
缩小令人印象深刻的模型演示与实际性能之间的差距对于成功部署企业生成式 AI 至关重要。尽管企业生成式 AI 具有令人难以置信的能力,但这种感知差距可能会成为许多开发人员和企业“生产化”AI 的障碍。这就是检索增强生成 (RAG) 变得不可或缺的地方——它通过建立对 AI 输出的信任来增强您的企业应用程序。今天,Cloud Ace 云一将分享Vertex AI 的 RAG Engine的全面可用性,这是一项完全托管的服务,可帮助您使用数据和方法构建和部署 RAG 实现。借助我们的 Vertex AI RAG Engine,您将能够:
- 适应任何架构:选择最适合您用例的模型、矢量数据库和数据源。这种灵活性可确保 RAG Engine 适合您现有的基础架构,而不是强迫您适应它。
- 随着用例的发展而发展:通过简单的配置更改即可添加新数据源、更新模型或调整检索参数。系统会随着您的发展而发展,在满足新需求的同时保持一致性。
- 通过简单的步骤进行评估:设置具有不同配置的多个 RAG 引擎,以找到最适合您的用例的引擎。
Vertex AI RAG 引擎简介
Vertex AI RAG Engine 是一项托管服务,可让您使用数据和方法构建和部署 RAG 实现。您可以将其视为拥有一支专家团队,他们已经解决了复杂的基础设施挑战,例如高效向量存储、智能分块、最佳检索策略和精确增强 — 同时为您提供针对特定用例进行自定义的控件。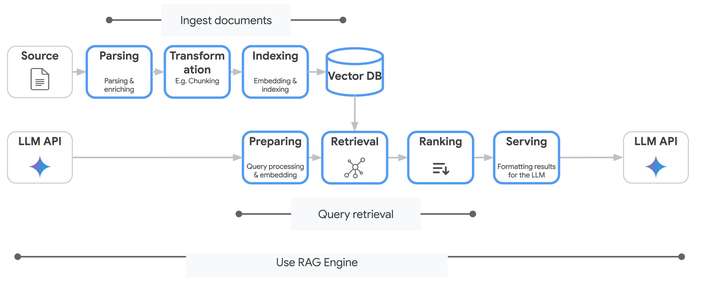 图 1:Vertex AI RAG Engine 工作流程。
Vertex AI 的 RAG 引擎提供了一个充满活力的生态系统,其中有一系列可满足不同需求的选项。
图 1:Vertex AI RAG Engine 工作流程。
Vertex AI 的 RAG 引擎提供了一个充满活力的生态系统,其中有一系列可满足不同需求的选项。
- DIY 功能:DIY RAG 允许用户通过混合和搭配不同的组件来定制解决方案。它非常适合中低复杂度用例,具有易于上手的 API,只需单击几下即可快速进行实验、概念验证和基于 RAG 的应用程序。
- 搜索功能:Vertex AI Search 是一款功能强大、完全托管的解决方案。它支持从简单到复杂的各种用例,具有开箱即用的质量高、易于上手和最低限度的维护。
- 连接器:快速增长的连接器列表可帮助您快速连接到各种数据源,包括 Cloud Storage、Google Drive、Jira、Slack 或本地文件。RAG Engine 通过直观的界面处理提取过程(即使对于多个来源也是如此)。
- 增强的性能和可扩展性:Vertex AI Search 旨在以极低的延迟处理大量数据。这意味着您的 RAG 应用程序的响应时间更快,性能更高,尤其是在处理复杂或广泛的知识库时。
- 简化的数据管理:从各种来源(例如网站、BigQuery 数据集和 Cloud Storage 存储桶)导入数据,从而简化数据提取过程。
- 提高 LLM 输出质量:通过使用 Vertex AI Search 的检索功能,您可以帮助确保您的 RAG 应用程序从语料库中检索最相关的信息,从而获得更准确、更具信息量的 LLM 生成输出。
定制
Vertex AI RAG Engine 的一大优势是其定制能力。这种灵活性让您可以微调各种组件,以完美匹配您的数据和用例。- 解析:当文档被录入索引时,它们会被分成块。RAG Engine 提供了调整块大小和块重叠的可能性,以及支持不同类型文档的不同策略。
- 检索:您可能已经在使用 Pinecone,或者您可能更喜欢 Weaviate 的开源功能。也许您想利用Vertex AI Vector Search或我们的Vector 数据库。RAG Engine 可根据您的选择工作,或者如果您愿意,可以完全为您管理矢量存储。这种灵活性可确保您在需求不断发展时永远不会局限于单一方法。
- 生成:您可以从 Vertex AI Model Garden 中的数百个 LLM 中进行选择,包括 Google 的 Gemini、Llama 和 Claude。
使用 Vertex AI RAG 作为 Gemini 中的工具
Vertex AI 的 RAG Engine 以工具形式与 Gemini API 原生集成。您可以创建使用 RAG 提供上下文相关答案的扎实对话。只需初始化 RAG 检索工具,配置特定设置(例如要检索的文档数量)并使用基于 LLM 的排名器。然后,此工具将传递给 Gemini 模型。from vertexai.preview import rag
from vertexai.preview.generative_models import GenerativeModel, Tool
import vertexai
PROJECT_ID = "PROJECT_ID"
CORPUS_NAME = "projects/{PROJECT_ID}/locations/LOCATION/ragCorpora/RAG_CORPUS_RESOURCE"
MODEL_NAME= "MODEL_NAME"
# Initialize Vertex AI API once per session
vertexai.init(project=PROJECT_ID, location="LOCATION")
config = vertexai.preview.rag.RagRetrievalConfig(
top_k=10,
ranking=rag.Ranking(
llm_ranker=rag.LlmRanker(
model_name=MODEL_NAME
)
)
)
rag_retrieval_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_resources=[
rag.RagResource(
rag_corpus=CORPUS_NAME,
)
],
rag_retrieval_config=config
),
)
)
rag_model = GenerativeModel(
model_name=MODEL_NAME, tools=[rag_retrieval_tool]
)
response = rag_model.generate_content("Why is the sky blue?")
print(response.text)
# Example response:
# The sky appears blue due to a phenomenon called Rayleigh scattering.
# Sunlight, which contains all colors of the rainbow, is scattered
# by the tiny particles in the Earth's atmosphere....
# ...
使用 Vertex AI Search 作为检索器:
Vertex AI Search 提供了一种在 Vertex AI RAG 应用程序中检索和管理数据的解决方案。通过使用 Vertex AI Search 作为检索后端,您可以提高性能、可扩展性和集成的简易性。- 增强的性能和可扩展性:Vertex AI Search 旨在以极低的延迟处理大量数据。这意味着您的 RAG 应用程序的响应时间更快,性能更高,尤其是在处理复杂或广泛的知识库时。
- 简化的数据管理:从各种来源(例如网站、BigQuery 数据集和 Cloud Storage 存储桶)导入数据,从而简化数据提取过程。
- 无缝集成:Vertex AI 提供与 Vertex AI Search 的内置集成,让您可以选择 Vertex AI Search 作为 RAG 应用程序的语料库后端。这简化了集成过程并有助于确保组件之间的最佳兼容性。
- 提高 LLM 输出质量:通过使用 Vertex AI Search 的检索功能,您可以帮助确保您的 RAG 应用程序从语料库中检索最相关的信息,从而获得更准确、更具信息量的 LLM 生成输出。
from vertexai.preview import rag
import vertexai
PROJECT_ID = "PROJECT_ID"
DISPLAY_NAME = "DISPLAY_NAME"
ENGINE_NAME = "ENGINE_NAME"
# Initialize Vertex AI API once per session
vertexai.init(project=PROJECT_ID, location="us-central1")
# Create a corpus
vertex_ai_search_config = rag.VertexAiSearchConfig(
serving_config=f"{ENGINE_NAME}/servingConfigs/default_search",
)
rag_corpus = rag.create_corpus(
display_name=DISPLAY_NAME,
vertex_ai_search_config=vertex_ai_search_config,
)
# Check the corpus just created
new_corpus = rag.get_corpus(name=rag_corpus.name)
print(new_corpus)