看到DeepSeek-V3使用了多token预测(Multi-token Prediction, MTP)技术,该技术原始论文是由Meta 发在ICML 2024的一篇Poster。
论文: [2404.19737] Better & Faster Large Language Models via Multi-token Prediction
主要内容
1. 作者和团队信息
- 团队背景:
- 所有作者都隶属于Meta(原Facebook)的AI研究部门,这是一个在人工智能领域具有领先地位的团队。
- 主要贡献者:
- Fabian Gloeckle 和 Badr Youbi Idrissi 为共同第一作者,David Lopez-Paz 和 Gabriel Synnaeve 为共同通讯作者。
2. 背景和动机
- 发表时间:ICML 2024 Poster
- 研究问题:论文的核心问题是:如何提高大型语言模型的训练效率,使其在相同的计算资源下,获得更好的性能。
- 问题背景:
- 目前的大型语言模型(如GPT和LLaMA)通常使用「下一个token预测」(next-token prediction)作为训练目标。
- 尽管这种方法取得了显著的成功,但其训练效率较低,需要大量的数据和计算资源。
- 「下一个token预测」倾向于捕捉局部模式,而忽略全局上下文和「硬决策」,这可能导致模型泛化能力不足。
- 人类儿童在学习语言时使用的训练数据远少于大型语言模型,但其学习效率和语言理解能力却非常高,这促使研究者思考是否可以通过改进训练方式来提高大型语言模型的学习效率。
- 动机:为了解决「下一个token预测」的低效性,论文提出了一种新的训练方法——多token预测,旨在提高模型的样本效率和整体性能。
3. 相关研究
- 传统方法:「下一个token预测」是目前主流的语言模型训练方法。其基本思想是,模型根据给定的上下文,预测下一个最有可能出现的token。
- 相关研究的不足:
- 低效性:传统的「下一个token预测」需要大量的训练数据才能达到较好的性能。
- 局部性:模型容易陷入局部模式,难以学习长距离依赖关系和全局语义。
- 推理速度慢:在推理时,模型需要逐个生成token,导致推理速度较慢。
- 其他相关工作:
- 文中也提及了一些通过修改Attention Mask来训练模型的工作,例如:使用Span Corruption的方法,或是使用Permuted Sequences的方法。但这些工作通常只在部分token上进行训练。
4. 核心思路
- 多token预测(Multi-token Prediction):论文的核心思路是,让模型在训练时,一次性预测多个未来token,而不是仅仅预测下一个token。
- 灵感来源:
- 人类学习:人类在理解语言时,通常会考虑多个词之间的关系,而不是只关注单个词。这启发了作者尝试多token预测的方法。
- 并行计算:多个token的预测可以并行进行,这有助于提高训练效率。
- 主要观点:
- 多token预测可以迫使模型学习token之间的依赖关系,更好地理解上下文信息。
- 多token预测可以促使模型关注更重要的「决策点」,而不是只关注局部模式。
- 通过多token预测,模型可以更快地学习到语言的全局结构,从而提高样本效率。
5. 方案与技术
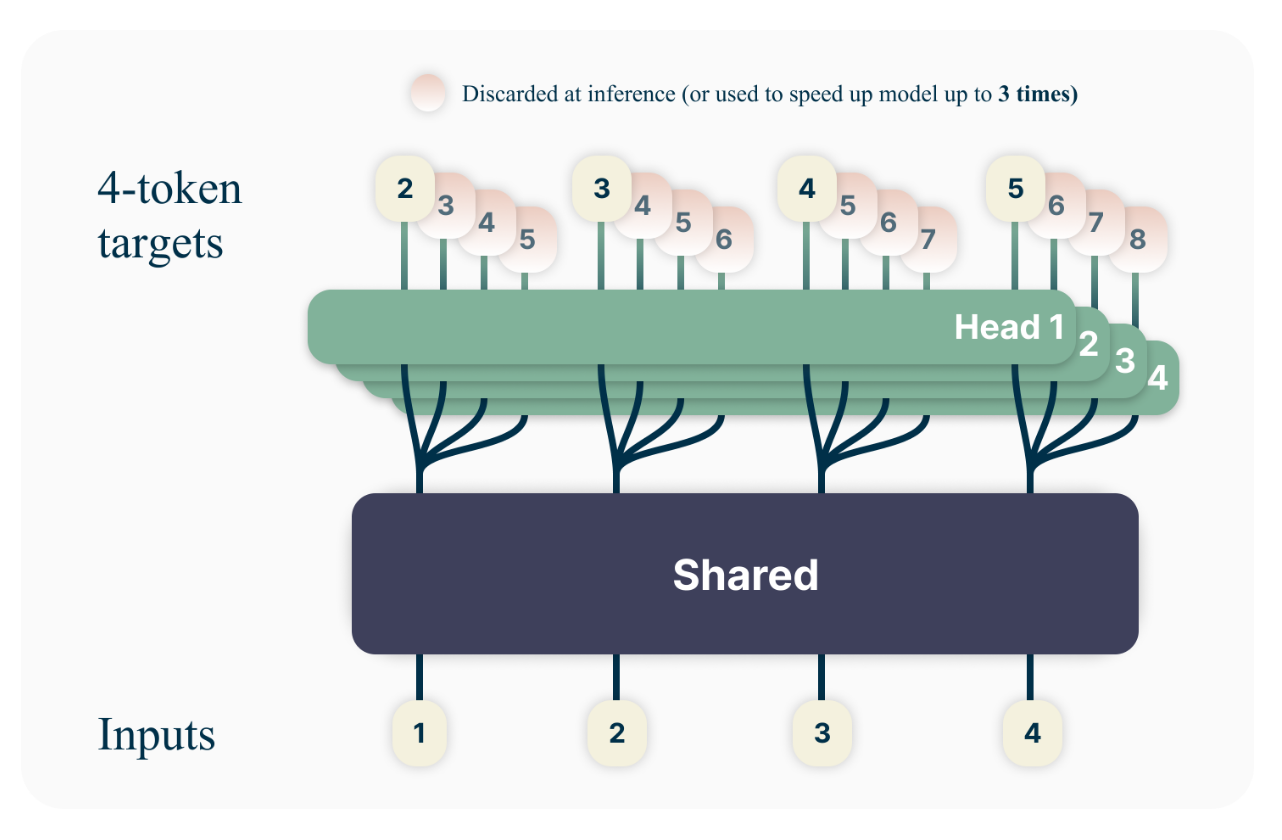
- 模型架构:
- 共享主干(Shared Trunk):模型的主体部分是一个Transformer结构,用于提取输入文本的特征表示。
- 独立输出头(Independent Output Heads):在共享主干的基础上,为每个待预测的token都设置一个独立的输出头。这些输出头并行工作,预测对应的未来token。
- Unembedding层: 每个输出头后面跟着一个Unembedding层,将Transformer的输出转换成词表空间(vocabulary space)。
- 损失函数:使用交叉熵损失函数来衡量模型预测的准确性。
- 内存优化:为了解决多token预测带来的内存消耗问题,论文提出了一种内存高效的实现方法。
- 前向和反向传播顺序调整:在计算梯度时,模型会依次计算每个输出头的梯度,而不是一次性计算所有头的梯度,从而避免了同时存储所有输出头的梯度信息,降低GPU内存占用。
- 推理加速:
- 自推测解码(Self-Speculative Decoding):利用多token预测的额外输出头进行自推测解码,从而加速推理过程。
- 工作原理:先用多个输出头并行预测多个token,然后用主输出头(next-token prediction head)验证预测结果,并选择最有可能的预测结果。
6. 实验与结论
- 实验设置:
- 数据集:论文使用了多种数据集进行实验,包括代码数据集(MBPP、HumanEval、APPS)、自然语言数据集以及一些合成数据集。
- 模型规模:实验中使用了多种规模的模型,从300M到13B参数不等。
- 训练方法:将多token预测与标准的下一个token预测进行对比。
- 实验结果:
- 代码生成:在代码生成任务中,多token预测显著优于「下一个token预测」。例如,在13B参数模型上,多token预测在HumanEval上提升了12%,在MBPP上提升了17%。
- 模型规模效应:多token预测的优势随着模型规模的增大而更加明显。
- 推理速度:使用多token预测训练的模型,可以通过自推测解码实现更快的推理速度。例如,4-token预测模型可以实现高达3倍的推理速度提升。
- 字节级别模型:在字节级别模型中,多字节预测也显示出巨大的优势。
- 消融实验:研究了不同预测token数量(n)的影响,发现n=4通常能取得最佳效果。
- 多轮训练:多token预测在多轮训练中仍然保持优势。
- 微调:在微调任务中,用多token预测预训练的模型也优于用下一个token预测预训练的模型。
- 自然语言:在自然语言任务中,多token预测在生成式任务(如文本摘要)上表现更好,但在选择式任务(如多项选择题)上不如「下一个token预测」。
- 合成数据实验:通过合成数据实验,发现多token预测可以提升模型的归纳能力和算法推理能力。
- 推理加速:使用自推测解码,多token预测可以显著提高推理速度。例如,8-token预测模型达到了6.4倍的推理加速。
- 核心发现和结论:
- 多token预测是一种更有效的语言模型训练方法,可以在相同计算资源下,获得更好的性能。
- 多token预测可以促使模型学习token之间的依赖关系,更好地理解上下文信息。
- 多token预测可以促使模型关注更重要的「决策点」。
- 多token预测可以提高模型的样本效率、生成质量和推理速度。
7. 贡献
- 主要贡献:
- 提出了一种简单且高效的多token预测架构,没有额外的训练时间和内存开销。
- 通过实验证明,多token预测在大规模模型中具有显著优势,尤其在代码生成任务上。
- 多token预测可以通过自推测解码,显著加快模型推理速度。
- 对后续研究的启发和影响:
- 鼓励研究者探索新的辅助损失函数,以提高大型语言模型的性能。
- 为后续研究提供了一种新的训练范式,有望改进大型语言模型的生成质量、一致性和推理能力。
- 促进了对大型语言模型训练和推理效率的进一步研究。
8. 不足
- 超参数选择:
- 论文中提到,多token预测的最佳预测token数量(n)可能依赖于输入数据的分布,如何自动选择最佳的n值还需要进一步研究。
- 不同的词表大小可能也需要调整多token预测的参数。
- 自然语言任务的挑战:
- 在某些自然语言任务中,多token预测的效果不如「下一个token预测」,这表明多token预测可能更适合生成式任务,而非判别式任务。
- 如何使多token预测在各种自然语言任务中都发挥最佳效果,仍需进一步研究。
- 理论分析:论文虽然从信息论角度进行了一些分析,但其理论基础仍需进一步完善。
QA
Q1:为什么传统的「下一个token预测」方法效率较低?
- 局部性:它只关注预测下一个token,容易陷入局部模式,难以学习长距离依赖关系和全局语义。就像一个只关注眼前道路的司机,容易错过全局的道路规划。
- 训练数据需求大:为了克服局部性的问题,模型需要大量的训练数据,这导致训练效率低下。
- 「硬决策」忽视:它倾向于捕捉简单的局部模式,而忽略了那些对生成文本的整体质量有重要影响的「硬决策」。这就像背诵课文一样,只关注每个词,而忽略了整体含义和上下文。
- 推理速度慢:推理时,模型需要逐个生成token,导致推理速度较慢。
Q2:多token预测是如何工作的?它与「下一个token预测」有什么不同?
- 预测范围:「下一个token预测」只预测一个token,而多token预测则预测多个token。
- 训练目标:多token预测的目标是让模型学习多个token之间的依赖关系,而「下一个token预测」的目标是学习单个token的出现概率。
- 学习方式:多token预测可以迫使模型关注更重要的「决策点」,学习更全局的模式,而「下一个token预测」则更容易陷入局部模式。
- 并行性:多token预测允许并行预测多个token,从而提高训练效率。
Q3:为什么多token预测可以提高模型的样本效率?
- 更强的监督信号:通过预测多个token,模型可以获得更丰富的监督信号,从而更快地学习到语言的结构和规律。
- 关注重要决策点:多token预测可以促使模型关注那些对后续文本生成有重要影响的「决策点」,而不是只关注局部模式。
- 学习长距离依赖:多token预测可以帮助模型学习token之间的长距离依赖关系,从而更好地理解上下文信息。
- 并行计算:多token预测允许并行预测多个token,从而提高训练效率,使得模型在有限的训练数据上能学习到更多的信息。
Q4:论文中是如何解决多token预测带来的内存消耗问题的?
- 前向和反向传播顺序调整:在计算梯度时,模型会依次计算每个输出头的梯度,而不是一次性计算所有头的梯度。这样做的好处是,每次只需要存储一个输出头的梯度信息,从而避免了同时存储所有输出头的梯度信息,降低了GPU内存占用。
Q5:自推测解码是如何加速模型推理的?它与多token预测有什么关系?
自推测解码是一种加速模型推理的方法,它利用了多token预测的额外输出头:
- 工作原理:首先,模型使用多个输出头并行预测多个token;然后,模型使用主输出头(next-token prediction head)验证预测结果,并选择最有可能的预测结果。如果预测正确,则可以跳过多个token的生成,从而加速推理过程。
- 与多token预测的关系:自推测解码是建立在多token预测基础上的。只有通过多token预测训练的模型,才具备多个输出头,才能进行自推测解码。
Q6:为什么多token预测在代码生成任务中表现更好?
- 代码的结构性:代码通常具有严格的结构和逻辑,这使得代码中后续token的依赖性更强,而多token预测可以更好地捕捉这种依赖性。
- 重要决策点:代码中的某些token(如函数名、变量名)通常是重要的「决策点」,多token预测可以促使模型更加关注这些token。
- 生成式任务特性:代码生成任务本质上是一种生成式任务,而多token预测更适合生成式任务。
Q7:为什么在自然语言的多项选择题中,多token预测表现不如「下一个token预测」?
- 判别式任务特性:多项选择题本质上是一种判别式任务,而「下一个token预测」更适合判别式任务。
- 局部信息:多项选择题更侧重于理解局部信息,而不是全局上下文。而多token预测更多地关注全局信息和长距离依赖关系。
- 信息冗余:多项选择题的选项之间通常具有很高的信息冗余,而「下一个token预测」可能更擅长处理这种冗余。
Q8:论文中提到多token预测可以提高模型的归纳能力和算法推理能力,这是如何体现的?
论文通过合成数据实验,证明了多token预测可以提高模型的归纳能力和算法推理能力:
- 归纳能力:在儿童故事数据集上,多token预测可以帮助模型更好地学习字符名称之间的联系,从而在新的故事中正确预测名称的第二个token。这表明模型具有了一定的归纳能力,可以从已有的模式中推广到新的情况。
- 算法推理能力:在多项式运算任务上,多token预测可以帮助模型更好地学习运算规则,从而在不同难度的运算任务中取得更好的表现。这表明模型具有了一定的算法推理能力,可以按照给定的规则进行计算。
Q9:进一步研究多token预测,有哪些可以入手的方向?
- 自适应的token预测数量:研究如何根据输入数据和任务动态调整预测的token数量。
- 多头之间的关系:探索不同的多头架构,例如考虑输出头之间的相互依赖关系,设计更精巧的结构。
- 不同领域的应用:在更多领域(如图像生成、语音识别)探索多token预测的应用潜力。
- 理论分析:深入研究多token预测背后的理论机制,为实践提供更坚实的理论基础。
- 可解释性:研究如何提高多token预测模型的可解释性,更好地理解模型的决策过程。
- 结合人类认知:深入研究人类语言学习的机制,尝试将人类认知融入多token预测的框架。
伪代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义多词预测的Transformer模型
class MultiTokenTransformer(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_encoder_layers, dim_feedforward,
max_seq_length, num_future_tokens, dropout=0.1):
super(MultiTokenTransformer, self).__init__()
self.d_model = d_model
self.num_future_tokens = num_future_tokens # 预测的未来词数量
# 词嵌入层
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码
self.positional_encoding = PositionalEncoding(d_model, dropout, max_seq_length)
# 共享的Transformer编码器(主干)
encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead,
dim_feedforward=dim_feedforward,
dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
# 定义多个独立的输出头
self.output_heads = nn.ModuleList([
nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Linear(dim_feedforward, vocab_size)
) for _ in range(num_future_tokens)
])
# 初始化参数
self._reset_parameters()
def _reset_parameters(self):
nn.init.xavier_uniform_(self.embedding.weight)
for head in self.output_heads:
for layer in head:
if isinstance(layer, nn.Linear):
nn.init.xavier_uniform_(layer.weight)
if layer.bias is not None:
nn.init.zeros_(layer.bias)
def encode(self, src):
"""
编码输入序列,返回共享的表示(memory)
输入:
src: [seq_length, batch_size]
输出:
memory: [seq_length, batch_size, d_model]
"""
# 词嵌入并添加位置编码
src_emb = self.embedding(src) * (self.d_model ** 0.5)
src_emb = self.positional_encoding(src_emb)
# 通过Transformer编码器(共享主干)
memory = self.transformer_encoder(src_emb)
return memory
def forward_head(self, memory, head_index):
"""
计算指定输出头的输出
输入:
memory: [seq_length, batch_size, d_model]
head_index: 输出头的索引
输出:
output: [seq_length, batch_size, vocab_size]
"""
output = self.output_heads[head_index](memory)
return output
def forward(self, src):
"""
完整的前向传播,返回所有输出头的结果
输入:
src: [seq_length, batch_size]
输出:
outputs: {'logits_head_0': ..., 'logits_head_1': ..., ...}
"""
memory = self.encode(src) # [seq_length, batch_size, d_model]
outputs = {}
for i in range(self.num_future_tokens):
logits = self.forward_head(memory, i) # [seq_length, batch_size, vocab_size]
outputs[f'logits_head_{i}'] = logits
return outputs
# 位置编码的实现
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=512):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 创建位置编码矩阵,形状为[max_len, d_model]
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # [max_len, 1]
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))
# 计算sin和cos位置编码
pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置
pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置
pe = pe.unsqueeze(1) # [max_len, 1, d_model]
self.register_buffer('pe', pe)
def forward(self, x):
"""
输入:
x: [seq_length, batch_size, d_model]
输出:
x: 添加了位置编码的输入
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
# 假设我们有以下参数
vocab_size = 10000 # 词表大小
d_model = 512 # 模型隐藏层维度
nhead = 8 # 注意力头数量
num_encoder_layers = 6 # Transformer编码器层数
num_decoder_layers = 6 # 如果有解码器,可设置解码器层数(本例中未使用)
dim_feedforward = 2048 # 前馈神经网络维度
max_seq_length = 512 # 序列最大长度
num_future_tokens = 4 # 预测的未来词数量
dropout = 0.1
# 创建模型实例
model = MultiTokenTransformer(
vocab_size=vocab_size,
d_model=d_model,
nhead=nhead,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers,
dim_feedforward=dim_feedforward,
max_seq_length=max_seq_length,
num_future_tokens=num_future_tokens,
dropout=dropout
)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 假设我们有以下数据
# input_seq: [seq_length, batch_size]
# target_seq: [seq_length, batch_size]
# target_seq 应该是 input_seq 在时间步上向后移动的序列
# 为了多词预测,我们需要为每个位置的输入,准备未来 num_future_tokens 个目标词
# 示例:训练循环
for epoch in range(num_epochs):
for batch in data_loader:
# 获取输入和目标序列
input_seq = batch['input'] # [seq_length, batch_size]
target_seq = batch['target'] # [seq_length, batch_size]
optimizer.zero_grad()
# 前向传播共享主干
memory = model.encode(input_seq) # [seq_length, batch_size, d_model]
# 对于每个输出头,依次计算前向和反向传播
for i in range(num_future_tokens):
# 前向传播第 i 个输出头
output = model.forward_head(memory, i) # [seq_length, batch_size, vocab_size]
# 获取对应的目标序列,向后偏移 i+1 个时间步
true_targets = target_seq[i+1:] # [seq_length - (i+1), batch_size]
pred_outputs = output[:-(i+1)] # [seq_length - (i+1), batch_size, vocab_size]
# 重塑张量以适应 CrossEntropyLoss 的输入格式
pred_outputs = pred_outputs.view(-1, vocab_size)
true_targets = true_targets.contiguous().view(-1)
# 计算当前输出头的损失
loss = criterion(pred_outputs, true_targets)
# 反向传播,累积梯度
loss.backward()
# 释放与当前输出头相关的计算图,节省内存
del output, pred_outputs, true_targets, loss
torch.cuda.empty_cache() # 可选,释放未使用的显存
# 更新模型参数
optimizer.step()
# 打印损失
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
# 推理时的使用示例
# 假设我们只使用第一个输出头来进行下一词预测
def generate_text(model, input_seq, max_length):
model.eval()
generated = input_seq.clone() # 克隆输入序列,避免修改原始输入
with torch.no_grad():
for _ in range(max_length):
# 前向传播共享主干,获取隐藏状态
memory = model.encode(generated) # [seq_length, batch_size, hidden_size]
# 使用第一个输出头(next-token prediction head)获取 logits
next_token_logits = model.forward_head(memory, head_index=0) # [seq_length, batch_size, vocab_size]
# 取最后一个时间步的 logits
next_token_logits = next_token_logits[-1, 0, :] # [vocab_size]
# 获取预测的下一个 token
next_token = torch.argmax(next_token_logits).unsqueeze(0).unsqueeze(1) # [1, 1]
# 将预测的 token 添加到生成的序列中
generated = torch.cat((generated, next_token), dim=0)
return generated
# 自我推测解码的简单示例
def generate_text_with_self_speculative_decoding(model, input_seq, max_length, tokenizer, prob_threshold=0.9):
"""
使用自我推测解码生成文本
参数:
- model: 训练好的多词预测模型,具有多个输出头
- input_seq: 初始的输入序列,形状为 [seq_length, batch_size]
- max_length: 生成的最大长度
- tokenizer: 分词器,用于解码生成的序列
- prob_threshold: 概率阈值,超过该阈值的 token 被接受
"""
model.eval()
generated = input_seq.clone() # 克隆输入序列,防止修改原始序列
seq_length, batch_size = generated.size()
with torch.no_grad():
while generated.size(0) < max_length:
# 获取模型的输出
outputs = model(generated)
# 获取 speculative tokens
speculative_tokens = []
for i in range(model.num_future_tokens):
logits = outputs[f'logits_head_{i+1}'] # 这里假设 head_0 是验证头,head_1 开始是推测头
# 取最后一个时间步的 logits
last_logits = logits[-1, :, :] # [batch_size, vocab_size]
probs = F.softmax(last_logits, dim=-1) # 计算概率分布
next_token = torch.argmax(probs, dim=-1, keepdim=True) # [batch_size, 1]
speculative_tokens.append(next_token)
# 将 speculative tokens 拼接到当前生成的序列中
speculative_tokens_tensor = torch.cat(speculative_tokens, dim=1) # [batch_size, num_future_tokens]
extended_generated = torch.cat([generated.transpose(0,1), speculative_tokens_tensor], dim=1) # [batch_size, seq_length + num_future_tokens]
extended_generated = extended_generated.transpose(0,1) # 转置回 [seq_length + num_future_tokens, batch_size]
# 使用验证头(head_0)验证 speculative tokens
extended_memory = model.encode(extended_generated) # [extended_seq_length, batch_size, d_model]
validation_logits = model.forward_head(extended_memory, head_index=0) # [extended_seq_length, batch_size, vocab_size]
# 提取 speculative tokens 部分的 logits
validation_logits = validation_logits[-model.num_future_tokens:, :, :] # [num_future_tokens, batch_size, vocab_size]
# 计算接受概率
acceptance_probs = []
for i in range(model.num_future_tokens):
logits = validation_logits[i, :, :] # [batch_size, vocab_size]
probs = F.softmax(logits, dim=-1) # 计算概率分布
token = speculative_tokens[i] # [batch_size, 1]
prob = probs.gather(dim=1, index=token) # 提取对应token的概率 [batch_size, 1]
acceptance_probs.append(prob)
acceptance_probs_tensor = torch.cat(acceptance_probs, dim=1) # [batch_size, num_future_tokens]
# 根据概率阈值创建接受掩码
accept_mask = (acceptance_probs_tensor >= prob_threshold).squeeze(0) # [num_future_tokens]
# 找到第一个不被接受的下标
if accept_mask.any():
# 如果存在被接受的token
first_reject_idx = (~accept_mask).nonzero(as_tuple=True)[0]
if len(first_reject_idx) > 0:
# 存在不被接受的token,接受第一个不被接受下标之前的tokens
num_accept = first_reject_idx[0].item()
else:
# 所有token都被接受
num_accept = model.num_future_tokens
else:
# 如果没有token被接受
num_accept = 0
if num_accept > 0:
# 接受第一个不被接受下标之前的tokens
accepted_tokens = speculative_tokens_tensor[:, :num_accept] # [batch_size, num_accept]
accepted_tokens = accepted_tokens.transpose(0,1) # [num_accept, batch_size]
generated = torch.cat([generated, accepted_tokens], dim=0) # 更新生成的序列
else:
# 如果没有 tokens 被接受,使用验证头生成一个 token
logits = outputs['logits_head_0'][-1, :, :] # [batch_size, vocab_size]
probs = F.softmax(logits, dim=-1)
next_token = torch.argmax(probs, dim=-1, keepdim=True) # [batch_size, 1]
generated = torch.cat([generated, next_token], dim=0)
# 将生成的 token IDs 转换为文本
generated_text_indices = generated.squeeze(1).tolist() # [total_seq_length]
generated_text = tokenizer.decode(generated_text_indices, skip_special_tokens=True)
return generated_text
import torch import torch.nn as nn import torch.nn.functional as F # 定义多词预测的Transformer模型 class MultiTokenTransformer(nn.模块): def __init__(self, vocab_size, d_model, nhead, num_encoder_layers, dim_feedforward, max_seq_length, num_future_tokens, dropout=0.1): super(MultiTokenTransformer, self).__init__() self.d_model = d_model self.num_future_tokens = num_future_tokens # 预测的未来词数量 # 词嵌入层 self.embedding = nn.Embedding(vocab_size, d_model) # 位置编码 self.positional_encoding = PositionalEncoding(d_model, dropout, max_seq_length) # 共享的Transformer编码器(主干) encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, dropout=dropout) self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_encoder_layers) # 定义多个独立的输出头 self.output_heads = nn.ModuleList([ nn.顺序 ( nn.线性 (d_model, dim_feedforward), nn.ReLU(), nn.Linear(dim_feedforward, vocab_size) ) for _ in range(num_future_tokens) ]) # 初始化参数 self._reset_parameters() def _reset_parameters(self): nn.init.xavier_uniform_(self.embedding.weight) for head in self.output_heads: for layer in head: if isinstance(layer, nn.Linear): nn.init.xavier_uniform_(layer.weight) if layer.bias is not None: nn.init.zeros_(layer.bias) def encode(self, src): “”“ 编码输入序列,返回共享的表示(memory) 输入: src: [seq_length, batch_size] 输出: memory: [seq_length, batch_size, d_model] ”“” # 词嵌入并添加位置编码 src_emb = self.embedding(src) * (self.d_model ** 0.5) src_emb = self.positional_encoding(src_emb) # 通过Transformer编码器(共享主干) memory = self.transformer_encoder(src_emb) return memory def forward_head(self, memory, head_index): “”“ 计算指定输出头的输出 输入: memory: [seq_length, batch_size, d_model] head_index: 输出头的索引 输出: output: [seq_length, batch_size, vocab_size] “”“ output = self.output_heads[head_index]((memory) return output def forward(self, src): ”“” 完整的前向传播,返回所有输出头的结果 输入: src: [seq_length, batch_size] 输出: outputs: {'logits_head_0': ..., 'logits_head_1': ..., ...} “””线性): nn.init.xavier_uniform_(layer.weight) 如果 layer.bias 不是 None: nn.init.zeros_(layer.bias) def encode(self, src): “”“ 编码输入序列,返回共享的表示(memory) 输入: src: [seq_length, batch_size] 输出: memory: [seq_length, batch_size,d_model] ”“” # 词嵌入并添加位置编码 src_emb = self.embedding(src) * (self.d_model ** 0.5) src_emb = self.positional_encoding(src_emb) # 通过Transformer编码器(共享主干) memory = self.transformer_encoder(src_emb) return memory def forward_head(self, memory, head_index): “”“ 计算指定输出头的输出 输入: memory: [seq_length, batch_size, d_model] head_index: 输出头的索引 输出: output: [seq_length, batch_size, vocab_size] “”“ output = self.output_heads[head_index](memory) return output def forward(self, src): ”“” 完整的前向传播,返回所有输出头的结果 输入: src: [seq_length, batch_size] 输出: outputs: {'logits_head_0': ..., 'logits_head_1': ..., ...} “”“ memory = self.encode(src) # [seq_length, batch_size, d_model] outputs = {} for i in range(self.num_future_tokens): logits = self.forward_head(memory, i) # [seq_length, batch_size, vocab_size] outputs[f'logits_head_{i}'] = logits return outputs # 位置编码的实现 class PositionalEncoding(nn. Module): def __init__(self, d_model, dropout=0.1, max_len=512): super(PositionalEncoding, self).__init__() self.dropout = nn. Dropout(p=dropout) # 创建位置编码矩阵,形状为[max_len, d_model] pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # [max_len, 1] div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0))g(src_emb) # 通过Transformer编码器(共享主干) memory = self.transformer_encoder(src_emb) return memory def forward_head(self, memory, head_index): “”“ 计算指定输出头的输出 输入: memory: [seq_length, batch_size, d_model] head_index: 输出头的索引 输出: output: [seq_length, batch_size, vocab_size] ”“” output = self.output_heads[head_index](memory) return output def forward(self, src): “”“ 完整的前向传播,返回所有输出头的结果 输入: src: [seq_length, batch_size] 输出: outputs: {'logits_head_0': ..., 'logits_head_1': ..., ...} ”“” memory = self.encode(src) # [seq_length, batch_size, d_model] outputs = {} for i in range(self.num_future_tokens): logits = self.forward_head(memory, i) # [seq_length, batch_size, vocab_size] outputs[f'logits_head_{i}'] = logits return outputs # 位置编码的实现 class PositionalEncoding(nn. Module): def __init__(self, d_model, dropout=0.1, max_len=512): super(PositionalEncoding, self).__init__() self.dropout = nn. Dropout(p=dropout) # 创建位置编码矩阵,形状为[max_len, d_model] pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # [max_len, 1] div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model)) # 计算sin和cos位置编码 pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置 pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置 pe = pe.unsqueeze(1) # [max_len, 1, d_model] self.register_buffer('pe', pe) def forward(self, x): “”“ 输入: x: [seq_length, batch_size, d_model] 输出: x: 添加了位置编码的输入 “”“ x = x + self.pe[:x.size(0), :] return self.dropout(x) # 假设我们有以下参数 vocab_size = 10000 # 词表大小 d_model = 512 # 模型隐藏层维度 nhead = 8 # 注意力头数量 num_encoder_layers = 6 # 转换器编码器层数 num_decoder_layers = 6 # 如果有解码器,可设置解码器层数(本例中未使用) dim_feedforward = 2048 # 前馈神经网络维度 max_seq_length = 512 # 序列最大长度 num_future_tokens = 4 # 预测的未来词量 dropout = 0.1 # 创建模型实例 model = MultiTokenTransformer( vocab_size=vocab_size, d_model=d_model, nhead=nhead, num_encoder_layers=num_encoder_layers, num_decoder_layers=num_decoder_layers, dim_feedforward=dim_feedforward, max_seq_length=max_seq_length, num_future_tokens=num_future_tokens, dropout=dropout ) # 定义损失函数和优化器 criteria = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) # 假设我们有以下数据 # input_seq: [seq_length, batch_size]# target_seq: [seq_length, batch_size] # target_seq 应该是 input_seq 在时间步上向后移动的序列 # 为了多词预测,我们需要为每个位置的输入,准备未来 num_future_tokens 个目标词 # 示例:训练循环 for epoch in range(num_epochs): for batch in data_loader: # 获取输入和目标序列 input_seq = batch['input'] # [seq_length, batch_size] target_seq = batch['target'] # [seq_length, batch_size] optimizer.zero_grad() # 前向传播共享主干 memory = model.encode(input_seq) # [seq_length, batch_size, d_model] # 对于每个输出头,依次计算前向和反向传播 for i in range(num_future_tokens): # 前向传播第 i 个输出头 output = model.forward_head(memory, i) # [seq_length, batch_size, vocab_size] # 获取对应的目标序列,向后偏移 i+1 个时间步 true_targets = target_seq[i+1:] # [seq_length - (i+1), batch_size] pred_outputs = output[:-(i+1)] # [seq_length - (i+1), batch_size, vocab_size] # 重塑张量以适应 CrossEntropyLoss 的输入格式 pred_outputs = pred_outputs.view(-1, vocab_size) true_targets = true_targets.contiguous().view(-1) # 计算当前输出头的损失 loss = criterion(pred_outputs, true_targets) # 反向传播,累积梯度 loss.backward() # 释放与当前输出头相关的计算图,节省内存 del output, pred_outputs, true_targets, loss torch.cuda.empty_cache() # 可选,释放未使用的显存 # 更新模型参数 optimizer.step() # 打印损失 print(f“Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}”) # 推理时使用示例 # 假设我们只使用第一个输出头来进行下一词预测 def generate_text(model, input_seq, max_length): model.eval() generated = input_seq.clone() # 克隆输入序列,避免修改原始输入 with torch.no_grad(): for _ in range(max_length): # 前向传播共享主干,获取隐藏状态 memory = model.encode(generated) # [seq_length, batch_size, hidden_size] # 使用第一个输出头(next-token prediction head)获取 logits next_token_logits = model.forward_head(memory, head_index=0) # [seq_length, batch_size, vocab_size] # 取最后一个时间步的 logits next_token_logits = next_token_logits[-1, 0, :] # [vocab_size] # 获取预测的下一个 token next_token = torch.argmax(next_token_logits).unsqueeze(0).unsqueeze(1) # [1, 1] # 将预测的 token 添加到生成的序列中 generated = torch.cat(generated, next_token), dim=0) return generated # 自我推测解码的简单示例 def generate_text_with_self_speculative_decoding(model, input_seq, max_length, tokenizer, prob_threshold=0.9): “”“ 使用自我推测解码生成文本 参数: - model: 训练好的多词预测模型,具有多个输出头 - input_seq: 初始的输入序列,形状为 [seq_length, batch_size] - max_length: 生成的最大长度 - tokenizer: 分词器,用于解码生成的序列 - prob_threshold: 概率阈值,超过该阈值的 token 被接受 “”“ model.eval() generated = input_seq.clone() # 克隆输入序列,防止修改原始序列 seq_length, batch_size = generated.size() with torch.no_grad(): while generated.size(0) < max_length: # 获取模型的输出 outputs = model(generated) # 获取推测性词元 speculative_tokens = [] for i in range(model.num_future_tokens): logits = outputs[f'logits_head_{i+1}'] # 这里假设 head_0 是验证头,head_1 开始是推测头 # 取最后一个时间步的 logits last_logits = logits[-1, :, :] # [batch_size, vocab_size] probs = F.softmax(last_logits, dim=-1) # 计算概率分布 next_token = torch.argmax(probs, dim=-1, keepdim=True) # [batch_size, 1] speculative_tokens.append(next_token) # 将推测令牌拼接到当前生成的序列中 speculative_tokens_tensor = torch.cat(speculative_tokens, dim=1) # [batch_size, num_future_tokens] extended_generated = torch.cat([generated.transpose(0,1), speculative_tokens_tensor], dim=1) # [batch_size, seq_length + num_future_tokens] extended_generated = extended_generated.transpose(0,1) # 转置回 [seq_length + num_future_tokens, batch_size] # 使用验证头(head_0)验证推测令牌
原文链接:https://zhuanlan.zhihu.com/p/15037286337
标签:Multi,seq,MTP,token,Token,length,model,self,size From: https://www.cnblogs.com/sddai/p/18676243