为了探究云原生应用系统的内部状态,我们希望向观测数据中注入尽量丰富的标签,这些标签以往通过开发人员手动在代码中注入,或通过配置 Promtheus、OpenTelemetry 实现,一方面造成了很大的工作量和资源开销,另一方面也导致不同信号源的数据标签不一致形成数据孤岛。DeepFlow 依靠 AutoTagging 机制可以为所有观测信号统一注入标准的、丰富的标签,很好的解决了这些问题。SmartEncoding 的高性能编码机制通过对标签数据的分离编码和查询时关联,我们将存储开销降低了 10~50 倍,并且能支持无限量的 K8s label/annotation 等信息作为业务自定义标签。
直播间的朋友们大家好,我是云杉网络的宋贞,很高兴今天能和大家一起分享 DeepFlow 的 AutoTagging 和 SmartEncoding 技术。这是 DeepFlow 的两项关键核心技术,希望通过今天的介绍,可以让大家详细了解 AutoTagging 和 SmartEncoding 的实现方法,并为各位在可观测性平台的性能提升或者说是资源优化方向提供一个思路。
今天的分享将会从五个方面展开:
- 从可观测性建设角度出发,总结大家在日常工作中遇到的痛点;
- 介绍 DeepFlow 的软件架构、系统组成;
- 讲解 DeepFlow 的关键特性 AutoTagging 技术;
- 讲解支撑 AutoTagging 10x 性能提升的 SmartEncoding 技术;
- 总结并分享后续的迭代和演进计划。
01|观测数据存储的挑战
可观测性建设从去年开始在国内非常的火热,大家谈的越来越多。随着云原生、微服务的发展落地,可观测性建设逐渐成为了一个必不可少的工程手段。
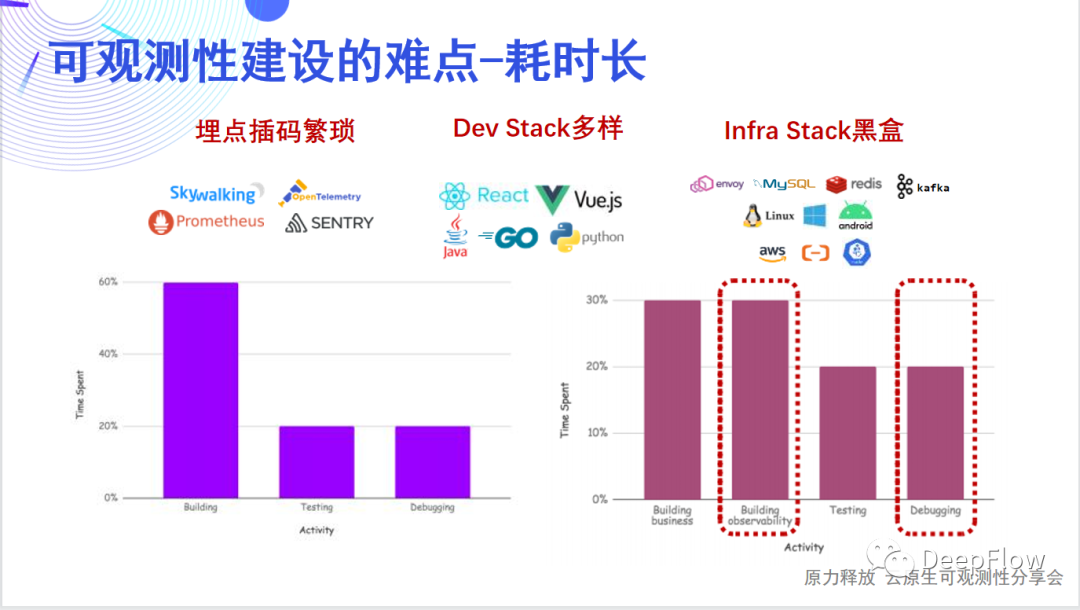
我们认为应用开发团队花了一半的时间用于可观测性的建设。这张图里面可以看到,开发者通常需要考虑在不同的 Dev Stack 和 Infra Stack 中如何埋点、如何插码、如何传递追踪上下文、如何生成指标/追踪/日志数据并进行关联,需要考虑的问题太多太杂。除此之外开发者还有很多时间在做 Debug,而这些 Debug 之所以耗费了这么多时间,通常大部分是因为可观测性建设的欠缺导致。

可观测性指标数据一般分为Tracing、Metric和Logging三类。Tracing关注的元数据是traceID/spanID/service/...;Metric关注的元数据是vpc/instance/node/kvm/...;Logging关注的元数据是type/level/time/message/...。每类指标关注的元数据/标签各不相同,所以经常会出现由于缺少数据标签,导致无法下钻定位具体的主机、微服务、Pod、实例、API Endpoint;又或者无法关联具体的 git commit id、service owner。同时数据标签的概念和定义繁多,比如有的用 service 表示服务,有的用 app 表示,进一步导致了可观测性数据的关联困难。 Prometheus应该是大家都非常熟悉的一款软件,它的 relabeling 机制能够对 Metrics 的标签进行灵活的管理,Metrics 的所有标签都是在这个阶段统一注入或转换的,特别是 K8s 资源相关的信息。但是用过的各位应该知道 relabeling 的配置非常复杂,可参见具体配置[3]。 可观测性业界很火的 OpenTelemetry 也需要做复杂的 opentelemetry processor 配置去注入/丢弃/改写标签。 让人崩溃的是,当你历尽千辛万苦做到了各类指标数据的无缝关联,你会发现一个指标需要携带上百个标签,消耗巨大的存储资源,“可观测性系统的资源消耗甚至超过了业务系统”。但幸运的是,目前就有一款软件可以很好的解决上面这些问题,而又不会耗费过多资源,那就是DeepFlow可观测性数据平台。
02|DeepFlow 软件架构
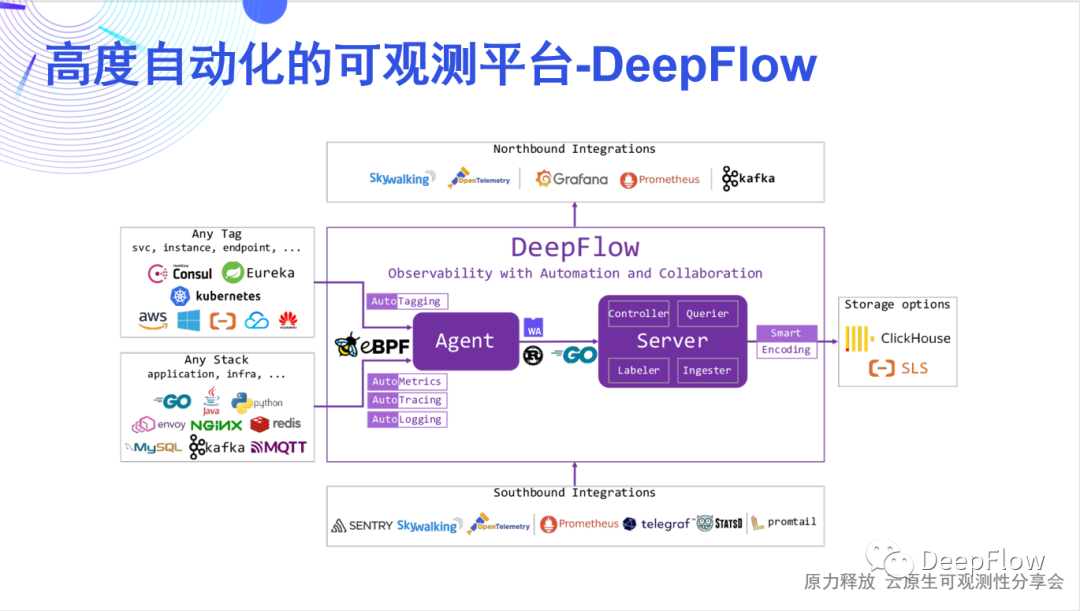
DeepFlow的架构其实非常简单,它简单到只有一个Agent和一个Server,分别是数据采集组件和数据存储查询组件。 Agent是使用Rust来实现的,高性能且内存安全,它通过eBPF技术实现了对任意开发技术栈、任意基础设施的全自动应用性能指标数据采集(AutoMetrics),以及自动化的分布式链路追踪(AutoTracing),这两项是DeepFlow Agent独有的能力,能极大降低开发者建设可观测性的工作量。 Server包含了4个内部模块:Controller面向采集器Agent的管理,能纳管多资源池的10万量级的Agent;Labeler面向标签数据的自动注入,提供AutoTagging的能力;Querier面向数据查询,提供统一的SQL接口;Ingester面向数据存储,提供插件化的、可替换可组合的数据库接口。它支持水平扩展,而且完全不依赖外部的消息队列或负载均衡,就能够去实现对多个Region、多个资源池中Agent的负载均摊。Server也有两个非常核心的技术,AutoTagging和SmartEncoding。通过AutoTagging我们能为Agent采集到的所有观测数据自动注入统一的资源、实例和API标签,使得我们能够消除不同数据类型之间的隔阂,增强所有数据的关联、切分、下钻能力。SmartEncoding是我们非常创新的一个高性能的标签编码机制,通过这个机制,我们既能方便的进行数据关联,又能将标签注入的存储性能提升10倍,这在我们的实际生产环境中已经进行了广泛的验证。
03|AutoTagging:构建标准化的标签体系
AutoTagging通过云API、K8s apiserver自动同步30多种资源标签、100多种自定义微服务标签,来构建标准化的标签体系。

DeepFlow的标签体系:
自定义标签
- k8s.label/k8s.env/k8s.annotation/..
- os.app/os.proc/...
- cloud.tag
进程
- 进程名
云资源
- 资源池:区域/可用区
- 计算资源:云服务器/宿主机
- 网络资源:VPC/子网/路由器/IP地址
- 网络服务:安全组/负载均衡器/NAT网关/对等连接/云企业网
- 存储资源:云数据库RDS/Redis
容器资源
- 容器集群/容器节点/命名空间/Ingress/容器服务/工作负载/POD
下面,我们依次介绍一下对各类资源信息的同步机制,以实现标签库的构建。
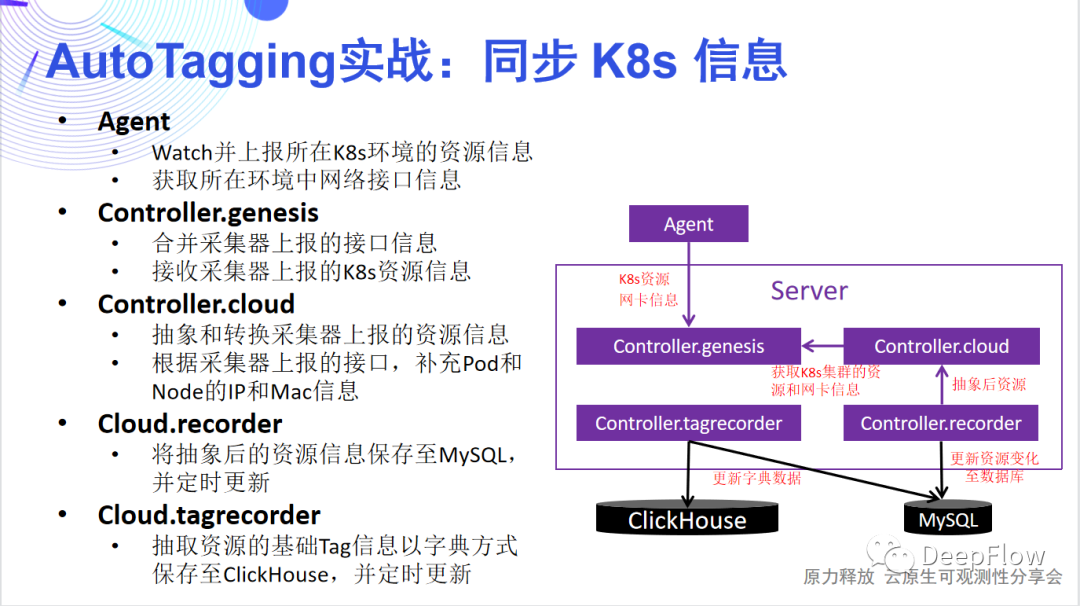
同步 K8s 资源:
- 为什么是 Agent watch 并上报 K8s资源?一个 Server 可以管理多个集群中的 Agent,Agent在所属集群中watch K8s,避免了集群外部用 server watch 时涉及到的权限和配置问题。
- 如何控制 Agent 对 K8s 资源的 watch?避免 K8s 的 API 压力过大,不能让所有的 Agent 都去 watch K8s,Server 在每个集群中选举一个 Agent;仅让被选中的 Agent watch K8s 资源。
除此之外,我们还需要考虑资源规模的问题,我们通过如下两个措施降低 deepflow-agent 的资源消耗:
- 内存优化:Agent 仅抓取同步必须的字段,同时会第一时间进行压缩。
- 带宽优化:仅当 K8s 资源有变化时,Agent 才会向 Server 发送具体的资源信息
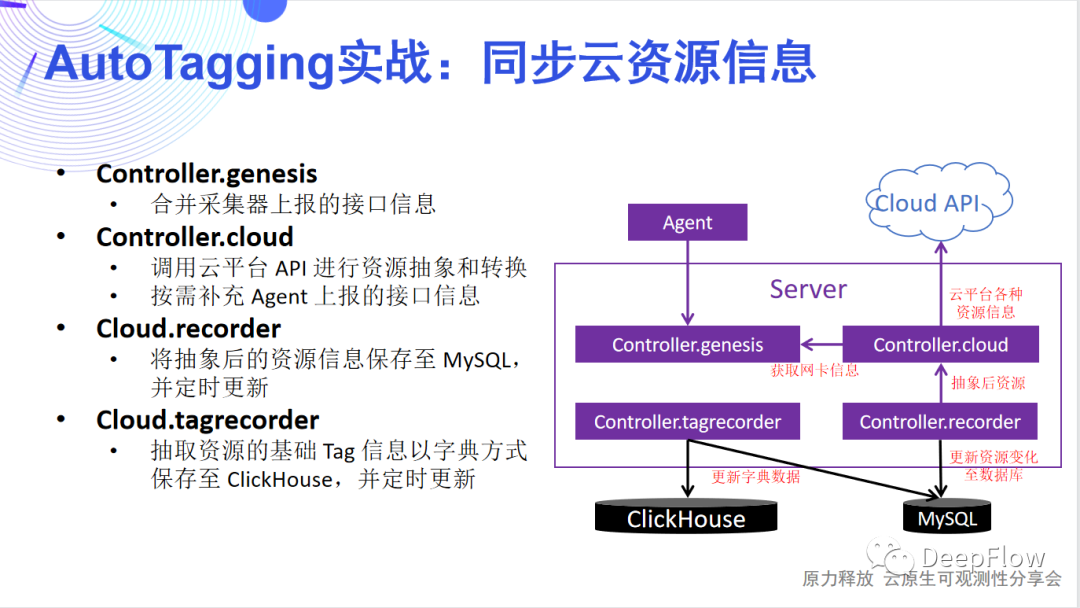
同步云资源
- 同步云资源信息:通过调用云平台 API 进行资源抽象和转换,然后将相关标签信息保存至 MySQL 中,并定期更新 ClickHosue 中的字典。
- 同步 Legacy Host 信息:一些环境中,可能没有真正意义的云平台,或者存在一些传统主机需要监控,这就需要用Legacy Host同步方案。由于没有具体的云API,我们完全通过Agent抓取所在服务器的名称等基本信息和网卡信息,上报给Server汇总并进行资源抽象。
- 同步托管 K8s 信息:当 K8s 平台部署在云资源上时,要做到真正的可观测性,需要将K8s的资源和云资源关联起来,才能真正做到无缝地关联、切分和下钻。我们一方面通过获取 K8s 资源所在的 VPC,基于 VPC 内 IP 的唯一性,通过 VPC + IP 将 K8s 的容器节点与云服务器关联起来;另一方面通过将云平台的 API 调用与 K8s 独立,两者使用不同的调用频率,从而解决大规模场景下,云平台 API 慢与 K8s 资源更新快的矛盾。
理想很丰满,现实很骨感。我们努力想实现观测数据无缝跳转,但当上百个标签呈现在眼前时,你会发现后端资源消耗飙升,性能急剧下降,整个平台别说无缝跳转了,连使用都成了问题。于是 SmartEncoding 技术诞生了。
04|SmartEncoding:实现 10x 性能提升
SmartEncoding 将标签注入分为3个阶段,通过采集时编码、存储时编码、和查询时编/解码降低标签写入的资源消耗,我们来详细看看每个阶段都如何实现:
采集时编码

Controller 根据云平台和 K8s 资源抽象好标签信息进行 Int 编码后,并不会将所有的标签下发给 Agent。仅会下发最少量的标签。这样 Agent 只需要为数据追加很少的Int标签即可。在混合云场景下,为了标识资源我们可以用 VPC ID 作为基,它能和 IP 地址联合决定客户端、服务端对应的实例和服务;可以通过 gpid 解决远端进程信息标记的问题。我们主要考虑 Agent 做的工作尽量少,这样可以最大限度的降低采集器的 CPU、内存消耗,以及传输数据的带宽消耗。我们在生产环境中发现有些 K8s 的标签会非常长,key 和 value 高达上百个字节。可以想象如果我们将上百个标签注入每个请求传输到后端,消耗的带宽会非常可观。
存储时编码
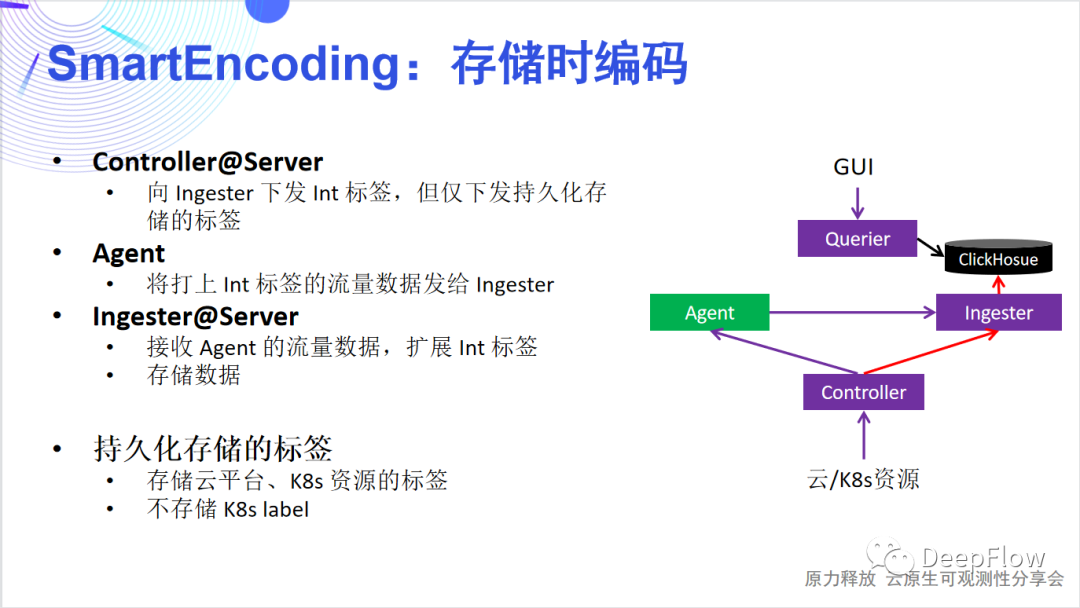
同样 Controller 会向 Ingester 下发 Int 标签,但仅下发持久化存储的标签。Ingester 在收到 Agent 发过来的数据后,会进行一轮标签的扩充,将 Agent 注入的少量标签扩展为更为丰富的标签集合。但这里注意的是,我们并不存储自定义标签。 标签的存储是为了方便检索和聚合,我们只需要保证每个切分粒度上都有标签存在即可。举例来讲我们存储 Region、AZ、VM、Node、Namespace、Service、POD 等固定的云或者 K8s 资源标签即可,而其他的自定义的标签一般是依附在这些标签之上的,存在一定的对应的关系。另外,自定义标签动态性高,也不适合全部存储。根据我们的经验,一般每一个请求涉及到的的固定标签在40个左右,自定义标签在60个左右。通过只存储固定的资源标签,我们能将压力进一步降低。
查询时编/解码

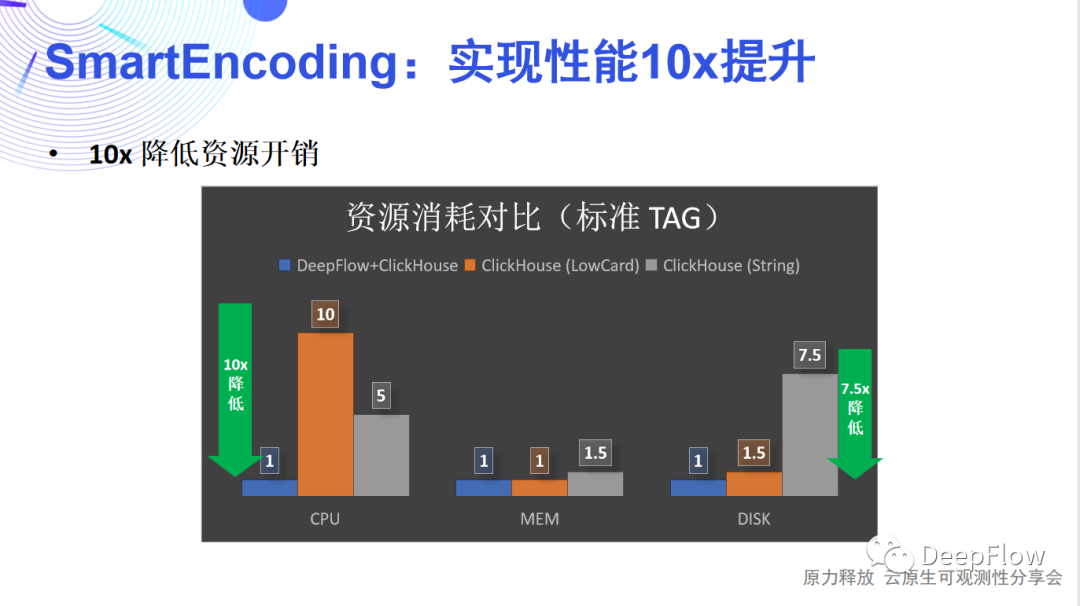
DeepFlow SQL支持通过字符串查询和聚合,并且也支持自定义标签的查询和聚合。这里我们依赖 ClickHouse 的字典能力。通过编码自定义标签的 Filter 和 Group 查询请求,利用 ClickHouse 的字典转换为系统标签;同时对于 Select 请求也可以利用 ClickHouse 的字典将系统标签转为字符串或者自定义标签返回。 我们再来回顾一下这三级编解码,可以发现它能为我们节省大量的资源消耗,性能提升应该十分可观。一方面采集器的CPU、内存可以降低,传输带宽可以降低,最主要的还是后端存储开销的降低。我们在谈论可观测性时经常会谈到采样、避免高基数等。ClickHouse 采用稀疏索引,很好的避免了高基数问题。我们在此之上的多级编解码又能将存储开销显著降低,而且由于查询阶段扫描的数据量变小了,所以能获得更好的查询性能。这里有一些数据可以看一下,DeepFlow 默认使用 ClickHouse 存储数据,在 SmartEncoding 的加持下,标准 Tag 的 CPU 和磁盘消耗相比 LowCard 存储或直接存储有一个数量级的优化,而由于自定义 Tag 不会随数据写入,在通常的场景下整体写入资源消耗可降低50倍。
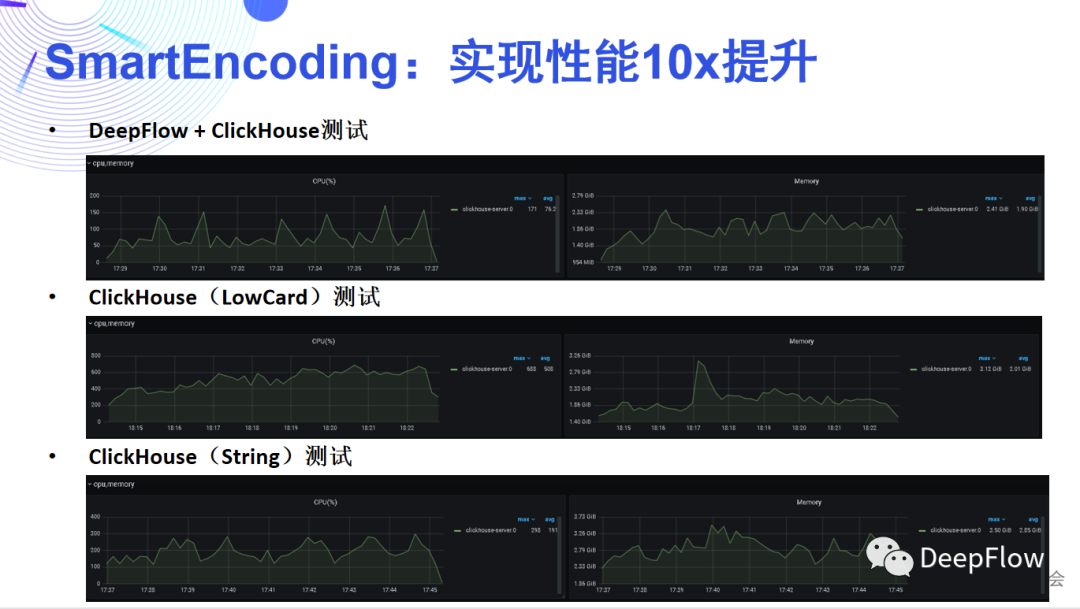

做了这么复杂的编码以后,如何让查询变得简单呢?下面我们来介绍 deepflow-server 的查询抽象层,它向用户隐藏了写时编码和读时关联的复杂逻辑,用户对数据的查询就像在一张大宽表上进行,体验非常丝滑。例如,我们可以直接查询所有表中的数据:
SELECT col_1, col_2, col_3 \
FROM tbl_1 \
WHERE col_4 = y \
GROUP BY col_1, col_2 \
HAVING col_5 > 100 \
ORDER BY col_3 \
LIMIT 100
我们可以查询某个 Tag 的所有候选项:
SHOW tag ${tag_name} values FROM ${table_name}
SHOW tag ${tag_name} values
FROM ${table_name}
WHERE display_name LIKE '*abc*'
SELECT pod
FROM `vtap_flow_port.1m`
WHERE pod_cluster = 'cluster1'
GROUP BY pod
更多详细用法[4]
查询 Universal Tag
- ClickHouse 的观测数据表中保存tag ID
CREATE TABLE flow_metrics.`vtap_flow_port.1m`
(
`time` DateTime('Asia/Shanghai') COMMENT 'v6.1.8' CODEC(DoubleDelta),
`ip4` IPv4 COMMENT 'IPv4地址',
`ip6` IPv6 COMMENT 'IPV6地址',
`is_ipv4` UInt8 COMMENT '是否IPV4地址. 0: 否, ip6字段有效, 1: 是, ip4字段有效',
`l3_device_id` UInt32 COMMENT 'ip对应的资源ID',
`l3_device_type` UInt8 COMMENT 'ip对应的资源类型',
`l3_epc_id` Int32 COMMENT 'ip对应的EPC ID',
`pod_cluster_id` UInt16 COMMENT 'ip对应的容器集群ID',
`pod_group_id` UInt32 COMMENT 'ip对应的容器工作负载ID',
`pod_id` UInt32 COMMENT 'ip对应的容器POD ID',
`pod_node_id` UInt32 COMMENT 'ip对应的容器节点ID',
`pod_ns_id` UInt16 COMMENT 'ip对应的容器命名空间ID'
)
ENGINE = Distributed(...)
- ClickHouse 的字典表中保存tag ID和名称对应关系
CREATE DICTIONARY flow_tag.pod_map
(
`id` UInt64,
`name` String,
`icon_id` Int64
)
PRIMARY KEY id
SOURCE(...)
- 通过 dictGet 实现tag ID到名称的转换
SELECT dictGet(flow_tag.pod_map, 'name', toUInt64(pod_id)) AS pod
FROM `vtap_flow_port.1m`
WHERE pod = 'deepflow'
GROUP BY pod
LIMIT 1
查询 K8s label
- ClickHouse 的字典表中保存tag ID和 K8s label对应关系
CREATE DICTIONARY flow_tag.k8s_label_map
(
`pod_id` UInt64,
`key` String,
`value` String,
)
PRIMARY KEY pod_id, key
SOURCE(...)
LIFETIME(MIN 0 MAX 60)
LAYOUT(COMPLEX_KEY_HASHED())
- 通过 dictGet 实现tag ID到 K8s label 的转换
SELECT dictGet(flow_tag.k8s_label_map, 'value', (toUInt64(pod_id), 'app')) AS `label.app`
FROM `vtap_flow_port.1m`
WHERE `label.app` = 'xxx'
LIMIT 1
查询集成数据,包括 Prometheus、Telegraf、OpenTelemetry 等数据。
- 存储集成数据时,会将数据中原有的 Tag 和 Metric 的 name 和 value 分别定义为 Array 类型,一一对应。
CREATE TABLE ext_metrics.prometheus_web
(
`time` DateTime('Asia/Shanghai') CODEC(DoubleDelta),
`_tid` UInt8 COMMENT '用于区分trident不同的pipeline',
`az_id` UInt16 COMMENT '可用区ID',
`host_id` UInt16 COMMENT '宿主机ID',
`tag_names` Array(String) COMMENT '额外的tag',
`tag_values` Array(String) COMMENT '额外的tag对应的值',
`metrics_float_names` Array(String) COMMENT '额外的metrics',
`metrics_float_values` Array(Float64) COMMENT '额外的metrics值'
)
- Tag 候选项只需要保留不重复的值,所以我们使用 ReplacingMergeTree Engine
CREATE TABLE flow_tag.ext_metrics_custom_field_local
(
`time` DateTime('Asia/Shanghai') CODEC(DoubleDelta),
`table` LowCardinality(String),
`vpc_id` Int32,
`pod_ns_id` UInt16,
`field_type` LowCardinality(String) COMMENT 'value: tag, metrics',
`field_name` LowCardinality(String),
`field_value_type` LowCardinality(String) COMMENT 'value: string, float'
)
ENGINE = ReplacingMergeTree(time)
- 通过 indexOf 进行 name 和 value 的对应
SELECT tag_values[indexOf(tag_names, 'host')] AS `tag.host`
FROM deepflow_agent_collect_sender
WHERE (tag_values[indexOf(tag_names, 'host')]) = 'xxxx'
LIMIT 1
05|总结与后续迭代计划
通过以上分享,相信您会发现DeepFlow有丰富、统一的标准化标签体系,非常方便进行数据关联、切分、下钻。通过 SmartEncoding 的性能优化,Server + ClickHouse 的资源消耗通常为业务消耗的 1%,即监控100个 16c64g 的容器节点,大概需要1个 16c64g 的 Node 部署 Server + ClickHouse,且可以通过对象存储转储冷数据;而且常见的可观测性数据一般都需要注入百量级的标签,DeepFlow Agent 由于只注入了 VPC、GPID 少数几个字段,因此它用于标签注入的资源消耗几乎只有其他方案的百分之几。这样10x性能的使用体验,相信 Cloud-Native、NewOps 都会喜欢! 后续我们会支持更丰富的自定义标签,包括通过 K8s API 获取的k8s.annotation 和 k8s.env、通过操作系统获取的 os.proc 信息、通过执行命令获取 os.app 信息;会从时间和带宽消耗两方面进一步优化AutoTagging的性能,通过不同类型资源的 API 可以设置不同的调用频率,避免每次都是重新获取全部资源来缩短缩短大规模下的资源同步时间;通过Agent 仅发送有变化的 K8s 资源信息,进一步降低带宽消耗。
06|关于DeepFlow
DeepFlow[5] 是一款开源的高度自动化的可观测性平台,是为云原生应用开发者建设可观测性能力而量身打造的全栈、全链路、高性能数据引擎。DeepFlow 使用 eBPF、WASM、OpenTelemetry 等新技术,创新的实现了 AutoTracing、AutoMetrics、AutoTagging、SmartEncoding 等核心机制,帮助开发者提升埋点插码的自动化水平,降低可观测性平台的运维复杂度。利用 DeepFlow 的可编程能力和开放接口,开发者可以快速将其融入到自己的可观测性技术栈中。 GitHub 地址:https://github.com/deepflowys/deepflow 访问 DeepFlow Demo[6],体验高度自动化的可观测性新时代。
参考资料
[1]回看链接: https://www.bilibili.com/video/BV1AM411b7E3/?share_source=copy_web
[2]PPT下载: http://yunshan-guangzhou.oss-cn-beijing.aliyuncs.com/yunshan-ticket/pdf/30b9ac0cfbd16b9d84e40e4112033c12_20230116190401.pdf
[3]具体配置: https://deepflow.yunshan.net/blog/008-standardizing-prometheus-telegraf-labels-to-break-data-silos/#0x2-%E6%A0%87%E7%AD%BE%E8%87%AA%E5%8A%A8%E5%8C%96%EF%BC%8C%E9%99%8D%E4%BD%8E%E5%B7%A5%E4%BD%9C%E8%B4%9F%E6%8B%85
[4]更多详细用法: https://deepflow.yunshan.net/docs/zh/server-integration/query/sql/
[5]DeepFlow: https://github.com/deepflowys/deepflow
[6]DeepFlow Demo: https://deepflow.yunshan.net/docs/zh/install/overview/
本文作者:树欲静而风不止
https://ost.51cto.com/#bkwz
标签:COMMENT,标签,AutoTagging,Agent,10x,tag,DeepFlow,K8s From: https://blog.51cto.com/harmonyos/6038796