
OpenAI推出了o1,这是一种通过强化学习训练的大型语言模型,专门用于进行复杂的推理任务。o1在回答问题之前会“思考”,能够在响应用户之前生成一条长的内部思维链。
在编程竞赛问题(Codeforces)中,OpenAI o1的排名在89%分位,位列美国数学奥林匹克预选赛(AIME)前500名学生之列,并且在物理、生物和化学问题的基准测试(GPQA)中超越了博士级别的准确率。尽管OpenAI仍在努力使这个新模型像当前模型一样易于使用,但已经发布了该模型的早期版本,即OpenAI o1-preview,供ChatGPT和可信API用户立即使用。
OpenAI使用的大规模强化学习算法教会了模型如何高效地利用其思维链进行推理。研究发现,o1的表现随着更多的强化学习(训练时计算量)和更多的思考时间(测试时计算量)而不断提高。OpenAI仍在继续研究这种方法的扩展限制,因为它与传统LLM的预训练方法有着显著的不同。

评估
为了突出与GPT-4o相比的推理能力提升,OpenAI在一系列人类考试和机器学习基准测试上对o1进行了测试。结果显示,o1在绝大多数以推理为主的任务上显著超越了GPT-4o。除非特别说明,OpenAI均在最大测试时间计算设置下评估了o1。


o1在复杂的推理基准测试中大幅领先于GPT-4o。在许多推理为主的基准测试中,o1的表现可媲美人类专家。对于一些如MATH和GSM8K的前沿模型表现如此优异,以至于这些基准测试已无法有效区分不同模型的能力。因此,OpenAI在AIME(美国数学竞赛)上对数学能力进行了评估,该竞赛专为挑战美国最优秀的高中生而设计。2024年AIME考试中,GPT-4o平均只能解出12%(1.8/15)的题目,而o1的平均解题率达74%(11.1/15),共识解(64个样本)解题率为83%(12.5/15),经过1,000个样本重新排序后的解题率为93%(13.9/15),这一分数将o1排在美国前500名学生之列,并超过了美国数学奥林匹克的入围线。
OpenAI还在GPQA钻石基准测试上对o1进行了评估,该测试旨在检验化学、物理和生物学领域的专业知识。为了将模型与人类专家进行比较,OpenAI招募了拥有博士学位的专家来解答GPQA钻石问题。结果表明,o1超越了这些人类专家的表现,成为首个在该基准测试上胜过人类的模型。这并不意味着o1在所有方面都比博士更胜一筹,只是表明该模型在解决某些博士级问题上表现得更为出色。o1在许多其他机器学习基准测试上也超越了现有的最先进模型。开启视觉感知功能后,o1在MMMU测试中的得分达到了78.2%,成为首个在该测试中与人类专家竞争的模型。o1还在57个MMLU子类别中的54个超越了GPT-4o。
思维链
类似于人类在回答复杂问题前会进行深思熟虑,o1在试图解决问题时也会利用思维链。通过强化学习,o1学会了完善其思维链,并优化解决问题的策略。它学会识别并纠正错误,学会将复杂的步骤拆分为更简单的步骤,学会在当前方法无效时尝试其他方法。这一过程极大地提升了模型的推理能力。为了展示这一重大进步,OpenAI展示了o1-preview在几个复杂问题上的思维链。
编程能力
OpenAI训练了一种模型,该模型在2024年国际信息学奥林匹克竞赛(IOI)中获得213分,位列第49%分位。这个模型是以o1为基础,并通过进一步训练其编程技能而发展出来的。在与人类参赛者相同的条件下,该模型在10小时内解决了6道复杂的算法问题,并允许每个问题提交50次。模型通过大量候选提交,并根据测试时的选择策略提交了50次。如果OpenAI随机提交,平均得分仅为156分,而该策略的应用使得得分提高了近60分。
当放宽提交限制时,OpenAI发现模型表现显著提高。在每个问题允许提交10,000次的情况下,即使没有任何测试时选择策略,该模型的得分达到了362.14分,超出了金牌门槛。
最后,OpenAI模拟了由Codeforces主办的编程竞赛,展示了该模型的编程技巧。OpenAI的评估严格遵循比赛规则,并允许提交10次。GPT-4o的Elo评分为808,处于人类参赛者的第11%分位。o1则远远超过了GPT-4o和o1-preview,达到了1807的Elo评分,超过了93%的参赛者。

人类偏好评估
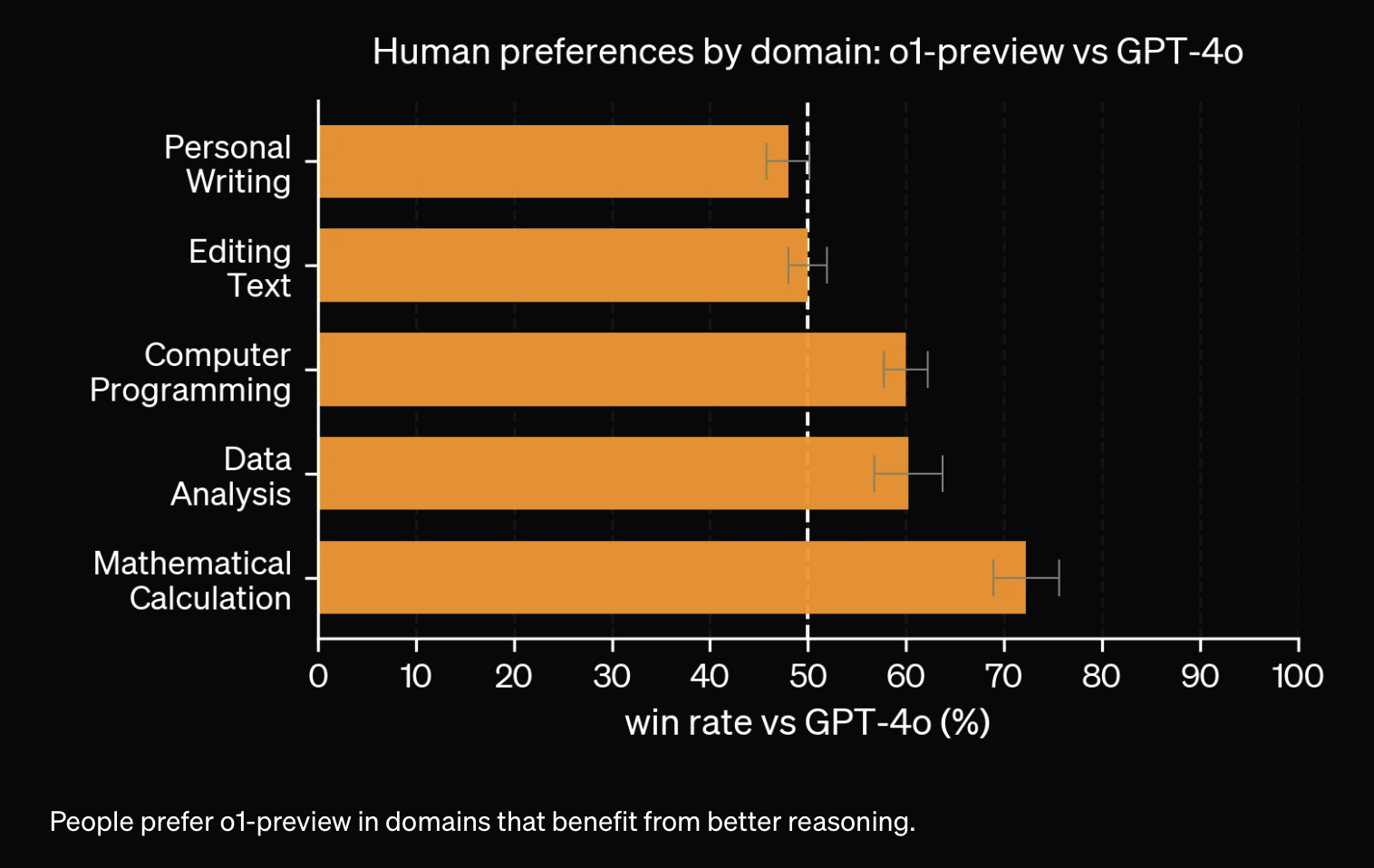
除了考试和学术基准测试,OpenAI还评估了人类对o1-preview和GPT-4o在挑战性开放性问题上的偏好。在这项评估中,人工训练师会看到o1-preview和GPT-4o的匿名响应,并投票选择他们更喜欢的回答。在推理密集型领域,如数据分析、编程和数学,o1-preview的表现大幅领先于GPT-4o。然而,在某些自然语言任务中,o1-preview的表现不如GPT-4o,这表明它并不适合所有用例。
安全性
思维链推理为模型对齐和安全提供了新的机会。OpenAI发现将模型行为的政策融入推理模型的思维链中,是一种有效传授人类价值观和原则的方法。通过教导模型安全规则并让其在上下文中推理这些规则,OpenAI发现推理能力能够直接增强模型的稳健性:o1-preview在关键的越狱测试和最难的内部安全评估中表现显著提升。OpenAI相信,思维链推理在安全性和对齐方面带来了显著进展,因为(1)它使得观察模型的思维过程变得更容易,(2)模型在思考安全规则时,能够更好地应对分布外的场景。
为了检验这些改进,OpenAI在部署前进行了全面的安全测试和红队测试,并遵循了OpenAI的准备框架。研究发现,思维链推理对提升模型能力评估起到了重要作用。特别值得注意的是,OpenAI在测试中观察到了一些有趣的奖励滥用现象。详细结果可以在随附的系统卡中找到。
隐藏的思维链
OpenAI认为,隐藏的思维链为监控模型提供了独特的机会。假设思维链是可信且易读的,隐藏的思维链允许OpenAI“读取”模型的思维过程,理解它的推理过程。例如,将来可能希望通过监控思维链来识别模型是否在操纵用户。然而,为了使这一方法有效,模型必须拥有自由表达其思维的能力,因此OpenAI不能将任何政策合规性或用户偏好训练到思维链中。同时,OpenAI也不希望将未对齐的思维链直接展示给用户。
因此,经过多方面的权衡,包括用户体验、竞争优势以及追求思维链监控的选项,OpenAI决定不向用户展示原始的思维链。OpenAI认识到这一决定有其劣势,但会通过让模型在答案中重现思维链中的有用想法来部分弥补这一缺陷。对于o1系列模型,OpenAI展示了由模型生成的思维链摘要。
结论
o1显著推动了AI推理能力的前沿发展。OpenAI计划继续迭代并发布改进版本,期待这些新的推理能力将进一步提高模型与人类价值观和原则的对齐程度。OpenAI相信o1及其后继者将为科学、编程、数学及相关领域的AI应用开辟新的可能性,并期待用户和API开发者发现它如何改进日常工作。
标签:思维,LLMs,模型,OpenAI,测试,推理,o1 From: https://blog.51cto.com/u_15863876/12087939本文由博客一文多发平台 OpenWrite 发布!