数据湖iceberg-day01
1.1 什么是数据湖
1.1.1 什么是数据湖
数据湖是一个集中式的存储库,允许你以任意规模存储多个来源、所有结构化和非结构化数据,可以按照原样存储数据,无需对数据进行结构化处理,并运行不同类型的分析,对数据进行加工,例如:大数据处理、实时分析、机器学习,以指导做出更好地决策。
1.1.2 大数据为什么需要数据湖
当前基于Hive的离线数据仓库已经非常成熟,在传统的离线数据仓库中对记录级别的数据进行更新是非常麻烦的,需要对待更新的数据所属的整个分区,甚至是整个表进行全面覆盖才行,由于离线数仓多级逐层加工的架构设计,数据更新时也需要从贴源层开始逐层反应到后续的派生表中去。
随着实时计算引擎的不断发展以及业务对于实时报表的产出需求不断膨胀,业界最近几年就一直聚焦并探索于实时数仓建设。根据数仓架构演变过程,在Lambda架构中含有离线处理与实时处理两条链路,其架构图如下:
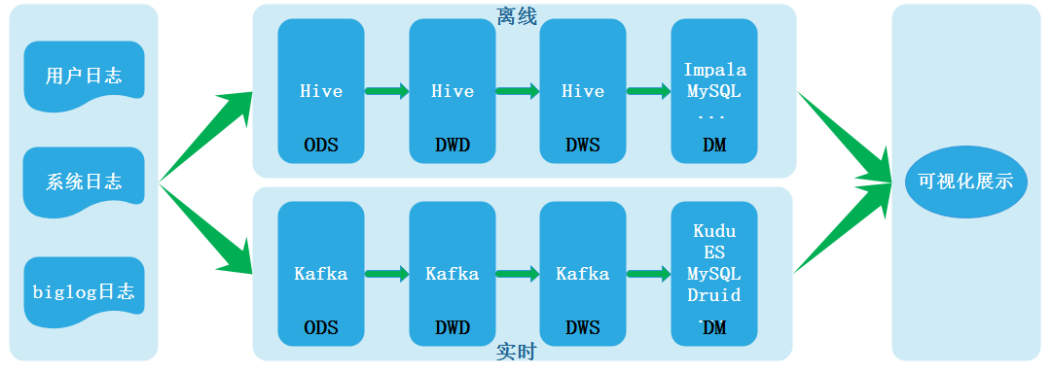
正是由于两条链路处理数据导致数据不一致等一些列问题所以才有了Kappa架构,Kappa架构如下:
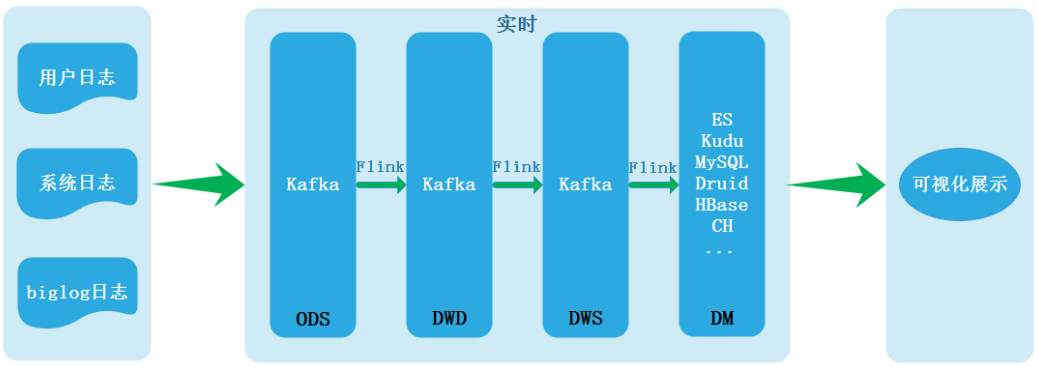
Kappa架构可以称为真正的实时数仓,目前在业界最常用实现就是Flink + Kafka,然而基于Kafka+Flink的实时数仓方案也有几个非常明显的缺陷,所以在目前很多企业中实时数仓构建中经常使用混合架构,没有实现所有业务都采用Kappa架构中实时处理实现。Kappa架构缺陷如下:
- Kafka无法支持海量数据存储。对于海量数据量的业务线来说,Kafka一般只能存储非常短时间的数据,比如最近一周,甚至最近一天。
- Kafka无法支持高效的OLAP查询,大多数业务都希望能在DWD\DWS层支持即席查询的,但是Kafka无法非常友好地支持这样的需求。
- 无法复用目前已经非常成熟的基于离线数仓的数据血缘、数据质量管理体系。需要重新实现一套数据血缘、数据质量管理体系。
- Kafka不支持update/upsert,目前Kafka仅支持append。
为了解决Kappa架构的痛点问题,业界最主流是采用“批流一体”方式,这里批流一体可以理解为批和流使用SQL同一处理,也可以理解为处理框架的统一,例如:Spark、Flink,但这里更重要指的是存储层上的统一,只要存储层面上做到“批流一体”就可以解决以上Kappa遇到的各种问题。数据湖技术可以很好的实现存储层面上的“批流一体”,这就是为什么大数据中需要数据湖的原因。
1.2 Iceberg概念及特点
Apache Iceberg是一种用于大型数据分析场景的开放表格式(Table Format)。Iceberg使用一种类似于SQL表的高性能表格式,Iceberg格式表单表可以存储数十PB数据,适配Spark、Trino、PrestoDB、Flink和Hive等计算引擎提供高性能的读写和元数据管理功能,Iceberg是一种数据湖解决方案。
注意:Trino就是原来的PrestoSQL ,2020年12月27日,PrestoSQL 项目更名为Trino,Presto分成两大分支:PrestoDB、PrestorSQL。
Iceberg非常轻量级,可以作为lib与Spark、Flink进行集成,Iceberg官网:https://iceberg.apache.org/,Iceberg具备以下特点:
- Iceberg支持实时/批量数据写入和读取,支持Spark/Flink计算引擎。
- Iceberg支持事务ACID,支持添加、删除、更新数据。
- 不绑定任何底层存储,支持Parquet、ORC、Avro格式兼容行存储和列存储。
- Iceberg支持隐藏分区和分区变更,方便业务进行数据分区策略。
- Iceberg支持快照数据重复查询,具备版本回滚功能。
- Iceberg扫描计划很快,读取表或者查询文件可以不需要分布式SQL引擎。
- Iceberg通过表元数据来对查询进行高效过滤。
- 基于乐观锁的并发支持,提供多线程并发写入能力并保证数据线性一致。
1.3 Iceberg数据存储格式
1.3.1 Iceberg术语
- data files(数据文件):
数据文件是Apache Iceberg表真实存储数据的文件,一般是在表的数据存储目录的data目录下,如果我们的文件格式选择的是parquet,那么文件是以“.parquet”结尾,例如:
00000-0-root_20211212192602_8036d31b-9598-4e30-8e67-ce6c39f034da-job_1639237002345_0025-00001.parquet 就是一个数据文件。
Iceberg每次更新会产生多个数据文件(data files)。
- Snapshot(表快照):
快照代表一张表在某个时刻的状态。每个快照里面会列出表在某个时刻的所有 data files 列表。data files是存储在不同的manifest files里面,manifest files是存储在一个Manifest list文件里面,而一个Manifest list文件代表一个快照。
- Manifest list(清单列表):
manifest list是一个元数据文件,它列出构建表快照(Snapshot)的清单(Manifest file)。这个元数据文件中存储的是Manifest file列表,每个Manifest file占据一行。每行中存储了Manifest file的路径、其存储的数据文件(data files)的分区范围,增加了几个数文件、删除了几个数据文件等信息,这些信息可以用来在查询时提供过滤,加快速度。
- Manifest file(清单文件):
Manifest file也是一个元数据文件,它列出组成快照(snapshot)的数据文件(data files)的列表信息。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据行数等信息。其中列级别的统计信息可以在扫描表数据时过滤掉不必要的文件。
Manifest file是以avro格式进行存储的,以“.avro”后缀结尾,例如:8138fce4-40f7-41d7-82a5-922274d2abba-m0.avro。
1.3.2 表格式Table Format
Apache Iceberg作为一款数据湖解决方案,是一种用于大型分析数据集的开放表格式(Table Format),表格式可以理解为元数据及数据文件的一种组织方式。Iceberg底层数据存储可以对接HDFS,S3文件系统,并支持多种文件格式,处于计算框架(Spark、Flink)之下,数据文件之上。
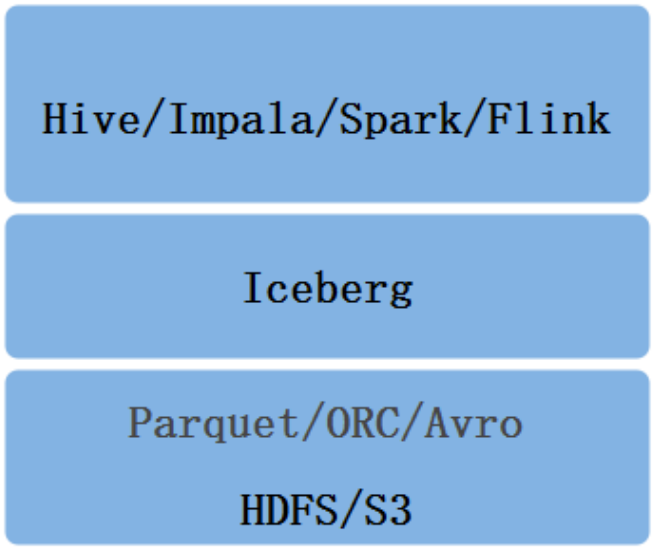
下面介绍下Iceberg底层文件组织方式,下图是Iceberg中表格式,s0、s1代表的是表Snapshot信息,每个表示当前操作的一个快照,每次commit都会生成一个快照Snapshot,每个Snapshot快照对应一个manifest list 元数据文件,每个manifest list 中包含多个Manifest元数据文件,manifest中记录了当前操作生成数据所对应的文件地址,也就是data file的地址。
基于snapshot的管理方式,Iceberg能够获取表历史版本数据、对表增量读取操作,data files存储支持不同的文件格式,目前支持parquet、ORC、Avro格式。
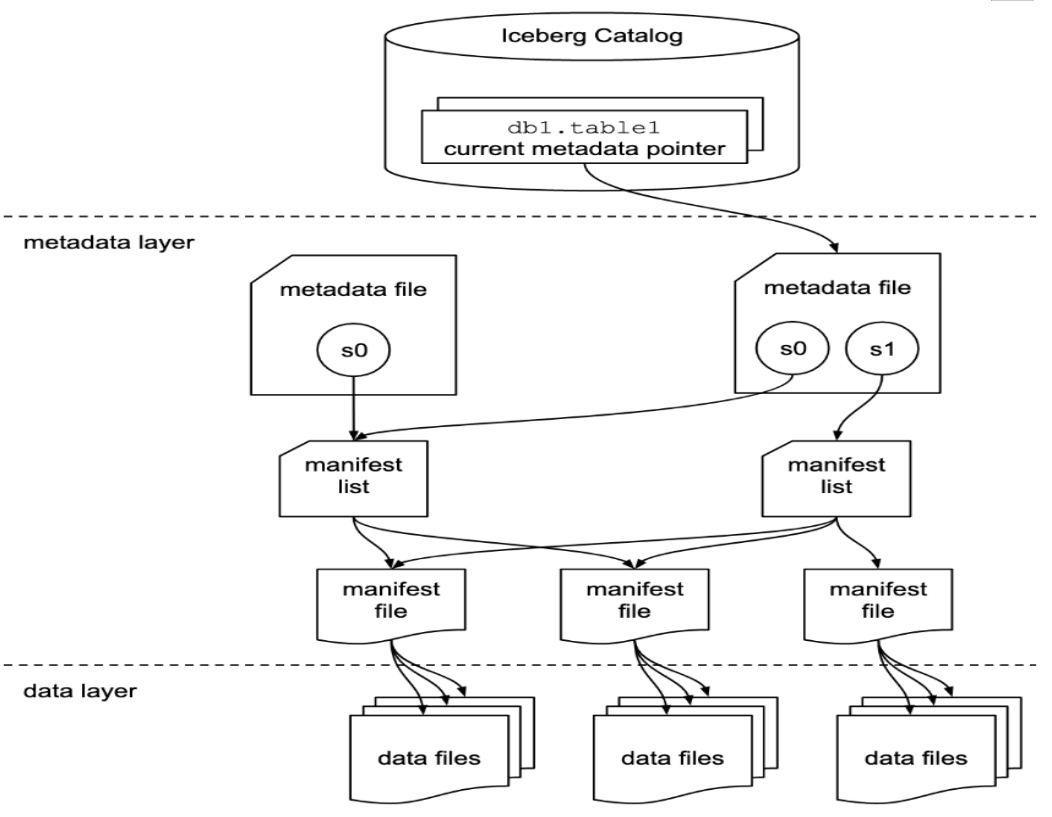
关于Iceberg表数据底层组织详细信息参照“Iceberg表数据组织与查询”小节。
1.4 Iceberg特点详述
1.4.1 Iceberg分区与隐藏分区(Hidden Partition)
Iceberg支持分区来加快数据查询。在Iceberg中设置分区后,可以在写入数据时将相似的行分组,在查询时加快查询速度。Iceberg中可以按照年、月、日和小时粒度划分时间戳组织分区。
在Hive中也支持分区,但是要想使分区能加快查询速度,需要在写SQL时指定对应的分区条件过滤数据,在Iceberg中写SQL查询时不需要再SQL中特别指定分区过滤条件,Iceberg会自动分区,过滤掉不需要的数据。
在Iceberg中分区信息可以被隐藏起来,Iceberg的分区字段可以通过一个字段计算出来,在建表或者修改分区策略之后,新的数据会自动计算所属于的分区,在查询的时候同样不用关心表的分区是什么字段,只需要关注业务逻辑,Iceberg会自动过滤不需要的分区数据。
正是由于Iceberg的分区信息和表数据存储目录是独立的,使得Iceberg的表分区可以被修改,而且不会涉及到数据迁移。
1.4.2 Iceberg表演化(Table Evolution)
在Hive分区表中,如果把一个按照天分区的表改成按小时分区,那么没有办法在原有表上进行修改,需要创建一个按照小时分区的表,然后把数据加载到此表中。
Iceberg支持就地表演化,可以通过SQL的方式进行表级别模式演进,例如:更改表分区布局。Iceberg进行以上操作时,代价极低,不存在读出数据重新写入或者迁移数据这种费时费力的操作。
1.4.3 模式演化(Schema Evolution)
Iceberg支持以下几种Schema的演化:
- ADD:向表或者嵌套结构增加新列。
- Drop:从表或嵌套结构中移除列。
- Rename:重命名表中或者嵌套结构中的列。
- Update:将复杂结构(Struct、Map<Key,Value>,list)中的基本类型扩展类型长度,比如:tinyint修改成int。
- Reorder:改变列的顺序,也可以改变嵌套结构中字段的排序顺序。
注意:
Iceberg Schema的改变只是元数据的操作改变,不会涉及到重写数据文件。Map结构类型不支持Add和Drop字段。
Iceberg保证Schema演化是没有副作用的独立操作,不会涉及到重写数据文件,具体如下:
- 增加列时不会从另一个列中读取已存在的数据
- 删除列或者嵌套结构中的字段时,不会改变任何其他列的值。
- 更新列或者嵌套结构中字段时,不会改变任何其他列的值。
- 改变列或者嵌套结构中字段顺序的时候,不会改变相关联的值。
Iceberg实现以上的原因使用唯一的id来追踪表中的每一列,当添加一个列时,会分配新的ID,因此列对应的数据不会被错误使用。
1.4.4 分区演化(partition Evolution)
Iceberg分区可以在现有表中更新,因为Iceberg查询流程并不和分区信息直接关联。
当我们改变一个表的分区策略时, 对应修改分区之前的数据不会改变, 依然会采用老的分区策略, 新的数据会采用新的分区策略, 也就是说同一个表会有两种分区策略, 旧数据采用旧分区策略, 新数据采用新新分区策略, 在元数据里两个分区策略相互独立,不重合.
因此,在我们写SQL进行数据查询时, 如果存在跨分区策略的情况, 则会解析成两个不同执行计划, 如Iceberg官网提供图所示:
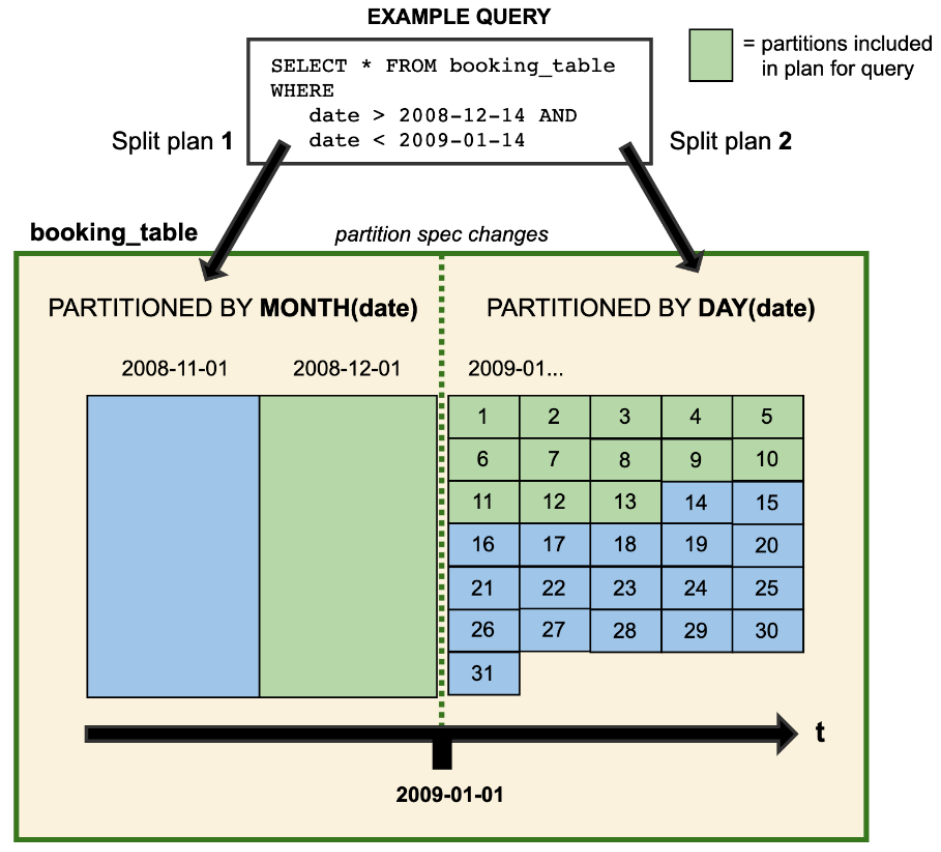
图中booking_table表2008年按月分区, 进入2009年后改为按天分区, 这两中分区策略共存于该表中。得益于Iceberg的隐藏分区(Hidden Partition), 针对上图中的SQL查询, 不需要在SQL中特别指定分区过滤条件(是按照月还是按照天), Iceberg会自动分区, 过滤掉不需要的数据。
1.4.5 列顺序演化(Sort Order Evolution)
Iceberg可以在一个已经存在的表上修改排序策略。修改了排序策略之后, 旧数据依旧采用老排序策略不变。往Iceberg里写数据的计算引擎总是会选择最新的排序策略, 但是当排序的代价极其高昂的时候, 就不进行排序了。
1.5 Iceberg数据类型
Iceberg表支持以下数据类型:
| 类型 | 描述 | 注意点 |
|---|---|---|
| boolean | 布尔类型,true或者false | |
| int | 32位有符号整形 | 可以转换成long类型 |
| long | 64位有符号整形 | |
| float | 单精度浮点型 | 可以转换成double类型 |
| double | 双精度浮点型 | |
| decimal(P,S) | decimal(P,S) | P代表精度,决定总位数,S代表规模,决定小数位数。P必须小于等于38。 |
| date | 日期,不含时间和时区 | |
| time | 时间,不含日期和时区 | 以微秒存储,1000微秒 = 1毫秒 |
| timestamp | 不含时区的timestamp | 以微秒存储,1000微秒 = 1毫秒 |
| timestamptz | 含时区的timestamp | 以微秒存储,1000微秒 = 1毫秒 |
| string | 任意长度的字符串类型 | UTF-8编码 |
| fixed(L) | 长度为L的固定长度字节数组 | |
| binary | 任意长度的字节数组 | |
| struct<...> | 任意数据类型组成的一个结构化字段 | |
list <E> |
任意数据类型组成的List | |
| map<K,V> | 任意类型组成的K,V的Map |