LLM中词向量的表示和词嵌入的一些疑问
词向量的一些特点
在3blue1brown的视频【官方双语】GPT是什么?直观解释Transformer | 深度学习第5章_哔哩哔哩_bilibili中, 在15min左右介绍了LLM的词嵌入的过程.
其中提到mother的词向量减去father的词向量, 会近似于women的词向量-man的词向量
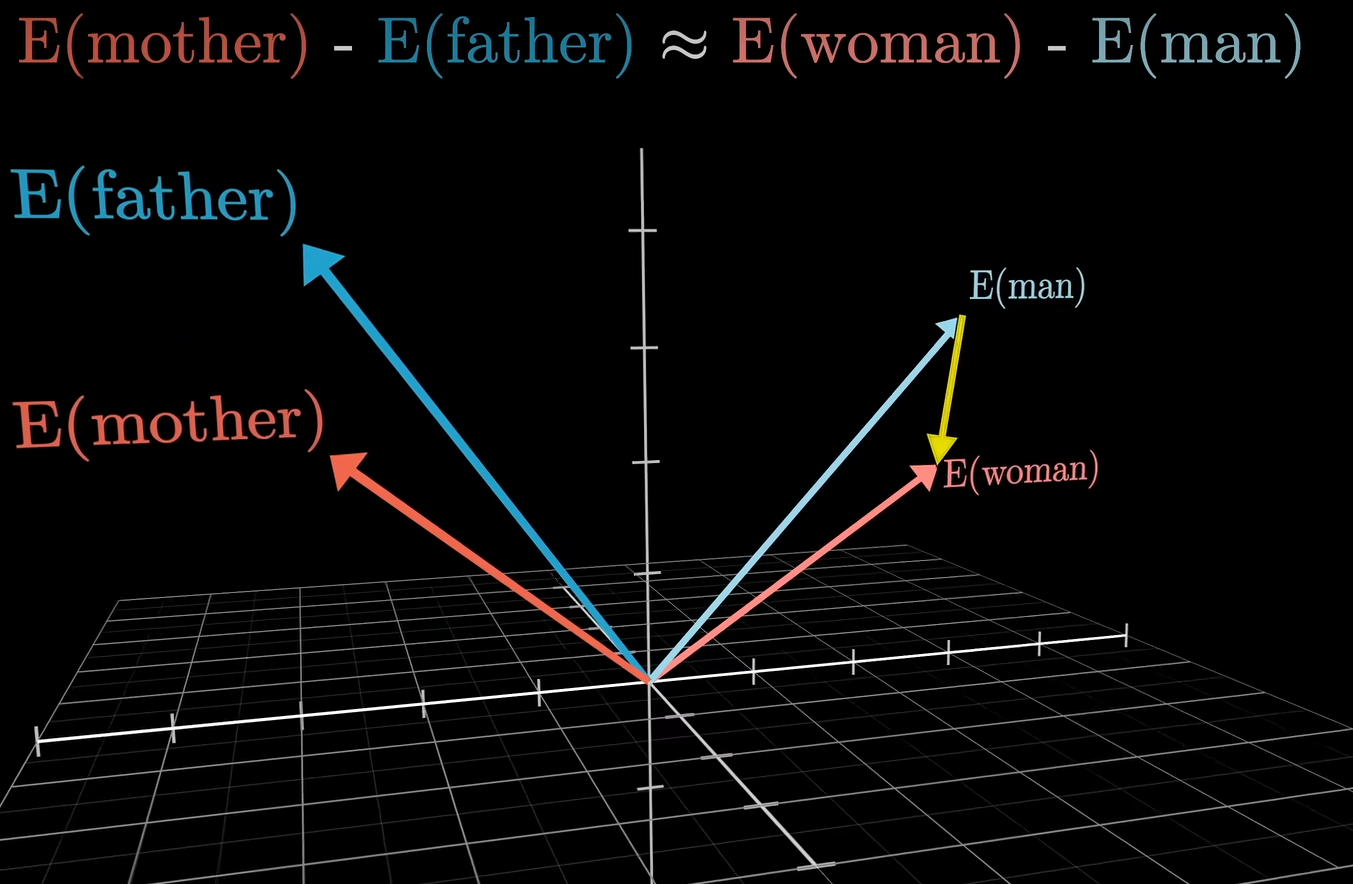
通过这个例子,说明模型在词嵌入空间上的某一方向编码了一个性别信息. 这个例子非常生动, 也非常符合直觉.
类似的有一篇2017年发表在CogSci的研究1705.04416 (arxiv.org)
在这篇论文中,也提到类似的例子
即\(E(woman)\approx E(man)+E(queen)-E(king)\)
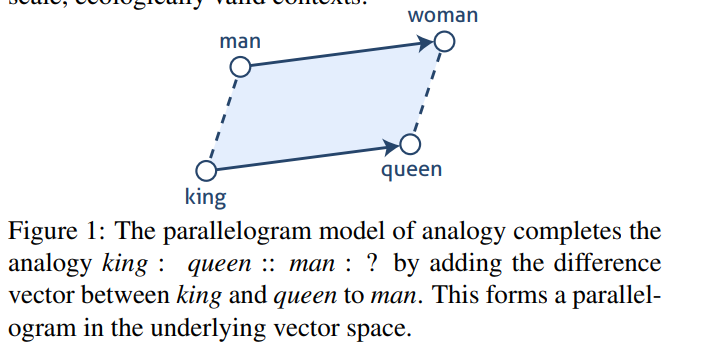
首先一点, 我认为使用\(E(woman)\approx E(man)+E(queen)-E(king)\) 来说明模型在某一方向上编码了特定信息并不一定准确.
因为我们可以理解为women和man 是一组相似的词, 词向量是比较接近的,同理queen和king也是
事实上, 在llama3-8B-instruction 中,通过余弦相似度去衡量woemn和man的词向量, 可以发现他们确实如此)
由于E(queen)和E(king)本身比较接近,因此他们相减应该得到一个较小的向量, 那么自然而然的,我们会有
\[E(woman)\approx E(man) \approx E(man)+E(queen)-E(king) \]因此,我认为像3Blue1Brown中直接比较\(E(queen)-E(king)\)和\(E(woman)- E(man)\) 相似度,显然是一个更合适的选择.
简单的实现
如果他们是相似的,那么他们的余弦相似度值应该尽可能大, 然后, 在llama3-8b 的测试中, 我们发现他们的相似度为-0.0220,也就是说,\(E(queen)-E(king)\)和\(E(woman)- E(man)\)这两个向量是几乎正交的.
而和之前的分析一样E(man) 和E(woman)-E(queen)+E(king)的相似度有0.3906, 这对于llama3模型而言是一个比较高的相似度(llama每个词向量的维度是4096)
除了llama3,和简单测试了phi-3, llama2,Qwen1.5等模型, 同时也简单试了一下其他的词, 得出了结果都和llama3基本都大差不差.
\(E(queen)-E(king)\)和\(E(woman)- E(man)\) 这两个向量不仅不是接近平行,甚至是几乎正交的. 至此, 我们可以3b1b和这篇论文中说提出的理论虽然很简洁优雅, 但在大模型上似乎没有那么奏效. 不过目前像3blue1brown中的理论, 依然可以在一些介绍LLM词向量的文章中看到, 这个理论本身非常有道理, 但实测下来, 可能还是需要更加谨慎的看待这个理论.
llama3的结果
//E(woman)-E(man)和E(queen)-E(king)的相似度
tensor([-0.0220], device='cuda:0', dtype=torch.bfloat16,
grad_fn=<SumBackward1>)
//E(man) 和E(woman)-E(queen)+E(king)的相似度
tensor([0.3906], device='cuda:0', dtype=torch.bfloat16, grad_fn=<SumBackward1>)
___________________________________
fake word2: male+ queen- king 整个embeding矩阵中和这个词最接近的一些词(tensor中是他们的相似度)
tensor([0.6797, 0.5469, 0.3906, 0.3828, 0.3340, 0.3320, 0.3086, 0.3047, 0.2559,
0.2500], device='cuda:0', dtype=torch.bfloat16,
grad_fn=<TopkBackward0>)
[' male', ' queen', ' female', ' Male', ' males', 'Male', ' Queen', 'male', ' queens', ' Female']
___________________________________
word1: male
tensor([1.0000, 0.5430, 0.5430, 0.4824, 0.4785, 0.4121, 0.3379, 0.3164, 0.2676,
0.2598], device='cuda:0', dtype=torch.bfloat16,
grad_fn=<TopkBackward0>)
[' male', ' Male', ' female', ' males', 'Male', 'male', ' Female', ' females', 'female', 'Female']
___________________________________
word2: female
tensor([1.0000, 0.5898, 0.5430, 0.4922, 0.4902, 0.4727, 0.3438, 0.3340, 0.3086,
0.3047], device='cuda:0', dtype=torch.bfloat16,
grad_fn=<TopkBackward0>)
[' female', ' Female', ' male', 'Female', ' females', 'female', ' women', 'EMALE', ' woman', ' Male']