项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5000517?contributionType=1
如遇到问题查看原项目解决
图学习温故以及初探Paddle Graph Learning (PGL)构建属于你的图【系列三】
相关项目参考:
图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二):https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1
关于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1
0.知识点回顾


根据图的节点间是否有方向,可将图分为无向图与有向图;图的边是否有权重,可以将图分为无权图和有权图;图的边和点是否具有多种类型,可以将图分为同构图和异构图
-
度是图上一节点,其边的条数
-
邻居指的是图上一节点的相邻节点
无向图的临界矩阵就是对称矩阵
邻接表:其实就是直接记录着每个节点的邻居信息

可以将基于图能做的任务进行一个分类。
-
这个点的类别或者其他的特性,那么这就是一个节点级别的任务;
-
预测这条边的权值,或者预测这条边是否存在,等等,那么这就是一个边级别的任务;
-
预测整张图的一个类别,或者想比较两张图之间的相似性等等,这就是一个图级别的任务了。
节点级别任务:金融诈骗检测
在建图的时候,它的节点是用户和商家,同时还包含了各自共有的信息作为节点。
其中,每个用户或者商家都有着各自的特征,也具备着某些相同的特征,同时也有着与他人的交互。传统方法通常是直接利用用户和商家的特征来训练一个分类网络,而没有利用节点与节点之间的交互,因此使用图学习, 可以同时学习图结构以及节点特征,更好的进行分类,从而更好地找到金融诈骗分子。
目标检测:点云
点云是通过激光扫描等来获得的点数据,而3D点云这个结构可以建模为图结构。
在点云中构建好图之后,将图结构和图特征经过这个叫 Point-GNN 的模型,从而预测出点云中每个点所对应的 object,也就是目标对象,同时要预测出对应目标的所在三维边界,也就是 bounding box。
由于预测对象是每个点,因此这是一个节点级别的任务。
推荐系统
比如, 想要向用户推荐新闻,以左边这个图为例, 已经知道了用户 ABC的历史点击行为,那么接下来,想要预测用户B会不会点击某条广告,其实就相当于预测这条边是否存在,因此这就是一个边预测的任务。
具体实现的时候,会把用户行为图关系通过图表示学习后,得到用户、商品或内容的向量表示;得到对应这些节点的 Embeddings 之后, 就可以利用这些 embeddings 来做各种的推荐任务。

这里分为了三大类:游走类算法、图神经网络算法、以及知识图谱嵌入算法。
因为知识图谱也是一种典型的图,因此把它也加入到了这个分类里面。
其中,图神经网络算法还可以进行更加具体的划分,比如分为卷积网络和递归网络,等等。
图游走类算法,任意选择一个出发点,然后随机地选择下一个目的地,不断地走,通过不断地游走,得到了多个序列,而游走类算法就是在得到这些序列之后,对它们应用图表示学习,再进行接下来的其他操作。
图神经网络算法相对来说则复杂一点,它的一种实现方式是消息传递。
消息传递,其实质就是把当前节点的邻居发送到自身,将这些信息聚合后,再利用这些信息更新自身的表示。
-
图游走类算法:通过在图上的游走,获得多个节点序列,再利用 Skip Gram 模型训练得到节点表示
-
图神经网络算法:端到端模型,利用消息传递机制实现。
-
知识图谱嵌入算法:专门用于知识图谱的相关算法。

1.Paddle Graph Learning (PGL) 简介
https://github.com/PaddlePaddle/PGL/blob/main/README.zh.md

Paddle Graph Learning (PGL)是一个基于PaddlePaddle的高效易用的图学习框架

PGL的优点:
- 易用性:建图方便
- 高效性:运行速度快
- 大规模:支持十亿节点百亿边
- 丰富性:预置了主流的图学习算法
在最新发布的PGL中引入了异构图的支持,新增MetaPath采样支持异构图表示学习,新增异构图Message Passing机制支持基于消息传递的异构图算法,利用新增的异构图接口,能轻松搭建前沿的异构图学习算法。而且,在最新发布的PGL中,同时也增加了分布式图存储以及一些分布式图学习训练算法,例如,分布式deep walk和分布式graphsage。结合PaddlePaddle深度学习框架, 的框架基本能够覆盖大部分的图网络应用,包括图表示学习以及图神经网络。
1.1 特色:高效性——支持Scatter-Gather及LodTensor消息传递
对比于一般的模型,图神经网络模型最大的优势在于它利用了节点与节点之间连接的信息。但是,如何通过代码来实现建模这些节点连接十分的麻烦。PGL采用与DGL相似的消息传递范式用于作为构建图神经网络的接口。用于只需要简单的编写send还有recv函数就能够轻松的实现一个简单的GCN网络。如下图所示,首先,send函数被定义在节点之间的边上,用户自定义send函数$\phie$会把消息从源点发送到目标节点。然后,recv函数$\phiv$负责将这些消息用汇聚函数$\oplus$ 汇聚起来。
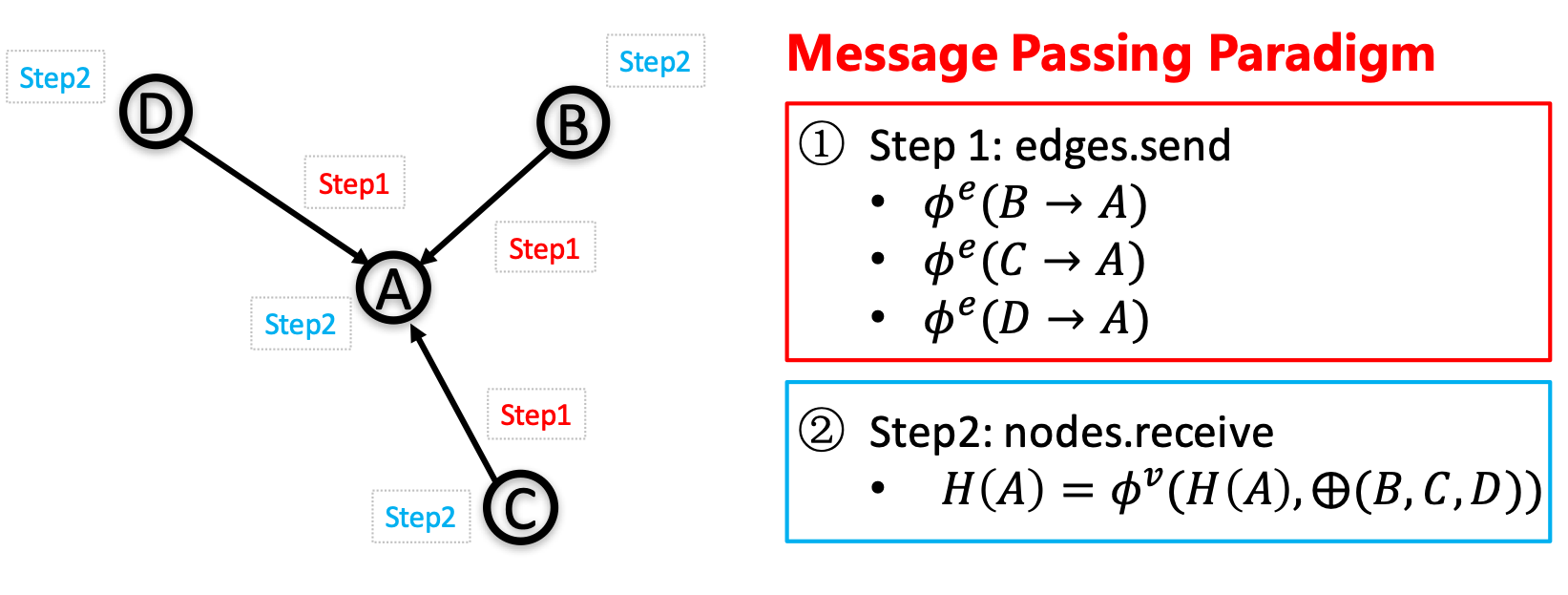
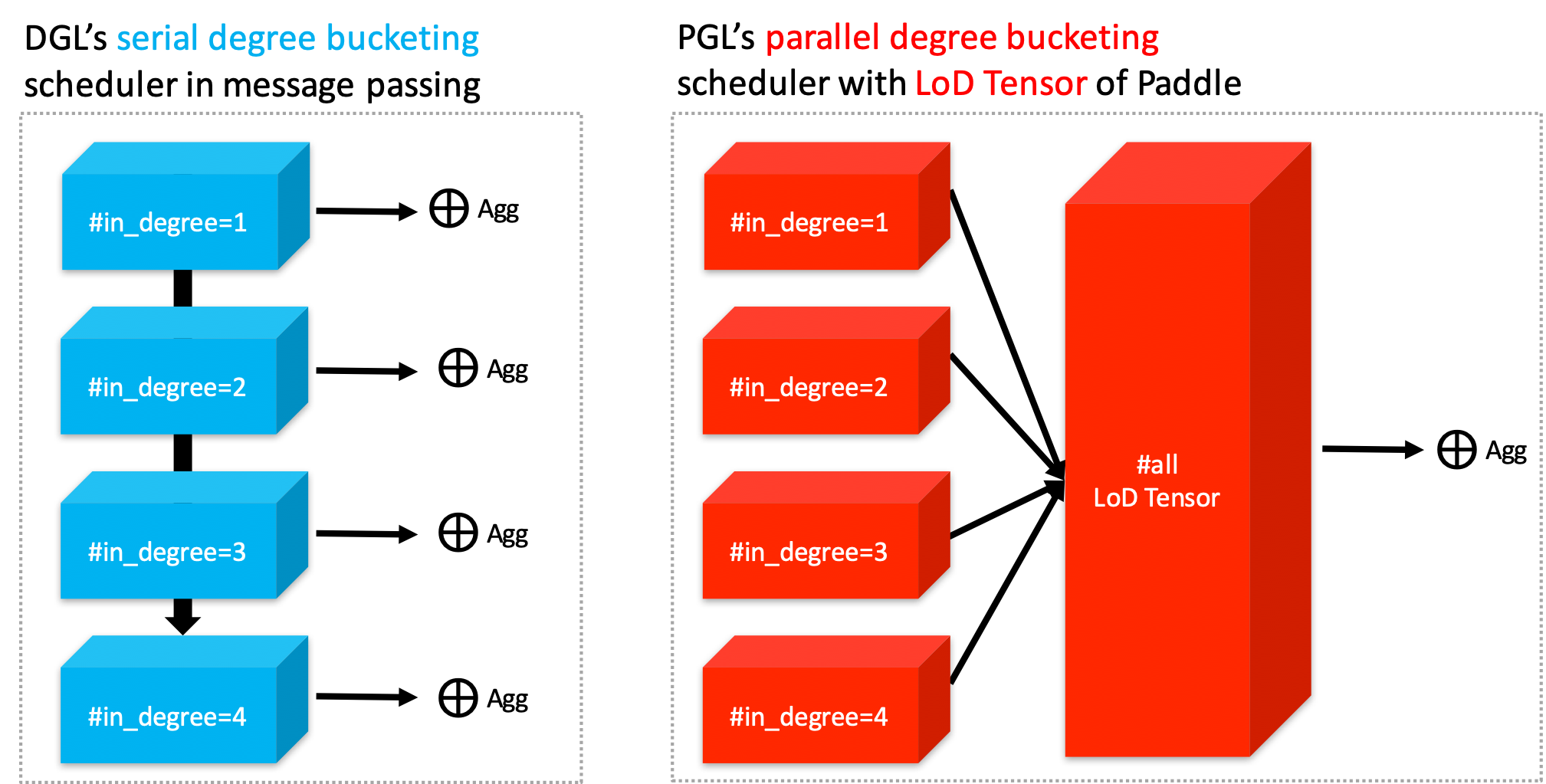
如下面左图所示,为了去适配用户定义的汇聚函数,DGL使用了Degree Bucketing来将相同度的节点组合在一个块,然后将汇聚函数$\oplus$作用在每个块之上。而对于PGL的用户定义汇聚函数, 则将消息以PaddlePaddle的LodTensor的形式处理,将若干消息看作一组变长的序列,然后利用LodTensor在PaddlePaddle的特性进行快速平行的消息聚合。
用户只需要下面简单几行代码,就可以实现一个求和聚合函数了。
import pgl
import paddle
import numpy as np
num_nodes = 5
edges = [(0, 1), (1, 2), (3, 4)]
feature = np.random.randn(5, 100).astype(np.float32)
g = pgl.Graph(num_nodes=num_nodes,
edges=edges,
node_feat={
"h": feature
})
g.tensor()
def send_func(src_feat, dst_feat, edge_feat):
return src_feat
def recv_func(msg):
return msg.reduce_sum(msg["h"])
msg = g.send(send_func, src_feat=g.node_feat)
ret = g.recv(recv_func, msg)
尽管DGL用了一些内核融合(kernel fusion)的方法来将常用的sum,max等聚合函数用scatter-gather进行优化。但是对于复杂的用户定义函数,他们使用的Degree Bucketing算法,仅仅使用串行的方案来处理不同的分块,并不会充分利用GPU进行加速。然而,在PGL中 使用基于LodTensor的消息传递能够充分地利用GPU的并行优化,在复杂的用户定义函数下,PGL的速度在 的实验中甚至能够达到DGL的13倍。即使不使用scatter-gather的优化,PGL仍然有高效的性能表现。当然, 也是提供了scatter优化的聚合函数。
性能测试
用Tesla V100-SXM2-16G测试了下列所有的GNN算法,每一个算法跑了200个Epoch来计算平均速度。准确率是在测试集上计算出来的,并且 没有使用Early-stopping策略。
| 数据集 | 模型 | PGL准确率 | PGL速度 (epoch) | DGL 0.3.0 速度 (epoch) |
|---|---|---|---|---|
| Cora | GCN | 81.75% | 0.0047s | 0.0045s |
| Cora | GAT | 83.5% | 0.0119s | 0.0141s |
| Pubmed | GCN | 79.2% | 0.0049s | 0.0051s |
| Pubmed | GAT | 77% | 0.0193s | 0.0144s |
| Citeseer | GCN | 70.2% | 0.0045 | 0.0046s |
| Citeseer | GAT | 68.8% | 0.0124s | 0.0139s |
如果 使用复杂的用户定义聚合函数,例如像GraphSAGE-LSTM那样忽略邻居信息的获取顺序,利用LSTM来聚合节点的邻居特征。DGL所使用的消息传递函数将退化成Degree Bucketing模式,在这个情况下DGL实现的模型会比PGL的慢的多。模型的性能会随着图规模而变化,在 的实验中,PGL的速度甚至能够能达到DGL的13倍。
| 数据集 | PGL速度 (epoch) | DGL 0.3.0 速度 (epoch time) | 加速比 |
|---|---|---|---|
| Cora | 0.0186s | 0.1638s | 8.80x |
| Pubmed | 0.0388s | 0.5275s | 13.59x |
| Citeseer | 0.0150s | 0.1278s | 8.52x |
1.2特色:易用性——原生支持异质图
图可以很方便的表示真实世界中事物之间的联系,但是事物的类别以及事物之间的联系多种多样,因此,在异质图中, 需要对图网络中的节点类型以及边类型进行区分。PGL针对异质图包含多种节点类型和多种边类型的特点进行建模,可以描述不同类型之间的复杂联系。
1.2.1 支持异质图MetaPath walk采样
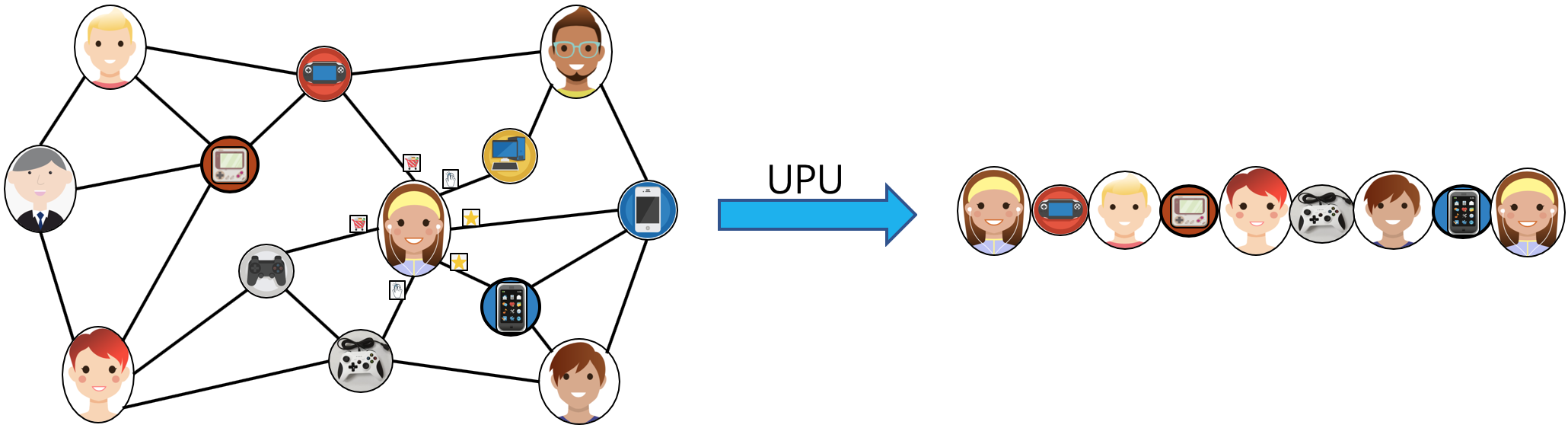
上图左边描述的是一个购物的社交网络,上面的节点有用户和商品两大类,关系有用户和用户之间的关系,用户和商品之间的关系以及商品和商品之间的关系。上图的右边是一个简单的MetaPath采样过程,输入metapath为UPU(user-product-user),采出结果为

然后在此基础上引入word2vec等方法,支持异质图表示学习metapath2vec等算法。
1.2.2 支持异质图Message Passing机制
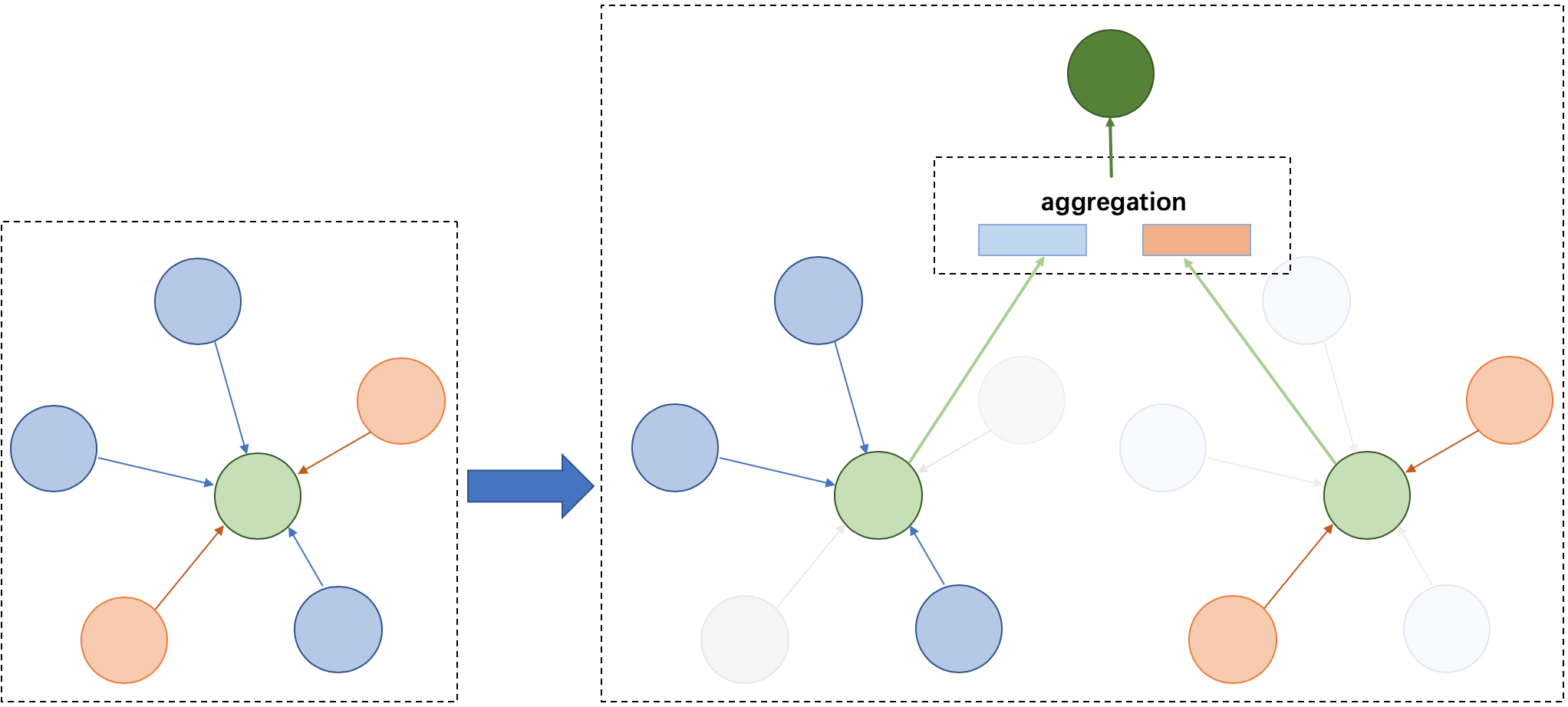
在异质图上由于节点类型不同,消息传递也方式也有所不同。如上图左边,它有五个邻居节点,属于两种不同的节点类型。如上图右边,在消息传递的时候需要把属于不同类型的节点分开聚合,然后在合并成最终的消息,从而更新目标节点。在此基础上PGL支持基于消息传递的异质图算法,如GATNE等算法。
1.3 特色:规模性——支持分布式图存储以及分布式学习算法
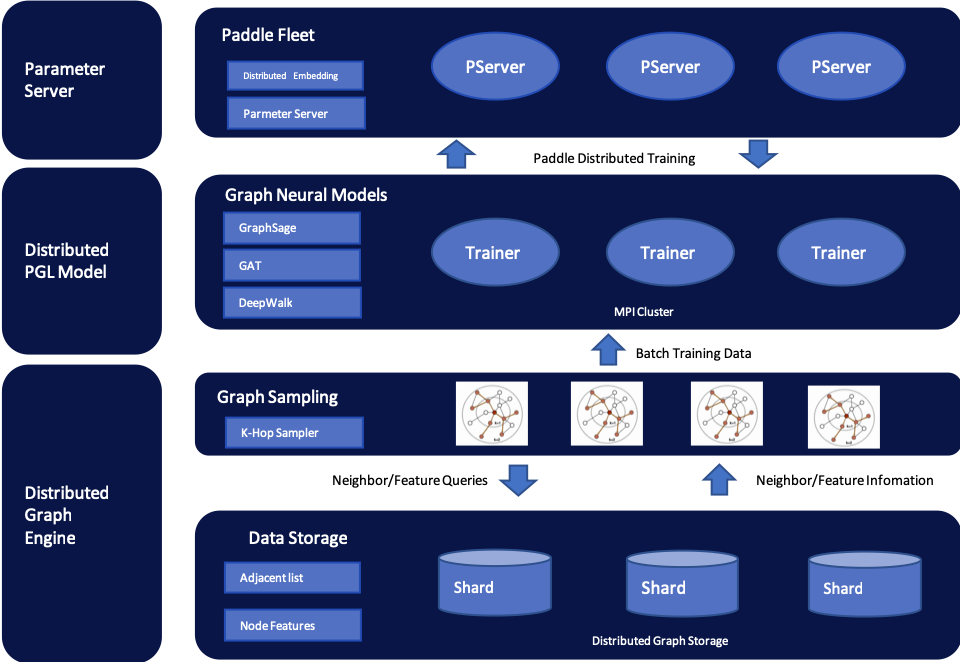
在大规模的图网络学习中,通常需要多机图存储以及多机分布式训练。如下图所示,PGL提供一套大规模训练的解决方案, 利用PaddleFleet(支持大规模分布式Embedding学习)作为 参数服务器模块以及一套简易的分布式存储方案,可以轻松在MPI集群上搭建分布式大规模图学习方法。
1.4 特色:丰富性——覆盖业界大部分图学习网络
下列是框架中已经自带实现的十三种图网络学习模型。详情请参考这里
| 模型 | 特点 |
|---|---|
| ERNIESage | 能同时建模文本以及图结构的ERNIE SAmple aggreGatE |
| GCN | 图卷积网络 |
| GAT | 基于Attention的图卷积网络 |
| GraphSage | 基于邻居采样的大规模图卷积网络 |
| unSup-GraphSage | 无监督学习的GraphSAGE |
| LINE | 基于一阶、二阶邻居的表示学习 |
| DeepWalk | DFS随机游走的表示学习 |
| MetaPath2Vec | 基于metapath的表示学习 |
| Node2Vec | 结合DFS及BFS的表示学习 |
| Struct2Vec | 基于结构相似的表示学习 |
| SGC | 简化的图卷积网络 |
| GES | 加入节点特征的图表示学习方法 |
| DGI | 基于图卷积网络的无监督表示学习 |
| GATNE | 基于MessagePassing的异质图表示学习 |
上述模型包含图表示学习,图神经网络以及异质图三部分,而异质图里面也分图表示学习和图神经网络。

2.使用PGL构建同质图--小试牛刀
2.1 用 PGL 来创建一张图
为了让用户快速上手,本教程的主要目的是:
理解PGL是如何在图网络上进行计算的。
使用PGL实现一个简单的图神经网络模型,用于对图网络中的节点进行二分类。
假设我们有下面的这一张图,其中包含了10个节点以及14条边。

我们的目的是,训练一个图模型,使得该图模型可以区分图上的黄色节点和绿色节点。
!pip install pgl==1.2.1
#需要注意的是,Paddle2.x+是动态图了,为了进一步简化使用,将GraphWrapper的概念去掉了,目前可以直接在Graph上进行Send/Recv
from pgl import graph # 导入 PGL 中的图模块
import paddle.fluid as fluid # 导入飞桨框架
import numpy as np
import paddle
def build_graph():
# 定义图中的节点数目,我们使用数字来表示图中的每个节点,每个节点用一个数字表示,即从0~9
num_nodes = 10
# 定义图中的边集,添加节点之间的边,每条边用一个tuple表示为: (src, dst)
edge_list = [(2, 0), (2, 1), (3, 1),(4, 0), (5, 0),
(6, 0), (6, 4), (6, 5), (7, 0), (7, 1),
(7, 2), (7, 3), (8, 0), (9, 7)]
# 随机初始化节点特征,特征维度为 d
# 每个节点可以用一个d维的特征向量作为表示,这里随机产生节点的向量表示.
# 在PGL中,我们可以使用numpy来添加节点的向量表示。
d = 16
feature = np.random.randn(num_nodes, d).astype("float32")
# 随机地为每条边赋值一个权重
# 对于边,也同样可以用一个特征向量表示。
edge_feature = np.random.randn(len(edge_list), 1).astype("float32")
# 创建图对象,最多四个输入
# 根据节点,边以及对应的特征向量,创建一个完整的图网络。
# 在PGL中,节点特征和边特征都是存储在一个dict中。
g = graph.Graph(num_nodes = num_nodes,
edges = edge_list,
node_feat = {'feature':feature},
edge_feat ={'edge_feature': edge_feature})
return g
# 创建一个图对象,用于保存图网络的各种数据。
g = build_graph()
print('图中共计 %d 个节点' % g.num_nodes)
print('图中共计 %d 条边' % g.num_edges)
%matplotlib inline
import matplotlib.pyplot as plt
import networkx as nx # networkx是一个常用的绘制复杂图形的Python包。
def display_graph(g):
nx_G = nx.Graph()
nx_G.add_nodes_from(range(g.num_nodes))
for line in g.edges:
nx_G.add_edge(*line)
nx.draw(nx_G, with_labels=True,
node_color=['y','g','g','g','y','y','y','g','y','g'], node_size=1000)
foo_fig = plt.gcf() # 'get current figure'
foo_fig.savefig('gcn.png', format='png', dpi=1000)
#foo_fig.savefig('./foo.pdf', format='pdf') # 也可以保存成pdf
plt.show()
display_graph(g)# 创建一个GraphWrapper作为图数据的容器,用于构建图神经网络。
2.2 定义图模型
定义下面的一个简单图模型层,这里的结构是添加了边权重信息的类 GCN 层。
在本教程中,我们使用图卷积网络模型(Kipf和Welling)来实现节点分类器。为了方便,这里我们使用最简单的GCN结构。如果读者想更加深入了解GCN,可以参考原始论文。
- 在第$l$层中,每个节点$u_il$都有一个特征向量$h_il$;
- 在每一层中,GCN的想法是下一层的每个节点$u_i{l+1}$的特征向量$h_i{l+1}$是由该节点的所有邻居节点的特征向量加权后经过一个非线性变换后得到的。
GCN模型符合消息传递模式(message-passing paradigm),当一个节点的所有邻居节点把消息发送出来后,这个节点就可以根据上面的定义更新自己的特征向量了。
在PGL中,我们可以很容易实现一个GCN层。如下所示:
def model_layer(gw, nfeat, efeat, hidden_size, name, activation):
'''
gw: GraphWrapper 图数据容器,用于在定义模型的时候使用,后续训练时再feed入真实数据 # gw是一个GraphWrapper;feature是节点的特征向量。
nfeat: 节点特征
efeat: 边权重
hidden_size: 模型隐藏层维度
activation: 使用的激活函数
'''
# 定义 send 函数,定义message函数,
def send_func(src_feat, dst_feat, edge_feat):
# 将源节点的节点特征和边权重共同作为消息发送
# 注意: 这里三个参数是固定的,虽然我们只用到了第一个参数。
# 在本教程中,我们直接返回源节点的特征向量作为message。用户也可以自定义message函数的内容。
return src_feat['h'] * edge_feat['e']
# # 定义reduce函数,参数feat其实是从message函数那里获得的。
def recv_func(feat):
# 目标节点接收源节点消息,采用 sum 的聚合方式
# 这里通过将源节点的特征向量进行加和。
# feat为LodTensor,关于LodTensor的介绍参照Paddle官网。
return fluid.layers.sequence_pool(feat, pool_type='sum')
# 触发消息传递机制
# send函数触发message函数,发送消息,并将返回消息。
msg = gw.send(send_func, nfeat_list=[('h', nfeat)], efeat_list=[('e', efeat)])
# recv函数接收消息,并触发reduce函数,对消息进行处理。
output = gw.recv(msg, recv_func)
# 以activation为激活函数的全连接输出层。
output = fluid.layers.fc(output,
size=hidden_size,
bias_attr=False,
act=activation,
name=name)
return output
2.3 模型定义
在PGL中,图对象用于保存各种图数据。我们还需要用到GraphWrapper作为图数据的容器,用于构建图神经网络。
这里我们简单的把上述定义好的模型层堆叠两层,作为我们的最终模型。
# 在定义好GCN层之后,我们可以构建一个更深的GCN模型,如下我们定一个两层GCN。
class Model(object):
def __init__(self, graph):
"""
graph: 我们前面创建好的图
"""
# 创建 GraphWrapper 图数据容器,用于在定义模型的时候使用,后续训练时再feed入真实数据
self.gw = pgl.graph_wrapper.GraphWrapper(name='graph',
node_feat=graph.node_feat_info(),
edge_feat=graph.edge_feat_info())
# 作用同 GraphWrapper,此处用作节点标签的容器,创建一个标签层作为节点类别标签的容器。
self.node_label = fluid.layers.data("node_label", shape=[None, 1],
dtype="float32", append_batch_size=False)
def build_model(self):
# 定义两层model_layer
# 第一层GCN将特征向量从16维映射到8维,激活函数使用relu。
output = model_layer(self.gw,
self.gw.node_feat['feature'],
self.gw.edge_feat['edge_feature'],
hidden_size=8,
name='layer_1',
activation='relu')
# 第二层GCN将特征向量从8维映射导2维,对应我们的二分类。不使用激活函数。
output = model_layer(self.gw,
output,
self.gw.edge_feat['edge_feature'],
hidden_size=1,
name='layer_2',
activation=None)
# 对于二分类任务,可以使用以下 API 计算损失 使用带sigmoid的交叉熵函数作为损失函数
loss = fluid.layers.sigmoid_cross_entropy_with_logits(x=output,
label=self.node_label)
# 计算平均损失
loss = fluid.layers.mean(loss)
# 计算准确率
prob = fluid.layers.sigmoid(output)
pred = prob > 0.5
pred = fluid.layers.cast(prob > 0.5, dtype="float32")
correct = fluid.layers.equal(pred, self.node_label)
correct = fluid.layers.cast(correct, dtype="float32")
acc = fluid.layers.reduce_mean(correct)
return loss, acc
GCN的训练过程跟训练其它基于paddlepaddle的模型是一样的。
- 首先我们构建损失函数;
- 接着创建一个优化器;
- 最后创建执行器并执行训练过程。
import paddle
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
#2.x版本动态转换为静态图
paddle.enable_static()
# 定义程序,也就是我们的 Program
startup_program = fluid.Program() # 用于初始化模型参数
train_program = fluid.Program() # 训练时使用的主程序,包含前向计算和反向梯度计算
test_program = fluid.Program() # 测试时使用的程序,只包含前向计算
with fluid.program_guard(train_program, startup_program):
model = Model(g)
# 创建模型和计算 Loss
loss, acc = model.build_model()
# 选择Adam优化器,学习率设置为0.01
adam = fluid.optimizer.Adam(learning_rate=0.01)
adam.minimize(loss) # 计算梯度和执行梯度反向传播过程
# 复制构造 test_program,与 train_program的区别在于不需要梯度计算和反向过程。
test_program = train_program.clone(for_test=True)
# 定义一个在 place(CPU)上的Executor来执行program, 创建执行器
exe = fluid.Executor(place)
# 参数初始化
exe.run(startup_program)
# 获取真实图数据,获取图数据
feed_dict = model.gw.to_feed(g)
# 获取真实标签数据
# 由于我们是做节点分类任务,因此可以简单的用0、1表示节点类别。其中,黄色点标签为0,绿色点标签为1。
y = [0,1,1,1,0,0,0,1,0,1]
label = np.array(y, dtype="float32")
label = np.expand_dims(label, -1)
feed_dict['node_label'] = label
print(feed_dict)
2.4 模型训练&测试
for epoch in range(100):
train_loss = exe.run(train_program,
feed=feed_dict, # feed入真实训练数据
fetch_list=[loss], # fetch出需要的计算结果
return_numpy=True)[0]
print('Epoch %d | Loss: %f' % (epoch, train_loss))
print("Test Acc: %f" % test_acc)
Test Acc: 0.700000
3.总结
本项目主要讲解了图的基本概念、图学习的概念、图的应用场景、以及图算法有哪些,最后介绍了PGL图学习框架,并给出demo实践。
Paddle Graph Learning (PGL)是一个基于PaddlePaddle的高效易用的图学习框架
PGL的优点:
- 易用性:建图方便
- 高效性:运行速度快
- 大规模:支持十亿节点百亿边
- 丰富性:预置了主流的图学习算法
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5000517?contributionType=1
如遇到问题查看原项目解决
标签:函数,Graph,PGL,fluid,Paddle,学习,Learning,feat,节点 From: https://www.cnblogs.com/ting1/p/16879621.html