UNeXt: MLP-based Rapid Medical Image Segmentation Network
论文:https://arxiv.org/abs/2203.04967
代码:https://github.com/jeya-maria-jose/UNeXt-pytorch
1.动机
- UNet及其最新的扩展如TransUNet以及 这些网络参数多、计算复杂、使用速度慢,因此不能有效地用于即时应用的快速图像分割。
2.主要贡献
- 提出了UNeXt,第一个基于卷积mlp的图像分割网络。
- 提出了一种新颖的带有轴向偏移的tokenized MLP块,以有效地学习潜在空间的良好表示。
- 提高了医学图像分割任务的性能,同时具有更少的参数、更高的推理速度和较低的计算复杂度
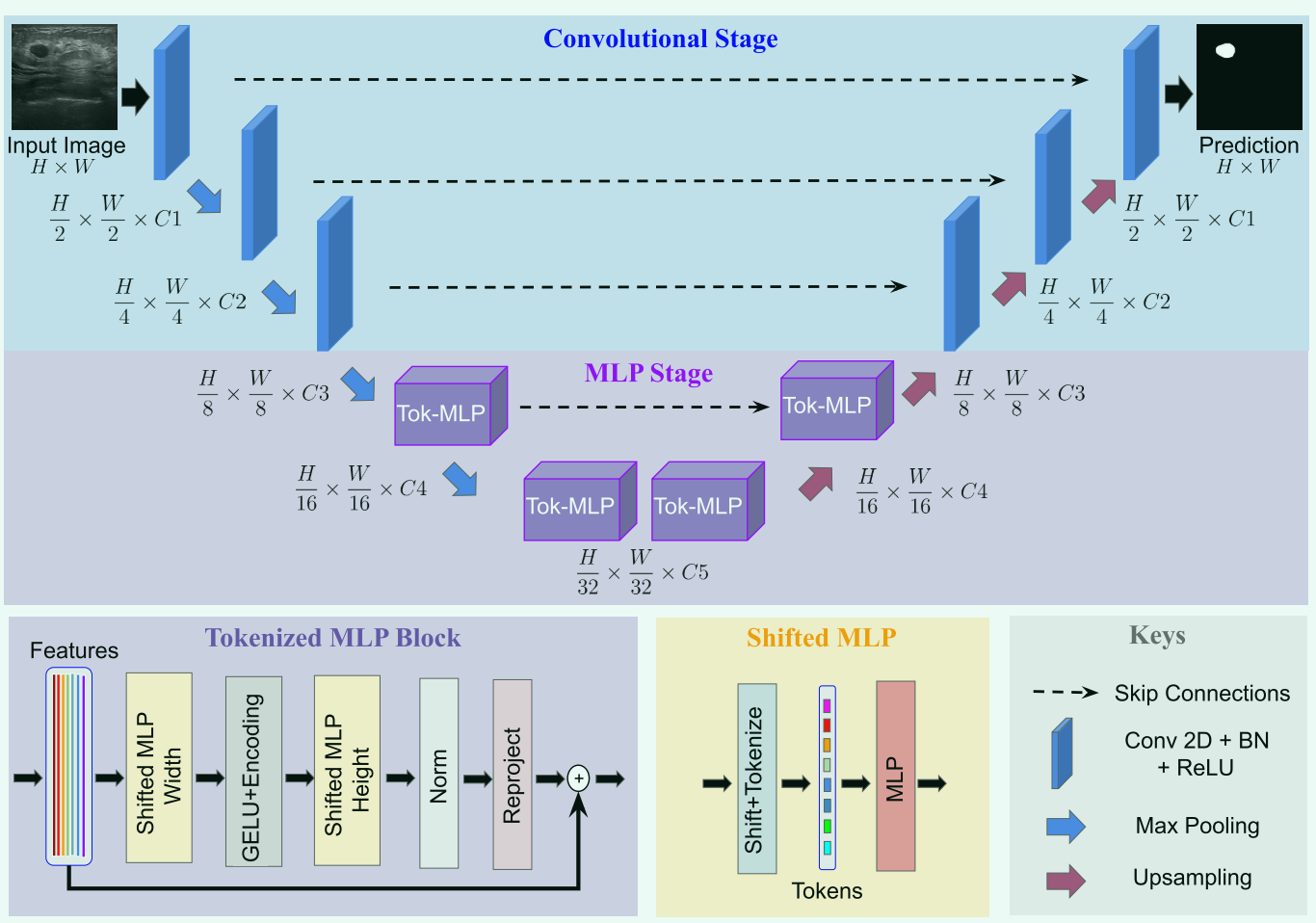
3.网络结构
UNeXt是一个编码器-解码器体系结构,有两个阶段:卷积阶段和tokenized MLP阶段。
(在计算机视觉中,tokenized指的是将图像数据分割成独立的、有意义的部分,称为token。token可以翻译为"标记"或"令牌"。)
-
卷积阶段:
-
编码器卷积块:kernel_size=3*3,stride=1,padding=1,下采样使用max_pooling=2 * 2,批量归一化,ReLU
-
解码器:卷积块形状与编码器相同,上采样使用双线性插值替代反卷积,以减少可学习参数数量
-
-
Shifted MLP:
在Shifted MLP 中,我们在对其进行tokenize之前将卷积特征的通道轴移位。这有助于 MLP 只关注卷积特征的特定位置,从而给该块带来局部性,只关注特定位置。由于 Tokenized MLP 块有 2 个 MLP,我们在一个 MLP 中沿宽度移位,在另一个 MLP 中沿高度移位。我们将特征划分为 h 个不同的分区,并根据指定轴移位 j 个位置。这有助于我们在轴上创建随机窗口,引入局部性。

灰色是特征块的位置,白色是移动之后的padding。
-
Tokenized MLP
- 将特征移位:$X_{shift}=Shift_W(X)$
- tokenize:使用kernel_size为3,将通道数改为E,其中E是嵌入维度(token的数量),它是一个超参数。$T_W=Tokenize(X_{shift})$
- 将这些标记传递给平移MLP(沿宽度),其中MLP的隐藏维度是超参数H。
- 将特征通过深度卷积层(depth wise convolutional layer:DW-Conv)传递。我们在这个块中使用DWConv有两个原因:1)它有助于编码MLP特征的位置信息。 2)DWConv使用的参数较少。
- 使用GELU激活层,因为它是一种更加平滑的替代方案。$Y=f(DWConv((MLP(T_W))))$
- 通过另一个平移MLP(沿高度)将特征从H传递到O。我们在这里使用残差连接,并将原始token作为残差。$T_H=Tokenize(Y_{shift})$
- 应用一个层规范化(LN),将输出特征传递到下一个块。$Y=f(LN(T+MLP(GELU(T_H))))$
这些计算都是在嵌入维数H上进行的,它明显小于特征映射的维数$ \frac{H}{N} × \frac{H}{N}$,其中N是2的因子,这取决于块。除非另有说明,否则在的实验中设置H为768。这种设计Tokenized MLP块的方法有助于编码有意义的特征信息,而不会使得计算量增加太多。
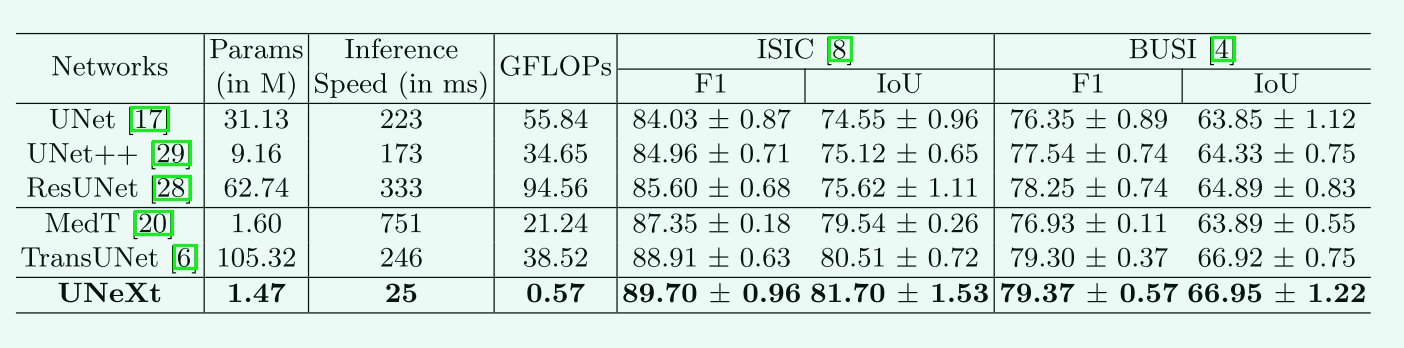
3.实验
- 数据集:ISIC 2018 和 (BUSI)
- 损失函数:$L=0.5BCE(\hat y,y)+Dice(\hat y,y)$ binary cross entropy (BCE)
- optimizer:Adam lr=0.00001,batch_size=8k,epochs=400
- 表现
4.讨论
-
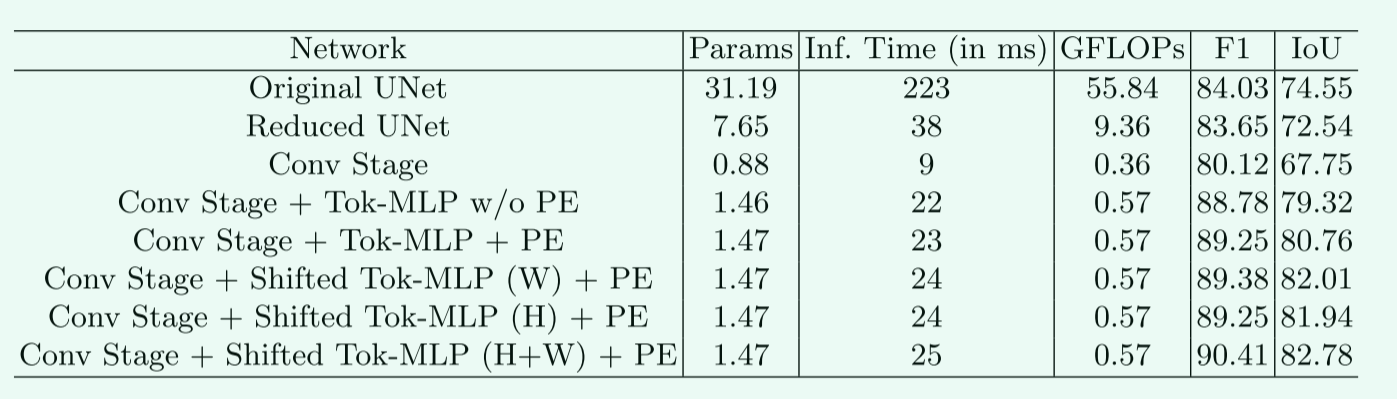
消融实验:
-
减少filter的数量,发现性能下降明显,但参数减少不明显
-
减少深度,这大大减少了参数的数量和复杂性,但也降低了4%的性能。
-
引入标记化的MLP块,它显著提高了性能,同时将复杂性和参数增加了最小值
-
使用DWConv添加位置嵌入方法,看到了更多的改进
-
在mlp中添加移位操作,并表明在tokenize之前对特性进行移位可以在不添加任何参数或复杂性的情况下提高性能。移位操作不会增加加法或乘法的次数。在两个轴上移动特性可以获得最佳性能,同时具有最小的参数和复杂性
-
-
通道数分析:增加通道(UNeXt-L)进一步提高了性能,同时增加了计算开销。

-
与MLP-Mixer的不同:MLP-Mixer采用全mlp架构进行图像识别。UNeXt是一种基于卷积和mlp的图像分割网络。MLP-Mixer专注于通道混合和token混合,以学习良好的表示。相比之下,本文提取卷积特征,然后标记通道,并使用一个新的tokenized的shifted mlp建模表示。实验中使用MLPMixer作为编码器和一个普通的卷积解码器。分割的性能不是最优的,但他的参数量达11M。