前言
InstructBlip可以理解为Blip2的升级版,重点加强了图文对话的能力。
模型结构和Blip2没差别,主要在数据集收集、数据集配比、指令微调等方面下文章。
创新点
- 数据集收集: 将26个公开数据集转换为指令微调格式,并将它们归类到11个任务类别中。使用了其中13个数据集来进行指令微调,另外13个数据集用于zero-shot评估。
- 数据集配比:提出了一种平衡采样策略,以同步不同数据集间的学习进度。
- 模型改进:提出了指令感知的视觉特征提取,能够根据输入文本,提取特定的图像特征。说白了,就是文本不仅输入到LLM,也输入到Q-Former,Q-Former的输出再又给到LLM。
- 评估并开源了一系列InstructBLIP模型,使用了两类大型语言模型:1) FlanT5,一种基于T5 微调得到的encoder-decoder模型;2) Vicuna,一种基于LLaMA微调得到的decoder模型。InstructBLIP模型在广泛的视觉-语言任务上实现了最先进的零样本性能。
具体细节
数据集收集
总共收集了11个任务类别(例如image captioning、visual reasoning等),26个数据集,如下:
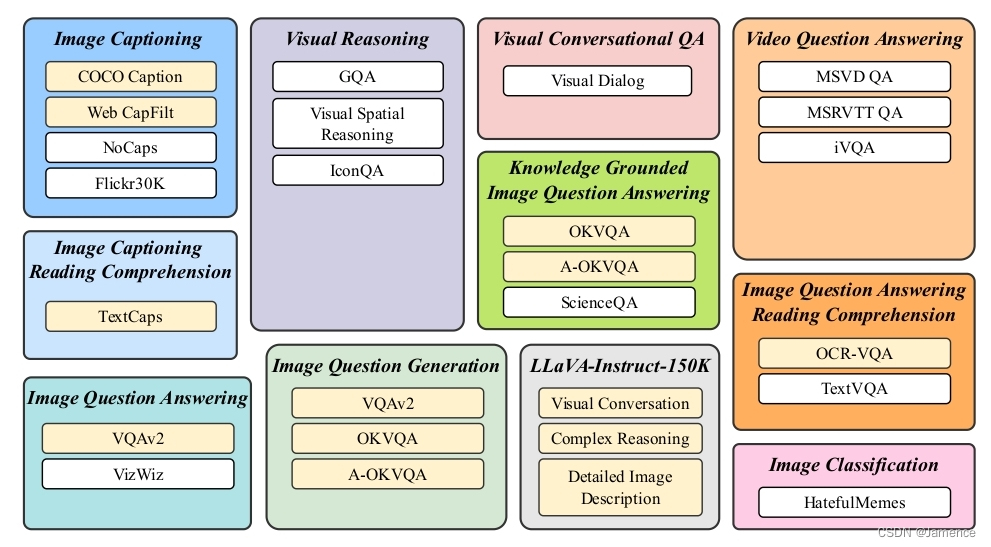
数据集需要转化为图文指令微调的形式,用于多模态大语言模型的训练。
举个例子,在image classification任务中,图片A的类别是狗,数据的组织形式要转换成
问题:图片A,请问图片的类别是什么
回答:类别是狗
针对不同的任务类型,有多样化模板来进行数据的形式转换,如下:

训练测试数据划分
26个数据集中,13个用于训练,另外13个用于测试
按照对zero-shot影响深浅,评测集分为两类
- 训练集有同一任务的其他数据集
- 训练集无同一任务的其他数据集
数据集配比
因数据集较多,直接均匀分布可能会导致模型对小数据集过拟合,而对大数据集欠拟合。
为了解决这个问题,提出了一种采样策略,即按照数据集大小(或训练样本数)的平方根成比例的概率来选择数据集。
给定D个数据集,其大小分别为{S1, S2, …, SD},从数据集d中选取一个训练样本的概率

模型优化
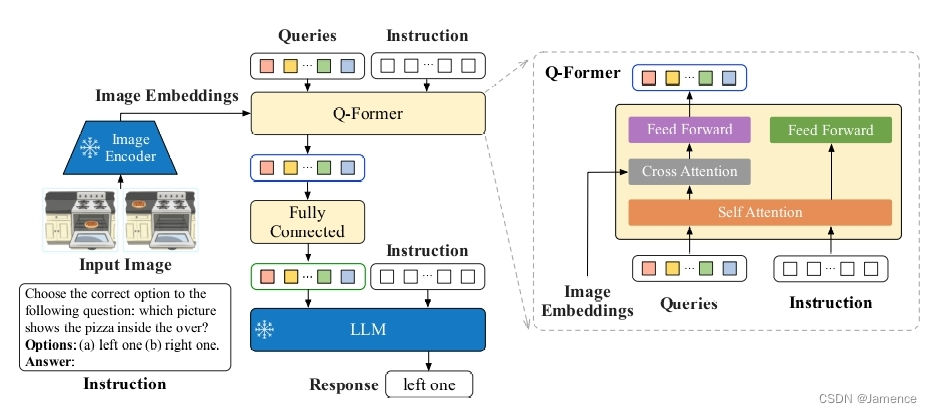
从模型结构上看,和Blip2一模一样。。。
Instruction指用户的问题,有两个输入位置:
- Q-Former:上一篇博客说到,左列输入图像,右列输入文本(Instruction),提取的是多模态特征,相较于Blip2仅输入图像效果肯定是更好的
- LLM:Q-Former的输出、Instruction在embedding层面融合,输入到LLM中
class BertEmbeddings(nn.Module):
"""Construct the embeddings from word and position embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(
config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id
)
self.position_embeddings = nn.Embedding(
config.max_position_embeddings, config.hidden_size
)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer(
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1))
)
self.position_embedding_type = getattr(
config, "position_embedding_type", "absolute"
)
self.config = config
def forward(
self,
input_ids=None,
position_ids=None,
query_embeds=None,
past_key_values_length=0,
):
if input_ids is not None:
seq_length = input_ids.size()[1]
else:
seq_length = 0
if position_ids is None:
position_ids = self.position_ids[
:, past_key_values_length : seq_length + past_key_values_length
].clone()
if input_ids is not None:
embeddings = self.word_embeddings(input_ids)
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings = embeddings + position_embeddings
if query_embeds is not None:
embeddings = torch.cat((query_embeds, embeddings), dim=1)
else:
embeddings = query_embeds
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
可以看到
if query_embeds is not None:
embeddings = torch.cat((query_embeds, embeddings), dim=1)
作者重写了bert embedding层的代码,将query_embeds(可理解为Q-Former的输出)和embeddings(可理解为Instruction的文本embedding) concat起来
推理策略
对于不同的任务类别,采用不同的推理策略
- 对于绝大部分任务,例如image captioning以及开放域VQA任务,采用传统的transformer解码方式生成回答
- 对于classification或multi-choice VQA这种回复内容受限的任务,生成时限制解码的词表,保证回复范围不超过规定范围。(例如多选任务里,回答只能约束在A B C D四个选项)
实验结果
zero-shot对比
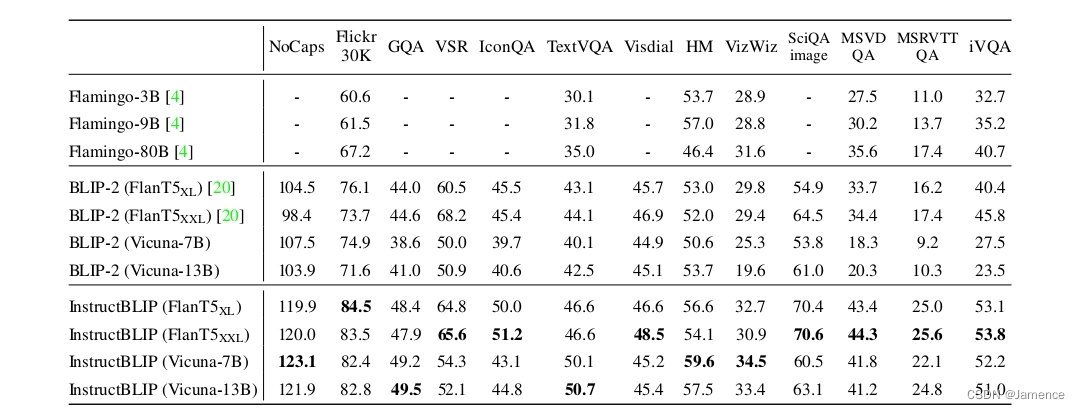
从图标上看,效果确实比Blip2,flamingo要好。不过InstructBlip在Blip2的基础上加了这么多数据训练,效果没道理差。
消融实验
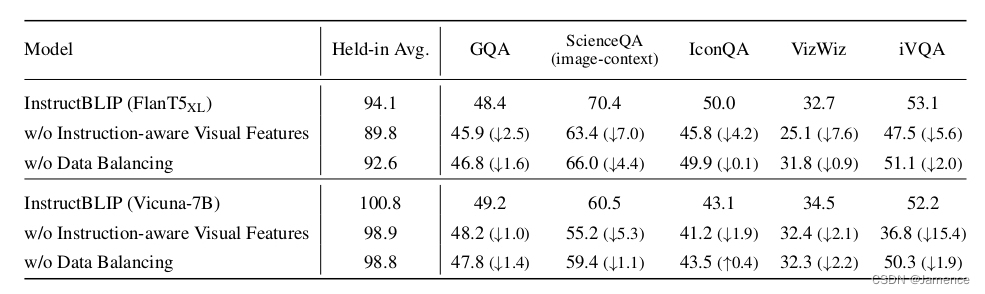
不把instruction送到Q-Former,效果确实差了很多
同时,不做数据配比,效果也差了一些
指令微调 VS 多任务学习
指令微调在实现的时候,利用了13个数据集来训练。一个比较类似的算法是多任务学习,也能够实现多个数据集的学习。
为比较效果,做了如下多任务学习实验:
- 训练用原任务input-output数据,测试用InstructBlip指令
- 训练在input前添加数据集名称,测试用InstructBlip指令
- 训练在input前添加数据集名称,测试在input前添加数据集名称
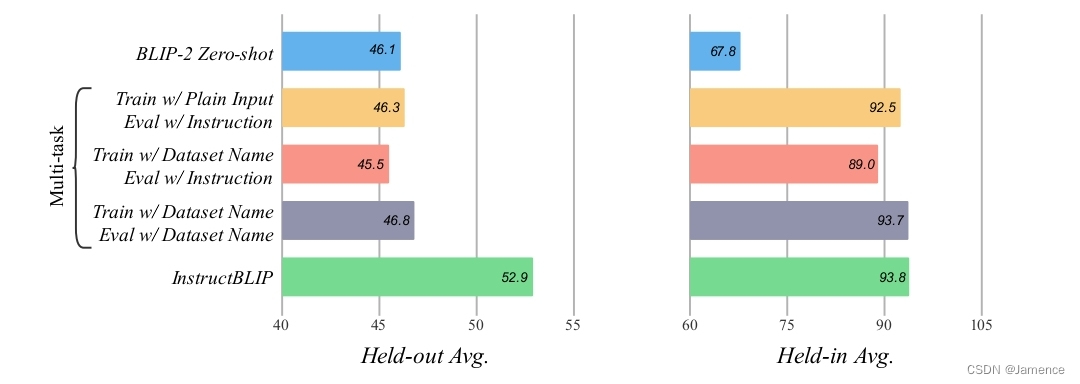
有两个观察 - 多任务学习和InstructBlip在held-in 数据集上,效果差不多。held-in数据可以理解为训练和测试均来自同一数据集,说明
- InstructBlip在held-out数据集上远优于多任务学习,held-out数据集指模型在训练时没见过这个数据集,直接跨数据集。
笔者会持续关注多模态大语言模型(MLLM),对底层原理、经典论文、开源代码都会进行详细解读,欢迎交流学习。
标签:模态,embeddings,config,self,ids,MLLM,InstructBlip,position,数据 From: https://blog.csdn.net/Jamence/article/details/142753938