1. 算法简介
树链剖分为将树分割成若干条链,维护树上信息的思想。通常将其分为链后能用数据结构维护。
树链剖分分为重链剖分,长链剖分,实链剖分。通常重链剖分最常用,本文主要介绍重链剖分。
重链剖分可将树划分为一个个长度不超过 \(O(\log n)\) 的链,并且保证每条链内的 \(dfs\) 序是连续的。这样就可以用线性数据结构维护树内的信息了。
比如:
- 动态修改树的节点(边)权值,路径信息,子树信息;
- 查询树上路径信息,子树信息;
- 求解 \(LCA\);
2. 算法实现
给出一些定义:
- 重儿子:表示在该节点中子树最大的子节点(若有多个重儿子,选其一)。
- 轻儿子:表示在该节点中不是重儿子的子节点。
- 重边:与重儿子相连的边;
- 轻边:与轻儿子相连的边;
- 重链:由若干重边组成的链;
- 链顶:树链中节点深度最小的节点编号,链顶节点与其父节点的连边为轻边,根节点一定为链顶节点;
给出一些需要维护的数据:
- \(fa_x\) 表示 \(x\) 的父节点;
- \(siz_x\) 表示 \(x\) 的子树大小;
- \(dep_x\) 表示 \(x\) 的节点深度;
- \(dfn_x\) 表示节点 \(x\) 对应的 \(dfs\) 序;
- \(id_x\) 表示 \(dfs\) 序 \(x\) 对应的节点编号;
- \(son_x\) 表示节点 \(x\) 的重儿子编号;
- \(top_x\) 表示节点 \(x\) 所在链的链顶节点的编号;
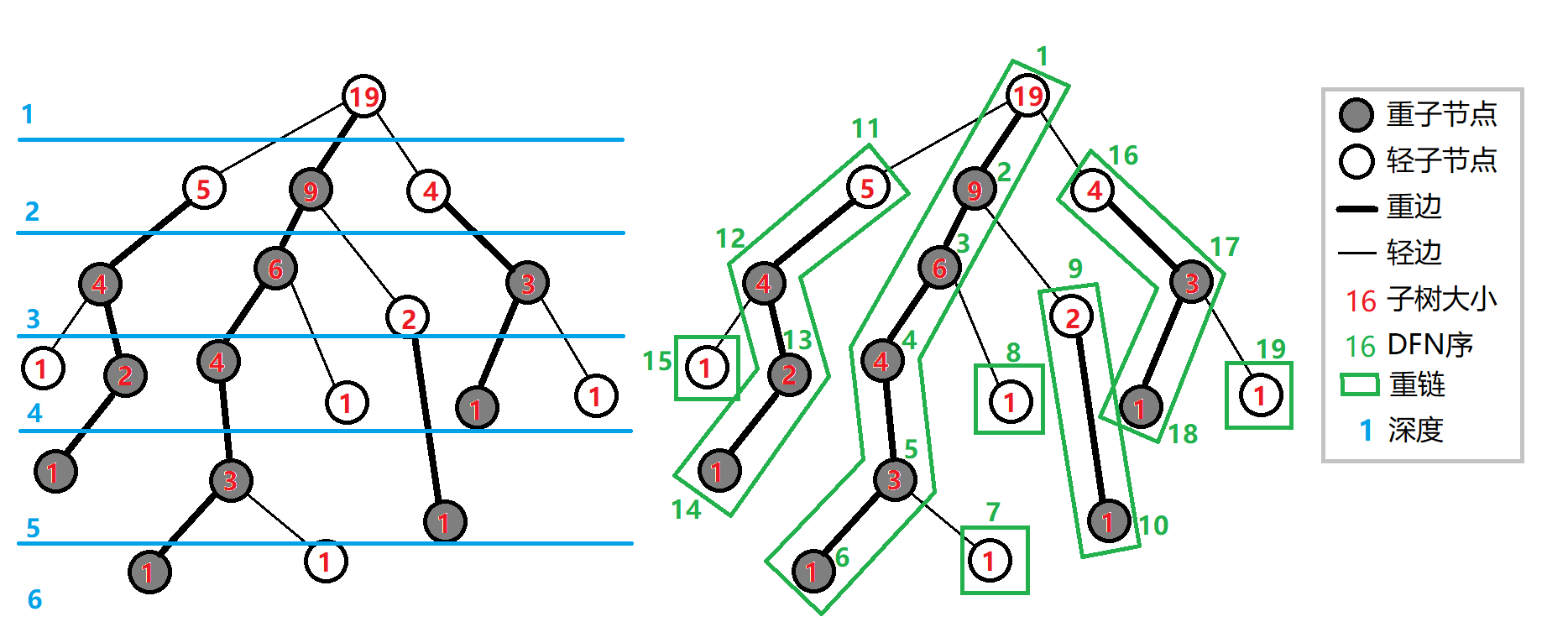
通过两边 \(dfs\) 维护出上述信息:
第一遍 \(dfs\) 维护出树的 \(fa,siz,dep,son\) 的信息。
void dfs(int x, int f) {
dep[x] = dep[f] + 1, siz[x] = 1;
fa[x] = f;
int maxi = 0;
for (int i = h[x]; i; i = e[i].nx) {
int y = e[i].v;
if(y == fa[x]) continue;
w[y] = e[i].w;
s[y] = s[x] ^ w[y];
dfs(y, x);
siz[x] += siz[y];
if(maxi < siz[y]) {
maxi = siz[y];
son[x] = y;
}
}
}
第二遍 \(dfs\) 优先走重儿子,再走轻儿子,并在期间依次定 \(dfn,id\),并更新 \(top\) 的信息。
void dfs1(int x, int tp) {
top[x] = tp;
dfn[x] = ++idx;
id[idx] = x;
if(son[x]) dfs1(son[x], tp);
for (int i = h[x]; i; i = e[i].nx) {
int y = e[i].v;
if(y == fa[x] || y == son[x]) continue;
dfs1(y, y);
}
}
走重儿子的时候链顶节点为原链顶节点,而走轻儿子的时候由于会重新划分一条链,所以将链顶节点信息 \(tp\) 更新为子节点后再进行遍历。最后遍历得到的 \(dfs\) 序在一条链内一定为连续的。并且保证树上每个节点都属于且仅属于一条重链。
基于此性质,可以使用线性数据结构将树上路径转化为区间,并进行相应的操作。
可以发现,每一次向下经过一条轻边时,所在子树大小会至少减半。
所以,我们可以很快的胡出求解 \(LCA\) 的方法。
2.1 求 LCA
对于 \(u, v\),若它们所在的链顶为同一个,即它们在同一条链中,则 \(LCA(u,v)\) 为深度较小的那个节点。
否则,我们需要让它们跳到同一个链中去。先比较当前的 \(dep_{top_u}\) 与 \(dep_{top_v}\),肯定是将所在链顶更深的那个节点跳到链顶,再跳出本链到达更浅链。如此往复直到它们在同一条链内。
int lca(int u, int v) {
while(top[u] != top[v]) {
if(dep[top[u]] < dep[top[v]]) swap(u, v);
u = fa[top[u]];
}
if(dep[u] > dep[v]) swap(u, v);
return u;
}
2.2 路径修改/查询
和求解 \(LCA\) 类似,不过这次需要维护路径的信息。于是在跳链顶的父节点之前对本链的贡献进行修改:
- 未在同一条链中时,在数据结构中修改区间 \([dfn_{top_x},dfn_x]\),因为保证了 \(dfn_{top_x}<dfn_x\);
- 在同一条链中,在数据结构中修改区间 \([dfn_v,dfn_x]\),前提要保证 \(dfn_v<dfn_x\);
void upd(int x, int y, int k) {
while(top[x] != top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x, y);
update(1, dfn[top[x]], dfn[x], k);
x = fa[top[x]];
}
if(dep[x] < dep[y]) swap(x, y);
update(1, dfn[y], dfn[x], k);
}
update函数为数据结构修改操作,以模版题为例,则为带标记的区间加。
修改操作同理:
int qry(int x, int y) {
int ans = 0;
while(top[x] != top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x, y);
ans = (ans % mod + query(1, dfn[top[x]], dfn[x]) % mod) % mod;
x = fa[top[x]];
}
if(dep[x] < dep[y]) swap(x, y);
ans = (ans % mod + query(1, dfn[y], dfn[x]) % mod) % mod;
return ans;
}
以模版题为例的区间加和,query函数为数据结构查询操作。
2.3 子树修改/查询
可以发现,子树内的 \(dfn\) 序是连续的,为 \([dfn_x,dfn_x+siz_x-1]\)。于是直接在数据结构上查询/修改 \([dfn_x,dfn_x+siz_x-1]\) 即可。
void Upd(int x, int k) {
update(1, dfn[x], dfn[x] + siz[x] - 1, k);
}
int Qry(int x) {
return query(1, dfn[x], dfn[x] + siz[x] - 1) % mod;
}
以上的所有的树上跳点操作均为 \(O(\log n)\),即单次求 \(LCA\) 为 \(O(\log n)\)。而套上数据结构维护树上信息,以线段树为例,则为 \(O(\log ^2 n)\)。但是由于树上跳点的 \(O(\log n)\) 常数很小,并且理论上限即为 \(\log n\) 严重跑不满。所以一般 \(n\le 5\times 10^5\) 是很稳定。
加上操作数 \(m\) 总时间复杂度为 \(O(m\log^2 n)\)。
P3384 【模板】重链剖分/树链剖分
将所有操作拼起来即可。
#include <bits/stdc++.h>
#define int long long
#define H 19260817
#define rint register int
#define For(i,l,r) for(rint i=l;i<=r;++i)
#define FOR(i,r,l) for(rint i=r;i>=l;--i)
#define MOD 1000003-
#define ls p<<1
#define rs p<<1|1
using namespace std;
namespace Read {
template <typename T>
inline void read(T &x) {
x=0;T f=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x*=f;
}
template <typename T, typename... Args>
inline void read(T &t, Args&... args) {
read(t), read(args...);
}
}
using namespace Read;
void print(int x){
if(x<0){putchar('-');x=-x;}
if(x>9){print(x/10);putchar(x%10+'0');}
else putchar(x+'0');
return;
}
const int N = 1e5 + 10;
struct Node {
int v, nx;
} e[N << 1];
struct Tree {
int l, r, val, add;
} t[N << 2];
int n, m, r, mod, h[N], tot, w[N], dep[N], fa[N], dfn[N], id[N], son[N], top[N], siz[N], idx;
void add(int u, int v) {
e[++tot] = (Node) {v, h[u]};
h[u] = tot;
}
void dfs(int x, int f) {
dep[x] = dep[f] + 1;
fa[x] = f, siz[x] = 1;
int maxi = -1;
for (int i = h[x]; i; i = e[i].nx) {
int y = e[i].v;
if(y == f) continue;
dfs(y, x);
siz[x] += siz[y];
if(maxi < siz[y]) {
maxi = siz[y];
son[x] = y;
}
}
}
void dfs1(int x, int tp) {
top[x] = tp;
dfn[x] = ++idx;
id[idx] = x;
if(son[x]) dfs1(son[x], tp);
for (int i = h[x]; i; i = e[i].nx) {
int y = e[i].v;
if(y == fa[x] || y == son[x]) continue;
dfs1(y, y);
}
}
void pushup(int p) {
t[p].val = (t[ls].val % mod + t[rs].val % mod) % mod;
}
void pushdown(int p) {
if(t[p].add) {
t[ls].val = (t[ls].val % mod + t[p].add * (t[ls].r - t[ls].l + 1) % mod) % mod;
t[rs].val = (t[rs].val % mod + t[p].add * (t[rs].r - t[rs].l + 1) % mod) % mod;
t[ls].add = (t[ls].add % mod + t[p].add % mod) % mod;
t[rs].add = (t[rs].add % mod + t[p].add % mod) % mod;
t[p].add = 0;
}
}
void build(int p, int l, int r) {
t[p].l = l, t[p].r = r;
if(l == r) {
t[p].val = w[id[l]] % mod;
return ;
}
int mid = (l + r) >> 1;
build(ls, l, mid);
build(rs, mid + 1, r);
pushup(p);
}
void update(int p, int l, int r, int k) {
if(l <= t[p].l && t[p].r <= r) {
t[p].val = (t[p].val % mod + k * (t[p].r - t[p].l + 1) % mod) % mod;
t[p].add = (t[p].add % mod + k % mod) % mod;
return ;
}
pushdown(p);
int mid = (t[p].l + t[p].r) >> 1;
if(l <= mid) update(ls, l, r, k);
if(r > mid) update(rs, l, r, k);
pushup(p);
}
int query(int p, int l, int r) {
if(l <= t[p].l && t[p].r <= r) {
return t[p].val % mod;
}
pushdown(p);
int mid = (t[p].l + t[p].r) >> 1, ans = 0;
if(l <= mid) ans = (ans + query(ls, l, r) % mod) % mod;
if(r > mid) ans = (ans + query(rs, l, r) % mod) % mod;
return ans;
}
void upd(int x, int y, int k) {
while(top[x] != top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x, y);
update(1, dfn[top[x]], dfn[x], k);
x = fa[top[x]];
}
if(dep[x] < dep[y]) swap(x, y);
update(1, dfn[y], dfn[x], k);
}
int qry(int x, int y) {
int ans = 0;
while(top[x] != top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x, y);
ans = (ans % mod + query(1, dfn[top[x]], dfn[x]) % mod) % mod;
x = fa[top[x]];
}
if(dep[x] < dep[y]) swap(x, y);
ans = (ans % mod + query(1, dfn[y], dfn[x]) % mod) % mod;
return ans;
}
void Upd(int x, int k) {
update(1, dfn[x], dfn[x] + siz[x] - 1, k);
}
int Qry(int x) {
return query(1, dfn[x], dfn[x] + siz[x] - 1) % mod;
}
signed main() {
read(n, m, r, mod);
For(i,1,n) read(w[i]);
For(i,1,n-1) {
int u, v;
read(u, v);
add(u, v);
add(v, u);
}
dfs(r, 0);
dfs1(r, r);
build(1, 1, n);
while(m--) {
int op, x, y, z;
read(op);
if(op == 1) {
read(x, y, z);
z %= mod;
upd(x, y, z);
} else if(op == 2) {
read(x, y);
cout << qry(x, y) << '\n';
} else if(op == 3) {
read(x, z);
z %= mod;
Upd(x, z);
} else {
read(x);
cout << Qry(x) << '\n';
}
}
return 0;
}
P4114 Qtree1
需要维护边权而不是点权,于是边权转点权维护即可。(边权打在深儿子上)。
细节注意的是转点权之后 \(u,v\) 的 \(LCA\) 的点权其实为 \(LCA\) 的父节点与 \(LCA\) 相连的边权。所以在修改/查询时不能将 \(LCA\) 节点的点权算入其中。
#include<bits/stdc++.h>
#define int long long
#define ls p<<1
#define rs p<<1|1
#define For(i,l,r) for(int i=l;i<=r;++i)
#define FOR(i,r,l) for(int i=r;i>=l;--i)
using namespace std;
const int N = 1e5 + 10;
struct node {
int l, r, val;
} t[N << 2];
struct edge {
int u, v;
} E[N];
struct Node {
int v, w, nx;
} e[N << 1];
int n, h[N], tot, fa[N], son[N], siz[N], dep[N], top[N], dfn[N], id[N], w[N], idx;
void add(int u, int v, int w) {
e[++tot] = (Node){v, w, h[u]};
h[u] = tot;
}
void dfs(int x, int f) {
fa[x] = f, siz[x] = 1;
dep[x] = dep[f] + 1;
int maxi = 0;
for (int i = h[x]; i; i = e[i].nx) {
int y = e[i].v;
if(y == f) continue;
w[y] = e[i].w;
dfs(y, x);
siz[x] += siz[y];
if(maxi < siz[y]) {
son[x] = y;
maxi = siz[y];
}
}
}
void dfs1(int x, int tp) {
top[x] = tp;
dfn[x] = ++idx;
id[idx] = x;
if(son[x]) dfs1(son[x], tp);
for (int i = h[x]; i; i = e[i].nx) {
int y = e[i].v;
if(y == fa[x] || y == son[x]) continue;
dfs1(y, y);
}
}
void pushup(int p) {
t[p].val = max(t[ls].val, t[rs].val);
}
void build(int p, int l, int r) {
t[p].l = l, t[p].r = r;
if(l == r) {
t[p].val = w[id[l]];
return ;
}
int mid = l + r >> 1;
build(ls, l, mid);
build(rs, mid + 1, r);
pushup(p);
}
void upd(int p, int x, int k) {
if(t[p].l == t[p].r) {
t[p].val = k;
return ;
}
int mid = t[p].l + t[p].r >> 1;
if(x <= mid) upd(ls, x, k);
else upd(rs, x, k);
pushup(p);
}
int qry(int p, int l, int r) {
if(l <= t[p].l && t[p].r <= r) {
return t[p].val;
}
int mid = t[p].l + t[p].r >> 1, ans = 0;
if(l <= mid) ans = max(ans, qry(ls, l, r));
if(r > mid) ans = max(ans, qry(rs, l, r));
return ans;
}
int query(int x, int y) {
int ans = 0;
while(top[x] != top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x, y);
ans = max(ans, qry(1, dfn[top[x]], dfn[x]));
x = fa[top[x]];
}
if(dep[x] < dep[y]) swap(x, y);
ans = max(ans, qry(1, dfn[y]+1, dfn[x]));
return ans;
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n;
For(i,1,n-1) {
int u, v, w;
cin >> u >> v >> w;
add(u, v, w);
add(v, u, w);
E[i] = (edge){u, v};
}
dfs(1, 0);
dfs1(1, 1);
build(1, 1, idx);
string op;
while(cin >> op) {
if(op == "DONE") break;
int u, v;
cin >> u >> v;
if(op == "QUERY") {
if(u == v) cout << 0 << '\n';
else cout << query(u, v) << '\n';
} else {
if(dep[E[u].u] < dep[E[u].v]) swap(E[u].u, E[u].v);
upd(1, dfn[E[u].u], v);
}
}
return 0;
}