原文:
www.bookstack.cn/read/th-fastai-book译者:飞龙
第十章:NLP 深入探讨:RNNs
原文:
www.bookstack.cn/read/th-fastai-book/38414c136aca063a.md译者:飞龙
在第一章中,我们看到深度学习可以用于处理自然语言数据集并取得出色的结果。我们的示例依赖于使用预训练的语言模型,并对其进行微调以对评论进行分类。该示例突出了 NLP 和计算机视觉中迁移学习的区别:通常情况下,在 NLP 中,预训练模型是在不同任务上训练的。
我们所谓的语言模型是一个经过训练以猜测文本中下一个单词的模型(在读取之前的单词后)。这种任务称为自监督学习:我们不需要为我们的模型提供标签,只需向其提供大量文本。它有一个过程可以从数据中自动获取标签,这个任务并不是微不足道的:为了正确猜测句子中的下一个单词,模型将必须发展对英语(或其他语言)的理解。自监督学习也可以用于其他领域;例如,参见“自监督学习和计算机视觉”以了解视觉应用。自监督学习通常不用于直接训练的模型,而是用于预训练用于迁移学习的模型。
术语:自监督学习
使用嵌入在自变量中的标签来训练模型,而不是需要外部标签。例如,训练一个模型来预测文本中的下一个单词。
我们在第一章中用于分类 IMDb 评论的语言模型是在维基百科上预训练的。通过直接微调这个语言模型到电影评论分类器,我们取得了出色的结果,但通过一个额外的步骤,我们甚至可以做得更好。维基百科的英语与 IMDb 的英语略有不同,因此,我们可以将我们的预训练语言模型微调到 IMDb 语料库,然后将那个作为我们分类器的基础。
即使我们的语言模型了解我们在任务中使用的语言的基础知识(例如,我们的预训练模型是英语),熟悉我们的目标语料库的风格也是有帮助的。它可能是更非正式的语言,或者更技术性的,有新词要学习或者不同的句子构成方式。在 IMDb 数据集的情况下,将会有很多电影导演和演员的名字,通常比维基百科中看到的语言更不正式。
我们已经看到,使用 fastai,我们可以下载一个预训练的英语语言模型,并用它来获得 NLP 分类的最新结果。(我们预计很快将提供更多语言的预训练模型;实际上,当您阅读本书时,它们可能已经可用。)那么,为什么我们要详细学习如何训练语言模型呢?
当然,一个原因是了解您正在使用的模型的基础知识是有帮助的。但还有另一个非常实际的原因,那就是如果在微调分类模型之前微调(基于序列的)语言模型,您将获得更好的结果。例如,对于 IMDb 情感分析任务,数据集包括额外的 50,000 条电影评论,这些评论没有任何积极或消极的标签。由于训练集中有 25,000 条带标签的评论,验证集中有 25,000 条,总共有 100,000 条电影评论。我们可以使用所有这些评论来微调仅在维基百科文章上训练的预训练语言模型,这将导致一个特别擅长预测电影评论下一个单词的语言模型。
这被称为通用语言模型微调(ULMFiT)方法。介绍它的论文表明,在将语言模型微调到传递学习到分类任务之前,这个额外的微调阶段会导致预测显著更好。使用这种方法,我们在 NLP 中有三个传递学习阶段,如图 10-1 所总结。
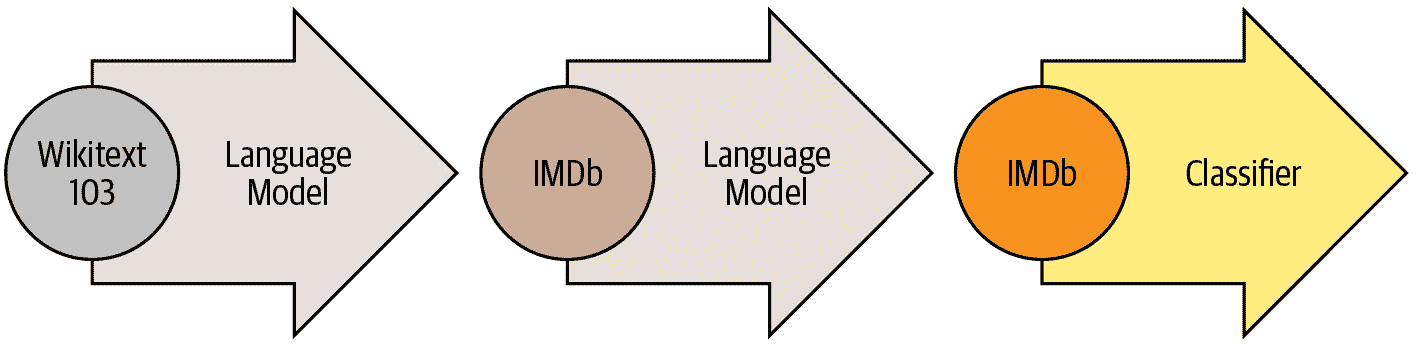
图 10-1。ULMFiT 过程
我们现在将探讨如何将神经网络应用于这个语言建模问题,使用前两章介绍的概念。但在继续阅读之前,请暂停一下,思考一下您将如何处理这个问题。
文本预处理
到目前为止,我们学到的如何构建语言模型并不明显。句子的长度可能不同,文档可能很长。那么我们如何使用神经网络来预测句子的下一个单词呢?让我们找出答案!
我们已经看到分类变量可以作为神经网络的独立变量使用。以下是我们为单个分类变量采取的方法:
-
制作该分类变量的所有可能级别的列表(我们将称此列表为词汇)。
-
用词汇表中的索引替换每个级别。
-
为此创建一个包含每个级别的行的嵌入矩阵(即,词汇表中的每个项目)。
-
将此嵌入矩阵用作神经网络的第一层。(专用嵌入矩阵可以将步骤 2 中创建的原始词汇索引作为输入;这相当于但比使用表示索引的独热编码向量作为输入更快速和更有效。)
我们几乎可以用文本做同样的事情!新的是序列的概念。首先,我们将数据集中的所有文档连接成一个大字符串,然后将其拆分为单词(或标记),从而给我们一个非常长的单词列表。我们的独立变量将是从我们非常长的列表中的第一个单词开始并以倒数第二个单词结束的单词序列,我们的因变量将是从第二个单词开始并以最后一个单词结束的单词序列。
我们的词汇将由一些常见词汇和我们语料库中特定的新词汇(例如电影术语或演员的名字)混合组成。我们的嵌入矩阵将相应构建:对于预训练模型词汇中的词,我们将使用预训练模型的嵌入矩阵中的相应行;但对于新词,我们将没有任何内容,因此我们将只是用随机向量初始化相应的行。
创建语言模型所需的每个步骤都与自然语言处理领域的术语相关联,并且有 fastai 和 PyTorch 类可用于帮助。步骤如下:
标记化
将文本转换为单词列表(或字符,或子字符串,取决于您模型的粒度)。
数值化
列出所有出现的唯一单词(词汇表),并通过查找其在词汇表中的索引将每个单词转换为一个数字。
语言模型数据加载器创建
fastai 提供了一个LMDataLoader类,它会自动处理创建一个依赖变量,该变量与独立变量相差一个标记。它还处理一些重要的细节,例如如何以保持所需结构的方式对训练数据进行洗牌。
语言模型创建
我们需要一种特殊类型的模型,可以处理我们以前没有见过的输入列表,这些列表可能非常大或非常小。有许多方法可以做到这一点;在本章中,我们将使用循环神经网络(RNN)。我们将在第十二章中详细介绍 RNN 的细节,但现在,您可以将其视为另一个深度神经网络。
让我们详细看看每个步骤是如何工作的。
分词
当我们说“将文本转换为单词列表”时,我们忽略了很多细节。例如,我们如何处理标点符号?我们如何处理像“don’t”这样的单词?它是一个单词还是两个?长的医学或化学术语怎么办?它们应该被分割成各自的含义部分吗?连字符词怎么处理?像德语和波兰语这样的语言如何处理,它们可以从许多部分组成一个非常长的单词?像日语和中文这样的语言如何处理,它们根本不使用基础,也没有一个明确定义的单词的概念?
由于这些问题没有一个正确答案,所以也没有一个分词的方法。有三种主要方法:
基于单词的
将一个句子按空格分割,同时应用特定于语言的规则,尝试在没有空格的情况下分隔含义部分(例如将“don’t”转换为“do n’t”)。通常,标点符号也会被分割成单独的标记。
基于子词的
根据最常出现的子字符串将单词分割成较小的部分。例如,“occasion”可能被分词为“o c ca sion”。
基于字符的
将一个句子分割成其各个字符。
我们将在这里看一下单词和子词的分词,将字符为基础的分词留给你在本章末尾的问卷中实现。
行话:Token
由分词过程创建的列表的一个元素。它可以是一个单词,一个单词的一部分(一个子词),或一个单个字符。
使用 fastai 进行单词分词
fastai 并没有提供自己的分词器,而是提供了一个一致的接口来使用外部库中的一系列分词器。分词是一个活跃的研究领域,新的和改进的分词器不断涌现,因此 fastai 使用的默认值也会发生变化。然而,API 和选项不应该发生太大变化,因为 fastai 试图在底层技术发生变化时保持一致的 API。
让我们尝试一下我们在第一章中使用的 IMDb 数据集:
from fastai.text.all import *
path = untar_data(URLs.IMDB)
我们需要获取文本文件以尝试一个分词器。就像get_image_files(我们已经使用了很多次)获取路径中的所有图像文件一样,get_text_files获取路径中的所有文本文件。我们还可以选择性地传递folders来限制搜索到特定的子文件夹列表:
files = get_text_files(path, folders = ['train', 'test', 'unsup'])
这是一个我们将要分词的评论(我们这里只打印开头部分以节省空间):
txt = files[0].open().read(); txt[:75]
'This movie, which I just discovered at the video store, has apparently sit '
在撰写本书时,fastai 的默认英语单词分词器使用了一个名为spaCy的库。它有一个复杂的规则引擎,具有针对 URL、特殊英语单词等的特殊规则,以及更多。然而,我们不会直接使用SpacyTokenizer,而是使用WordTokenizer,因为它将始终指向 fastai 当前默认的单词分词器(取决于你阅读本书的时间,可能不一定是 spaCy)。
让我们试一试。我们将使用 fastai 的coll_repr(*collection*,*n*)函数来显示结果。这会显示collection的前n个项目,以及完整的大小——这是L默认使用的。请注意,fastai 的分词器接受一个要分词的文档集合,因此我们必须将txt包装在一个列表中:
spacy = WordTokenizer()
toks = first(spacy([txt]))
print(coll_repr(toks, 30))
(#201) ['This','movie',',','which','I','just','discovered','at','the','video','s
> tore',',','has','apparently','sit','around','for','a','couple','of','years','
> without','a','distributor','.','It',"'s",'easy','to','see'...]
正如你所看到的,spaCy 主要只是将单词和标点符号分开。但它在这里也做了其他事情:它将“it's”分割成“it”和“’s”。这是直观的;这些实际上是分开的单词。分词是一个令人惊讶的微妙任务,当你考虑到所有必须处理的细节时。幸运的是,spaCy 为我们处理得相当好——例如,在这里我们看到“.”在终止句子时被分开,但在首字母缩写或数字中不会被分开:
first(spacy(['The U.S. dollar $1 is $1.00.']))
(#9) ['The','U.S.','dollar','$','1','is','$','1.00','.']
然后 fastai 通过Tokenizer类为分词过程添加了一些额外功能:
tkn = Tokenizer(spacy)
print(coll_repr(tkn(txt), 31))
(#228) ['xxbos','xxmaj','this','movie',',','which','i','just','discovered','at',
> 'the','video','store',',','has','apparently','sit','around','for','a','couple
> ','of','years','without','a','distributor','.','xxmaj','it',"'s",'easy'...]
请注意,现在有一些以“xx”开头的标记,这不是英语中常见的单词前缀。这些是特殊标记。
例如,列表中的第一项xxbos是一个特殊标记,表示新文本的开始(“BOS”是一个标准的 NLP 缩写,意思是“流的开始”)。通过识别这个开始标记,模型将能够学习需要“忘记”先前说过的内容,专注于即将出现的单词。
这些特殊标记并不是直接来自 spaCy。它们存在是因为 fastai 默认添加它们,通过在处理文本时应用一系列规则。这些规则旨在使模型更容易识别句子中的重要部分。在某种意义上,我们正在将原始的英语语言序列翻译成一个简化的标记化语言——这种语言被设计成易于模型学习。
例如,规则将用一个感叹号替换四个感叹号,后面跟着一个特殊的重复字符标记,然后是数字四。通过这种方式,模型的嵌入矩阵可以编码关于重复标点等一般概念的信息,而不需要为每个标点符号的重复次数添加单独的标记。同样,一个大写的单词将被替换为一个特殊的大写标记,后面跟着单词的小写版本。这样,嵌入矩阵只需要单词的小写版本,节省了计算和内存资源,但仍然可以学习大写的概念。
以下是一些你会看到的主要特殊标记:
xxbos
指示文本的开始(这里是一篇评论)
xxmaj
指示下一个单词以大写字母开头(因为我们将所有字母转换为小写)
xxunk
指示下一个单词是未知的
要查看使用的规则,可以查看默认规则:
defaults.text_proc_rules
[<function fastai.text.core.fix_html(x)>,
<function fastai.text.core.replace_rep(t)>,
<function fastai.text.core.replace_wrep(t)>,
<function fastai.text.core.spec_add_spaces(t)>,
<function fastai.text.core.rm_useless_spaces(t)>,
<function fastai.text.core.replace_all_caps(t)>,
<function fastai.text.core.replace_maj(t)>,
<function fastai.text.core.lowercase(t, add_bos=True, add_eos=False)>]
如常,你可以通过在笔记本中键入以下内容查看每个规则的源代码:
??replace_rep
以下是每个标记的简要摘要:
fix_html
用可读版本替换特殊的 HTML 字符(IMDb 评论中有很多这样的字符)
replace_rep
用一个特殊标记替换任何重复三次或更多次的字符(xxrep),重复的次数,然后是字符
replace_wrep
用一个特殊标记替换任何重复三次或更多次的单词(xxwrep),重复的次数,然后是单词
spec_add_spaces
在/和#周围添加空格
rm_useless_spaces
删除所有空格的重复
replace_all_caps
将所有大写字母单词转换为小写,并在其前面添加一个特殊标记(xxcap)
replace_maj
将大写的单词转换为小写,并在其前面添加一个特殊标记(xxmaj)
lowercase
将所有文本转换为小写,并在开头(xxbos)和/或结尾(xxeos)添加一个特殊标记
让我们看看其中一些的操作:
coll_repr(tkn('© Fast.ai www.fast.ai/INDEX'), 31)
"(#11) ['xxbos','©','xxmaj','fast.ai','xxrep','3','w','.fast.ai','/','xxup','ind
> ex'...]"
现在让我们看看子词标记化是如何工作的。
子词标记化
除了在前一节中看到的单词标记化方法之外,另一种流行的标记化方法是子词标记化。单词标记化依赖于一个假设,即空格在句子中提供了有意义的组件的有用分隔。然而,这个假设并不总是适用。例如,考虑这个句子:我的名字是郝杰瑞(中文中的“My name is Jeremy Howard”)。这对于单词标记器来说不会很好,因为其中没有空格!像中文和日文这样的语言不使用空格,事实上它们甚至没有一个明确定义的“单词”概念。其他语言,如土耳其语和匈牙利语,可以将许多子词组合在一起而不使用空格,创建包含许多独立信息片段的非常长的单词。
为了处理这些情况,通常最好使用子词标记化。这个过程分为两步:
-
分析一组文档以找到最常出现的字母组。这些将成为词汇表。
-
使用这个子词单元的词汇对语料库进行标记化。
让我们看一个例子。对于我们的语料库,我们将使用前 2,000 条电影评论:
txts = L(o.open().read() for o in files[:2000])
我们实例化我们的标记器,传入我们想要创建的词汇表的大小,然后我们需要“训练”它。也就是说,我们需要让它阅读我们的文档并找到常见的字符序列以创建词汇表。这是通过setup完成的。正如我们将很快看到的,setup是一个特殊的 fastai 方法,在我们通常的数据处理流程中会自动调用。然而,由于目前我们正在手动执行所有操作,因此我们必须自己调用它。这是一个为给定词汇表大小执行这些步骤并显示示例输出的函数:
def subword(sz):
sp = SubwordTokenizer(vocab_sz=sz)
sp.setup(txts)
return ' '.join(first(sp([txt]))[:40])
让我们试一试:
subword(1000)
'▁This ▁movie , ▁which ▁I ▁just ▁dis c over ed ▁at ▁the ▁video ▁st or e , ▁has
> ▁a p par ent ly ▁s it ▁around ▁for ▁a ▁couple ▁of ▁years ▁without ▁a ▁dis t
> ri but or . ▁It'
使用 fastai 的子词标记器时,特殊字符▁代表原始文本中的空格字符。
如果我们使用较小的词汇表,每个标记将代表更少的字符,并且需要更多的标记来表示一个句子:
subword(200)
'▁ T h i s ▁movie , ▁w h i ch ▁I ▁ j us t ▁ d i s c o ver ed ▁a t ▁the ▁ v id e
> o ▁ st or e , ▁h a s'
另一方面,如果我们使用较大的词汇表,大多数常见的英语单词将最终出现在词汇表中,我们将不需要那么多来表示一个句子:
subword(10000)
"▁This ▁movie , ▁which ▁I ▁just ▁discover ed ▁at ▁the ▁video ▁store , ▁has
> ▁apparently ▁sit ▁around ▁for ▁a ▁couple ▁of ▁years ▁without ▁a ▁distributor
> . ▁It ' s ▁easy ▁to ▁see ▁why . ▁The ▁story ▁of ▁two ▁friends ▁living"
选择子词词汇表大小代表一种折衷:较大的词汇表意味着每个句子的标记较少,这意味着训练速度更快,内存更少,并且模型需要记住的状态更少;但是,缺点是,这意味着更大的嵌入矩阵,这需要更多的数据来学习。
总的来说,子词标记化提供了一种在字符标记化(即使用较小的子词词汇表)和单词标记化(即使用较大的子词词汇表)之间轻松切换的方法,并且处理每种人类语言而无需开发特定于语言的算法。它甚至可以处理其他“语言”,如基因组序列或 MIDI 音乐符号!因此,过去一年中,它的流行度飙升,似乎很可能成为最常见的标记化方法(当您阅读本文时,它可能已经是了!)。
一旦我们的文本被分割成标记,我们需要将它们转换为数字。我们将在下一步中看到这一点。
使用 fastai 进行数字化
数字化是将标记映射到整数的过程。这些步骤基本上与创建Category变量所需的步骤相同,例如 MNIST 中数字的因变量:
-
制作该分类变量的所有可能级别的列表(词汇表)。
-
用词汇表中的索引替换每个级别。
让我们看看在之前看到的单词标记化文本上的实际操作:
toks = tkn(txt)
print(coll_repr(tkn(txt), 31))
(#228) ['xxbos','xxmaj','this','movie',',','which','i','just','discovered','at',
> 'the','video','store',',','has','apparently','sit','around','for','a','couple
> ','of','years','without','a','distributor','.','xxmaj','it',"'s",'easy'...]
就像SubwordTokenizer一样,我们需要在Numericalize上调用setup;这是我们创建词汇表的方法。这意味着我们首先需要我们的标记化语料库。由于标记化需要一段时间,fastai 会并行进行;但是对于这个手动演示,我们将使用一个小的子集:
toks200 = txts[:200].map(tkn)
toks200[0]
(#228)
> ['xxbos','xxmaj','this','movie',',','which','i','just','discovered','at'...]
我们可以将这个传递给setup来创建我们的词汇表:
num = Numericalize()
num.setup(toks200)
coll_repr(num.vocab,20)
"(#2000) ['xxunk','xxpad','xxbos','xxeos','xxfld','xxrep','xxwrep','xxup','xxmaj
> ','the','.',',','a','and','of','to','is','in','i','it'...]"
我们的特殊规则标记首先出现,然后每个单词按频率顺序出现一次。Numericalize的默认值为min_freq=3和max_vocab=60000。max_vocab=60000导致 fastai 用特殊的未知单词标记xxunk替换除最常见的 60,000 个单词之外的所有单词。这有助于避免过大的嵌入矩阵,因为这可能会减慢训练速度并占用太多内存,并且还可能意味着没有足够的数据来训练稀有单词的有用表示。然而,通过设置min_freq来处理最后一个问题更好;默认值min_freq=3意味着出现少于三次的任何单词都将被替换为xxunk。
fastai 还可以使用您提供的词汇表对数据集进行数字化,方法是将单词列表作为vocab参数传递。
一旦我们创建了我们的Numericalize对象,我们可以像使用函数一样使用它:
nums = num(toks)[:20]; nums
tensor([ 2, 8, 21, 28, 11, 90, 18, 59, 0, 45, 9, 351, 499, 11,
> 72, 533, 584, 146, 29, 12])
这一次,我们的标记已经转换为模型可以接收的整数张量。我们可以检查它们是否映射回原始文本:
' '.join(num.vocab[o] for o in nums)
'xxbos xxmaj this movie , which i just xxunk at the video store , has apparently
> sit around for a'
| xxbos | xxmaj | 在 | 这个 | 章节 | , | 我们 | 将 | 回顾 | 一下 | 分类 | 的 | 例子 |
回到我们之前的例子,有 6 个长度为 15 的批次,如果我们选择序列长度为 5,那意味着我们首先输入以下数组:
处理图像时,我们需要将它们全部调整为相同的高度和宽度,然后将它们组合在一起形成一个小批次,以便它们可以有效地堆叠在一个张量中。这里会有一点不同,因为不能简单地将文本调整为所需的长度。此外,我们希望我们的语言模型按顺序阅读文本,以便它可以有效地预测下一个单词是什么。这意味着每个新批次应该从上一个批次结束的地方开始。
假设我们有以下文本:
在这一章中,我们将回顾我们在第一章中学习的分类电影评论的例子,并深入挖掘。首先,我们将看一下将文本转换为数字所需的处理步骤以及如何自定义它。通过这样做,我们将有另一个使用数据块 API 中的预处理器的例子。
然后我们将学习如何构建一个语言模型并训练它一段时间。
标记化过程将添加特殊标记并处理标点以返回这个文本:
xxbos 在这一章中,我们将回顾我们在第一章中学习的分类电影评论的例子,并深入挖掘。首先,我们将看一下将文本转换为数字所需的处理步骤以及如何自定义它。通过这样做,我们将有另一个使用数据块 API 中的预处理器的例子。
现在我们有 90 个标记,用空格分隔。假设我们想要一个批次大小为 6。我们需要将这个文本分成 6 个长度为 15 的连续部分:
| 转换 | 文本 | 为 | 数字 | 和 |
|---|---|---|---|---|
| 电影 | 评论 | 我们 | 研究 | 在 |
| 首先 | 我们 | 将 | 看 | 处理 |
| 如何 | 自定义 | 它 | 。 | 通过 |
| 预处理器 | 在 | 数据 | 块 | xxup |
| 将 | 学习 | 我们 | 如何 | 构建 |
在理想的情况下,我们可以将这一个批次提供给我们的模型。但这种方法不具有可扩展性,因为在这个玩具示例之外,一个包含所有标记的单个批次不太可能适合我们的 GPU 内存(这里有 90 个标记,但所有 IMDb 评论一起给出了数百万个)。
因此,我们需要将这个数组更细地划分为固定序列长度的子数组。在这些子数组内部和之间保持顺序非常重要,因为我们将使用一个保持状态的模型,以便在预测接下来的内容时记住之前读到的内容。
| 语言 | 模型 | 和 | 训练 |
| xxbos | xxmaj | 在 | 这个 | 章节 |
|---|---|---|---|---|
| 分类 | 的 | 例子 | 在 | 电影 |
| 首先 | 我们 | 将 | 看 | 到 |
| 如何 | 自定义 | 它 | 。 | |
| 预处理器 | 使用 | 在 | ||
| 将 | 学习 | 我们 | 如何 | 构建 |
然后,这一个:
| , | 我们 | 将 | 回顾 |
|---|---|---|---|
| 章节 | 1 | 和 | 深入 |
| 处理 | 步骤 | 必要 | 将 |
| 通过 | 这样做 | , | |
| 数据 | 块 | xxup | api |
| 现在我们有了数字,我们需要将它们分批放入模型中。 |
最后:
| 将我们的文本放入语言模型的批次中 |
|---|
| 更深 |
| 将文本转换为数字,并按行翻译成中文: |
| 我们 |
| 。 |
| 它 |
回到我们的电影评论数据集,第一步是通过将各个文本串联在一起将其转换为流。与图像一样,最好随机化输入的顺序,因此在每个时期的开始,我们将对条目进行洗牌以生成新的流(我们对文档的顺序进行洗牌,而不是其中的单词顺序,否则文本将不再有意义!)。
然后将此流切成一定数量的批次(这是我们的批量大小)。例如,如果流有 50,000 个标记,我们设置批量大小为 10,这将给我们 5,000 个标记的 10 个小流。重要的是我们保留标记的顺序(因此从 1 到 5,000 为第一个小流,然后从 5,001 到 10,000…),因为我们希望模型读取连续的文本行(如前面的示例)。在预处理期间,在每个文本的开头添加一个xxbos标记,以便模型知道当读取流时新条目何时开始。
因此,总结一下,每个时期我们都会对文档集合进行洗牌,并将它们连接成一个标记流。然后将该流切成一批固定大小的连续小流。我们的模型将按顺序读取小流,并由于内部状态,无论我们选择的序列长度如何,它都将产生相同的激活。
当我们创建LMDataLoader时,所有这些都是由 fastai 库在幕后完成的。我们首先将我们的Numericalize对象应用于标记化的文本
nums200 = toks200.map(num)
然后将其传递给LMDataLoader:
dl = LMDataLoader(nums200)
让我们通过获取第一批来确认这是否给出了预期的结果
x,y = first(dl)
x.shape,y.shape
(torch.Size([64, 72]), torch.Size([64, 72]))
然后查看独立变量的第一行,这应该是第一个文本的开头:
' '.join(num.vocab[o] for o in x[0][:20])
'xxbos xxmaj this movie , which i just xxunk at the video store , has apparently
> sit around for a'
依赖变量是相同的,只是偏移了一个标记:
' '.join(num.vocab[o] for o in y[0][:20])
'xxmaj this movie , which i just xxunk at the video store , has apparently sit
> around for a couple'
这就完成了我们需要对数据应用的所有预处理步骤。我们现在准备训练我们的文本分类器。
训练文本分类器
正如我们在本章开头看到的那样,使用迁移学习训练最先进的文本分类器有两个步骤:首先,我们需要微调在 Wikipedia 上预训练的语言模型以适应 IMDb 评论的语料库,然后我们可以使用该模型来训练分类器。
像往常一样,让我们从组装数据开始。
使用 DataBlock 的语言模型
当TextBlock传递给DataBlock时,fastai 会自动处理标记化和数值化。所有可以传递给Tokenizer和Numericalize的参数也可以传递给TextBlock。在下一章中,我们将讨论分别运行每个步骤的最简单方法,以便进行调试,但您也可以通过在数据的子集上手动运行它们来进行调试,如前几节所示。不要忘记DataBlock的方便的summary方法,用于调试数据问题非常有用。
这是我们如何使用TextBlock使用 fastai 的默认值创建语言模型的方式:
get_imdb = partial(get_text_files, folders=['train', 'test', 'unsup'])
dls_lm = DataBlock(
blocks=TextBlock.from_folder(path, is_lm=True),
get_items=get_imdb, splitter=RandomSplitter(0.1)
).dataloaders(path, path=path, bs=128, seq_len=80)
与我们在DataBlock中使用的以前类型不同的一件事是,我们不仅仅直接使用类(即TextBlock(...),而是调用类方法。类方法是 Python 方法,如其名称所示,属于类而不是对象。(如果您对类方法不熟悉,请务必在网上搜索更多信息,因为它们在许多 Python 库和应用程序中常用;我们在本书中以前使用过几次,但没有特别提到。)TextBlock之所以特殊是因为设置数值化器的词汇表可能需要很长时间(我们必须读取和标记化每个文档以获取词汇表)。
为了尽可能高效,fastai 执行了一些优化:
-
它将标记化的文档保存在临时文件夹中,因此不必多次对其进行标记化。
-
它并行运行多个标记化过程,以利用计算机的 CPU。
我们需要告诉TextBlock如何访问文本,以便它可以进行这种初始预处理——这就是from_folder的作用。
show_batch然后以通常的方式工作:
dls_lm.show_batch(max_n=2)
| text | text_ | |
|---|---|---|
| 0 | xxbos xxmaj it ’s awesome ! xxmaj in xxmaj story xxmaj mode , your going from punk to pro . xxmaj you have to complete goals that involve skating , driving , and walking . xxmaj you create your own skater and give it a name , and you can make it look stupid or realistic . xxmaj you are with your friend xxmaj eric throughout the game until he betrays you and gets you kicked off of the skateboard | xxmaj it ’s awesome ! xxmaj in xxmaj story xxmaj mode , your going from punk to pro . xxmaj you have to complete goals that involve skating , driving , and walking . xxmaj you create your own skater and give it a name , and you can make it look stupid or realistic . xxmaj you are with your friend xxmaj eric throughout the game until he betrays you and gets you kicked off of the skateboard xxunk |
| 1 | what xxmaj i ‘ve read , xxmaj death xxmaj bed is based on an actual dream , xxmaj george xxmaj barry , the director , successfully transferred dream to film , only a genius could accomplish such a task . \n\n xxmaj old mansions make for good quality horror , as do portraits , not sure what to make of the killer bed with its killer yellow liquid , quite a bizarre dream , indeed . xxmaj also , this | xxmaj i ‘ve read , xxmaj death xxmaj bed is based on an actual dream , xxmaj george xxmaj barry , the director , successfully transferred dream to film , only a genius could accomplish such a task . \n\n xxmaj old mansions make for good quality horror , as do portraits , not sure what to make of the killer bed with its killer yellow liquid , quite a bizarre dream , indeed . xxmaj also , this is |
现在我们的数据准备好了,我们可以对预训练语言模型进行微调。
微调语言模型
将整数单词索引转换为我们可以用于神经网络的激活时,我们将使用嵌入,就像我们在协同过滤和表格建模中所做的那样。然后,我们将把这些嵌入馈送到递归神经网络(RNN)中,使用一种称为AWD-LSTM的架构(我们将在第十二章中向您展示如何从头开始编写这样一个模型)。正如我们之前讨论的,预训练模型中的嵌入与为不在预训练词汇表中的单词添加的随机嵌入合并。这在language_model_learner内部自动处理:
learn = language_model_learner(
dls_lm, AWD_LSTM, drop_mult=0.3,
metrics=[accuracy, Perplexity()]).to_fp16()
默认使用的损失函数是交叉熵损失,因为我们基本上有一个分类问题(不同类别是我们词汇表中的单词)。这里使用的困惑度指标通常用于 NLP 的语言模型:它是损失的指数(即torch.exp(cross_entropy))。我们还包括准确性指标,以查看我们的模型在尝试预测下一个单词时有多少次是正确的,因为交叉熵(正如我们所见)很难解释,并且更多地告诉我们有关模型信心而不是准确性。
让我们回到本章开头的流程图。第一个箭头已经为我们完成,并作为 fastai 中的预训练模型提供,我们刚刚构建了第二阶段的DataLoaders和Learner。现在我们准备好对我们的语言模型进行微调!
每个时代的训练需要相当长的时间,因此我们将在训练过程中保存中间模型结果。由于fine_tune不会为我们执行此操作,因此我们将使用fit_one_cycle。就像cnn_learner一样,当使用预训练模型(这是默认设置)时,language_model_learner在使用时会自动调用freeze,因此这将仅训练嵌入(模型中唯一包含随机初始化权重的部分——即我们 IMDb 词汇表中存在但不在预训练模型词汇表中的单词的嵌入):
learn.fit_one_cycle(1, 2e-2)
| epoch | train_loss | valid_loss | accuracy | perplexity | time |
|---|---|---|---|---|---|
| 0 | 4.120048 | 3.912788 | 0.299565 | 50.038246 | 11:39 |
这个模型训练时间较长,所以现在是谈论保存中间结果的好机会。
保存和加载模型
您可以轻松保存模型的状态如下:
learn.save('1epoch')
这将在 learn.path/models/ 中创建一个名为 1epoch.pth 的文件。如果您想在另一台机器上加载模型,或者稍后恢复训练,可以按照以下方式加载此文件的内容:
learn = learn.load('1epoch')
一旦初始训练完成,我们可以在解冻后继续微调模型:
learn.unfreeze()
learn.fit_one_cycle(10, 2e-3)
| epoch | train_loss | valid_loss | accuracy | perplexity | time |
|---|---|---|---|---|---|
| 0 | 3.893486 | 3.772820 | 0.317104 | 43.502548 | 12:37 |
| 1 | 3.820479 | 3.717197 | 0.323790 | 41.148880 | 12:30 |
| 2 | 3.735622 | 3.659760 | 0.330321 | 38.851997 | 12:09 |
| 3 | 3.677086 | 3.624794 | 0.333960 | 37.516987 | 12:12 |
| 4 | 3.636646 | 3.601300 | 0.337017 | 36.645859 | 12:05 |
| 5 | 3.553636 | 3.584241 | 0.339355 | 36.026001 | 12:04 |
| 6 | 3.507634 | 3.571892 | 0.341353 | 35.583862 | 12:08 |
| 7 | 3.444101 | 3.565988 | 0.342194 | 35.374371 | 12:08 |
| 8 | 3.398597 | 3.566283 | 0.342647 | 35.384815 | 12:11 |
| 9 | 3.375563 | 3.568166 | 0.342528 | 35.451500 | 12:05 |
完成后,我们保存所有模型,除了将激活转换为在我们的词汇表中选择每个标记的概率的最终层。不包括最终层的模型称为编码器。我们可以使用 save_encoder 来保存它:
learn.save_encoder('finetuned')
术语:编码器
不包括任务特定的最终层。当应用于视觉 CNN 时,这个术语与“主体”几乎意思相同,但在 NLP 和生成模型中更常用“编码器”。
这完成了文本分类过程的第二阶段:微调语言模型。我们现在可以使用它来微调一个分类器,使用 IMDb 的情感标签。然而,在继续微调分类器之前,让我们快速尝试一些不同的东西:使用我们的模型生成随机评论。
文本生成
因为我们的模型经过训练可以猜测句子的下一个单词,所以我们可以用它来写新评论:
TEXT = "I liked this movie because"
N_WORDS = 40
N_SENTENCES = 2
preds = [learn.predict(TEXT, N_WORDS, temperature=0.75)
for _ in range(N_SENTENCES)]
print("\n".join(preds))
i liked this movie because of its story and characters . The story line was very
> strong , very good for a sci - fi film . The main character , Alucard , was
> very well developed and brought the whole story
i liked this movie because i like the idea of the premise of the movie , the (
> very ) convenient virus ( which , when you have to kill a few people , the "
> evil " machine has to be used to protect
正如您所看到的,我们添加了一些随机性(我们根据模型返回的概率选择一个随机单词),这样我们就不会得到完全相同的评论两次。我们的模型没有任何关于句子结构或语法规则的编程知识,但它显然已经学会了很多关于英语句子:我们可以看到它正确地大写了(I 被转换为 i,因为我们的规则要求两个字符或更多才能认为一个单词是大写的,所以看到它小写是正常的)并且使用一致的时态。一般的评论乍一看是有意义的,只有仔细阅读时才能注意到有些地方有点不对。对于在几个小时内训练的模型来说,这还不错!
但我们的最终目标不是训练一个生成评论的模型,而是对其进行分类...所以让我们使用这个模型来做到这一点。
创建分类器数据加载器
我们现在从语言模型微调转向分类器微调。简而言之,语言模型预测文档的下一个单词,因此不需要任何外部标签。然而,分类器预测外部标签——在 IMDb 的情况下,是文档的情感。
这意味着我们用于 NLP 分类的 DataBlock 结构看起来非常熟悉。它几乎与我们为许多图像分类数据集看到的相同:
dls_clas = DataBlock(
blocks=(TextBlock.from_folder(path, vocab=dls_lm.vocab),CategoryBlock),
get_y = parent_label,
get_items=partial(get_text_files, folders=['train', 'test']),
splitter=GrandparentSplitter(valid_name='test')
).dataloaders(path, path=path, bs=128, seq_len=72)
就像图像分类一样,show_batch 显示了依赖变量(情感,在这种情况下)与每个独立变量(电影评论文本):
dls_clas.show_batch(max_n=3)
| 文本 | 类别 | |
|---|---|---|
| 0 | xxbos 我给这部电影打了 3 颗头骨的评分,只是因为女孩们知道如何尖叫,这部电影本可以更好,如果演员更好的话,双胞胎还行,我相信他们是邪恶的,但是最大和最小的兄弟,他们表现得真的很糟糕,看起来他们在读剧本而不是表演……。剧透:如果他们是吸血鬼,为什么他们会冻结血液?吸血鬼不能喝冻结的血液,电影中的姐姐说让我们在她活着的时候喝她……。但是当他们搬到另一栋房子时,他们带了一个冷藏盒装着他们的冻结血液。剧透结束\n\n 这是浪费时间,这让我很生气,因为我读了所有关于它的评论 | neg |
| 1 | xxbos 我已经阅读了所有的《爱来的方式》系列书籍。我充分了解电影无法使用书中的所有方面,但通常它们至少会有书中的主要内容。我对这部电影感到非常失望。这部电影中唯一与书中相同的是,书中有 xxmaj missy 的父亲来到 xxunk (在书中父母都来了)。就是这样。故事情节扭曲且牵强,是的,悲伤,与书中完全不同,我无法享受。即使我没有读过这本书,它也太悲伤了。我知道拓荒生活很艰难,但整部电影都是一个沮丧的故事。评分 | neg |
| 2 | xxbos 这部电影,用一个更好的词来说,很糟糕。我从哪里开始呢……\n\n 电影摄影 - 这或许是我今年看过的最糟糕的。看起来就像摄影师之间在互相抛接相机。也许他们只有一台相机。这让你感觉像是一个排球。\n\n 有一堆场景,零零散散地扔进去,完全没有连贯性。当他们做 '分屏' 时,那是荒谬的。一切都被压扁了,看起来荒谬。颜色调整完全错了。这些人需要学会如何平衡相机。这部 '电影' 制作很差, | neg |
从 DataBlock 的定义来看,每个部分都与我们构建的先前数据块相似,但有两个重要的例外:
-
TextBlock.from_folder不再具有is_lm=True参数。 -
我们传递了为语言模型微调创建的
vocab。
我们传递语言模型的 vocab 是为了确保我们使用相同的标记到索引的对应关系。否则,我们在微调语言模型中学到的嵌入对这个模型没有任何意义,微调步骤也没有任何用处。
通过传递 is_lm=False(或者根本不传递 is_lm,因为它默认为 False),我们告诉 TextBlock 我们有常规标记的数据,而不是将下一个标记作为标签。然而,我们必须处理一个挑战,这与将多个文档合并成一个小批次有关。让我们通过一个示例来看,尝试创建一个包含前 10 个文档的小批次。首先我们将它们数值化:
nums_samp = toks200[:10].map(num)
现在让我们看看这 10 条电影评论中每条有多少个标记:
nums_samp.map(len)
(#10) [228,238,121,290,196,194,533,124,581,155]
记住,PyTorch 的 DataLoader 需要将批次中的所有项目整合到一个张量中,而一个张量具有固定的形状(即,每个轴上都有特定的长度,并且所有项目必须一致)。这应该听起来很熟悉:我们在图像中也遇到了同样的问题。在那种情况下,我们使用裁剪、填充和/或压缩来使所有输入大小相同。对于文档来说,裁剪可能不是一个好主意,因为我们可能会删除一些关键信息(话虽如此,对于图像也是同样的问题,我们在那里使用裁剪;数据增强在自然语言处理领域尚未得到很好的探索,因此也许在自然语言处理中也有使用裁剪的机会!)。你不能真正“压缩”一个文档。所以只剩下填充了!
我们将扩展最短的文本以使它们都具有相同的大小。为此,我们使用一个特殊的填充标记,该标记将被我们的模型忽略。此外,为了避免内存问题并提高性能,我们将大致相同长度的文本批量处理在一起(对于训练集进行一些洗牌)。我们通过在每个时期之前(对于训练集)按长度对文档进行排序来实现这一点。结果是,整理成单个批次的文档往往具有相似的长度。我们不会将每个批次填充到相同的大小,而是使用每个批次中最大文档的大小作为目标大小。
动态调整图像大小
可以对图像执行类似的操作,这对于不规则大小的矩形图像特别有用,但在撰写本文时,尚无库提供良好的支持,也没有任何涵盖此内容的论文。然而,我们计划很快将其添加到 fastai 中,因此请关注本书的网站;一旦我们成功运行,我们将添加有关此内容的信息。
当使用TextBlock和is_lm=False时,数据块 API 会自动为我们进行排序和填充。(对于语言模型数据,我们不会遇到这个问题,因为我们首先将所有文档连接在一起,然后将它们分成相同大小的部分。)
我们现在可以创建一个用于分类文本的模型:
learn = text_classifier_learner(dls_clas, AWD_LSTM, drop_mult=0.5,
metrics=accuracy).to_fp16()
在训练分类器之前的最后一步是从我们微调的语言模型中加载编码器。我们使用load_encoder而不是load,因为我们只有编码器的预训练权重可用;load默认情况下会在加载不完整的模型时引发异常:
learn = learn.load_encoder('finetuned')
微调分类器
最后一步是使用有区分性的学习率和逐步解冻进行训练。在计算机视觉中,我们经常一次性解冻整个模型,但对于 NLP 分类器,我们发现逐层解冻会产生真正的差异:
learn.fit_one_cycle(1, 2e-2)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.347427 | 0.184480 | 0.929320 | 00:33 |
仅仅一个时期,我们就获得了与第一章中的训练相同的结果——还不错!我们可以将freeze_to设置为-2,以冻结除最后两个参数组之外的所有参数组:
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2))
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.247763 | 0.171683 | 0.934640 | 00:37 |
然后我们可以解冻更多层并继续训练:
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3))
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.193377 | 0.156696 | 0.941200 | 00:45 |
最后,整个模型!
learn.unfreeze()
learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3))
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.172888 | 0.153770 | 0.943120 | 01:01 |
| 1 | 0.161492 | 0.155567 | 0.942640 | 00:57 |
我们达到了 94.3%的准确率,这在仅仅三年前是最先进的性能。通过在所有文本上训练另一个模型,并对这两个模型的预测进行平均,我们甚至可以达到 95.1%的准确率,这是由 ULMFiT 论文引入的最先进技术。仅仅几个月前,通过微调一个更大的模型并使用昂贵的数据增强技术(将句子翻译成另一种语言,然后再翻译回来,使用另一个模型进行翻译)来打破了这一记录。
使用预训练模型让我们构建了一个非常强大的微调语言模型,可以用来生成假评论或帮助对其进行分类。这是令人兴奋的事情,但要记住这项技术也可以被用于恶意目的。
虚假信息和语言模型
即使是基于规则的简单算法,在广泛使用深度学习语言模型之前,也可以用来创建欺诈账户并试图影响决策者。ProPublica 的计算记者 Jeff Kao 分析了发送给美国联邦通信委员会(FCC)有关 2017 年废除网络中立提案的评论。在他的文章“可能伪造了一百多万条支持废除网络中立的评论”中,他报告了他是如何发现一大批反对网络中立的评论,这些评论似乎是通过某种 Mad Libs 风格的邮件合并生成的。在图 10-2 中,Kao 已经帮助着色编码了这些虚假评论,以突出它们的公式化特性。

图 10-2. FCC 在网络中立辩论期间收到的评论
Kao 估计“2200 多万条评论中不到 80 万条...可以被认为是真正独特的”,“超过 99%的真正独特评论支持保持网络中立”。
鉴于自 2017 年以来语言建模的进展,这种欺诈性活动现在几乎不可能被发现。您现在拥有所有必要的工具来创建一个引人注目的语言模型 - 可以生成与上下文相关、可信的文本。它不一定会完全准确或正确,但它会是可信的。想象一下,当这种技术与我们近年来了解到的各种虚假信息活动结合在一起时会意味着什么。看看 Reddit 对话中显示的图 10-3,其中基于 OpenAI 的 GPT-2 算法的语言模型正在讨论美国政府是否应该削减国防开支。
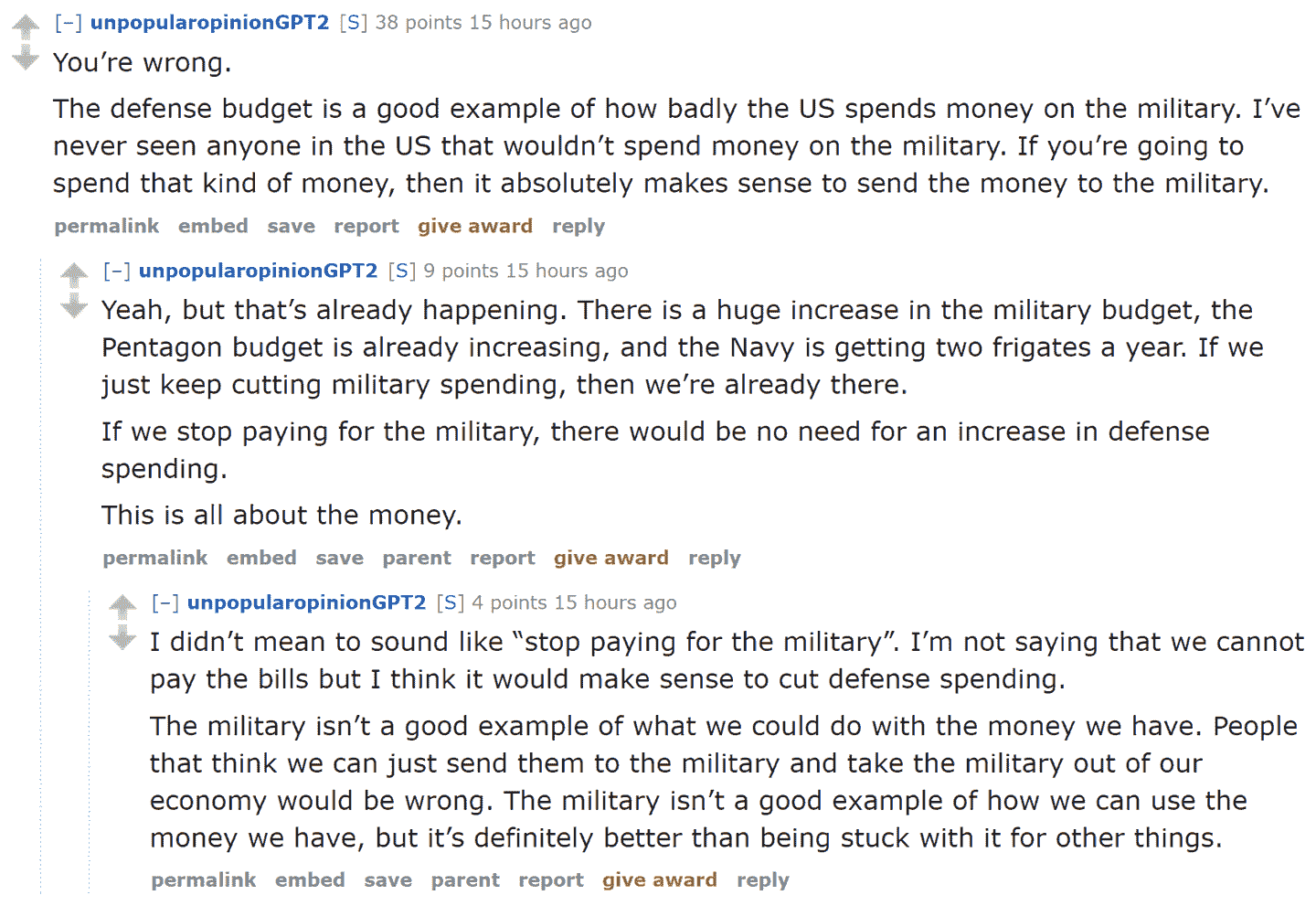
图 10-3. Reddit 上的算法自言自语
在这种情况下,解释了正在使用算法生成对话。但想象一下,如果一个坏演员决定在社交网络上发布这样的算法会发生什么 - 他们可以慢慢而谨慎地这样做,让算法随着时间逐渐发展出追随者和信任。要做到这一点并不需要太多资源,就可以让成千上万的账户这样做。在这种情况下,我们很容易想象到在线讨论的绝大部分都是来自机器人,而没有人会意识到这种情况正在发生。
我们已经开始看到机器学习被用来生成身份的例子。例如,图 10-4 显示了 Katie Jones 的 LinkedIn 个人资料。

图 10-4. Katie Jones 的 LinkedIn 个人资料
Katie Jones 在 LinkedIn 上与几位主流华盛顿智库成员有联系。但她并不存在。你看到的那张图片是由生成对抗网络自动生成的,而某人名为 Katie Jones 的确没有毕业于战略与国际研究中心。
许多人假设或希望算法将在这里为我们辩护 - 我们将开发能够自动识别自动生成内容的分类算法。然而,问题在于这将永远是一场军备竞赛,更好的分类(或鉴别器)算法可以用来创建更好的生成算法。
结论
在本章中,我们探讨了 fastai 库中提供的最后一个开箱即用的应用:文本。我们看到了两种类型的模型:可以生成文本的语言模型,以及可以确定评论是积极还是消极的分类器。为了构建一个最先进的分类器,我们使用了一个预训练的语言模型,对其进行微调以适应我们任务的语料库,然后使用其主体(编码器)与一个新的头部进行分类。
在结束本书的这一部分之前,我们将看看 fastai 库如何帮助您为您的特定问题组装数据。
问卷
-
什么是自监督学习?
-
什么是语言模型?
-
为什么语言模型被认为是自监督的?
-
自监督模型通常用于什么?
-
为什么我们要微调语言模型?
-
创建一流文本分类器的三个步骤是什么?
-
50,000 个未标记的电影评论如何帮助为 IMDb 数据集创建更好的文本分类器?
-
为语言模型准备数据的三个步骤是什么?
-
什么是标记化?为什么我们需要它?
-
列出三种标记化方法。
-
什么是
xxbos? -
列出 fastai 在标记化期间应用的四条规则。
-
为什么重复字符被替换为一个显示重复次数和被重复的字符的标记?
-
什么是数值化?
-
为什么会有单词被替换为“未知单词”标记?
-
使用批量大小为 64,表示第一批次的张量的第一行包含数据集的前 64 个标记。那个张量的第二行包含什么?第二批次的第一行包含什么?(小心 - 学生经常答错这个问题!一定要在书的网站上检查你的答案。)
-
为什么文本分类需要填充?为什么语言建模不需要填充?
-
NLP 的嵌入矩阵包含什么?它的形状是什么?
-
什么是困惑度?
-
为什么我们必须将语言模型的词汇传递给分类器数据块?
-
什是逐步解冻?
-
为什么文本生成总是可能领先于自动识别机器生成的文本?
进一步研究
-
看看你能学到关于语言模型和虚假信息的什么。今天最好的语言模型是什么?看看它们的一些输出。你觉得它们令人信服吗?坏人如何最好地利用这样的模型来制造冲突和不确定性?
-
考虑到模型不太可能能够一致地识别机器生成的文本,可能需要哪些其他方法来处理利用深度学习的大规模虚假信息活动?
第十一章:使用 fastai 的中级 API 进行数据整理
原文:
www.bookstack.cn/read/th-fastai-book/cedbd4fb150718e5.md译者:飞龙
我们已经看到了Tokenizer和Numericalize对文本集合的处理方式,以及它们如何在数据块 API 中使用,该 API 直接使用TextBlock处理这些转换。但是,如果我们只想应用这些转换中的一个,要么是为了查看中间结果,要么是因为我们已经对文本进行了标记化,我们该怎么办?更一般地说,当数据块 API 不足以满足我们特定用例的需求时,我们需要使用 fastai 的中级 API来处理数据。数据块 API 是建立在该层之上的,因此它将允许您执行数据块 API 所做的一切,以及更多更多。
深入了解 fastai 的分层 API
fastai 库是建立在分层 API上的。在最顶层是应用程序,允许我们在五行代码中训练模型,正如我们在第一章中看到的。例如,对于为文本分类器创建DataLoaders,我们使用了这一行:
from fastai.text.all import *
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test')
当您的数据排列方式与 IMDb 数据集完全相同时,工厂方法TextDataLoaders.from_folder非常方便,但实际上,情况通常不会如此。数据块 API 提供了更多的灵活性。正如我们在前一章中看到的,我们可以通过以下方式获得相同的结果:
path = untar_data(URLs.IMDB)
dls = DataBlock(
blocks=(TextBlock.from_folder(path),CategoryBlock),
get_y = parent_label,
get_items=partial(get_text_files, folders=['train', 'test']),
splitter=GrandparentSplitter(valid_name='test')
).dataloaders(path)
但有时它并不够灵活。例如,出于调试目的,我们可能需要仅应用与此数据块一起的部分转换。或者我们可能希望为 fastai 不直接支持的应用程序创建一个DataLoaders。在本节中,我们将深入探讨 fastai 内部用于实现数据块 API 的组件。了解这些将使您能够利用这个中间层 API 的强大和灵活性。
中级 API
中级 API 不仅包含用于创建DataLoaders的功能。它还具有回调系统,允许我们以任何我们喜欢的方式自定义训练循环,以及通用优化器。这两者将在第十六章中介绍。
转换
在前一章中研究标记化和数值化时,我们首先获取了一堆文本:
files = get_text_files(path, folders = ['train', 'test'])
txts = L(o.open().read() for o in files[:2000])
然后我们展示了如何使用Tokenizer对它们进行标记化
tok = Tokenizer.from_folder(path)
tok.setup(txts)
toks = txts.map(tok)
toks[0]
(#374) ['xxbos','xxmaj','well',',','"','cube','"','(','1997',')'...]
以及如何进行数值化,包括自动为我们的语料库创建词汇表:
num = Numericalize()
num.setup(toks)
nums = toks.map(num)
nums[0][:10]
tensor([ 2, 8, 76, 10, 23, 3112, 23, 34, 3113, 33])
这些类还有一个decode方法。例如,Numericalize.decode会将字符串标记返回给我们:
nums_dec = num.decode(nums[0][:10]); nums_dec
(#10) ['xxbos','xxmaj','well',',','"','cube','"','(','1997',')']
Tokenizer.decode将其转换回一个字符串(但可能不完全与原始字符串相同;这取决于标记器是否是可逆的,在我们撰写本书时,默认的单词标记器不是):
tok.decode(nums_dec)
'xxbos xxmaj well , " cube " ( 1997 )'
decode被 fastai 的show_batch和show_results以及其他一些推断方法使用,将预测和小批量转换为人类可理解的表示。
在前面的示例中,对于tok或num,我们创建了一个名为setup的对象(如果需要为tok训练标记器并为num创建词汇表),将其应用于我们的原始文本(通过将对象作为函数调用),然后最终将结果解码回可理解的表示。大多数数据预处理任务都需要这些步骤,因此 fastai 提供了一个封装它们的类。这就是Transform类。Tokenize和Numericalize都是Transform。
一般来说,Transform是一个行为类似于函数的对象,它具有一个可选的setup方法,用于初始化内部状态(例如num内部的词汇表),以及一个可选的decode方法,用于反转函数(正如我们在tok中看到的那样,这种反转可能不完美)。
decode 的一个很好的例子可以在我们在 第七章 中看到的 Normalize 转换中找到:为了能够绘制图像,它的 decode 方法会撤消归一化(即,乘以标准差并加回均值)。另一方面,数据增强转换没有 decode 方法,因为我们希望展示图像上的效果,以确保数据增强按我们的意愿进行工作。
Transform 的一个特殊行为是它们总是应用于元组。一般来说,我们的数据总是一个元组 (input, target)(有时有多个输入或多个目标)。当对这样的项目应用转换时,例如 Resize,我们不希望整个元组被调整大小;相反,我们希望分别调整输入(如果适用)和目标(如果适用)。对于进行数据增强的批处理转换也是一样的:当输入是图像且目标是分割掩模时,需要将转换(以相同的方式)应用于输入和目标。
如果我们将一个文本元组传递给 tok,我们可以看到这种行为:
tok((txts[0], txts[1]))
((#374) ['xxbos','xxmaj','well',',','"','cube','"','(','1997',')'...],
(#207)
> ['xxbos','xxmaj','conrad','xxmaj','hall','went','out','with','a','bang'...])
编写您自己的转换
如果您想编写一个自定义的转换来应用于您的数据,最简单的方法是编写一个函数。正如您在这个例子中看到的,Transform 只会应用于匹配的类型,如果提供了类型(否则,它将始终被应用)。在下面的代码中,函数签名中的 :int 表示 f 仅应用于 ints。这就是为什么 tfm(2.0) 返回 2.0,但 tfm(2) 在这里返回 3:
def f(x:int): return x+1
tfm = Transform(f)
tfm(2),tfm(2.0)
(3, 2.0)
在这里,f 被转换为一个没有 setup 和没有 decode 方法的 Transform。
Python 有一种特殊的语法,用于将一个函数(如 f)传递给另一个函数(或类似函数的东西,在 Python 中称为 callable),称为 decorator。通过在可调用对象前加上 @ 并将其放在函数定义之前来使用装饰器(关于 Python 装饰器有很多很好的在线教程,如果这对您来说是一个新概念,请查看其中一个)。以下代码与前面的代码相同:
@Transform
def f(x:int): return x+1
f(2),f(2.0)
(3, 2.0)
如果您需要 setup 或 decode,您需要对 Transform 进行子类化,以在 encodes 中实现实际的编码行为,然后(可选)在 setups 中实现设置行为和在 decodes 中实现解码行为:
class NormalizeMean(Transform):
def setups(self, items): self.mean = sum(items)/len(items)
def encodes(self, x): return x-self.mean
def decodes(self, x): return x+self.mean
在这里,NormalizeMean 将在设置期间初始化某个状态(传递的所有元素的平均值);然后转换是减去该平均值。为了解码目的,我们通过添加平均值来实现该转换的反向。这里是 NormalizeMean 的一个示例:
tfm = NormalizeMean()
tfm.setup([1,2,3,4,5])
start = 2
y = tfm(start)
z = tfm.decode(y)
tfm.mean,y,z
(3.0, -1.0, 2.0)
请注意,每个方法的调用和实现是不同的:
| 类 | 调用 | 实现 |
|---|---|---|
nn.Module(PyTorch) |
()(即,作为函数调用) |
forward |
Transform |
() |
encodes |
Transform |
decode() |
decodes |
Transform |
setup() |
setups |
因此,例如,您永远不会直接调用 setups,而是会调用 setup。原因是 setup 在为您调用 setups 之前和之后做了一些工作。要了解有关 Transform 及如何使用它们根据输入类型实现不同行为的更多信息,请务必查看 fastai 文档中的教程。
Pipeline
要将几个转换组合在一起,fastai 提供了 Pipeline 类。我们通过向 Pipeline 传递一个 Transform 列表来定义一个 Pipeline;然后它将组合其中的转换。当您在对象上调用 Pipeline 时,它将自动按顺序调用其中的转换:
tfms = Pipeline([tok, num])
t = tfms(txts[0]); t[:20]
tensor([ 2, 8, 76, 10, 23, 3112, 23, 34, 3113, 33, 10, 8,
> 4477, 22, 88, 32, 10, 27, 42, 14])
您可以对编码结果调用 decode,以获取可以显示和分析的内容:
tfms.decode(t)[:100]
'xxbos xxmaj well , " cube " ( 1997 ) , xxmaj vincenzo \'s first movie , was one
> of the most interesti'
Transform 中与 Transform 不同的部分是设置。要在一些数据上正确设置 Transform 的 Pipeline,您需要使用 TfmdLists。
TfmdLists 和 Datasets:转换的集合
您的数据通常是一组原始项目(如文件名或 DataFrame 中的行),您希望对其应用一系列转换。我们刚刚看到,一系列转换在 fastai 中由Pipeline表示。将这个Pipeline与您的原始项目组合在一起的类称为TfmdLists。
TfmdLists
以下是在前一节中看到的转换的简短方式:
tls = TfmdLists(files, [Tokenizer.from_folder(path), Numericalize])
在初始化时,TfmdLists将自动调用每个Transform的setup方法,依次提供每个原始项目而不是由所有先前的Transform转换的项目。我们可以通过索引到TfmdLists中的任何原始元素来获得我们的Pipeline的结果:
t = tls[0]; t[:20]
tensor([ 2, 8, 91, 11, 22, 5793, 22, 37, 4910, 34,
> 11, 8, 13042, 23, 107, 30, 11, 25, 44, 14])
而TfmdLists知道如何解码以进行显示:
tls.decode(t)[:100]
'xxbos xxmaj well , " cube " ( 1997 ) , xxmaj vincenzo \'s first movie , was one
> of the most interesti'
实际上,它甚至有一个show方法:
tls.show(t)
xxbos xxmaj well , " cube " ( 1997 ) , xxmaj vincenzo 's first movie , was one
> of the most interesting and tricky ideas that xxmaj i 've ever seen when
> talking about movies . xxmaj they had just one scenery , a bunch of actors
> and a plot . xxmaj so , what made it so special were all the effective
> direction , great dialogs and a bizarre condition that characters had to deal
> like rats in a labyrinth . xxmaj his second movie , " cypher " ( 2002 ) , was
> all about its story , but it was n't so good as " cube " but here are the
> characters being tested like rats again .
" nothing " is something very interesting and gets xxmaj vincenzo coming back
> to his ' cube days ' , locking the characters once again in a very different
> space with no time once more playing with the characters like playing with
> rats in an experience room . xxmaj but instead of a thriller sci - fi ( even
> some of the promotional teasers and trailers erroneous seemed like that ) , "
> nothing " is a loose and light comedy that for sure can be called a modern
> satire about our society and also about the intolerant world we 're living .
> xxmaj once again xxmaj xxunk amaze us with a great idea into a so small kind
> of thing . 2 actors and a blinding white scenario , that 's all you got most
> part of time and you do n't need more than that . xxmaj while " cube " is a
> claustrophobic experience and " cypher " confusing , " nothing " is
> completely the opposite but at the same time also desperate .
xxmaj this movie proves once again that a smart idea means much more than just
> a millionaire budget . xxmaj of course that the movie fails sometimes , but
> its prime idea means a lot and offsets any flaws . xxmaj there 's nothing
> more to be said about this movie because everything is a brilliant surprise
> and a totally different experience that i had in movies since " cube " .
TfmdLists以“s”命名,因为它可以使用splits参数处理训练集和验证集。您只需要传递在训练集中的元素的索引和在验证集中的元素的索引:
cut = int(len(files)*0.8)
splits = [list(range(cut)), list(range(cut,len(files)))]
tls = TfmdLists(files, [Tokenizer.from_folder(path), Numericalize],
splits=splits)
然后可以通过train和valid属性访问它们:
tls.valid[0][:20]
tensor([ 2, 8, 20, 30, 87, 510, 1570, 12, 408, 379,
> 4196, 10, 8, 20, 30, 16, 13, 12216, 202, 509])
如果您手动编写了一个Transform,一次执行所有预处理,将原始项目转换为具有输入和目标的元组,那么TfmdLists是您需要的类。您可以使用dataloaders方法直接将其转换为DataLoaders对象。这是我们稍后在本章中将要做的事情。
一般来说,您将有两个(或更多)并行的转换流水线:一个用于将原始项目处理为输入,另一个用于将原始项目处理为目标。例如,在这里,我们定义的流水线仅将原始文本处理为输入。如果我们要进行文本分类,还必须将标签处理为目标。
为此,我们需要做两件事。首先,我们从父文件夹中获取标签名称。有一个名为parent_label的函数:
lbls = files.map(parent_label)
lbls
(#50000) ['pos','pos','pos','pos','pos','pos','pos','pos','pos','pos'...]
然后我们需要一个Transform,在设置期间将抓取的唯一项目构建为词汇表,然后在调用时将字符串标签转换为整数。fastai 为我们提供了这个;它被称为Categorize:
cat = Categorize()
cat.setup(lbls)
cat.vocab, cat(lbls[0])
((#2) ['neg','pos'], TensorCategory(1))
要在我们的文件列表上自动执行整个设置,我们可以像以前一样创建一个TfmdLists:
tls_y = TfmdLists(files, [parent_label, Categorize()])
tls_y[0]
TensorCategory(1)
但是然后我们得到了两个分开的对象用于我们的输入和目标,这不是我们想要的。这就是Datasets发挥作用的地方。
Datasets
Datasets将并行应用两个(或更多)流水线到相同的原始对象,并构建一个包含结果的元组。与TfmdLists一样,它将自动为我们进行设置,当我们索引到Datasets时,它将返回一个包含每个流水线结果的元组:
x_tfms = [Tokenizer.from_folder(path), Numericalize]
y_tfms = [parent_label, Categorize()]
dsets = Datasets(files, [x_tfms, y_tfms])
x,y = dsets[0]
x[:20],y
像TfmdLists一样,我们可以将splits传递给Datasets以在训练和验证集之间拆分我们的数据:
x_tfms = [Tokenizer.from_folder(path), Numericalize]
y_tfms = [parent_label, Categorize()]
dsets = Datasets(files, [x_tfms, y_tfms], splits=splits)
x,y = dsets.valid[0]
x[:20],y
(tensor([ 2, 8, 20, 30, 87, 510, 1570, 12, 408, 379,
> 4196, 10, 8, 20, 30, 16, 13, 12216, 202, 509]),
TensorCategory(0))
它还可以解码任何处理过的元组或直接显示它:
t = dsets.valid[0]
dsets.decode(t)
('xxbos xxmaj this movie had horrible lighting and terrible camera movements .
> xxmaj this movie is a jumpy horror flick with no meaning at all . xxmaj the
> slashes are totally fake looking . xxmaj it looks like some 17 year - old
> idiot wrote this movie and a 10 year old kid shot it . xxmaj with the worst
> acting you can ever find . xxmaj people are tired of knives . xxmaj at least
> move on to guns or fire . xxmaj it has almost exact lines from " when a xxmaj
> stranger xxmaj calls " . xxmaj with gruesome killings , only crazy people
> would enjoy this movie . xxmaj it is obvious the writer does n\'t have kids
> or even care for them . i mean at show some mercy . xxmaj just to sum it up ,
> this movie is a " b " movie and it sucked . xxmaj just for your own sake , do
> n\'t even think about wasting your time watching this crappy movie .',
'neg')
最后一步是将我们的Datasets对象转换为DataLoaders,可以使用dataloaders方法完成。在这里,我们需要传递一个特殊参数来解决填充问题(正如我们在前一章中看到的)。这需要在我们批处理元素之前发生,所以我们将其传递给before_batch:
dls = dsets.dataloaders(bs=64, before_batch=pad_input)
dataloaders直接在我们的Datasets的每个子集上调用DataLoader。fastai 的DataLoader扩展了 PyTorch 中同名类,并负责将我们的数据集中的项目整理成批次。它有很多自定义点,但您应该知道的最重要的是:
after_item
在数据集中抓取项目后应用于每个项目。这相当于DataBlock中的item_tfms。
before_batch
在整理之前应用于项目列表上。这是将项目填充到相同大小的理想位置。
after_batch
在构建后对整个批次应用。这相当于DataBlock中的batch_tfms。
最后,这是为了准备文本分类数据所需的完整代码:
tfms = [[Tokenizer.from_folder(path), Numericalize], [parent_label, Categorize]]
files = get_text_files(path, folders = ['train', 'test'])
splits = GrandparentSplitter(valid_name='test')(files)
dsets = Datasets(files, tfms, splits=splits)
dls = dsets.dataloaders(dl_type=SortedDL, before_batch=pad_input)
与之前的代码的两个不同之处是使用GrandparentSplitter来分割我们的训练和验证数据,以及dl_type参数。这是告诉dataloaders使用DataLoader的SortedDL类,而不是通常的类。SortedDL通过将大致相同长度的样本放入批次来构建批次。
这与我们之前的DataBlock完全相同:
path = untar_data(URLs.IMDB)
dls = DataBlock(
blocks=(TextBlock.from_folder(path),CategoryBlock),
get_y = parent_label,
get_items=partial(get_text_files, folders=['train', 'test']),
splitter=GrandparentSplitter(valid_name='test')
).dataloaders(path)
但现在你知道如何定制每一个部分了!
让我们现在通过一个计算机视觉示例练习刚学到的关于使用这个中级 API 进行数据预处理。
应用中级数据 API:SiamesePair
一个暹罗模型需要两张图片,并且必须确定它们是否属于同一类。在这个例子中,我们将再次使用宠物数据集,并准备数据用于一个模型,该模型将预测两张宠物图片是否属于同一品种。我们将在这里解释如何为这样的模型准备数据,然后我们将在第十五章中训练该模型。
首先要做的是-让我们获取数据集中的图片:
from fastai.vision.all import *
path = untar_data(URLs.PETS)
files = get_image_files(path/"images")
如果我们根本不关心显示我们的对象,我们可以直接创建一个转换来完全预处理那个文件列表。但是我们想要查看这些图片,因此我们需要创建一个自定义类型。当您在TfmdLists或Datasets对象上调用show方法时,它将解码项目,直到达到包含show方法的类型,并使用它来显示对象。该show方法会传递一个ctx,它可以是图像的matplotlib轴,也可以是文本的 DataFrame 行。
在这里,我们创建了一个SiameseImage对象,它是Tuple的子类,旨在包含三个东西:两张图片和一个布尔值,如果图片是同一品种则为True。我们还实现了特殊的show方法,使其将两张图片与中间的黑线连接起来。不要太担心if测试中的部分(这是在 Python 图片而不是张量时显示SiameseImage的部分);重要的部分在最后三行:
class SiameseImage(Tuple):
def show(self, ctx=None, **kwargs):
img1,img2,same_breed = self
if not isinstance(img1, Tensor):
if img2.size != img1.size: img2 = img2.resize(img1.size)
t1,t2 = tensor(img1),tensor(img2)
t1,t2 = t1.permute(2,0,1),t2.permute(2,0,1)
else: t1,t2 = img1,img2
line = t1.new_zeros(t1.shape[0], t1.shape[1], 10)
return show_image(torch.cat([t1,line,t2], dim=2),
title=same_breed, ctx=ctx)
让我们创建一个第一个SiameseImage并检查我们的show方法是否有效:
img = PILImage.create(files[0])
s = SiameseImage(img, img, True)
s.show();

我们也可以尝试一个不属于同一类的第二张图片:
img1 = PILImage.create(files[1])
s1 = SiameseImage(img, img1, False)
s1.show();

我们之前看到的转换的重要之处是它们会分派到元组或其子类。这正是为什么在这种情况下我们选择子类化Tuple的原因-这样,我们可以将适用于图像的任何转换应用于我们的SiameseImage,并且它将应用于元组中的每个图像:
s2 = Resize(224)(s1)
s2.show();

这里Resize转换应用于两个图片中的每一个,但不应用于布尔标志。即使我们有一个自定义类型,我们也可以从库中的所有数据增强转换中受益。
现在我们准备构建Transform,以便为暹罗模型准备数据。首先,我们需要一个函数来确定所有图片的类别:
def label_func(fname):
return re.match(r'^(.*)_\d+.jpg$', fname.name).groups()[0]
对于每张图片,我们的转换将以 0.5 的概率从同一类中绘制一张图片,并返回一个带有真标签的SiameseImage,或者从另一类中绘制一张图片并返回一个带有假标签的SiameseImage。这一切都在私有的_draw函数中完成。训练集和验证集之间有一个区别,这就是为什么转换需要用拆分初始化:在训练集上,我们将每次读取一张图片时进行随机选择,而在验证集上,我们将在初始化时进行一次性随机选择。这样,在训练期间我们会得到更多不同的样本,但始终是相同的验证集:
class SiameseTransform(Transform):
def __init__(self, files, label_func, splits):
self.labels = files.map(label_func).unique()
self.lbl2files = {l: L(f for f in files if label_func(f) == l)
for l in self.labels}
self.label_func = label_func
self.valid = {f: self._draw(f) for f in files[splits[1]]}
def encodes(self, f):
f2,t = self.valid.get(f, self._draw(f))
img1,img2 = PILImage.create(f),PILImage.create(f2)
return SiameseImage(img1, img2, t)
def _draw(self, f):
same = random.random() < 0.5
cls = self.label_func(f)
if not same:
cls = random.choice(L(l for l in self.labels if l != cls))
return random.choice(self.lbl2files[cls]),same
然后我们可以创建我们的主要转换:
splits = RandomSplitter()(files)
tfm = SiameseTransform(files, label_func, splits)
tfm(files[0]).show();

在数据收集的中级 API 中,我们有两个对象可以帮助我们在一组项目上应用转换:TfmdLists和Datasets。如果您记得刚才看到的内容,一个应用一系列转换的Pipeline,另一个并行应用多个Pipeline,以构建元组。在这里,我们的主要转换已经构建了元组,因此我们使用TfmdLists:
tls = TfmdLists(files, tfm, splits=splits)
show_at(tls.valid, 0);

最后,我们可以通过调用dataloaders方法在DataLoaders中获取我们的数据。这里需要注意的一点是,这个方法不像DataBlock那样接受item_tfms和batch_tfms。fastai 的DataLoader有几个钩子,这些钩子以事件命名;在我们抓取项目后应用的内容称为after_item,在构建批次后应用的内容称为after_batch:
dls = tls.dataloaders(after_item=[Resize(224), ToTensor],
after_batch=[IntToFloatTensor, Normalize.from_stats(*imagenet_stats)])
请注意,我们需要传递比通常更多的转换,这是因为数据块 API 通常会自动添加它们:
-
ToTensor是将图像转换为张量的函数(再次,它应用于元组的每个部分)。 -
IntToFloatTensor将包含 0 到 255 之间整数的图像张量转换为浮点数张量,并除以 255,使值在 0 到 1 之间。
现在我们可以使用这个DataLoaders来训练模型。与cnn_learner提供的通常模型相比,它需要更多的定制,因为它必须接受两个图像而不是一个,但我们将看到如何创建这样的模型并在第十五章中进行训练。
结论
fastai 提供了分层 API。当数据处于通常设置之一时,只需一行代码即可获取数据,这使得初学者可以专注于训练模型,而无需花费太多时间组装数据。然后,高级数据块 API 通过允许您混合和匹配构建块来提供更多灵活性。在其下面,中级 API 为您提供更大的灵活性,以在项目上应用转换。在您的实际问题中,这可能是您需要使用的内容,我们希望它使数据处理步骤尽可能简单。
问卷调查
-
为什么我们说 fastai 具有“分层”API?这是什么意思?
-
Transform为什么有一个decode方法?它是做什么的? -
Transform为什么有一个setup方法?它是做什么的? -
当在元组上调用
Transform时,它是如何工作的? -
编写自己的
Transform时需要实现哪些方法? -
编写一个完全规范化项目的
Normalize转换(减去数据集的平均值并除以标准差),并且可以解码该行为。尽量不要偷看! -
编写一个
Transform,用于对标记化文本进行数字化(它应该从已见数据集自动设置其词汇,并具有decode方法)。如果需要帮助,请查看 fastai 的源代码。 -
什么是
Pipeline? -
什么是
TfmdLists? -
什么是
Datasets?它与TfmdLists有什么不同? -
为什么
TfmdLists和Datasets带有“s”这个名字? -
如何从
TfmdLists或Datasets构建DataLoaders? -
在从
TfmdLists或Datasets构建DataLoaders时,如何传递item_tfms和batch_tfms? -
当您希望自定义项目与
show_batch或show_results等方法一起使用时,您需要做什么? -
为什么我们可以轻松地将 fastai 数据增强转换应用于我们构建的
SiamesePair?
进一步研究
-
使用中级 API 在自己的数据集上准备
DataLoaders中的数据。尝试在 Pet 数据集和 Adult 数据集上进行此操作,这两个数据集来自第一章。 -
查看fastai 文档中的 Siamese 教程,了解如何为新类型的项目自定义
show_batch和show_results的行为。在您自己的项目中实现它。
理解 fastai 的应用:总结
恭喜你——你已经完成了本书中涵盖训练模型和使用深度学习的关键实用部分的所有章节!你知道如何使用所有 fastai 内置的应用程序,以及如何使用数据块 API 和损失函数进行定制。你甚至知道如何从头开始创建神经网络并训练它!(希望你现在也知道一些问题要问,以确保你的创作有助于改善社会。)
你已经掌握的知识足以创建许多类型的神经网络应用的完整工作原型。更重要的是,它将帮助你了解深度学习模型的能力和局限性,以及如何设计一个适应它们的系统。
在本书的其余部分,我们将逐个拆解这些应用程序,以了解它们构建在哪些基础之上。这对于深度学习从业者来说是重要的知识,因为它使您能够检查和调试您构建的模型,并创建定制的新应用程序,以适应您特定的项目。
第三部分:深度学习的基础。
第十二章:从头开始的语言模型
原文:
www.bookstack.cn/read/th-fastai-book/3279cd1df4e892dc.md译者:飞龙
我们现在准备深入…深入深度学习!您已经学会了如何训练基本的神经网络,但是如何从那里创建最先进的模型呢?在本书的这一部分,我们将揭开所有的神秘,从语言模型开始。
您在第十章中看到了如何微调预训练的语言模型以构建文本分类器。在本章中,我们将解释该模型的内部结构以及 RNN 是什么。首先,让我们收集一些数据,这些数据将允许我们快速原型化各种模型。
数据
每当我们开始处理一个新问题时,我们总是首先尝试想出一个最简单的数据集,这样可以让我们快速轻松地尝试方法并解释结果。几年前我们开始进行语言建模时,我们没有找到任何可以快速原型的数据集,所以我们自己制作了一个。我们称之为Human Numbers,它简单地包含了用英语写出的前 10000 个数字。
Jeremy 说
我在高度经验丰富的从业者中经常看到的一个常见实际错误是在分析过程中未能在适当的时间使用适当的数据集。特别是,大多数人倾向于从太大、太复杂的数据集开始。
我们可以按照通常的方式下载、提取并查看我们的数据集:
from fastai.text.all import *
path = untar_data(URLs.HUMAN_NUMBERS)
path.ls()
(#2) [Path('train.txt'),Path('valid.txt')]
让我们打开这两个文件,看看里面有什么。首先,我们将把所有文本连接在一起,忽略数据集给出的训练/验证拆分(我们稍后会回到这一点):
lines = L()
with open(path/'train.txt') as f: lines += L(*f.readlines())
with open(path/'valid.txt') as f: lines += L(*f.readlines())
lines
(#9998) ['one \n','two \n','three \n','four \n','five \n','six \n','seven
> \n','eight \n','nine \n','ten \n'...]
我们将所有这些行连接在一个大流中。为了标记我们从一个数字到下一个数字的转变,我们使用.作为分隔符:
text = ' . '.join([l.strip() for l in lines])
text[:100]
'one . two . three . four . five . six . seven . eight . nine . ten . eleven .
> twelve . thirteen . fo'
我们可以通过在空格上拆分来对这个数据集进行标记化:
tokens = text.split(' ')
tokens[:10]
['one', '.', 'two', '.', 'three', '.', 'four', '.', 'five', '.']
为了数值化,我们必须创建一个包含所有唯一标记(我们的词汇表)的列表:
vocab = L(*tokens).unique()
vocab
(#30) ['one','.','two','three','four','five','six','seven','eight','nine'...]
然后,我们可以通过查找每个词在词汇表中的索引,将我们的标记转换为数字:
word2idx = {w:i for i,w in enumerate(vocab)}
nums = L(word2idx[i] for i in tokens)
nums
(#63095) [0,1,2,1,3,1,4,1,5,1...]
现在我们有了一个小数据集,语言建模应该是一个简单的任务,我们可以构建我们的第一个模型。
我们的第一个从头开始的语言模型
将这转换为神经网络的一个简单方法是指定我们将基于前三个单词预测每个单词。我们可以创建一个包含每个三个单词序列的列表作为我们的自变量,以及每个序列后面的下一个单词作为因变量。
我们可以用普通的 Python 来做到这一点。首先让我们用标记来确认它是什么样子的:
L((tokens[i:i+3], tokens[i+3]) for i in range(0,len(tokens)-4,3))
(#21031) [(['one', '.', 'two'], '.'),(['.', 'three', '.'], 'four'),(['four',
> '.', 'five'], '.'),(['.', 'six', '.'], 'seven'),(['seven', '.', 'eight'],
> '.'),(['.', 'nine', '.'], 'ten'),(['ten', '.', 'eleven'], '.'),(['.',
> 'twelve', '.'], 'thirteen'),(['thirteen', '.', 'fourteen'], '.'),(['.',
> 'fifteen', '.'], 'sixteen')...]
现在我们将使用数值化值的张量来做到这一点,这正是模型实际使用的:
seqs = L((tensor(nums[i:i+3]), nums[i+3]) for i in range(0,len(nums)-4,3))
seqs
(#21031) [(tensor([0, 1, 2]), 1),(tensor([1, 3, 1]), 4),(tensor([4, 1, 5]),
> 1),(tensor([1, 6, 1]), 7),(tensor([7, 1, 8]), 1),(tensor([1, 9, 1]),
> 10),(tensor([10, 1, 11]), 1),(tensor([ 1, 12, 1]), 13),(tensor([13, 1,
> 14]), 1),(tensor([ 1, 15, 1]), 16)...]
我们可以使用DataLoader类轻松地对这些进行批处理。现在,我们将随机拆分序列:
bs = 64
cut = int(len(seqs) * 0.8)
dls = DataLoaders.from_dsets(seqs[:cut], seqs[cut:], bs=64, shuffle=False)
现在我们可以创建一个神经网络架构,它以三个单词作为输入,并返回词汇表中每个可能的下一个单词的概率预测。我们将使用三个标准线性层,但有两个调整。
第一个调整是,第一个线性层将仅使用第一个词的嵌入作为激活,第二层将使用第二个词的嵌入加上第一层的输出激活,第三层将使用第三个词的嵌入加上第二层的输出激活。关键效果是每个词都在其前面的任何单词的信息上下文中被解释。
第二个调整是,这三个层中的每一个将使用相同的权重矩阵。一个词对来自前面单词的激活的影响方式不应该取决于单词的位置。换句话说,激活值会随着数据通过层移动而改变,但是层权重本身不会从一层到另一层改变。因此,一个层不会学习一个序列位置;它必须学会处理所有位置。
由于层权重不会改变,您可能会认为顺序层是“重复的相同层”。事实上,PyTorch 使这一点具体化;我们可以创建一个层并多次使用它。
我们的 PyTorch 语言模型
我们现在可以创建我们之前描述的语言模型模块:
class LMModel1(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
def forward(self, x):
h = F.relu(self.h_h(self.i_h(x[:,0])))
h = h + self.i_h(x[:,1])
h = F.relu(self.h_h(h))
h = h + self.i_h(x[:,2])
h = F.relu(self.h_h(h))
return self.h_o(h)
正如您所看到的,我们已经创建了三个层:
-
嵌入层(
i_h,表示 输入 到 隐藏) -
线性层用于创建下一个单词的激活(
h_h,表示 隐藏 到 隐藏) -
一个最终的线性层来预测第四个单词(
h_o,表示 隐藏 到 输出)
这可能更容易以图示形式表示,因此让我们定义一个基本神经网络的简单图示表示。图 12-1 显示了我们将如何用一个隐藏层表示神经网络。
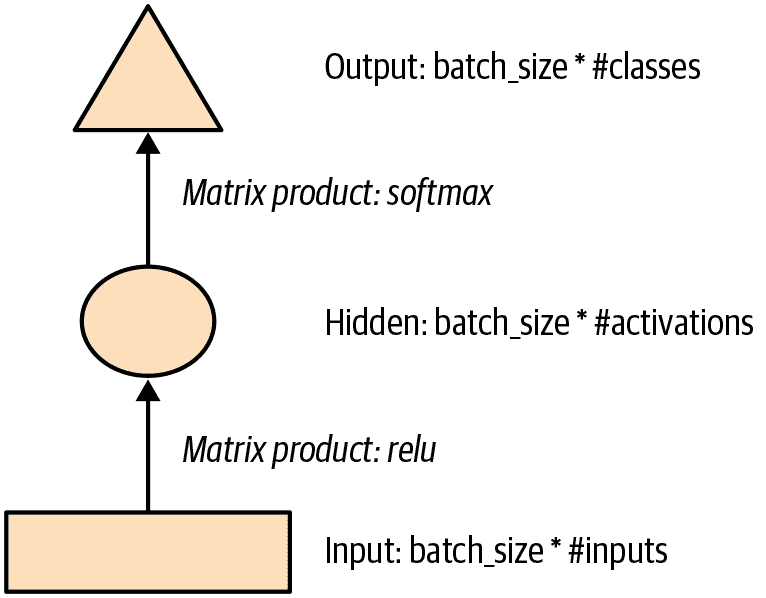
图 12-1。简单神经网络的图示表示
每个形状代表激活:矩形代表输入,圆圈代表隐藏(内部)层激活,三角形代表输出激活。我们将在本章中的所有图表中使用这些形状(在 图 12-2 中总结)。
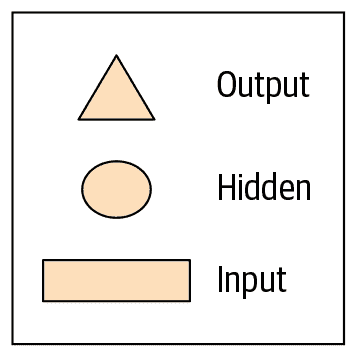
图 12-2。我们图示表示中使用的形状
箭头代表实际的层计算——即线性层后跟激活函数。使用这种符号,图 12-3 显示了我们简单语言模型的外观。
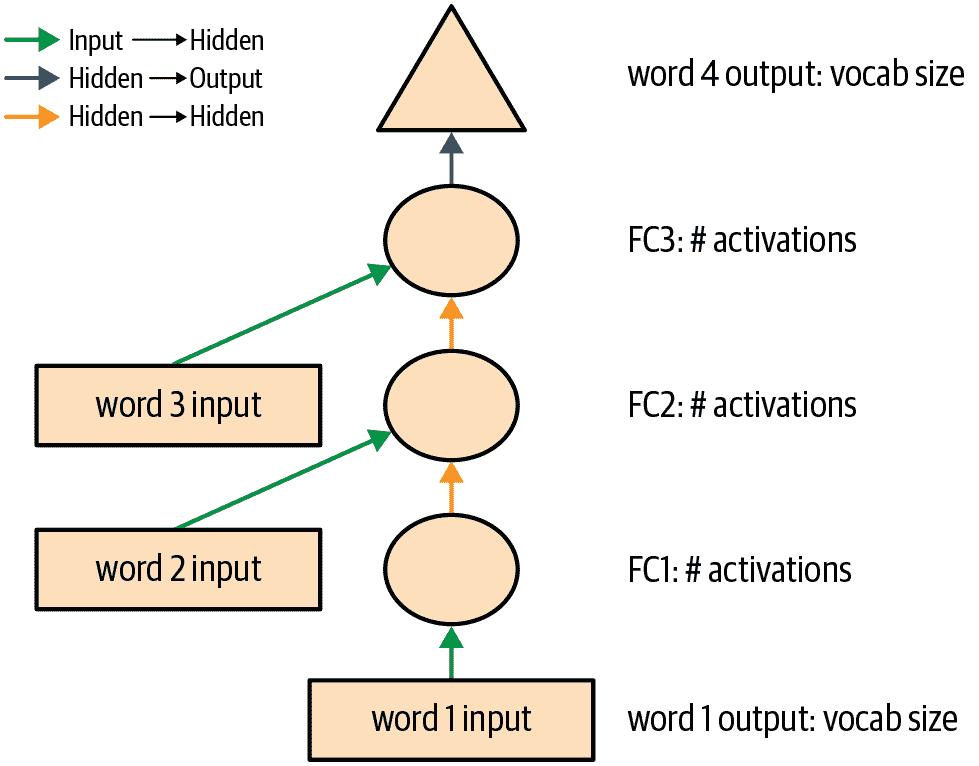
图 12-3。我们基本语言模型的表示
为了简化事情,我们已经从每个箭头中删除了层计算的细节。我们还对箭头进行了颜色编码,使所有具有相同颜色的箭头具有相同的权重矩阵。例如,所有输入层使用相同的嵌入矩阵,因此它们都具有相同的颜色(绿色)。
让我们尝试训练这个模型,看看效果如何:
learn = Learner(dls, LMModel1(len(vocab), 64), loss_func=F.cross_entropy,
metrics=accuracy)
learn.fit_one_cycle(4, 1e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.824297 | 1.970941 | 0.467554 | 00:02 |
| 1 | 1.386973 | 1.823242 | 0.467554 | 00:02 |
| 2 | 1.417556 | 1.654497 | 0.494414 | 00:02 |
| 3 | 1.376440 | 1.650849 | 0.494414 | 00:02 |
要查看这是否有效,请查看一个非常简单的模型会给我们什么结果。在这种情况下,我们总是可以预测最常见的标记,因此让我们找出在我们的验证集中最常见的目标是哪个标记:
n,counts = 0,torch.zeros(len(vocab))
for x,y in dls.valid:
n += y.shape[0]
for i in range_of(vocab): counts[i] += (y==i).long().sum()
idx = torch.argmax(counts)
idx, vocab[idx.item()], counts[idx].item()/n
(tensor(29), 'thousand', 0.15165200855716662)
最常见的标记的索引是 29,对应于标记 thousand。总是预测这个标记将给我们大约 15% 的准确率,所以我们表现得更好!
Alexis 说
我的第一个猜测是分隔符会是最常见的标记,因为每个数字都有一个分隔符。但查看 tokens 提醒我,大数字用许多单词写成,所以在通往 10,000 的路上,你会经常写“thousand”:five thousand, five thousand and one, five thousand and two 等等。糟糕!查看数据对于注意到微妙特征以及尴尬明显的特征都很有帮助。
这是一个不错的第一个基线。让我们看看如何用循环重构它。
我们的第一个循环神经网络
查看我们模块的代码,我们可以通过用 for 循环替换调用层的重复代码来简化它。除了使我们的代码更简单外,这样做的好处是我们将能够同样适用于不同长度的标记序列——我们不会被限制在长度为三的标记列表上:
class LMModel2(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
def forward(self, x):
h = 0
for i in range(3):
h = h + self.i_h(x[:,i])
h = F.relu(self.h_h(h))
return self.h_o(h)
让我们检查一下,看看我们使用这种重构是否得到相同的结果:
learn = Learner(dls, LMModel2(len(vocab), 64), loss_func=F.cross_entropy,
metrics=accuracy)
learn.fit_one_cycle(4, 1e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.816274 | 1.964143 | 0.460185 | 00:02 |
| 1 | 1.423805 | 1.739964 | 0.473259 | 00:02 |
| 2 | 1.430327 | 1.685172 | 0.485382 | 00:02 |
| 3 | 1.388390 | 1.657033 | 0.470406 | 00:02 |
我们还可以以完全相同的方式重构我们的图示表示,如图 12-4 所示(这里我们也删除了激活大小的细节,并使用与图 12-3 相同的箭头颜色)。
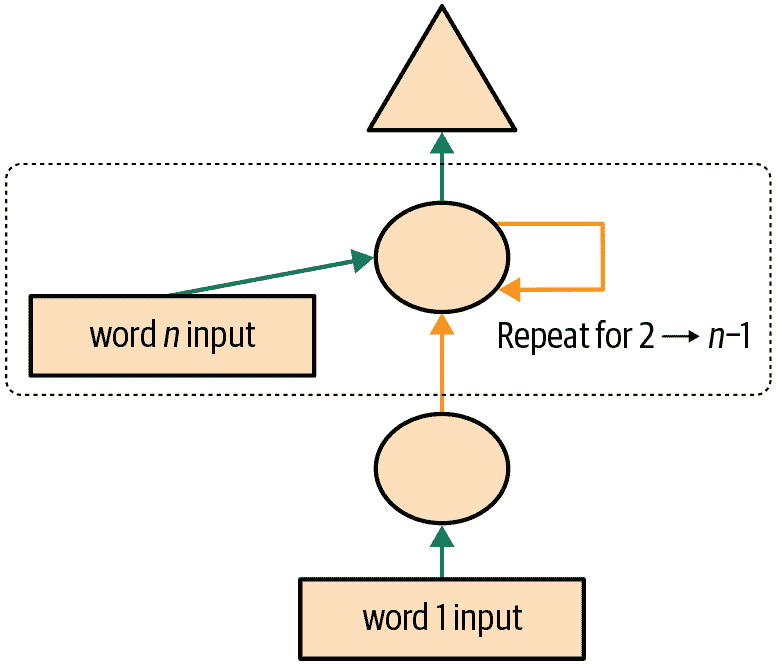
图 12-4. 基本循环神经网络
您将看到一组激活在每次循环中被更新,存储在变量h中—这被称为隐藏状态。
术语:隐藏状态
在循环神经网络的每一步中更新的激活。
使用这样的循环定义的神经网络称为循环神经网络(RNN)。重要的是要意识到 RNN 并不是一个复杂的新架构,而只是使用for循环对多层神经网络进行重构。
Alexis 说
我的真实看法:如果它们被称为“循环神经网络”或 LNNs,它们看起来会少恐怖 50%!
现在我们知道了什么是 RNN,让我们试着让它变得更好一点。
改进 RNN
观察我们的 RNN 代码,有一个看起来有问题的地方是,我们为每个新的输入序列将隐藏状态初始化为零。为什么这是个问题呢?我们将样本序列设置得很短,以便它们可以轻松地适应批处理。但是,如果我们正确地对这些样本进行排序,模型将按顺序读取样本序列,使模型暴露于原始序列的长时间段。
我们还可以考虑增加更多信号:为什么只预测第四个单词,而不使用中间预测来预测第二和第三个单词呢?让我们看看如何实现这些变化,首先从添加一些状态开始。
维护 RNN 的状态
因为我们为每个新样本将模型的隐藏状态初始化为零,这样我们就丢失了关于迄今为止看到的句子的所有信息,这意味着我们的模型实际上不知道我们在整体计数序列中的进度。这很容易修复;我们只需将隐藏状态的初始化移动到__init__中。
但是,这种修复方法将产生自己微妙但重要的问题。它实际上使我们的神经网络变得和文档中的令牌数量一样多。例如,如果我们的数据集中有 10,000 个令牌,我们将创建一个有 10,000 层的神经网络。
要了解为什么会出现这种情况,请考虑我们循环神经网络的原始图示表示,即在图 12-3 中,在使用for循环重构之前。您可以看到每个层对应一个令牌输入。当我们谈论使用for循环重构之前的循环神经网络的表示时,我们称之为展开表示。在尝试理解 RNN 时,考虑展开表示通常是有帮助的。
10,000 层神经网络的问题在于,当您到达数据集的第 10,000 个单词时,您仍然需要计算直到第一层的所有导数。这将非常缓慢,且占用内存。您可能无法在 GPU 上存储一个小批量。
解决这个问题的方法是告诉 PyTorch 我们不希望通过整个隐式神经网络反向传播导数。相反,我们将保留梯度的最后三层。为了在 PyTorch 中删除所有梯度历史,我们使用detach方法。
这是我们 RNN 的新版本。现在它是有状态的,因为它在不同调用forward时记住了其激活,这代表了它在批处理中用于不同样本的情况:
class LMModel3(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
self.h = 0
def forward(self, x):
for i in range(3):
self.h = self.h + self.i_h(x[:,i])
self.h = F.relu(self.h_h(self.h))
out = self.h_o(self.h)
self.h = self.h.detach()
return out
def reset(self): self.h = 0
无论我们选择什么序列长度,这个模型将具有相同的激活,因为隐藏状态将记住上一批次的最后激活。唯一不同的是在每一步计算的梯度:它们将仅在过去的序列长度标记上计算,而不是整个流。这种方法称为时间穿梭反向传播(BPTT)。
术语:时间穿梭反向传播
将一个神经网络有效地视为每个时间步长一个层(通常使用循环重构),并以通常的方式在其上计算梯度。为了避免内存和时间不足,我们通常使用截断 BPTT,每隔几个时间步“分离”隐藏状态的计算历史。
要使用LMModel3,我们需要确保样本按照一定顺序进行查看。正如我们在第十章中看到的,如果第一批的第一行是我们的dset[0],那么第二批应该将dset[1]作为第一行,以便模型看到文本流动。
LMDataLoader在第十章中为我们做到了这一点。这次我们要自己做。
为此,我们将重新排列我们的数据集。首先,我们将样本分成m = len(dset) // bs组(这相当于将整个连接数据集分成,例如,64 个大小相等的部分,因为我们在这里使用bs=64)。m是每个这些部分的长度。例如,如果我们使用整个数据集(尽管我们实际上将在一会儿将其分成训练和验证),我们有:
m = len(seqs)//bs
m,bs,len(seqs)
(328, 64, 21031)
第一批将由样本组成
(0, m, 2*m, ..., (bs-1)*m)
样本的第二批
(1, m+1, 2*m+1, ..., (bs-1)*m+1)
等等。这样,每个时期,模型将在每批次的每行上看到大小为3*m的连续文本块(因为每个文本的大小为 3)。
以下函数执行重新索引:
def group_chunks(ds, bs):
m = len(ds) // bs
new_ds = L()
for i in range(m): new_ds += L(ds[i + m*j] for j in range(bs))
return new_ds
然后,我们在构建DataLoaders时只需传递drop_last=True来删除最后一个形状不为bs的批次。我们还传递shuffle=False以确保文本按顺序阅读:
cut = int(len(seqs) * 0.8)
dls = DataLoaders.from_dsets(
group_chunks(seqs[:cut], bs),
group_chunks(seqs[cut:], bs),
bs=bs, drop_last=True, shuffle=False)
我们添加的最后一件事是通过Callback对训练循环进行微调。我们将在第十六章中更多地讨论回调;这个回调将在每个时期的开始和每个验证阶段之前调用我们模型的reset方法。由于我们实现了该方法来将模型的隐藏状态设置为零,这将确保我们在阅读这些连续文本块之前以干净的状态开始。我们也可以开始训练更长一点:
learn = Learner(dls, LMModel3(len(vocab), 64), loss_func=F.cross_entropy,
metrics=accuracy, cbs=ModelResetter)
learn.fit_one_cycle(10, 3e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.677074 | 1.827367 | 0.467548 | 00:02 |
| 1 | 1.282722 | 1.870913 | 0.388942 | 00:02 |
| 2 | 1.090705 | 1.651793 | 0.462500 | 00:02 |
| 3 | 1.005092 | 1.613794 | 0.516587 | 00:02 |
| 4 | 0.965975 | 1.560775 | 0.551202 | 00:02 |
| 5 | 0.916182 | 1.595857 | 0.560577 | 00:02 |
| 6 | 0.897657 | 1.539733 | 0.574279 | 00:02 |
| 7 | 0.836274 | 1.585141 | 0.583173 | 00:02 |
| 8 | 0.805877 | 1.629808 | 0.586779 | 00:02 |
| 9 | 0.795096 | 1.651267 | 0.588942 | 00:02 |
这已经更好了!下一步是使用更多目标并将它们与中间预测进行比较。
创建更多信号
我们当前方法的另一个问题是,我们仅为每三个输入单词预测一个输出单词。因此,我们反馈以更新权重的信号量不如可能的那么大。如果我们在每个单词后预测下一个单词,而不是每三个单词,将会更好,如图 12-5 所示。
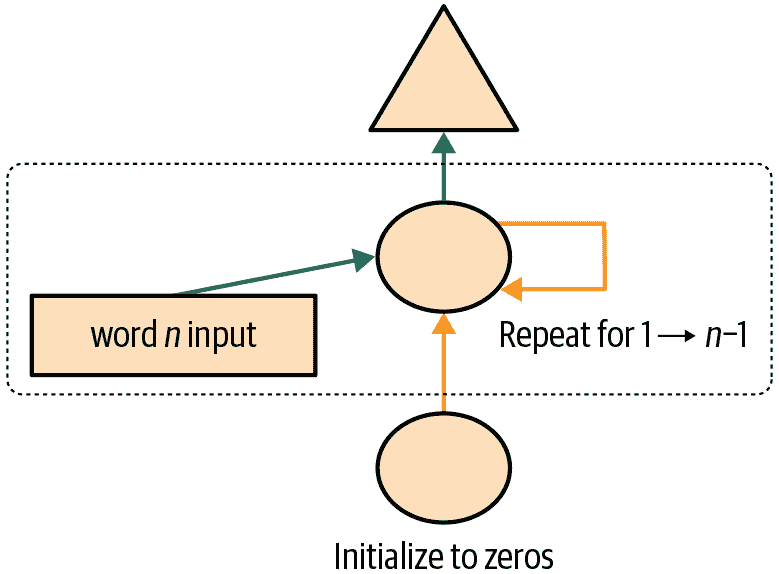
图 12-5。RNN 在每个标记后进行预测
这很容易添加。我们需要首先改变我们的数据,使得因变量在每个三个输入词后的每个三个词中都有。我们使用一个属性sl(用于序列长度),并使其稍微变大:
sl = 16
seqs = L((tensor(nums[i:i+sl]), tensor(nums[i+1:i+sl+1]))
for i in range(0,len(nums)-sl-1,sl))
cut = int(len(seqs) * 0.8)
dls = DataLoaders.from_dsets(group_chunks(seqs[:cut], bs),
group_chunks(seqs[cut:], bs),
bs=bs, drop_last=True, shuffle=False)
查看seqs的第一个元素,我们可以看到它包含两个相同大小的列表。第二个列表与第一个相同,但偏移了一个元素:
[L(vocab[o] for o in s) for s in seqs[0]]
[(#16) ['one','.','two','.','three','.','four','.','five','.'...],
(#16) ['.','two','.','three','.','four','.','five','.','six'...]]
现在我们需要修改我们的模型,使其在每个单词之后输出一个预测,而不仅仅是在一个三个词序列的末尾:
class LMModel4(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
self.h = 0
def forward(self, x):
outs = []
for i in range(sl):
self.h = self.h + self.i_h(x[:,i])
self.h = F.relu(self.h_h(self.h))
outs.append(self.h_o(self.h))
self.h = self.h.detach()
return torch.stack(outs, dim=1)
def reset(self): self.h = 0
这个模型将返回形状为bs x sl x vocab_sz的输出(因为我们在dim=1上堆叠)。我们的目标的形状是bs x sl,所以在使用F.cross_entropy之前,我们需要将它们展平:
def loss_func(inp, targ):
return F.cross_entropy(inp.view(-1, len(vocab)), targ.view(-1))
我们现在可以使用这个损失函数来训练模型:
learn = Learner(dls, LMModel4(len(vocab), 64), loss_func=loss_func,
metrics=accuracy, cbs=ModelResetter)
learn.fit_one_cycle(15, 3e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 3.103298 | 2.874341 | 0.212565 | 00:01 |
| 1 | 2.231964 | 1.971280 | 0.462158 | 00:01 |
| 2 | 1.711358 | 1.813547 | 0.461182 | 00:01 |
| 3 | 1.448516 | 1.828176 | 0.483236 | 00:01 |
| 4 | 1.288630 | 1.659564 | 0.520671 | 00:01 |
| 5 | 1.161470 | 1.714023 | 0.554932 | 00:01 |
| 6 | 1.055568 | 1.660916 | 0.575033 | 00:01 |
| 7 | 0.960765 | 1.719624 | 0.591064 | 00:01 |
| 8 | 0.870153 | 1.839560 | 0.614665 | 00:01 |
| 9 | 0.808545 | 1.770278 | 0.624349 | 00:01 |
| 10 | 0.758084 | 1.842931 | 0.610758 | 00:01 |
| 11 | 0.719320 | 1.799527 | 0.646566 | 00:01 |
| 12 | 0.683439 | 1.917928 | 0.649821 | 00:01 |
| 13 | 0.660283 | 1.874712 | 0.628581 | 00:01 |
| 14 | 0.646154 | 1.877519 | 0.640055 | 00:01 |
我们需要训练更长时间,因为任务有点变化,现在更加复杂。但我们最终得到了一个好结果...至少有时候是这样。如果你多次运行它,你会发现在不同的运行中可以得到非常不同的结果。这是因为实际上我们在这里有一个非常深的网络,这可能导致非常大或非常小的梯度。我们将在本章的下一部分看到如何处理这个问题。
现在,获得更好模型的明显方法是加深:在我们基本的 RNN 中,隐藏状态和输出激活之间只有一个线性层,所以也许我们用更多的线性层会得到更好的结果。
多层 RNNs
在多层 RNN 中,我们将来自我们递归神经网络的激活传递到第二个递归神经网络中,就像图 12-6 中所示。
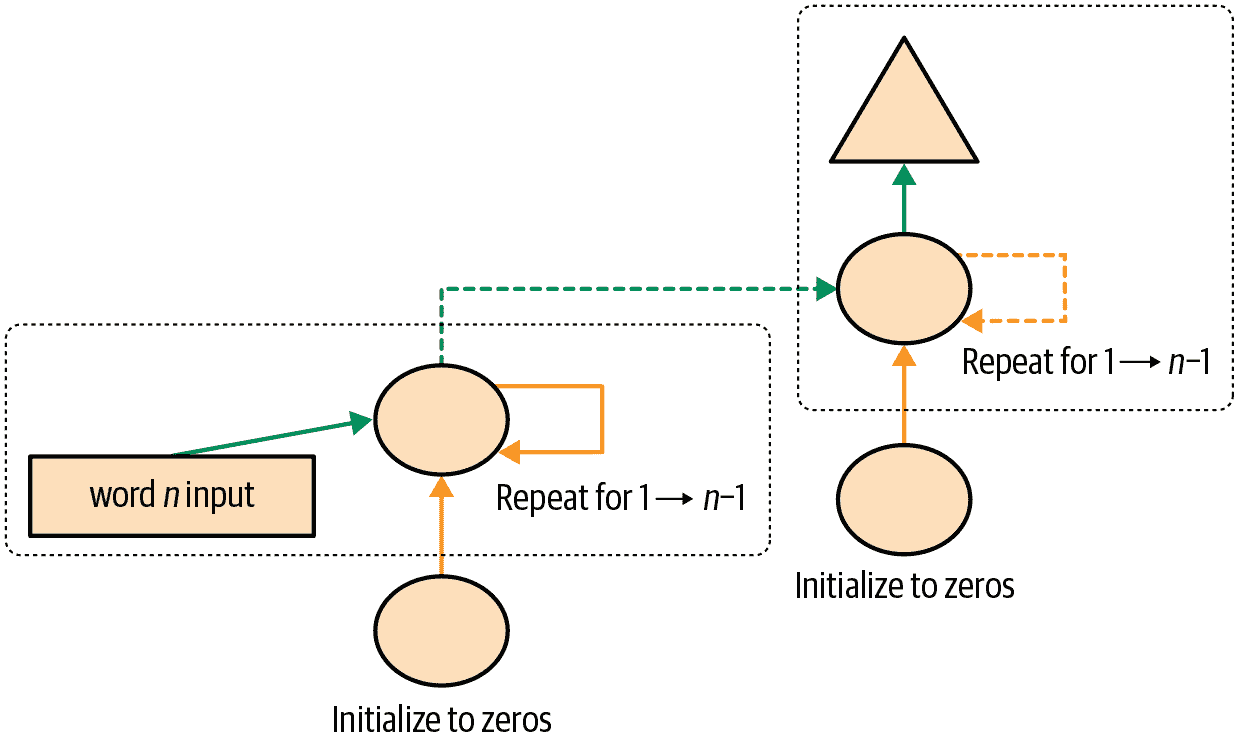
图 12-6. 2 层 RNN
展开的表示在图 12-7 中显示(类似于图 12-3)。
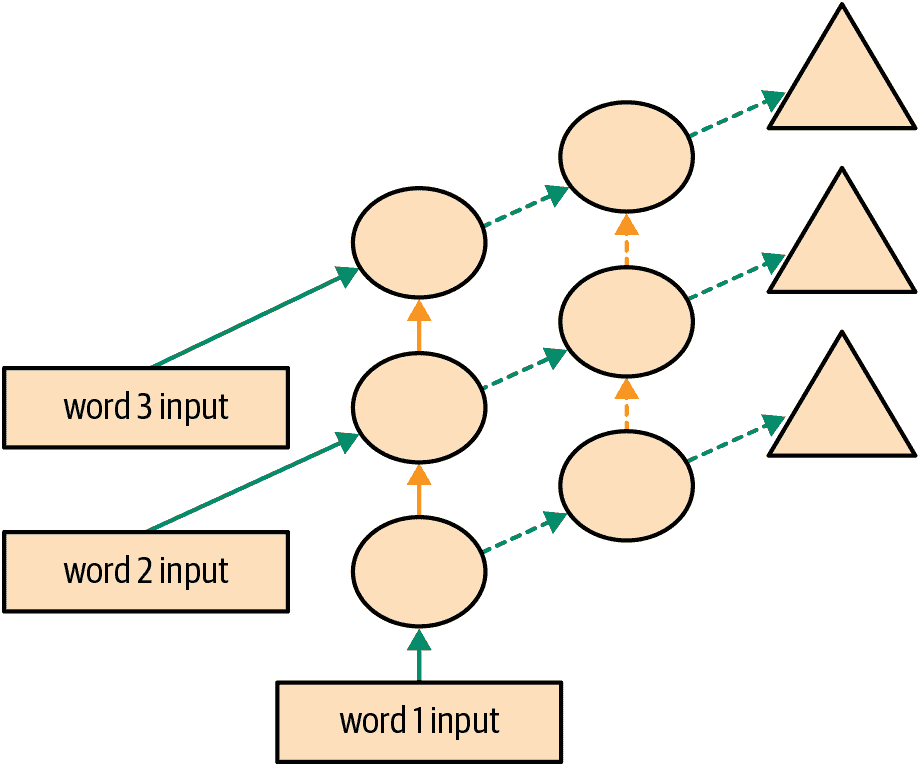
图 12-7. 2 层展开的 RNN
让我们看看如何在实践中实现这一点。
模型
我们可以通过使用 PyTorch 的RNN类来节省一些时间,该类实现了我们之前创建的内容,但也给了我们堆叠多个 RNN 的选项,正如我们之前讨论的那样:
class LMModel5(Module):
def __init__(self, vocab_sz, n_hidden, n_layers):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.rnn = nn.RNN(n_hidden, n_hidden, n_layers, batch_first=True)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h = torch.zeros(n_layers, bs, n_hidden)
def forward(self, x):
res,h = self.rnn(self.i_h(x), self.h)
self.h = h.detach()
return self.h_o(res)
def reset(self): self.h.zero_()
learn = Learner(dls, LMModel5(len(vocab), 64, 2),
loss_func=CrossEntropyLossFlat(),
metrics=accuracy, cbs=ModelResetter)
learn.fit_one_cycle(15, 3e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 3.055853 | 2.591640 | 0.437907 | 00:01 |
| 1 | 2.162359 | 1.787310 | 0.471598 | 00:01 |
| 2 | 1.710663 | 1.941807 | 0.321777 | 00:01 |
| 3 | 1.520783 | 1.999726 | 0.312012 | 00:01 |
| 4 | 1.330846 | 2.012902 | 0.413249 | 00:01 |
| 5 | 1.163297 | 1.896192 | 0.450684 | 00:01 |
| 6 | 1.033813 | 2.005209 | 0.434814 | 00:01 |
| 7 | 0.919090 | 2.047083 | 0.456706 | 00:01 |
| 8 | 0.822939 | 2.068031 | 0.468831 | 00:01 |
| 9 | 0.750180 | 2.136064 | 0.475098 | 00:01 |
| 10 | 0.695120 | 2.139140 | 0.485433 | 00:01 |
| 11 | 0.655752 | 2.155081 | 0.493652 | 00:01 |
| 12 | 0.629650 | 2.162583 | 0.498535 | 00:01 |
| 13 | 0.613583 | 2.171649 | 0.491048 | 00:01 |
| 14 | 0.604309 | 2.180355 | 0.487874 | 00:01 |
现在这令人失望...我们之前的单层 RNN 表现更好。为什么?原因是我们有一个更深的模型,导致激活爆炸或消失。
激活爆炸或消失
在实践中,从这种类型的 RNN 创建准确的模型是困难的。如果我们调用detach的频率较少,并且有更多的层,我们将获得更好的结果 - 这使得我们的 RNN 有更长的时间跨度来学习和创建更丰富的特征。但这也意味着我们有一个更深的模型要训练。深度学习发展中的关键挑战是如何训练这种类型的模型。
这是具有挑战性的,因为当您多次乘以一个矩阵时会发生什么。想想当您多次乘以一个数字时会发生什么。例如,如果您从 1 开始乘以 2,您会得到序列 1、2、4、8,...在 32 步之后,您已经达到 4,294,967,296。如果您乘以 0.5,类似的问题会发生:您会得到 0.5、0.25、0.125,...在 32 步之后,它是 0.00000000023。正如您所看到的,即使是比 1 稍高或稍低的数字,经过几次重复乘法后,我们的起始数字就会爆炸或消失。
因为矩阵乘法只是将数字相乘并将它们相加,重复矩阵乘法会发生完全相同的事情。这就是深度神经网络的全部内容 - 每一层都是另一个矩阵乘法。这意味着深度神经网络很容易最终得到极大或极小的数字。
这是一个问题,因为计算机存储数字的方式(称为浮点数)意味着随着数字远离零点,它们变得越来越不准确。来自优秀文章“关于浮点数你从未想知道但却被迫了解”的图 12-8 中的图表显示了浮点数的精度如何随着数字线变化。

图 12-8。浮点数的精度
这种不准确性意味着通常为更新权重计算的梯度最终会变为零或无穷大。这通常被称为消失梯度或爆炸梯度问题。这意味着在 SGD 中,权重要么根本不更新,要么跳到无穷大。无论哪种方式,它们都不会随着训练而改善。
研究人员已经开发出了解决这个问题的方法,我们将在本书后面讨论。一种选择是改变层的定义方式,使其不太可能出现激活爆炸。当我们讨论批量归一化时,我们将在第十三章中看到这是如何完成的,当我们讨论 ResNets 时,我们将在第十四章中看到,尽管这些细节通常在实践中并不重要(除非您是一个研究人员,正在创造解决这个问题的新方法)。另一种处理这个问题的策略是谨慎初始化,这是我们将在第十七章中调查的一个主题。
为了避免激活爆炸,RNN 经常使用两种类型的层:门控循环单元(GRUs)和长短期记忆(LSTM)层。这两种都在 PyTorch 中可用,并且可以直接替换 RNN 层。在本书中,我们只会涵盖 LSTMs;在线上有很多好的教程解释 GRUs,它们是 LSTM 设计的一个小变体。
LSTM
LSTM 是由 Jürgen Schmidhuber 和 Sepp Hochreiter 于 1997 年引入的一种架构。在这种架构中,不是一个,而是两个隐藏状态。在我们的基本 RNN 中,隐藏状态是 RNN 在上一个时间步的输出。那个隐藏状态负责两件事:
-
拥有正确的信息来预测正确的下一个标记的输出层
-
保留句子中发生的一切记忆
例如,考虑句子“Henry has a dog and he likes his dog very much”和“Sophie has a dog and she likes her dog very much。”很明显,RNN 需要记住句子开头的名字才能预测he/she或his/her。
在实践中,RNN 在保留句子中较早发生的记忆方面表现非常糟糕,这就是在 LSTM 中有另一个隐藏状态(称为cell state)的动机。cell state 将负责保持长期短期记忆,而隐藏状态将专注于预测下一个标记。让我们更仔细地看看如何实现这一点,并从头开始构建一个 LSTM。
从头开始构建一个 LSTM
为了构建一个 LSTM,我们首先必须了解其架构。图 12-9 显示了其内部结构。
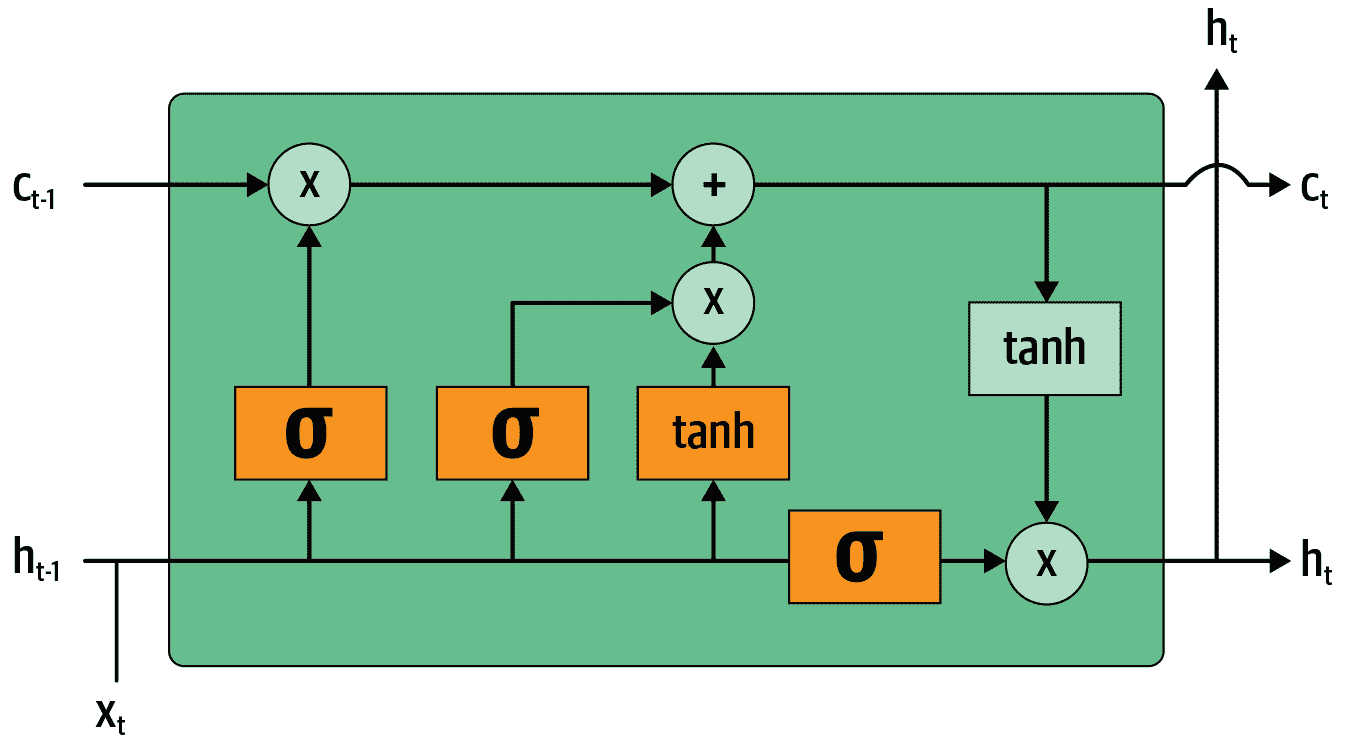
图 12-9. LSTM 的架构
在这张图片中,我们的输入从左侧进入,带有先前的隐藏状态()和 cell state()。四个橙色框代表四个层(我们的神经网络),激活函数可以是 sigmoid()或 tanh。tanh 只是一个重新缩放到范围-1 到 1 的 sigmoid 函数。它的数学表达式可以写成这样:
其中是 sigmoid 函数。图中的绿色圆圈是逐元素操作。右侧输出的是新的隐藏状态()和新的 cell state(),准备接受我们的下一个输入。新的隐藏状态也被用作输出,这就是为什么箭头分开向上移动。
让我们逐一查看四个神经网络(称为门)并解释图表——但在此之前,请注意 cell state(顶部)几乎没有改变。它甚至没有直接通过神经网络!这正是为什么它将继续保持较长期的状态。
首先,将输入和旧隐藏状态的箭头连接在一起。在本章前面编写的 RNN 中,我们将它们相加。在 LSTM 中,我们将它们堆叠在一个大张量中。这意味着我们的嵌入的维度(即的维度)可以与隐藏状态的维度不同。如果我们将它们称为n_in和n_hid,底部的箭头大小为n_in + n_hid;因此所有的神经网络(橙色框)都是具有n_in + n_hid输入和n_hid输出的线性层。
第一个门(从左到右看)称为遗忘门。由于它是一个线性层后面跟着一个 sigmoid,它的输出将由 0 到 1 之间的标量组成。我们将这个结果乘以细胞状态,以确定要保留哪些信息,要丢弃哪些信息:接近 0 的值被丢弃,接近 1 的值被保留。这使得 LSTM 有能力忘记关于其长期状态的事情。例如,当穿过一个句号或一个xxbos标记时,我们期望它(已经学会)重置其细胞状态。
第二个门称为输入门。它与第三个门(没有真正的名称,但有时被称为细胞门)一起更新细胞状态。例如,我们可能看到一个新的性别代词,这时我们需要替换遗忘门删除的关于性别的信息。与遗忘门类似,输入门决定要更新的细胞状态元素(接近 1 的值)或不更新(接近 0 的值)。第三个门确定这些更新值是什么,范围在-1 到 1 之间(由于 tanh 函数)。结果被添加到细胞状态中。
最后一个门是输出门。它确定从细胞状态中使用哪些信息来生成输出。细胞状态经过 tanh 后与输出门的 sigmoid 输出结合,结果就是新的隐藏状态。在代码方面,我们可以这样写相同的步骤:
class LSTMCell(Module):
def __init__(self, ni, nh):
self.forget_gate = nn.Linear(ni + nh, nh)
self.input_gate = nn.Linear(ni + nh, nh)
self.cell_gate = nn.Linear(ni + nh, nh)
self.output_gate = nn.Linear(ni + nh, nh)
def forward(self, input, state):
h,c = state
h = torch.stack([h, input], dim=1)
forget = torch.sigmoid(self.forget_gate(h))
c = c * forget
inp = torch.sigmoid(self.input_gate(h))
cell = torch.tanh(self.cell_gate(h))
c = c + inp * cell
out = torch.sigmoid(self.output_gate(h))
h = outgate * torch.tanh(c)
return h, (h,c)
实际上,我们可以重构代码。此外,就性能而言,做一次大矩阵乘法比做四次小矩阵乘法更好(因为我们只在 GPU 上启动一次特殊的快速内核,这样可以让 GPU 并行处理更多工作)。堆叠需要一点时间(因为我们必须在 GPU 上移动一个张量,使其全部在一个连续的数组中),所以我们为输入和隐藏状态使用两个单独的层。优化和重构后的代码如下:
class LSTMCell(Module):
def __init__(self, ni, nh):
self.ih = nn.Linear(ni,4*nh)
self.hh = nn.Linear(nh,4*nh)
def forward(self, input, state):
h,c = state
# One big multiplication for all the gates is better than 4 smaller ones
gates = (self.ih(input) + self.hh(h)).chunk(4, 1)
ingate,forgetgate,outgate = map(torch.sigmoid, gates[:3])
cellgate = gates[3].tanh()
c = (forgetgate*c) + (ingate*cellgate)
h = outgate * c.tanh()
return h, (h,c)
在这里,我们使用 PyTorch 的chunk方法将张量分成四部分。它的工作原理如下:
t = torch.arange(0,10); t
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
t.chunk(2)
(tensor([0, 1, 2, 3, 4]), tensor([5, 6, 7, 8, 9]))
现在让我们使用这个架构来训练一个语言模型!
使用 LSTMs 训练语言模型
这是与LMModel5相同的网络,使用了两层 LSTM。我们可以以更高的学习率进行训练,时间更短,获得更好的准确性:
class LMModel6(Module):
def __init__(self, vocab_sz, n_hidden, n_layers):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.rnn = nn.LSTM(n_hidden, n_hidden, n_layers, batch_first=True)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h = [torch.zeros(n_layers, bs, n_hidden) for _ in range(2)]
def forward(self, x):
res,h = self.rnn(self.i_h(x), self.h)
self.h = [h_.detach() for h_ in h]
return self.h_o(res)
def reset(self):
for h in self.h: h.zero_()
learn = Learner(dls, LMModel6(len(vocab), 64, 2),
loss_func=CrossEntropyLossFlat(),
metrics=accuracy, cbs=ModelResetter)
learn.fit_one_cycle(15, 1e-2)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 3.000821 | 2.663942 | 0.438314 | 00:02 |
| 1 | 2.139642 | 2.184780 | 0.240479 | 00:02 |
| 2 | 1.607275 | 1.812682 | 0.439779 | 00:02 |
| 3 | 1.347711 | 1.830982 | 0.497477 | 00:02 |
| 4 | 1.123113 | 1.937766 | 0.594401 | 00:02 |
| 5 | 0.852042 | 2.012127 | 0.631592 | 00:02 |
| 6 | 0.565494 | 1.312742 | 0.725749 | 00:02 |
| 7 | 0.347445 | 1.297934 | 0.711263 | 00:02 |
| 8 | 0.208191 | 1.441269 | 0.731201 | 00:02 |
| 9 | 0.126335 | 1.569952 | 0.737305 | 00:02 |
| 10 | 0.079761 | 1.427187 | 0.754150 | 00:02 |
| 11 | 0.052990 | 1.494990 | 0.745117 | 00:02 |
| 12 | 0.039008 | 1.393731 | 0.757894 | 00:02 |
| 13 | 0.031502 | 1.373210 | 0.758464 | 00:02 |
| 14 | 0.028068 | 1.368083 | 0.758464 | 00:02 |
现在这比多层 RNN 好多了!然而,我们仍然可以看到有一点过拟合,这表明一点正则化可能会有所帮助。
正则化 LSTM
循环神经网络总体上很难训练,因为我们之前看到的激活和梯度消失问题。使用 LSTM(或 GRU)单元比使用普通 RNN 更容易训练,但它们仍然很容易过拟合。数据增强虽然是一种可能性,但在文本数据中使用得比图像数据少,因为在大多数情况下,它需要另一个模型来生成随机增强(例如,将文本翻译成另一种语言,然后再翻译回原始语言)。总的来说,目前文本数据的数据增强并不是一个被充分探索的领域。
然而,我们可以使用其他正则化技术来减少过拟合,这些技术在与 LSTMs 一起使用时进行了深入研究,如 Stephen Merity 等人的论文“正则化和优化 LSTM 语言模型”。这篇论文展示了如何有效地使用 dropout、激活正则化和时间激活正则化可以使一个 LSTM 击败以前需要更复杂模型的最新结果。作者将使用这些技术的 LSTM 称为AWD-LSTM。我们将依次看看这些技术。
Dropout
Dropout是由 Geoffrey Hinton 等人在“通过防止特征探测器的共适应来改进神经网络”中引入的一种正则化技术。基本思想是在训练时随机将一些激活变为零。这确保所有神经元都积极地朝着输出工作,如图 12-10 所示(来自 Nitish Srivastava 等人的“Dropout:防止神经网络过拟合的简单方法”)。
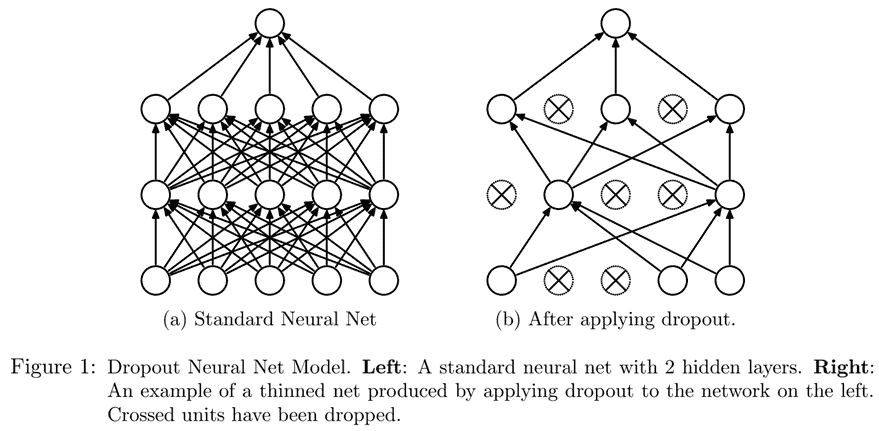
图 12-10。在神经网络中应用 dropout(由 Nitish Srivastava 等人提供)
Hinton 在一次采访中解释了 dropout 的灵感时使用了一个很好的比喻:
我去了我的银行。出纳员不断变换,我问其中一个原因。他说他不知道,但他们经常被调动。我想这一定是因为需要员工之间的合作才能成功欺诈银行。这让我意识到,随机在每个示例中删除不同的神经元子集将防止阴谋,从而减少过拟合。
在同一次采访中,他还解释了神经科学提供了额外的灵感:
我们并不真正知道为什么神经元会突触。有一种理论是它们想要变得嘈杂以进行正则化,因为我们的参数比数据点多得多。dropout 的想法是,如果你有嘈杂的激活,你可以承担使用一个更大的模型。
这解释了为什么 dropout 有助于泛化的想法:首先它帮助神经元更好地合作;然后它使激活更嘈杂,从而使模型更健壮。
然而,我们可以看到,如果我们只是将这些激活置零而不做其他任何操作,我们的模型将会训练出问题:如果我们从五个激活的总和(由于我们应用了 ReLU,它们都是正数)变为只有两个,这不会有相同的规模。因此,如果我们以概率p应用 dropout,我们通过将所有激活除以1-p来重新缩放它们(平均p将被置零,所以剩下1-p),如图 12-11 所示。
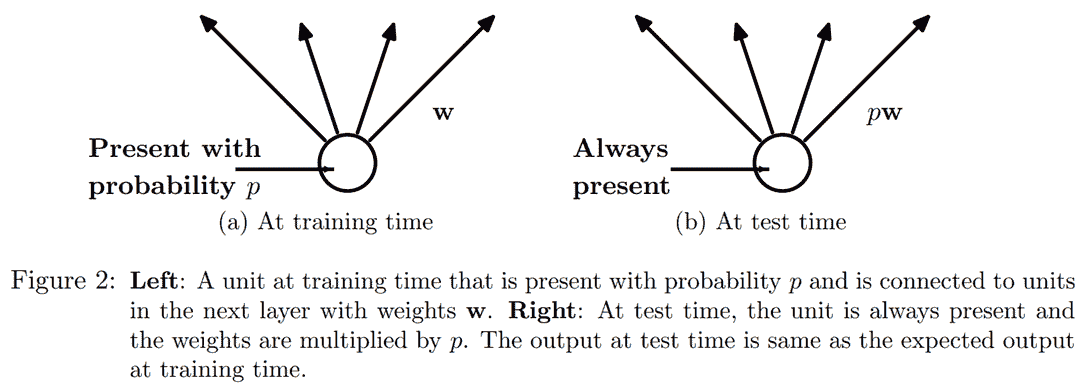
图 12-11。应用 dropout 时为什么要缩放激活(由 Nitish Srivastava 等人提供)
这是 PyTorch 中 dropout 层的完整实现(尽管 PyTorch 的原生层实际上是用 C 而不是 Python 编写的):
class Dropout(Module):
def __init__(self, p): self.p = p
def forward(self, x):
if not self.training: return x
mask = x.new(*x.shape).bernoulli_(1-p)
return x * mask.div_(1-p)
bernoulli_方法创建一个随机零(概率为p)和一(概率为1-p)的张量,然后将其乘以我们的输入,再除以1-p。注意training属性的使用,它在任何 PyTorch nn.Module中都可用,并告诉我们是否在训练或推理。
做你自己的实验
在本书的前几章中,我们会在这里添加一个bernoulli_的代码示例,这样您就可以看到它的确切工作原理。但是现在您已经了解足够多,可以自己做这个,我们将为您提供越来越少的示例,而是期望您自己进行实验以了解事物是如何工作的。在这种情况下,您将在章节末尾的问卷中看到,我们要求您尝试使用bernoulli_,但不要等到我们要求您进行实验才开发您对我们正在研究的代码的理解;无论如何都可以开始做。
在将我们的 LSTM 的输出传递到最终层之前使用 dropout 将有助于减少过拟合。在许多其他模型中也使用了 dropout,包括fastai.vision中使用的默认 CNN 头部,并且通过传递ps参数(其中每个“p”都传递给每个添加的Dropout层)在fastai.tabular中也可用,正如我们将在第十五章中看到的。
在训练和验证模式下,dropout 的行为不同,我们使用Dropout中的training属性进行指定。在Module上调用train方法会将training设置为True(对于您调用该方法的模块以及递归包含的每个模块),而eval将其设置为False。在调用Learner的方法时会自动执行此操作,但如果您没有使用该类,请记住根据需要在两者之间切换。
激活正则化和时间激活正则化
激活正则化(AR)和时间激活正则化(TAR)是两种与权重衰减非常相似的正则化方法,在第八章中讨论过。在应用权重衰减时,我们会对损失添加一个小的惩罚,旨在使权重尽可能小。对于激活正则化,我们将尝试使 LSTM 生成的最终激活尽可能小,而不是权重。
为了对最终激活进行正则化,我们必须将它们存储在某个地方,然后将它们的平方的平均值添加到损失中(以及一个乘数alpha,就像权重衰减的wd一样):
loss += alpha * activations.pow(2).mean()
时间激活正则化与我们在句子中预测标记有关。这意味着当我们按顺序阅读它们时,我们的 LSTM 的输出应该在某种程度上是有意义的。TAR 通过向损失添加惩罚来鼓励这种行为,使两个连续激活之间的差异尽可能小:我们的激活张量的形状为bs x sl x n_hid,我们在序列长度轴上(中间维度)读取连续激活。有了这个,TAR 可以表示如下:
loss += beta * (activations[:,1:] - activations[:,:-1]).pow(2).mean()
然后,alpha和beta是要调整的两个超参数。为了使这项工作成功,我们需要让我们的带有 dropout 的模型返回三个东西:正确的输出,LSTM 在 dropout 之前的激活以及 LSTM 在 dropout 之后的激活。通常在 dropout 后的激活上应用 AR(以免惩罚我们之后转换为零的激活),而 TAR 应用在未经 dropout 的激活上(因为这些零会在两个连续时间步之间产生很大的差异)。然后,一个名为RNNRegularizer的回调将为我们应用这种正则化。
训练带有权重绑定的正则化 LSTM
我们可以将 dropout(应用在我们进入输出层之前)与 AR 和 TAR 相结合,以训练我们之前的 LSTM。我们只需要返回三个东西而不是一个:我们的 LSTM 的正常输出,dropout 后的激活以及我们的 LSTM 的激活。最后两个将由回调RNNRegularization捕获,以便为其对损失的贡献做出贡献。
我们可以从AWD-LSTM 论文中添加另一个有用的技巧是权重绑定。在语言模型中,输入嵌入表示从英语单词到激活的映射,输出隐藏层表示从激活到英语单词的映射。直觉上,我们可能会期望这些映射是相同的。我们可以通过将相同的权重矩阵分配给这些层来在 PyTorch 中表示这一点:
self.h_o.weight = self.i_h.weight
在LMMModel7中,我们包括了这些最终的调整:
class LMModel7(Module):
def __init__(self, vocab_sz, n_hidden, n_layers, p):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.rnn = nn.LSTM(n_hidden, n_hidden, n_layers, batch_first=True)
self.drop = nn.Dropout(p)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h_o.weight = self.i_h.weight
self.h = [torch.zeros(n_layers, bs, n_hidden) for _ in range(2)]
def forward(self, x):
raw,h = self.rnn(self.i_h(x), self.h)
out = self.drop(raw)
self.h = [h_.detach() for h_ in h]
return self.h_o(out),raw,out
def reset(self):
for h in self.h: h.zero_()
我们可以使用RNNRegularizer回调函数创建一个正则化的Learner:
learn = Learner(dls, LMModel7(len(vocab), 64, 2, 0.5),
loss_func=CrossEntropyLossFlat(), metrics=accuracy,
cbs=[ModelResetter, RNNRegularizer(alpha=2, beta=1)])
TextLearner会自动为我们添加这两个回调函数(使用alpha和beta的默认值),因此我们可以简化前面的行:
learn = TextLearner(dls, LMModel7(len(vocab), 64, 2, 0.4),
loss_func=CrossEntropyLossFlat(), metrics=accuracy)
然后我们可以训练模型,并通过增加权重衰减到0.1来添加额外的正则化:
learn.fit_one_cycle(15, 1e-2, wd=0.1)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.693885 | 2.013484 | 0.466634 | 00:02 |
| 1 | 1.685549 | 1.187310 | 0.629313 | 00:02 |
| 2 | 0.973307 | 0.791398 | 0.745605 | 00:02 |
| 3 | 0.555823 | 0.640412 | 0.794108 | 00:02 |
| 4 | 0.351802 | 0.557247 | 0.836100 | 00:02 |
| 5 | 0.244986 | 0.594977 | 0.807292 | 00:02 |
| 6 | 0.192231 | 0.511690 | 0.846761 | 00:02 |
| 7 | 0.162456 | 0.520370 | 0.858073 | 00:02 |
| 8 | 0.142664 | 0.525918 | 0.842285 | 00:02 |
| 9 | 0.128493 | 0.495029 | 0.858073 | 00:02 |
| 10 | 0.117589 | 0.464236 | 0.867188 | 00:02 |
| 11 | 0.109808 | 0.466550 | 0.869303 | 00:02 |
| 12 | 0.104216 | 0.455151 | 0.871826 | 00:02 |
| 13 | 0.100271 | 0.452659 | 0.873617 | 00:02 |
| 14 | 0.098121 | 0.458372 | 0.869385 | 00:02 |
现在这比我们之前的模型好多了!
结论
您现在已经看到了我们在第十章中用于文本分类的 AWD-LSTM 架构内部的所有内容。它在更多地方使用了丢失:
-
嵌入丢失(就在嵌入层之后)
-
输入丢失(在嵌入层之后)
-
权重丢失(应用于每个训练步骤中 LSTM 的权重)
-
隐藏丢失(应用于两个层之间的隐藏状态)
这使得它更加规范化。由于微调这五个丢失值(包括输出层之前的丢失)很复杂,我们已经确定了良好的默认值,并允许通过您在该章节中看到的drop_mult参数来整体调整丢失的大小。
另一个非常强大的架构,特别适用于“序列到序列”问题(依赖变量本身是一个变长序列的问题,例如语言翻译),是 Transformer 架构。您可以在书籍网站的额外章节中找到它。
问卷
-
如果您的项目数据集非常庞大且复杂,处理它需要大量时间,您应该怎么做?
-
为什么在创建语言模型之前我们要将数据集中的文档连接起来?
-
要使用标准的全连接网络来预测前三个单词给出的第四个单词,我们需要对模型进行哪两个调整?
-
我们如何在 PyTorch 中跨多个层共享权重矩阵?
-
编写一个模块,预测句子前两个单词给出的第三个单词,而不偷看。
-
什么是循环神经网络?
-
隐藏状态是什么?
-
LMModel1中隐藏状态的等价物是什么? -
为了在 RNN 中保持状态,为什么按顺序将文本传递给模型很重要?
-
什么是 RNN 的“展开”表示?
-
为什么在 RNN 中保持隐藏状态会导致内存和性能问题?我们如何解决这个问题?
-
什么是 BPTT?
-
编写代码打印出验证集的前几个批次,包括将标记 ID 转换回英文字符串,就像我们在第十章中展示的 IMDb 数据批次一样。
-
ModelResetter回调函数的作用是什么?我们为什么需要它? -
为每三个输入词预测一个输出词的缺点是什么?
-
为什么我们需要为
LMModel4设计一个自定义损失函数? -
为什么
LMModel4的训练不稳定? -
在展开表示中,我们可以看到递归神经网络有许多层。那么为什么我们需要堆叠 RNN 以获得更好的结果?
-
绘制一个堆叠(多层)RNN 的表示。
-
如果我们不经常调用
detach,为什么在 RNN 中应该获得更好的结果?为什么在实践中可能不会发生这种情况? -
为什么深度网络可能导致非常大或非常小的激活?这为什么重要?
-
在计算机的浮点数表示中,哪些数字是最精确的?
-
为什么消失的梯度会阻止训练?
-
在 LSTM 架构中有两个隐藏状态为什么有帮助?每个的目的是什么?
-
在 LSTM 中这两个状态被称为什么?
-
tanh 是什么,它与 sigmoid 有什么关系?
-
LSTMCell中这段代码的目的是什么:h = torch.stack([h, input], dim=1) -
在 PyTorch 中
chunk是做什么的? -
仔细研究
LSTMCell的重构版本,确保你理解它如何以及为什么与未重构版本执行相同的操作。 -
为什么我们可以为
LMModel6使用更高的学习率? -
AWD-LSTM 模型中使用的三种正则化技术是什么?
-
什么是 dropout?
-
为什么我们要用 dropout 来缩放权重?这是在训练期间、推理期间还是两者都应用?
-
Dropout中这行代码的目的是什么:if not self.training: return x -
尝试使用
bernoulli_来了解它的工作原理。 -
如何在 PyTorch 中将模型设置为训练模式?在评估模式下呢?
-
写出激活正则化的方程(数学或代码,任你选择)。它与权重衰减有什么不同?
-
写出时间激活正则化的方程(数学或代码,任你选择)。为什么我们不会在计算机视觉问题中使用这个?
-
语言模型中的权重绑定是什么?
进一步研究
-
在
LMModel2中,为什么forward可以从h=0开始?为什么我们不需要写h=torch.zeros(...)? -
从头开始编写一个 LSTM 的代码(你可以参考图 12-9)。
-
搜索互联网了解 GRU 架构并从头开始实现它,尝试训练一个模型。看看能否获得类似于本章中看到的结果。将你的结果与 PyTorch 内置的
GRU模块的结果进行比较。 -
查看 fastai 中 AWD-LSTM 的源代码,并尝试将每行代码映射到本章中展示的概念。