前言
又是一年乍暖还寒,春天的风迎面而来,凉意中夹杂着些许温暖。哦,你知道,是春天来了。就像那年的实习期,在挥手告别的毕业季,定格在了那年的七月。
人会怀念,怀念青涩时期的自己,懵懵懂懂却又充满着努力。人会想念,想念每天朝夕相处的人,有一天会在转角挥手告别。人会改变,改变了不善言辞的自己,终游荡于人情世故之中。
毕业近三年,接触大数据已近四年,顺着大数据的浪潮,在一个不大不小的城市有了立身之地。每逢佳节,亲朋好友谈及工作,皆以开发手机软件答之,避免出现半天解释不清的情况。后来在很多地方也遇到询问大数据的问题,所以趁着空闲之余记录一下这些年的大数据时光。
概念
什么是大数据
我理解的大数据就是利用一些技术手段来处理海量数据并实现其价值。首先是海量数据,如果没有数据支撑,大数据就只是空谈。其次是技术手段,用来离线或者实时处理数据,其中的Hadoop你一定有所耳闻。目前,大数据应用比较广泛的行业有:电商、运营商、金融、医疗等。
为什么需要大数据
这里就拿电商举例。是否你曾经思考过,为什么每次你在购物平台浏览过的商品,就会出现在首页推荐或者其他APP的广告中。其实这就是大数据的应用之一。
你在APP上浏览商品,后台会收集你的商品浏览数据,其中包括用户账号、商品类别等字段。此刻,如果你是技术人员,你会如何将浏览数据存放起来?在传统开发思维中很多人会选择:MySQL/Oracle。
但是一天几百、几千亿的商品浏览数据,主机需要多大的磁盘才能完成数据留存?MySQL能处理这么多数据吗?如何实时高效分析出用户的浏览偏好?这需要开发者思考技术选型。
而大数据的出现,就解决了这些问题。
大数据难学么
纸上得来终觉浅,绝知此事要躬行。大数据其实是不难学的,只是要求技术层面比较广,涉及编程、网络、主机等方面知识,需要多方面知识的沉淀。大数据的深入学习需要在理论的基础上加以实践。在学习技术框架的时候,最好动手在阿里云或者虚拟机上搭建集群,一方面可以提高Linux的使用能力和了解集群的运行原理,另一方面可以在集群上进行操作练习。
其次,大数据技术在生产和测试环境中其实是不一样的。生产环境会有实际的业务场景和各种各样的问题,所以有机会接触到大数据生产环境的话,学习效率会事半功倍。
主要技术
大数据中,不同的业务场景对应着不用的技术选型,大数据技术运用方向主要是离线计算和实时计算。在此之前,我们先了解一下Hadoop。
Hadoop
大部分人都知道Hadoop,Hadoop作为最基本大数据框架,占据着核心的位置。Apache Hadoop是社区开源版本,而生产中使用最多的,还是基于Apache的第三方发行版的Hadoop,例如HDP和CDH,这两家是免费的,目前我们使用的是HDP。当然也有收费,例如华为、Intel。
那么,Hadoop发挥着什么样的作用?
在传统思维中,程序的运行只占用运行程序主机的计算资源,例如CPU和内存;文件只占用所在主机的磁盘存储。而Hadoop可以利用多台机器组成集群,从而提供分布式计算和分布式存储的能力。
HDFS(Hadoop Distributed File System)
HDFS由主节点NameNode和从节点DataNode组成。在大数据中,主从结构是最常见的架构。
NameNode负责管理整个文件系统的元数据,例如某个文件存放在哪台机器上。当NameNode故障无法工作,则HDFS就变得不可用。目前解决方法的就是HA高可用,即集群中有两个NameNode,平时一个处于Active状态,一个处于StandBy状态。当处于Active的NameNode无法工作时,StandBy的NameNode会变成Active状态并接管工作。
DataNode负责数据文件的存储,每个文件根据预先设置的副本数被存储在不同的机器上。假如你设置的副本数为3,那么一个文件将会额外被复制三份,生成三个副本。根据机架感知策略,存放在不同的节点上。
- 副本1放在和Client相同机架的节点上(Client不在集群内则选择最近的节点)
- 副本2放在与第一个机架不同的机架中的任意节点上
- 副本3放在与第二个节点所在机架的不同的节点
这样,当一个节点故障导致文件损坏,也可以通过其他节点的文件副本保证正常使用,这就是数据容灾策略,通过牺牲空间、数据冗余来保证数据的可用性,类似于raid。同时,Kafka也是通过副本来保证数据可用性。
MapReduce
MapReduce是一个分布式计算模型,将任务的执行分为Map和Reduce两个阶段,每个阶段都拆分成多个任务来并发执行,类似于算法中的分治思想。
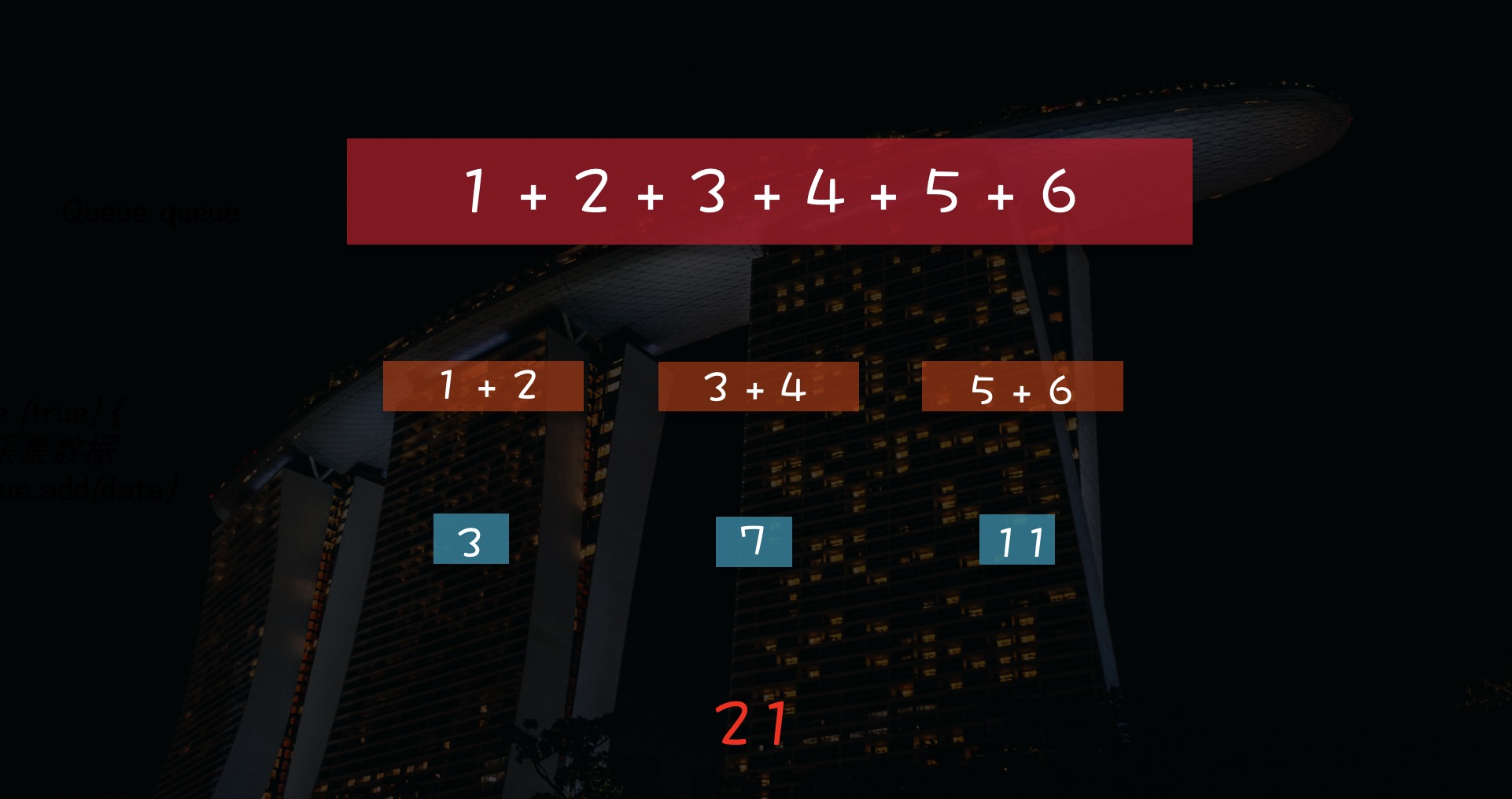
如图,分治思想是将任务拆分成多个子任务同时计算,以此得出最终结果。MapReduce也是将任务拆分,分发到Hadoop的各个节点上进行计算,这样就可以利用多个主机的计算资源。至于MapReduce底层的实现细节,有兴趣的话可以研究一下。
离线计算
离线数据通常是指已经持久化到磁盘的数据,例如存储于文件、数据库。我把离线计算理解成有边界计算,因为文件、数据库中的数据是已知的、通常不会改变。狭义上也可以理解为数据库SQL计算,利用大数据技术在海量离线数据中进行分析,用于营销决策或者报表展示等。
技术架构
离线计算一般使用的是Hive。Hive作为数据仓库工具,其数据文件存放于HDFS之上,通过HiveSQL对数据文件进行增删改查操作。虽然Hive提供着数据库的操作方式,但HiveSQL会被Hive的执行引擎解析成MapReduce任务,分发在Hadoop节点上执行,所以Hive本身并不是一个数据库,底层计算还是依赖于MapReduce。
经常使用的技术还有SparkSQL、Kylin、Hbase、Druid、Clickhouse等。
应用举例
分析出一个月内成交量最多的商品Top100,制作可视化报表。
实时计算
与离线计算对应的就是实时计算,可以理解为无边界流式计算。数据就像河水一样,源源不断的进入程序中。而程序也会一直运行,直到出现异常或者被人工停止。
技术架构
目前企业使用最多的实时计算框架的就是Flink和SparkStreaming,并配合Kafka作为消息队列来构建实时计算。这里简单模拟一下流处理:

如图,采集程序作为生产者,实时生成数据写入Kafka;Flink程序作为消费者,实时读取Kafka中的数据源来进行计算处理,最终将计算结果写入Kafka或者HDFS中。
日常中比较常用的流处理技术还有Storm、RabbitMQ等,而Redis通常作为缓存为流式计算提供服务。
应用举例
运营商举例,到达某个景区会收到景区欢迎短信,这就是实时位置能力的应用之一。
岗位划分
很多人想从事大数据行业,问的最多的就是大数据有哪些岗位?大数据的岗位主要分为三种:大数据分析、大数据开发、大数据运维。当然往细了说,还有平台架构师,主要负责集群搭建等工作,这暂且不谈。
我在实习的时候,做过一个月的大数据分析和半年的大数据运维工作,毕业之后就开始负责大数据开发的工作。一圈体验下来,对每个岗位也有了一些自己的心得体会。
大数据分析
大数据分析主要面向于离线计算。负责数据分析、报表统计等工作,重于数据价值的体现;数据的ETL调度,即E抽取、T转换、L加载,着重于离线数据的流转。虽然工作形式比较固定,但日常需求比较多,尤其是节假日的数据分析工作对时间要求也是极为紧迫。
在知乎上有人问,为什么大数据行业,大部分岗位都是做离线数仓的工作,写HiveSQL的?
我在大数据实习的第一份工作就是大数据分析,目前很多实习生来了也都是安排数据分析工作。因为这一块工作偏向于业务,对技术要求不是很严格,入手比较简单。大部分的工作都是数据库SQL开发,经过指导很快就能开始工作。
其次,离线数据量大,数据的清洗、分层汇聚、准确性验证都是很需要人力和时间的。同时,业务需求量多,离线数据需要通过统计、同比、环比等分析手段,高效地支撑客户的营销决策以及对外变现,能快速为公司创造效益。所以,公司的业务结构和运营体系决定了需要大量的大数据分析岗位。
技术栈
-
编程语言:会则锦上添花,不会也可工作,但是建议学一点Python、Java。
-
大数据技术:Hadoop、HDFS、Hive、Hbase、ETL调度等。
-
其他:Shell、Linux操作、SQL。
大数据开发
大数据开发主要面向于实时计算。主要使用Java、Scala完成Flink、Spark的应用开发。相对于大数据分析来说,工作范围比较广,技术要求比较高,同时工作形式也比较灵活,可以通过不同的技术选型来制定多种解决方案,而且工作也没有那么繁杂。
目前,我的主要负责工作内容:
-
数据的接入:将数据量1万亿/天的二进制数据根据规范解析成明文,放于Kafka。主要是对Java多线程、JVM、NIO的应用。
-
流处理开发:Flink、Spark、IBMStreams应用开发。开发语言:Scala、SPL。
-
数据留存:将1万亿/天、300T大小的数据存放于HDFS,并加载到Hive。技术选型:Flume。
-
爬虫开发:结合营销场景采集数据,百万级数据量/天。技术选型:Scrapy。
所以,大数据开发主要是编程多一些。和传统的Java开发的区别就是,Java开发面向于项目工程,模块结构比较庞大复杂,需要多人协同完成;大数据开发面向于单个应用场景的解决方案,通常就是几百行代码,通常一人即可完成。
技术栈
-
编程语言:主要语言是Java、Scala,需要有很强的编程能力。
-
大数据技术:主要是Flink、Spark、Kafka、Redis、Hadoop、HDFS、Yarn。
-
其他:Shell、Linux。
大数据运维
大数据运维主要是监控大数据平台、应用程序的健康状态,需要对紧急情况及时做出反应。大数据运维的工作比较辛苦,经常需要熬夜值班。要求运维工作者需要对集群、主机有详细的了解,同时也具有日志分析、问题跟踪解决的能力。
我负责大数据运维工作的时候,基本上电脑不离身,不是坐在电脑前就是背着电脑走在路上,除此之外,还要时常接受告警短信的轰炸。
技术栈
大数据平台使用、Linux操作、主机、网络、调度等。
我和大数据
17年的那个夏天,经历一番波折之后,开始了大数据的实习生活。刚开始主要做一些HiveSQL的数据校验工作,也会被安排一些写文档的工作。那时候心中依旧怀揣Java开发的理想,每天下班在出租屋里和大学舍友一起学着没学完的Java课程,在公司里跟着大数据视频搭建集群,在公交车上每天看大数据的文章。
那时候的脸皮是真的薄,上班的时候习惯把头趴到在电脑屏幕之下,遇到问题也不好意思去问,都是攒一起,等到同事过来询问进度的时候一股脑儿的全问完。工作的重复以及与Java开发理想的渐行渐远,让我经常在夜深人静会想:这是我想要的工作吗?
两个月后,运维小哥离职,我摇身一变,成为了一名大数据运维,从此过上了人机合一的生活。因为需要监控一些应用,我写下了人生中的第一个Shell脚本。后来因为会Java,也以运维的身份参与了一些开发工作,同时也自学Spark、Kafka等大数据开发技术。在后来几个月的加班中,趁机深入了解了平台架构,也理清了数据在整个大数据平台的流转过程,从此豁然开朗。
那时候真的辛苦,但也是真的快乐充实,那段时光让我离大数据开发的岗位越来越近。那时候的我有着用不完的精力、对知识充满着渴望,对工作充满着热情。长时间的相处下来,内心的懵懂与紧张也随之淡去,在某天的不经意间融入到了大数据这个集体中。
后来,经历了转正,经历了分别,经历了一个人的成长,再后来成为了一名小小的大数据开发。
三年匆匆,亦未能洗尽铅华,这条路上,仍需努力学习,继续前进。
人要忠于自己年轻时的梦想。
结语
希望看完这篇文章,能让你大数据有一些基本的了解。希望有一天别人谈及大数据的时候,你也能胸有成竹、侃侃而谈。亦或能让你有一些感悟,哦,原来大数据是这样。我心足矣。
时间更迭、技术换代,大数据的热潮已然退去,人工智能、机器学习已占尽流量话题。但大数据依然还是大数据,也愿每个人走出半生,归来依旧是少年。
标签:Java,运维,杂谈,离线,Hadoop,工作,2021,2017,数据 From: https://www.cnblogs.com/xieqisheng666/p/16963125.html