
前言
近期有粉丝私信,不知道如何训练某讯系点选验证码,之前星球群也有不少粉丝讨论相关问题,为满足粉丝们的需求,本文将对这型验证码的训练进行讲解, 文末可以下载相关的工具,包括 文章配套标注工具 + 文章配套训练代码 + 部分学习数据集(少量类目,仅供学习使用,不设计成品) + 六宫格推理比较算法 。已加入星球 > 3 天的成员可以免费下载:


CLIP 简介
CLIP(Contrastive Language-Image Pre-Training)是由 OpenAI 在 2021 年发布的一种多模态预训练神经网络模型,旨在将图像和自然语言的表示空间统一起来,使得它们可以相互理解和关联。CLIP 的出现标志着计算机视觉领域的一次重大突破,它展示了利用自然语言监督来训练图像模型的强大能力。与以往的图像分类模型不同,CLIP 并没有使用大规模的标注图像数据集来进行训练,而是通过自监督对比学习的方式从未标注的图像进行预训练,以便使得模型更好的理解图像和文本之间的关系,这种模型我们称为双塔模型。整体流程如下:

每张图像都有一句解释性文字。将文字和图片分别通过一个编码器得到向量,文本编码器常用的是 Bert,而图片编码器则是 resnet 或者 vit,更多详细内容可以查看 OpenAI 相关资料:https://github.com/OpenAI/CLIP?tab=readme-ov-file。
1. 模型架构
CLIP 的核心思想是使用对比学习(contrastive learning),通过对图像和文本进行共同训练,来学习两者之间的关联。CLIP 模型由两部分组成:
- 视觉编码器:通常使用如 ResNet 或 ViT(Vision Transformer)架构,用于处理图像并将其编码为特征向量;
- 文本编码器:使用 Transformer 架构,将输入的文本描述转换为特征向量。
在训练过程中,CLIP 将大量图像-文本对作为输入,利用对比学习的方法,使相对应的图像和文本特征向量尽可能接近,而不匹配的图像和文本对的特征向量则尽可能远离。
2. 预训练数据和任务
CLIP 的训练使用了来自互联网的大规模图像-文本对(超过 4 亿对)。这些数据包括了非常多样化的内容,涵盖了自然语言和视觉场景的各种形式和细节。
CLIP 不依赖于传统的任务特定标签(如 ImageNet 数据集中的类别标签),而是通过从互联网上自然收集的图像和文本对进行训练。CLIP 模型通过学习图像和文本的对齐关系,可以理解图像中物体的复杂概念及其相关的文本描述。
3. 多任务能力
CLIP 在预训练过程中,学习了广泛的任务,包括:
- OCR(光学字符识别):CLIP 可以通过关联图像中的文字和对应的文本描述来识别图像中的文字内容;
- 地理定位:通过结合图像内容和文本描述中的位置线索,CLIP 可以对图像的地理位置进行推断;
- 动作识别:CLIP 可以识别视频中的动作或图像中的动态场景,并关联相应的文本描述。
4. 优势
CLIP 在多个任务上展示出了超越传统监督学习模型的能力,尤其是在以下几个方面:
- 广泛的任务处理能力:由于它的预训练数据集来自互联网,CLIP 具有处理各种复杂任务的能力,而不仅仅是单一任务的分类模型;
- 零样本学习(zero-shot learning):CLIP 可以在不需要任务特定的微调情况下,直接在没有见过的任务上进行推断。对于像 ImageNet 这样的图像分类任务,CLIP 甚至在未经过微调的情况下,能够超越一些专门训练的模型;
- 计算效率:CLIP 的多模态对比学习方法相较于传统的监督学习方法具有更高的计算效率,尤其是在处理大规模数据和任务迁移时。
5. 应用场景
CLIP 的通用性使其在许多实际应用中展现了巨大潜力,包括但不限于:
- 图像分类与搜索:通过输入自然语言描述,CLIP 可以从图像库中搜索相关图片,或者对图像内容进行文本化描述。
- 图文匹配:CLIP 能够识别图像和文本之间的语义匹配关系,适用于如生成式对话、跨模态检索等任务。
- 生成模型的辅助:CLIP 在图像生成任务中也可以发挥辅助作用,如指导图像生成模型生成符合特定文本描述的图像内容。
Chinese-CLIP
在上文了解了 CLIP 之后,我们对图文相似度有了一定认知,CN-CLIP 则是 CLIP 的汉化,使用了全新的训练方式,最原始的 CLIP 仅支持英文,倘若我们每次需要将中文翻译成英文去做检索和相似度计算,这种不仅存在精度问题,而且还存在偏差,所以便有了 Chinese-CLIP 模型。 拥有处理多模态数据的能力。初始阶段以预训练的方式设定了两种编码器:一种是 CLIP 的视觉编码器,另一种是中文版本的 RoBERTa 文本编码器,更多详细介绍见 Git: https://github.com/OFA-Sys/Chinese-CLIP。
CNCLIP 使用的数据集为 ~2 亿图文对, Chinese-CLIP 目前开源 5 个不同规模如下:
模型规模
| 模型规模 | 视觉侧骨架 | 参数量 | 文本侧骨架 | 文本侧参数量 | 分辨率 |
|---|---|---|---|---|---|
| CN-CLIPRN50 | ResNet50 | 77M | RBT3 | 39M | 224 |
| CN-CLIPViT-B/16 | ViT-B/16 | 188M | RoBERTa-wwm-Base | 102M | 224 |
| CN-CLIPViT-L/14 | ViT-L/14 | 406M | RoBERTa-wwm-Base | 102M | 224 |
| CN-CLIPViT-L/14@336px | ViT-L/14 | 407M | RoBERTa-wwm-Base | 102M | 336 |
| CN-CLIPViT-H/14 | ViT-H/14 | 958M | RoBERTa-wwm-Large | 326M | 224 |
本来都已经是大炮打麻雀了,那么本类验证码我们用的便是 CN-CLIPRN50 作为预训练 ckpt 来进行训练!
环境准备
本地环境
- python >= 3.6.4
- pytorch >= 1.8.0 (with torchvision >= 0.9.0)
- CUDA Version >= 10.2
没有 GPU 的同学可以采用往期文章推荐去租用 GPU 去训练,租用方法详细查看往期文章:【验证码识别专栏】人均通杀点选验证码!Yolov5 + 孪生神经网络 or 图像分类 = 高精模型 。
AutoDL 版本环境
-
镜像:PyTorch 2.0.0 Python 3.8(ubuntu20.04) Cuda 11.8
-
内存:80GB
-
硬盘:系统盘 30 GB;数据盘 -> 免费 50 GB,付费 20 GB扩容缩容
这里有坑点,硬盘最好花费个位数去扩容一下,因为你不能保证你全程不踩雷,某些操作不当可能会导致服务器硬盘爆满,导致训练最后模型保存失败,内存不足等问题:

finetune
代码组织
工作目录如下,全文 ${DATAPATH} 将用 KG_finetune 代替:
Chinese-CLIP/
├── run_scripts/
│ ├── muge_finetune_vit-b-16_rbt-base.sh # 训练脚本,官方样例
│ ├── flickr30k_finetune_vit-b-16_rbt-base.sh # 训练脚本,官方样例
│
└── cn_clip/
├── clip/
├── eval/
├── preprocess/
└── training/
${DATAPATH} # 作者为 KG_finetune
├── pretrained_weights/ # 预训练骨架
├── experiments/ # 训练模型导出地址
├── deploy/ # 用于存放 pt 转换 ONNX
└── datasets/
├── KG_GE/
预训练 CKPT
上文我们谈到,我们选择 CN-CLIPRN50 骨架作为预训练模型,我们将 CN-CLIPRN50 下载到本地,然后将其移动到 pretrained_weights 目录下。
数据集预处理
CLIP 数据集与我们常见数据集不同,为了与 Chinese-CLIP 代码适配,同时保证数据处理和读取的效率,我们建议将训练 & 评测使用的图文数据集统一组织成如下的方式:
${DATAPATH} # 作者为TX_6icon
└── datasets/
└── KG_GE/
├── train_imgs.tsv # 图片id & 图片内容
├── train_texts.jsonl # 文本id & 文本内容,连同匹配的图片id列表
├── valid_imgs.tsv
├── valid_texts.jsonl
├── test_imgs.tsv
└── test_texts.jsonl
图片不是以大量的小文件方式存放,而是将训练/验证/测试图片以 base64 形式分别存放在 ${split}_imgs.tsv 文件中。文件每行表示一张图片,包含图片 id(int 型)与图片 base64,以 tab 隔开,格式如下:
1000002 /9j/4AAQSkZJ...YQj7314oA//2Q==
当然也给大家写好了完整的代码,只需将待标注图片放到指定文件夹,运行脚本,即可完成转换,即可生成 train_imgs.tsv,val_imgs.tsv,test_imgs.tsv。完整代码如下:
import os
import random
import base64
from PIL import Image
from io import BytesIO
from sklearn.model_selection import train_test_split
def image_to_base64(file_path):
# Convert image to base64 string
with Image.open(file_path) as img:
img_buffer = BytesIO()
img.save(img_buffer, format=img.format)
byte_data = img_buffer.getvalue()
base64_str = base64.b64encode(byte_data).decode('utf-8')
return base64_str
def generate_random_id(length=10):
# Generate a random number with the specified number of digits
return ''.join([str(random.randint(1, 9)) for _ in range(length)])
def save_images_to_split_tsv(image_dir, output_dir, train_ratio=0.8, val_ratio=0.1, test_ratio=0.1, id_length=15):
# 获取所有图片文件
image_files = os.listdir(image_dir)
# 随机分成训练集、验证集和测试集
train_files, test_files = train_test_split(image_files, test_size=test_ratio)
train_files, val_files = train_test_split(train_files, test_size=val_ratio / (train_ratio + val_ratio))
# 保存到不同的TSV文件中
save_images_to_tsv(train_files, os.path.join(output_dir, 'train_imgs.tsv'), image_dir, id_length)
save_images_to_tsv(val_files, os.path.join(output_dir, 'val_imgs.tsv'), image_dir, id_length)
save_images_to_tsv(test_files, os.path.join(output_dir, 'test_imgs.tsv'), image_dir, id_length)
def save_images_to_tsv(image_files, output_file, image_dir, id_length):
with open(output_file, 'w') as f_out:
for file_name in image_files:
file_path = os.path.join(image_dir, file_name)
image_id = generate_random_id(id_length)
try:
base64_str = image_to_base64(file_path)
f_out.write(f"{image_id}\t{base64_str}\n")
except Exception as e:
print(f"Error processing {file_name}: {e}")
# Example usage
image_directory = 'img'
output_directory = 'datasets'
save_images_to_split_tsv(image_directory, output_directory)
训练集/验证集/测试集比例这里推荐 0.9:0.1:0.1,运行后将会在当前目录生成所需文件,文件内格式如下:

文本信息及图文对匹配关系则保存在 ${split}_texts.jsonl 文件。文件每行是一行 json,格式如下:
{"text_id": 8428, "text": "高级感托特包斜挎", "image_ids": [1076345, 517602]}
对于测试集只有文本,不知道图文对匹配关系的情况,每行的 image_ids 字段处理为空列表即可,即 "image_ids": []。
所以这种数据集格式就和我们平台所见不同,需要将指定 id,放到所匹配的 text_id 中,所以标注就有点困难,这里也提供了专属的标注工具:

支持断点续标,标注词记忆,全部图片完成标注后将会在当前目录生成我们所需的数据集格式。
最后,我们还需要将 tsv 和 jsonl 文件一起序列化,转换为内存索引的 LMDB 数据库文件,方便训练时的随机读取 ,命令如下:
python cn_clip/preprocess/build_lmdb_dataset.py \
--data_dir ${DATAPATH}/datasets/${dataset_name}
--splits train,valid,test
这部分转换我们在后续将全部准备工作完成后,将代码打包上传到 GPU 服务器再进行执行。
例如对于 KG_GE 数据集,则 ${dataset_name} 设为 KG_GE,--splits 指定需要转换的数据集划分,以逗号不加空格分隔。转换后,数据集文件夹下会对应增加以下 LMDB 序列化文件 ,格式如下:
${DATAPATH}
└── datasets/
└── ${dataset_name}/
└── lmdb/
├── train
│ ├── imgs
│ └── pairs
├── valid
└── test
模型微调
前面的步骤,我们已经将数据集准备完毕,接下来我们开始训练的部分,需要我们参考样例,手写一个训练脚本,这里我们举例几个重要的配置文件来讲:
WORKER_CNT: 训练的机器个数,一般都是单机器,写1就行
GPUS_PER_NODE: 每个机器上的GPU个数,大部分为1,具体查询自己的gpu个数
训练/验证数据
train-data: 训练数据LMDB目录
val-data: 验证数据LMDB目录
num-workers: 训练集数据处理
valid-num-workers: 验证集数据处理(DataLoader)的进程数,默认为1。
训练超参数
vision-model: 这里选择 RN50
text-model: 参考骨架对应,我们选择 RBT3-chinese
context-length: 文本输入序列长度。
warmup: warmup步数。
batch-size: 训练时单卡batch-size。
lr: 学习率。
wd: weight decay。
max-steps: 训练步数,也可通过max-epochs指定训练轮数。
valid-batch-size: 验证时单机batch-size。
输出选项
name: 指定输出路径。超参日志, 训练日志以及产出ckpt均会存放至 ${DATAPATH}/experiments/${name}/。
save-step-frequency及save-epoch-frequency: 存ckpt的步数或轮数间隔。
report-training-batch-acc: 日志是否报告训练图到文&文到图batch准确率。
权重读取相关选项
resume: 权重读取的路径。预训练骨架
这里给出我的训练脚本,如下:
#!/usr/bin/env
# Guide:
# This script supports distributed training on multi-gpu workers (as well as single-worker training).
# Please set the options below according to the comments.
# For multi-gpu workers training, these options should be manually set for each worker.
# After setting the options, please run the script on each worker.
# Command: bash run_scripts/muge_finetune_vit-b-16_rbt-base.sh ${DATAPATH}
# Number of GPUs per GPU worker
GPUS_PER_NODE=1
# Number of GPU workers, for single-worker training, please set to 1
WORKER_CNT=1
# The ip address of the rank-0 worker, for single-worker training, please set to localhost
export MASTER_ADDR=localhost
# The port for communication
export MASTER_PORT=8514
# The rank of this worker, should be in {0, ..., WORKER_CNT-1}, for single-worker training, please set to 0
export RANK=0
export PYTHONPATH=${PYTHONPATH}:`pwd`/cn_clip/
DATAPATH=${1}
# data options
train_data=${DATAPATH}/datasets/KG_GE/lmdb/train
val_data=${DATAPATH}/datasets/KG_GE/lmdb/valid # if val_data is not specified, the validation will be automatically disabled
# restore options
resume=${DATAPATH}/pretrained_weights/clip_cn_rn50.pt # or specify your customed ckpt path to resume
reset_data_offset="--reset-data-offset"
reset_optimizer="--reset-optimizer"
# reset_optimizer=""
# output options
output_base_dir=${DATAPATH}/experiments/
name=txmuge_rs50
save_step_frequency=999999 # disable it
save_epoch_frequency=1
log_interval=1
report_training_batch_acc="--report-training-batch-acc"
# report_training_batch_acc=""
# training hyper-params
context_length=52
warmup=100
batch_size=128
valid_batch_size=20
accum_freq=1
lr=5e-5
wd=0.001
max_epochs=150 # or you can alternatively specify --max-steps
valid_step_interval=20
valid_epoch_interval=1
vision_model=RN50
text_model=RBT3-chinese
use_augment="--use-augment"
# use_augment=""
python3 -m torch.distributed.launch --use_env --nproc_per_node=${GPUS_PER_NODE} --nnodes=${WORKER_CNT} --node_rank=${RANK} \
--master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} cn_clip/training/main.py \
--train-data=${train_data} \
--val-data=${val_data} \
--resume=${resume} \
${reset_data_offset} \
${reset_optimizer} \
--logs=${output_base_dir} \
--name=${name} \
--save-step-frequency=${save_step_frequency} \
--save-epoch-frequency=${save_epoch_frequency} \
--log-interval=${log_interval} \
${report_training_batch_acc} \
--context-length=${context_length} \
--warmup=${warmup} \
--batch-size=${batch_size} \
--valid-batch-size=${valid_batch_size} \
--valid-step-interval=${valid_step_interval} \
--valid-epoch-interval=${valid_epoch_interval} \
--accum-freq=${accum_freq} \
--lr=${lr} \
--wd=${wd} \
--max-epochs=${max_epochs} \
--vision-model=${vision_model} \
${use_augment} \
--text-model=${text_model}
我们在 run_scripts 文件夹新建一个 sh 脚本文件,将上面训练脚本复制进去,具体参数按个人习惯进行修改。
此脚本我们用的就是 RN50 作为预训练模型进行训练的。
train
我们在本地将所需文件全部准备好以后,按下面的格式压缩成压缩包,压缩包内容为俩个文件夹,分别是 Chinese-CLIP 与 TX_6icon:
Chinese-CLIP/
├── run_scripts/
│ ├── muge_finetune_vit-b-16_rbt-base.sh
│ ├── flickr30k_finetune_vit-b-16_rbt-base.sh
│
└── cn_clip/
├── clip/
├── eval/
├── preprocess/
└── training/
TX_6icon #作者为TX_6icon
├── pretrained_weights/
├── experiments/
├── deploy/
└── datasets/
├── KG_GE/
进入 GPU 训练平台,这里有一个暗坑,我们需要选择数据盘,千万不要选择其他地方:

将我们的压缩包传到此处,最终如下:

进入 cd Chinese-CLIP,我们上文说的命令现在进行执行 python3 cn_clip/preprocess/build_lmdb_dataset.py --data_dir /root/autodl-tmp/TX_6icon/datasets/KG_GE --splits train,valid,test 。
结果如下:

紧接着进入 run_scripts 中,新建一个 tx_rs50_rbt-base.sh 脚本,将我们上面的训练脚本复制进去并保存!
紧接着回到 root@autodl-container-d4594a8753-96d5e6b4:~/autodl-tmp/Chinese-CLIP# 中执行命令:
bash run_scripts/tx_rs50_rbt-base.sh /root/autodl-tmp/TX_6icon
这样我们的训练代码就跑起来了,如下:

最终导出的模型会在 experiments 文件夹中,取决于我们刚刚写的训练脚本里面的目录是怎样的:
output_base_dir=${DATAPATH}/experiments/
name=txmuge_rs50
则我的模型文件导出则在 experiments 下的 txmuge_rs50 中,如下:

onnx 转换
最新的 Chinese-CLIP 代码,已支持将各规模的 Pytorch 模型,转换为 onnx 模型。
- ONNX:请安装
pip install onnx onnxruntime-gpu onnxmltoolsONNX 库。onnx 版本 1.13.0,onnxruntime-gpu 版本 1.13.1,onnxmltools 版本 1.11.1 为例; - Pytorch:建议直接 pip 安装
1.12.1+cu116/118。
这里有个暗坑,选择 GPU 平台去训练的同学这里需要降级 Pytorch,命令如下:
pip install torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 --index-url https://download.pytorch.org/whl/cu117
将 pt 模型转换 onnx 同时也需要我们编写 sh 脚本,由于我们开始整理结构的时候文件目录就已经创好,所以 mkdir -p /root/autodl-tmp/TX_6icon/deploy/ 命令就是多余的,我的 onnx.sh 脚本如下:
#cd Chinese-CLIP/
export CUDA_VISIBLE_DEVICES=0
export PYTHONPATH=${PYTHONPATH}:`pwd`/cn_clip
# ${DATAPATH}的指定,请参考Readme"代码组织"部分创建好目录,尽量使用相对路径:https://github.com/OFA-Sys/Chinese-CLIP#代码组织
checkpoint_path=/root/epoch_latest.pt # 指定要转换的ckpt完整路径
#mkdir -p /root/autodl-tmp/TX_6icon/deploy/ # 创建ONNX模型的输出文件夹
python cn_clip/deploy/pytorch_to_onnx.py \
--model-arch RN50 \
--pytorch-ckpt-path ${checkpoint_path} \
--save-onnx-path /root/autodl-tmp/TX_6icon/deploy/tx666 \
--convert-text --convert-vision
如果不降级 Pytorch 可能会出现如下错误,只需按上面要求将 torch 版本降低即可。
最终 onnx 转换完毕提示如下则为成功,即可在 deploy 文件下找到我们成功转换的 onnx 文件:
Finished PyTorch to ONNX conversion...
>>> The text FP32 ONNX model is saved at ${DATAPATH}/deploy/vit-b-16.txt.fp32.onnx
>>> The text FP16 ONNX model is saved at ${DATAPATH}/deploy/vit-b-16.txt.fp16.onnx with extra file ${DATAPATH}/deploy/vit-b-16.txt.fp16.onnx.extra_file
>>> The vision FP32 ONNX model is saved at ${DATAPATH}/deploy/vit-b-16.img.fp32.onnx
>>> The vision FP16 ONNX model is saved at ${DATAPATH}/deploy/vit-b-16.img.fp16.onnx with extra file ${DATAPATH}/deploy/vit-b-16.img.fp16.onnx.extra_file
然后将与 fp16 有关的 4 个模型文件全部导出: tx666.img.fp16.onnx,tx666.img.fp16.onnx.extra_file ,tx666.txt.fp16.onnx,tx666.txt.fp16.onnx.extra_file。
推理部署
提取图像/文本特征/相似度比较:
# 完成必要的import(下文省略)
import onnxruntime
from PIL import Image
import numpy as np
import torch
import argparse
import cn_clip.clip as clip
from clip import load_from_name, available_models
from clip.utils import _MODELS, _MODEL_INFO, _download, available_models, create_model, image_transform
DIR_PATH = pathlib.Path(__file__).parent.as_posix()
img_sess_options = onnxruntime.SessionOptions()
img_sess_options.intra_op_num_threads = 8
img_sess_options.inter_op_num_threads = 4
img_onnx_model_path = f'{DIR_PATH}/cn_clip/deploy/tx666.img.fp16.onnx'
img_session = onnxruntime.InferenceSession(img_onnx_model_path, sess_options=img_sess_options,
providers=["CUDAExecutionProvider"])
model_arch = "RN50"
preprocess = image_transform(_MODEL_INFO[model_arch]['input_resolution'])
txt_sess_options = onnxruntime.SessionOptions()
txt_sess_options.intra_op_num_threads = 8
txt_sess_options.inter_op_num_threads = 4
txt_onnx_model_path = f'{DIR_PATH}/cn_clip/deploy/tx666.txt.fp16.onnx'
txt_session = onnxruntime.InferenceSession(txt_onnx_model_path, sess_options=txt_sess_options,
providers=["CUDAExecutionProvider"])
由于训练机器和本机 TF 环境可能不同,预测函数我们要略加修改:
def calculate_matching_probability(text: str, images: Image.Image) -> float:
image = preprocess(images)
if isinstance(image, np.ndarray):
image = np.expand_dims(image.astype(np.float32), axis=0)
elif isinstance(image, torch.Tensor):
image = image.float().unsqueeze(0).cpu().numpy()
else:
raise ValueError("Unsupported image format. Expected a numpy array or torch tensor.")
image_features = img_session.run(["unnorm_image_features"], {"image": image})[0]
image_features /= np.linalg.norm(image_features, axis=-1, keepdims=True)
text_tokens = clip.tokenize(["K哥爬虫", text], context_length=52)
text_features = []
for one_text in text_tokens:
one_text = np.expand_dims(one_text, axis=0)
text_feature = txt_session.run(["unnorm_text_features"], {"text": one_text})[0]
text_features.append(text_feature)
text_features = np.vstack(text_features)
text_features /= np.linalg.norm(text_features, axis=1, keepdims=True)
logits_per_image = 100 * np.dot(image_features, text_features.T)
probabilities = np.exp(logits_per_image - np.max(logits_per_image)) / np.sum(
np.exp(logits_per_image - np.max(logits_per_image)), axis=-1, keepdims=True)
return probabilities[0][1]
因为 CLIP 是图像与多个文本进行对比,找出最优,所以我们在匹配答案的时候需要随机一个字符串,以便模型可以正确比较,text_tokens = clip.tokenize(["K哥爬虫", text], context_length=52)。
最终,通过比较找出相似度最优解,对比算法可以自行去编写,可以设置一个相似度阈值,将超过该部分的答案成功匹配即可,这部分算法文章开头已经说过,星球成员可以私信领取,运行结果如下:
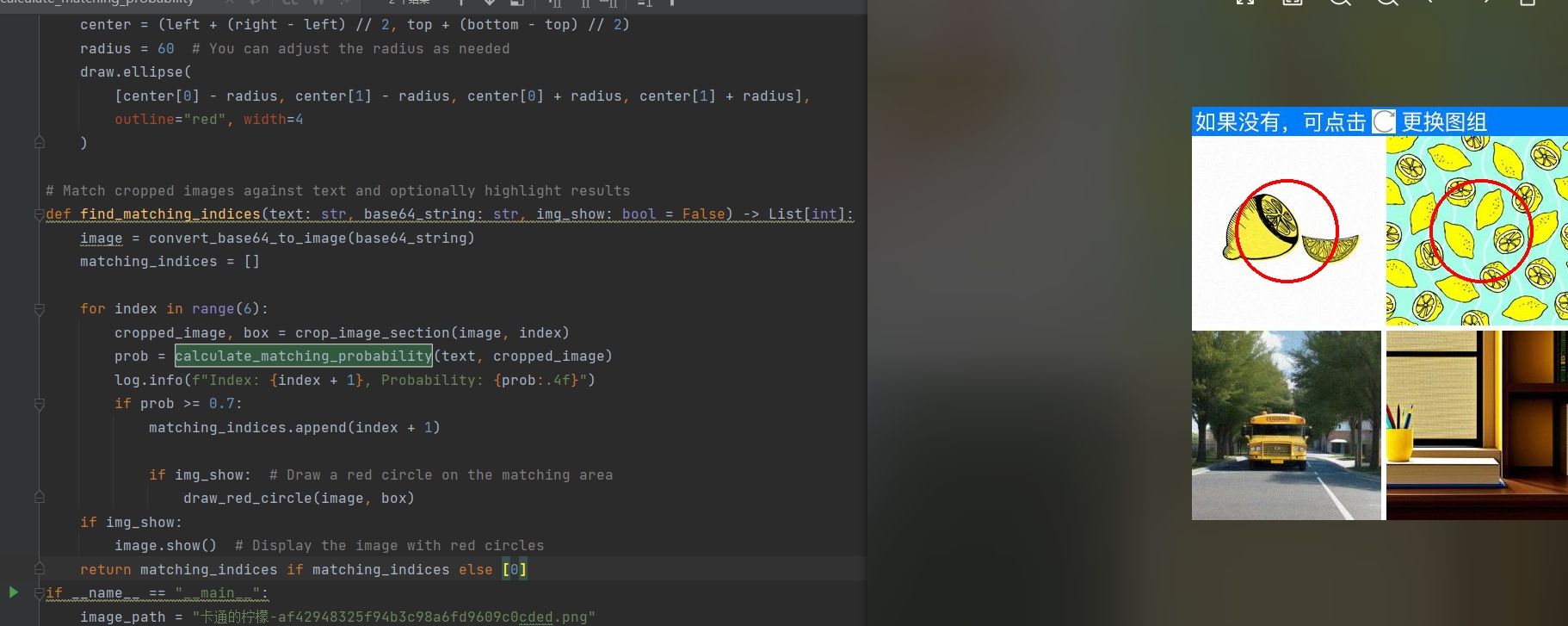
最终也是得到了我们需要的坐标 [1, 2]。
当然除了原图识别以外,也可以基于这个思路去开发截图识别,无非就是接收参数由一个文本 + 图像,变成了只传入一张截图进行识别,思路不变,可以利用飞浆等框架进行题目的分割与识别,最终还是要回归到相似度图文相似度比较。
结果展示
GPU 环境下,6 图速度基本维持毫秒级别,结果如下:
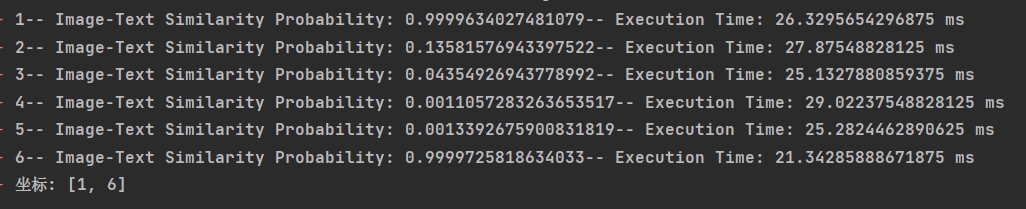
雷区(基于 GPU 训练平台)
-
GPU 平台训练机器选择 PyTorch 2.0.0,Python 3.8(ubuntu20.04),Cuda 11.8;
-
训练与转 onnx 所需 Pytorch 环境不同;
-
模型微调 save-step-frequency 及 save-epoch-frequency 默认为 1,最好修改为 20,轮数设置 150-200,不然每跑一轮保存一遍模型,你的数据盘很快就满了;
-
训练机器与本机推理机器 TF 环境可能不同,要注意推理时微调图像参数,详情见如下:
if isinstance(image, np.ndarray):
image = np.expand_dims(image.astype(np.float32), axis=0)
elif isinstance(image, torch.Tensor):
image = image.float().unsqueeze(0).cpu().numpy()
--use-flash-attention较难安装,训练脚本不使用加速也可正常训练,不要钻牛角尖(粉丝疑问)。