0. 准备工作
lab 地址:https://pdos.csail.mit.edu/6.824/labs/lab-raft.html
github 地址:https://github.com/lawliet9712/MIT-6.824
论文翻译地址:https://blog.csdn.net/Hedon954/article/details/119186225
Raft 的目标是在多个节点上维护一致的操作日志。为此,Raft 会首先在系统内自动选出一个 leader 节点,并由这个 leader 节点负责维护系统内所有节点上的操作日志的一致性。Leader 节点将负责接收用户的请求(一个请求即为一条对 RSM 的操作日志),将用户请求中携带的操作日志 replicate 到系统内的各个节点上,并择机告诉系统内各个节点将操作日志中的操作序列应用到各个节点中的状态机上。
阅读两篇论文,其中 GFS 是 raft 分布式算法的一种实践。分布式一致算法通常需要保证如下的几个属性:
- 安全性(safety):在不出现 non-Byzantine 的条件下,系统不应该返回不正确的结果。Non-Byzantine 条件主要包括网络上存在延迟、网络上存在丢包现象等。
- 可用性(Availability):当多数节点仍然处于正常工作状态时,整个系统应该是可用的。多数节点指超过系统中节点总数一半的节点。
- 不依赖时间来保证系统一致性。
- 少数的运行速度迟缓的节点不会拖慢整个系统的性能。
lab2 分为 4 个部分,2a, 2b, 2c, 2d,依次进行分析。
1. Part 2A: leader election (moderate)
第一个 part 主要实现一个 leader election 的机制,即在大多数情况下,这里涉及到 3 种角色,初始情况下都为 follower
- leader
- candidate
- follower
其状态机流转如下图:
目前该 part 涉及到 2 个 rpc:
- RequestAppendEntries :leader 节点 -> 其他节点,目前功能仅做心跳使用
- RequestVote :candidate 节点 -> 其他节点,candidate 成为 leader 的前置步骤,只有当大多数节点(> 1/2) rpc 结果返回成功时,才能成为 leader
由于该结构下,通常只会存在一个 leader 和多个 follower ,leader 单点显然是非常不安全的,因此该 part 需要保证在 节点异常 情况下也能够选举出新的 leader。
1.1 分析
Leader election 的逻辑大致如下:
- 最开始所有节点都是 follower
- follower 【超时时间】内没有收到任何消息就会转变为 candidate,然后自增任期
term,任期 term 的作用用来保证该任期内,节点只会给一个 candidate 投票。- candidate 会发送
RequestVoterpc 调用给其他节点- 当 rpc 调用中结果大部分为成功,则 candidate 转变为 leader
- leader 需要定时(100ms)发送心跳给所有节点
关于节点角色的转变,主要有如下情况:
- follower
- -> candidate :【超时时间】内没有收到任何 RPC
- candidate
- -> follwer :
- 收到 leader 的心跳,并且 leader 的
term>= 当前角色的term- 收到任意 RPC,RPC 参数中的
term大于当前角色的term- -> leader :
- 发送给其他节点的 RequestVote 大部分(大于 1/2)都成功了
- leader
- -> follwer
- 收到任意 RPC,RPC 参数中的
term大于当前角色的term
1.2 实现
最初版的实现方式非常朴素,直接在 ticker 中循环,根据当前角色处理不同逻辑,只用到了 goroutine 。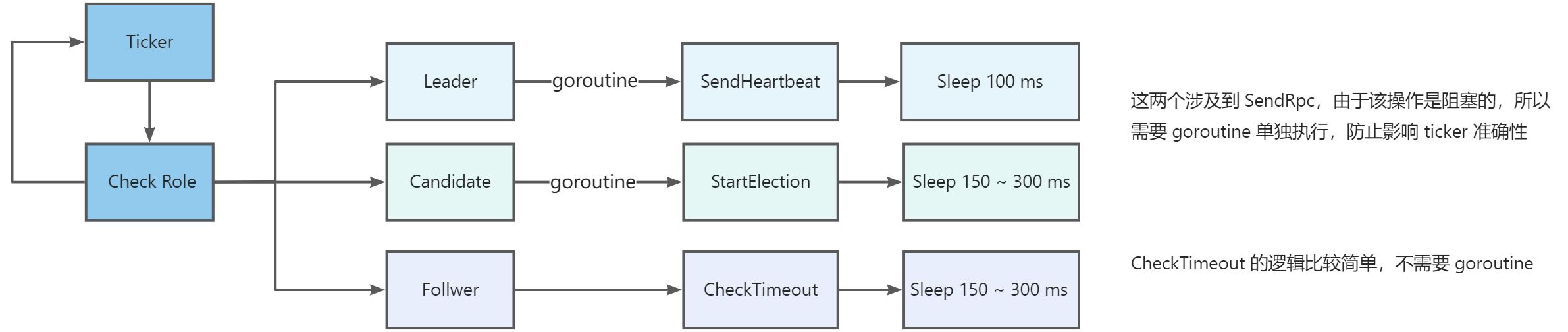
1.2.1 Ticker
核心的 Ticker 实现如下:
// The ticker go routine starts a new election if this peer hasn't received
// heartsbeats recently.
func (rf *Raft) ticker() {
for rf.killed() == false {
// Your code here to check if a leader election should
// be started and to randomize sleeping time using
// time.Sleep().
select {
case <-rf.heartbeatTimer.C:
rf.mu.Lock()
if rf.currentRole == ROLE_Leader {
rf.SendAppendEntries()
rf.heartbeatTimer.Reset(100 * time.Millisecond)
}
rf.mu.Unlock()
case <-rf.electionTimer.C:
rf.mu.Lock()
switch rf.currentRole {
case ROLE_Candidate:
rf.StartElection()
case ROLE_Follwer:
// 2B 这里直接进行选举,防止出现:
/* leader 1 follwer 2 follwer 3
1. follwer 3 长期 disconnect, term 一直自增进行 election
2. leader 1 和 follower 2 一直在同步 log
3. 由于 leader restriction, leader 1 和 follwer 2 的 log index 比 3 要长
4. 此时 follwer 3 reconnect,leader 1 和 follwer 2 都转为 follwer,然后由于一直没有 leader,会心跳超时,转为 candidate
5. 此时会出现如下情况:
5.1 [3] 发送 vote rpc 给 [1] 和 [2]
5.2 [1] 和 [2] 发现 term 比自己的要高,先转换为 follwer,并修改 term,等待 election timeout 后开始 election
5.3 [3] 发送完之后发现失败了,等待 election timeout 后再重新进行 election
5.4 此时 [3] 会比 [1] 和 [2] 更早进入 election([2]和[3]要接收到 rpc 并且处理完才会等待 eletcion,而 [1] 基本发出去之后就进行等待了)
*/
rf.SwitchRole(ROLE_Candidate)
rf.StartElection()
}
rf.mu.Unlock()
}
}
}
逻辑比较简单,follwer 和 candidate 的 sleep time 采用随机 300 ~ 450 ms 。
1.2.1 Leader 处理
任意角色,其主要需要处理的为两件事:
- 处理当前角色应当做的事情
- 检查当前是否触发了角色转变的条件
leader 主要的任务就是发送心跳,并且检查目标节点的 Term,当前 Term小于目标节点的 Term 时,Leader 转变为 Follwer。
func (rf *Raft) SendHeartbeat() {
for server, _ := range rf.peers {
if server == rf.me {
continue
}
go func(server int) {
args := RequestAppendEntriesArgs{}
reply := RequestAppendEntriesReply{}
rf.mu.Lock()
args.Term = rf.currentTerm
rf.mu.Unlock()
ok := rf.sendRequestAppendEntries(server, &args, &reply)
if (!ok) {
//fmt.Printf("[SendHeartbeat] id=%d send heartbeat to %d failed \n", rf.me, server)
return
}
rf.mu.Lock()
if (reply.Term > args.Term) {
rf.switchRole(ROLE_Follwer)
rf.currentTerm = reply.Term
rf.votedFor = -1
}
rf.mu.Unlock()
}(server)
}
}
1.2.2 Candidate 处理
Candidate 的处理比较冗长一些,但是核心其实是一件事,发送 RequestVote rpc 给其他节点求票。
func (rf *Raft) StartElection() {
/* 每一个 election time 收集一次 vote,直到:
1. leader 出现,heart beat 会切换当前状态
2. 自己成为 leader
*/
rf.mu.Lock()
// 重置票数和超时时间
rf.currentTerm += 1
rf.votedCnt = 1
rf.votedFor = rf.me
//fmt.Printf("[StartElection] id=%d role=%d term=%d Start Election ... \n", rf.me, rf.currentRole, rf.currentTerm)
rf.mu.Unlock()
// 集票阶段
for server, _ := range rf.peers {
if server == rf.me {
continue
}
// 由于 sendRpc 会阻塞,所以这里选择新启动 goroutine 去 sendRPC,不阻塞当前协程
go func(server int) {
rf.mu.Lock()
//fmt.Printf("[StartElection] id %d role %d term %d send vote req to %d\n", rf.me, rf.currentRole, rf.currentTerm, server)
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
}
reply := RequestVoteReply{}
rf.mu.Unlock()
ok := rf.sendRequestVote(server, &args, &reply)
if !ok {
//fmt.Printf("[StartElection] id=%d request %d vote failed ...\n", rf.me, server)
return
} else {
//fmt.Printf("[StartElection] %d send vote req succ to %d\n", rf.me, server)
}
rf.mu.Lock()
if reply.Term > rf.currentTerm {
rf.switchRole(ROLE_Follwer)
rf.currentTerm = reply.Term
rf.votedFor = -1
rf.mu.Unlock()
return
}
if reply.VoteGranted {
rf.votedCnt = rf.votedCnt + 1
}
votedCnt := rf.votedCnt
currentRole := rf.currentRole
rf.mu.Unlock()
if votedCnt*2 >= len(rf.peers){
// 这里有可能处理 rpc 的时候,收到 rpc,变成了 follower,所以再校验一遍
rf.mu.Lock()
if rf.currentRole == ROLE_Candidate {
//fmt.Printf("[StartElection] id=%d election succ, votecnt %d \n", rf.me, votedCnt)
rf.switchRole(ROLE_Leader)
currentRole = rf.currentRole
}
rf.mu.Unlock()
if (currentRole == ROLE_Leader) {
rf.SendHeartbeat() // 先主动 send heart beat 一次
}
}
}(server)
}
}
1.2.3 Follwer 处理
follwer 的处理比较简单
func (rf *Raft) CheckHeartbeat() {
// 指定时间没有收到 Heartbeat
rf.mu.Lock()
if rf.heartbeatFlag != 1 {
// 开始新的 election, 切换状态
// [follwer -> candidate] 1. 心跳超时,进入 election
//fmt.Printf("[CheckHeartbeat] id=%d role=%d term=%d not recived heart beat ... \n", rf.me, rf.currentRole, rf.currentTerm)
rf.switchRole(ROLE_Candidate)
}
rf.heartbeatFlag = 0 // 每次重置 heartbeat 标记
rf.mu.Unlock()
}
1.2.4 RequestVote
接下来是收到收集票的请求时的处理,这里需要注意,相同任期内如果有多个 candidate,对于 follwer 来说,是先到先服务,后到者理论上无法获取到票,这是通过 votedFor 字段保证的。
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
//fmt.Printf("id=%d role=%d term=%d recived vote request \n", rf.me, rf.currentRole, rf.currentTerm)
rf.heartbeatFlag = 1
// 新的任期,重置下投票权
if rf.currentTerm < args.Term {
rf.switchRole(ROLE_Follwer)
rf.currentTerm = args.Term
rf.votedFor = -1
}
switch rf.currentRole {
case ROLE_Follwer:
if rf.votedFor == -1 {
rf.votedFor = args.CandidateId
reply.VoteGranted = true
} else {
reply.VoteGranted = false
}
case ROLE_Candidate, ROLE_Leader:
reply.VoteGranted = false
}
reply.Term = rf.currentTerm
rf.mu.Unlock()
}
1.2.5 RequestAppendEntries
目前来说,该 rpc 主要作为心跳处理
func (rf *Raft) RequestAppendEntries(args *RequestAppendEntriesArgs, reply *RequestAppendEntriesReply) {
/*
0. 优先处理
如果 args.term > currentTerm ,则直接转为 follwer, 更新当前 currentTerm = args.term
1. candidate
相同任期内,收到心跳,则转变为 follwer
2. follwer
需要更新 election time out
3. leader
无需处理
*/
rf.mu.Lock()
if rf.currentTerm < args.Term {
rf.switchRole(ROLE_Follwer)
rf.currentTerm = args.Term
rf.votedFor = -1
rf.heartbeatFlag = 1
}
// 正常情况下,重置 election time out 时间即可
if rf.currentRole == ROLE_Follwer {
rf.heartbeatFlag = 1
} else if (rf.currentRole == ROLE_Candidate && rf.currentTerm == args.Term) {
rf.switchRole(ROLE_Follwer)
rf.currentTerm = args.Term
rf.votedFor = -1
rf.heartbeatFlag = 1
}
reply.Term = rf.currentTerm
rf.mu.Unlock()
}
1.2.6 一些辅助函数和结构定义
// serverRole
type ServerRole int
const (
ROLE_Follwer ServerRole = 1
ROLE_Candidate ServerRole = 2
ROLE_Leader ServerRole = 3
)
// A Go object implementing a single Raft peer.
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
currentTerm int
votedFor int
currentRole ServerRole
heartbeatFlag int // follwer sleep 期间
votedCnt int
}
/********** RPC *************/
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int // candidate's term
CandidateId int // candidate global only id
}
type RequestVoteReply struct {
// Your data here (2A).
Term int // Term id
VoteGranted bool // true 表示拿到票了
}
type RequestAppendEntriesArgs struct {
Term int
}
type RequestAppendEntriesReply struct {
Term int
}
/********** RPC *************/
// 获取下次超时时间
func getRandomTimeout() int64 {
// 150 ~ 300 ms 的误差
return (rand.Int63n(150) + 150) * 1000000
}
// 获取当前时间
func getCurrentTime() int64 {
return time.Now().UnixNano()
}
// 切换 role
func (rf *Raft) switchRole(role ServerRole) {
if role == rf.currentRole {
return
}
//fmt.Printf("[SwitchRole] id=%d role=%d term=%d change to %d \n", rf.me, rf.currentRole, rf.currentTerm, role)
rf.currentRole = role
if (rf.currentRole == ROLE_Follwer) {
rf.votedFor = -1
}
}
1.3 select + channel 版实现
网上还有另一种实现方式,通过 select + channel 的方式,这里不多赘述,可以参考 https://www.cnblogs.com/mignet/p/6824_Lab_2_Raft_2A.html
1.4 小结
完成该 part 的时候遇到了一些坑,主要还是之前没怎么写过多线程相关的 code ,个人感觉有如下的点需要注意:
- 临界区要尽可能短,像 sleep 或者 sendRPC 都没有必要 lock ,否则可能出现死锁。有如下例子:
2 个 process p1 p2
每个 process 都有 2 个 goroutine,g1 g2
g1 是一个 ticker , g2 是专门处理 rpc(实际上是每来一个 rpc 就开个 goroutine,就当做有一个固定的 goroutine 在处理 rpc 好了),这两个在执行的时候都会有一小段临界区持有 mutex
p1 的 ticker g1 先操作:
- mutex.lock
- send rpc to p2
- mutex.unlock
p2 收到 rpc 的时候,可能正 执行 ticker,此时 g2 会暂时 lock,等 g1 ticker 释放 lock
p2 的 g1 ticker 这个时候有可能操作- mutex.lock
- send rpc to p1
- mutex.unlock
由于 p1 正在等 p2 处理 rpc,会阻塞(这里 send rpc 是阻塞的),所以 p1 的 g2 无法处理 rpc
这里就循环依赖死锁了
- lab 中 sendRpc 是阻塞的,因此尽量使用 goroutine 去执行该操作
- 对于角色转换,有一条优先规则是:假设有节点 a 和节点 b 在 rpc 通信,发现节点 a 的 term < 节点 b 的 term,节点 a 无论是什么 role,都需要转换为 follwer。
- 为了防止同时多个节点进行 election,因此在设置 election timeout 的时候会加上 150 ~ 300 ms 的误差,尽量拉开不同节点的 election 时间。
- 为了防止出现多个 leader,同个 term 的 follwer 只有一票,一个 term 的 follwer 只能给一个 candidate 投票。票数刷新的时机在于:当前 term 发生转换
关于 term,论文中也有一张图描述的比较贴切,每次 term 的递增总是伴随着新的 election 开始。
2. Part 2B: log (hard)
第二个 Part 主要实现 log replication 机制,log 可以理解为一个 command ,也就是要将 log 从 leader 同步到各个 follwer 中。参考下图,当 leader 收到一个 log 的时候,需要将其【复制】到大部分节点上,当大部分节点都【复制】完毕 log 的时候,需要将其进行 【提交】,可以理解为类似写 DB 的操作,因此 log replication 的流程大致可以分为 3 步:
- leader 收到 log
- leader 【复制】 log
- leader 确认当前是否大多数节点都已经收到 log
- leader 【提交】 log,并通知大多数节点提交 log

2.1 分析
2.1.1 复制与提交
首先需要完成最基本的【复制】和【提交】功能。这两个功能都是通过 AppendEntries RPC 实现的,可以再阅读下 论文 Figure 2 中该 RPC 接口的描述
- 【复制】简单来说就是将 leader 收到的新的 log entries 通过 rpc 发送给其他 follwer
- 【提交】就是将已经同步给大多数节点的 log entries 给 apply 到
applyCh这个 channel 当中,需要注意的是,leader 和 follwer 都需要 apply。

Arguments 中 entries[] 字段是需要复制给其他节点的 log,而 leaderCommit 是 leader 当前已经 commit 到了第几个 log。有了这两个字段 follwer 就能知道当前应该提交到第几个 log,并且当前应该新增哪些 log。
对于 leader 来说,他需要知道每个节点当前 log 的复制情况以及提交情况。从而知道该同步哪些 log 给 follwer,因此 leader 需要新增如下字段:
nextIndex[] 记录每个 follwer 下一个应该复制的 log,因此 AppendEntries 中 entries 字段实际上就是 [nextIndex[follwer.id], leader.log[len(leader.log)] 这个区间内的 log
对于每个节点,需要记录当前提交的情况
2.1.2 冲突
前面实现了基本的 【复制】 与 【提交】功能之后,需要考虑节点各种异常的情况,如下图:
正常操作期间,leader 和 follower 的日志都是保持一致的,所以 AppendEntries 的一致性检查从来不会失败。但是,如果 leader 崩溃了,那么就有可能会造成日志处于不一致的状态,比如说老的 leader 可能还没有完全复制它日志中的所有条目它就崩溃了。这些不一致的情况会在一系列的 leader 和 follower 崩溃的情况下加剧。为了解决以上冲突,raft 会强制 leader 覆盖 follwer 的日志 。
为了对比冲突,leader -> follwer 的 RPC 增加了两个参数 prevLogIndex和 prevLogTerm
这两个参数含义为当前 leader 认为对端 follwer 目前最后一条日志的 Index 和 Term(根据 leader 专门记录的 nextIndex[] ),follwer 接收到这两个参数后,如果发现不一致,则返回 success = false,leader 检查到这种情况后,会修改 nextIndex[] 。
2.1.3 安全性
有一种情况,一个 follower 可能会进入不可用状态,在此期间,leader 可能提交了若干的日志条目,然后这个 follower 可能被选举为新的 leader 并且用新的日志条目去覆盖这些【已提交】的日志条目。这样就会造成不同的状态机执行不同的指令的情况。为了防止这种情况,raft 增加了一个叫 **leader restriction **的机制:
- 对于给定的任意任期号,该任期号对应的 leader 都包含了之前各个任期所有被提交的日志条目
- 一个 candidate 如果想要被选为 leader,那它就必须跟集群中超过半数的节点进行通信,这就意味这些节点中至少一个包含了所有已经提交的日志条目。如果 candidate 的日志至少跟过半的服务器节点一样新,那么它就一定包含了所有以及提交的日志条目,一旦有投票者自己的日志比 candidate 的还新,那么这个投票者就会拒绝该投票,该 candidate 也就不会赢得选举。
所谓 “新” :
Raft 通过比较两份日志中的最后一条日志条目的索引和任期号来定义谁的日志更新。
- 如果两份日志最后条目的任期号不同,那么任期号大的日志更新
- 如果两份日志最后条目的任期号相同,那么谁的日志更长(LogIndex 更大),谁就更新
2.2 实现
2.2.1 leader 同步日志到 follwer
这一步主要处理三个事情:
- 根据记录的
nextIndex[],给 follwer 同步日志 - 检查日志是否已经同步到大多数 follwer,是则进行提交操作
- 更新
matchIndex[]和nextIndex[]
func (rf *Raft) SendAppendEntries() {
for server := range rf.peers {
if server == rf.me {
continue
}
go func(server int) {
args := AppendEntriesArgs{}
reply := AppendEntriesReply{}
// 1. check if need replicate log
rf.mu.Lock()
if rf.currentRole != ROLE_Leader {
rf.mu.Unlock()
return
}
args.Term = rf.currentTerm
args.LeaderCommit = rf.commitIndex
args.LeaderId = rf.me
args.PrevLogIndex = rf.nextIndex[server] - 1
args.PrevLogTerm = rf.log[args.PrevLogIndex].Term
// 意味着有日志还没被 commit
if len(rf.log) != rf.matchIndex[server] {
for i := rf.nextIndex[server]; i <= len(rf.log); i++ { // log 的 index 从 1 开始
args.Entries = append(args.Entries, rf.log[i])
}
}
rf.mu.Unlock()
////fmt.Printf("%d send heartbeat %d , matchIndex=%v nextIndex=%v\n", rf.me, server, rf.matchIndex, rf.nextIndex)
ok := rf.sendAppendEntries(server, &args, &reply)
if !ok {
////fmt.Printf("[SendAppendEntries] id=%d send heartbeat to %d failed \n", rf.me, server)
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > args.Term {
rf.SwitchRole(ROLE_Follwer)
rf.currentTerm = reply.Term
rf.persist()
return
}
if rf.currentRole != ROLE_Leader || rf.currentTerm != args.Term {
return
}
// 如果同步日志失败,则将 nextIndex - 1,下次心跳重试
if !reply.Success {
rf.nextIndex[server] = reply.ConflictIndex
// if term found, override it to
// the first entry after entries in ConflictTerm
if reply.ConflictTerm != -1 {
for i := args.PrevLogIndex; i >= 1; i-- {
if rf.log[i].Term == reply.ConflictTerm {
// in next trial, check if log entries in ConflictTerm matches
rf.nextIndex[server] = i
break
}
}
}
} else {
// 1. 如果同步日志成功,则增加 nextIndex && matchIndex
rf.nextIndex[server] = args.PrevLogIndex + len(args.Entries) + 1
rf.matchIndex[server] = rf.nextIndex[server] - 1
////fmt.Printf("%d replicate log to %d succ , matchIndex=%v nextIndex=%v\n", rf.me, server, rf.matchIndex, rf.nextIndex)
// 2. 检查是否可以提交,检查 rf.commitIndex
for N := len(rf.log); N > rf.commitIndex; N-- {
if rf.log[N].Term != rf.currentTerm {
continue
}
matchCnt := 1
for j := 0; j < len(rf.matchIndex); j++ {
if rf.matchIndex[j] >= N {
matchCnt += 1
}
}
//fmt.Printf("%d matchCnt=%d\n", rf.me, matchCnt)
// a. 票数 > 1/2 则能够提交
if matchCnt*2 > len(rf.matchIndex) {
rf.setCommitIndex(N)
break
}
}
}
}(server)
}
}
2.2.2 follwer 接收日志
这一步主要处理两个事情:
- 检查日志是否存在冲突,冲突则返回失败,等待 leader 调整发送的日志,最后从冲突位置开始使用 leader 的日志覆盖冲突日志
- 检查日志是否可以提交
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
/*
part 2A 处理心跳
0. 优先处理
如果 args.term > currentTerm ,则直接转为 follwer, 更新当前 currentTerm = args.term
1. candidate
无需处理
2. follwer
需要更新 election time out
3. leader
无需处理
part 2B 处理日志复制
1. [先检查之前的]先获取 local log[args.PrevLogIndex] 的 term , 检查是否与 args.PrevLogTerm 相同,不同表示有冲突,直接返回失败
2. [在检查当前的]遍历 args.Entries,检查 3 种情况
a. 当前是否已经有了该日志,如果有了该日志,且一致,检查下一个日志
b. 当前是否与该日志冲突,有冲突,则从冲突位置开始,删除 local log [conflict ~ end] 的 日志
c. 如果没有日志,则直接追加
*/
// 1. Prev Check
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
if rf.currentTerm > args.Term {
reply.Success = false
reply.Term = rf.currentTerm
return
}
if rf.currentTerm < args.Term {
rf.SwitchRole(ROLE_Follwer)
rf.currentTerm = args.Term
}
////fmt.Printf("[ReciveAppendEntires] %d electionTimer reset %v\n", rf.me, getCurrentTime())
rf.electionTimer.Reset(getRandomTimeout())
reply.Term = rf.currentTerm
// 1. [先检查之前的]先获取 local log[args.PrevLogIndex] 的 term , 检查是否与 args.PrevLogTerm 相同,不同表示有冲突,直接返回失败
/* 有 3 种可能:
a. 找不到 PrevLog ,直接返回失败
b. 找到 PrevLog, 但是冲突,直接返回失败
c. 找到 PrevLog,不冲突,进行下一步同步日志
*/
// a
lastLogIndex := len(rf.log)
if lastLogIndex < args.PrevLogIndex {
reply.Success = false
reply.Term = rf.currentTerm
// optimistically thinks receiver's log matches with Leader's as a subset
reply.ConflictIndex = len(rf.log) + 1
// no conflict term
reply.ConflictTerm = -1
return
}
// b. If an existing entry conflicts with a new one (same index
// but different terms), delete the existing entry and all that
// follow it (§5.3)
if rf.log[(args.PrevLogIndex)].Term != args.PrevLogTerm {
reply.Success = false
reply.Term = rf.currentTerm
// receiver's log in certain term unmatches Leader's log
reply.ConflictTerm = rf.log[args.PrevLogIndex].Term
// expecting Leader to check the former term
// so set ConflictIndex to the first one of entries in ConflictTerm
conflictIndex := args.PrevLogIndex
// apparently, since rf.log[0] are ensured to match among all servers
// ConflictIndex must be > 0, safe to minus 1
for rf.log[conflictIndex-1].Term == reply.ConflictTerm {
conflictIndex--
}
reply.ConflictIndex = conflictIndex
return
}
// c. Append any new entries not already in the log
// compare from rf.log[args.PrevLogIndex + 1]
unmatch_idx := -1
for i := 0; i < len(args.Entries); i++ {
index := args.Entries[i].Index
if len(rf.log) < index || rf.log[index].Term != args.Entries[i].Term {
unmatch_idx = i
break
}
}
if unmatch_idx != -1 {
// there are unmatch entries
// truncate unmatch Follower entries, and apply Leader entries
// 1. append leader 的 Entry
for i := unmatch_idx; i < len(args.Entries); i++ {
rf.log[args.Entries[i].Index] = args.Entries[i]
}
}
// 3. 持久化提交
if args.LeaderCommit > rf.commitIndex {
commitIndex := args.LeaderCommit
if commitIndex > len(rf.log) {
commitIndex = len(rf.log)
}
rf.setCommitIndex(commitIndex)
}
reply.Success = true
}
2.2.3 candidate 选举限制
这一步主要就是 2.1.3 中的安全性限制,防止出现 follower 可能被选举为新的 leader 并且用新的日志条目去覆盖这些【已提交】的日志条目的情况,因此在 RequestVote 阶段进行限制(27 ~ 32 行)
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
//fmt.Printf("id=%d role=%d term=%d recived vote request %v\n", rf.me, rf.currentRole, rf.currentTerm, args)
reply.Term = rf.currentTerm
if rf.currentTerm > args.Term ||
(args.Term == rf.currentTerm && rf.votedFor != -1 && rf.votedFor != args.CandidateId) {
reply.VoteGranted = false
return
}
rf.electionTimer.Reset(getRandomTimeout())
// 新的任期,重置下投票权
if rf.currentTerm < args.Term {
rf.SwitchRole(ROLE_Follwer)
rf.currentTerm = args.Term
}
// 2B Leader restriction,拒绝比较旧的投票(优先看任期)
// 1. 任期号不同,则任期号大的比较新
// 2. 任期号相同,索引值大的(日志较长的)比较新
lastLog := rf.log[len(rf.log)]
if (args.LastLogIndex < lastLog.Index && args.LastLogTerm == lastLog.Term) || args.LastLogTerm < lastLog.Term {
//fmt.Printf("[RequestVote] %v not vaild, %d reject vote request\n", args, rf.me)
reply.VoteGranted = false
return
}
rf.votedFor = args.CandidateId
reply.VoteGranted = true
}
2.3 小结
这里主要需要注意:
- leader 需要维护好
matchIndex[](表示 follwer 的 commit 情况)和nextIndex[](表示 follwer 的 log replication 情况),leader 崩溃后也需要正常重新初始化好这两个数组。 - follwer 接收到日志后,需要注意是否存在冲突,通过检查 RPC 中 leader 认为的当前 follwer 的
prevLogIndex和prevLogTerm来判断日志是否存在冲突,需要 leader 将 follwer 的日志从冲突部分开始强行覆盖 - 新的 leader 的日志需要确保拥有所有已经 commit 的 log,其次一个 follower 可能会进入不可用状态,在此期间,leader 可能提交了若干的日志条目,可能出现 follower 被选举为新的 leader 并且用新的日志条目去覆盖这些【已提交】的日志条目的情况,candidate 选举时需要增加 leader restriction 机制,即 follwer 只给持有的最后一条日志比自己新的 candidate 的投票,新的定义如下:
3. Part 2C: persistence (hard)
这一 part 主要做的事情是在 node crash 后能保证恢复一些状态,简单来说就是实现 persist() 和 readPersist() 函数,一个保存 raft 的状态,另一个在 raft 启动时恢复之前保存的数据。
参考资料:
lab2C 代码 :https://www.cnblogs.com/mignet/p/6824_Lab_2_Raft_2C.html
Figure 8 解读:https://zhuanlan.zhihu.com/p/369989974
lab2C bug:https://www.jianshu.com/p/59a224fded77?ivk_sa=1024320u
lab2C test case : https://cloud.tencent.com/developer/article/1193877
幽灵复现问题:https://mp.weixin.qq.com/s?__biz=MzIzOTU0NTQ0MA==&mid=2247494453&idx=1&sn=17b8a97fe9490d94e14b6a0583222837&scene=21#wechat_redirect
3.1 分析
3.1.1 保存状态
首先需要确定要保存 raft 哪些字段,通过 Raft-Extended 的 Figure 2 可以看到,已经注明了三个保存的字段:currentTerm,votedFor,log[]
3.1.2 保存时机
3.2 实现
3.2.1 persist
//
// save Raft's persistent state to stable storage,
// where it can later be retrieved after a crash and restart.
// see paper's Figure 2 for a description of what should be persistent.
//
func (rf *Raft) persist() {
// Your code here (2C).
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.log)
data := w.Bytes()
rf.persister.SaveRaftState(data)
}
3.2.2 readPersist
//
// restore previously persisted state.
//
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
// Your code here (2C).
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votedFor int
var log map[int]LogEntry
if d.Decode(¤tTerm) != nil ||
d.Decode(&votedFor) != nil ||
d.Decode(&log) != nil {
fmt.Printf("[readPersist] decode failed ...")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votedFor
rf.log = log
}
}
3.3 小结
这一章的 Test case 中最麻烦的是 Figure 8 以及 Figure 8 unreliable,Figure 8 如下:
Figure 8 Test 的通过关键点是,当前 Leader 只能提交自己任期内的日志,在图 c 的情况下,如果 s1 新增了 log index 3 后 crash 了,并且在 crash 之前提交了 log index 2,随后 s5 成为了 leader,s5 会覆盖已经提交的日志,即图 d 的情况,我们需要保证 commit 后的日志不能被修改,因此这里即便前任任期的日志已经复制到大多数节点了,也不能对其提交。
Figure 8 Unreliable 主要问题在于其对 rpc 进行了乱序发送的操作,因此需要考虑两点:
- Leader 发送 AppendEntries ,复制成功的时候,nextIndex 和 matchIndex 的维护需要注意使用 args 中的 prevLogIndex + 实际同步的 log 数量,而不能单纯累加。
- 还有一种情况如下:
Test (2C): Figure 8 (unreliable) ...
2019/05/01 09:49:14 apply error: commit index=235 server=0 7998 != server=2 4299
exit status 1
FAIL raft 28.516s
在拿到 reply 后他要用 currentTerm 和 args.Term去做比较。也就是说 2 个 sendRPC 的地方,在拿到 reply 之后,还要做个 CHECK ,如果 currentTerm 和 args.Term 不一致,就要直接 return ,而忽略这个 reply。
完整代码参考 github ,目前 2C 的 Figure 8 unreliable 还有小概率 Failed,后续继续观察修复 bug。
4. Part 2D: log compaction (hard)
该 part 主要实现快照机制,raft 会定时触发保存快照,将部分旧 log 截断保存为快照。从而达到节约内存的功能,防止 log 无限增长。
4.1 分析
4.1.1 快照保存
正常来说,快照保存需要考虑:
- 选择快照保存的日志范围
- 选择快照保存的时机
- 日志序列化为快照,精简原有日志
但是 raft 上述情况都基本帮我们实现了,我们只需要精简日志即可。
快照保存函数为:func (rf *Raft) Snapshot(index int, snapshot []byte),index 表示从第 index 个日志开始,往前所有的日志(包括 index位置的日志)保存为快照,snapshot 参数实际上就是已经保存好的快照数据,我们只需要将日志快照部分截断即可。
4.1.2 快照同步
由于日志被截断,当有新的 follwer 加入时,可能会出现需要同步快照内的日志,raft 采用将整个快照都发送过去的方式来实现同步,此处还需要记录快照最后一个日志的 Index 以及最后一个日志的 Term。因此在这里新增一个 Snapshot 结构
type Snapshot struct {
lastIncludedTerm int
lastIncludedIndex int
}

4.1.3 下标索引转换
由于日志被截断了,因此原先索引日志的方式也需要调整,从原来直接获取下标转换成两种下标:logicIndex 和 realIndex ,分别表示日志逻辑上的下标大小以及实际访问时下标的位置(主要对快照的 lastIncludedIndex 做偏移计算)。
func (rf * Raft) getLastLogLogicIndex() int {
return len(rf.log) - 1 + rf.snapshot.lastIncludedIndex
}
func (rf * Raft) getLastLogRealIndex() int {
return len(rf.log) - 1
}
func (rf *Raft) getLogLogicSize() int {
return len(rf.log) + rf.snapshot.lastIncludedIndex
}
func (rf *Raft) getLogRealSize() int {
return len(rf.log)
}
func (rf *Raft) logicIndexToRealIndex(logicIndex int) int {
return logicIndex - rf.snapshot.lastIncludedIndex
}
func (rf *Raft) realIndexToLogicIndex(realIndex int) int {
return realIndex + rf.snapshot.lastIncludedIndex
}
4.2 实现
4.2.1 Snapshot
// the service says it has created a snapshot that has
// all info up to and including index. this means the
// service no longer needs the log through (and including)
// that index. Raft should now trim its log as much as possible.
func (rf *Raft) Snapshot(index int, snapshot []byte) {
// Your code here (2D).
rf.mu.Lock()
defer rf.mu.Unlock()
if index <= rf.snapshot.lastIncludedIndex {
return
}
defer rf.persist()
// get real index
realIndex := rf.logicIndexToRealIndex(index) - 1
rf.snapshot.lastIncludedTerm = rf.log[realIndex].Term
// discard before index log
if rf.getLogLogicSize() <= index {
rf.log = []LogEntry{}
} else {
rf.log = append([]LogEntry{}, rf.log[realIndex+1:]...)
}
rf.snapshot.lastIncludedIndex = index
DPrintf("[Snapshot] %s do snapshot, index = %d", rf.role_info(), index)
rf.persister.SaveStateAndSnapshot(rf.persister.ReadRaftState(), snapshot)
}
4.2.2 InstallSnapshot
leader 同步给客户端的日志在快照中时,发送 InstallSnapshot RPC,客户端的处理逻辑如下:
func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {
// 1. Reply immediately if term < currentTerm
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
if args.Term < rf.currentTerm || args.LastIncludedIndex <= rf.snapshot.lastIncludedIndex {
DPrintf("[InstallSnapshot] return because rf.currentTerm > args.Term , %s", rf.role_info())
return
}
DPrintf("[InstallSnapshot] %s recive InstallSnapshot rpc %v", rf.role_info(), args)
defer rf.persist()
if rf.currentTerm < args.Term {
rf.SwitchRole(ROLE_Follwer)
rf.currentTerm = args.Term
}
rf.electionTimer.Reset(getRandomTimeout())
rf.commitIndex = args.LastIncludedIndex - 1
rf.lastApplied = args.LastIncludedIndex - 1
realIndex := rf.logicIndexToRealIndex(args.LastIncludedIndex) - 1
DPrintf("[InstallSnapshot] %s commitIndex=%d, Log=%v", rf.role_info(), rf.commitIndex, rf.log)
if rf.getLogLogicSize() <= args.LastIncludedIndex {
rf.log = []LogEntry{}
} else {
rf.log = append([]LogEntry{}, rf.log[realIndex+1:]...)
}
rf.snapshot.lastIncludedIndex = args.LastIncludedIndex
rf.snapshot.lastIncludedTerm = args.LastIncludedTerm
go func() {
rf.applyCh <- ApplyMsg{
SnapshotValid: true,
Snapshot: args.Data,
SnapshotTerm: args.LastIncludedTerm,
SnapshotIndex: args.LastIncludedIndex,
}
rf.mu.Lock()
defer rf.mu.Unlock()
rf.persister.SaveStateAndSnapshot(rf.persister.ReadRaftState(), args.Data)
}()
}
4.2.3 SendInstallSnapshot
快照同步,执行时机为 Leader 发现 AppendEntries 中的 PrevIndex < snapshot.lastIncludedIndex,则表示需要同步的日志在快照中,此时需要同步整个快照,并且修改 nextIndex 为 snapshot.lastIncludedIndex。
func (rf *Raft) SendInstallSnapshot(server int) {
rf.mu.Lock()
args := InstallSnapshotArgs{
Term: rf.currentTerm,
LastIncludedIndex: rf.snapshot.lastIncludedIndex,
LastIncludedTerm: rf.snapshot.lastIncludedTerm,
// hint: Send the entire snapshot in a single InstallSnapshot RPC.
// Don't implement Figure 13's offset mechanism for splitting up the snapshot.
Data: rf.persister.ReadSnapshot(),
}
reply := InstallSnapshotReply{}
rf.mu.Unlock()
ok := rf.sendInstallSnapshot(server, &args, &reply)
if ok {
// check reply term
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.currentRole != ROLE_Leader || rf.currentTerm != args.Term {
return
}
if reply.Term > args.Term {
DPrintf("[SendInstallSnapshot] %v to %d failed because reply.Term > args.Term, reply=%v\n", rf.role_info(), server, reply)
rf.SwitchRole(ROLE_Follwer)
rf.currentTerm = reply.Term
rf.persist()
return
}
// update nextIndex and matchIndex
rf.nextIndex[server] = args.LastIncludedIndex
rf.matchIndex[server] = rf.nextIndex[server] - 1
DPrintf("[SendInstallSnapshot] %s to %d nextIndex=%v, matchIndex=%v", rf.role_info(), server, rf.nextIndex, rf.matchIndex)
}
}
4.2.4 持久化
需要注意,readPersist 的时候,需要更新 commitIndex 和 lastApplied
func (rf *Raft) persist() {
// Your code here (2C).
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
//e.Encode(rf.commitIndex)
e.Encode(rf.log)
e.Encode(rf.snapshot.lastIncludedIndex)
e.Encode(rf.snapshot.lastIncludedTerm)
data := w.Bytes()
rf.persister.SaveRaftState(data)
}
//
// restore previously persisted state.
//
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
// Your code here (2C).
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votedFor int
var log []LogEntry
var snapshot Snapshot
//var commitIndex int
if d.Decode(¤tTerm) != nil ||
d.Decode(&votedFor) != nil ||
//d.Decode(&commitIndex) != nil ||
d.Decode(&log) != nil ||
d.Decode(&snapshot.lastIncludedIndex) != nil ||
d.Decode(&snapshot.lastIncludedTerm) != nil {
DPrintf("[readPersist] decode failed ...")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votedFor
rf.log = log
rf.snapshot = snapshot
rf.lastApplied = snapshot.lastIncludedIndex - 1
rf.commitIndex = snapshot.lastIncludedIndex - 1
DPrintf("[readPersist] Term=%d VotedFor=%d, Log=%v ...", rf.currentTerm, rf.votedFor, rf.log)
}
}
4.3 小结
该 part 主要麻烦的点在于下标的转换,需要把所有用到下标的地方都进行处理。其次需要注意,截断日志时,不能简单使用切片,可能会有 data race ,其次直接对 rf.log 使用切片会有引用未释放的问题。
5. 测试
对代码总体进行测试 100 次,结果基本通过,参考 测试结果。中间测试时遇到一些问题:
- 由于使用 select 接收 timer 的信号,切换 role 的时候没有 stop timer,select 在多个信号到达时,会随机选择一个,导致会有 timer 超时不触发,比如 election time out 但是没有发起 election。因此切换 role 时需要 stop timer。(修改了此处后 Figure8 unreliable 基本都 pass 了)
- 发送 AppendEntries RPC 的时候,出现了 data race,因为对参数中的日志使用了切片,导致持有了参数的引用,发送 rpc 时需要对参数进行序列化,两者产生 data race。解决方式就是使用如 copy 之类的操作,深拷贝,防止 data race。
- 目前还有一种小概率情况会导致 case 不会过,假定有 3 个节点,节点 a 竞选后成为 leader,并且 start 了一条 log,此时节点的 Term 都为 2,但是 log 还没同步给其他节点时,节点 b election time out 了,也发起了投票,因此节点 b Term 更新为 3,由于节点 c 未同步到 log,因此会给 b 投票,b 成为了新的 leader(2/3),最初的那条 log 就会丢失,这种情况应该是允许出现的,检查了 test,发现 start log 有个可以 retry 的参数,如果 retry 为 true 则会进行重试。只 start 一次 log 的情况下理论上是会有丢失的可能的,因此不认为此处为 bug。