目录
一、概述
Hudi(Hadoop Upserts Deletes and Incrementals),简称Hudi,是一个流式数据湖平台,关于Hudi的更多介绍可以参考我以下几篇文章:
这里主要讲解Hive、Trino、Starrocks与Hudi的整合操作,其实主要分为四大块:
- 数据处理:计算引擎,例如:flink、spark等。
- 数据存储:HDFS、云存储、AWS S3、对象存储等。
- 数据管理:Apache Hudi。
- 数据查询:查询引擎,例如:Spark、Trino(Presto)、Hive、Starrocks(Doris)等。
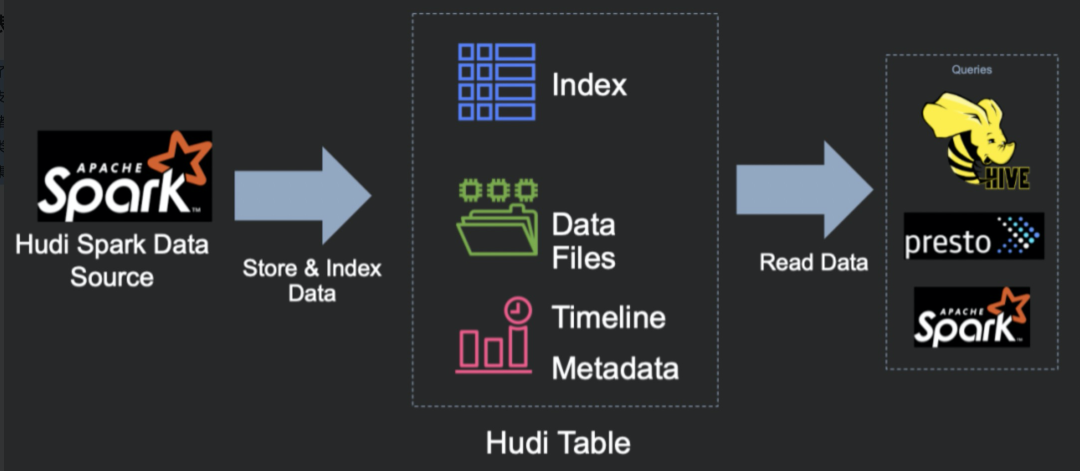
二、Hudi 数据管理
Hudi表的数据文件,可以使用操作系统的文件系统存储,也可以使用HDFS这种分布式的文件系统存储。为了后续分析性能和数据的可靠性,一般使用HDFS进行存储。以HDFS存储来看,一个Hudi表的存储文件分为两类。

.hoodie文件: 由于CRUD的零散性, 每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响HDFS的性能,Hudi设计了一套文件合并机制。.hoodie文件夹中存放了对应的文件合并操作相关的日志文件。americas和asia相关的路径是实际的数据文件,按分区存储,分区的路径key是可以指定的。
1).hoodie文件
Hudi把随着时间流逝,对表的一系列CRUD操作叫做Timeline, Timeline中某一次的操作,叫做Instant。

Instant Action,记录本次操作是一次数据提交(COMMITS),还是文件合并(COMPACTION),或者是文件清理(CLEANS);Instant Time,本次操作发生的时间;State,操作的状态,发起(REQUESTED),进行中(INFLIGHT),还是已完成(COMPLETED);
2)数据文件
Hudi真实的数据文件使用Parquet文件格式存储

- 其中包含一个metadata元数据文件和数据文件parquet列式存储。
- Hudi为了实现数据的CRUD,需要能够唯一标识一条记录,Hudi将把数据集中的唯一字段(
record key) +数据所在分区(partitionPath)联合起来当做数据的唯一键。
三、数据存储
hudi数据集的组织目录结构与hive非常相似,一份数据集对应一个根目录。数据集被打散为多个分区,分区字段以文件夹形式存在,该文件夹包含该分区的所有文件。
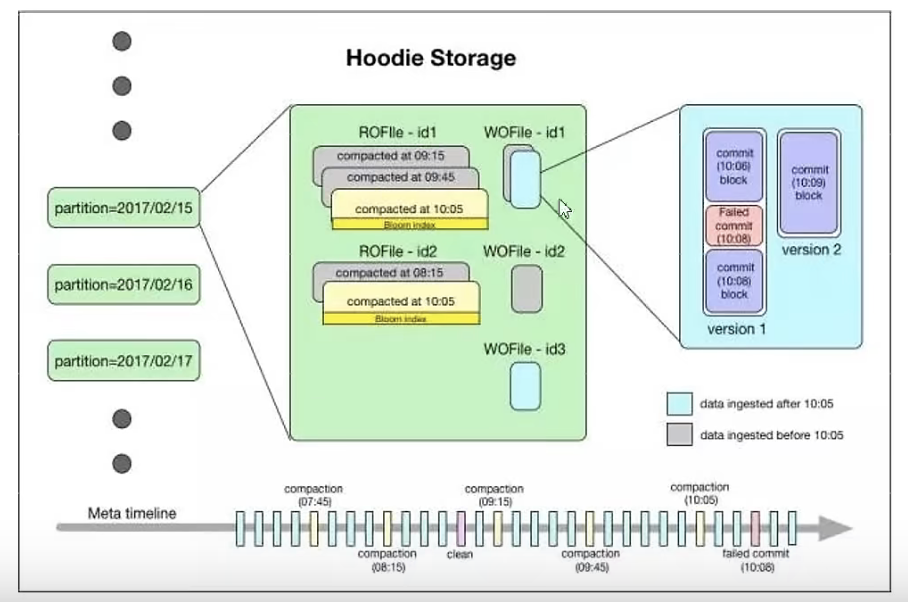
在根目录下,每个分区都有唯一的分区路径,每个分区数据存储在多个文件中
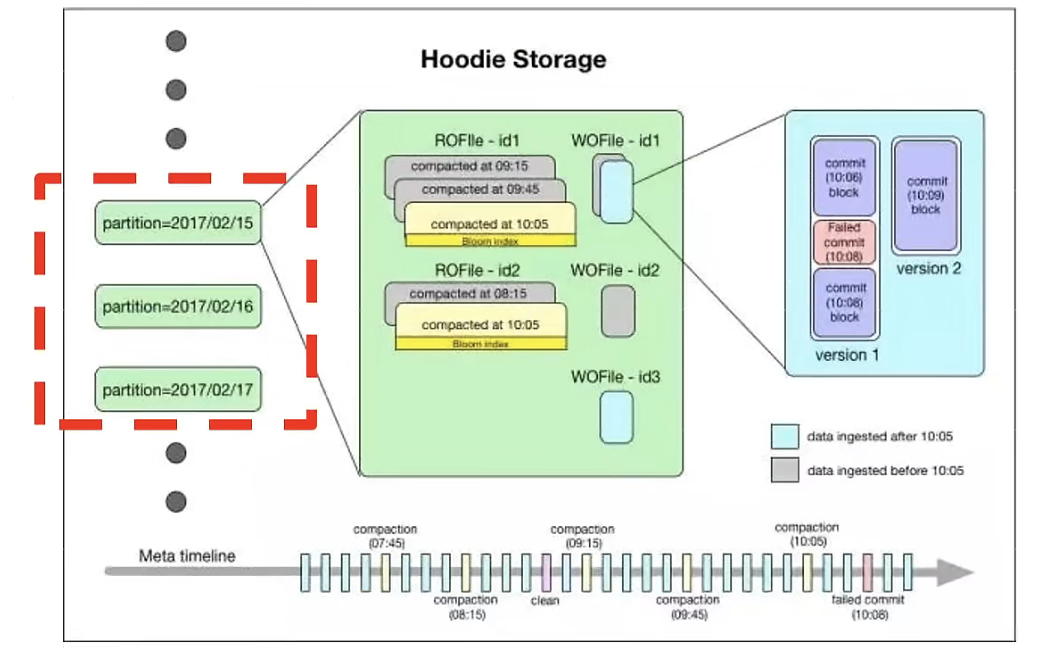
每个文件都有唯一的fileId和生成文件的commit所标识。如果发生更新操作时,多个文件共享相同的fileId,但会有不同的commit
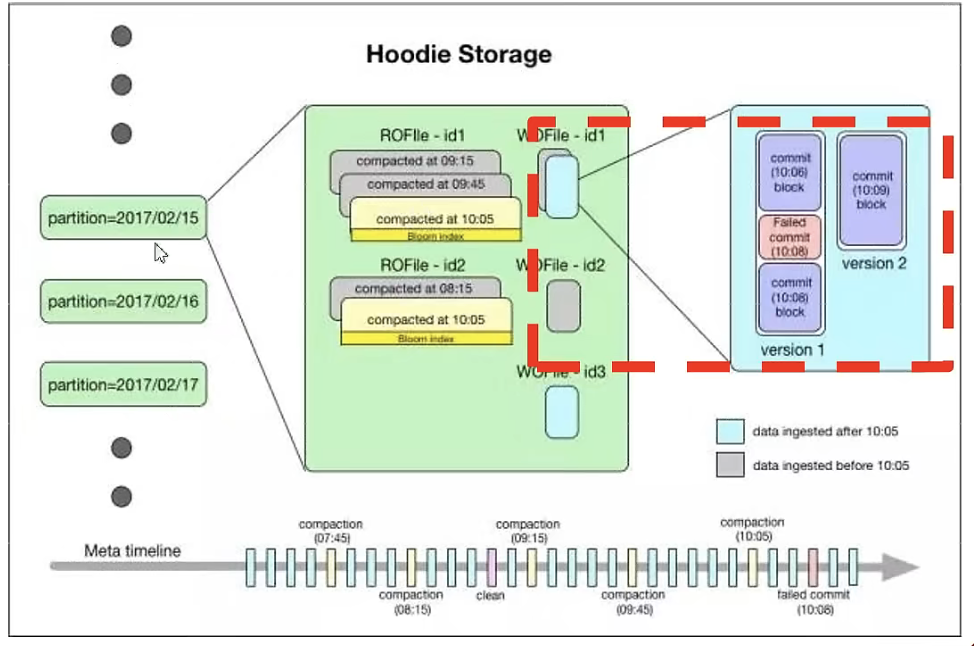
Metadata 元数据
以时间轴(timeline)的形式将数据集上的各项操作元数据维护起来,以支持数据集的瞬态视图,这部分元数据存储于根目录下的元数据目录。一共有三种类型的元数据:
Commits:一个单独的commit包含对数据集上一批数据的一次原子写入操作的相关信息。我们用单调递增的时间戳来标识commits,标的是一次写入操作的开始。Cleans:用于清除数据集中不再被查询所用到的旧版本文件的后台活动。Compactions:用于协调hudi内部的数据结构差异的后台活动。例如,将更新操作由基于行存的日志文件归集到列式数据上。

四、Hive 与 Hudi 集成使用
关于Hive的介绍与部署,可以参考我这篇文章:大数据Hadoop之——数据仓库Hive
1)安装mysql数据库
这里选择使用mysql on k8s,有不清楚的小伙伴,可以参考我这篇文章:【云原生】MySQL on k8s 环境部署
创建hive用户
MYSQL_ROOT_PASSWORD=$(kubectl get secret --namespace mysql mysql -o jsonpath="{.data.mysql-root-password}" | base64 -d)
#登录pod
kubectl exec -it mysql-primary-0 -n mysql -- bash
# 连接myslq
mysql -u root -p$MYSQL_ROOT_PASSWORD
CREATE USER 'hive'@'%' IDENTIFIED BY '123456';
GRANT ALL ON *.* to 'hive'@'%' WITH GRANT OPTION;
flush privileges;
2)安装 Hive
1、下载
wget http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
tar -xf apache-hive-3.1.3-bin.tar.gz
2、配置
hive-site.xml内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置hdfs存储目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hudi_hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop-hadoop-hdfs-nn-0:9083</value>
</property>
<!-- 所连接的 MySQL 数据库的地址,hudi_hive是数据库,程序会自动创建,自定义就行 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.182.110:30306/hive_metastore?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value>
</property>
<!-- MySQL 驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!-- mysql连接用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<!-- mysql连接密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<!--元数据是否校验-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>system:user.name</name>
<value>admin</value>
<description>user name</description>
</property>
<!-- host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop-hadoop-hdfs-nn-0</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<!-- hs2端口 默认是1000,为了区别,我这里不使用默认端口-->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
</configuration>
hive-env.sh #底部追加两行
export HADOOP_HOME=/opt/apache/hadoop
export HIVE_CONF_DIR=/opt/apache/apache-hive-3.1.3-bin/conf
export HIV_AUX_JARS_PATH=/opt/apache/apache-hive-3.1.3-bin/lib
3、解决Hive与Hadoop之间guava版本的差异
$ cd /opt/bigdata/hadoop/server
$ ls -l apache-hive-3.1.2-bin/lib/guava-*.jar
$ ls -l hadoop-3.3.1/share/hadoop/common/lib/guava-*.jar
# 删除hive中guava低版本
$ rm -f apache-hive-3.1.2-bin/lib/guava-*.jar
# copy hadoop中的guava到hive
$ cp hadoop-3.3.1/share/hadoop/common/lib/guava-*.jar apache-hive-3.1.2-bin/lib/
$ ls -l apache-hive-3.1.2-bin/lib/guava-*.jar
4、下载对应版本的mysql驱动包
下载地址:https://downloads.mariadb.com/Connectors/java
cd $HIVE_HOME/lib
# 根据java8版本下载这个版本,这个版本已验证可行
wget https://downloads.mariadb.com/Connectors/java/connector-java-1.2.2/mariadb-java-client-1.2.2.jar
# /etc/profile追加以下内容,source加载生效
export HIVE_HOME="/opt/apache/hive-3.1.2"
export PATH=$HIVE_HOME/bin:$PATH
5、初始化元数据
schematool -initSchema -dbType mysql --verbose
6、修改hadoop配置文件core-site.xml,表示设置可访问的用户及用户组
配置hadoop core-site.xml,再core-site.xml文件中追加如下内容
<property>
<name>hadoop.proxyuser.admin.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.admin.groups</name>
<value>*</value>
</property>
7、将hudi-hive的jar包放到hive lib目录下
cp hudi-0.12.0/packaging/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.12.0.jar $HIVE_HOME/lib/
cp hudi-0.12.0/packaging/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.12.0.jar $HIVE_HOME/lib/
8、启动服务
# 启动元数据服务,默认端口9083
nohup hive --service metastore &
# 启动hiveserver2服务,默认端口10000
nohup hive --service hiveserver2 > /dev/null 2>&1 &
# 查看日志
tail -f /tmp/admin/hive.log
# 连接
beeline -u jdbc:hive2://localhost:10000 -n admin
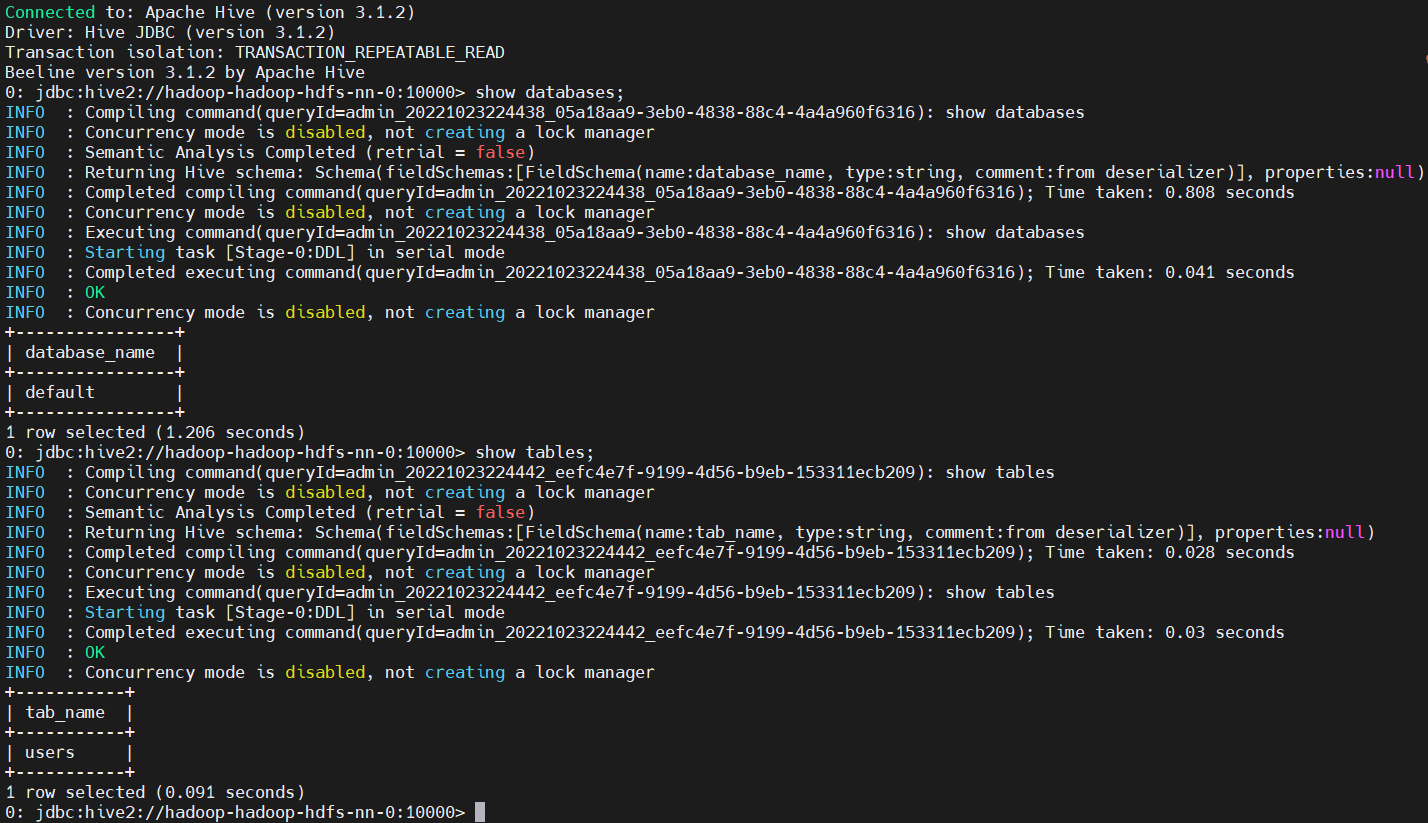
9、测试验证
# 这里使用新命令beeline,跟hive命令差不多
$ hive
show databases;
create table users(id int,name string);
show tables;
insert into users values(1,'zhangsan');
beelive连接
beeline -u jdbc:hive2://hadoop-hadoop-hdfs-nn-0:10000 -n admin
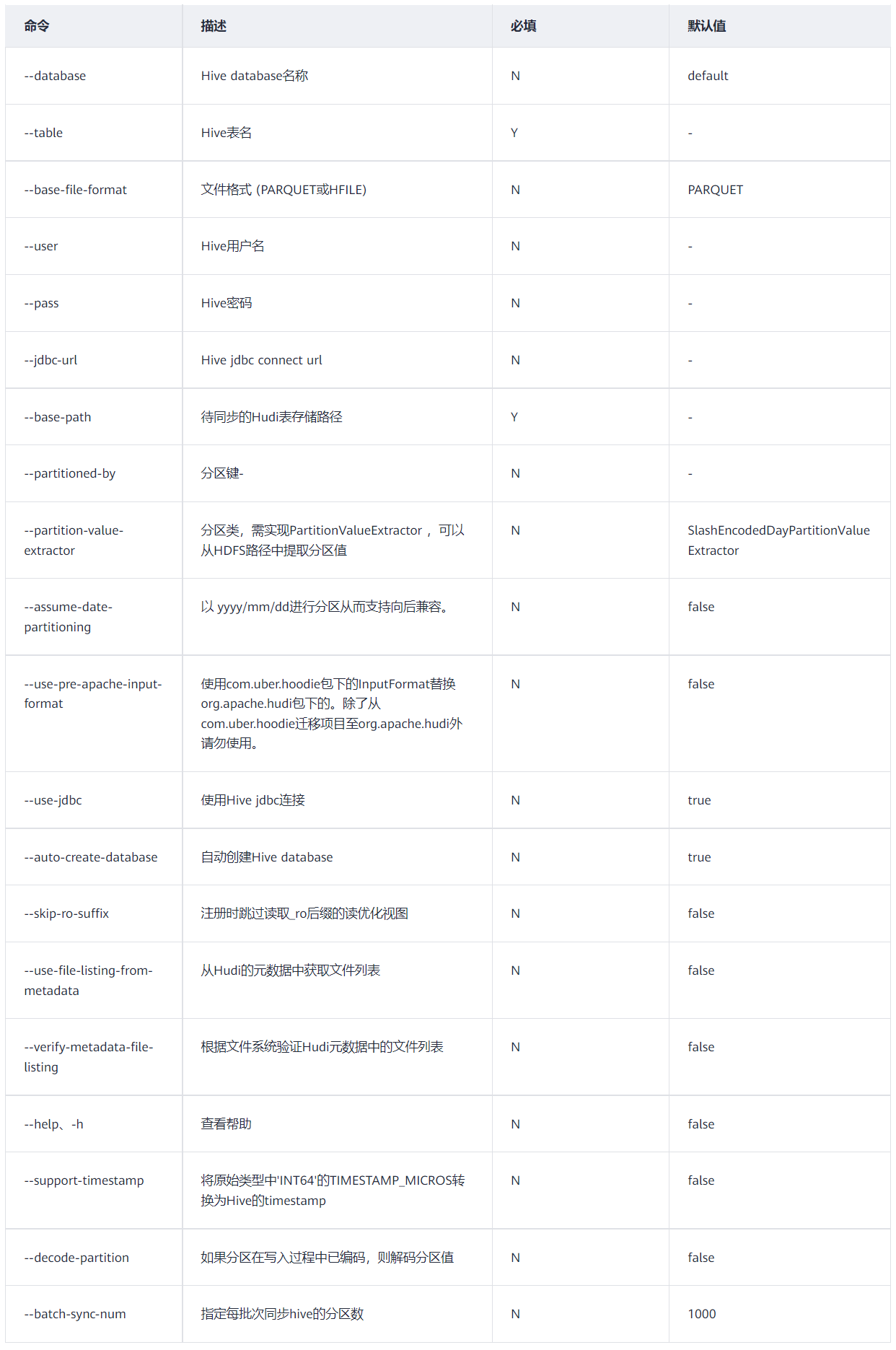
3)通过Hive sync tool 同步数据到Hive
应用hudi不可避免地要创建对应的hive表以方便查询hudi数据。一般我们使用flink、spark写入数据时,可以配置自动建表、同步元数据。有时也会选择使用hive sync tool工具离线进行操作。
Hive sync tool的介绍
Hudi提供Hive sync tool用于同步hudi最新的元数据(包含自动建表、增加字段、同步分区信息)到hive metastore。Hive sync tool提供三种同步模式,Jdbc,Hms,hivesql。推荐使用
jdbc、hms。
官网文档:https://hudi.apache.org/docs/syncing_metastore/
1、JDBC模式同步
cd /opt/apache/hudi-0.12.0/hudi-sync/hudi-hive-sync/
./run_sync_tool.sh \
--base-path hdfs://hadoop-hadoop-hdfs-nn:9000/tmp/hudi_trips_cow \
--database hudi_hive \
--table hudi_trips_cow \
--partitioned-by dt \
--jdbc-url 'jdbc:hive2://hadoop-hadoop-hdfs-nn-0:10000' \
--partition-value-extractor org.apache.hudi.hive.MultiPartKeysValueExtractor \
--user admin \
--pass admin \
--partitioned-by dt
2、HMS 模式同步
hive meta store同步,提供hive metastore的地址,如thrift://hms:9083,通过hive metastore的接口完成同步。使用时需要设置 --sync-mode=hms --use-jdbc=false。
./run_sync_tool.sh \
--base-path hdfs://hadoop-hadoop-hdfs-nn:9000/tmp/hudi_trips_cow \
--database hudi_hive \
--table hudi_trips_cow \
--jdbc-url thrift://hadoop-hadoop-hdfs-nn:9083 \
--user admin --pass admin \
--partitioned-by dt \
--sync-mode hms
Hive Sync时会判断表不存在时建外表并添加分区,表存在时对比表的schema是否存在差异,存在则替换,对比分区是否有新增,有则添加分区。
因此使用hive sync时有以下约束:
- 写入数据Schema只允许增加字段,不允许修改、删除字段。
- 分区目录只能新增,不会删除。
- Overwrite覆写Hudi表不支持同步覆盖Hive表。
- Hudi同步Hive表时,不支持使用timestamp类型作为分区列。
五、基于 Flink CDC 同步 MySQL 分库分表构建实时数据湖
1)Flink CDC 是什么?
2020年 Flink cdc 首次在 Flink forward 大会上官宣, 由 Alibaba的 Jark Wu & Qingsheng Ren 两位大佬介绍的,官方网址。
Flink CDC 文档:https://ververica.github.io/flink-cdc-connectors/master/content/about.html
GitHub地址:https://github.com/ververica/flink-cdc-connectors
Flink CDC(Change Data Capture:变更数据捕获) connector可以捕获在一个或多个表中发生的所有变更。该模式通常有一个前记录和一个后记录。Flink CDC connector 可以直接在Flink中以非约束模式(流)使用,而不需要使用类似 kafka 之类的中间件中转数据。
2)基于 Flink CDC 同步 MySQL 分库分表构建实时数据湖
官方文档:基于 Flink CDC 同步 MySQL 分库分表构建实时数据湖
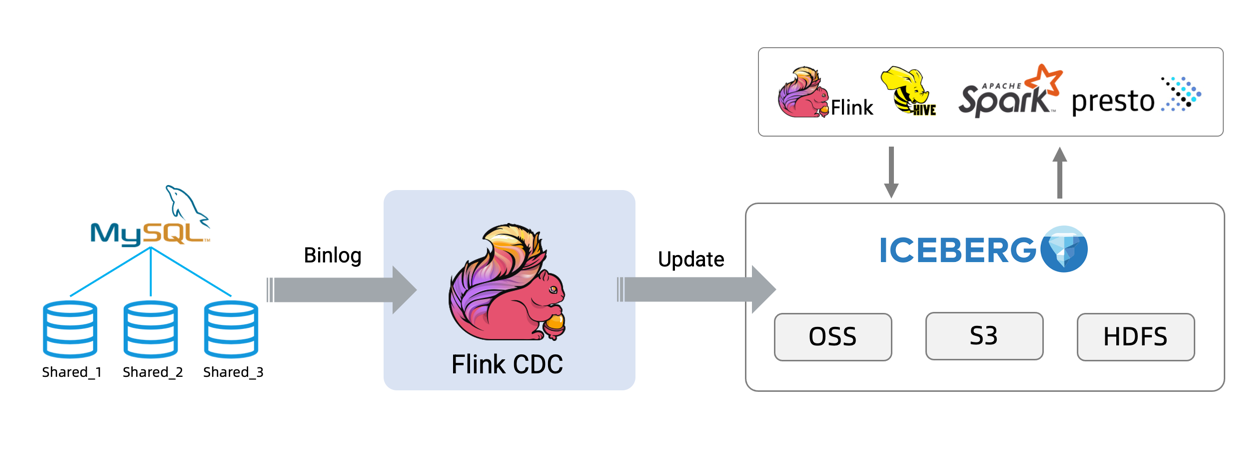
你也可以使用不同的 source 比如 Oracle/Postgres 和 sink 比如 Hudi 来构建自己的 ETL 流程。
对上图进行简化:
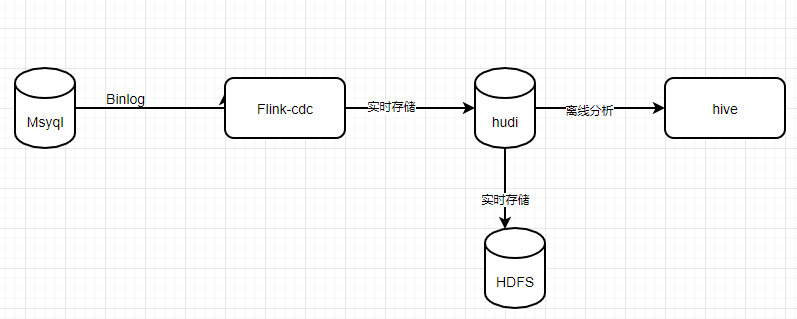
1、添加flink mysql jar包
flink-sql-connector-mysql-cdc jar包下载地址:https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/
cd $FLINK_HOME/lib
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.2.1/flink-sql-connector-mysql-cdc-2.2.1.jar
2、创建数据库表,并且配置binlog 文件
[mysqld]
#开启 Binlog,一般放在/var/lib/mysql;比如上面的设置重启数据库会生成mysql-bin.000001文件,文件名跟log_bin 值对应,当然也可以指定存储路径。
log_bin = mysql-bin
#删除超出这个变量保留期之前的全部日志被删除
expire_logs_days = 7
# 定一个集群内的 MySQL 服务器 ID,如果做数据库集群那么必须全局唯一。
server_id = 1024
# mysql复制主要有三种方式:基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。对应的,binlog的格式也有三种:STATEMENT,ROW,MIXED。
binlog_format = ROW
重启mysql
# 重启数据库
systemctl restart mariadb
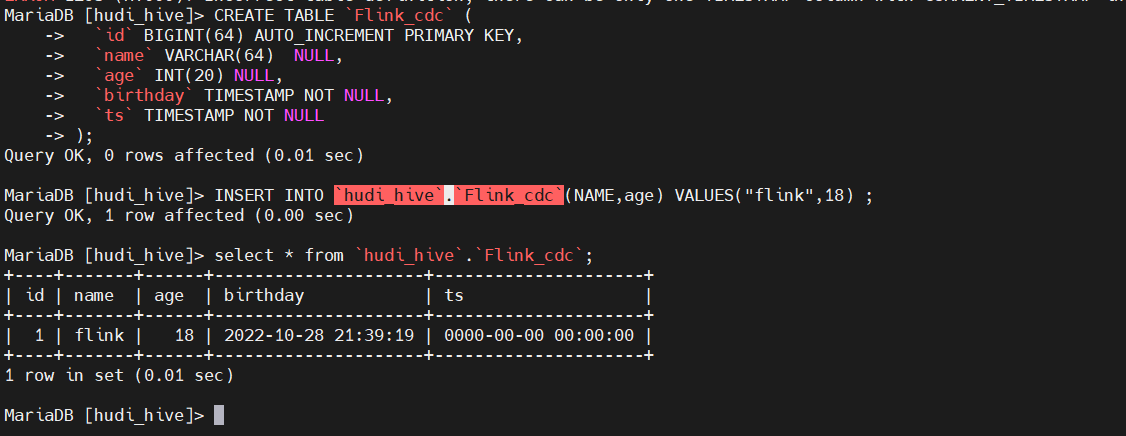
3、 创建mysql 库表
mysql -uhive -h192.168.182.110 -P30306 -p
密码:123456
CREATE DATABASE hudi_hive;
USE hudi_hive;
CREATE TABLE `Flink_cdc` (
`id` BIGINT(64) AUTO_INCREMENT PRIMARY KEY,
`name` VARCHAR(64) NULL,
`age` INT(20) NULL,
`birthday` TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
`ts` TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL
) ;
INSERT INTO `hudi_hive`.`Flink_cdc`(NAME,age) VALUES("flink",18) ;
4、在 Flink SQL CLI 中使用 Flink DDL 创建表
# 添加环境变量
export HADOOP_HOME=/opt/apache/hadoop
export HADOOP_DIR_CONF=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
# 启动单点flink
cd $FLINK_HOME
./bin/start-cluster.sh
# 测试可用性
# ./bin/flink run examples/batch/WordCount.jar
# 登录flink-sql CLI
./bin/sql-client.sh embedded -j ../hudi-0.12.0/packaging/hudi-flink-bundle/target/hudi-flink1.14-bundle-0.12.0.jar shell
# 设置表输出格式
SET 'sql-client.execution.result-mode' = 'tableau';
CREATE TABLE source_mysql (
id BIGINT PRIMARY KEY NOT ENFORCED,
name STRING,
age INT,
birthday TIMESTAMP(3),
ts TIMESTAMP(3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.182.110',
'port' = '30306',
'username' = 'hive',
'password' = '123456',
'server-time-zone' = 'Asia/Shanghai',
'debezium.snapshot.mode' = 'initial',
'database-name' = 'hudi_hive',
'table-name' = 'Flink_cdc'
);
# 创建flinksql 中的 flinkcdc 视图
create view view_source_flinkcdc_mysql AS SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') as part FROM source_mysql;
# 查mysql数据
SELECT id, name,age,birthday, ts, part FROM view_source_flinkcdc_mysql ;
5、创建输出表,关联Hudi表,并且自动同步到Hive表
使用下面的 Flink SQL 语句将数据从 MySQL 写入 hudi 中,并同步到hive
CREATE TABLE flink_cdc_sink_hudi_hive(
id bigint ,
name string,
age int,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
part VARCHAR(20),
primary key(id) not enforced
)
PARTITIONED BY (part)
with(
'connector'='hudi',
'path'= 'hdfs://hadoop-hadoop-hdfs-nn-0:9000/flink_cdc_sink_hudi_hive',
'table.type'= 'MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field'= 'id',
'write.precombine.field'= 'ts',
'write.tasks'= '1',
'write.rate.limit'= '2000',
'compaction.tasks'= '1',
'compaction.async.enabled'= 'true',
'compaction.trigger.strategy'= 'num_commits',
'compaction.delta_commits'= '1',
'changelog.enabled'= 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable'= 'true',
'hive_sync.mode'= 'hms',
'hive_sync.metastore.uris'= 'thrift://hadoop-hadoop-hdfs-nn-0:9083',
'hive_sync.jdbc_url'= 'jdbc:hive2://hadoop-hadoop-hdfs-nn-0:10000',
'hive_sync.table'= 'flink_cdc_sink_hudi_hive',
'hive_sync.db'= 'db_hive',
'hive_sync.username'= 'admin',
'hive_sync.password'= '123456',
'hive_sync.support_timestamp'= 'true'
);
6、查询视图数据,添加数据到输出表
# 将mysql数据同步到hudi和hive
INSERT INTO flink_cdc_sink_hudi_hive SELECT id, name,age,birthday, ts, part FROM view_source_flinkcdc_mysql ;
7、查看hive数据
beeline -u jdbc:hive2://localhost:10000 -n admin
show tables from db_hive;
hive 会有两张表:
flink_cdc_sink_hudi_hive_ro类型是读优化查询 ,flink_cdc_sink_hudi_hive_rt类型快照查询。
关于FlinkCDC,hive,mysql与hudi的整合就先到这里了,有任何疑问的小伙伴欢迎给我留言,后续会持续更新【大数据+云原生】相关的文档,请小伙伴耐心等待~
标签:hudi,Hadoop,hive,hadoop,FlinkCDC,mysql,Hudi,数据 From: https://www.cnblogs.com/liugp/p/16837940.html