一、基础变量
可使用 type(param) 查看变量类型
1. 整型int
可使用 int(param) 强转
2. 浮点型float
可使用 float(param) 强转
3. 复数complex
以 j 结尾,例如 1+ 1j,一般不使用
4. 布尔 bool (True,False)
5. 字符串 String
name = "limingze" 可使用 + 号拼接
1)查找字符串位置
str1 = "IT monkey"
print(str1.index("m"))2)字符串替换 replace
# 字符串替换 replace str.replace(str1, str2) 把str里的str1替换为str2
# 此方法会生成一个新的字符串,不会改变str1
str2 = str1.replace("monkey", "dog")
print(f"替换后:str1为{str1} str2为{str2}")3)字符串分割 split
# 字符串分割 split str.split(参数) 按照参数分割字符串生成一个新列表
new_list = str1.split(" ")
print(f"分割结果为{new_list}")4)字符串规整操作 strip
# 字符串规整操作 str.strip(参数) 把字符串开头结尾与参数值相同的值剔除
# 不穿参默认去除前后空格
str3 = " IT monkey "
print(str3.strip())
# 去除字符串开头结尾在参数中所有出现过的字符
str3 = "12IT 12 monkey12"
# IT 12 monkey
print(str3.strip("12"))5)统计子串在字符串中出现的次数 count
# 统计子串在字符串中出现的次数 str.count(str)
str4 = "it it monkey it"
count = str4.count("it")
print(f"it在str4字符串中出现的次数为{count}")6)计算字符串长度 len
# 计算字符串长度 len(str)
length = len(str4)
print(f"str4字符串长度为{length}")7)首字母大写 capiatlize
# capiatlize : 首字母大写,可以把字符串的第一个字母大写
print(str4.capitalize())8)将字符串中的每个单词的首字母大写 title
# title : 将字符串中的每个单词的首字母大写
print(str4.title())9)把字符串全部转为小写/大写
# lower : 把字符串全部转为小写
# upper : 把字符串全部转为大写
print(f"全部转为小写:{str4.lower()}")
print(f"全部转为大写:{str4.upper()}")10)连接字符串, 将一个字符串拼接到列表中,返回字符串
str2 = "abcsd"
str4 = str2.join(li)
# 1 abcsd b abcsd c
print(str4)11)调整规范与删除功能
# # ljust : left just, 左对齐、并且将字符串调整至指定长度
# print(str2.ljust(10,"*"))
# # rjust: right just, 右对齐、并且将字符串调整至指定长度
# print(str2.rjust(10,"-"))
# # center : 居中对齐、并且将字符串调整至指定长度
# print(str2.center(11,"."))
#
# str3 = " abc , def "
# # strip : 删除字符串两端的空白字符
print(str3.strip())
# # lstrip : left strip,删除左边的空白字符
# print(str3.lstrip())
# # rstrip : right strip,删除右边的空白字符
# print(str3.rstrip())
12)判断功能
# startswith : 从..开始,判断字符串是否以指定的文字开头
# print(str4.startswith("bc Aacb"))
# endswith : 以..结束,判断字符串是否以指定的文字结尾
# print(str4.endswith("Aac"))
# isalpha : alpha 字母,判断是否所有的字符都是字母(中文),是为true
print(str4.isalpha())
# isdigit : digit 数字,判断字符串中是否全都是数字 是为true
str5 = "123a22"
print(str5.isdigit())
# isalnum : alpha number,判断字符串中是否全都是字母(中文)或数字,是为true
print(str5.isalnum())
# isspace : space 空白,判断字符串中是否只包含空格(换行符),
str6 = " ."
print(str6.isspace())二、基本句式
1. print("Hello, Python") 打印
2. input
a = input("你好")
print(a)
# 也可对input进行强转
b = int(input("猜数字,请输入数字:\n"))
print(b)3. while语句
while i <= 2:
print(f"i的值为{i}")
i += 14. for语句
name为列表
name = "liming"
for i in name:
print(i)5. if else 和if elif else
if int(input("猜数字,请输入数字:\n")) == 1:
print("第一次猜对了")
elif int(input("猜错了,还有一次机会:\n")) == 1:
print("猜对了")
else:
print("猜错了")三、容器
1. 列表 List (有序有下标)
1) 特点
# list列表 容量为 2**63-1 == 9223372036854775807
# 可容纳不同类型元素
# 数据有序储存 (有下标)
# 允许数据重复存在
# 可修改
name_list = ['liming', 'Jenny', 'Danny', [1, 2, 3]]
# 空列表
list_null = []
list_null = list()
print(name_list[-3])
print(name_list[3])
print(name_list[3][0])2) index(param)
# index(元素) 查找指定元素在列表的下标,找不到报错ValueError
index = name_list.index("Danny")
print(f"Danny的下标为{index}")
# print(f"报错{name_list.index('a')}")3)修改值
# 修改第一个值
print(f"修改前 {name_list[0]}")
name_list[0] = 1
print(f"修改后 {name_list[0]}")4)插入
# 插入 List.insert(下标, 值)
print(f"插入前: {name_list}")
name_list.insert(1, "liming")
print(f"插入后: {name_list}")5)尾部追加元素
# 尾部追加单个元素 List.append(value)
print(f"追加前: {name_list}")
name_list.append([4, 5, 6])
name_list.append(7)
print(f"追加后: {name_list}")
# 尾部追加多个元素 List.extend(value)
my_list = [1, 2, 3, 4]
my_list.extend([5, 6, 7])
print(f"追加后:{my_list}")6)删除元素
# 删除元素 del List[n]
del my_list[1]
print(f"删除(del方法)后:{my_list}")
my_list.pop(2)
print(f"删除后(pop方法):{my_list}")
# 删除某元素在列表中的第一个匹配项 List.remove(value)
my_list = [1, 2, 3, 2, 4]
my_list.remove(2)
print(f"删除后(remove方法):{my_list}")
# 清空列表 List.clear()
my_list.clear()
print(f"清空后:{my_list}")7) 计算某元素在列表内的数量
# 计算某元素在列表内的数量 List.count(value)
my_list = [1, 2, 3, 2, 4, 2]
count = my_list.count(2)
print(f"元素2在列表中的数量为:{count}")8)计算列表的长度(列表元素数量)
# 计算列表的长度(列表元素数量)
print(f"列表长度为:{len(my_list)} \n {my_list}")9)反转列表 list.reverse() 会改变原列表
# 反转列表 list.reverse() 会改变原列表
my_list = [1, 2, 3, 4, 5]
my_list.reverse()
print(f"反转后为{my_list}")2. 元组 Tuple
1) 特点
可理解为不可变列表,一旦定义就不修改 其余和列表相同
定义元组只有一个元素时在元素后加逗号,否则定义的单元素元组为元素的类型
元组不可修改,但是内嵌的list可以修改
t1 = (1, 2, "hello", True)
t2 = ()
t3 = tuple()
print(f"t1类型是: {type(t1)}, 内容是 {t1}")
print(f"t2类型是: {type(t2)}, 内容是 {t2}")
print(f"t3类型是: {type(t3)}, 内容是 {t3}")
# t4类型是: <class 'str'>, 内容是 hello
print(f"t4类型是: {type(t4)}, 内容是 {t4}")
t4 = ("hello", )
# t4类型是: <class 'tuple'>, 内容是 ('hello',)
print(f"t4类型是: {type(t4)}, 内容是 {t4}")
t4 = ((1, 2, 3), (4, 5, 6))
print(f"t4类型是: {type(t4)}, 内容是 {t4}")
# 从t4取元组值 6
print(t4[1][2])2)查找元组元素下标 tuple.index(value)
3)统计元组中某个元素出现的次数 tuple.count(value)
4)计算元组长度 len(tuple)
3. 集合 Set
# 集合是无序的,不支持下标索引,自动去重,可修改
# 集合只能包含数字,字符串,元组等不可变类型数据,不能包含列表,字典,集合等可变序列的数据
# 集合的遍历 集合没有下标不能用while遍历,只能使用for循环遍历
my_set = {"礼炮", "it monkey", "老人与海", "礼炮", "it monkey", "老人与海"}
my_set_empty = {}
my_set_empty = set()
print(f"my_set内容是: {my_set}类型是 {type(my_set)}")
print(f"my_set_empty内容是: {my_set_empty}类型是 {type(my_set_empty)}")1)集合的添加
# 集合的添加
# s.add(5)
# s.update(100) # 需要传入可迭代对象 拆分添加
# 添加元素 set.add(value)
my_set.add("python")2)集合的删除
s.remove(23) # 元素不存在则报错
s.pop() # 随机删除,删除的是左边 第一个
s.discard(23) # 不存在就不删除3)清空集合 set.clear()
4)取集合的差值
# 取出两个集合的差值 set1.difference(set2) 取出set1有set2没有的值
# 不影响set1 和 set2的值
set1 = {1, 2, 3, 4}
set2 = {1, 5, 6}
set3 = set1.difference(set2)
print(f"set1的值为:{set1}")
print(f"set2的值为:{set2}")
print(f"set1有而set2没有的值为: {set3}")5)消除两个集合的交集
# 消除交集 set1.difference_update(set2) 会改变set1的值
set1 = {1, 2, 3, 4}
set2 = {1, 5, 6}
set1.difference_update(set2)
print(f"set1的值为:{set1}")
print(f"set2的值为:{set2}")6)合并集合
# 合并集合 set3 = set1.union(set2) 不影响set1 和 set2的值
set1 = {1, 2, 3, 4}
set2 = {1, 5, 6}
set3 = set1.union(set2)
print(f"set1的值为:{set1}")
print(f"set2的值为:{set2}")
print(f"合并后为:{set3}")7)len()统计集合元素数量
4. 字典 Dictionary
无序的Key-Value集合,类似java的map
字典不允许 列表, 字典,集合作为key值,value可以
字典不允许key值重复,后定义的key会覆盖先定义的key
my_dict = {}
my_dict = dict()
print(f"字典内容为: {my_dict}\n 字典类型为{type(my_dict)}")
dic = {'HAHA', 'day'}1)新增元素
# 新增元素
my_dict = {
"name": "liming",
"score": 90,
"hobby": "唱歌"
}
my_dict["money"] = 100
print(my_dict)
2)删除元素
# 删除字典元素 dict.pop(key)
my_dict.pop('name')
print(my_dict)3)清空字典
# 清空字典 dist.clear()
my_dict.clear()
print(my_dict)4)获取字典中全部key值
my_dict = {
"name": "liming",
"score": 90,
"hobby": "唱歌"
}
keys = my_dict.keys()
print(f"字典中的全部key值为: {keys}")5) setdefault(key, default) 存在就查询,不存在就添加 键不存在时,默认值为default
print(my_dict.setdefault("name", 0))6) 计算字典长度len(my_dist)
7) 排序
# 排序 正常排序会改变原值,反转时不改变原值
set1 = {2, 1, 4, 3}
set2 = sorted(set1, reverse=True)
print(set1)
print(set2)8) 遍历
# 遍历字典
for key in keys:
print(f"字典的key是: {key}\t字典的value是: {my_dict[key]}")
# 拆包
for i, j in enumerate(my_dict,100):
print(i, j)5. 序列切片
# 序列切片 str[start:end [, step] ]反向取值需要范围对调
# 步长为1可不写
str4 = "abcAacc艾哈12"
print(str4[1: 5])
print(str4[1: 5: 2])
print(str4[5: 1: -1])6. 区别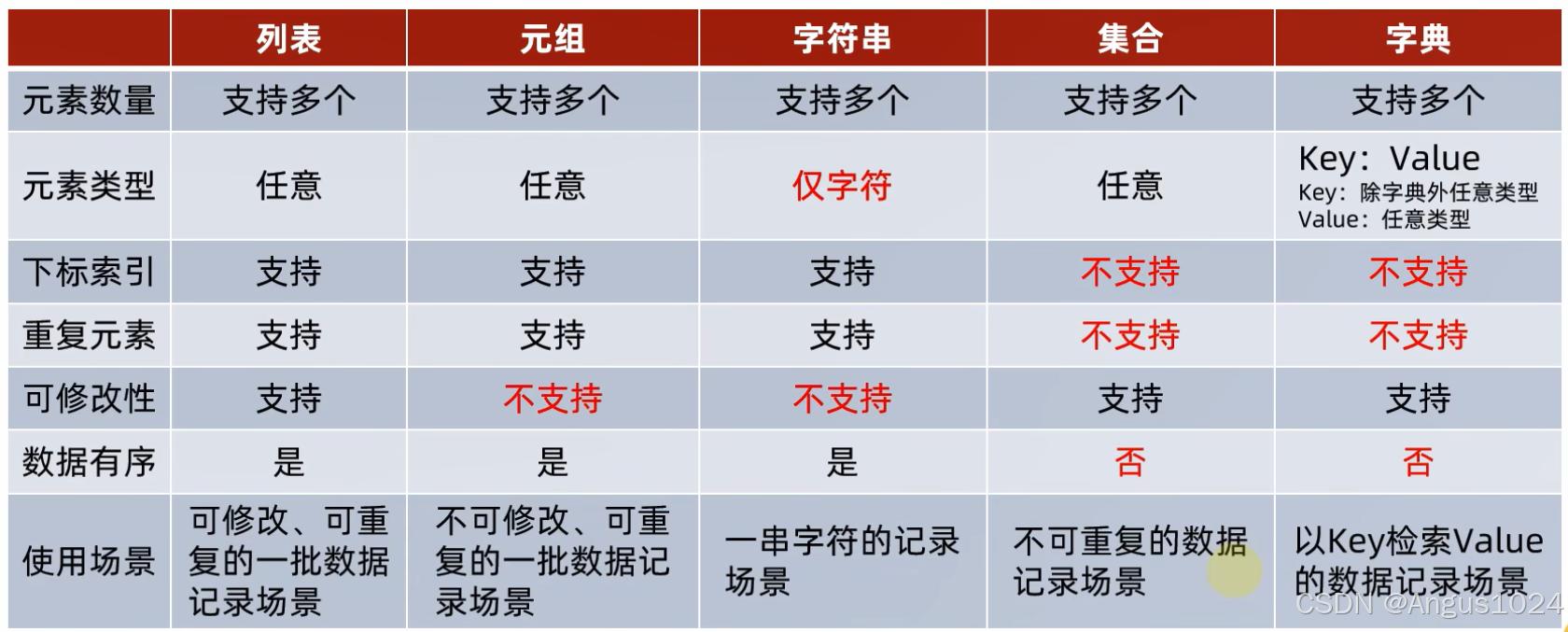
四、函数
1. 函数的定义
无返回值只是我们没有定义返回值,拿属性去接无返回值函数时,属性值为None
# 函数定义
# 有参有返回值
def test_print1(msg):
return msg
# 无参无返回值
def test_print2():
print("Hello World")
test_print1("你好")
test_print2()
test2 = test_print2()
print(test2)2. 多返回值函数
# 多返回值函数
def test_print3():
return 1, "2", ["你好", "hello"]
x, y, z = test_print3()
print(x)
print(y)
print(z)3. 函数说明文档、嵌套使用、函数作为参数传递
def add_demo(x, y):
"""
说明文档
:param x: 参数x
:param y: 参数y
:return: 返回和
"""
print_demo()
return x + y
def print_demo():
print("Hello World")
add_demo(1, 2)
def demo_add(add_demo):
return add_demo(1, 2)4. 函数的多种参数

# 位置参数传参 (按顺序传参) def user_info(name, age): print(f"姓名:{name}, 年龄:{age}") name = "liming" age = 21 user_info(age, name) # 姓名:21, 年龄:liming user_info("liming", 21) # 姓名:liming, 年龄:21 # 关键字传参 根据关键字传参,可打乱顺序 user_info(age=31, name="liming") # 姓名:liming, 年龄:31 # 混合传参 混合传参时位置参数必须放在前边,且位置参数会优先匹配第一个参数 # user_info(age=31, "liming") 报错 # 缺省参数,设置的默认值必须放在最后 def user_info(name, age, gender = "女"): print(name, age, gender) # 不定长参数 # 位置参数不定长为 *号 一般用args # 关键字参数不定长为 **号 一般用 kwargs def user_info(*args): print(args) user_info(1, 2, 3, [1, 2], "a") def user_info(**kwargs): print(kwargs) user_info(name = 1, b = 2, c = 3)
5. lambda函数
# lambda 传入参数: 函数体(一行代码)
# lambda 函数只能在定义时执行一次
lambda a, b, c: a + b + c
6. 常用函数
# 将python转为json
import json
data = [
{"name": "张大山", "age": 19},
{"name": "王大锤", "age": 18},
{"name": "赵小虎", "age": 17}]
json_str = json.dumps(data, ensure_ascii=False)
print(type(json_str))
print(json_str)
# 将json转换为python
s = '[
{"name": "张大山", "age": 19},
{"name": "王大锤", "age": 18},
{"name": "赵小虎", "age": 17}]'
li = json.loads(s)
print(type(li))
print(li)
# 列表推导式
li = [i for i in range(10)]
print(li)
li = [(i, j) for i in range(2) for j in range(10, 0, -1)]
print(li)
# map函数
my_list = [1, 2, 3, 4, 5]
def f(x):
return x ** 2
result = map(f, my_list)
# <class 'map'> <map object at 0x00000287F8323040> [1, 4, 9, 16, 25]
print(type(result), result, list(result))
# reduce函数
import functools
my_list = [1, 2, 3, 4, 5]
def f(x1, x2):
return x1 + x2
result = functools.reduce(f, my_list)
print(result) # 15
# filter过滤函数
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def f(x):
return x % 2 == 0
result = filter(f, my_list)
print(list(result))
# 正则表达式
import re
s = "abcdefghijklmnb"
# match() 开头匹配
result = re.match("b", s)
print(result)
# search() 搜索匹配
result = re.search("b", s)
print(result)
# findall() 搜索全部匹配
result = re.findall("b",s)
print(result)五、文件操作

"""
open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
file 文件路径
mode 文件的操作
buffering 缓存区,暂时性存储数据
encoding 编码格式
errors 错误
newline 换行
closefd 关闭
W 写入模式
每次都是重新写入,指针在文件的最前面
write() 参数必须是str
writelines() 参数是可迭代对象,元素必须是str
writable() 判断当前文件是否可以写入
R 读取模式
指针在文件的最前面
没编码读字节,有编码读字符
read() 读全部
readline() 读整行
readlines() 将每行当成一个元素,最终会返回一个列表,只会整个读
"""
# 写入
# 1、创建写入对象,没有会创建
fd = open("ds.pa","w") # 句柄
# 2、写入内容
li = ["aa","bb","cc"]
fd.write("\nabvc")
fd.writelines(li)
print(fd.writable())
# 3、关闭资源
fd.close()
# 读取
# 1、创建读取对象,没有会报错
fd = open("aaa.txt", "r" ,encoding="utf-8")
#2、读取内容
# s = fd.read(10)
# s =fd.readline(3)
s = fd.readlines(7)
fd.readable()
print(s)
# 3、关闭资源
fd.close()
# fd = open("a.jpg","rb")
# s = fd.read()
# print(s)
# fd.close()
#
# fd2 = open("aCopy.jpg","wb")
# fd2.write(s)
# fd2.close()
# 可读可写
# fd = open("aa.txt","w+",encoding="utf-8")
# # fd.write("aaa小白兔\n")
# # fd.write("白又白")
# #
# # # utf-8 一个中文是3个字节 gbk 一个中文是两个字节
# # fd.seek(1,0) # 参数1 预留几个字节的位置 ,参数2 调整指针的位置 0从头读 1当前位置 2末尾
# # fd.write("db哈哈")
# # s = fd.read()
# # print(s)
# # fd.close()
fd = open("aa.txt","a",encoding="utf-8")
fd.seek(2,0) # a模式不能调整指针位置
fd.write("aaa")
fd.close()
# """
# W write 写入模式
# 每次都是重新写入,指针在文件的最前面
# write() 参数必须是str
# writelines() 参数是可迭代对象,元素必须是str
# writable() 判断当前文件是否可以写入
#
# R read 读取模式
# 指针在文件的最前面
# 没编码读字节,有编码读字符
# read() 读全部
# readline() 读整行
# readlines() 将每行当成一个元素,最终会返回一个列表,只会整个读
#
# X xor 异或模式
# 不存在就创建,存在就报错,指针在最前面
#
# A append 追加模式
# 不存在就创建,存在就继续往后写,指针在文件的最后面
#
# 不能单独使用的模式
# b binary 二进制模式
# t text 文本模式(默认)
# + 更新读写
# 套装
# wb\rb\ab\xb 二进制的读写
# w+\r+\a+\x+ 可读可写的操作普通文件
# wb+\rb+\ab+\xb+ 可读可写的操作二进制文件
# """
# fd = open("aaaa.txt","x",encoding="utf-8")
# fd.write("哈哈")
# fd.close()
# fd = open("aa.txt","a",encoding="utf-8")
# fd.write("美术老师")
# fd.close()六、异常
# 异常
try:
f = open("practice.txt", "r", encoding="UTF-8")
except:
print("出现异常")
f = open("practice.txt", "w", encoding="UTF-8")
# 捕获指定异常
try:
# print(name) #name 'name' is not defined
1 / 0 # division by zero
except (NameError, ZeroDivisionError) as e:
print("出现了变量未定义异常")
print(e)
# 捕获所有异常
try:
1 / 0
except Exception as e:
print(f"出现异常:{e}")
else:
print("没有异常时输出")
finally:
print("不论有没有异常都执行")
# 异常具有传递性
def fun1():
print("fun1开始执行")
num = 1 / 0
print("fun1执行结束")
def fun2():
print("fun2开始执行")
fun1()
print("fun2执行结束")
def main():
try:
fun2()
except Exception as e:
print(f"出现异常了: {e}")
main()
七、对象
1. 对象和面向对象的概念
"""
面向对象:一种编程思想和编程规范,相对于面向过程而言的
面向过程: 每一件事都由我们自己做
面向对象: 从执行者变成了指挥者,把事情交给对象去做
三大特征: 封装、继承、多态
类与对象的关系
类:某一些形态的统称 属性(变量) 行为(方法)
对象:是类的具体实例
"""
# 旧式类
# class person:
# pass
#
# class person():
# pass
# 新式类
class person(object): # object 所有类的基类
"""
这是人类 说明文档 person.__doc__ 查看说明文档
"""
# 行为 方法
def eat(self): # self 对象的引用 谁调用它 它就代表谁
print("到点就吃饭")
p = person()
# 属性
p.name = "zhangsan"
print(p.name)
p.eat()
p2 = person()
p2.eat()
# 面向过程
# def getSum(li):
# sum = 0
# for i in li:
# sum+=i
# return sum
#
# li= [1,2,3,4,5]
# print(getSum(li))
# 面向对象
# print(sum(li))2. 构造放法及其魔术方法
class person(object):
# 对对象进行初始化,一般用来设置属性,创建对象时自动加载
def __init__(self, name, age):
self.name = name # 局部变量
self.age = age
# 用来显示信息 只能return 并且必须是字符串 没有重新定义时,显示的是对象的地址值
def __str__(self):
return "%s,%d" % (self.name, self.age)
# 删除对象,对象引用结束后自动删除
def __del__(self):
print("对象%s已删除" % self.name)
p = person("zhangssan", 23)
print(p.name, p.age)
p2 = person("lisi", 25)
print(p2.name, p2.age)
print(p)
print(p2)
class Student:
name = None
sex = None
nationality = None
native_place = None
age = None
# __init__ 方法会自动执行,有此方法必须传参
def __init__(self, name, sex, nationality, native_place, age):
self.name = name
self.sex = sex
self.nationality = nationality
self.native_place = native_place
self.age = age
print("创建成功!!!")
def say_hi(self):
print(f"你好,{self.name}")
def say_hi01(self, msg):
print(f"你好,{msg}")
# stu1 = Student()
#
# stu1.name = "坤坤"
# stu1.sex = "公"
# stu1.nationality = "坤国"
# stu1.native_place = "坤省"
# stu1.age = 25
#
# print(stu1.name)
# print(stu1.sex)
# print(stu1.nationality)
# print(stu1.native_place)
# print(stu1.age)
# stu1.say_hi()
# stu1.say_hi01("老人于海")
stu2 = Student("老人与海", "不详", "中国", "北京", 19)
print(stu2.name)
print(stu2.sex)
print(stu2.nationality)
print(stu2.native_place)
print(stu2.age)
# 常用内置方法
class Demo:
# 构造方法,可用于创建类对象的时候设置初始化行为
def __init__(self, name, age):
self.name = name
self.age = age
print(f"我是__init__构造方法")
# 用于类对象转字符串的行为
def __str__(self):
return f"Demo类对象, name={self.name},age={self.age}"
# __lt__ 方法判断大小
def __lt__(self, other):
return f"__lt__ 方法比较结果: {self.age < other.age}"
# __le__ 方法判断大于等于或小于等于
def __le__(self, other):
return f"__le__ 方法比较结果: {self.age <= other.age}"
# __eq__ 方法判断是否相等
def __eq__(self, other):
return f"__eq__ 方法比较结果: {self.age < other.age}"
demo1 = Demo("ikun", 23)
demo2 = Demo("iyu", 25)
print(demo1)
print(str(demo1))
print(demo1 > demo2)
print(demo1 <= demo2)
print(demo1 == demo2)3. 封装
# 封装
# 前边有__符号的为私有变量或方法,不能直接调用使用,但可以定义内置方法使用,
# 类似java定义private 通过get,set方法获取或设置值
class Phone:
__number = "123"
def print_number(self):
print(self.__number)
phone = Phone()
# print(phone.__number)
phone.print_number()4. 继承
# 继承 单继承,多继承
class Phone():
IMEI = None
producer = "HM"
def call_by_4g(self):
print("4g通话")
def call_by_5g(self):
print("父类5g")
class Phone2023(Phone):
face_id = "10001"
producer = "2023"
def call_by_5g(self):
print(f"父类变量:{super().producer}")
super().call_by_5g()
print("2023年新功能: 5g通话")
phone = Phone2023()
print(phone.producer)
phone.call_by_4g()
phone.call_by_5g()
# 注解 my_list: list[int] = [1, 2, 3]
# 联合注解 my_list: list[Union[str,int]] = [1, 2, 'aa', 'bbb'] (需要导包 from typing import Union)5. 多态
# 多态
class Animal:
def speak(self):
pass
class Dog(Animal):
def speak(self):
print("汪汪汪")
class Cat(Animal):
def speak(self):
print("喵喵喵")
def make_noise(animal):
animal.speak()
dog = Dog()
cat = Cat()
make_noise(dog)
make_noise(cat)八、数据库的简单使用
from pymysql import Connection
# 获取到MySQL数据库连接对象
conn = Connection(
host='localhost',
port=3306,
user='root',
password='123456',
# autocommit=True # 设置自动提交
)
# 打印数据库软件信息
print(conn.get_server_info())
#获取游标对象
cursor = conn.cursor()
# 选择数据库
conn.select_db('mydemo')
# 使用游标对象,执行sql语句
cursor.execute('select * from user')
# 获取查询结果
result: tuple = cursor.fetchall()
for row in result:
print(row)
# 当对数据库数据进行改变时,需要提交操作
cursor.execute("insert into user (id, name, age, sex) values (4, '测试', 12, '男')")
conn.commit()
cursor.execute('select * from user')
result: tuple = cursor.fetchall()
for row in result:
print(row)
# 关闭数据库连接
conn.close()九、闭包
闭包指的是满足以下几个条件的函数:
- 必须有一个内嵌函数。
- 内嵌函数必须引用外部函数中的变量。
- 外部函数的返回值必须是内嵌函数。
简而言之,闭包就是由函数以及创建该函数时存在的自由变量组成的实体。
# 简单闭包
def outer(logo):
def inner(msg):
print(f"{logo} -- {msg}")
return inner
fn1 = outer("Hello")
fn1("world")
# 如果想修改外部函数传来的值 例如 logo 需要用nonlocal声明变量
def outer(logo):
def inner(msg):
nonlocal logo
logo = "你好"
print(f"{logo} -- {msg}")
return inner
fn1 = outer("Hello")
fn1("world")
十、线程的基本使用
import threading
# 属性值
# group: 暂时没有用处,未来预留的参数
# target: 执行的目标任务名
# args: 以元组的形式给执行任务传参
# kwargs: 以字典的方式给执行任务传参
# name: 线程名,一般不用设置
def thread_sing():
print("唱")
def thread_dance():
print("跳舞")
thread_obj = threading.Thread(target=thread_sing)
thread_obj.start()