前言
书接上文
本项目代码已开源 放在 Github上,欢迎参考使用,Star
主要功能说明:对手动拍照的问卷图片进行统计分数(对应分数打对号),单张问卷各项得分写入excel文件,并汇总所有图片得分到 excel
模型
基于前面的模型知识,完成了这一需求
首先涉及到的模型(在技术测试过程中,也发现了一些效果更好的模型,放在后续迭代过程中加入)
表格定位模型,使用ppstructure
表格特征编码模型和表格结构识别模型 分别是 Detr,和 微软的table-transformer-structure-recognition
字符识别模型,使用 PaddleOCR
对号处理模型,使用 微调的Yolov8n-cls(Yolov8n-det 也可以)
模型的加载统一放在 ModelManager.py 中实现
UI
UI,是用pyqt5简单实现的界面,主要包括
简单的进度展示
简单的图像状态展示
处理图像展示
打开单张图片、打开文件夹、以及 开始处理的三个按钮
其中模型加载,以及表格图像处理都是耗时操作,为了避免主进程阻塞,导致界面卡住,使用了 Worker 封装然后用线程执行,多提升点用户体验,在Workers.py 中定义
UI层逻辑
如有问题,欢迎留言、私信或加群交流【群号:392784757】
模型加载
self.model: TableProcessModel = None
self.thread = None
self.worker = None
# load model by thread
self.load_model()
load_model函数
def load_model(self):
self.thread = QThread()
self.worker = ModelLoadWorker()
self.worker.moveToThread(self.thread)
# connect
self.worker.model_loaded.connect(self.on_model_loaded)
self.thread.started.connect(self.worker.run)
self.thread.finished.connect(self.thread.deleteLater)
#
self.thread.start()
表格处理
def process_images_v2(self):
if self.model is None:
QMessageBox.information(
self, 'info', "Model has not been loaded successfully! Please wait")
return
if len(self.images_need_process) == 0:
QMessageBox.information(
self, 'info', "No Image loaded! Please load images")
return
self.process_button.setEnabled(False)
self.thread = QThread()
self.worker = ImageProcessWorker(
self.images_need_process, self.model, log=True)
self.worker.moveToThread(self.thread)
self.worker.image_processed.connect(self.update_ui)
self.worker.finished.connect(self.on_processing_finished)
self.worker.show_signal.connect(self.load_image_on_screen)
self.thread.started.connect(self.worker.run)
self.thread.start()
模型加载Worker
class ModelLoadWorker(QObject):
model_loaded = pyqtSignal(object)
def __init__(self):
super().__init__()
self.model = None
def run(self):
try:
self.model = TableProcessModel()
except Exception as e:
print('error loading model', e)
else:
self.model_loaded.emit(self.model)
Workers
如有问题,欢迎留言、私信或加群交流【群号:392784757】
图像(表格)处理 Worker
class ImageProcessWorker(QObject):
image_processed = pyqtSignal(str)
finished = pyqtSignal()
show_signal = pyqtSignal(int)
def __init__(self, images, model:TableProcessModel,log=False):
super().__init__()
self.images = images
self.processor = model
self.log = log
@pyqtSlot()
def run(self):
for i, image_path in enumerate(self.images):
try:
self.show_signal.emit(i)
# 处理图片
if self.log:
print('processing ', image_path, '--->', end='')
self.processor.run(image_path)
if self.log:
print('done')
time.sleep(0.5)
self.image_processed.emit(f"Processed: {image_path}")
except Exception as e:
self.image_processed.emit(
f"Error processing {image_path}: {str(e)}")
self.finished.emit() # 处理完成
在具体执行时,交由线程处理,避免了主线程的阻塞
表格处理模块 TableProcess.py
涉及到的模型,表格定位模型、表格特征编码和表格结构识别模型
其中表格处理模块 在完成结构识别后,会调用统计分数模块,二者存在一定的低耦合性,但主要逻辑还是互相分离,比较清晰,也方便适配其他业务逻辑,只需要修改或添加 后面的业务模块,如统计分数
统一调用接口
def run(self, next_image_path):
try:
self.reset_results()
self.image_path = next_image_path
self.load_image()
self.initialize_cache_dir()
self.run_parse_table()
self.score_eval.eval_score()
self.score_eval.to_xlsx()
except Exception as e:
print('run error ', e)
核心函数 run_parse_table()
def run_parse_table(self):
table_image = self.infer_locate_table() # bgr
if len(self.locate_table_bbox) == 0:
raise Exception("定位表格失败")
table_image = Image.fromarray(cv2.cvtColor(table_image,cv2.COLOR_BGR2RGB))
target_sizes = [table_image.size[::-1]]
self.encoding_for_table_split(table_image)
if self.table_split_result['encoding'] is None:
raise Exception("表格特征编码失败")
self.infer_split(self.table_split_result['encoding'], target_sizes)
if len(self.table_split_result.keys()) <= 1:
raise Exception("表格切分失败")
self.parse_table_split_result()
# visualize first for debug
if CACHE:
self.draw_boxs(table_image.copy(), cut_cell=False)
self.setup_score_eval(table_image)
整体流程:表格定位 -> 表格图像编码 -> 表格结构识别 -> 表格分数评估
中间图,settings.py 中提供了 CACHE = True 开启,默认False 关闭
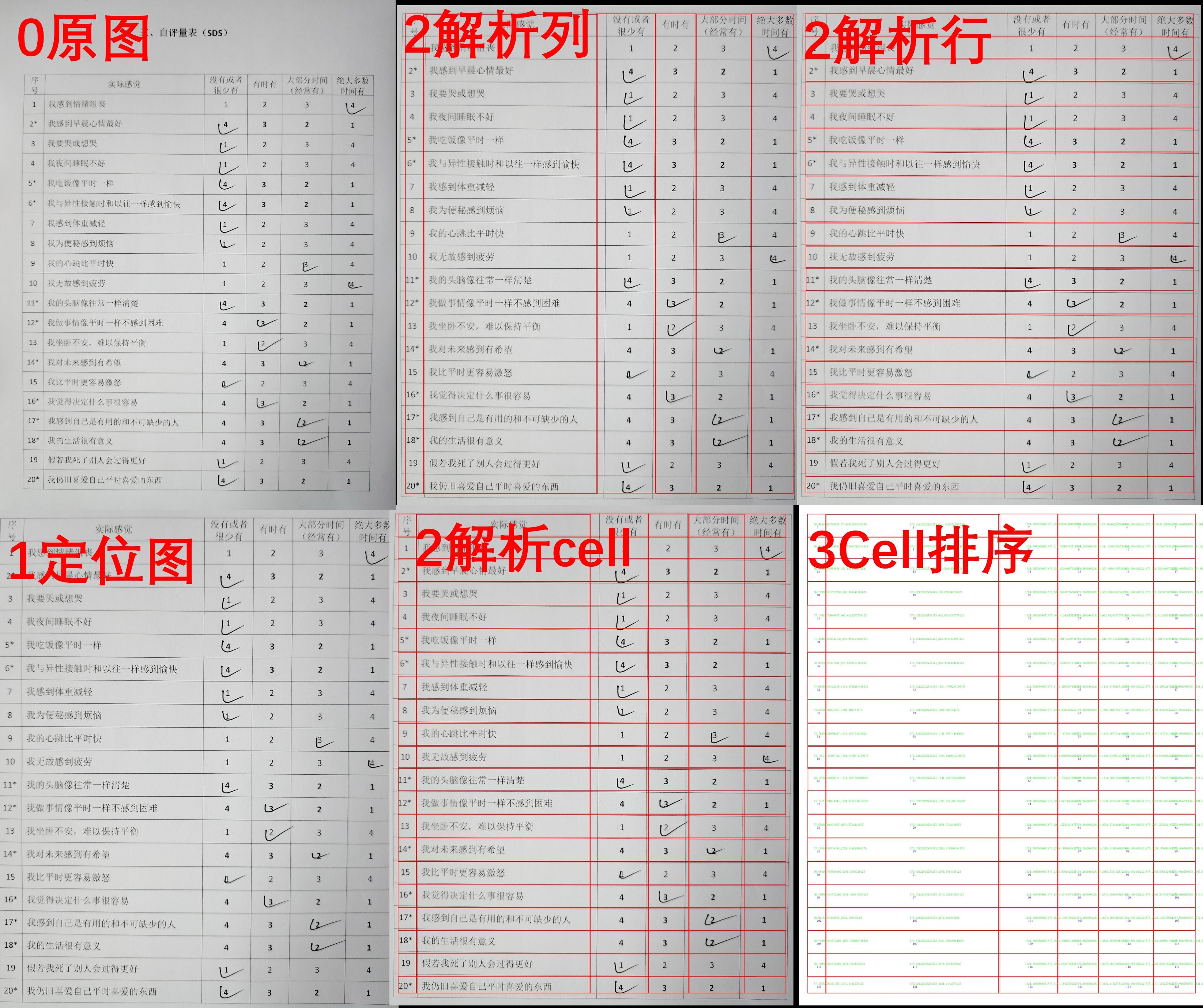
其中
self.infer_locate_table()
self.encoding_for_table_split(table_image)
self.infer_split(self.table_split_result['encoding'], target_sizes)
分别涉及了模型的推理
完整代码,请前往 Github 下载查看
如有问题,欢迎留言、私信或加群交流【群号:392784757】
统计分数模块 ScoreEvaluation.py
涉及到的模块,字符识别模型、对号处理模型
主要函数 eval_score()
def eval_score(self):
for row_i in range(self.n_row):
if row_i == 0:
continue
score_boxs = self.cells[row_i*self.n_col +
self.score_col_start_idx:row_i*self.n_col+self.score_col_end_idx+1]
line_score = self.eval_line_score(score_boxs)
self.row_scores.append(line_score)
self.score_history.append(
(f'{self.cur_image_name}_score.xlsx', sum(self.row_scores)))
eval_line_score() 评估每一行得分,涉及到模型推理,以及顺序的判断
完整代码,请前往 Github 下载查看
性能测试
4060 8G 16G内存 i9-13900HX
100张图片 GPU 3.5s/张,CPU4.6s/张
注意事项
编程过程注意
-
使用一定的方法,防止模型重复加载(一次加载,多次推理)
-
paddle的模型 GPU的使用应该是自动管理的,use_gpu = True;其他模型的GPU推理,需要自行管理,同时需要设置 输入 和 模型 所在设备位置一致 CPU/GPU
-
模型的推理与解析,需要先了解模型输入输出,根据官方demo/sample学习;然后结合自己的需求修改;多Debug;
-
不同模型默认使用的图像读取,有的是 PIL.Image,或者是 cv2.imread() ,读取后送入模型处理,发现模型结果有一定区别,甚至完全不对,当发现你的模型结果很奇怪,不妨查看一下 输入
-
耗时操作不要在主线程做【我的模型加载在ui初始化里完成,虽然使用了额外线程去做,但还是会影响到主线程,主界面,有大佬知道怎么处理,还请指点!!!】
-
对于某些操作,如处理单张图片和文件夹多张图片 应该要统一;加载图片接口统一 不要分别实现
-
注意资源的清理,临时变量的清理