作者:京东科技 于飞跃
一、背景
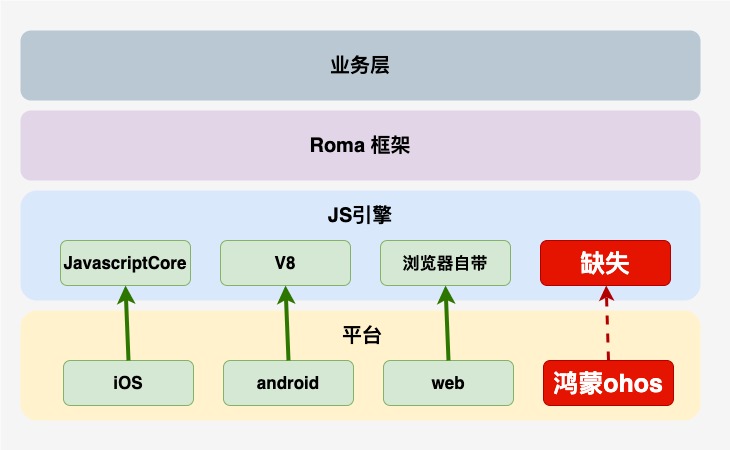
如图所示,Roma框架是我们自主研发的动态化跨平台解决方案,已支持iOS,android,web三端。目前在京东金融APP已经有200+页面,200+乐高楼层使用,为保证基于Roma框架开发的业务可以零成本、无缝运行到鸿蒙系统,需要将Roma框架适配到鸿蒙系统。
Roma框架是基于JS引擎运行的,在iOS系统使用系统内置的JavascriptCore,在Android系统使用V8,然而,鸿蒙系统却没有可以执行Roma框架的JS引擎,因此需要移植一个JS引擎到鸿蒙平台。
二、JS引擎选型
目前主流的JS引擎有以下这些:
| 应用代表 | 公司 | |
|---|---|---|
| V8 | Chrome/Opera/Edge/Node.js/Electron | |
| SpiderMonkey | firefox | Mozilla |
| JavaScriptCore | Safari | Apple |
| Chakra | IE | Microsoft |
| Hermes | React Native | |
| JerryScript/duktape/QuickJS | 小型并且可嵌入的Javascript引擎/主要应用于IOT设备 | - |
其中最流行的是Google开源的V8引擎,除了Chrome等浏览器,Node.js也是用的V8引擎。Chrome的市场占有率高达60%,而Node.js是JS后端编程的事实标准。另外,Electron(桌面应用框架)是基于Node.js与Chromium开发桌面应用,也是基于V8的。国内的众多浏览器,其实也都是基于Chromium浏览器开发,而Chromium相当于开源版本的Chrome,自然也是基于V8引擎的。甚至连浏览器界独树一帜的Microsoft也投靠了Chromium阵营。V8引擎使得JS可以应用在Web、APP、桌面端、服务端以及IOT等各个领域。
三、V8引擎的工作原理
V8的主要任务是执行JavaScript代码,并且能够处理JavaScript源代码、即时编译(JIT)代码以及执行代码。v8是一个非常复杂的项目,有超过100万行C++代码。
下图展示了它的基本工作流程:

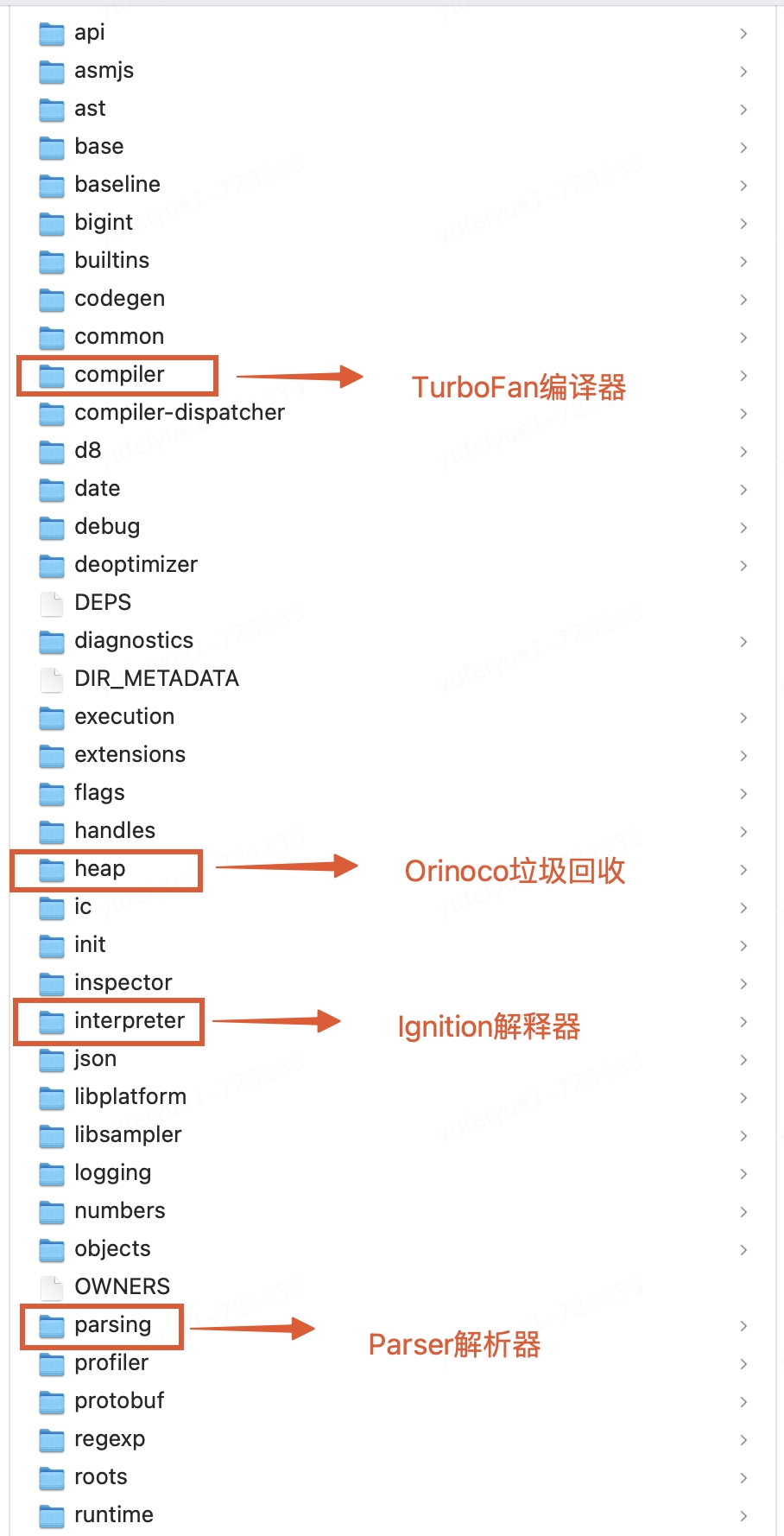
如图所示,它通过词法分析、语法分析、字节码生成与执行、即时编译与机器码生成以及垃圾回收等步骤,实现了对JavaScript源代码的高效执行。此外,V8引擎还通过监控代码的执行情况,对热点函数进行自动优化,从而进一步提高了代码的执行性能。其中 Parser(解析器)、Ignition(解释器)、TurboFan(编译器) 、Orinoco(垃圾回收)是 V8 中四个核心工作模块,对应的V8源码目录如下图。
1、Parser:解析器
负责将JavaScript源码转换为Abstract Syntax Tree (AST)抽象语法树,解析过程分为:词法分析(Lexical Analysis)和语法分析(Syntax Analysis)两个阶段。
1.1、词法分析
V8 引擎首先会扫描所有的源代码,进行词法分析(Tokenizing/Lexing)(词法分析是通过 Scanner 模块来完成的)。也称为分词,是将字符串形式的代码转换为标记(token)序列的过程。这里的token是一个字符串,是构成源代码的最小单位,类似于英语中单词,例如,var a = 2; 经过词法分析得到的tokens如下:
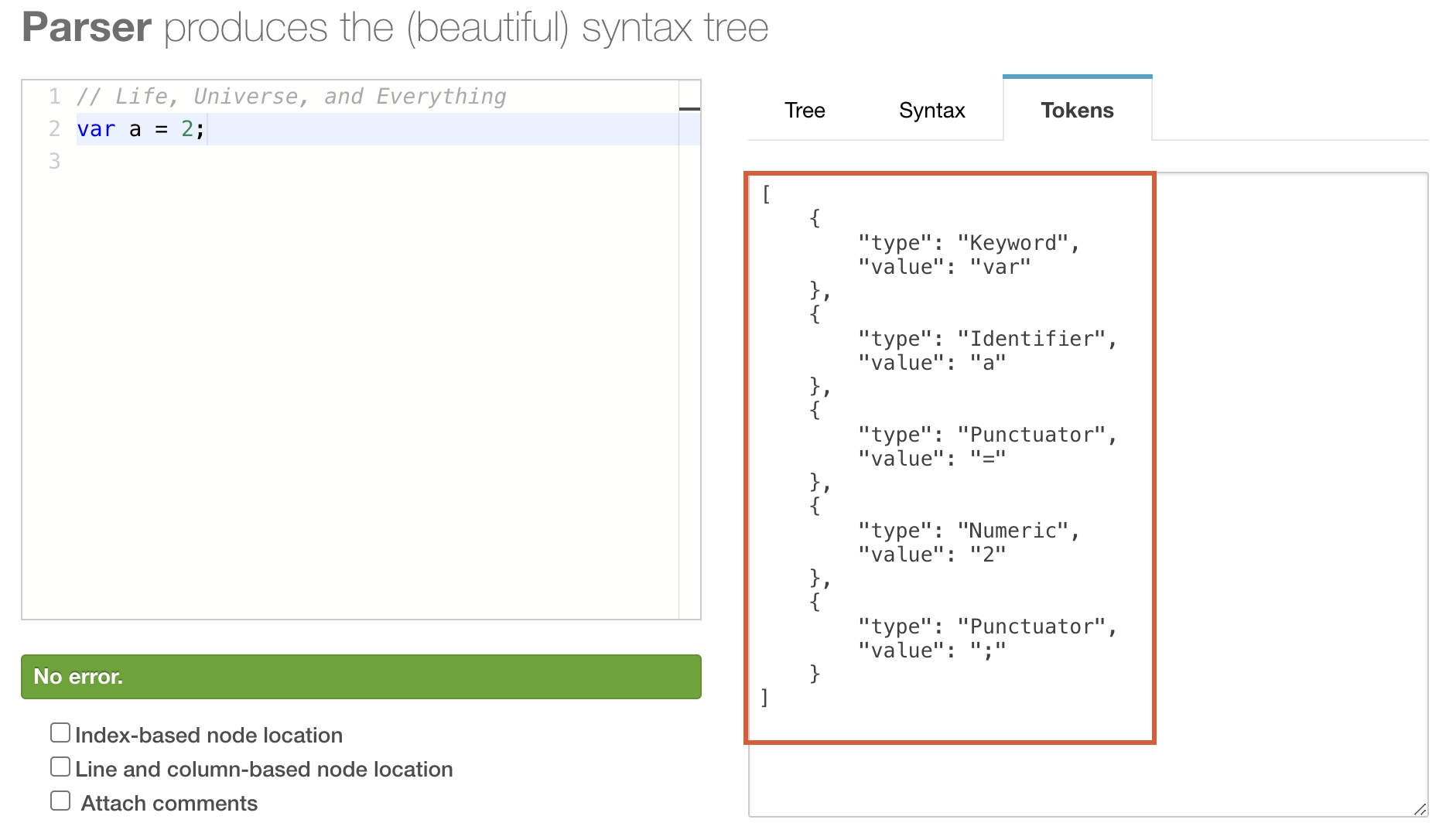
从上图中可以看到,这句代码最终被分解出了五个词法单元:
var 关键字
a 标识符
= 运算符
2 数值
;分号
一个可以在线查看Tokens的网站: https://esprima.org/demo/parse.html
1.2、语法分析
语法分析是将词法分析产生的token按照某种给定的形式文法(这里是JavaScript语言的语法规则)转换成抽象语法树(AST)的过程。也就是把单词组合成句子的过程。这个过程会分析语法错误:遇到错误的语法会抛出异常。AST是源代码的语法结构的树形表示。AST包含了源代码中的所有语法结构信息,但不包含代码的执行逻辑。
例如, var a = 2; 经过语法分析后生成的AST如下:

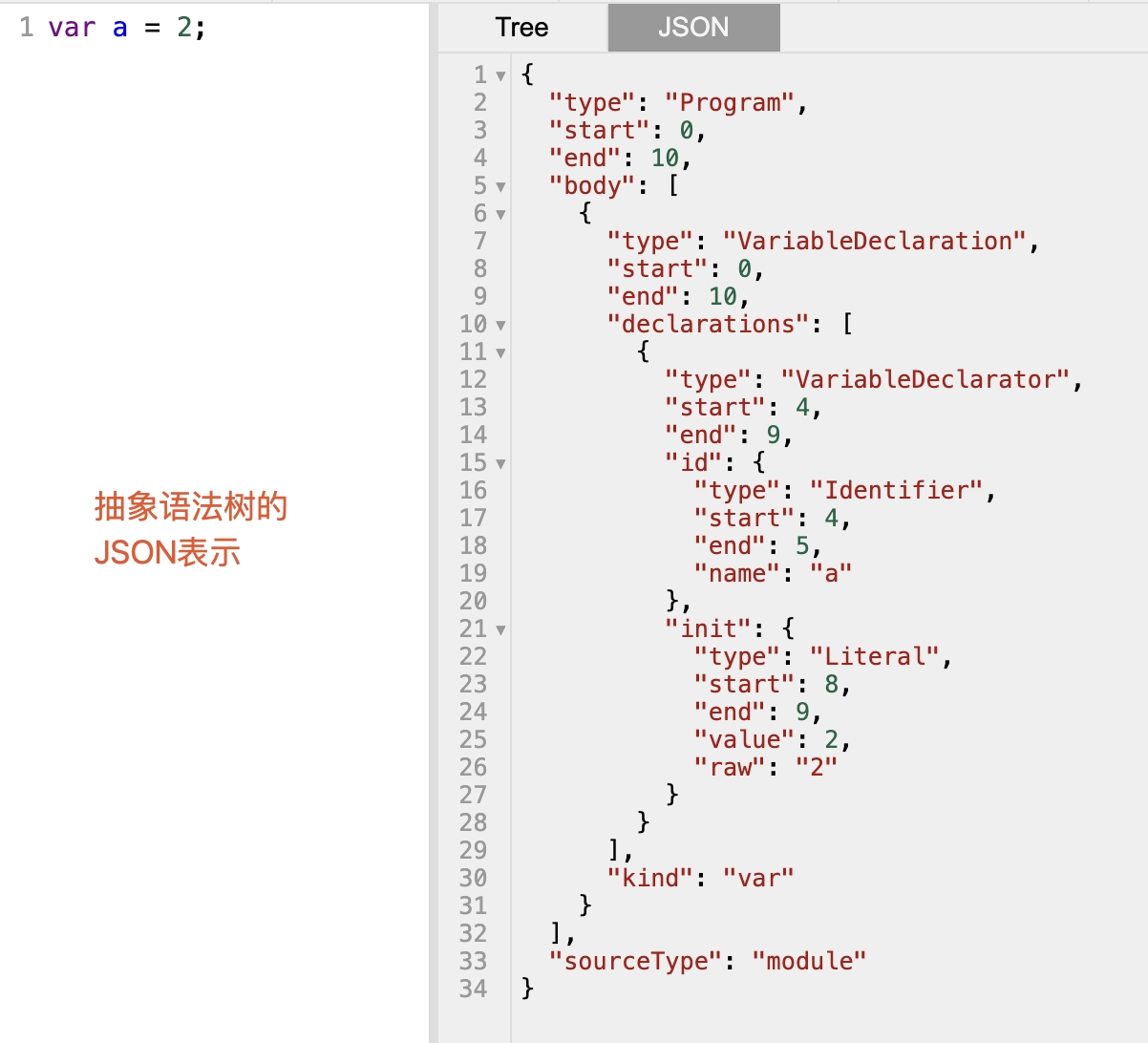
可以看到这段程序的类型是 VariableDeclaration,也就是说这段代码是用来声明变量的。
一个可以在线查看AST结构的网站:https://astexplorer.net/
2、Ignition:(interpreter)解释器
负责将AST转换成字节码(Bytecode)并逐行解释执行字节码,提供快速的启动和较低的内存使用,同时会标记热点代码,收集TurboFan优化编译所需的信息,比如函数参数的类型。
2.1、什么是字节码?
字节码(Bytecode)是一种介于AST和机器码之间的中间表示形式,它比AST更接近机器码,它比机器码更抽象,也更轻量,与特定机器代码无关,需要解释器转译后才能成为机器码。字节码通常不像源码一样可以让人阅读,而是编码后的数值常量、引用、指令等构成的序列。
2.2、字节码的优点
•不针对特定CPU架构 •比原始的高级语言转换成机器语言更快 •字节码比机器码占用内存更小 •利用字节码,可以实现Compile Once,Run anywhere(一次编译到处运行)。早期版本的 V8 ,并没有生成中间字节码的过程,而是将所有源码转换为了机器代码。机器代码虽然执行速度更快,但是占用内存大。
2.3、查看字节码
Node.js是基于V8引擎实现的,因此node命令提供了很多V8引擎的选项,我们可以通过这些选项,查看V8引擎中各个阶段的产物。使用node的--print-bytecode选项,可以打印出Ignition生成的Bytecode。
示例test.js如下
//test.js
function add(a, b){
return a + b;
}
add(1,2); //V8不会编译没有被调用的函数,因此需要在最后一行调用add函数运行下面的node命令,打印出Ignition生成的字节码。
node --print-bytecode test.js
[generated bytecode for function: add (0x29e627015191 <SharedFunctionInfo add>)]
Bytecode length: 6
Parameter count 3
Register count 0
Frame size 0
OSR urgency: 0
Bytecode age: 0
33 S> 0x29e627015bb8 @ 0 : 0b 04 Ldar a1
41 E> 0x29e627015bba @ 2 : 39 03 00 Add a0, [0]
44 S> 0x29e627015bbd @ 5 : a9 Return
Constant pool (size = 0)
Handler Table (size = 0)
Source Position Table (size = 8)
0x29e627015bc1 <ByteArray[8]>控制台输出的内容非常多,最后一部分是add函数的Bytecode。
字节码的详细信息如下:
•[generated bytecode for function: add (0x29e627015191 <SharedFunctionInfo add>)]: 这行告诉我们,接下来的字节码是为 add 函数生成的。0x29e627015191 是这个函数在内存中的地址。 •Bytecode length: 6: 整个字节码的长度是 6 字节。 •Parameter count 3: 该函数有 3 个参数。包括传入的 a,b 以及 this。 •Register count 0: 该函数没有使用任何寄存器。 •Frame size 0: 该函数的帧大小是 0。帧大小是指在调用栈上分配给这个函数的空间大小,用于存储局部变量、函数参数等。 •OSR urgency: 0: On-Stack Replacement(OSR)优化的紧急程度是 0。OSR 是一种在运行时将解释执行的函数替换为编译执行的函数的技术,用于提高性能。 •Bytecode age: 0: 字节码的年龄是 0。字节码的年龄是指它被执行的次数,年龄越高,说明这个字节码被执行的越频繁,可能会被 V8 引擎优化。 •Ldar a1 表示将寄存器中的值加载到累加器中 ,这行是字节码的第一条指令 •Add a0, [0] 从 a0 寄存器加载值并且将其与累加器中的值相加,然后将结果再次放入累加器 。 •Return 结束当前函数的执行,并把控制权传给调用方,将累加器中的值作为返回值 •S> 表示这是一个“Safepoint”指令,V8 引擎可以在执行这条指令时进行垃圾回收等操作。 •E> 表示这是一个“Effect”指令,可能会改变程序的状态。 •Constant pool (size = 0): 常量池的大小是 0。常量池是用来存储函数中使用的常量值的。 •Handler Table (size = 0): 异常处理表的大小是 0。异常处理表是用来处理函数中可能出现的异常的。 •Source Position Table (size = 8): 源代码位置表的大小是 8。源代码位置表是用来将字节码指令与源代码行号关联起来的,方便调试。 •0x29e627015bc1 <ByteArray[8]>: 这行是源代码位置表的具体内容,显示了每个字节码指令对应的源代码行号和列号。可以看到,Bytecode某种程度上就是汇编语言,只是它没有对应特定的CPU,或者说它对应的是虚拟的CPU。这样的话,生成Bytecode时简单很多,无需为不同的CPU生产不同的代码。要知道,V8支持9种不同的CPU,引入一个中间层Bytecode,可以简化V8的编译流程,提高可扩展性。如果我们在不同硬件上去生成Bytecode,生成代码的指令是一样的.
3、TurboFan:(compiler)编译器
V8 的优化编译器也是v8实现即时编译(JIT)的核心,负责将热点函数的字节码编译成高效的机器码。
3.1、什么是JIT?
我们需要先了解一下JIT(Just in Time)即时编译。
在运行C、C++以及Java等程序之前,需要进行编译,不能直接执行源码;但对于JavaScript来说,我们可以直接执行源码(比如:node server.js),它是在运行的时候先编译再执行,这种方式被称为即时编译(Just-in-time compilation),简称为JIT。因此,V8也属于JIT编译器。
实现JIT编译器的系统通常会不断地分析正在执行的代码,并确定代码的某些部分,在这些部分中,编译或重新编译所获得的加速将超过编译该代码的开销。 JIT编译是两种传统的机器代码翻译方法——提前编译(AOT)和解释——的结合,它结合了两者的优点和缺点。大致来说,JIT编译将编译代码的速度与解释的灵活性、解释器的开销以及额外的编译开销(而不仅仅是解释)结合起来。
除了V8引擎,Java虚拟机、PHP 8也用到了JIT。
3.2、V8引擎的JIT
V8的JIT编译包括多个阶段,从生成字节码到生成高度优化的机器码,根据JavaScript代码的执行特性动态地优化代码,以实现高性能的JavaScript执行。看下图Ignition 和 TurboFan 的交互:
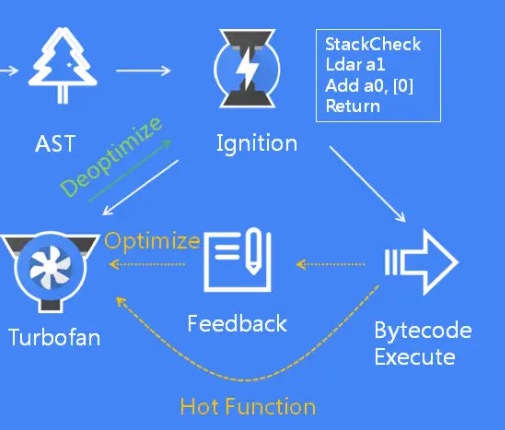
当 Ignition 开始执行 JavaScript 代码后,V8 会一直观察 JavaScript 代码的执行情况,并记录执行信息,如每个函数的执行次数、每次调用函数时,传递的参数类型等。如果一个函数被调用的次数超过了内设的阈值,监视器就会将当前函数标记为热点函数(Hot Function),并将该函数的字节码以及执行的相关信息发送给 TurboFan。TurboFan 会根据执行信息做出一些进一步优化此代码的假设,在假设的基础上将字节码编译为优化的机器代码。如果假设成立,那么当下一次调用该函数时,就会执行优化编译后的机器代码,以提高代码的执行性能。
如果假设不成立,上图中,绿色的线,是“去优化(Deoptimize)”的过程,如果TurboFan生成的优化机器码,对需要执行的代码不适用,会把优化的机器码,重新转换成字节码来执行。这是因为Ignition收集的信息可能是错误的。
例如:
function add(a, b) {
return a + b;
}
add(1, 2);
add(2, 2);
add("1", "2");add函数的参数之前是整数,后来又变成了字符串。生成的优化机器码已经假定add函数的参数是整数,那当然是错误的,于是需要进行去优化,Deoptimize为Bytecode来执行。
TurboFan除了上面基于类型做优化和反优化,还有包括内联(inlining)和逃逸分析(Escape Analysis)等,内联就是将相关联的函数进行合并。例如:
function add(a, b) {
return a + b
}
function foo() {
return add(2, 4)
}内联优化后:
function fooAddInlined() {
var a = 2
var b = 4
var addReturnValue = a + b
return addReturnValue
}
// 因为 fooAddInlined 中 a 和 b 的值都是确定的,所以可以进一步优化
function fooAddInlined() {
return 6
}使用node命令的--print-code以及--print-opt-code选项,可以打印出TurboFan生成的汇编代码。
node --print-code --print-opt-code test.js4、Orinoco:垃圾回收
一个高效的垃圾回收器,用于自动管理内存,回收不再使用的对象内存;它使用多种垃圾回收策略,如分代回收、标记-清除、增量标记等,以实现高效内存管理。
Orinoco的主要特点包括:
•并发标记: Orinoco使用并发标记技术来减少垃圾回收的停顿时间(Pause Time)。这意味着在应用程序继续执行的同时,垃圾回收器可以在后台进行标记操作。 •增量式垃圾回收: Orinoco支持增量式垃圾回收,这允许垃圾回收器在小的时间片内执行部分垃圾回收工作,而不是一次性处理所有的垃圾。 •更高效的内存管理: Orinoco引入了一些新的内存管理策略和数据结构,旨在减少内存碎片和提高内存利用率。 •可扩展性: Orinoco的设计考虑了可扩展性,使得它可以适应不同的工作负载和硬件配置。 •多线程支持: Orinoco支持多线程环境,可以利用多核CPU来加速垃圾回收过程。四、V8移植工具选型
我们的开发环境各式各样可能系统是Mac,Linux或者Windows,架构是x86或者arm,所以要想编译出可以跑在鸿蒙系统上的v8库我们需要使用交叉编译,它是在一个平台上为另一个平台编译代码的过程,允许我们在一个平台上为另一个平台生成可执行文件。这在嵌入式系统开发中尤为常见,因为许多嵌入式设备的硬件资源有限,不适合直接在上面编译代码。 交叉编译需要一个特定的编译器、链接器和库,这些都是为目标平台设计的。此外,开发者还需要确保代码没有平台相关的依赖,否则编译可能会失败。

v8官网上关于交叉编译Android和iOS平台的V8已经有详细的介绍。尚无关于鸿蒙OHOS平台的文档。V8官方使用的构建系统是gn + ninja。gn 是一个元构建系统,最初由 Google 开发,用于生成 Ninja 文件。它提供了一个声明式的方式来定义项目的依赖关系、编译选项和其他构建参数。通过运行 gn gen 命令,可以生成一个 Ninja 文件。类似于camke + make构建系统。
gn + ninja的构建流程如下:

通过查看鸿蒙sdk,我们发现鸿蒙提供给开发者的native构建系统是cmake + ninja,所以我们决定将v8官方采用的gn + ninja转成cmake + ninja。这就需要将gn语法的构建配置文件转成cmake的构建配置文件。
1、CMake简介
CMake是一个开源的、跨平台的构建系统。它不仅可以生成标准的Unix Makefile配合make命令使用,还能够生成build.ninja文件配合ninja使用,还可以为多种IDE生成项目文件,如Visual Studio、Eclipse、Xcode等。这种跨平台性使得CMake在多种操作系统和开发环境中都能够无缝工作。
cmake的构建流程如下:
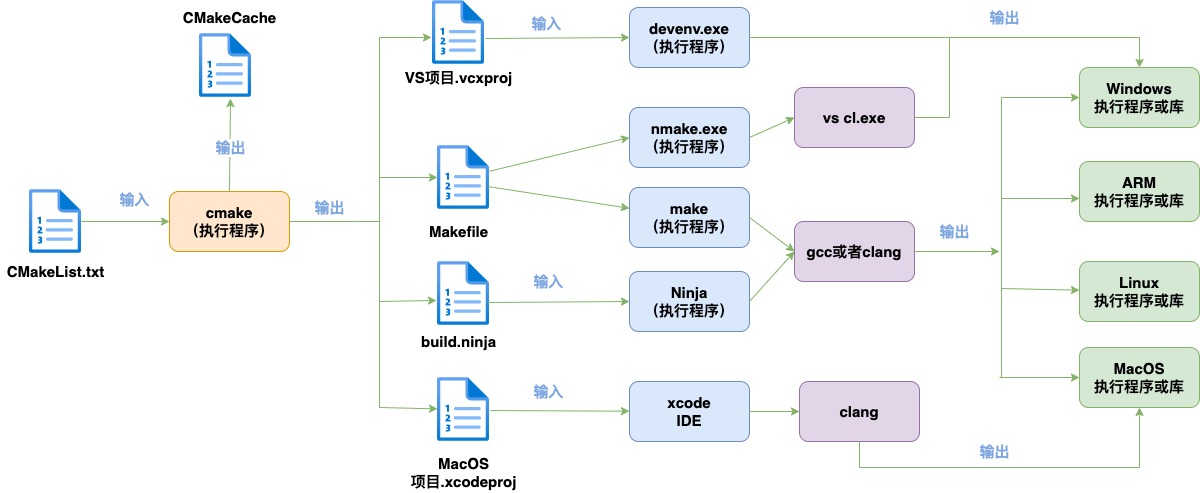
CMake构建主要过程是编写CMakeLists.txt文件,然后用cmake命令将CMakeLists.txt文件转化为make所需要的Makefile文件或者ninja需要的build.ninja文件,最后用make命令或者ninja命令执行编译任务生成可执行程序或共享库(so(shared object))。
完整CMakeLists.txt文件的主要配置样例:
# 1. 声明要求的cmake最低版本
cmake_minimum_required( VERSION 2.8 )
# 2. 添加c++11标准支持
#set( CMAKE_CXX_FLAGS "-std=c++11" )
# 3. 声明一个cmake工程
PROJECT(camke_demo)
MESSAGE(STATUS "Project: SERVER") #打印相关消息
# 4. 头文件
include_directories(
${PROJECT_SOURCE_DIR}/../include/mq
${PROJECT_SOURCE_DIR}/../include/incl
${PROJECT_SOURCE_DIR}/../include/rapidjson
)
# 5. 通过设定SRC变量,将源代码路径都给SRC,如果有多个,可以直接在后面继续添加
set(SRC
${PROJECT_SOURCE_DIR}/../include/incl/tfc_base_config_file.cpp
${PROJECT_SOURCE_DIR}/../include/mq/tfc_ipc_sv.cpp
${PROJECT_SOURCE_DIR}/../include/mq/tfc_net_ipc_mq.cpp
${PROJECT_SOURCE_DIR}/../include/mq/tfc_net_open_mq.cpp
)
# 6. 创建共享库/静态库
# 设置路径(下面生成共享库的路径)
set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${PROJECT_SOURCE_DIR}/lib)
# 即生成的共享库在工程文件夹下的lib文件夹中
set(LIB_NAME camke_demo_lib)
# 创建共享库(把工程内的cpp文件都创建成共享库文件,方便通过头文件来调用)
# 这时候只需要cpp,不需要有主函数
# ${PROJECT_NAME}是生成的库名 表示生成的共享库文件就叫做 lib工程名.so
# 也可以专门写cmakelists来编译一个没有主函数的程序来生成共享库,供其它程序使用
# SHARED为生成动态库,STATIC为生成静态库
add_library(${LIB_NAME} STATIC ${SRC})
# 7. 链接库文件
# 把刚刚生成的${LIB_NAME}库和所需的其它库链接起来
# 如果需要链接其他的动态库,-l后接去除lib前缀和.so后缀的名称,以链接
# libpthread.so 为例,-lpthread
target_link_libraries(${LIB_NAME} pthread dl)
# 8. 编译主函数,生成可执行文件
# 先设置路径
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${PROJECT_SOURCE_DIR}/bin)
# 可执行文件生成
add_executable(${PROJECT_NAME} ${SRC})
# 链接这个可执行文件所需的库
target_link_libraries(${PROJECT_NAME} pthread dl ${LIB_NAME})一般把CMakeLists.txt文件放在工程目录下,使用时先创建一个叫build的文件夹(这个并非必须,因为cmake命令指向CMakeLists.txt所在的目录,例如cmake .. 表示CMakeLists.txt在当前目录的上一级目录。cmake执行后会生成很多编译的中间文件,所以一般建议新建一个新的目录,专门用来编译),通常构建步骤如下:
1.mkdir build
2.cd build
3.cmake .. 或者 cmake -G Ninja ..
4.make 或者 ninja其中cmake .. 在build文件夹下生成Makefile。make命令在Makefile所在的目录下执行,根据Makefile进行编译。
或者cmake -G Ninja .. 在build文件夹下生成build.ninja。ninja命令在build.ninja所在的目录下执行,根据build.ninja进行编译。
2、CMake中的交叉编译设置
配置方式一:
直接在CMakeLists.txt文件中,使用CMAKE_C_COMPILER和CMAKE_CXX_COMPILER这两个变量来指定C和C++的编译器路径。使用CMAKE_LINKER变量来指定项目的链接器。这样,当CMake生成构建文件时,就会使用指定的编译器来编译源代码。使用指定的链接器进行项目的链接操作。
以下是一个简单的设置交叉编译器和链接器的CMakeLists.txt文件示例:
# 指定CMake的最低版本要求
cmake_minimum_required(VERSION 3.10)
# 项目名称
project(CrossCompileExample)
# 设置C编译器和C++编译器
set(CMAKE_C_COMPILER "/path/to/c/compiler")
set(CMAKE_CXX_COMPILER "/path/to/cxx/compiler")
# 设置链接器
set(CMAKE_LINKER "/path/to/linker")
# 添加可执行文件
add_executable(myapp main.cpp)另外我们还可以使用单独工具链文件配置交叉编译环境。
配置方式二:CMake中使用工具链文件配置
工具链文件(toolchain file)是将配置信息提取到一个单独的文件中,以便于在多个项目中复用。包含一系列CMake变量定义,这些变量指定了编译器、链接器和其他工具的位置,以及其他与目标平台相关的设置,以确保它能够正确地为目标平台生成代码。它让我们可以专注于解决实际的问题,而不是每次都要手动配置编译器和工具。
一个基本的工具链文件示例如下:
创建一个名为toolchain.cmake的文件,并在其中定义工具链的路径和设置:
该项目需要为ARM架构的Linux系统进行交叉编译
# 设置C和C++编译器
set(CMAKE_C_COMPILER "/path/to/c/compiler")
set(CMAKE_CXX_COMPILER "/path/to/cxx/compiler")
# 设置链接器
set(CMAKE_LINKER "/path/to/linker")
# 指定目标系统的类型
set(CMAKE_SYSTEM_NAME Linux)
set(CMAKE_SYSTEM_PROCESSOR arm)
# 其他与目标平台相关的设置 # ...在执行cmake命令构建时,使用-DCMAKE_TOOLCHAIN_FILE参数指定工具链文件的路径:
cmake -DCMAKE_TOOLCHAIN_FILE=/path/to/toolchain.cmake /path/to/source这样,CMake就会使用工具链文件中指定的编译器和设置来为目标平台生成代码。
五、V8和常规C++库移植的重大差异
常规C++项目按照上述交叉编译介绍的配置即可完成交叉编译过程,但是V8的移植必须充分理解builtin和snapshot才能完成!一般的库,所谓交叉编译就是调用目标平台指定的工具链直接编译源码生成目标平台的文件。比如一个C文件要给android用,调用ndk包的gcc、clang编译即可。但由于v8的builtin实际用的是v8自己的工具链体系编译成目标平台的代码,所以并不能套用上面的方式。
1、builtin
1.1、builtin是什么
在V8引擎中,builtin即内置函数或模块。V8的内置函数和模块是JavaScript语言的一部分,提供了一些基本的功能,例如数学运算、字符串操作、日期处理等。另外ignition解析器每一条字节码指令实现也是一个builtin。
V8的内置函数和模块是通过C++代码实现的,并在编译时直接集成到V8引擎中。这些内置函数和模块不需要在JavaScript代码中显式地导入或引用,就可以直接使用。
以下是一些V8的内置函数和模块的例子:
•Math对象:提供了各种数学运算的函数,例如Math.sin()、Math.cos()等。 •String对象:提供了字符串操作的函数,例如String.prototype.split()、String.prototype.replace()等。 •Date对象:提供了日期和时间处理的函数,例如Date.now()、Date.parse()等。 •JSON对象:提供了JSON数据的解析和生成的函数,例如JSON.parse()、JSON.stringify()等。 •ArrayBuffer对象:提供了对二进制数据的操作的函数,例如ArrayBuffer.prototype.slice()、ArrayBuffer.prototype.byteLength等。 •WebAssembly模块:提供了对WebAssembly模块的加载和实例化的函数,例如WebAssembly.compile()、WebAssembly.instantiate()等。这些内置函数和模块都是V8引擎的重要组成部分,提供了基础的JavaScript功能。它们是V8运行时最重要的“积木块”;
1.2、builtin是如何生成的
v8源码中builtin的编译比较绕,因为v8中大多数builtin的“源码”,其实是builtin的生成逻辑,这也是理解V8源码的关键。
builtin和snapshot都是通过mksnapshot工具运行生成的。mksnapshot是v8编译过程中的一个中间产物,也就是说v8编译过程中会生成一个mksnapshot可执行程序并且会执行它生成v8后续编译需要的builtin和snapshot,就像套娃一样。
例如v8源码中字节码Ldar指令的实现如下:
IGNITION_HANDLER(Ldar, InterpreterAssembler) {
TNode<Object> value = LoadRegisterAtOperandIndex(0);
SetAccumulator(value);
Dispatch();
}
上述代码只在V8的编译阶段由mksnapshot程序执行,执行后会产出机器码(JIT),然后mksnapshot程序把生成的机器码dump下来放到汇编文件embedded.S里,编译进V8运行时(相当于用JIT编译器去AOT)。
builtin被dump到embedded.S的对应v8源码在v8/src/snapshot/embedded-file-writer.h
void WriteFilePrologue(PlatformEmbeddedFileWriterBase* w) const {
w->Comment("Autogenerated file. Do not edit.");
w->Newline(); w->FilePrologue();
}上述Ldar指令dump到embedded.S后汇编代码如下:
Builtins_LdarHandler:
.def Builtins_LdarHandler; .scl 2; .type 32; .endef;
.octa 0x72ba0b74d93b48fffffff91d8d48,0xec83481c6ae5894855ccffa9104ae800
.octa 0x2454894cf0e4834828ec8348e2894920,0x458948e04d894ce87d894cf065894c20
.octa 0x4d0000494f808b4500001410858b4dd8,0x1640858b49e1894c00000024bac603
.octa 0x4d00000000158d4ccc01740fc4f64000,0x2045c749d0ff206d8949285589
.octa 0xe4834828ec8348e289492024648b4800,0x808b4500001410858b4d202454894cf0
.octa 0x858b49d84d8b48d233c6034d00004953,0x158d4ccc01740fc4f64000001640
.octa 0x2045c749d0ff206d89492855894d0000,0x5d8b48f0658b4c2024648b4800000000
.octa 0x4cf7348b48007d8b48011c74be0f49e0,0x100000000ba49211cb60f43024b8d
.octa 0xa90f4fe800000002ba0b77d33b4c0000,0x8b48006d8b48df0c8b49e87d8b4cccff
.octa 0xcccccccccccccccc90e1ff30c48348c6
.byte 0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc
builtin在v8源代码v8\src\builtins\builtins-definitions.h中定义,这个文件还include一个根据ignition指令生成的builtin列表以及torque编译器生成的builtin定义,一共1700+个builtin。每个builtin,都会在embedded.S中生成一段代码。
builtin生成的v8源代码在:v8\src\builtins\setup-builtins-internal.cc
void SetupIsolateDelegate::SetupBuiltinsInternal(Isolate* isolate) {
Builtins* builtins = isolate->builtins();
DCHECK(!builtins->initialized_);
PopulateWithPlaceholders(isolate);
// Create a scope for the handles in the builtins.
HandleScope scope(isolate);
int index = 0;
Code code;
#define BUILD_CPP(Name) \
code = BuildAdaptor(isolate, Builtin::k##Name, \
FUNCTION_ADDR(Builtin_##Name), #Name); \
AddBuiltin(builtins, Builtin::k##Name, code); \
index++;
#define BUILD_TFJ(Name, Argc, ...) \
code = BuildWithCodeStubAssemblerJS( \
isolate, Builtin::k##Name, &Builtins::Generate_##Name, Argc, #Name); \
AddBuiltin(builtins, Builtin::k##Name, code); \
index++;
#define BUILD_TFC(Name, InterfaceDescriptor) \
/* Return size is from the provided CallInterfaceDescriptor. */ \
code = BuildWithCodeStubAssemblerCS( \
isolate, Builtin::k##Name, &Builtins::Generate_##Name, \
CallDescriptors::InterfaceDescriptor, #Name); \
AddBuiltin(builtins, Builtin::k##Name, code); \
index++;
#define BUILD_TFS(Name, ...) \
/* Return size for generic TF builtins (stub linkage) is always 1. */ \
code = BuildWithCodeStubAssemblerCS(isolate, Builtin::k##Name, \
&Builtins::Generate_##Name, \
CallDescriptors::Name, #Name); \
AddBuiltin(builtins, Builtin::k##Name, code); \
index++;
#define BUILD_TFH(Name, InterfaceDescriptor) \
/* Return size for IC builtins/handlers is always 1. */ \
code = BuildWithCodeStubAssemblerCS( \
isolate, Builtin::k##Name, &Builtins::Generate_##Name, \
CallDescriptors::InterfaceDescriptor, #Name); \
AddBuiltin(builtins, Builtin::k##Name, code); \
index++;
#define BUILD_BCH(Name, OperandScale, Bytecode) \
code = GenerateBytecodeHandler(isolate, Builtin::k##Name, OperandScale, \
Bytecode); \
AddBuiltin(builtins, Builtin::k##Name, code); \
index++;
#define BUILD_ASM(Name, InterfaceDescriptor) \
code = BuildWithMacroAssembler(isolate, Builtin::k##Name, \
Builtins::Generate_##Name, #Name); \
AddBuiltin(builtins, Builtin::k##Name, code); \
index++;
BUILTIN_LIST(BUILD_CPP, BUILD_TFJ, BUILD_TFC, BUILD_TFS, BUILD_TFH, BUILD_BCH,
BUILD_ASM);
#undef BUILD_CPP
#undef BUILD_TFJ
#undef BUILD_TFC
#undef BUILD_TFS
#undef BUILD_TFH
#undef BUILD_BCH
#undef BUILD_ASM
// ...
}
BUILTIN_LIST宏内定义了所有的builtin,并根据其类型去调用不同的参数,在这里参数是BUILD_CPP, BUILD_TFJ...这些,定义了不同的生成策略,这些参数去掉前缀代表不同的builtin类型(CPP, TFJ, TFC, TFS, TFH, BCH, ASM)
mksnapshot执行时生成builtin的方式有两种:
•直接生成机器码,ASM和CPP类型builtin使用这种方式(CPP类型只是生成适配器) •先生成turbofan的graph(IR),然后由turbofan编译器编译成机器码,除ASM和CPP之外其它builtin类型都是这种例如:DoubleToI是一个ASM类型builtin,功能是把double转成整数,该builtin的JIT生成逻辑位于Builtins::Generate_DoubleToI,如果是x64的window,该函数放在v8/src/builtins/x64/builtins-x64.cc文件。由于每个CPU架构的指令都不一样,所以每个CPU架构都有一个实现,放在各自的builtins-ArchName.cc文件。
x64的实现如下:
void Builtins::Generate_DoubleToI(MacroAssembler* masm) {
Label check_negative, process_64_bits, done;
// Account for return address and saved regs.
const int kArgumentOffset = 4 * kSystemPointerSize;
MemOperand mantissa_operand(MemOperand(rsp, kArgumentOffset));
MemOperand exponent_operand(
MemOperand(rsp, kArgumentOffset + kDoubleSize / 2));
// The result is returned on the stack.
MemOperand return_operand = mantissa_operand;
Register scratch1 = rbx;
// Since we must use rcx for shifts below, use some other register (rax)
// to calculate the result if ecx is the requested return register.
Register result_reg = rax;
// Save ecx if it isn't the return register and therefore volatile, or if it
// is the return register, then save the temp register we use in its stead
// for the result.
Register save_reg = rax;
__ pushq(rcx);
__ pushq(scratch1);
__ pushq(save_reg);
__ movl(scratch1, mantissa_operand);
__ Movsd(kScratchDoubleReg, mantissa_operand);
__ movl(rcx, exponent_operand);
__ andl(rcx, Immediate(HeapNumber::kExponentMask));
__ shrl(rcx, Immediate(HeapNumber::kExponentShift));
__ leal(result_reg, MemOperand(rcx, -HeapNumber::kExponentBias));
__ cmpl(result_reg, Immediate(HeapNumber::kMantissaBits));
__ j(below, &process_64_bits, Label::kNear);
// Result is entirely in lower 32-bits of mantissa
int delta =
HeapNumber::kExponentBias + base::Double::kPhysicalSignificandSize;
__ subl(rcx, Immediate(delta));
__ xorl(result_reg, result_reg);
__ cmpl(rcx, Immediate(31));
__ j(above, &done, Label::kNear);
__ shll_cl(scratch1);
__ jmp(&check_negative, Label::kNear);
__ bind(&process_64_bits);
__ Cvttsd2siq(result_reg, kScratchDoubleReg);
__ jmp(&done, Label::kNear);
// If the double was negative, negate the integer result.
__ bind(&check_negative);
__ movl(result_reg, scratch1);
__ negl(result_reg);
__ cmpl(exponent_operand, Immediate(0));
__ cmovl(greater, result_reg, scratch1);
// Restore registers
__ bind(&done);
__ movl(return_operand, result_reg);
__ popq(save_reg);
__ popq(scratch1);
__ popq(rcx);
__ ret(0);
}
看上去很像汇编(编程的思考方式按汇编来),实际上是c++函数,比如这行movl
__ movl(scratch1, mantissa_operand);__是个宏,实际上是调用masm变量的函数(movl)
#define __ ACCESS_MASM(masm)
#define ACCESS_MASM(masm) masm->而movl的实现是往pc_指针指向的内存写入mov指令及其操作数,并把pc_指针前进指令长度。
ps:一条条指令写下来,然后把内存权限改为可执行,这就是JIT的基本原理。
除了ASM和CPP的其它类型builtin都通过调用CodeStubAssembler API(下称CSA)编写,这套API和之前介绍ASM类型builtin时提到的“类汇编API”类似,不同的是“类汇编API”直接产出原生代码,CSA产出的是turbofan的graph(IR)。CSA比起“类汇编API”的好处是不用每个平台各写一次。
但是类汇编的CSA写起来还是太费劲了,于是V8提供了一个类javascript的高级语言:torque ,这语言最终会编译成CSA形式的c++代码和V8其它C++代码一起编译。
例如Array.isArray使用torque语言实现如下:
namespace runtime {
extern runtime ArrayIsArray(implicit context: Context)(JSAny): JSAny;
} // namespace runtime
namespace array {
// ES #sec-array.isarray
javascript builtin ArrayIsArray(js-implicit context: NativeContext)(arg: JSAny):
JSAny {
// 1. Return ? IsArray(arg).
typeswitch (arg) {
case (JSArray): {
return True;
}
case (JSProxy): {
// TODO(verwaest): Handle proxies in-place
return runtime::ArrayIsArray(arg);
}
case (JSAny): {
return False;
}
}
}
} // namespace array经过torque编译器编译后,会生成一段复杂的CSA的C++代码,下面截取一个片段
TNode<JSProxy> Cast_JSProxy_1(compiler::CodeAssemblerState* state_, TNode<Context> p_context, TNode<Object> p_o, compiler::CodeAssemblerLabel* label_CastError) {
// other code ...
if (block0.is_used()) {
ca_.Bind(&block0);
ca_.SetSourcePosition("../../src/builtins/cast.tq", 162);
compiler::CodeAssemblerLabel label1(&ca_);
tmp0 = CodeStubAssembler(state_).TaggedToHeapObject(TNode<Object>{p_o}, &label1);
ca_.Goto(&block3);
if (label1.is_used()) {
ca_.Bind(&label1);
ca_.Goto(&block4);
}
}
// other code ...
}和上面讲的Ldar字节码一样,这并不是跑在v8运行时的Array.isArray实现。这段代码只运行在mksnapshot中,这段代码的产物是turbofan的IR。IR经过turbofan的优化编译后生成目标机器指令,然后dump到embedded.S汇编文件,下面才是真正跑在v8运行时的Array.isArray:
Builtins_ArrayIsArray:
.type Builtins_ArrayIsArray, %function
.size Builtins_ArrayIsArray, 214
.octa 0xd10043ff910043fda9017bfda9be6fe1,0x540003a9eb2263fff8560342f81e83a0
.octa 0x7840b063f85ff04336000182f9401be2,0x14000007d2800003540000607110907f
.octa 0x910043ffa8c17bfd910003bff85b8340,0x35000163d2800020d2800023d65f03c0
.octa 0x540000e17102d47f7840b063f85ff043,0xf94da741f90003e2f90007ffd10043ff
.octa 0x17ffffeef85c034017fffff097ffb480,0xaa1b03e2f9501f41d2800000f90003fb
.octa 0x17ffffddf94003fb97ffb477aa0003e3,0x840000000100000002d503201f
.octa 0xffffffff000000a8ffffffffffffffff
.byte 0xff,0xff,0xff,0xff,0x0,0x1,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc,0xcc在这个过程中,JIT编译器turbofan同样干的是AOT的活。
1.3、builtin是怎么加载使用的
mksnapshot生成的包含所有builtin的产物embedded.S会和其他v8源码一起编译成最终的v8库,embedded.S中声明了四个全局变量,分别是:
•v8_Default_embedded_blob_code_:初始化为第一个builtin的起始位置(全部builtin紧凑的放在一个代码段里) •v8_Default_embedded_blob_data_:指向一块数据,这块数据包含诸如各builtin相对v8_Default_embedded_blob_code_的偏移,builtin的长度等等信息 •v8_Default_embedded_blob_code_size_:所有builtin的总长度 •v8_Default_embedded_blob_data_size_:v8_Default_embedded_blob_data_数据的总长度在v8/src/execution/isolate.cc中声明了几个extern变量,链接embedded.S后v8/src/execution/isolate.cc就能引用到那几个变量:
extern "C" const uint8_t* v8_Default_embedded_blob_code_;
extern "C" uint32_t v8_Default_embedded_blob_code_size_;
extern "C" const uint8_t* v8_Default_embedded_blob_data_;
extern "C" uint32_t v8_Default_embedded_blob_data_size_;v8_Default_embedded_blob_data_中包含了各builtin的偏移,这些偏移组成一个数组,放在isolate的builtin_entry_table,数组下标是该builtin的枚举值。调用某builtin就是builtin_entry_table通过枚举值获取起始地址调用。
2、snapshot
在V8引擎中,snapshot是指在启动时将部分或全部JavaScript堆内存的状态保存到一个文件中,以便在后续的启动中可以快速恢复到这个状态。这个技术可以显著减少V8引擎的启动时间,特别是在大型应用程序中。
snapshot文件包含了以下几个部分:
•JavaScript堆的内存布局:包括了所有对象的地址、大小和类型等信息。 •JavaScript代码的字节码:包括了所有已经编译的JavaScript函数的字节码。 •全局对象的状态:包括了全局对象的属性值、函数指针等信息。 •其他必要的状态:例如,垃圾回收器的状态、Just-In-Time (JIT) 编译器的缓存等。当V8引擎启动时,如果存在有效的Snapshot文件,V8会直接从这个文件中读取JavaScript堆的状态和字节码,而不需要重新解析和编译所有的JavaScript代码。这可以大幅度缩短V8引擎的启动时间。V8的Snapshot技术有以下几个优点:
•快速启动:可以显著减少V8引擎的启动时间,特别是在大型应用程序中。 •低内存占用:由于部分或全部JavaScript堆的状态已经被保存到文件中,所以在启动时可以节省内存。 •稳定性:Snapshot文件是由V8引擎生成的,保证了与引擎的兼容性和稳定性。如果不是交叉编译,snapshot生成还是挺容易理解的:v8对各种对象有做了序列化和反序列化的支持,所谓生成snapshot,就是序列化,通常会以context作为根来序列化。
mksnapshot制作快照可以输入一个额外的脚本,也就是生成snapshot前允许执行一段代码,这段代码调用到的函数的编译结果也会序列化下来,后续加载快照反序列化后等同于执行过了这脚本,就免去了编译过程,大大加快的启动的速度。
mksnapshot制作快照是通过调用v8::SnapshotCreator完成,而v8::SnapshotCreator提供了我们输入外部数据的机会。如果只有一个Context需要保存,用SnapshotCreator::SetDefaultContext就可以了,恢复时直接v8::Context::New即可。如果有多于一个Context,可以通过SnapshotCreator::AddContext添加,它会返回一个索引,恢复时输入索引即可恢复到指定的存档。如果保存Context之外的数据,可以调用SnapshotCreator::AddData,然后通过Isolate或者Context的GetDataFromSnapshot接口恢复。
//保存
size_t context_index = snapshot_creator.AddContext(context, si_cb);
//恢复
v8::Local<v8::Context> context = v8::Context::FromSnapshot(isolate, context_index, di_cb).ToLocalChecked();结合交叉编译时就会有个很费解的地方:我们前面提到mksnapshot在交叉编译时,JIT生成的builtin是目标机器指令,而js的运行得通过跑builtin来实现(Ignition解析器每个指令就是一个builtin),这目标机器指令(比如arm64)怎么在本地(比如linux 的x64)跑起来呢?mksnapshot为了实现交叉编译中目标平台snapshot的生成,它做了各种cpu(arm、mips、risc、ppc)的模拟器(Simulator)
通过查看源码交叉编译时,mksnapshot会用一个目标机器的模拟器来跑这些builtin:
//src\common\globals.h
#if !defined(USE_SIMULATOR)
#if (V8_TARGET_ARCH_ARM64 && !V8_HOST_ARCH_ARM64)
#define USE_SIMULATOR 1
#endif
// ...
#endif
//src\execution\simulator.h
#ifdef USE_SIMULATOR
Return Call(Args... args) {
// other code ...
return Simulator::current(isolate_)->template Call<Return>(
reinterpret_cast<Address>(fn_ptr_), args...);
}
#else
DISABLE_CFI_ICALL Return Call(Args... args) {
// other code ...
}
#endif // USE_SIMULATOR如果交叉编译,将会走USE_SIMULATOR分支。arm64将会调用到v8/src/execution/simulator-arm64.h, v8/src/execution/simulator-arm64.cc实现的模拟器。上面Call的处理是把指令首地址赋值到模拟器的_pc寄存器,参数放寄存器,执行完指令从寄存器获取返回值。
六、V8移植的具体步骤
一般我们将负责编译的机器称为host,编译产物运行的目标机器称为target。
•本文使用的host机器是Mac M1 ,Xcode版本Version 14.2 (14C18) •鸿蒙IDE版本:DevEco Studio NEXT Developer Beta5 •鸿蒙SDK版本是HarmonyOS-NEXT-DB5 •目标机器架构:arm64-v8a如果要在Mac M1上交叉编译鸿蒙 arm64的builtin,步骤如下:
•调用本地编译器,编译一个Mac M1版本mksnapshot可执行程序 •执行上述mksnapshot生成鸿蒙平台arm64指令并dump到embedded.S •调用鸿蒙sdk的工具链,编译链接embedded.S和v8的其它代码,生成能在鸿蒙arm64上使用的v8库1.首先安装cmake及ninja构建工具
鸿蒙sdk自带构建工具我们可以将它们加入环境变量中使用

2.编写交叉编译V8到鸿蒙的CMakeList.txt
总共有1千多行,部分CMakeList.txt片段:
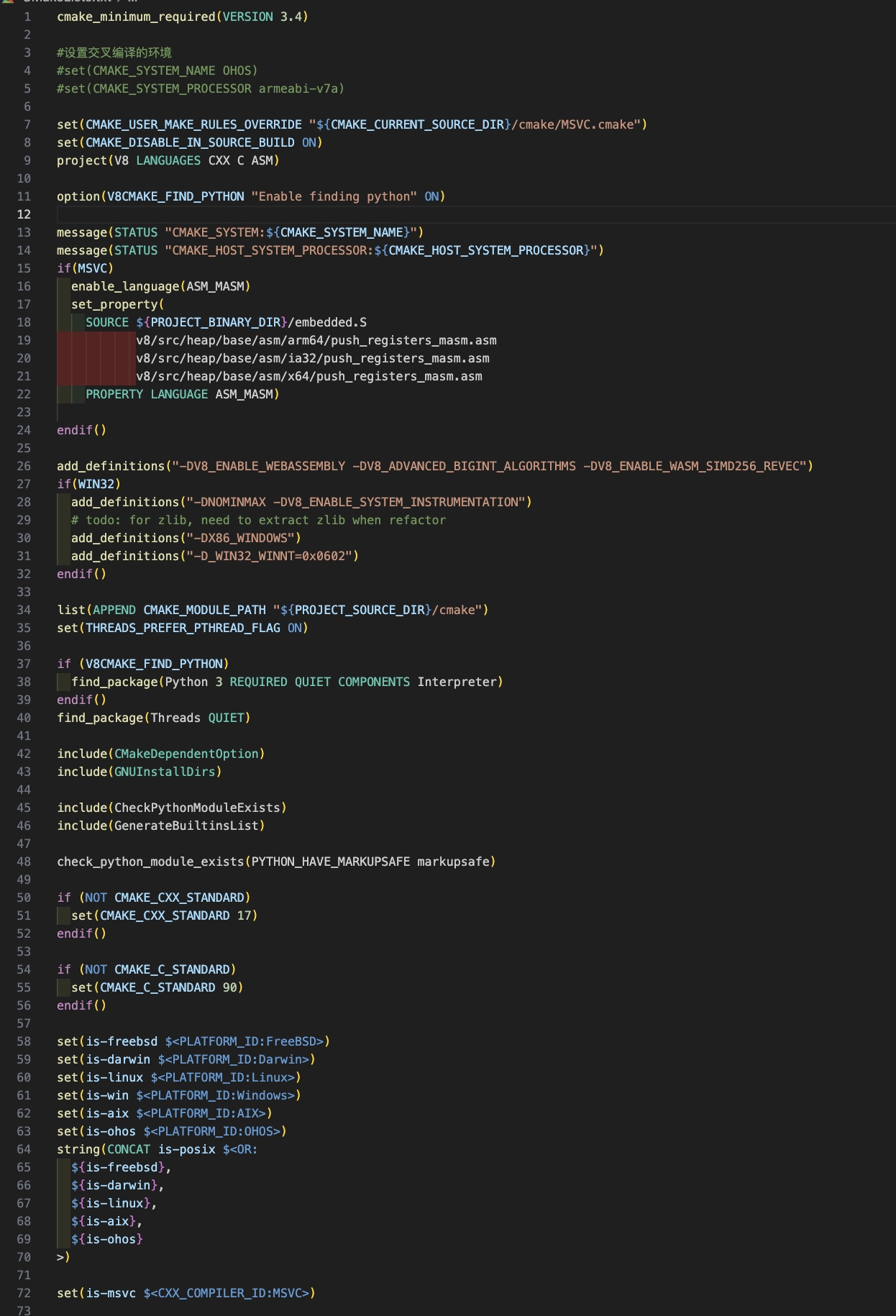
3.使用host本机的编译工具链编译
$ mkdir build
$ cd build
$ cmake -G Ninja ..
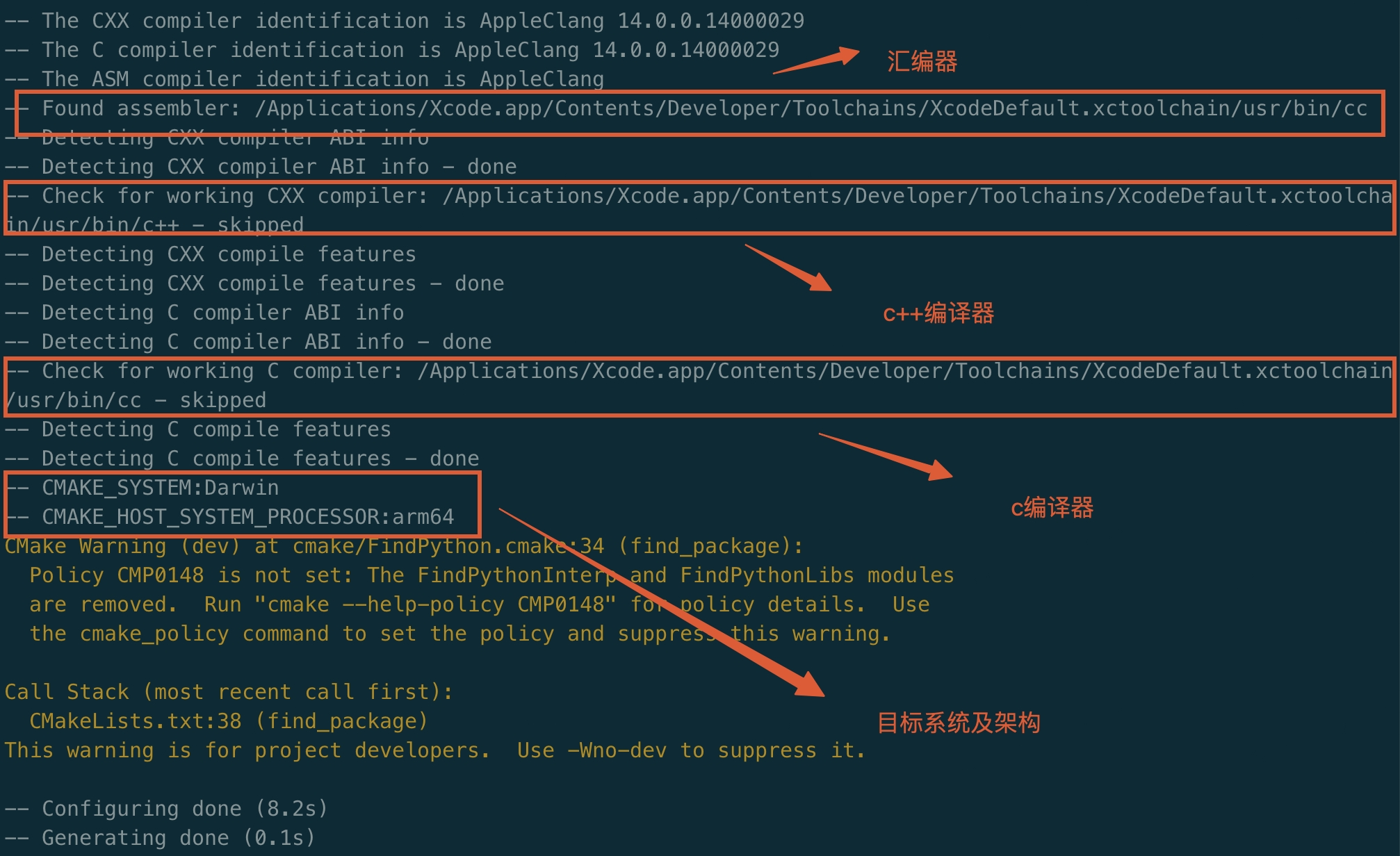
$ ninja 或者 cmake --build .首先创建一个编译目录build,打开build执行cmake -G Ninja .. 生成针对ninja编译需要的文件。
下面是控制台打印的工具链配置信息,使用的是Mac本地xcode的工具链:
build文件夹下生成以下文件:
其中CMakeCache.txt是一个由CMake生成的缓存文件,用于存储CMake在配置过程中所做的选择和决策。它是根据你的项目的CMakeLists.txt文件和系统环境来生成一个初始的CMakeCache.txt文件。这个文件包含了所有可配置的选项及其默认值。
build.ninja文件是Ninja的主要输入文件,包含了项目的所有构建规则和依赖关系。
这个文件的内容是Ninja的语法,描述了如何从源文件生成目标文件。它包括了以下几个部分:
•规则:定义了如何从源文件生成目标文件的规则。例如,编译C++文件、链接库等。 •构建目标:列出了项目中所有需要构建的目标,包括可执行文件、静态库、动态库等。 •依赖关系:描述了各个构建目标之间的依赖关系。Ninja会根据这些依赖关系来确定构建的顺序。 •变量:定义了一些Ninja使用的变量,例如编译器、编译选项等。然后执行cmake --build . 或者 ninja
查看build文件夹下生成的产物:
其中红框中的三个可执行文件是在编译过程中生成,同时还会在编译过程中执行。bytecode_builtins_list_generator主要生成是字节码对应builtin的生成代码。torque负责将.tq后缀的文件(使用torque语言编写的builtin)编译成CSA类型builtin的c++源码文件。
torque编译.tq文件生成的c++代码在torque-generated目录中:
bytecode_builtins_list_generator执行生成字节码函数列表在下面目录中:
mksnapshot则链接这些代码并执行,执行期间会在内置的对应架构模拟器中运行v8,最终生成host平台的buildin汇编代码——embedded.S和snapshot(context的序列化对象)——snapshot.cc。它们跟随其他v8源代码一起编译生成最终的v8静态库libv8_snapshot.a。目前build目录中已经编译出host平台的完整v8静态库及命令行调试工具d8。
mksnapshot程序自身的编译生成及执行在CMakeList.txt中的配置代码如下:
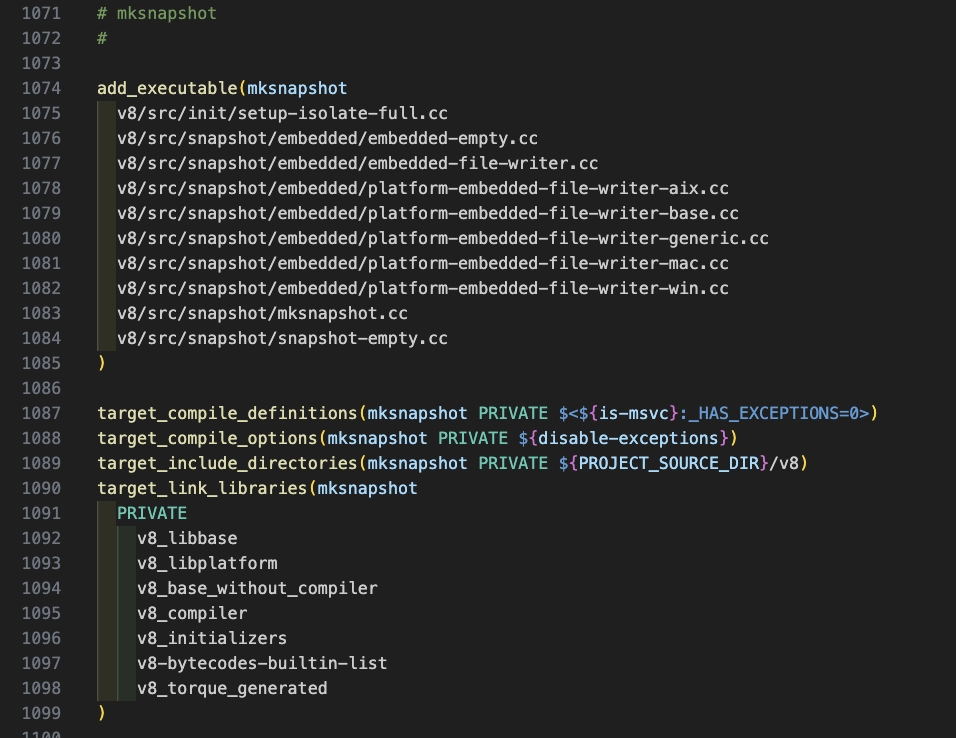
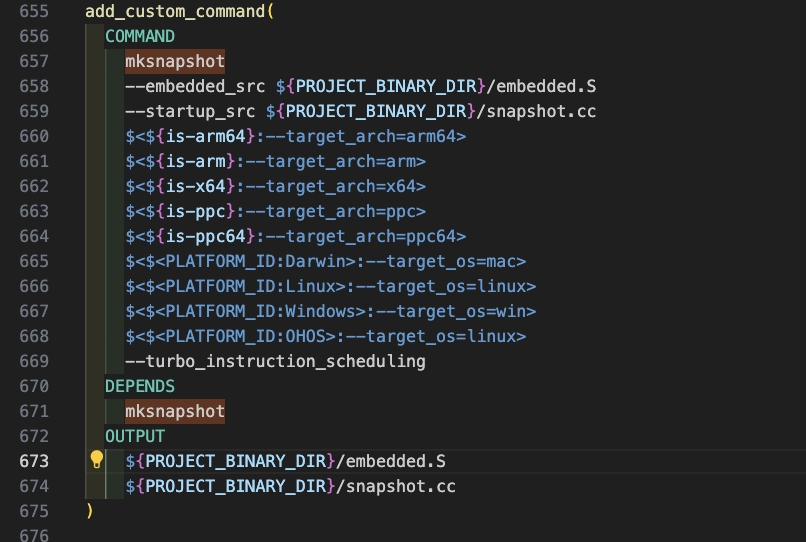
4.使用鸿蒙SDK的编译工具链编译
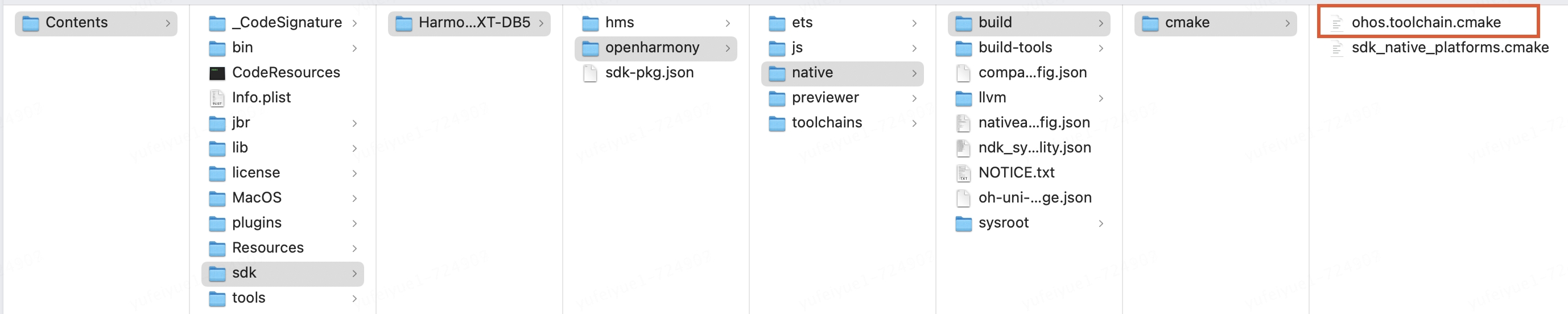
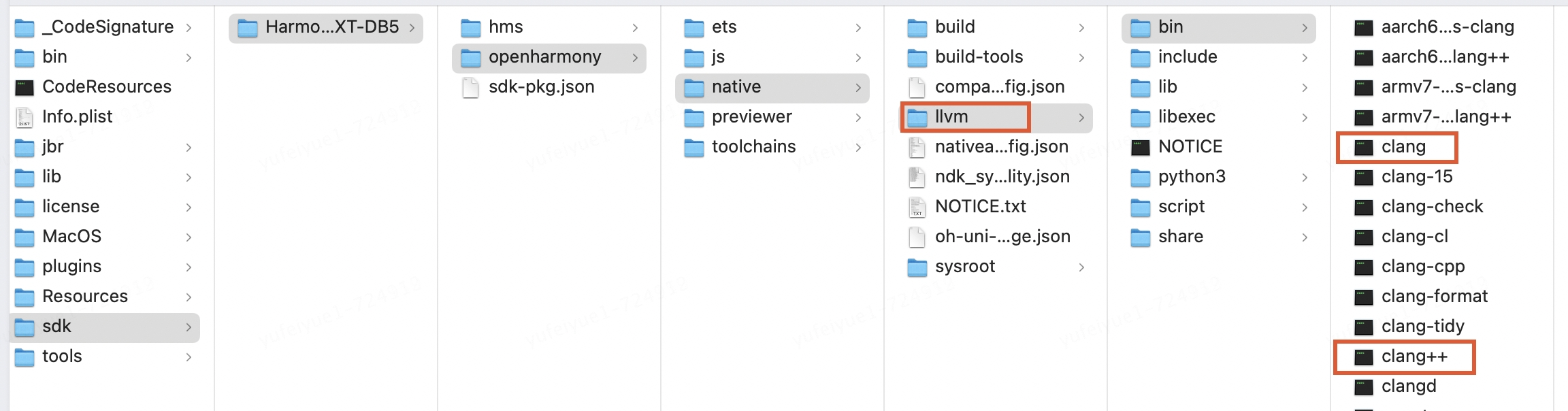
因为在编译target平台的v8时中间生成的bytecode_builtins_list_generator,torque,mksnapshot可执行文件是针对target架构的无法在host机器上执行。所以首先需要把上面在host平台生成的可执行文件拷贝到/usr/local/bin,这样在编译target平台的v8过程中执行这些中间程序时会找到 /usr/local/bin下的可执行文件正确的执行生成针对target的builtin和snapshot快照。
$ cp bytecode_builtins_list_generator torque mksnapshot /usr/local/bin
$ mkdir ohosbuild #创建新的鸿蒙v8的编译目录
$ cd ohosbuild
#使用鸿蒙提供的工具链文件
$ cmake -DOHOS_STL=c++_shared -DOHOS_ARCH=arm64-v8a -DOHOS_PLATFORM=OHOS -DCMAKE_TOOLCHAIN_FILE=/Applications/DevEco-Studio.app/Contents/sdk/HarmonyOS-NEXT-DB5/openharmony/native/build/cmake/ohos.toolchain.cmake -G Ninja ..
$ ninja 或者 cmake --build .执行第一步cmake配置后控制台的信息可以看到,使用了鸿蒙的工具链
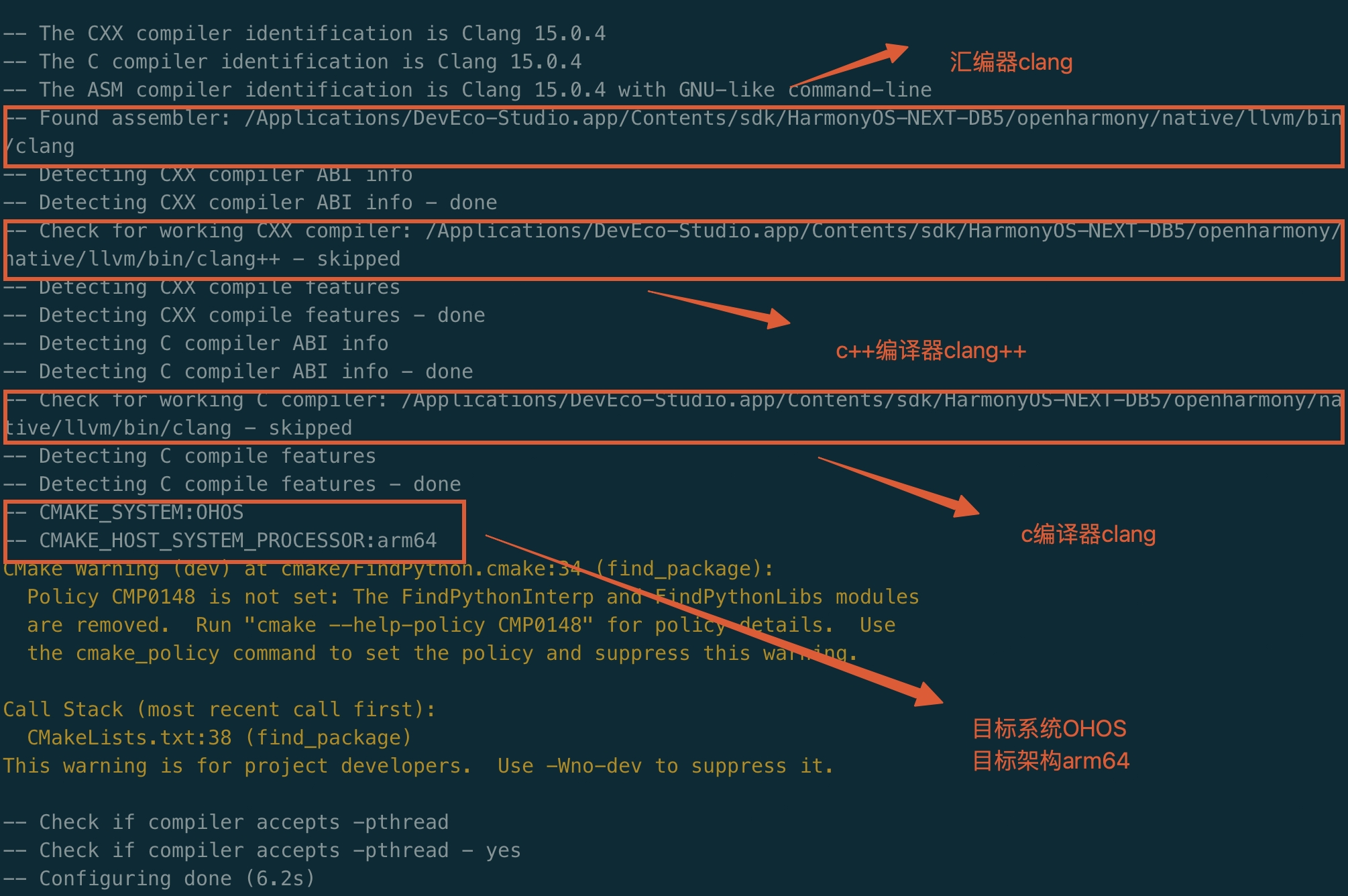
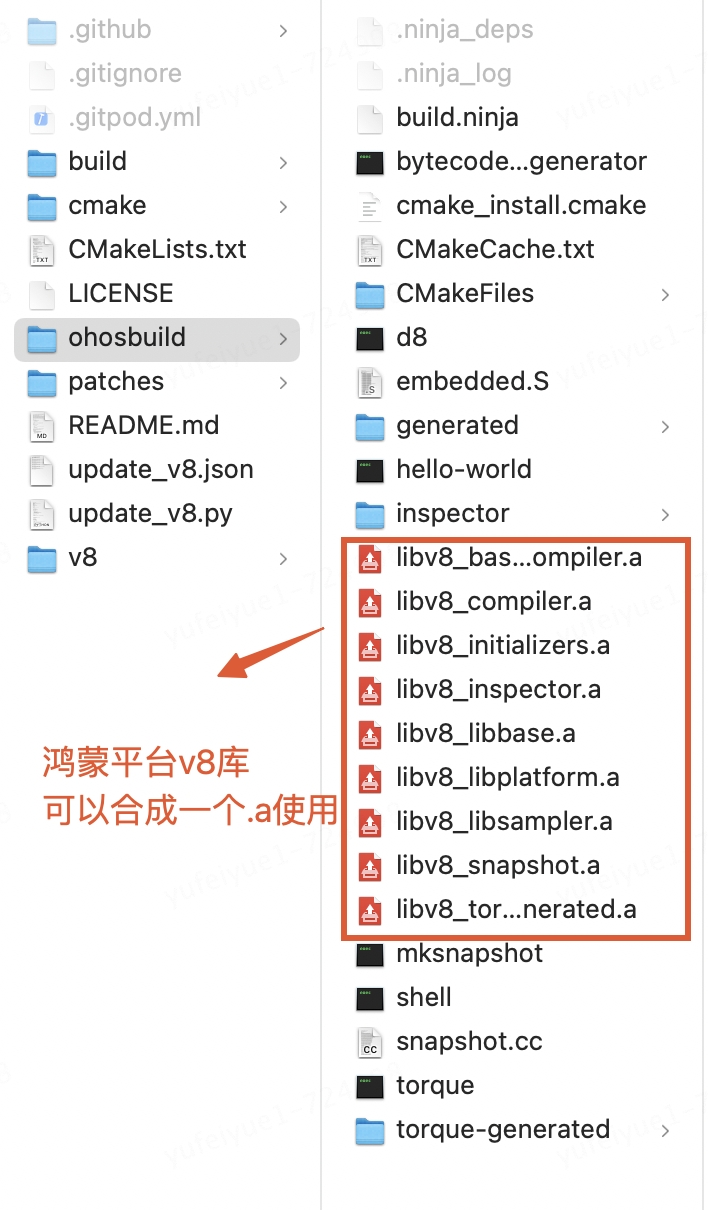
执行完成后ohosbuild文件夹下生成了鸿蒙平台的v8静态库,可以修改CMakeList.txt配置合成一个.a或者生成.so。
七、鸿蒙工程中使用v8库
1.新建native c++工程
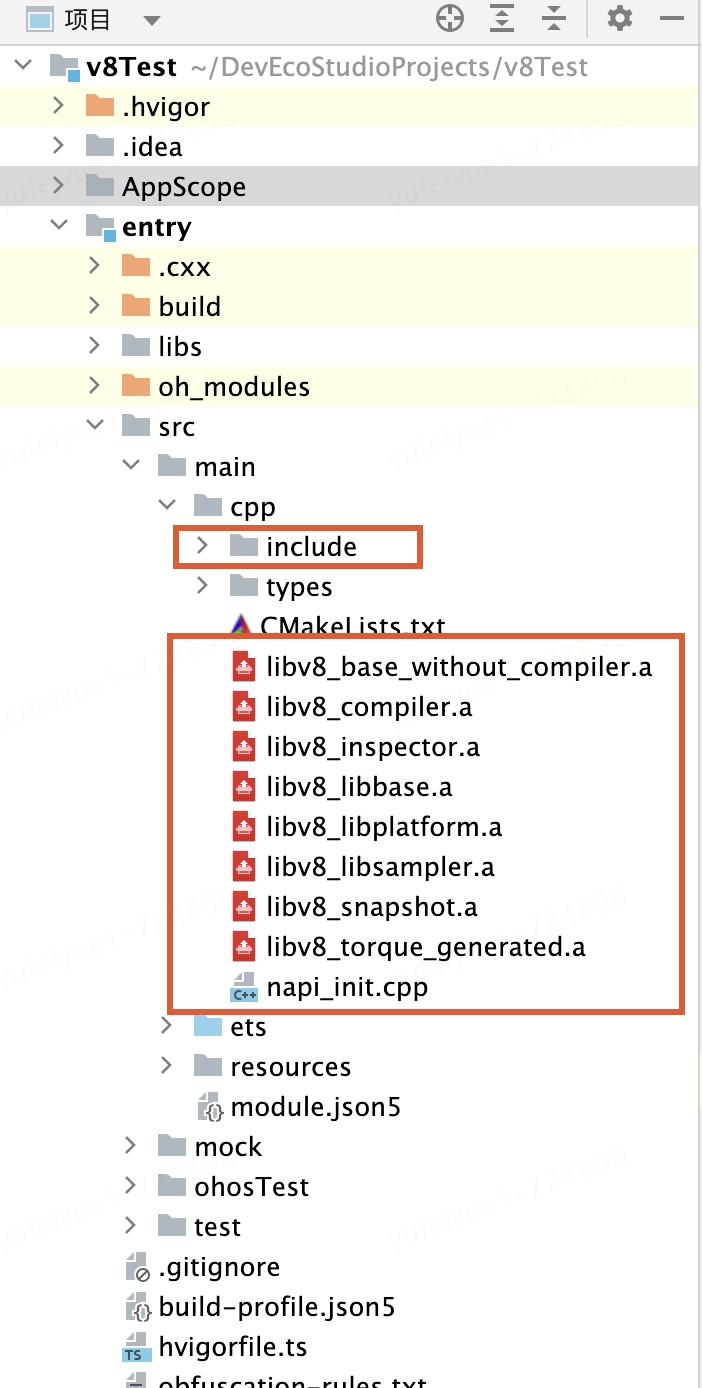
2.导入v8库
将v8源码中的include目录和上面编译生成的.a文件放入cpp文件夹下
3.修改cpp目录下CMakeList.txt文件
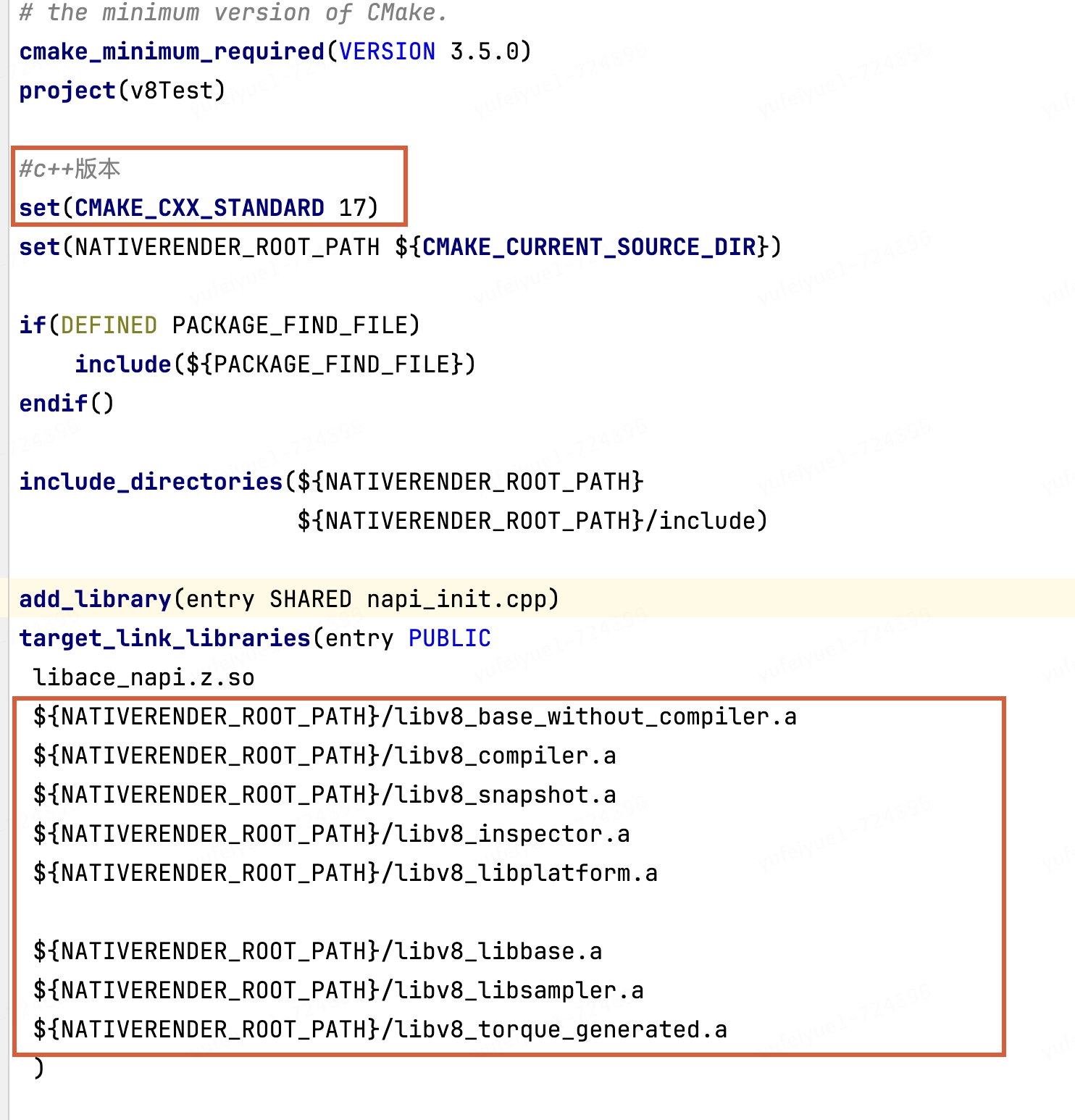
设置c++标准17,链接v8静态库
4.添加napi方法测试使用v8
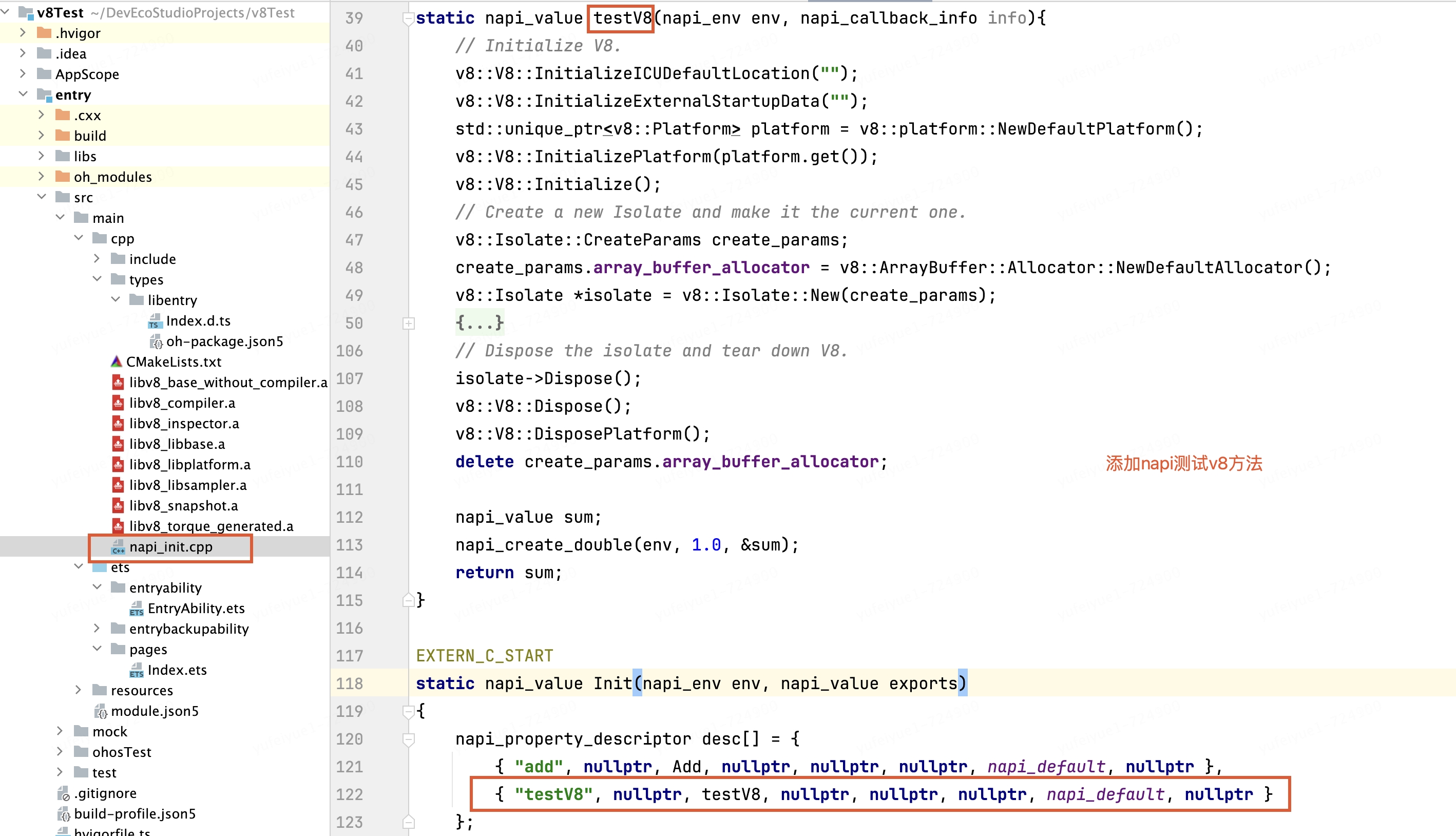
下面是简单的demo
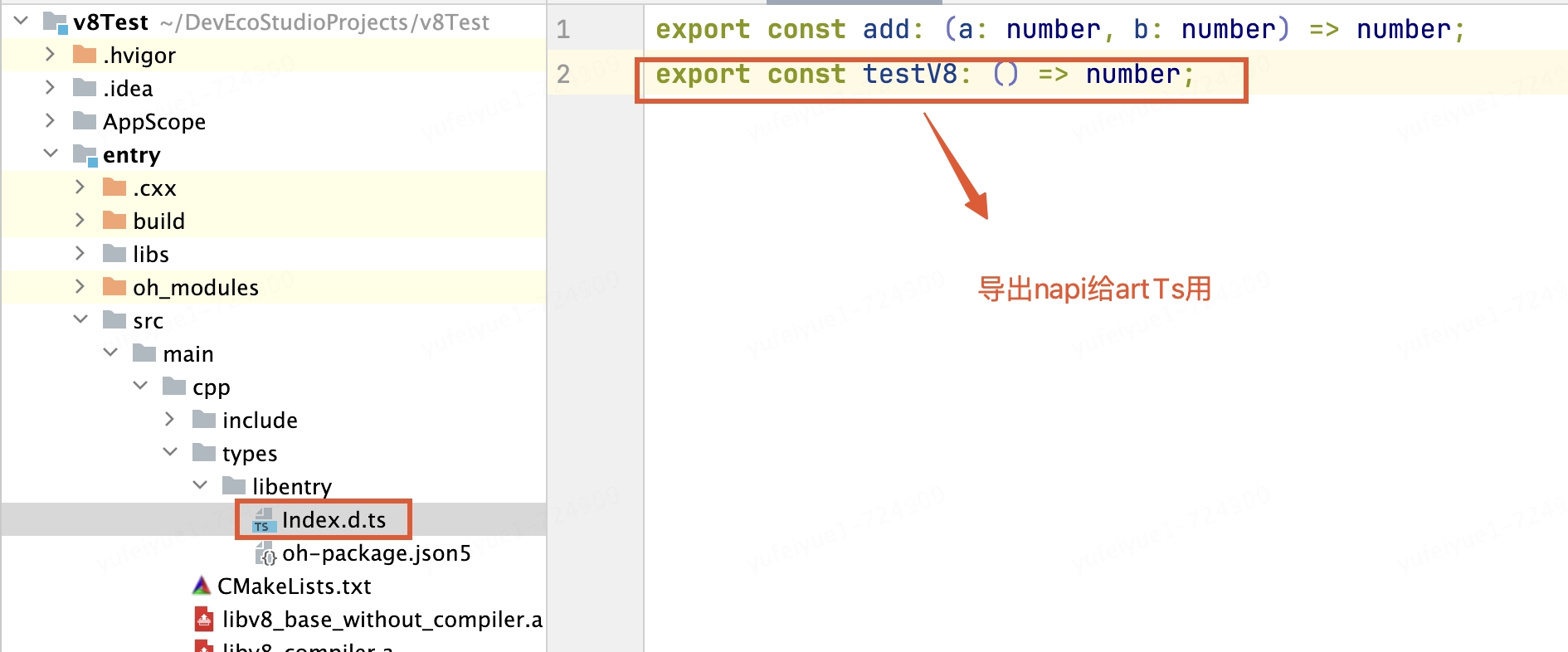
导出c++方法
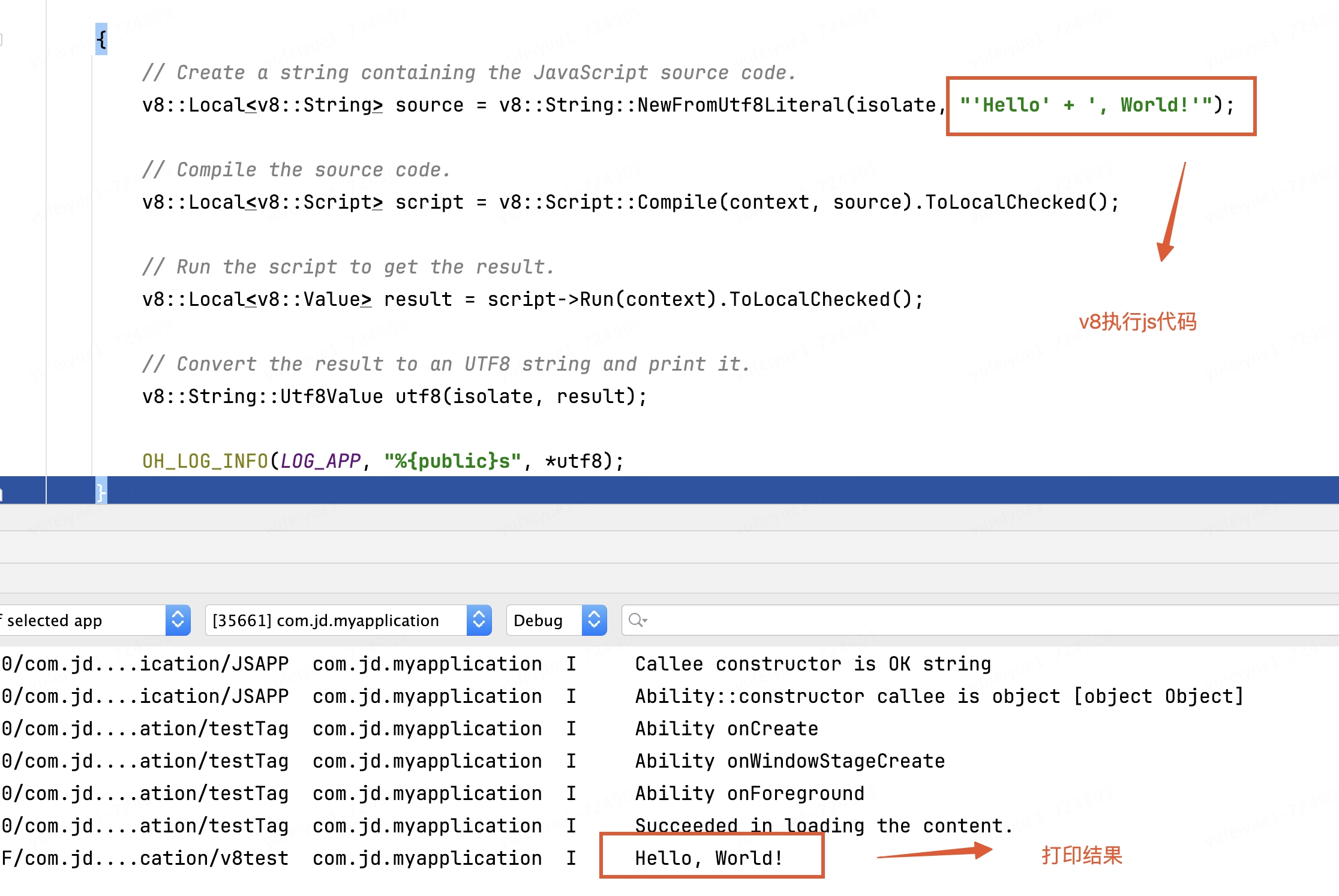
、
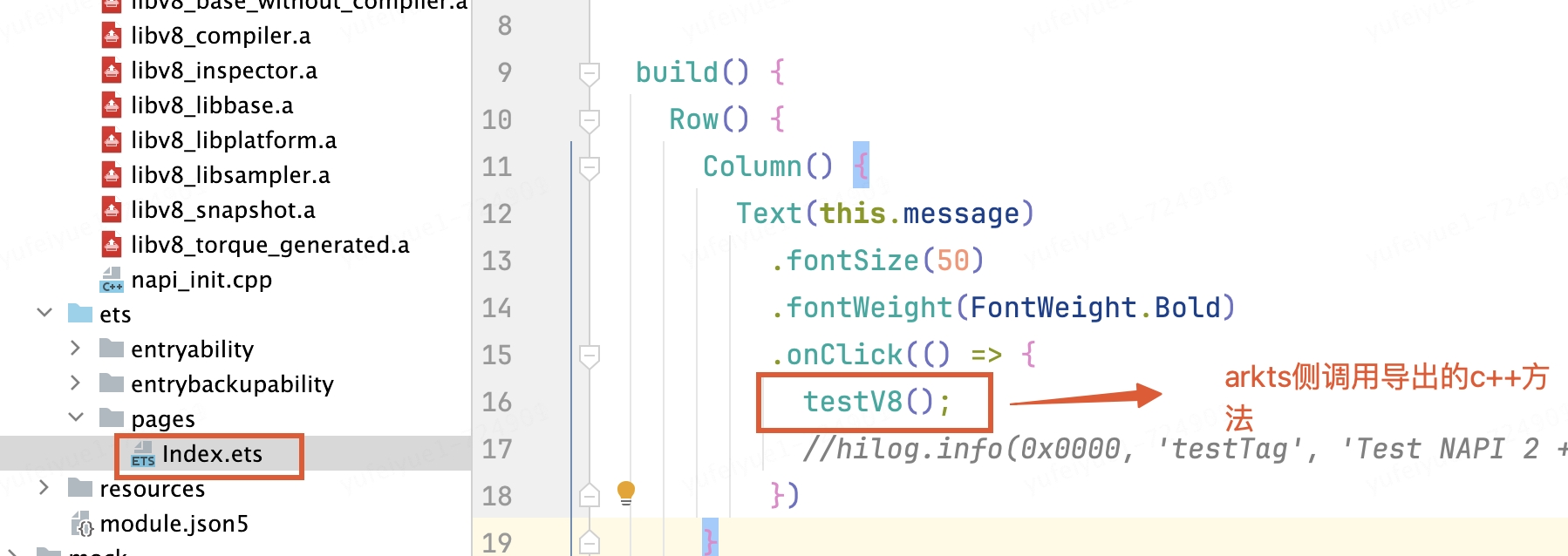
arkts侧调用c++方法
运行查看结果:
八、JS引擎的发展趋势
随着物联网的发展,人们对IOT设备(如智能手表)的使用越来越多。如果希望把JS应用到IOT领域,必然需要从JS引擎角度去进行优化,只是去做上层的框架收效甚微。因为对于IOT硬件来说,CPU、内存、电量都是需要省着点用的,不是每一个智能家电都需要装一个骁龙855。那怎么可以基于V8引擎进行改造来进一步提升JS的执行性能呢?
•使用TypeScript编程,遵循严格的类型化编程规则; •构建的时候将TypeScript直接编译为Bytecode,而不是生成JS文件,这样运行的时候就省去了Parse以及生成Bytecode的过程; •运行的时候,需要先将Bytecode编译为对应CPU的汇编代码; •由于采用了类型化的编程方式,有利于编译器优化所生成的汇编代码,省去了很多额外的操作;基于V8引擎来实现,技术上应该是可行的:
•将Parser以及Ignition拆分出来,用于构建阶段; •删掉TurboFan处理JS动态特性的相关代码;这样可以将JS引擎简化很多,一方面不再需要parse以及生成bytecode,另一方面编译器不再需要因为JavaScript动态特性做很多额外的工作。因此可以减少CPU、内存以及电量的使用,优化性能,唯一的问题是必须使用严格的TS语法进行编程。
Facebook的Hermes差不多就是这么干的,只是它没有要求用TS编程。
如今鸿蒙原生的ETS引擎Panda也是这么干的,它要求使用ets语法,其实是基于TS只不过做了更加严格的类型及语法限制(舍弃了更多的动态特性),进一步提升js的执行性能。
将V8移植到鸿蒙系统是一个巨大的嵌入式范畴工作,涉及交叉编译、CMake、CLang、Ninja、C++、torque等各种知识,虽然我们经历了巨大挑战并掌握了V8移植技术,但出于应用包大小、稳定性、兼容性、维护成本等维度综合考虑,如果华为系统能内置V8,对Roma框架及业界所有依赖JS虚拟机的跨端框架都是一件意义深远的事情,通过和华为持续沟通,鸿蒙从API11版本提供了一个内置的JS引擎,它实际上是基于v8的封装,并提供了一套c-api接口。
如果不想用c-api并且不考虑包大小的问题仍然可以自己编译一个独立的v8引擎嵌入APP,直接使用v8面向对象的C++ API。
Roma框架是一个涉及JavaScript、C&C++、Harmony、iOS、Android、Java、Vue、Node、Webpack等众多领域的综合解决方案,我们有各个领域优秀的小伙伴共同前行,大家如果想深入了解某个领域的具体实现,可以随时留言交流~
标签:v8,虚拟机,生成,编译,builtin,V8,纯血,代码 From: https://www.cnblogs.com/Jcloud/p/18418178