RAG OVERVIEW
https://opendatascience.com/getting-started-with-multimodal-retrieval-augmented-generation/
What is RAG?
RAG is an architectural framework for LLM-powered applications which consists of two main steps:
- Retrieval. In this stage, the system has the task of retrieving from the provided knowledge base the context that is the most similar to the user’s query. This step involves the concept of embedding.
Definition
Embedding is a process of transforming data into numerical vectors and it is used to represent text, images, audio, or other complex data types in a multi-dimensional space that preserves the semantic similarity and relevance of the original data. This means that, for example, the embeddings representing two words or concepts that are semantically similar, will be mathematically close within the multi-dimensional space.
Embedding is essential for generative AI and RAG (retrieval-augmented generation) because it allows the models to access and compare external knowledge sources with the user input and generate more accurate and reliable outputs.
The process involves the embedding of the user’s query and the retrieval of those words or sentences that are represented by vectors that are mathematical to the query’s vector.
- Augmented Generation. Once the relevant set of words, sentences or documents is retrieved, it becomes the context from which the LLM generates the response. It is augmented in the sense that the context is not simply “copied-pasted” and presented to the user as it is, but it is rather passed to the LLM as context and used to produce an AI-generated answer.

RAG能解决大模型的什么问题?不能解决什么问题?
RAG(Retrieval Augmented Generation,检索增强生成)技术在大模型领域主要解决了一些关键问题,同时也存在一些其无法直接解决的问题。以下是对这两方面的详细分析:
RAG能解决大模型的什么问题?
- 提高答案的准确性和相关性:
- RAG通过将检索组件与生成组件相结合,利用检索到的知识来辅助答案的生成,从而提高了响应的准确性和相关性。这种方法有效地解决了大模型在回答时可能出现的“幻觉”问题,即模型编造出不存在于上下文中的答案。
- 增强模型的泛化能力:
- 通过引入外部知识源,RAG使得大模型能够处理更广泛的问题,而不仅仅是依赖于模型内部存储的知识。这有助于提升模型在未知或罕见问题上的表现。
- 适应不同领域和任务:
- RAG允许根据不同领域和任务的需求,动态地检索和注入相关的知识,从而提高了模型在不同场景下的适应性和灵活性。
- 优化长输入长输出问题:
- 在处理长输入和长输出问题时,RAG可以通过检索和整合相关知识,减轻大模型的负担,提高处理效率和性能。
- 提升模型的透明度和可控性:
- 通过优化提示词和引入元数据过滤等方法,RAG可以增强模型的透明度和可控性,使用户能够更清楚地了解模型的决策过程和工作原理。
RAG不能解决大模型的什么问题?
- 数据质量和标注问题:
- RAG虽然可以利用外部知识源来提高答案的准确性和相关性,但前提是这些数据必须是高质量且准确的。然而,高质量的数据往往难以获取且标注成本高昂,这是RAG无法直接解决的问题。
- 模型可解释性问题:
- 尽管RAG可以通过可视化工具等方式提高模型的可解释性,但大模型本身的复杂性和黑盒特性仍然限制了其可解释性的提升。RAG无法从根本上解决这一问题。
- 隐私和安全问题:
- 在使用RAG技术时,需要处理大量的用户数据,这可能导致隐私泄露和安全问题。虽然可以采取差分隐私等技术来保护用户隐私,但这些问题仍然需要额外的注意和努力来解决。
- 所有类型的幻觉问题:
- RAG虽然可以有效地解决一些由模型内部知识不足引起的幻觉问题,但对于由训练数据中的错误或偏见信息引起的幻觉问题,RAG的解决能力有限。这需要更全面的数据清洗和预处理工作来配合解决。
- 极端复杂和新颖的问题:
- 对于一些极端复杂或新颖的问题,即使引入了外部知识源,大模型也可能无法给出满意的答案。这需要更高级别的推理能力和知识整合能力来支持。
综上所述,RAG技术在大模型领域具有显著的优势和潜力,但也存在一些无法直接解决的问题。在实际应用中,需要根据具体需求和场景来选择合适的方法和策略来优化和提升大模型的性能。
机器学习中的判别式模型和生成式模型
https://zhuanlan.zhihu.com/p/74586507
RAG的能力增强生成。
判别式模型和生成式模型的对比图
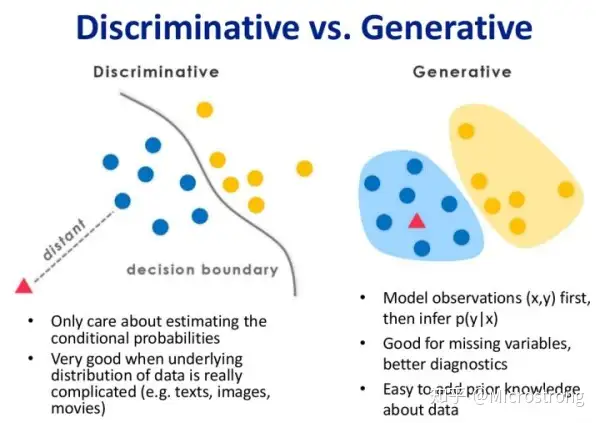
上图左边为判别式模型而右边为生成式模型,可以很清晰地看到差别,判别式模型是在寻找一个决策边界
,通过该边界来将样本划分到对应类别。而生成式模型则不同,它学习了每个类别的边界,它包含了更多信息,可以用来生成样本。
multimodal RAG
Introducing Multimodality
Multimodality refers to the integration of information from different modalities (e.g., text, images, audio). Introducing multimodality in RAG further enriches the model’s capabilities:
- Text-Image Fusion: Combining textual context with relevant images allows RAG to provide more comprehensive and context-aware responses. For instance, a medical diagnosis system could benefit from both textual descriptions and relevant medical images.
- Cross-Modal Retrieval: RAG can retrieve information from diverse sources, including text, images, and videos. Cross-modal retrieval enables a deeper understanding of complex topics by leveraging multiple types of data.
- Domain-Specific Knowledge: Multimodal RAG can integrate domain-specific information from various sources. For example, a travel recommendation system could consider both textual descriptions and user-generated photos to suggest personalized destinations.
Multimodal RAG (MM-RAG) follows the same pattern as the “monomodal” RAG described in the previous section, with the difference that we can interact with the model in multiple ways, plus the indexed knowledge base can also be in different data formats. The idea behind this pattern is to create a shared embedding space, where data in different modalities can be represented with vectors in the same multidimensional space. Also in this case, the idea is that similar data will be represented by vectors that are close to each other.
Once our knowledge base is properly embedded, we can store it in a multimodal VectorDB and use it to retrieve relevant context given the user’s query (which can be multimodal as well):
Building a MM-RAG application with CLIP and GPT-4-vision
Now let’s see how to practically build an MM-RAG application. The idea is to build a conversational application that can receive as input both text and images, as well as retrieve relevant information from a PDF that contains text and images. Henceforth, in this scenario, multimodality refers to “text + images” data. The goal is to create a shared embedding space where both images and text have their vector representation.
Let’s break down the architecture into its main steps.
Embedding the multimodal knowledge base
To embed our images, there are two main options we can follow:
1. Using an LMM such as the GPT-4-vision to first get a rich captioning of the image. Then, use a text embedding model such as the text-ada-002 to embed that caption.
2. Using a model that is capable of directly embedding images without intermediate steps. For example, we can use a Vision Transformer for this purpose.
Definition
The Vision Transformer (ViT) emerged as an alternative to Convolutional Neural Networks (CNNs). Like LLMs, ViT employs a core architecture consisting of an encoder and decoder. In ViT, the central mechanism is Attention, which enables the model to selectively focus on specific parts of the input sequence during predictions. By teaching the model to attend to relevant input data while disregarding irrelevant portions, ViT enhances its ability to tackle tasks effectively.
What sets attention in Transformers apart is its departure from traditional techniques like recurrence (commonly used in Recurrent Neural Networks or RNNs) and convolutions. Unlike previous models, the Transformer relies solely on attention to compute representations of both input and output. This unique approach allows the Transformer to capture a broader range of relationships between words in a sentence, resulting in a more nuanced representation of the input.
An example of this type of model is CLIP, a ViT developed by OpenAI that can learn visual concepts from natural language supervision. It can perform various image classification tasks by simply providing the names of the visual categories in natural language, without any fine-tuning or labeled data. CLIP achieves this by learning a joint embedding space of images and texts, where images and texts that are semantically related are close to each other. The model was trained on a large-scale dataset of (image, text) pairs collected from the internet.
Once you’ve got your embedding, you will need to store them somewhere, likely a Vector DB.
Retrieving relevant context
For a fully multimodal experience, we want our application to be able not only to retrieve both text and images but also to receive both as input. This means that users can enjoy a multimodal experience, explaining concepts with both written and visual inputs.
To achieve this result, we will need an LMM to process the user’s input. The idea is that, given a user’s input (text + image), the LMM will reason over it and produce images’ description which is also in line with the whole context provided by the user. Then, once the text + images’ descriptions are obtained, a text embedding model will create the vectors that will be compared with those of the knowledge base.
Once gathered the relevant context (text + images) from the knowledge base, it will be used as input for the LMM to reason over it, in order to produce the generative answer. Note that the generative answer will contain references to both text and image sources.
Conclusion
In the ever-expanding landscape of artificial intelligence, Multimodal Retrieval-Augmented Generation emerges as a beacon of promise. This fusion of Large Multimodal Models and external multimodal knowledge sources opens up exciting avenues for research, applications, and societal impact.
In the next few years, we anticipate MM-RAG to evolve into an indispensable tool for content creation, education, and problem-solving, just like “only-text” RAG has started to become indispensable over the last year. In other words, it will enable more effective communication between AI systems and humans.
If you are interested in learning more about MM-RAG and how to build multimodal applications with Python and




用例
https://raga.ai/blogs/rag-use-cases-impact
Practical Use Cases of RAG (Retrieval-Augmented Generation)
Document Question Answering Systems: Enhancing Access to Proprietary Documents
Envisage having an enormous base of proprietary documents and requiring precise details from them swiftly. Document Question Answering System, powered by RAG, can transform this process. By asking queries in natural language, you can promptly recover specific responses from your documents, saving time and enhancing effectiveness.
Conversational Agents: Customizing LLMs to Specific Guidelines or Manuals
Conversational agents can become even more efficient when customized to precise instructions or manuals. With RAG, you can tailor language models to adhere to concrete conventions and industry standards. This ensures that the AI interacts with precision while complying with specific needs.
Real-time Event Commentary with Live Data and LLMs
For live events, giving real-time commentary is critical. RAG can connect language models to live data feeds, permitting you to produce up-to-minute reports that improve the virtual experience. Whether it’s a sports game, a meeting, or a breaking news story, RAG keeps your audience engaged with the newest updates.
Content Generation: Personalizing Content and Ensuring Contextual Relevance
Generating customized content that reverberates with your audience can be challenging. RAG helps by using real-time data to create content that is not only pertinent but also gradually customized. This ensures that your readers find your content appealing and valuable, elevating your content’s efficiency.
Personalized Recommendation: Evolving Content Recommendations through LLMs
RAG can revolutionize how you provide customized suggestions. By incorporating retrieval mechanisms and language models, you can offer suggestions that develop based on user interactions and choices. This dynamic approach ensures that your suggestions remain pertinent and customized over time.
Virtual Assistants: Creating More Personalized User Experiences
Virtual Assistants equipped with RAG abilities can provide gradually customized user experiences. They can recover pertinent details and produce answers that serve specifically to the user’s requirement and context. This makes interactions more relevant and improves user contentment.
Customer Support Chatbots: Providing Up-to-date and Accurate Responses
Customer support chatbots need to deliver precise and prompt responses. With RAG, your chatbots can attain the most latest information, ensuring they give dependable and up-to-date details. This enhances customer service standards and decreases answering duration.
Business Intelligence and Analysis: Delivering Domain-specific, Relevant Insights
In the scenario of Business Intelligence, RAG can be a groundbreaker. By delivering domain-specific perceptions, RAG enables you to make informed decisions based on the newest and most pertinent information. This improves your inquisitive abilities and helps you stay ahead in your industry.
Healthcare Information Systems: Accessing Medical Research and Patient Data for Better Care
Healthcare professionals can take advantage of RAG by attaining medical investigation and patient records efficiently. RAG permits for swift recovery of relevant details, helping in better curing and treatment plans, eventually enhancing patient care.
Legal Research and Compliance: Assisting in the Analysis of Legal Documents and Regulatory Compliance
Legitimate professionals can use RAG to sleek the inspection of legitimate documents and ensure regulatory compliance. By recovering and producing pertinent legitimate data, RAG helps in comprehensive investigation and compliance checks, making legitimate processes more effective and precise.
And that's not all—RAG's utility is expanding into even more advanced, specialized areas. Check out some next-level use cases.
Advanced RAG Use Cases
Gaining Insights from Sales Rep Feedback
Imagine turning your sales representative’ remarks into gold mines of applicable insights. You can use Retrieval-Augmented Generation (RAG) to dissect sales feedback. By involuntarily classifying and amalgamating responses, you can pinpoint trends, common problems and opportunities.
This permits you to cautiously acknowledge concerns, customize your approach to customer requirements, and eventually drive better customer success results. It’s like having a 24/7 annotator that turns every piece of response into planned insights.
Medical Insights Miner: Enhancing Research with Real-Time PubMed Data
Stay ahead in medical investigation by pounding into real-time information from PubMed using RAG. This tool permits you to constantly observe and extract pertinent research discoveries, keeping you updated with the newest evolutions.
By incorporating these perceptions into your research process, you can improve the quality and promptness of your studies. This approach boosts discovery, helps in pinpointing emerging trends, and ensures that your work stays at the cutting edge of medical science.
L1/L2 Customer Support Assistant: Improving Customer Support Experiences
Elevate your customer support experience by using RAG to assist your L1 and L2 support teams. This tool can rapidly recover and present pertinent solutions from a wide knowledge base, ensuring that your support agents always have the correct data at their fingertips. By doing so, you can decrease response duration, increase solution rates, and improve overall customer contentment. It’s like giving your support team a significant support that never sleeps and always has the answers.
Compliance in Customer Contact Centers: Ensuring Behavior Analysis in Regulated Industries
Ensure your customer centers follow regulatory requirements using RAG. This tool can dissect interactions for compliance, discerning any divergence required conventions.
By giving real-time responses and recommendations, you can acknowledge problems instantly, ensuring that your functioning remains within the bounds of industry regulations. This proactive approach not only helps in sustaining compliance but also builds trust with your customers and investors.
Employee Knowledge Training Assessment: Enhancing Training Effectiveness Across Roles
Revolutionize your employee training programs with RAG. By inspecting training materials and employee responses, you can pinpoint gaps in knowledge and areas for enhancement.
This tool helps in customizing training sessions to acknowledge precise requirements, ensuring that employees across all roles receive the most efficient and pertinent training. By constantly evaluating and processing your training programs, you can elevate workflow, improve expertise, and ensure that your employees are always prepared to meet new challenges.
Global SOP Standardization: Analyzing and Improving Standard Operating Procedures
Sleek your worldwide operations by homogenizing your Standard Operating Procedures (SOPs) with RAG. This tool can dissect SOPs from distinct regions, dissect inconsistencies, and recommend enhancements.
By ensuring that all your SOPs are aligned and upgraded, you can improve functioning effectiveness, reduce errors, and ensure congruous quality across your organization. It’s like having a universal process examiner that ensures every process is up to par.
Operations Support Assistant in Manufacturing: Assisting Technical Productivity with Complex Machinery Maintenance
Improve your manufacturing operations with an RAG-powered support assistant. This tool can aid in sustaining intricate machinery by offering real-time troubleshooting and preserving data.
By rapidly recovering and presenting pertinent technical data, you can reduce interruption, enhance workflow, and lengthen the lifespan of your equipment. This approach ensures that your technical workforce always has the details they need to keep your operations running sleekly.
Of course, implementing RAG comes with its own set of best practices and considerations, and we'll explore those next.
https://cloud.baidu.com/article/3326428
实际应用案例
假设我们有一个电商平台,用户想要购买一款特定款式的服装。传统的搜索方式可能只能通过关键词进行模糊匹配,难以精确满足用户需求。而采用多模态RAG技术,用户可以上传一张图片作为查询,系统能够自动检索到与图片中服装款式相似的商品,并生成详细的商品描述和推荐理由。
这种应用不仅提升了用户体验,还大大提高了搜索的准确性和效率。
https://xie.infoq.cn/article/ed917a90d564e2c06dd120247
多模态 RAG
在多模态搜索基础上,OpenSearch 结合文本生成大模型,面向企业知识库、电商导购等场景推出多模态 RAG 能力。用户上传业务数据后,OpenSearch 不仅能智能理解图片中的信息,还会以此作为参考,生成相应对话结果,提供基于企业知识库、商城商品库的 RAG 服务。
标签:RAG,text,模型,问题,images,解决,data,your From: https://www.cnblogs.com/lightsong/p/18423988