转载于:oracle之检查点(Checkpoint) - 张冲andy - 博客园 (cnblogs.com)
检查点是一个数据库事件,它把修改数据从高速缓存写入磁盘,并更新控制文件和数据文件。
检查点分为三类:
1)局部检查点:单个实例执行数据库所有数据文件的一个检查点操作,属于此实例的全部脏缓存区写入数据文件。
触发命令:
svmrgrl>alter system checkpoint local;
这条命令显示的触发一个局部检查点。
2)全局检查点:所有实例(对应并行数据服务器)执行数据库所有所有数据文件的一个检查点操作,属于此实例的全部脏缓存区写入数据文件。
触发命令
svrmgrl>alter system checkpoint global;
这条命令显示的触发一个全局检查点。
3)文件检查点:所有实例需要执行数据文件集的一个检查点操作,如使用热备份命令alter tablespace USERS begin backup,或表空间脱机命令alter tablespace USERS offline,将执行属于USERS表空间的所有数据文件的一个检查点操作。
检查点处理步骤:
1)获取实例状态队列:实例状态队列是在实例状态转变时获得,ORACLE获得此队列以保证检查点执行期间,数据库处于打开状态;
2)获取当前检查点信息:获取检查点记录信息的结构,此结构包括当前检查点时间、活动线程、进行检查点处理的当前线程、日志文件中恢复截止点的地址信息;
3)缓存区标识:标识所有脏缓存区,当检查点找到一个脏缓存区就将其标识为需进行刷新,标识的脏缓存区由系统进程DBWR进行写操作,将脏缓存区的内容写入数据文件;
4)脏缓存区刷新:DBWR进程将所有脏缓存区写入磁盘后,设置一标志,标识已完成脏缓存区至磁盘的写入操作。系统进程LGWR与CKPT进程将继续进行检查,直至DBWR进程结束为止;
5)更新控制文件与数据文件。
注:控制文件与数据文件头包含检查点结构信息。
在两种情况下,文件头中的检查点信息(获取当前检查点信息时)将不做更新:
1)数据文件不处于热备份方式,此时ORACLE将不知道操作系统将何时读文件头,而备份拷贝在拷贝开始时必须具有检查点SCN;
ORACLE在数据文件头中保留一个检查点的记数器,在正常操作中保证使用数据文件的当前版本,在恢复时防止恢复数据文件的错误版本;即使在热备份方式下,计数器依然是递增的;每个数据文件的检查点计数器,也保留在控制文件相对应数据文件项中。
2)检查SCN小于文件头中的检查点SCN的时候,这表明由检查点产生的改动已经写到磁盘上,在执行全局检查点的处理过程中,如果一个热备份快速检查点在更新文件头时,则可能发生此种情况。应该注意的是,ORACLE是在实际进行检查点处理的大量工作之前捕获检查SCN的,并且很有可能被一条象热备份命令alter tablespace USERS begin backup进行快速检查点处理时的命令打断。
ORACLE在进行数据文件更新之前,将验证其数据一致性,当验证完成,即更新数据文件头以反映当前检查点的情况;未经验证的数据文件与写入时出现错误的数据文件都被忽略;如果日志文件被覆盖,则这个文件可能需要进行介质恢复,在这种情况下,ORACLE系统进程DBWR将此数据文件脱机。
检 查点算法描述:
脏缓存区用一个新队列链接,称为检查点队列。对缓存区的每一个改动,都有一个与其相关的重做值。检查点队列包含脏的日志缓存区,这些缓存区按照它们在日志文件中的位置排序,即在检查点队列中,缓存区按照它们的低重做值进行排序。需要注意的是,由于缓存区是依照第一次变脏的次序链接到队列中的,所以,如果在缓存区写出之前对它有另外的改动,链接不能进行相应变更,缓存区一旦被链接到检查点队列,它就停留在此位置,直到将它被写出为止。
ORACLE系统进程DBWR在响应检查点请求时,按照这个队列的低重做值的升序写出缓存区。每个检查点请求指定一个重做值,一旦DBWR写出的缓存区重做值等于或大雨检查点的重做值,检查点处理即完成,并将记录到控制文件与数据文件。
由于检查点队列上的缓存区按照低重做值进行排序,而DBWR也按照低重做值顺序写出检查点缓存区,故可能有多个检查点请求处于活动状态,当DBWR写出缓存区时,检查位于检查点队列前端的缓存区重做值与检查点重做值的一致性,如果重做值小于检查点队列前缓存区的低重做值的所有检查点请求,即可表示处理完成。当存在未完成的活动检查点请求时,DBWR继续写出检查点缓存区。
算法特点:
1)DBWR能确切的知道为满足检查点请求需要写那些缓存区;
2)在每次进行检查点写时保证指向完成最早的(具有最低重做值的)检查点;
3)根据检查点重做值可以区别多个检查点请求,然后按照它们的顺序完成处理。
1.检查点(Checkpoint)的本质
许多文档把Checkpint描述得非常复杂,为我们正确理解检查点带来了障碍,结果现在检查点变成了一个非常复杂的问题。实际上,检查点只是一个数据库事件,它存在的根本意义在于减少崩溃恢复(Crash Recovery)时间。
当修改数据时,需要首先将数据读入内存中(Buffer Cache),修改数据的同时,Oracle会记录重做信息(Redo)用于恢复。因为有了重做信息的存在,Oracle不需要在提交时立即将变化的数据写回磁盘(立即写的效率会很低),重做(Redo)的存在也正是为了在数据库崩溃之后,数据就可以恢复。
最常见的情况,数据库可以因为断电而Crash,那么内存中修改过的、尚未写入文件的数据将会丢失。在下一次数据库启动之后,Oracle可以通过重做日志(Redo)进行事务重演,也就是进行前滚,将数据库恢复到崩溃之前的状态,然后数据库可以打开提供使用,之后Oracle可以将未提交的数据进行回滚。
在这个过程中,通常大家最关心的是数据库要经历多久才能打开。也就是需要读取多少重做日志才能完成前滚。当然用户希望这个时间越短越好,Oracle也正是通过各种手段在不断优化这个过程,缩短恢复时间。
检查点的存在就是为了缩短这个恢复时间。
当检查点发生时(此时的SCN被称为CheckPoint SCN),Oracle会通知DBWR进程,把修改过的数据,也就是Checkpoint SCN之前的脏数据(Dirty Data)从Buffer Cache写入磁盘,当写入完成之后,CKPT进程更新控制文件和数据文件头,记录检查点信息,标识变更。
Oracle SCN的相关知识可以参考我的另外一篇文章:DBA入门之认识Oracle SCN(System Change Number)
Checkpoint SCN可以从数据库中查询得到:
 SQL> select file#,CHECKPOINT_CHANGE#,to_char(CHECKPOINT_TIME,'yyyy-mm-dd hh24:mi:ss') cpt from v$datafile;
SQL> select file#,CHECKPOINT_CHANGE#,to_char(CHECKPOINT_TIME,'yyyy-mm-dd hh24:mi:ss') cpt from v$datafile;FILE# CHECKPOINT_CHANGE# CPT
---------- ------------------ -------------------
1 913306 2011-11-16 16:06:06
2 913306 2011-11-16 16:06:06
3 913306 2011-11-16 16:06:06
4 913306 2011-11-16 16:06:06
SQL> select dbid,CHECKPOINT_CHANGE# from v$database;
DBID CHECKPOINT_CHANGE#
---------- ------------------
1294662348 913306
在检查点完成之后,此检查点之前修改过的数据都已经写回磁盘,重做日志文件中的相应重做记录对于崩溃/实例恢复不再有用。
下图标记了3个日志组,假定在T1时间点,数据库完成并记录了最后一次检查点,在T2时刻数据库Crash。那么在下次数据库启动时,T1时间点之前的Redo不再需要进行恢复,Oracle需要重新应用的就是时间点T1至T2之间数据库生成的重做日志(Redo)。
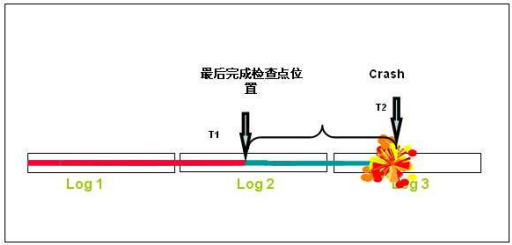
上图可以很轻易地看出来,检查点的频率对于数据库的恢复时间具有极大的影响,如果检查点的频率高,那么恢复时需要应用的重做日志就相对得少,检查时间就可以缩短。然而,需要注意的是,数据库内部操作的相对性极强,国语平凡的检查点同样会带来性能问题,尤其是更新频繁的数据库。所以数据库的优化是一个系统工程,不能草率。
更进一步可以知道,如果Oracle可以在性能允许的情况下,使得检查点的SCN主键逼近Redo的最新更新,那么最终可以获得一个最佳平衡点,使得Oracle可以最大化地减少恢复时间。
为了实现这个目标,Oracle在不同版本中一直在改进检查点的算法。
2.常规检查点与增量检查点
为了区分,在Oracle8之前,Oracle实时的检查点通常被称为常规检查点(Conventional Checkpoint),这类检查点按一定的条件出发(log_checkpoint_interval、log_checkpoint_timeout参数设置及log switch等条件出发)。
从Oracle 8开始,Oracle引入了增量检查点(Inctrmental Checkpoint)的概念。
和以前的版本相比,在新版本中,Oracle主要引入了检查点队列(Checkpoinnt Queue)机制,在数据库内部,每一个脏数据块都会被移动到检查点队列,按照Low RBA的顺序(第一次对比数据块修改对应的Redo Byte Address)来排列,如果一个数据块进行过多次修改,该数据库在检查点队列上的顺序并不会发生变化。
当执行检查点时,DBWR从检查点队列按照Low RBA的顺序写出,实例检查点因此可以不断增进、阶段性的,CKPT进程使用非常轻量级的控制文件更新协议,将当前的最低RBA写入控制文件。
因为增量检查点可以连续地进行,因此检查点RBA可以比常规检查点更接近数据库的最后状态,从而在数据库的实例恢复中可以极大地减少恢复时间。
而且,通过增量检查点,DBWR可以持续进行写出,从而避免了常规检查点出发的峰值写入对于I/O的国度征用,通过下图可以清楚地看到这一改进的意义。

在数据库中,增量检查点是通过Fast-Start Checkpointing特性来实现的,从Oracle 8i开始,这一特性包含了Oracle企业版的Fast-Start Fault Recovery组件之中,通过查询v$option视图,了解这一特性:
SQL> select * from v$version where rownum<2;BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 – Prod
SQL> col parameter for a30
SQL> col value for a20
SQL> select * from V$option where Parameter='Fast-Start Fault Recovery';
PARAMETER VALUE
------------------------------ --------------------
Fast-Start Fault Recovery TRUE
该组件包含3个主要特性,可以加快系统在故障后的恢复,提高系统的可用性。
Fast-Start Checkpointing;
Fast-Start On-Demand Rollback;
Fast-Start Parallel Rollback;
Fast-Start Checkpointing 特性在Oracle 8i中主要通过参数FAST_START_IO_TARGET来实现,在Oracle 9i中,Fast-Start Checkpointing主要通过参数FAST_START_MTTR_TARGET来实现。
3.FAST_START_MTTR_TARGET
FAST_START_MTTR_TARGET参数从Oracle 9i开始被引入,该参数定义数据库进行Crash恢复的时间,单位是秒,取值范围是在0~3600秒之间。
在Oracle 9i中,Oracle推荐设置这个参数代替FAST_START_IO_TARGE、LOG_CHECKPOINT_TIMEROUT及LOG_CHECKPOINT_INSTERVAL参数。
缺省情况下,在Oracle 9i中,FAST_START_IO_TARGET和LOG_CHECKPOINT_INTERVAL参数已经被设置为0.
SQL> show parameter fast_start_ioNAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fast_start_io_target integer 0
SQL> show parameter interval
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_checkpoint_interval integer 0
在Oracle 9i R2开始,Oracle引入了一个新的视图提供MTTR建议:
SQL> select * from v$mttr_target_advice;MTTR_TARGET_FOR_ESTIMATE ADVICE_STATUS DIRTY_LIMIT ESTD_CACHE_WRITES ESTD_CACHE_WRITE_FACTOR ESTD_TOTAL_WRITES ESTD_TOTAL_WRITE_FACTOR ESTD_TOTAL_IOS ESTD_TOTAL_IO_FACTOR
------------------------ ------------- ----------- ----------------- ----------------------- ----------------- ----------------------- -------------- --------------------
该视图评估在不同FAST_START_MATTR_TARGET设置下,系统需要执行的I/O次数等操作。用户可以根据数据库的建议,对FAST_START_MTTR_TARGET进行相应调整。
这个建议信息的手机收到Oracle 9i新引入的初始化参数statistics_level的控制,当该参数设置为Typical或ALL时,MTTR建议信息被手机:
SQL> show parameter statistics_levelNAME TYPE VALUE
------------------------------------ ----------- ------------------------------
statistics_level string TYPICAL
也可以通过v$statistics_level视图来查询MTTR_Advice的当前设置:
SQL> select * from v$statistics_level where STATISTICS_NAME='MTTR Advice';STATISTICS_NAME DESCRIPTION SESSION_STATUS SYSTEM_STATUS ACTIVATION_LEVEL STATISTICS_VIEW_NAME SESSION_SETTABLE
---------------------------------------------------------------- -------------------------------------------------------------------------------- -------------- ------------- ---------------- ---------------------------------------------------------------- ----------------
MTTR Advice Predicts the impact of different MTTR settings on number of physical I/Os ENABLED ENABLED TYPICAL V$MTTR_TARGET_ADVICE NO
数据库当前的实例恢复状态可以通过视图v$instance_recovery查询得到:
SQL> select * from v$instance_recovery;RECOVERY_ESTIMATED_IOS 53
ACTUAL_REDO_BLKS 376
TARGET_REDO_BLKS 184320
LOG_FILE_SIZE_REDO_BLKS 184320
LOG_CHKPT_TIMEOUT_REDO_BLKS
LOG_CHKPT_INTERVAL_REDO_BLKS
FAST_START_IO_TARGET_REDO_BLKS
TARGET_MTTR 0
ESTIMATED_MTTR 18
CKPT_BLOCK_WRITES 27
OPTIMAL_LOGFILE_SIZE
ESTD_CLUSTER_AVAILABLE_TIME
WRITES_MTTR 0
WRITES_LOGFILE_SIZE 0
WRITES_LOG_CHECKPOINT_SETTINGS 0
WRITES_OTHER_SETTINGS 0
WRITES_AUTOTUNE 104
WRITES_FULL_THREAD_CKPT 0
从v$instance_recovery视图,可以看到当前数据库估计的平均恢复时间(MTTR)参数:ESTIMATED_MTTR。
ESTIMATED_MTTR的估算值是基于Dirty Buffer 的数据量和日志块数量得出的,这个参数值告诉我们,如果此时数据库本亏,那么进行实例恢复将会需要的时间。
在V$instance_revovery视图中,TARGET_MTTR代表的是期望的恢复时间,通常改参数应该等于FAST_START_MTTR_TARGET参数设置值(但是如果FAST_START_MTTR_TARGET参数定义的值极大或极小,TARGET_MEER可能不等于FAST_START_MTTR_TARGET的设置)。
当ESTIMATED_MTTR接近或超过FAST_START_MTTR_TARGET参数设置(v$instance_recovery TARGET_MTTR)时,系统就会促发检查点,执行写出之后,系统恢复信息将会重新计算:
 View Code
View Code
在繁忙的系统中,可能会观察到ESTIMATED_MTTR>TARGET_MTTR,这可能是因为DBWR正忙于写出,甚或出现Checkpoint不能及时完成的情况。
4. Oracle 10g自动检查点调整
从Oracle 10g开始,数据库可以实现自动调整的检查点,使用自动调整的检查点,Oracle数据库可以利用系统的低I/O负载时段写出内存中的脏数据,从而提高数据库的效率。因此,及时数据库管理员设置了不合理的检查点相关参数,Oracle仍然能够通过自动调整将数据库的Crash Recovery时间控制在合理的范围之内。
当FAST_START_MTTR_TARGET参数未设置,自动检查点调整生效。
通常,如果必须严格控制实例或节点恢复时间,那么可以设置FAST_START_MTTR_TARGET为期望时间值;如果恢复时间不严格控制,那么可以不设置FAST_START_MTTR_TARGET参数,从而启用Oracle 10g的自动调整特性。
当取消FAST_START_MTTR_TARGET参数设置之后:
View Code
在启动数据库的时候,可以从alter文件中看到如下信息:
View Code
检查v$instance_recovery视图,可以发现Oracle 10g的改变:
View Code
在以上视图中,WRITES_AUTOTUNE字段数据就是指由于自动调整检查点执行的写出次数,而CK_BLOCK_WRITES指的则是由于检查点写出的Block的数量。
关于检查点的机制问题,我们侧重介绍了原理,至于具体的算法实现,不需要去追究过多,只要明白了这个原理性的规则,理解Oracle就会变成轻松的事情。
Oracle的算法改进是一种优化,对于数据库的调整优化也不外如此,借鉴Oracle的优化对于理解和优化Oracle数据库都具有极大的好处。
5.从控制文件获取检查点信息
在控制文件的转储中,可以看到关于检查点进程进度的记录:
View Code
这里的low cache rba(Revovery block address)指在Cache中,最低的RBA地址,在实例恢复或者崩溃恢复中,需要从这里开始恢复。
On disk dba是磁盘上的最高的重做值,在进行恢复时应用重做至少要达到这个值。
除了检查点队列(CKPTQ)之外,数据库中还存在另外一个队列和检查点有关,这就是文件检查点队列(FILE QUEUE),通常称为FILEQ,文件检查点的引入提供了表空间相关的检查点的性能。每个Dirty Buffer同时链接到这两个队列,CKPTQ包含实例所有需要执行检查点的Buffer,FILEQ包含属于特定文件需要执行的检查点Buffer,每个文件都包含一个文件队列,在执行表空间检查点请求时需要使用FILEQ,通常当对表空间执行Offline等操作时会触发表空间检查点。CKPTQ和FILEQ都是双向链表,每个队列中都记录了两个地址信息,分别是前一块和下一块Buffer的地址信息。注意只有Dirty Buffer才会包含CKPTQ信息,否则为NULL,信息类似"ckptq:[NULL]fileq:[NULL]"。
检查点(checkpoint)的工作机制
检查点是一个数据库事件,它把修改数据从高速缓存写入磁盘,并更新控制文件和数据文件,总结起来如下:
检查点分为三类:
1)局部检查点:单个实例执行数据库所有数据文件的一个检查点操作,属于此实例的全部脏缓存区写入数据文件。
触发命令:
svmrgrl>alter system checkpoint local;
这条命令显示的触发一个局部检查点。
2)全局检查点:所有实例(对应并行数据服务器)执行数据库所有所有数据文件的一个检查点操作,属于此实例的全部脏缓存区写入数据文件。
触发命令
svrmgrl>alter system checkpoint global;
这条命令显示的触发一个全局检查点。
3)文件检查点:所有实例需要执行数据文件集的一个检查点操作,如使用热备份命令alter tablespace USERS begin backup,或表空间脱机命令alter tablespace USERS offline,将执行属于USERS表空间的所有数据文件的一个检查点操作。
检查点处理步骤:
1)获取实例状态队列:实例状态队列是在实例状态转变时获得,ORACLE获得此队列以保证检查点执行期间,数据库处于打开状态;
2)获取当前检查点信息:获取检查点记录信息的结构,此结构包括当前检查点时间、活动线程、进行检查点处理的当前线程、日志文件中恢复截止点的地址信息;
3)缓存区标识:当数据在buffer cache中做了修改之后会自动被为脏缓冲区,加入到Checkpoint Queue的脏缓冲区队列。
4)脏缓存区刷新:当检查点发生时,会到CKPTQ中的脏缓冲区队列找到到目前为止最大的LRBA,并通知DBWR进程将所有脏缓存区写入磁盘,完成之后设置一标志,标识已完成脏缓存区至磁盘的写入操作,以便刷新脏缓冲队列(此时DML可以继续进行)。系统进程LGWR与CKPT进程将继续进行检查,直至DBWR进程结束为止;
5)更新控制文件与数据文件。
注:控制文件与数据文件头包含检查点结构信息。
在两种情况下,文件头中的检查点信息(获取当前检查点信息时)将不做更新:
1)数据文件不处于热备份方式,此时ORACLE将不知道操作系统将何时读文件头,而备份拷贝在拷贝开始时必须具有检查点SCN;
ORACLE在数据文件头中保留一个检查点的记数器,在正常操作中保证使用数据文件的当前版本,在恢复时防止恢复数据文件的错误版本;即使在热备份方式下,计数器依然是递增的;每个数据文件的检查点计数器,也保留在控制文件相对应数据文件项中。
2)检查SCN小于文件头中的检查点SCN的时候,这表明由检查点产生的改动已经写到磁盘上,在执行全局检查点的处理过程中,如果一个热备份快速检查点在更新文件头时,则可能发生此种情况。应该注意的是,ORACLE是在实际进行检查点处理的大量工作之前捕获检查SCN的,并且很有可能被一条象热备份命令
alter tablespace USERS begin backup进行快速检查点处理时的命令打断。
ORACLE在进行数据文件更新之前,将验证其数据一致性,当验证完成,即更新数据文件头以反映当前检查点的情况;未经验证的数据文件与写入时出现错误的数据文件都被忽略;如果日志文件被覆盖,则这个文件可能需要进行介质恢复,在这种情况下,ORACLE系统进程DBWR将此数据文件脱机。
检查点算法描述:
脏缓存区用一个新队列链接,称为检查点队列。对缓存区的每一个改动,都有一个与其相关的重做值。检查点队列包含脏的日志缓存区,这些缓存区按照它们在日志文件中的位置排序,即在检查点队列中,缓存区按照它们的LRBA进行排序。需要注算法特点:
3)根据检查点重做值可以区别多个检查点请求,然后按照它们的顺序完成处理。
1)DBWR能确切的知道为满足检查点请求需要写那些缓存区;
2)在每次进行检查点写时保证指向完成最早的(具有最低重做值的)检查点;意的是,由于缓存区是依照第一次变脏的次序链接到队列中的,所以,如果在缓存区写出之前对它有另外的改动,链接不能进行相应变更,缓存区一旦被链接到检查点队列,它就停留在此位置,直到将它被写出为止。
ORACLE系统进程DBWR在响应检查点请求时,按照这个队列的LRBA的升序写出缓存区。每个检查点请求指定一个重做值,一旦DBWR写出的缓存区重做值等于或大雨检查点的重做值,检查点处理即完成,并将记录到控制文件与数据文件。
由于检查点队列上的缓存区按照低重做值进行排序,而DBWR也按照低重做值顺序写出检查点缓存区,故可能有多个检查点请求处于活动状态,当DBWR写出缓存区时,检查位于检查点队列前端的缓存区重做值与检查点重做值的一致性,如果重做值小于检查点队列前缓存区的低重做值的所有检查点请求,即可表示处理完成。当存在未完成的活动检查点请求时,DBWR继续写出检查点缓存区。 转:http://www.cnblogs.com/Ronger/archive/2011/12/09/2281650.html 文章可以转载,必须以链接形式标明出处。 标签:缓存,数据文件,队列,数据库,Checkpoint,Oracle,检查点,oracle From: https://www.cnblogs.com/shuihaya/p/17292114.html