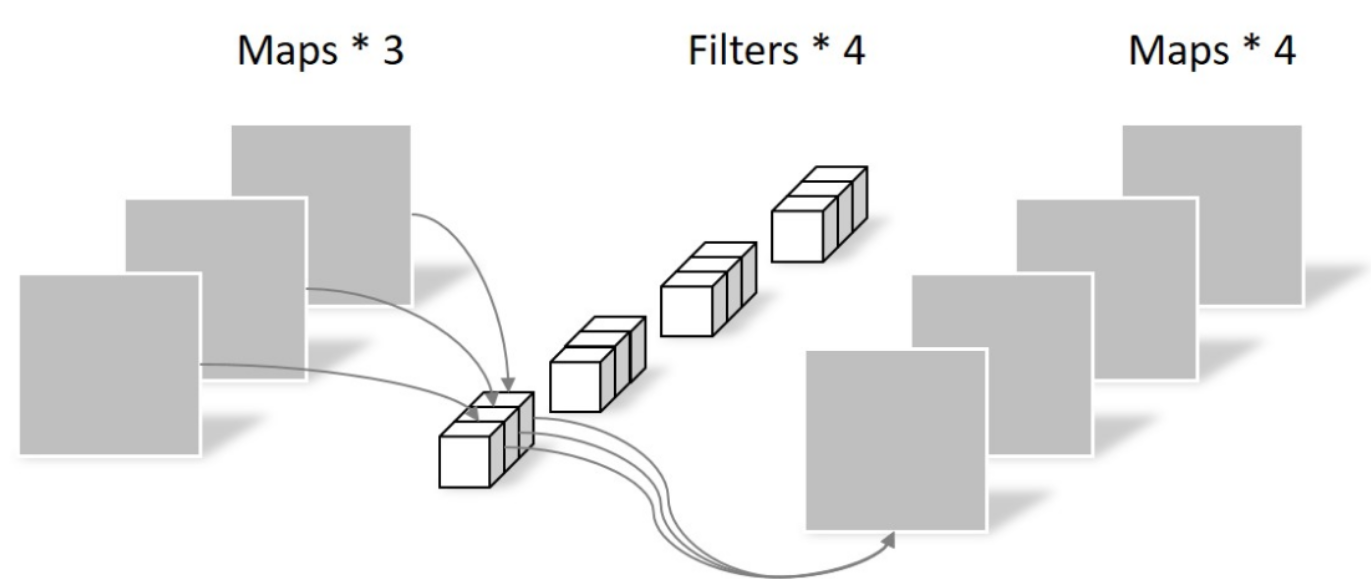
1x1卷积核(Network In Network, 2014)
- N_pointwise = 1 × 1 × 3 × 4 = 12
- 逐像素的点积运算
- 此时卷积运算得到的map是输入特征图在深度方向的加权求和(线性组合)。
- 通常用作升降维。
深度卷积(Depthwise Convolution)
深度卷积(Depthwise Convolution),更适合称为逐通道卷积。
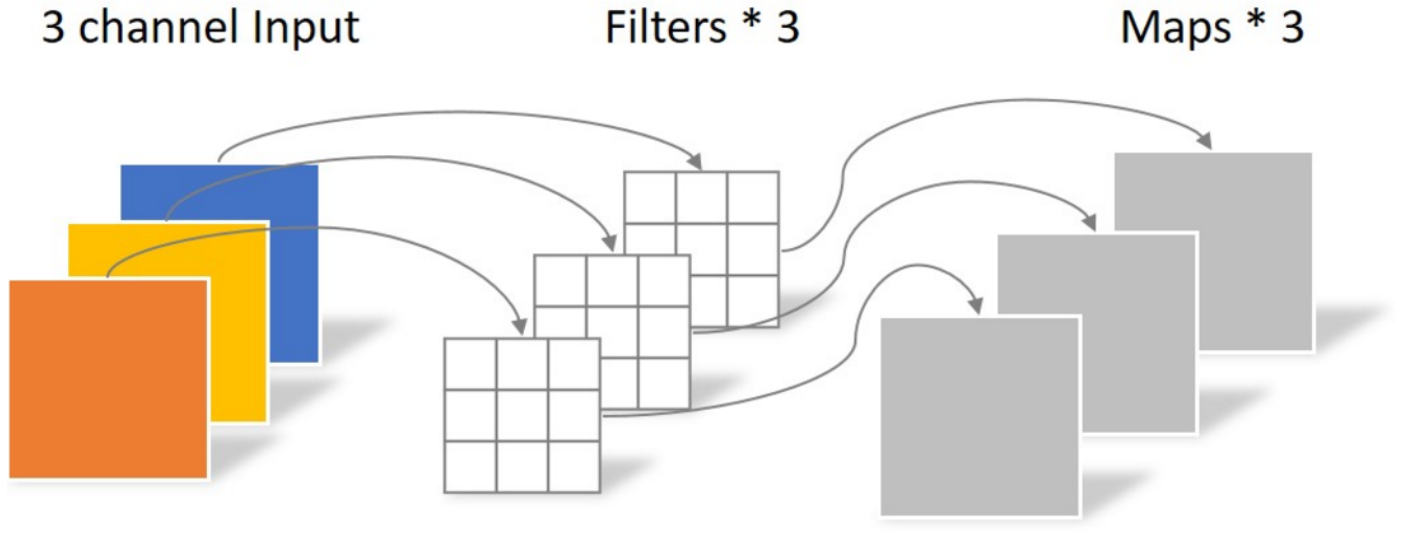
- 一个卷积核只有一个通道,只和一个输入通道做卷积运算。
- N_depthwise = 3 × 3 × 3 = 27
- 通过控制卷积核的维度和个数控制参数量,但缺点也显而易见,无法扩展特征图(对特征图升降维)
- 无法有效利用输入特征图在不同通道上相同空间位置上的特征信息。
深度可分离卷积(Depthwise Separable Convolution)
Xception: Deep Learning with Depthwise Separable Convolutios
基于以上深度卷积的缺点,一个改进方案是将深度卷积和逐点卷积结合,是为深度可分离卷积。
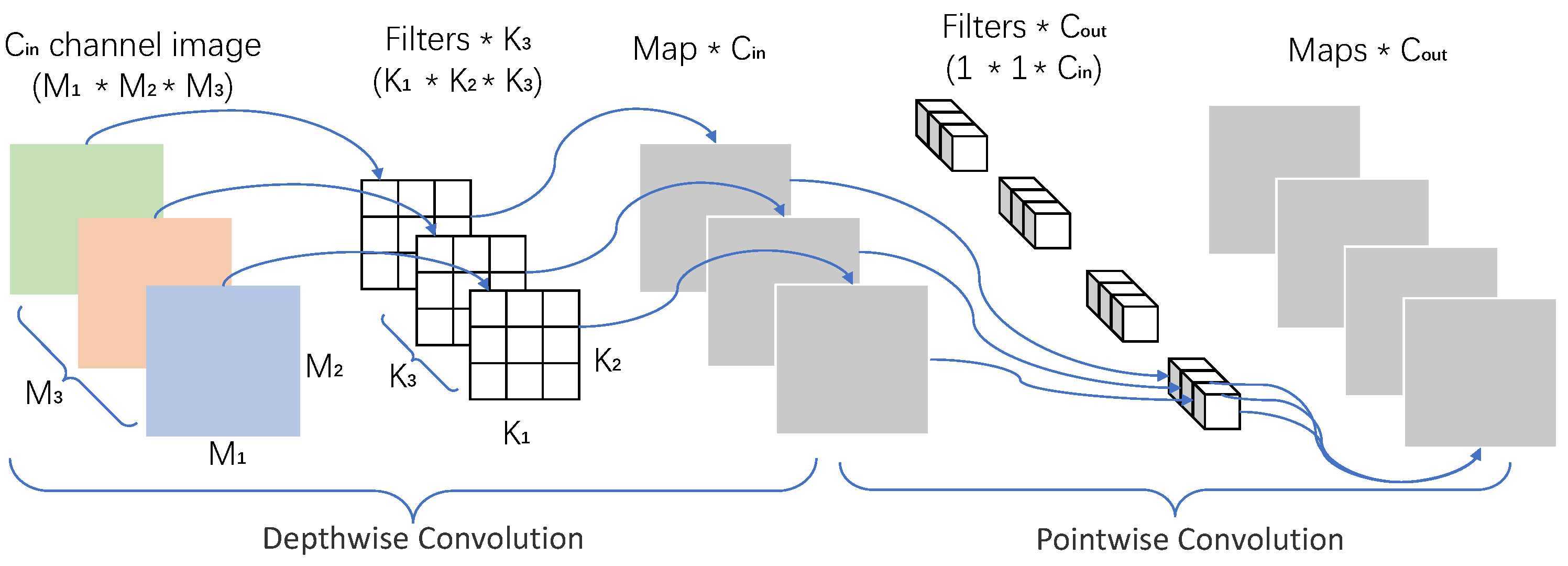
-
N_separable = N_depthwise + N_pointwise = 39
-
前半部分是逐通道卷积,后半部分是逐点卷积。
-
逐点卷积的作用
- 方便控制维度,且参数量小
- 特征图在深度方向的特征信息的融合
Depthwise convolution is extremely efficient relative to standard convolution. However it only filters input channels, it does not combine them to create new features. So an additional layer that computes a linear combination of the output of depthwise convolution via 1 × 1 convolution is needed in order to generate these new features.
参数量
常规卷积:N_std = 4 × 3 × 3 × 3 = 108
深度卷积:N_depthwise = 3 × 3 × 3 = 27
逐点卷积:N_pointwise = 1 × 1 × 3 × 4 = 12
深度可分离卷积:N_separable = N_depthwise + N_pointwise = 39
网络结构
标准卷积层替换为深度可分离卷积层。
Counting depthwise and pointwise convolutions as separate layers, MobileNet has 28 layers.

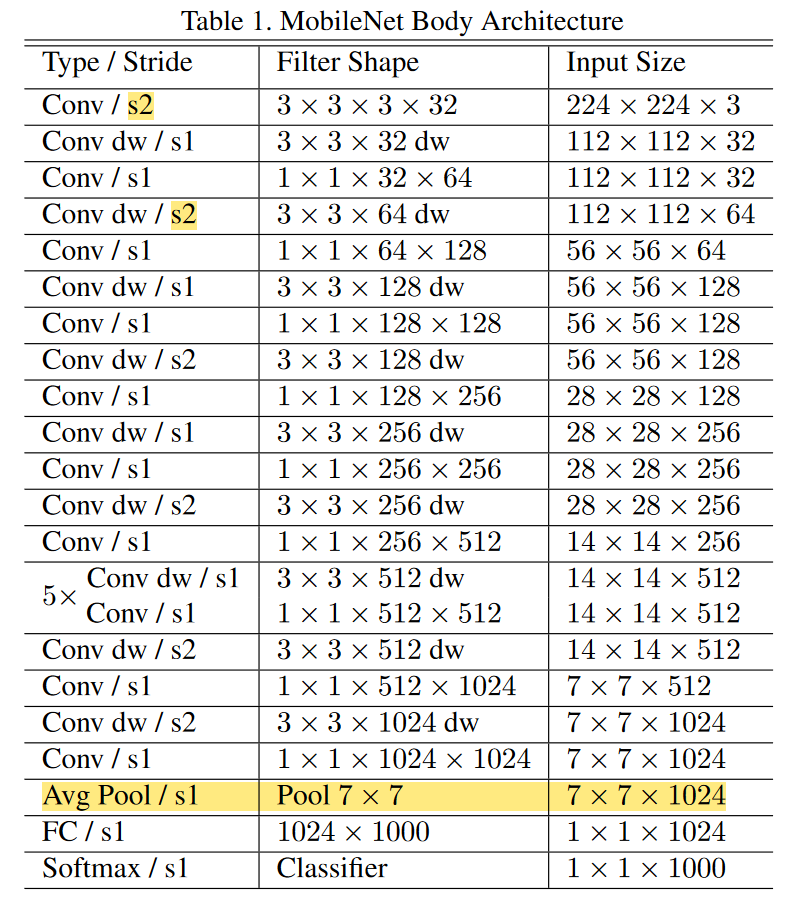
Down sampling is handled with strided convolution in the depthwise convolutions as well as in the first layer.
A final average pooling reduces the spatial resolution to 1 before the fully connected layer.
两个参数
- 提供了两个参数控制模型的宽度:width multiplier、resolution multiplier
对比实验
- 轻参数的MobileNet和其他模型对比
完整的mobileNet和原始的GoogleNet和VGG16的比较。
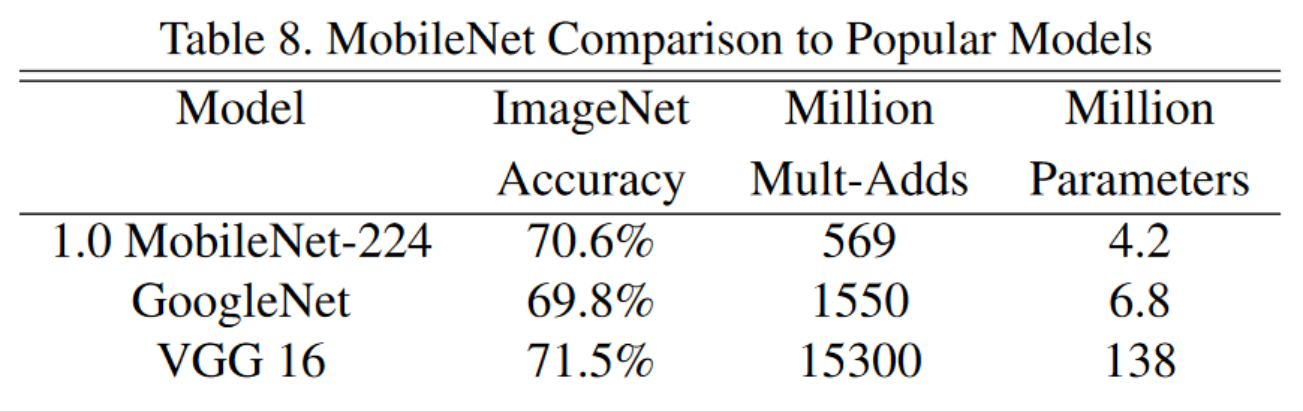
- 不同参数的模型表现对比
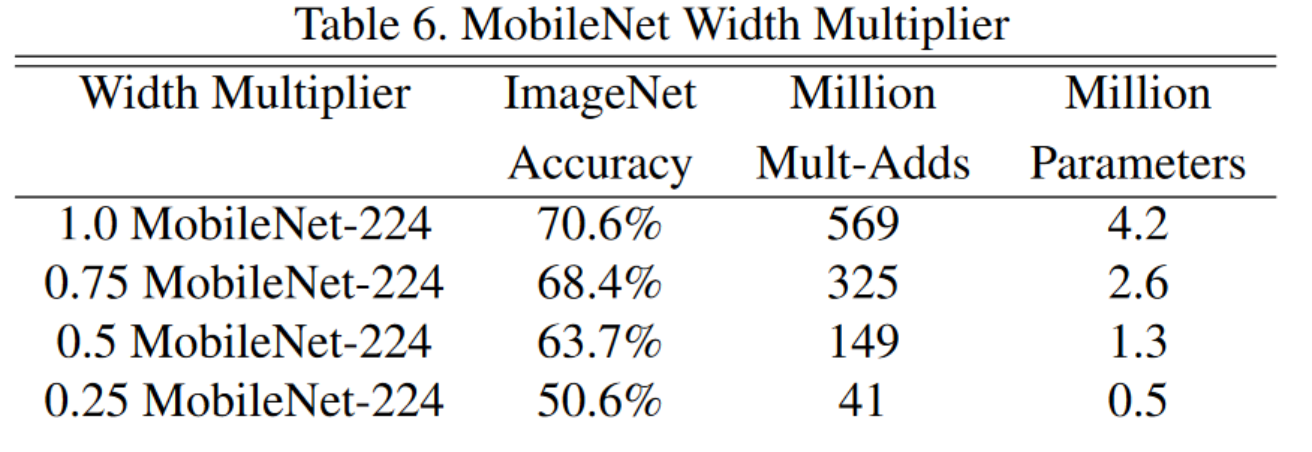
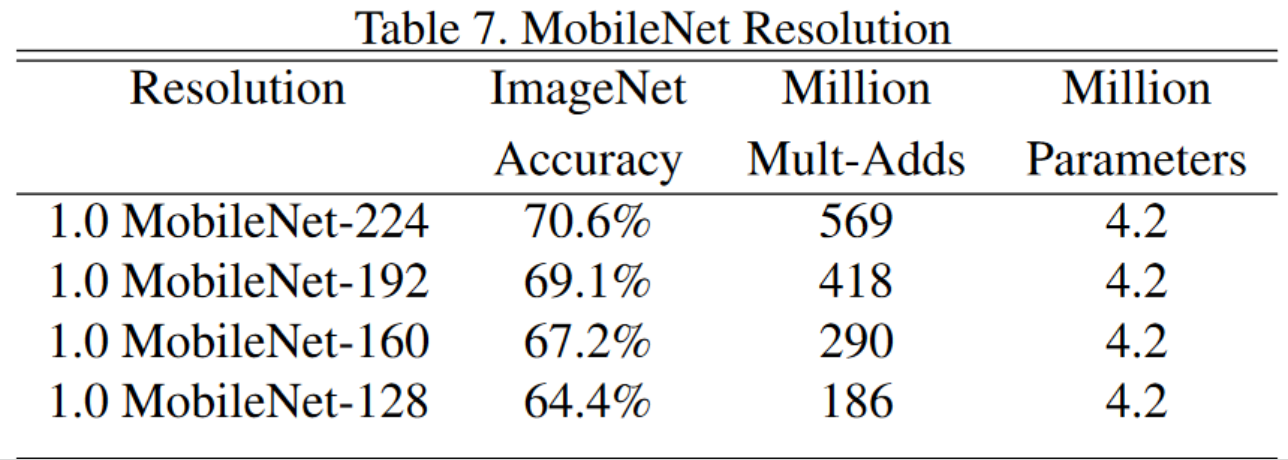
- 深度可分离卷积核和3x3卷积对比

Q
- 深度可分离卷积不是MobileNet提出,一般认为是Xception提出。
- 为什么抛弃池化层,而用步长大于2的卷积做下采样?
- 加上残差连接的效果如何?
参考文献
https://zhuanlan.zhihu.com/p/92134485
https://blog.csdn.net/wuruivv/article/details/109471071
RepVGG
参考文献
https://blog.csdn.net/qq_37541097/article/details/125692507
https://zhuanlan.zhihu.com/p/547097374
标签:..,MobileNet,卷积,模型,VGG,网络,拟合,残差,深度 From: https://www.cnblogs.com/handsome6/p/cnn-summary-vgg-yvwxy.html