# Towards Realistic 3D Human Motion Prediction with A Spatio-temporal Cross-transformer Approach #paper
1. paper-info
1.1 Metadata
- Author:: [[Hua Yu]], [[Xuanzhe Fan]], [[Yaqing Hou]], [[Wenbin Pei]], [[Hongwei Ge]], [[Xin Yang]], [[Dongsheng Zhou]], [[Qiang Zhang]], [[Mengjie Zhang]]
- 作者机构::
- Keywords:: #HMP , #Transformer
- Journal:: #IEEE
- Date:: [[2020]]
- 状态:: #Done
1.2 Abstract
Human motion prediction intends to predict how humans move given a historical sequence of 3D human motions. Recent transformer-based methods have attracted increasing attentions and demonstrated their promising performance in 3D human motion prediction. However, existing methods generally decompose the input of human motion information into spatial and temporal branches in a separate way and seldom consider their inherent coherence between the two branches, hence often failing to register the dynamic spatio-temporal information during the training process. Motivated by these issues, we propose a spatio-temporal cross-transformer network (STCT) for 3D human motion predictions. Specifically, we investigate various types of interaction methods (i.e., Concatenation Interaction, Msg token interaction, and Cross-transformer) to capture the coherence of the spatial and temporal branches. According to the obtained results, the proposed cross-transformer interaction method shows its superiority over other methods. Meanwhile, considering that most existing works treat the human body as a set of 3D human joint positions, the predicted human joints are proportionally less appropriate to the realistic human body due to unreasonable bone length and non-plausible poses as time progresses. We further resort to the bone constraints of human mesh to produce more realistic human motions. By fitting a parametric body model (i.e., SMPL-X model) to the predicted human joints, a reconstruction loss function is proposed to remedy the unreasonable bone length and pose errors. Comprehensive experiments on AMASS and Human3.6 datasets have demonstrated that our method achieves superior performance over compared methods.
2. Introduction
- 领域:
human motion prediction - 之前的方法:
- RNN-based methods
- 问题:有错误累计的问题,并且只对动作序列的时间信息建模,忽略了空间信息。
- GCNs-based methods
- 无法处理人体动作序列中的长期依赖。
- Transformer-based methods
- 该类方法对时间和空间维度分开建模,没有考虑两种维度之间的联合信息。
- 现有的方法都是用
3D human joints positions来对人体结构建模,导致预测的结果不能够很好地表征真实的人体姿势。
- RNN-based methods
- 作者的方法:
- 在
transformer的基础之上,加入各种交互方法(Concatenation, Interaction, Msg token interaction, Cross-transformer)用于处理时间和空间的联系。 - 为了解决预测的人体动作姿势不合理的问题,提出了一种新方法----
reconstruction loss function,该方法能够修复不正常的人体动作。 - 由于人体网格能够为重建人体提供丰富的身体约束,作者采用
SMPL-X方法将人体关节恢复成人体网格。
- 在
3. Approach
3.1 Network Architecture
\(X=\{x_1,x_2,...,x_T\}\in \mathbb{R}^{T\times NF}\)
\(T\):时间步长
\(N\):人体关节点数
\(F\):关节表征维度
\(x_t=\{j_t^{(1)},j_t^{(2)},...,j_t^{(N)}\}\):\(t\)时刻的人体姿势。
\(E\in \mathbb{R}^{T\times ND}\):经过位置编码后的输入。
整体网络结构如图Fig.1
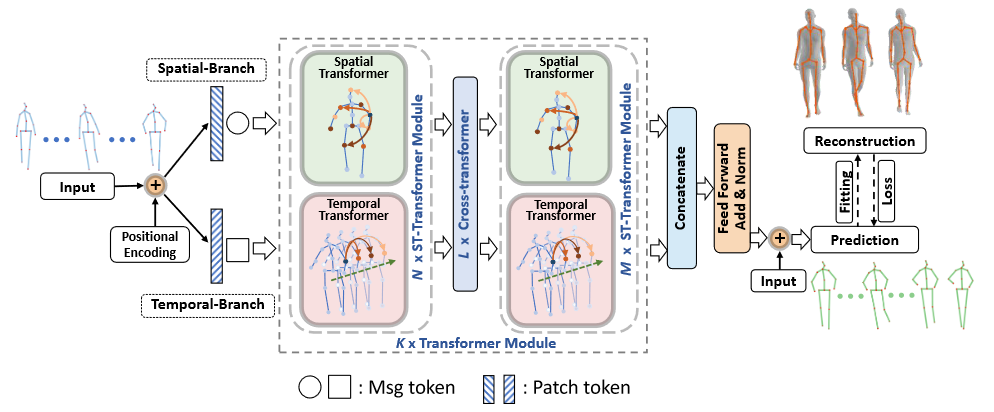
Fig.1 The illustration of the proposed network
Source:
输入序列加上位置编码作为输入,然后利用\(N\)个时间和空间\(Transformer\)平行处理特征向量,用于获取时间和空间的特征,不同于之前的transformer框架,这里使用的是Msg token;每个transformer 分支获取到自己的特征后,送入Cross-transformer交换彼此的特征信息;当Cross-transformer更新完Msg token之后,进入\(M\)个Spatial transformer和Temporal Transformer,该过程是将从其他特征分支学习到的信息带回到自己的特征分支;最后将学习到的空间时间特征拼接起来用于最后的人体动作预测。
Temporal Transformer
利用vanilla transformer[link]
Spatial Transformer
3.2 Interaction Methods for Spatial and Temporal Branches
\(x^i\):token 序列(包括Msg 和 patch token),\(i\)可以是时间分支也可以是空间分支。
\(x_{Msg}^i\):\(i\)分支的Msg token
\(x_{patch}^i\):\(i\)分支的patch token
各种信息交互的方法如Fig.2
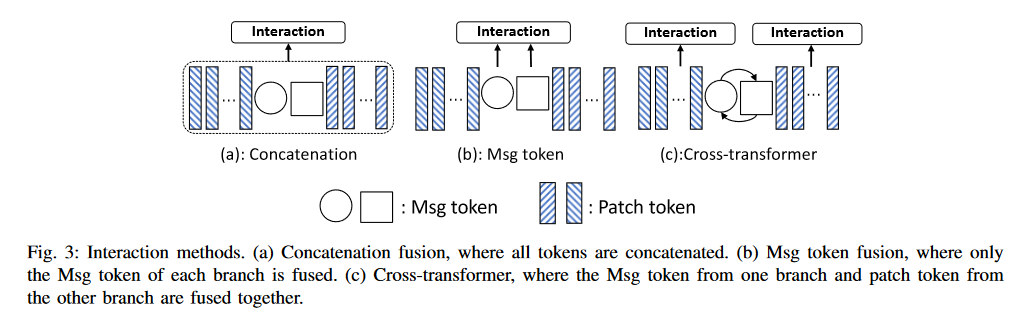
Fig.2 Interaction methods
Source:
Concatenation Interaction
该方法是通过将时间和空间分支的token拼接在一起,然后通过self-attention module去整合信息,计算流程如下:
\(f^i(.)\)和\(g^i(.)\):表示维度对齐的投影和反向投影函数。
\(LN(.)\):layer Normalization
\(MSK\):multi-head self-attention module
Msg Token Interaction
Msg token概括了每个分支的信息。
将每个分支的Msg token加起来,然后通过一个slef-attention module返回到各自的分支。
Cross-transformer
Cross-transformer的流程如图Fig.3
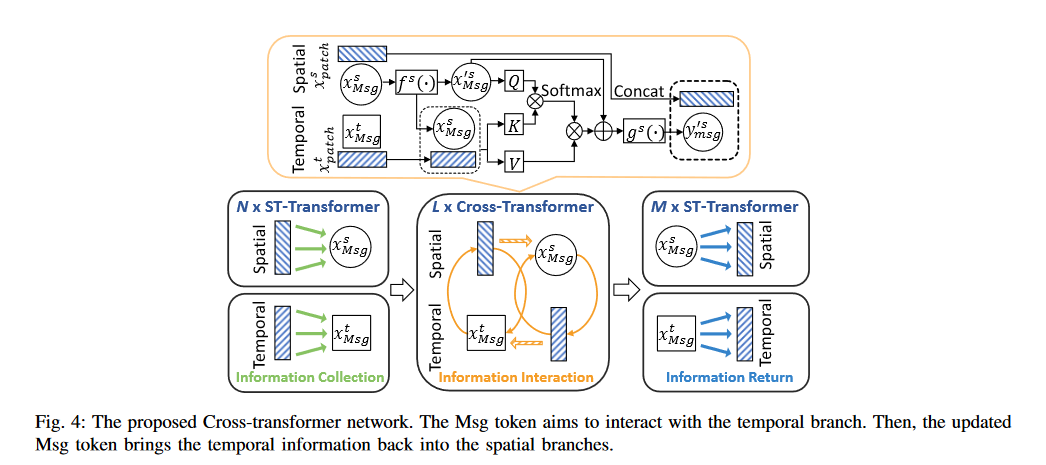
Fig.3 Cross-transformer
Source:
该过程分为三个阶段
Information Collection
不同的分支处理不同的特征信息,然后得到Msg tokenInformation Interaction
如Fig3黄框所示,该过程用于将其他分支的信息吸收到本分支上。通过self-attention machanism来达到交换信息的目的。Information Return
交换信息之后的msg token通过\(M\)个ST-Transformer将信息带回自己的分支。
3.3 Loss function
损失函数由不同部分构成,每个部分优化不同的组件。
Reconstruction loss
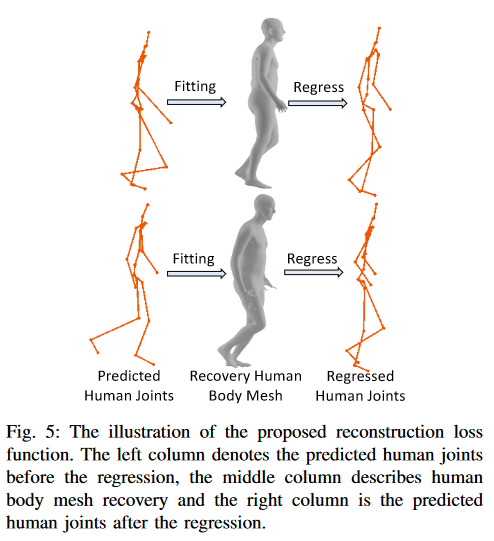
Fig.4 The illustration of the proposed reconstruction loss function
Source:
Fitting 过程是利用了SMPI-X model将人体关节点转换成人体网格,该模型已经被预训练好,然后通过Regression matrix将人体网格还原得到还原后的3D human joints\(J_{3D}^{reg}\) 。
\(J_{3D}^{reg}=GV_{3D}\)
\(G\in \mathbb{R}^{K\times M},(K:关节点数;M:人体网格的向量数)\):regression matrix
\(V_{3D}\in \mathbb{R}^{M\times3}\):人体网格
reconstruction loss\(L_J^{reg}\):
\(\bar{J}_{3 D}\):表示预测的关节点。
Transformer Loss:
\(j_{t}^{(n)}\):ground truth 关节点
\(\tilde{j}_{t}^{(n)}\):预测出的关节点。
Skeleton Integrity Loss:
Global loss:
\[L_{\text {total }}=\alpha_{1} L(X, \tilde{X})+\alpha_{2} L_{s}+\alpha_{3} L_{J}^{\text {reg }} \]\(\alpha_{1}=0.5,\alpha_{2}=0.2,\alpha_{3}=0.3\)
4. Experimental Design
- datasets
- AMASS
- Human3.6M
- Metrics
- MPJPE (Mean Per Joint Position Error)
\(S\):skeleton- PSEnt:用于衡量方法的性能,计算的是一个数据库上的功率谱的熵
每个关节点对应一个特征序列\(x_f\),该特征序列的power spectrum(PS)为:
\(f\):特征
\(e\):频率- PSKLD:计算两个分布之间的距离
short-term prediction
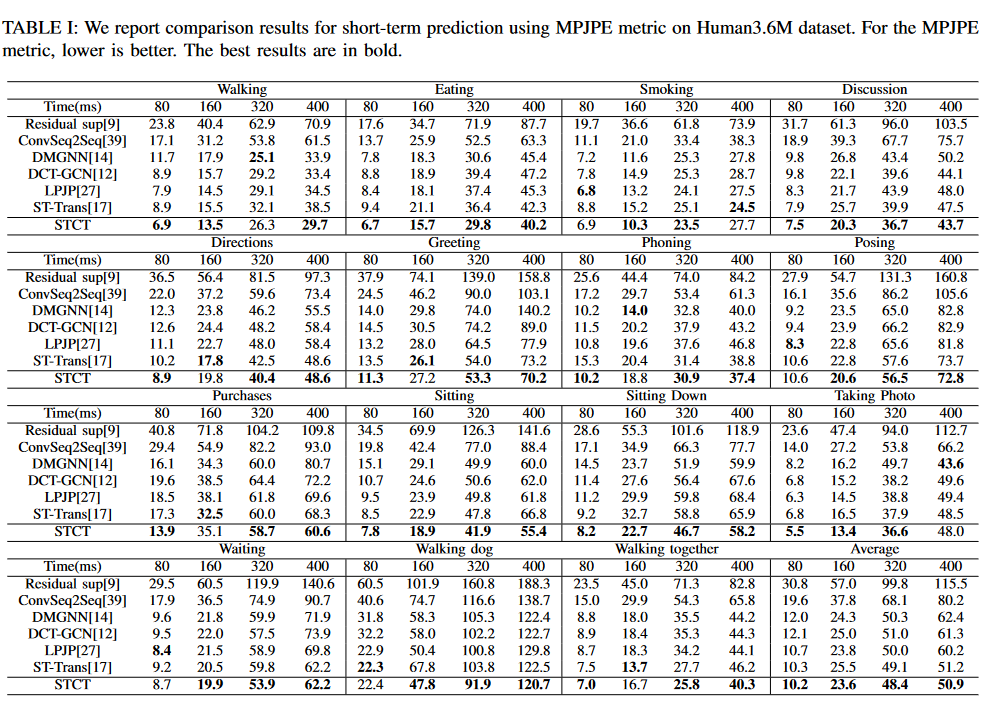
Fig.5 Human3.6M dataset
Source:
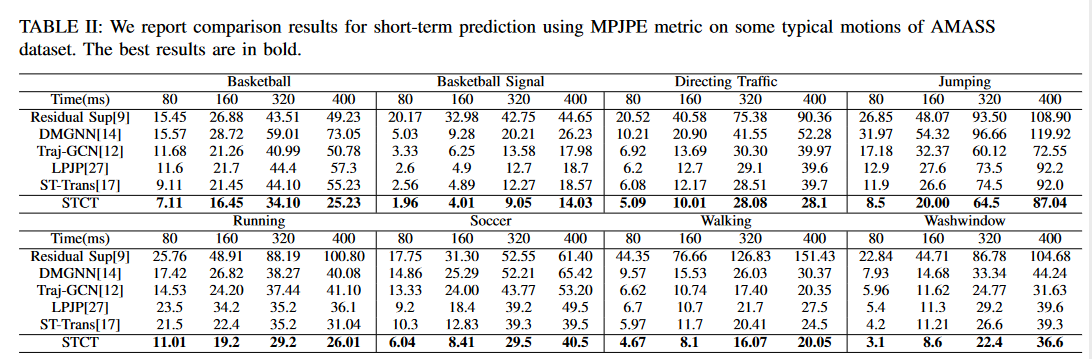
Fig6. AMASS dataset
Source:
long-term prediction
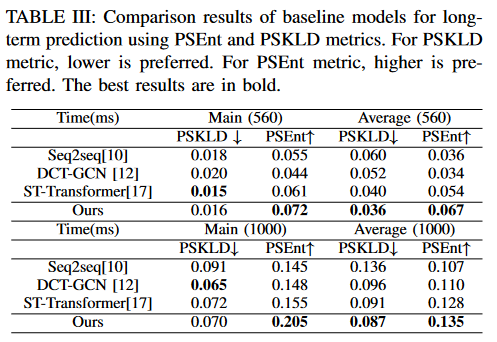
Fig.7.
Source:
Ablation Analysis
- 比较不同交互方法。
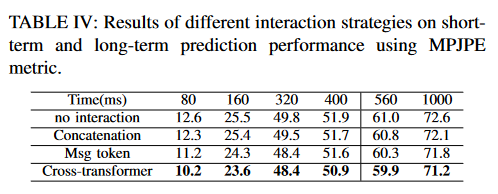
Fig.8
Source:
- 不同损失函数。

Fig.9.
Source:
5. 总结
该文章利用一种交叉transformer整合人体动作序列中的时间和空间维度上面的信息,并且提出了一种基于SMPL-X的模型的重构损失函数,该损失函数可能减少生成的动作序列与真实人体结构之间的差异。