大语言模型(LLM)通过其参数储存了大量信息,这些信息主要以密集层中线性矩阵变换的权重形式存在。然而,参数规模的扩大必然导致计算成本和能源消耗的显著增加。
这种参数存储方式是否可以通过更高效的键值查找机制来优化?
尽管此前已有多项相关研究,但在当前 AI 架构规模下的实践尚属首次。
Meta 研究团队通过开发记忆层技术,成功实现了对现有大语言模型的性能提升。该技术通过替换一个或多个 Transformer 层中的前馈网络(FFN)来实现功能。
实验数据显示,记忆层的引入使大语言模型在事实准确性方面提升了 100% 以上。同时其在代码生成和通用知识领域的表现可与使用 4 倍计算资源训练的传统大语言模型相媲美。
在事实性任务评估中,搭载记忆层的大语言模型的性能明显优于在相似计算资源和参数规模条件下训练的专家混合型(Mixture-of-experts)架构。
本文将深入探讨记忆层的技术原理及其对大语言模型性能的提升机制,这一技术创新对下一代 AI 架构的发展具有重要意义。
记忆层的技术原理
我们先看一下Transformer的基本机构
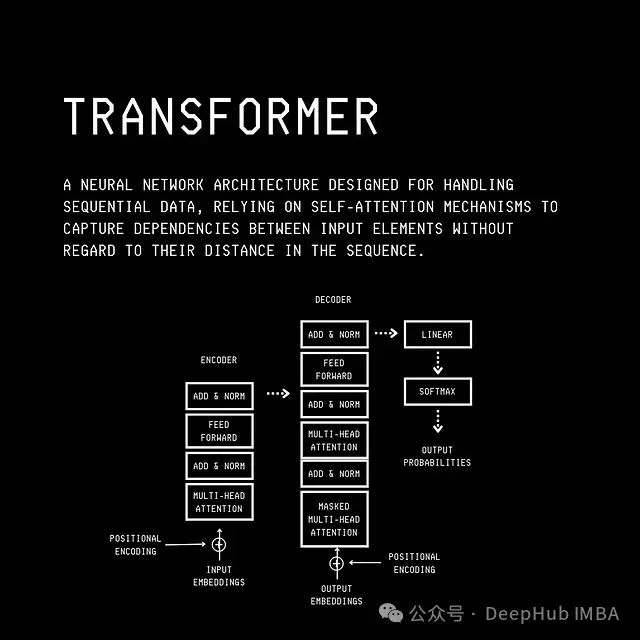
记忆层在功能实现上与 Transformer 的注意力机制有相似之处。基本原理是:给定查询(
https://avoid.overfit.cn/post/bc94fb7278ff425f8af5ffa053a5ab12
标签:Transformer,架构,语言,模型,记忆,LLM,键值 From: https://www.cnblogs.com/deephub/p/18687195