阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说)、深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云。更多精彩内容请单击此处。

摘要:Hudi是数据湖的文件组织层,对Parquet格式文件进行管理提供数据湖能力,支持多种计算引擎。
本文分享自华为云社区《【云小课】EI第39课 MRS基础原理之Hudi介绍》,作者:Hello EI 。
Hudi是数据湖的文件组织层,对Parquet格式文件进行管理提供数据湖能力,支持多种计算引擎,提供IUD接口,在 HDFS的数据集上提供了插入更新和增量拉取的流原语。

Hudi结构
Hudi的架构如图1-1所示。
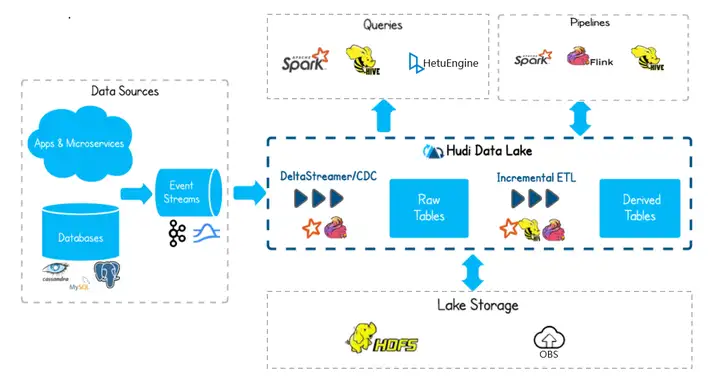
Hudi支持两种表类型
Copy On Write
写时复制表也简称cow表,使用parquet文件存储数据,内部的更新操作需要通过重写原始parquet文件完成。
- 优点:读取时,只读取对应分区的一个数据文件即可,较为高效。
- 缺点:数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。且由于耗时,读请求读取到的数据相对就会滞后。
Merge On Read
读时合并表也简称mor表,使用列格式parquet和行格式Avro两种方式混合存储数据。其中parquet格式文件用于存储基础数据,Avro格式文件(也可叫做log文件)用于存储增量数据。
- 优点:由于写入数据先写delta log,且delta log较小,所以写入成本较低。
- 缺点:需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log和老数据文件合并。
Hudi支持三种视图,针对不同场景提供相应的读能力
Snapshot View
实时视图:该视图提供当前hudi表最新的快照数据,即一旦有最新的数据写入hudi表,通过该视图就可以查出刚写入的新数据。
cow表和mor均支持这种视图能力。
Incremental View
增量视图:该视图提供增量查询的能力,可以查询指定COMMIT之后的增量数据,可用于快速拉取增量数据。
cow表支持该种视图能力, mor表也可以支持该视图,但是一旦mor表完成compact操作其增量视图能力消失。
Read Optimized View
读优化视图:该视图只会提供最新版本的parquet文件中存储的数据。
该视图在cow表和mor表上表现不同:
- 对于cow表,该视图能力和实时视图能力是一样的(cow表只用parquet文件存数据)。
- 对于mor表,仅访问基本文件,提供给定文件片自上次执行compact操作以来的数据, 可简单理解为该视图只会提供mor表parquet文件存储的数据,log文件里面的数据将被忽略。 该视图数据并不一定是最新的,但是mor表一旦完成compact操作,增量log数据被合入到了base数据里面,这个时候该视图和实时视图能力一样。
如何使用Hudi
目前Hudi集成在Spark2x中,使用Hudi需要安装Spark2x组件,并安装Spark2x的客户端。
- MRS集群的创建可参考MRS快速入门中的“创建集群”章节,例如购买MRS 3.1.0版本集群。
- 安装Spark2x客户端,可参考MRS用户指南中的“安装客户端”章节,例如客户端安装目录为:“/opt/client”。
- 安全模式(开启Kerberos认证)集群,在使用Hudi时,需要创建一个具有访问Hudi权限的用户,可参考MRS用户指南中的“创建用户”章节,用户组选择hadoop、hive和supergroup,主组选择hadoop,角色选择System_administrator,例如创建人机用户“testuser”。
1.使用root用户登录集群客户端节点,执行如下命令:
cd /opt/client source bigdata_env source Hudi/component_env kinit testuser
2.执行以下命令进入Spark SQL命令行。
spark-sql --master yarn
3.准备Hive数据表。
drop table if exists hivetb_text; create table hivetb_text (id int, comb long, name string, dt date) row format delimited fields terminated by ',' stored as textfile; insert into hivetb_text values (3,301,'0003','2021-09-11'),(4,400,'0004','2021-09-11');
4.创建Hudi Cow分区表。
drop table if exists hudi_test1; create table hudi_test1 (id int, comb long, name string, dt date) using hudi partitioned by (dt) options(type='cow',primaryKey='id', preCombineField='comb');
5.执行insert,插入数据,并查询结果。
insert into hudi_test1 values (1,100,'aaa','2021-08-28'),(2,200,'bbb','2021-08-28'); insert into hudi_test1 select 3,300,'ccc','2021-09-11'; select id,comb,dt,name from hudi_test1;
6.执行update,更新数据,并查询结果。
update hudi_test1 set name='0001' where id = 1; select id,comb,dt,name from hudi_test1;
7.执行delete,删除数据,并查询结果。
delete from hudi_test1 where id = 2; select id,comb,dt,name from hudi_test1;
8.执行merge,写入增量数据,并查询结果。
merge into hudi_test1 t1 using hivetb_text t2 on t1.id = t2.id when matched then update set id=t2.id, comb=t2.comb, name='aaaa', dt=t2.dt when not matched then insert *; select id,comb,dt,name from hudi_test1;
好了,本期云小课就介绍到这里,快去体验MapReduce(MRS)更多功能吧!猛戳这里
标签:test1,Hudi,云小课,视图,MRS,hudi,数据,id From: https://www.cnblogs.com/huaweiyun/p/16836575.html