mmdection识别环境搭建手册
1. 环境搭建
我们所选用的环境为: python3.8 + pytorch2.1.0。
环境安装中。有些库之间存在相互依赖关系,因此安装存在顺序。安装顺序大致为:
pytorch==2.1.0 -> mkl==2021.4.0和fsspec -> openmim -> mmcv==2.1.0 -> mmdetection3.2.0
注意: 上述的依赖安装的顺序必须按这个顺序来,否则会出现安装失败的情况。如: mmcv 是依赖于指定版本的pytorch的, mmdection 在内部依赖于mmcv 和 pytorch , openmim工具依赖于指定版本的mkl和fsspec。除了以上这几个依赖,其他依赖正常安装即可。以下教程就是基于这个安装顺序来进行安装
步骤 0. 从官方网站下载并安装 Miniconda。(官网地址:https://docs.anaconda.com/free/miniconda/)
安装时,全部下一步即可,默认安装完Miniconda自己会配置好conda的环境变量。安装完成后可以在 cmd 里面输入 conda 查看conda是否安装成功。如未成功可以百度 "conda环境变量配置" ,手动配置一下即可。
步骤 1. 创建并激活一个 conda 环境
# 创建一个名为openmmlab的虚拟环境
conda create --name openmmlab python=3.8 -y
# 激活虚拟环境
conda activate openmmlab
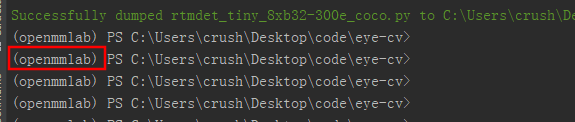
后续的操作都时基于openmmlab虚拟环境来进行操作的。激活虚拟环境后再控制台会显示如图所示的标识,可以区别你在那个环境。如果没有这个标识。请执行conda activate openmmlab 来切换到指定的虚拟环境。
步骤 2. 基于 PyTorch 官方说明安装 PyTorch。
以下关于PyTorch 的安装CPU版本和GPU版本的任选其一即可。切勿重复安装。
注意: 首先,PyTorch的安装建议不要选择最新版,因为最新版要求的mmcv版本为2.2.0及其以上,但是mmdection环境依赖的mmcv最高仅支持到2.1.0。目前最新版的PyTorch是无法支持运行mmdection。经过测试,目前最稳定版本对应关系如下,后续操作也都是基于这个版本来进行安装的。
pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0
mmcv==2.1.0
mmdection==3.2.0
2.1 CPU版本的PyTorch安装
安装 PyTorch 时可以参照官网的版本说明,选择合适的版本。这里我建议不要选最新版,最新版会和后续安装的框架冲突。我在这里选用了pytorch2.1.0版本。
注: 下载可能有点慢,耐心等待即可。
# 安装pytorch及其相关依赖库(CPU用户安装)
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 cpuonly -c pytorch
这里我选用的是基于CPU的相关配置。
2.2 CPU版本的PyTorch安装
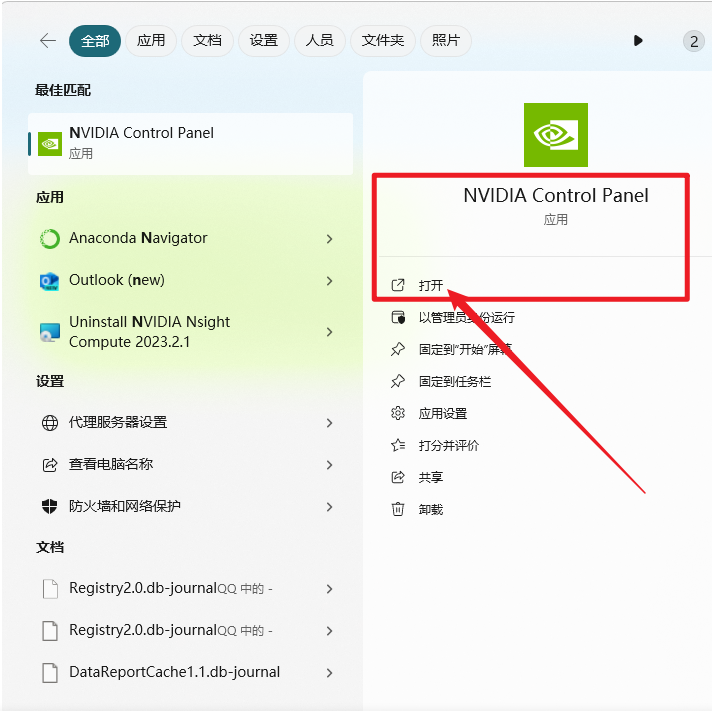
安装CUDA,目前仅支持NVDIA版本的显卡。(这里建议搜索CUDA安装来按照教程安装)
进入NVDIA官网下载显卡驱动,并更新到最新版。
根据自己的显卡版本,下载CUDA软件。
 |
 |
|---|---|
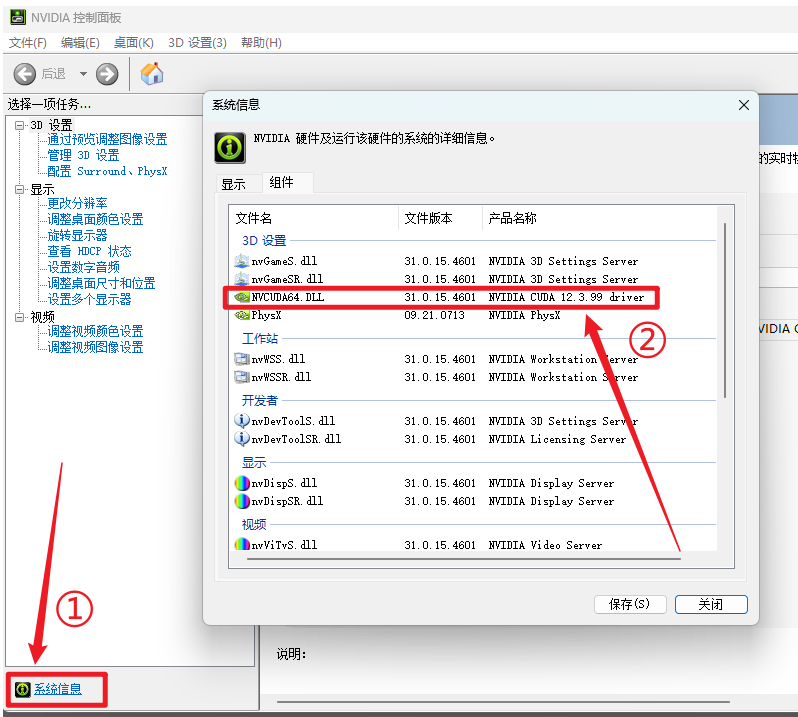
| 打开NVDIA控制面板 | 查看显卡对应的CUDA版本号 |
根据版本号在官网下载所需CUDA-toolkit
官网下载地址: https://developer.nvidia.com/cuda-toolkit-archive
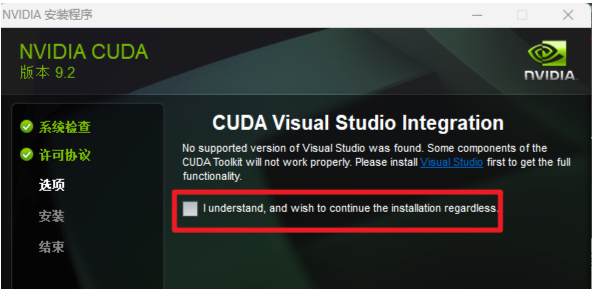
下载完正常安装即可。如果安装完提示如下。则需要下载进行安装Visual Studio 然后进入后安装C++桌面开发相关依赖。Visual Studio版本没有要求。
安装完成后,打开CMD 输入 nvcc --version 可查看版本号。执行set cuda,可以查看 CUDA 设置的环境变量。
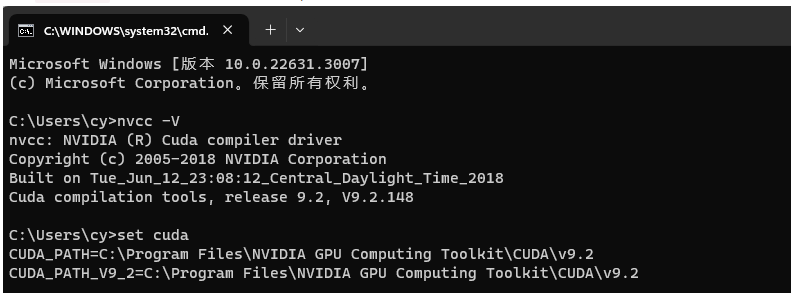
安装完成后,安装pytorch。
通过以下网站来查看适合自己电脑CUDA版本的安装命令。
查看地址: https://pytorch.org/get-started/previous-versions/
如果未找到,选择与自己版本最接近的即可。我这里选用的是 CUDA 12.1 版本的 pytorch 2.1.0。你也可以选择pytorch2.1.0 对应的其他CUDA版本,以自己的CUDA版本为准。
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia
步骤 3. 使用 MIM 安装 MMEngine 和 MMCV。
其中fsspec和mkl 是 openmim 的必要依赖,需要提前安装。这里容易踩坑,官方文档中未提及。社区论坛中里面提及这两个库。
# 这个库必须先安装,否则后续库安装会失败
pip install mkl==2021.4.0
pip install fsspec
# 安装openmim包管理工具
pip install -U openmim
mim install mmengine
mim install "mmcv==2.1.0"
步骤 4. 安装 MMDetection
关于mmdetection的安装,这里选用发布版本 3.2.0,
方法一: 你可以直接下载 3.2.0 的发布版,下载下来进行安装。(推荐)
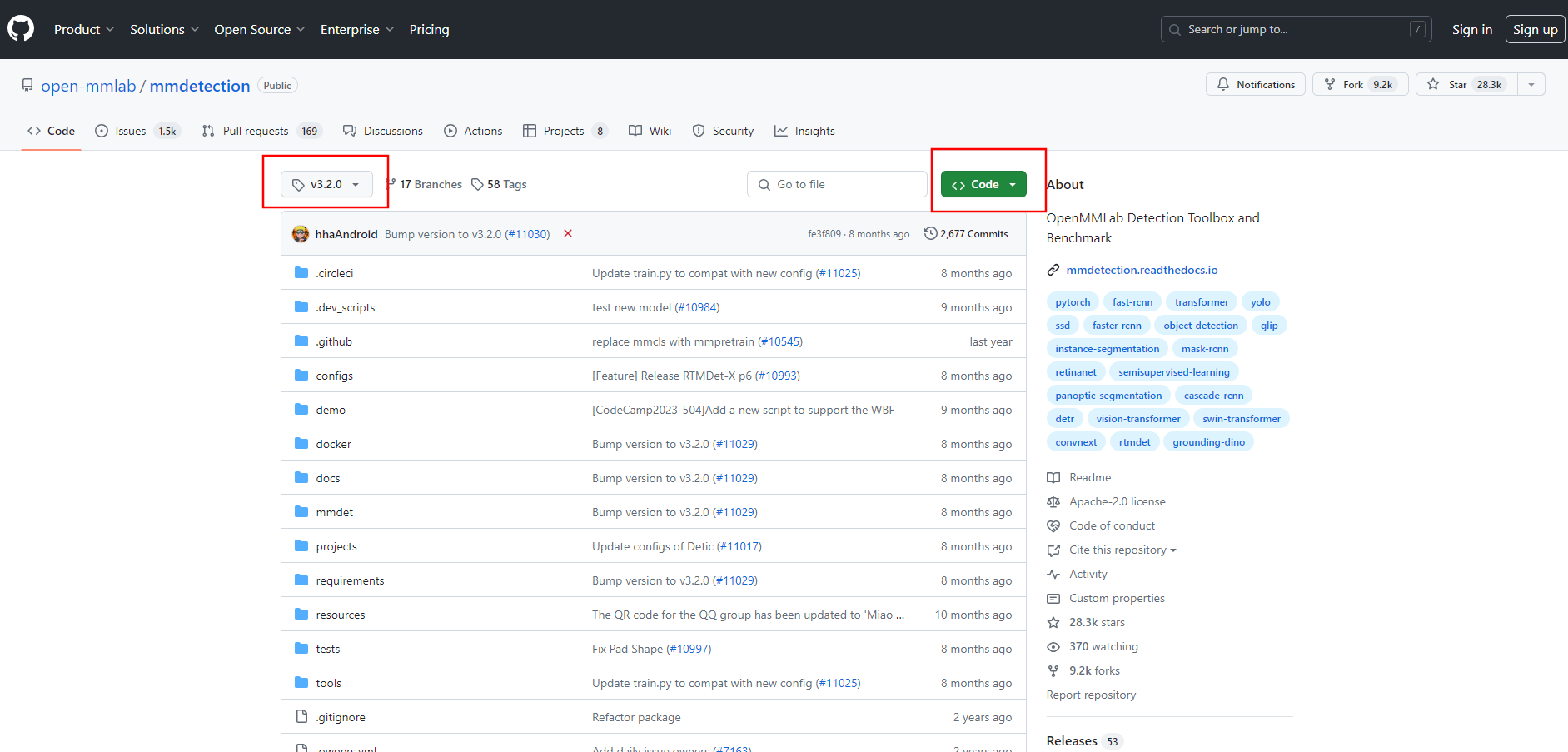
下载下来后,进行编译安装。
cd mmdetection-3.2.0
pip install -v -e .
# "-v" 指详细说明,或更多的输出
# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。
方法二: git clone 安装 (clone下来代码后须有切换到分支/tag 3.2.0)进行安装
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -v -e .
# "-v" 指详细说明,或更多的输出
# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。
环境安装完成!!!
2. 测试安装
为了验证 MMDetection 是否安装正确,我们提供了一些示例代码来执行模型推理。
步骤 1. 我们需要下载配置文件和模型权重文件。
mim download mmdet --config rtmdet_tiny_8xb32-300e_coco --dest .
下载完成后,我们会在当前目录下生成两个文件。其中rtmdet_tiny_8xb32-300e_coco.py 为模型的配置文件,另一个pth 结尾的文件为模型权重文件。也就是模型。在这个框架中,所有的模型识别都依赖于这两个配置。
执行以下命令进行测试
# demo/demo.jpg 为待测试的图片
python demo/image_demo.py demo/demo.jpg rtmdet_tiny_8xb32-300e_coco.py --weights rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --device cpu
执行完成后。会在outputs生成识别后的图片。效果如下。
 |
 |
|---|---|
| 测试图(demo/demo.jpg) | 结果图(outputs/vis/demo.jpg) |
如果出结果图则表示环境搭建成功!!!
3. 模型训练
1. 数据集准备
首先,需要提前准备好待训练的图片。我这里采集了大概5000张安全帽相关的照片。用于进行模型训练和模型修正。
2. 数据集标注
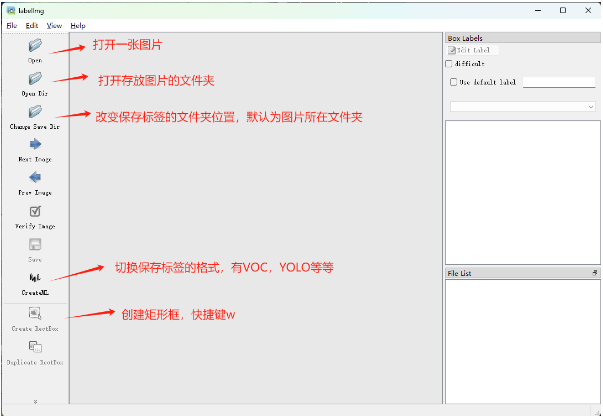
对于采集好的图片,需要转化为能被及其识别的文件。这个过程就需要进行数据标注。进行图像标注,通过标注将其转化为xml文件。关于标注我选用了python提供的 labelImg 库,也可以选择现有的标注平台进行标注(如:Basicfinder,LABEL STUDIO,CVAT)。根据自己的实际需要来选择。这里我选择python提供的labelImg这个主要就是使用简单、开箱即用、无需多余的配置、对开发者友好的特点。
可以通过pip命令进行安装。
pip install labelimg
然后在控制台输入 labelimg 即可启动成功。
启动之后界面如图所示
 |
 |
|---|---|
 |
 |
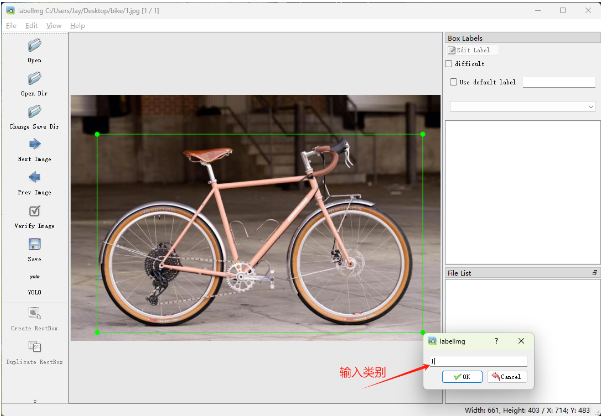
在标注时格式选择VOC来进行标注。标注完后后,会在相应的文件夹下生成xml文件。
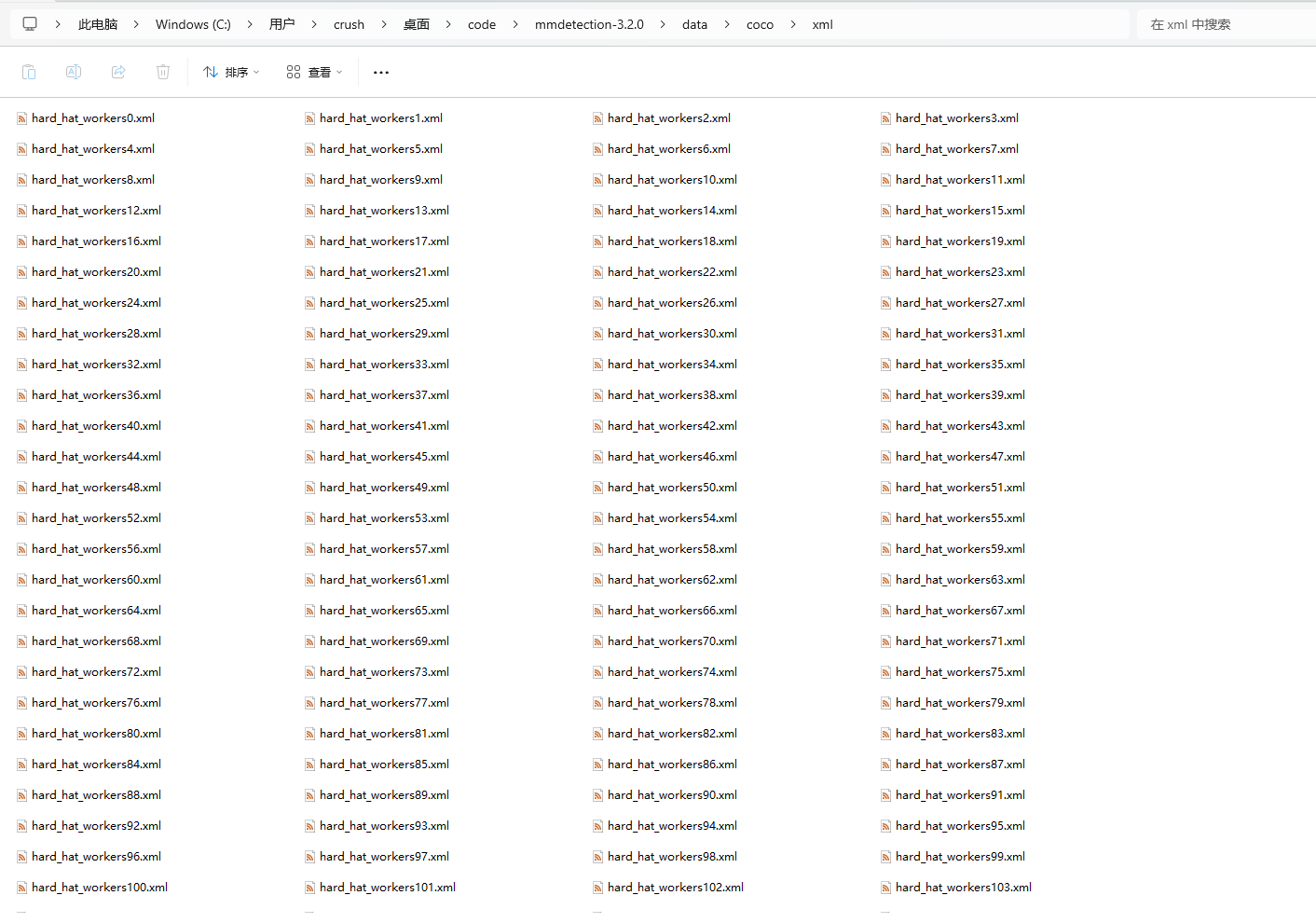
数据标注完成。标注过程中要仔细,标错太多可能会造成模型识别的准确度下降。
3. 模型训练准备
标注完成后,我们开始进行训练模型的准备工作。这里我们就需要上面的两个东西。1. 原始图片(进行标注的原始图片)。2.标注产生的xml文件。对于标注中产生的其他东西舍弃即可。
回到mmdection目录中,在根目录建立一个data目录。用来存放标注好的图片和XML文件。这里说的图片指的是原始图片。标注后,我们只需要xml文件。不需要处理后的图片。data目录结构如图所示。
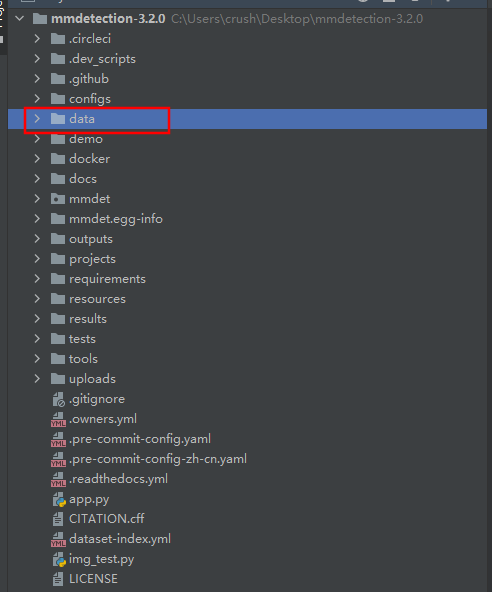 |
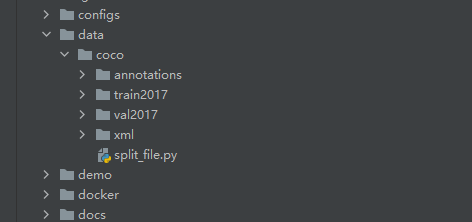 |
|---|---|
| data目录位置 | data下目录结构 |
data下目录结构 (目录结构严格要求。不允许修改文件夹名称及其层级)
.
├── data
│ ├── coco
│ ├── annotations - 存放训练读取的JSON数据,这里建立空目录即可。后面会生成json文件到里面。
│ ├── train2017 - 存放训练所需的图片(原始图片)
| ├── val2017 - 存放模型测试的图片,可以将训练的图片复制一份放进去。这里的图片是框架去做模型矫正用,建议与训练图片一一致
| ├── xml - 存放标注后的XML文件。数量、名称需要与训练所需图片一致。
│ └── split_file.py - 这个文件是将xml转化为框架所需的coco数据集的json文件。下面我会提供相关代码。
└── ...
先建立如图所示的文件夹,文件名严格按照这样命名,不允许其他命名(重要),然后将原始图片放入到 train2017 和 val2017 文件夹中。内容完全一致即可。然后将标注产生的xml文件复制到xml文件夹下。
然后进行xml转换,将其转换为 mmdection 框架所需的 json 数据文件。运行以下脚本(split_file.py)进行转化即可。如果split_file.py放在data/coco 文件夹下,无需任何修改,直接运行即可。如果存放在其他位置,需要手动调整json文件生成的位置。
split_file.py
import os
import json
import xml.etree.ElementTree as ET
from collections import defaultdict
def parse_xml(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
data = {
"filename": root.find('filename').text,
"size": {
"width": int(root.find('size/width').text),
"height": int(root.find('size/height').text),
"depth": int(root.find('size/depth').text)
},
"objects": []
}
for obj in root.findall('object'):
obj_data = {
"name": obj.find('name').text,
"bndbox": {
"xmin": int(obj.find('bndbox/xmin').text),
"ymin": int(obj.find('bndbox/ymin').text),
"xmax": int(obj.find('bndbox/xmax').text),
"ymax": int(obj.find('bndbox/ymax').text)
}
}
data["objects"].append(obj_data)
return data
def convert_to_coco_format(xml_files, output_json):
images = []
annotations = []
categories = defaultdict(lambda: len(categories))
ann_id = 1
for img_id, xml_file in enumerate(xml_files):
data = parse_xml(xml_file)
images.append({
"id": img_id,
"file_name": data["filename"],
"width": data["size"]["width"],
"height": data["size"]["height"]
})
for obj in data["objects"]:
category_id = categories[obj["name"]]
bndbox = obj["bndbox"]
annotations.append({
"id": ann_id,
"image_id": img_id,
"category_id": category_id,
"bbox": [
bndbox["xmin"],
bndbox["ymin"],
bndbox["xmax"] - bndbox["xmin"],
bndbox["ymax"] - bndbox["ymin"]
],
"area": (bndbox["xmax"] - bndbox["xmin"]) * (bndbox["ymax"] - bndbox["ymin"]),
"iscrowd": 0
})
ann_id += 1
coco_format = {
"images": images,
"annotations": annotations,
"categories": [{"id": cid, "name": name} for name, cid in categories.items()]
}
os.makedirs(os.path.dirname(output_json), exist_ok=True)
with open(output_json, 'w') as f:
json.dump(coco_format, f, indent=4)
if __name__ == "__main__":
xml_dir_train = "xml" # 修改为你的训练集 XML 文件路径
xml_dir_val = "xml" # 修改为你的验证集 XML 文件路径
output_json_train = "annotations/instances_train2017.json" # 修改为输出训练集 JSON 文件路径
output_json_val = "annotations/instances_val2017.json" # 修改为输出验证集 JSON 文件路径
# 创建输出目录(如果不存在)
os.makedirs(os.path.dirname(output_json_train), exist_ok=True)
os.makedirs(os.path.dirname(output_json_val), exist_ok=True)
xml_files_train = [os.path.join(xml_dir_train, f) for f in os.listdir(xml_dir_train) if f.endswith('.xml')]
xml_files_val = [os.path.join(xml_dir_val, f) for f in os.listdir(xml_dir_val) if f.endswith('.xml')]
convert_to_coco_format(xml_files_train, output_json_train)
convert_to_coco_format(xml_files_val, output_json_val)
执行split_file.py 文件。执行后。会在annotations目录下生成对应的json文件。
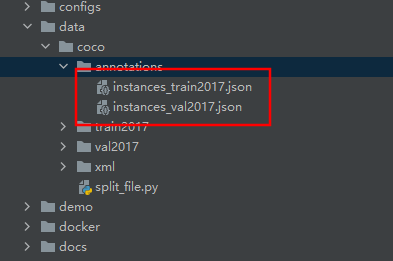
接下来进行修改配置文件。将配置文件的训练集修改为我们的数据集。然后就可以开始训练了。(下面内容很重要)
在 configs/faster_rcnn 目录下找到 faster-rcnn_r50_fpn_1x_coco.py 文件,复制一份,重新命名为 my-data.py 位置与 faster-rcnn_r50_fpn_1x_coco.py 同一文件夹下。
修改my-data.py配置文件。添加配置如下。
_base_ = [
'../_base_/models/faster-rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
classes = ('helmet', 'head', 'person') # 修改为你的类别
data = dict(
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
classes=classes),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
classes=classes),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
classes=classes)
)
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=3)) # 【修改类别数为你的类别数量】
)
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
修改my-data.py 的继承文件。在这里,他的继承关系有如下四个,我们修改的只有fast-rcnn_r50_fpn.py
_base_ = [
'../_base_/models/faster-rcnn_r50_fpn.py', #【修改】
'../_base_/datasets/coco_detection.py', #【无需修改】
'../_base_/schedules/schedule_1x.py', #【无需修改】
'../_base_/default_runtime.py' #【无需修改】
]
配置文件 configs/_base_/models/fast-rcnn_r50_fpn.py 需要修改的位置我已经标注出来,修改值即可。
代码中最低阈值指的是训练模型中的最低匹配度,设置0.3就是指在训练过程中作模型修正的时候,与模型匹配度小于30%的会直接舍弃。
关于模型修正,指的是通过train2017 的图片进行模型训练,每训练完一轮,会使用val2017文件夹下的图片与其进行匹配,根据匹配度,对模型进行修正。一般默认是进行训练和修正12次。这个参数也可以进行调整。
# model settings
model = dict(
type='FasterRCNN',
data_preprocessor=dict(
type='DetDataPreprocessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True,
pad_size_divisor=32),
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=3, # 【修改类别数为你的类别数量】
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
# model training and testing settings
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
# score_thr=0.05,
score_thr=0.3, # 【修改为最低阈值,范围:0-1】
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)
# soft-nms is also supported for rcnn testing
# e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
))
修改配置文件coco.py 文件位置 mmdet/datasets/coco.py 将原有数据标签注释,改为你标注的ID,也就是你在标注软件中为每个框设置的label。
注意: 对于文件中classes的设置,如果一个标签,请写为 'classes': ('helmet', ) 不要写为 'classes': ('helmet') 否则会出现不报错。但训练处的模型识别度为0的情况, 已踩坑。
# Copyright (c) OpenMMLab. All rights reserved.
import copy
import os.path as osp
from typing import List, Union
from mmengine.fileio import get_local_path
from mmdet.registry import DATASETS
from .api_wrappers import COCO
from .base_det_dataset import BaseDetDataset
@DATASETS.register_module()
class CocoDataset(BaseDetDataset):
"""Dataset for COCO."""
METAINFO = {
'classes': ('helmet', 'head', 'person') , # 【修改为你的标签】
'palette':
[(220, 20, 60) # 【标签颜色,可以多个,但不能对多于定义的标签数量】
]
}
COCOAPI = COCO
# ann_id is unique in coco dataset.
ANN_ID_UNIQUE = True
def load_data_list(self) -> List[dict]:
"""Load annotations from an annotation file named as ``self.ann_file``
Returns:
List[dict]: A list of annotation.
""" # noqa: E501
with get_local_path(
self.ann_file, backend_args=self.backend_args) as local_path:
self.coco = self.COCOAPI(local_path)
# The order of returned `cat_ids` will not
# change with the order of the `classes`
self.cat_ids = self.coco.get_cat_ids(
cat_names=self.metainfo['classes'])
self.cat2label = {cat_id: i for i, cat_id in enumerate(self.cat_ids)}
self.cat_img_map = copy.deepcopy(self.coco.cat_img_map)
img_ids = self.coco.get_img_ids()
data_list = []
total_ann_ids = []
for img_id in img_ids:
raw_img_info = self.coco.load_imgs([img_id])[0]
raw_img_info['img_id'] = img_id
ann_ids = self.coco.get_ann_ids(img_ids=[img_id])
raw_ann_info = self.coco.load_anns(ann_ids)
total_ann_ids.extend(ann_ids)
parsed_data_info = self.parse_data_info({
'raw_ann_info':
raw_ann_info,
'raw_img_info':
raw_img_info
})
data_list.append(parsed_data_info)
if self.ANN_ID_UNIQUE:
assert len(set(total_ann_ids)) == len(
total_ann_ids
), f"Annotation ids in '{self.ann_file}' are not unique!"
del self.coco
return data_list
def parse_data_info(self, raw_data_info: dict) -> Union[dict, List[dict]]:
"""Parse raw annotation to target format.
Args:
raw_data_info (dict): Raw data information load from ``ann_file``
Returns:
Union[dict, List[dict]]: Parsed annotation.
"""
img_info = raw_data_info['raw_img_info']
ann_info = raw_data_info['raw_ann_info']
data_info = {}
# TODO: need to change data_prefix['img'] to data_prefix['img_path']
img_path = osp.join(self.data_prefix['img'], img_info['file_name'])
if self.data_prefix.get('seg', None):
seg_map_path = osp.join(
self.data_prefix['seg'],
img_info['file_name'].rsplit('.', 1)[0] + self.seg_map_suffix)
else:
seg_map_path = None
data_info['img_path'] = img_path
data_info['img_id'] = img_info['img_id']
data_info['seg_map_path'] = seg_map_path
data_info['height'] = img_info['height']
data_info['width'] = img_info['width']
if self.return_classes:
data_info['text'] = self.metainfo['classes']
data_info['custom_entities'] = True
instances = []
for i, ann in enumerate(ann_info):
instance = {}
if ann.get('ignore', False):
continue
x1, y1, w, h = ann['bbox']
inter_w = max(0, min(x1 + w, img_info['width']) - max(x1, 0))
inter_h = max(0, min(y1 + h, img_info['height']) - max(y1, 0))
if inter_w * inter_h == 0:
continue
if ann['area'] <= 0 or w < 1 or h < 1:
continue
if ann['category_id'] not in self.cat_ids:
continue
bbox = [x1, y1, x1 + w, y1 + h]
if ann.get('iscrowd', False):
instance['ignore_flag'] = 1
else:
instance['ignore_flag'] = 0
instance['bbox'] = bbox
instance['bbox_label'] = self.cat2label[ann['category_id']]
if ann.get('segmentation', None):
instance['mask'] = ann['segmentation']
instances.append(instance)
data_info['instances'] = instances
return data_info
def filter_data(self) -> List[dict]:
"""Filter annotations according to filter_cfg.
Returns:
List[dict]: Filtered results.
"""
if self.test_mode:
return self.data_list
if self.filter_cfg is None:
return self.data_list
filter_empty_gt = self.filter_cfg.get('filter_empty_gt', False)
min_size = self.filter_cfg.get('min_size', 0)
# obtain images that contain annotation
ids_with_ann = set(data_info['img_id'] for data_info in self.data_list)
# obtain images that contain annotations of the required categories
ids_in_cat = set()
for i, class_id in enumerate(self.cat_ids):
ids_in_cat |= set(self.cat_img_map[class_id])
# merge the image id sets of the two conditions and use the merged set
# to filter out images if self.filter_empty_gt=True
ids_in_cat &= ids_with_ann
valid_data_infos = []
for i, data_info in enumerate(self.data_list):
img_id = data_info['img_id']
width = data_info['width']
height = data_info['height']
if filter_empty_gt and img_id not in ids_in_cat:
continue
if min(width, height) >= min_size:
valid_data_infos.append(data_info)
return valid_data_infos
4. 模型训练
开始进行模型训练,在控制台输入以下命令进行训练
python tools/train.py configs/faster_rcnn/my-data.py
这将是一个漫长的等待过程。一般情况下,如果电脑性能有关,一般可能需要至少半天。等待训练完成后后,我们会在work_dirs/my-data文件夹下看到pth格式的模型文件。与配置文件 work_dirs/my-data/my-data.py。训练过程中会出现多个epoch_XXX.pth模型文件。对于多个,测试识别度最高的作为你的最终模型即可。
在模型训练完成后,我们会得到两个东西。一个是pth格式的模型权重文件,一个是最终的配置文件my-data.py
4. 模型测试
调用测试命令进行测试
python demo/image_demo.py demo/demo002.jpeg work_dirs/my-data/my-data.py --weights work_dirs/my-data/epoch_12.pth --device cpu
会在 outputs/vis/ 下生成测试图片的结果
 |
 |
|---|---|
| 测试图(demo/demo002.jpeg) | 结果图(outputs/vis/demo002.jpeg) |
5. 推流与接口实现
关于推流接口,选用轻量级的Flask来实现。首先安装Flask相关依赖。
pip install flask
安装完成后,通过新建app.py 启动文件,来做接口推流。具体实现逻辑如下
import gc
import os
import io
import mmcv
import numpy as np
from flask import Flask, request, jsonify, send_file
from mmdet.apis import init_detector, inference_detector
from mmdet.registry import VISUALIZERS
from PIL import Image
app = Flask(__name__)
# 配置文件和权重文件路径
config_file = "model/my-data.py"
checkpoint_file = "model/epoch_12.pth"
# 初始化检测模型
model = init_detector(config_file, checkpoint_file, device="cpu")
# 初始化 visualizer(仅需执行一次)
visualizer = VISUALIZERS.build(model.cfg.visualizer)
visualizer.dataset_meta = model.dataset_meta
def parse_result(result):
parsed_results = []
bboxes = result.pred_instances.bboxes.cpu().numpy()
labels = result.pred_instances.labels.cpu().numpy()
scores = result.pred_instances.scores.cpu().numpy()
for bbox, label, score in zip(bboxes, labels, scores):
parsed_results.append({
'bbox': bbox.tolist(),
'label': int(label),
'score': float(score)
})
return parsed_results
@app.route('/detect', methods=['POST'])
def detect():
if 'file' not in request.files:
return jsonify({'error': '未找到参数[file]'})
file = request.files['file']
if file.filename == '':
return jsonify({'error': '未检测到文件'})
if file:
file_bytes = file.read()
np_img = np.frombuffer(file_bytes, np.uint8)
image = mmcv.imfrombytes(np_img)
# 推理检测
result = inference_detector(model, image)
# 解析结果为 JSON 可序列化的格式
parsed_result = parse_result(result)
# 手动释放内存
del file_bytes, np_img, image, result
gc.collect()
# 返回检测结果
return jsonify(parsed_result)
@app.route('/detect_image', methods=['POST'])
def detect_and_save():
if 'file' not in request.files:
return jsonify({'error': '未找到参数[file]'})
file = request.files['file']
if file.filename == '':
return jsonify({'error': '未检测到文件'})
if file:
file_bytes = file.read()
np_img = np.frombuffer(file_bytes, np.uint8)
image = mmcv.imfrombytes(np_img)
# 推理检测
result = inference_detector(model, image)
# 使用 visualizer 绘制检测结果
visualizer.add_datasample(
'result',
image,
data_sample=result,
draw_gt=False,
wait_time=0
)
# 绘制检测结果并转换为字节流
image_with_result = visualizer.get_image()
image_pil = Image.fromarray(mmcv.bgr2rgb(image_with_result))
img_io = io.BytesIO()
image_pil.save(img_io, 'PNG')
img_io.seek(0)
# 手动释放内存
del file_bytes, np_img, image, result, image_with_result, image_pil
gc.collect()
return send_file(img_io, mimetype='image/png')
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True)
6. 遇到的问题及其方案
问题一
ImportError: DLL load failed while importing _imaging: 找不到指定的模块。
Pillow依赖冲突,重新安装Pillow依赖即可。
pip uninstall pillow
pip install pillow
问题二
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. torch 2.1.0 requires fsspec, which is not installed.
错误是由于缺少 fsspec 包,这是 PyTorch 2.1.0 需要的依赖。安装fsspec即可。
pip install fsspec