过去几年,大语言模型 (LLM) 的进程主要由训练时计算缩放主导。尽管这种范式已被证明非常有效,但预训练更大模型所需的资源变得异常昂贵,数十亿美元的集群已经出现。这一趋势引发了人们对其互补方法的浓厚兴趣, 即推理时计算缩放。推理时计算缩放无需日趋庞大的预训练预算,而是采用动态推理策略,让模型能够对难题进行“更长时间的思考”。最著名的案例是 OpenAI 的 o1 模型,随着推理时计算量的增加,该模型在数学难题上获得了持续的改进:
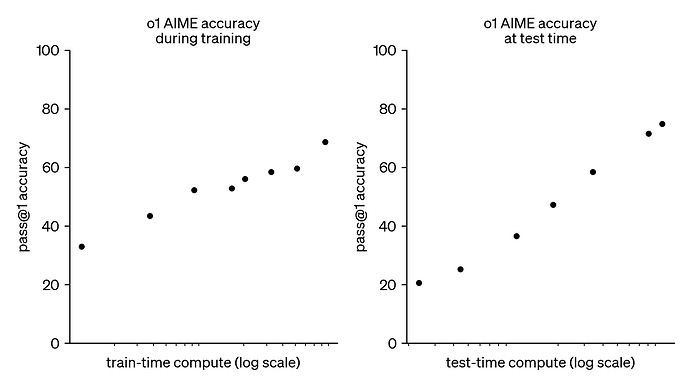
尽管我们无从得知 o1 是如何训练的,但 DeepMind 最新的研究表明,使用迭代式自完善或让奖励模型在解空间上搜索等策略,可以较好地实现优化推理时计算缩放。通过根据提示自适应地分配推理时计算,较小的模型可以与更大、更耗资源的模型相媲美,有时甚至优于它们。当内存受限或可用硬件不足以运行更大的模型时,缩放推理时计算尤其有利。然而,目前所有对于该方法的效果报告都是基于闭源模型的,并且没有公开任何实现细节或代码
标签:缩放,PRM,模型,搜索,波束,推理 From: https://www.cnblogs.com/huggingface/p/18648349