transformer
Encoder
之前的Self-attention其实已经提到过transformer,而且transformer和后面的bert也有很大关系,transformer就是一个sequence to sequence的model
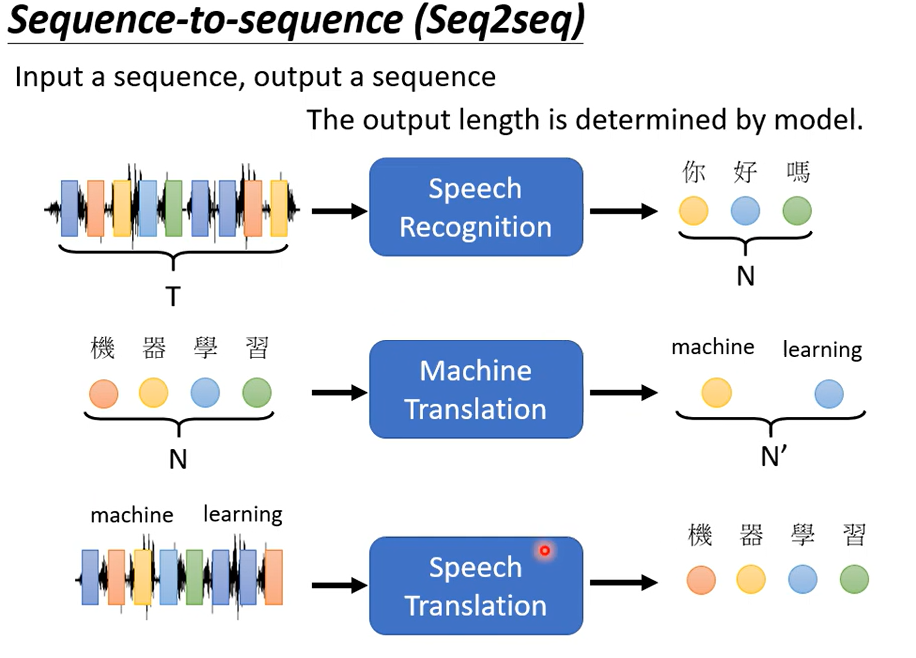
这些都是输出不定长的例子,语音识别+机器翻译=语音翻译 吗,有些语言可能没有文字,或者说某些方言
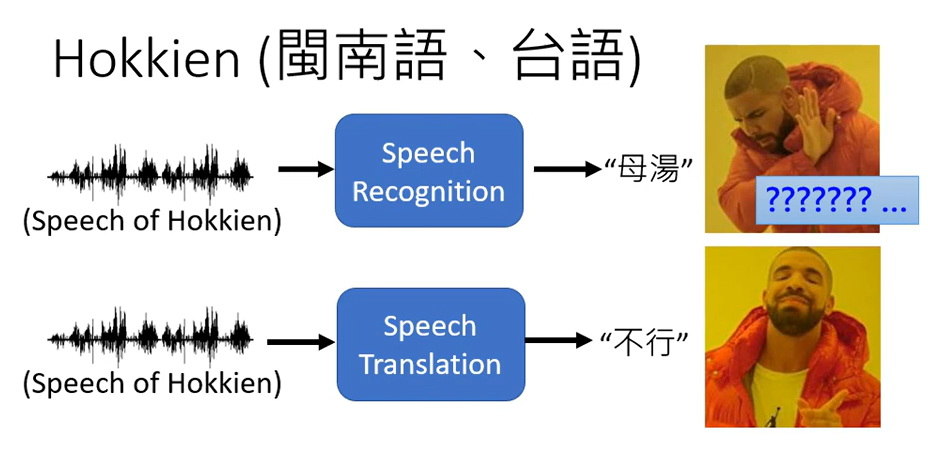
训练这样的模型,你就需要台语的语音资料和对应的中文,YouTube上有很多乡土剧,乡土剧就是台语语音,中文字幕
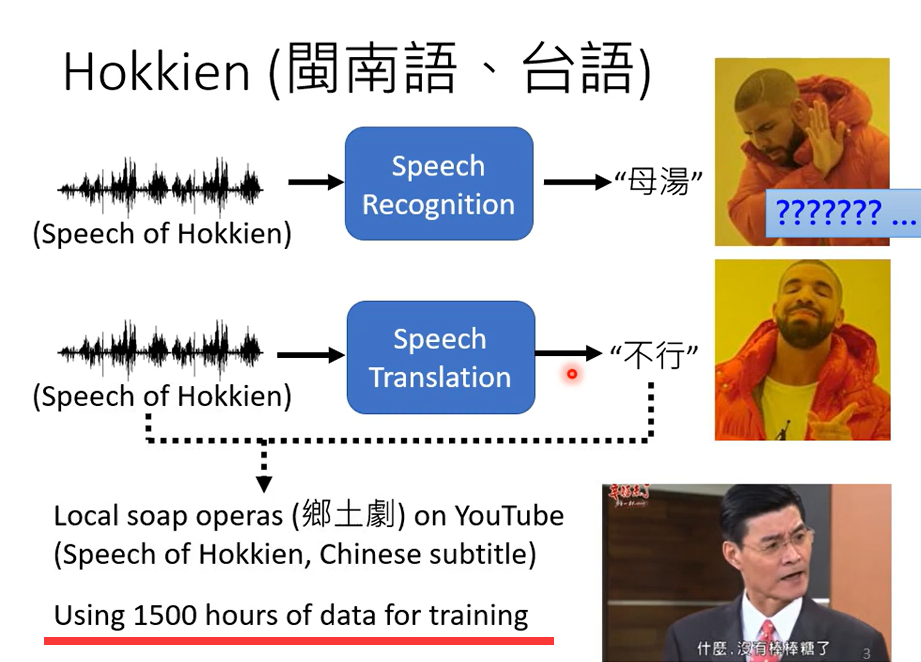
使用1500小时的数据训练一个语音识别系统

不考虑背景音乐和噪音,也不考虑声音和字幕不一致的情况,直接输入语音,输出是字幕开始训练,这就是硬train

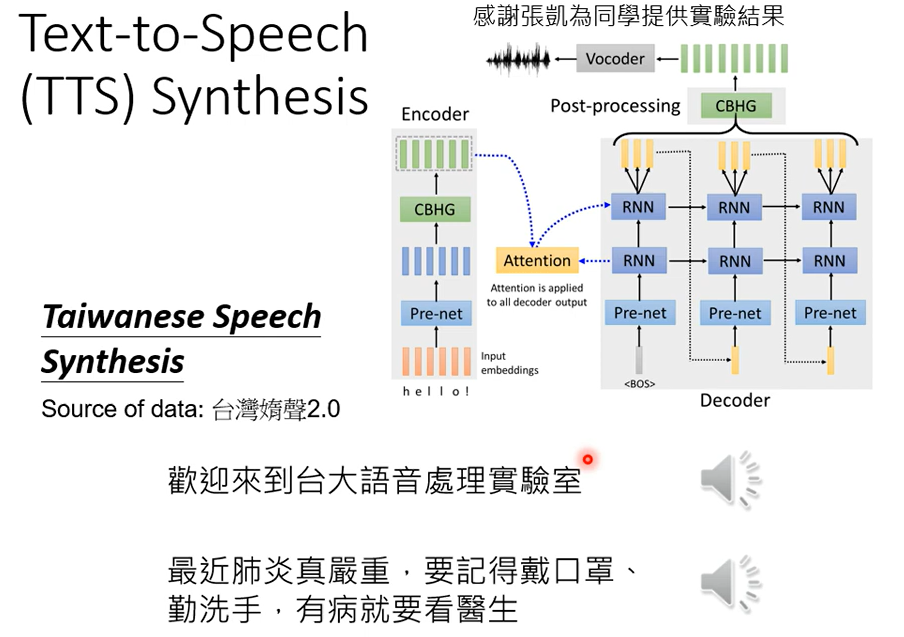
这样也是有可能能训练出一个语音辨识系统的。输入声音讯号输出文字就是语音辨识,反过来输入文字,输出台语语音,就是语音合成
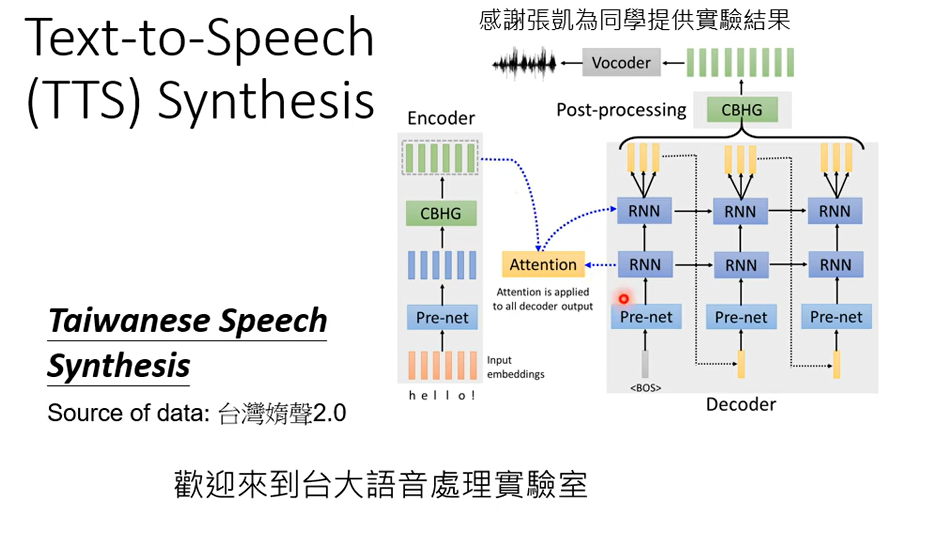
上图还没有做到end to end,而是分两阶段去做,先把中文文字转成台语的台罗音标,然后再把台罗音标转成声音讯号
除了语音,还可以训练对话机器人
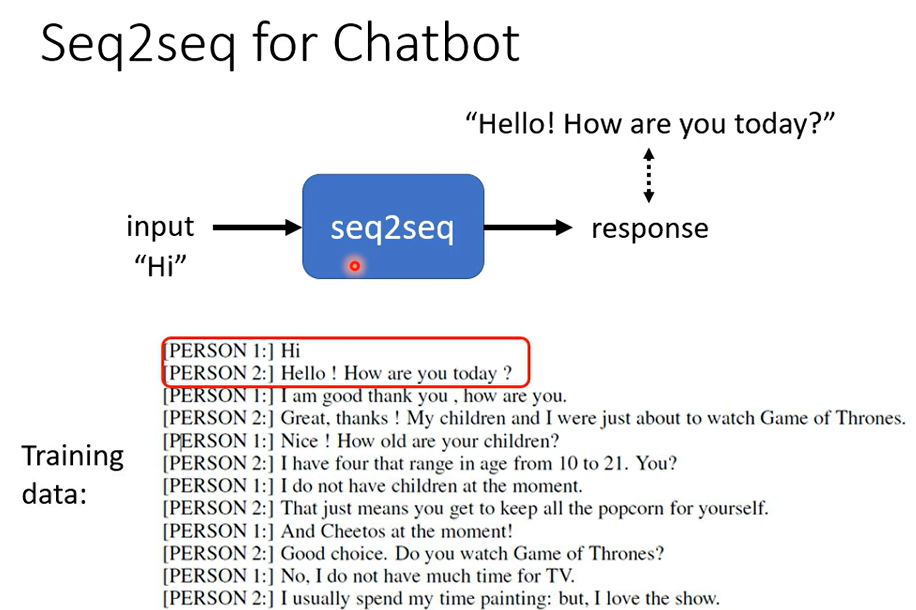
其实很多问题都可以看成是QA的问题(给机器一段文字,然后问一个问题,机器给出答案)

所以各式各样的NLP问题都可以看成是QA问题,而QA的问题可以用seq2seq model解决

但是需要强调的是,对多数的NLP任务或者语音任务,往往会为这些任务特质化模型,会得到更好的结果
对自然语言或者语音感兴趣可以看上面的课程。上面是seq2seq在语音和自然语言处理上的应用,但有很多应用,你不觉得它是一个seq2seq的问题,但是可以用seq2seq硬解,比如文法刨析
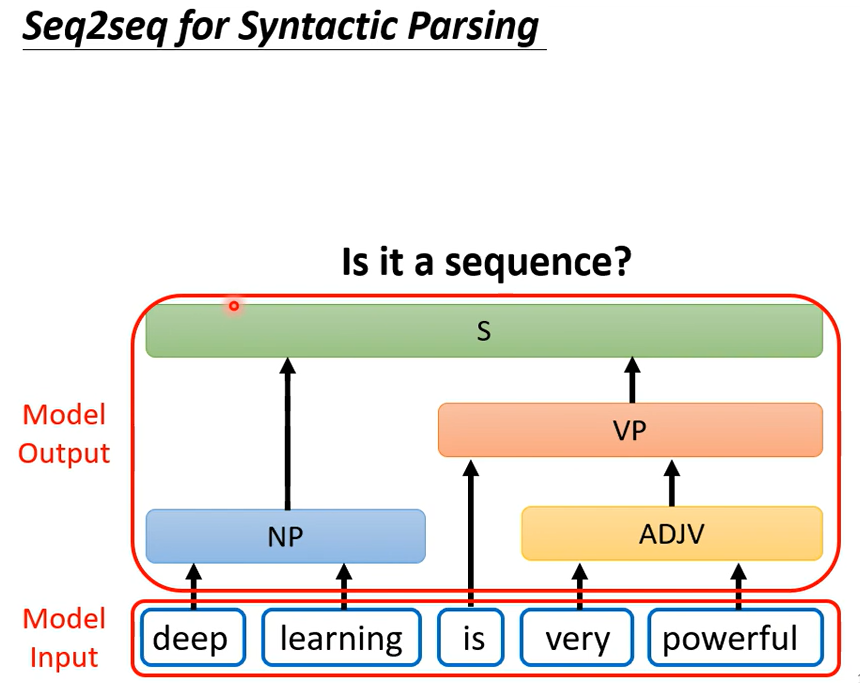
看起来输出不是一个序列,但是可以把这个树状结构硬看成一个sequence
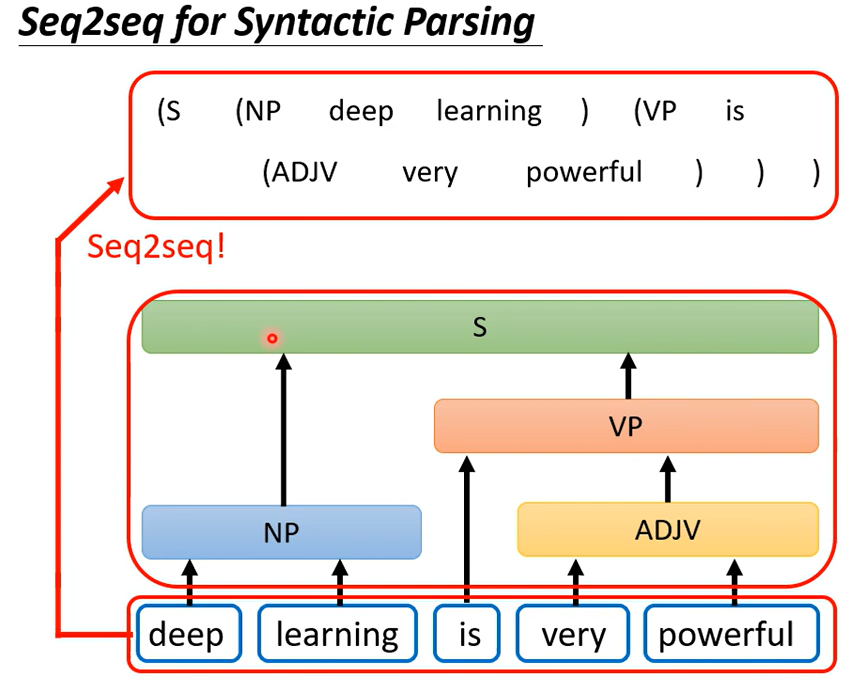
怎麼說呢,這個樹狀結構可以對應到一個這樣子的Sequence,你就可以硬是用Seq2Seq model
來做文法剖析這件事这个想法听起来很疯狂但是真的可以做到,可以看下面这篇文章

seq2seq还能用于multi-class的classification

multi-class的classification,是机器从数个class里选一个出来,而multi-label的classification是一个样本属于多个类别标签。
我现在就输出分数最高的前三名看看能不能解multi-label的classification。但这种方法呢,可能是行不通的,为什么?因为每一篇文章对应的class数目根本不一样啊,有些东西有些文章对应的数目对应的class数目是两个,有的是一个,有的是三个。所以如果你说我直接取一个threshold后,我直接取分数最高的前三名,class file output分数最高前三名来当作我的输出,显然不一定能够得到好的结果.
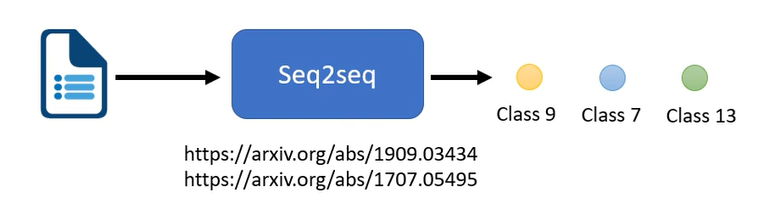
可以用seq2seq硬做,输入是一篇文章,输出是class,机器自己决定要输出几个class。seq2seq model就是有机器自己决定输出几个东西。
seq2seq甚至可以用在目标检测,這個看起來跟seq2seq model,應該八竿子打不著的問題它也可以用seq2seqs model硬解
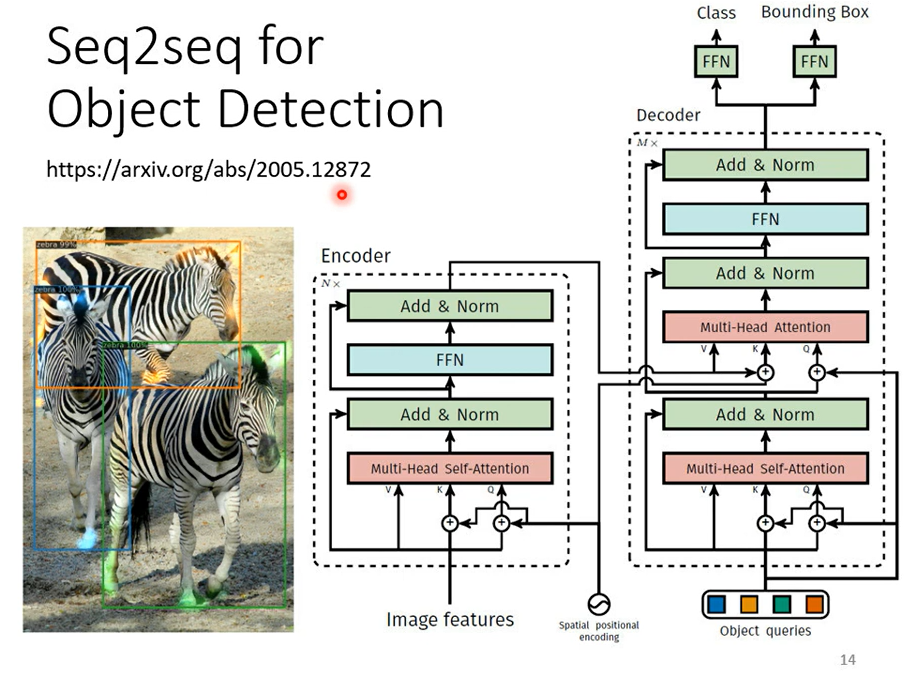
至於怎麼做 我們這邊就不細講,我在這邊放一個文獻放一個連結給大家參考,講這麼多就是要告訴你說seq2seq's model 它是一個很powerful的model,它是一個很有用的model,我們現在就是要來學怎麼做seq2seq這件事,一般的seq2seq's model它裡面會分成兩塊 一塊是Encoder另外一塊是Decoder
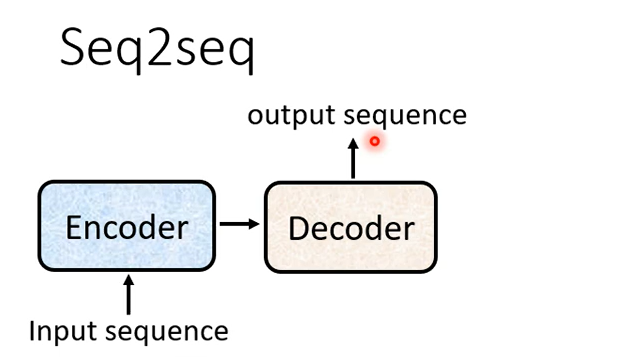
你input一個sequence有Encoder負責處理這個sequence,再把處理好的結果丟給Decoder,由Decoder決定它要輸出什麼樣sequence
,等一下 我們都還會再細講Encoder跟 Decoder內部的架構
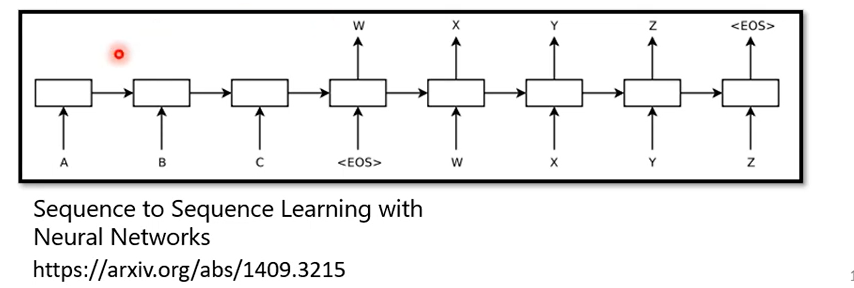
seq2seq's model的起源其實非常的早 在14年的9月就有一篇seq2seq's model用在翻譯的文章 被放到Arxiv上,可以想像當時的seq2seq's model看起來還是比較陽春的,今天講到seq2seq's model的時候大家第一個會浮現在腦中的可能都是我們今天的主角,也就是transformer
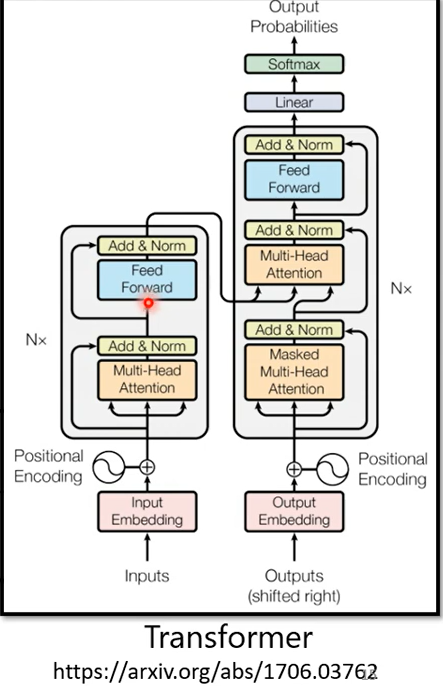
它有一個Encoder架構,有一個Decoder架構,它裡面有很多花花綠綠的block,等一下就會講一下這裡面每一個花花綠綠的block分別在做的事情是什麼。
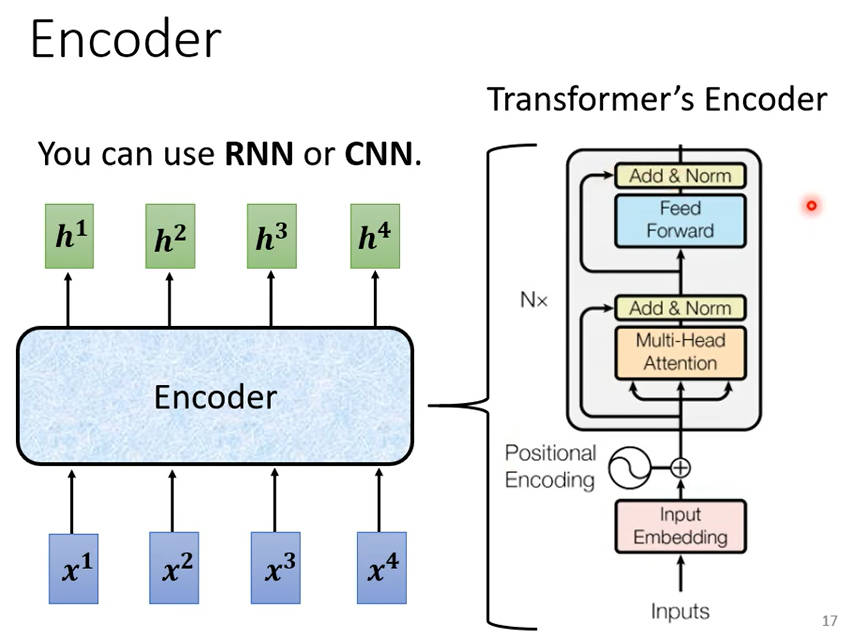
接下來 我們就來講Encoder的部分,seq2seq's model Encoder要做的事情就是給一排向量輸出另外一排向量給一排向量 。輸出一排向量這件事情很多模型都可以做到,可能第一個想到的是我們剛剛講完的self-attention,其實不只self-attention,RNN CNN 其實也都能夠做到input一排向量output另外一個同樣長度的向量,在transformer裡面transformer的Encoder用的就是self-attention。
這邊看起來有點複雜,我們用另外一張圖來仔細地解釋一下這個Encoder的架構,等一下再來跟原始的transformer的論文裡面的圖進行比對
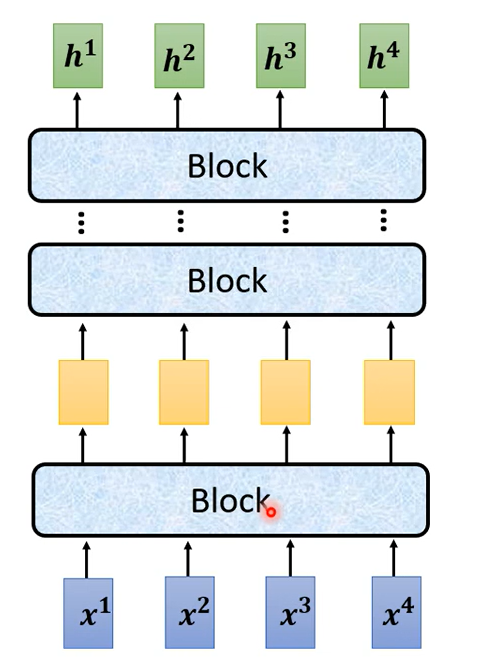
現在的Encoder裡面會分成很多很多的block,每一個block都是輸入一排向量輸出一排向量,你輸入一排向量 第一個block輸出另外一排向量,再輸給另外一個block,到最後一個block會輸出最終的vector sequence,每一個block 其實並不是neural network的一層,這邊之所以不稱說每一個block是一個layer是因為每一個block裡面做的事情是好幾個layer在做的事情。
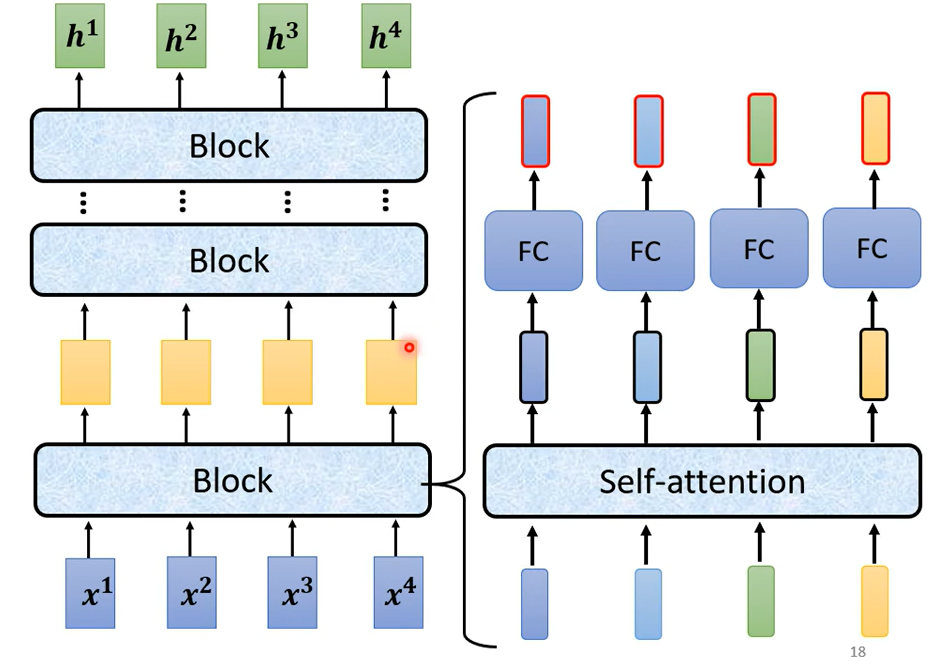
在transformer的Encoder裡面每一個block做的事情大概是這樣子的,先做一個self-attention,input一排vector以後做self-attention考慮整個sequence的資訊,Output另外一排vector.接下來這一排vector會再丟到fully connected的feed forward network裡面再output另外一排vector,這一排vector就是block的輸出。
事實上在原來的transformer裡面它做的事情是更複雜的,實際上做的事情是這個樣子的,它加入了一個設計
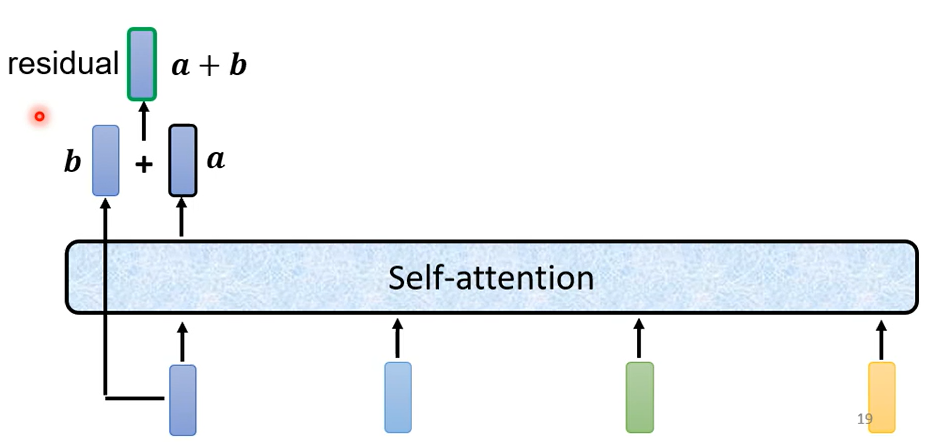
加入了residual connection(残差网络架构)
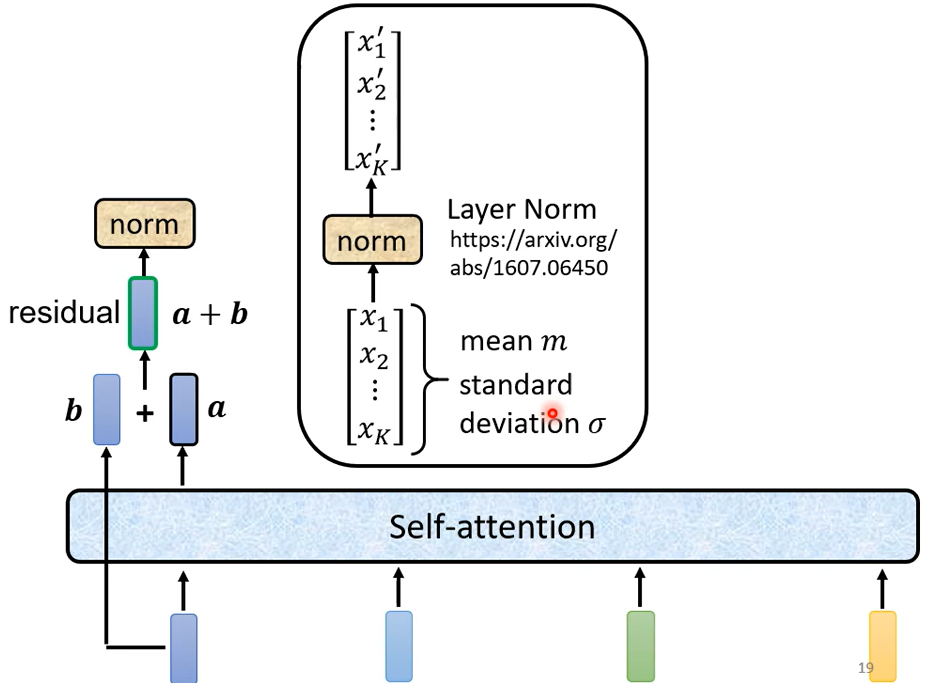
得到residual的結果以後再把它做一件事情叫做normalization,這邊用的不是batch normalization這邊用的叫做layer normalization,layer normalization做的事情比bacth normalization更簡單一點,layer normalization做的事情是這個樣子的,輸入一個向量 輸出另外一個向量,這邊不需要考慮batch,剛剛在講batch normalization的時候需要考慮batch,那這邊這個layer normalization不用考慮batch的資訊輸入一個向量, 輸出另外一個向量,layer normalization做的事情是什麼呢,它會把輸入的這個向量,計算它的mean跟standard deviation。
但是要注意一下 剛才在講batch normalization的時候,在小批量(batch)维度上归一化。对于一个小批量中的每个样本,它使用整个小批量的数据来计算均值和方差。对这批样本的同一维度特征做归一化,归一化操作在每个小批量的样本之间共享参数。Layer Normalization在特征维度上进行归一化,即对于一个样本的所有特征进行归一化,而不是在整个小批量的样本之间。它更适合于RNN等时序数据模型,因为RNN中每个时间步的数据是逐个处理的,没有小批量的维度。
Batch Normalization 适合大批量、独立同分布的数据,常用于卷积和全连接网络。
Layer Normalization 适合处理单样本、特征相关性较强的情况,常用于RNN和Transformer等网络。
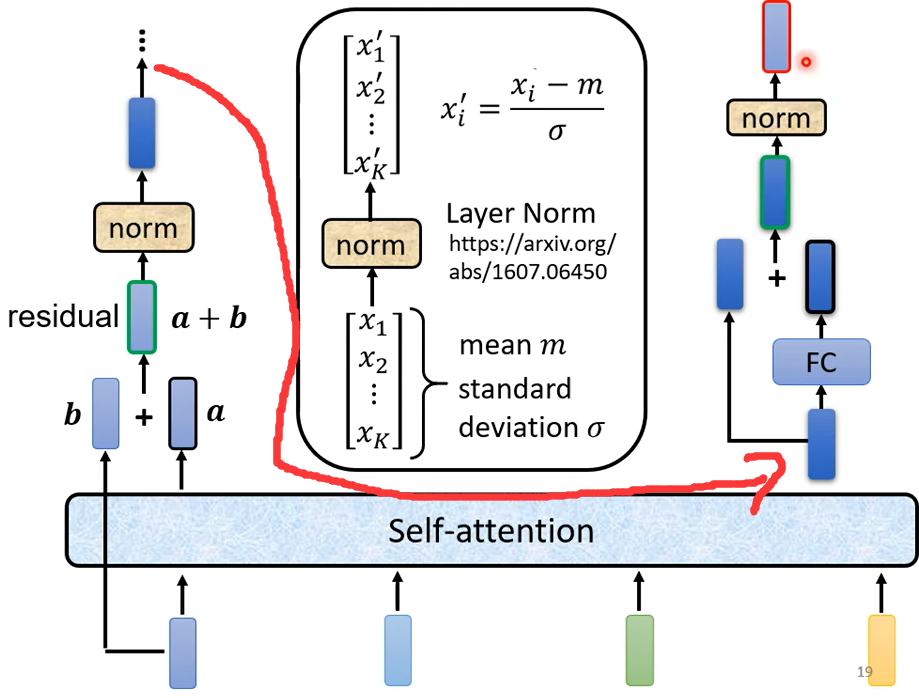
所以這個是挺複雜的,所以我們這邊講的 這一個圖其實就是我們剛才講的那件事情,
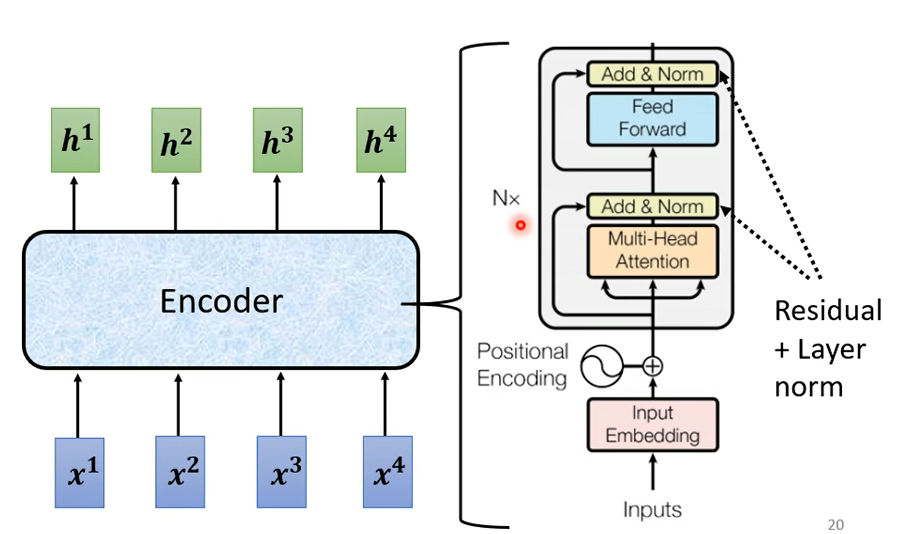
首先 你有self-attention,其實在input的地方還有加上positional encoding,我們之前已經有講過如果你只光用self-attention你沒有未知的資訊,所以你需要加上positional的information,然後在這個圖上有特別畫出這一塊它這邊寫一個Multi-Head Attention,這邊有一個Add&norm是什麼意思就是residual加layer normalization,我們剛才有說self-attention有加上residual的connection加下來還要過layer normalization,這邊這個圖上的Add&norm就是residual加layer norm的意思,接下來 這邊要過feed forward networkfc的feed forward network以後再做一次Add&norm再,做一次residual加layer norm才是一個block的輸出,然後這個block會重複n次。
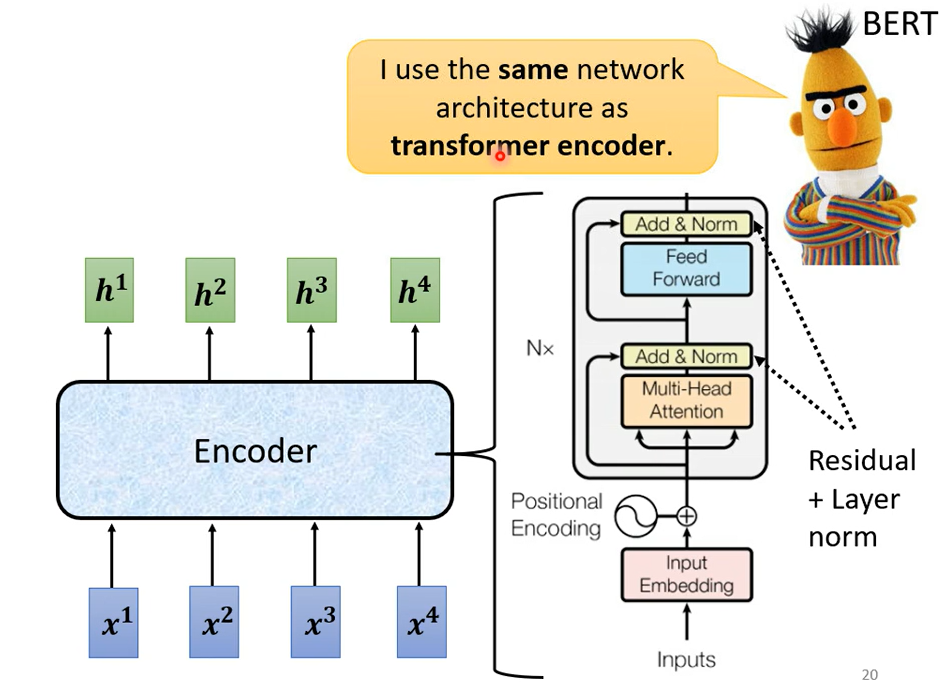
這個複雜的block其實在之後會講到的一個非常重要的模型BERT裡面會再用到 ,BERT它其實就是transformer的encoder,講到這邊 你心裡一定充滿了問號,就是為什麼 transformer的encoder要這樣設計 ,不這樣設計行不行,行 不一定要這樣設計這個encoder的network架構,現在設計的方式我是按照原始的論文講給你聽的,但原始論文的設計 不代表它是最好的
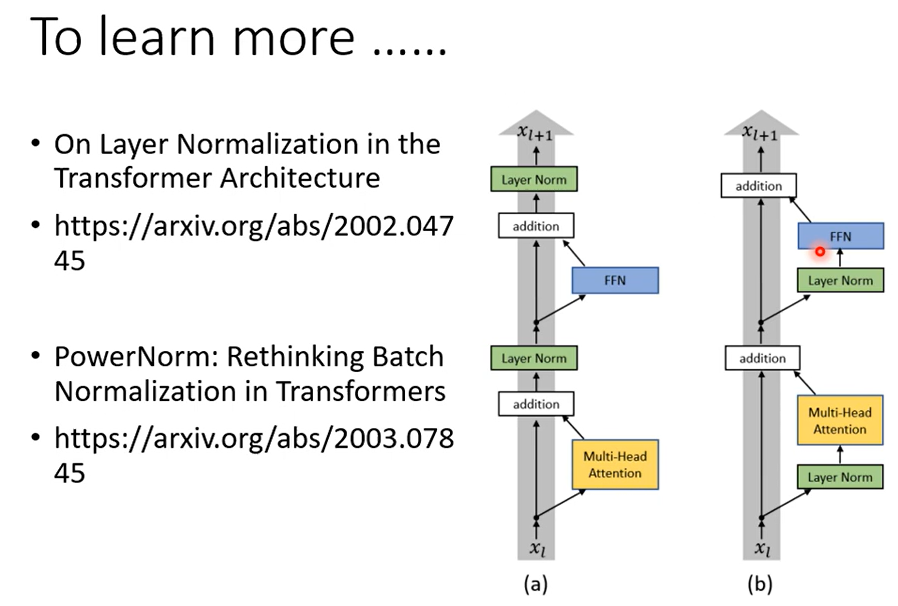
舉例來說有一篇文章叫on layer normalization in the transformer architecture,它問的問題就是 為什麼layer normalization是放在那個地方呢,為什麼我們是先做residual再做layer normalization,能不能夠把layer normalization放到每一個block的input,也就是說 你做residual以後再做layer normalization再加進去 ,你可以看到說左邊這個圖是原始的transformer右邊這個圖是稍微把block更換一下順序以後的transformer,更換一下順序以後 結果是會比較好的。
這就代表說原始的transformer 的架構並不是一個最optimal的設計,你永遠可以思考看看有沒有更好的設計方式,再來還有一個問題就是為什麼是layer norm 為什麼不是別的,為什麼不做batch normalization。也許這篇paper可以回答你的問題,這篇paper是Power Norm:Rethinking Batch Normalization In Transformers它首先告訴你說 在Transformers裡面為什麼batch normalization不如layer normalization。接下來在說它提出來一個power normalization,一聽就是很power的意思,都可以比layer normalization還要performance差不多或甚至好一點
Decoder
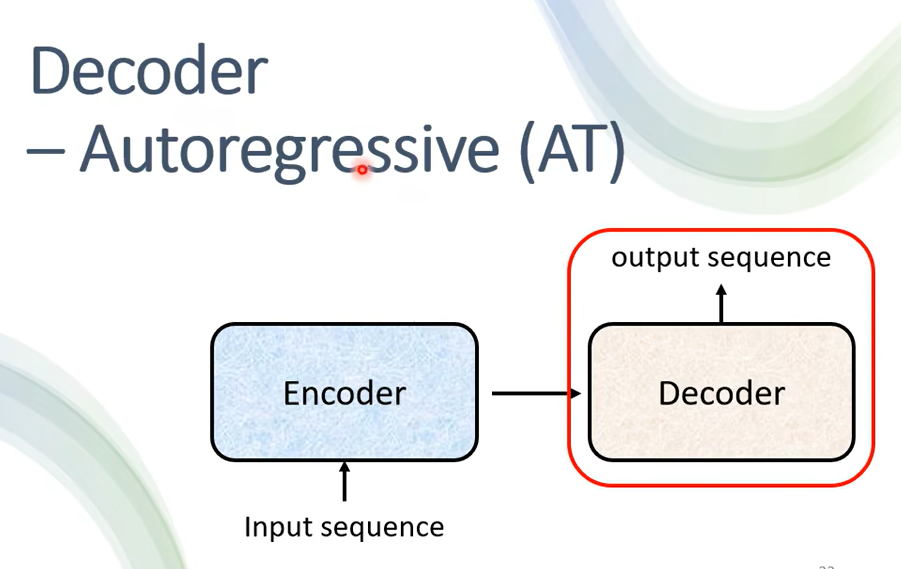
那 Decoder 呢 其實有兩種,等一下呢會花比較多時間介紹你比較常見的這個叫做 Autoregressive 的 Decoder
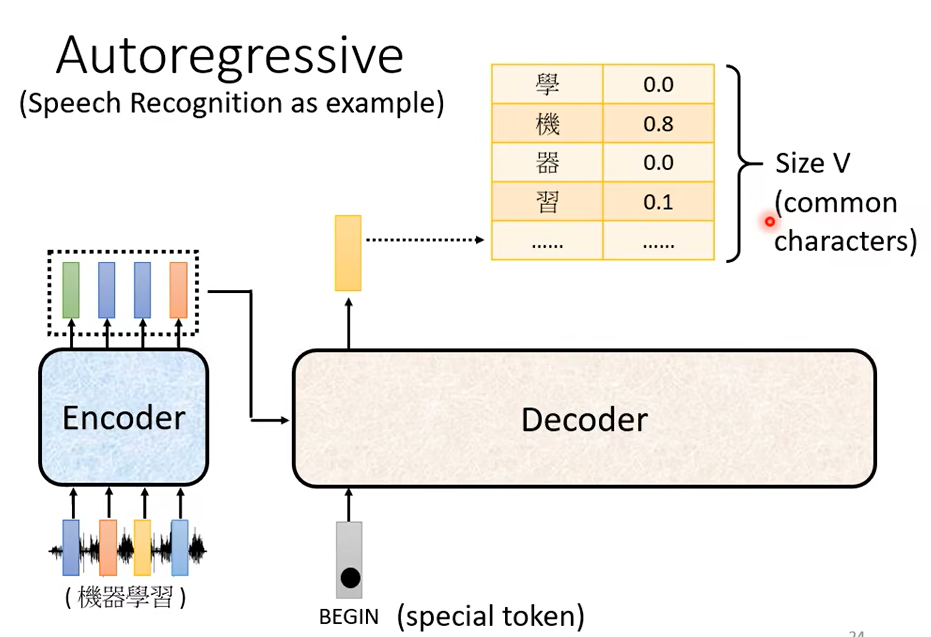
那這個 Autoregressive 的 Decoder是怎麼運作的呢,那等一下我們是用語音辨識來當作例子來跟大家說明,或用在作業裡面的機器翻譯其實是一模一樣的,你只是把輸入輸出改成不同的東西而已好, 那語音辨識是怎麼做的呢,語音辨識你知道語音辨識就是輸入一段聲音輸出一串文字,那你會把一段聲音輸入給 Encoder,比如說你對機器說機器學習機器,收到一段聲音訊號聲音訊號呢 進入 Encoder以後輸出會是什麼呢,輸出會變成一排 Vector。
那 Decoder 做的事情就是把 Encoder 的輸出先讀進去,那 Decoder 怎麼產生一段文字呢,你要先給它一個特殊的符號,這個特殊的符號呢代表開始,那這個是一個 Special 的 Token,你就在你可能本來 Decoder 可能產生的文字裡面呢多加一個特殊的符號就代表了 BEGIN,代表了開始這個事情,好 所以 Decoder 呢就吃到這個特殊的符號,那在這個機器學習裡面啊假設你要處理 NLP 的問題每一個 Token你都可以把它用一個 One-Hot 的 Vector 來表示,所以 BEGIN 也是用 One-Hot Vector 來表示,那接下來呢Decoder 會吐出一個向量,這個 Vector 的長度啊它很長,它的長度呢跟你的 Vocabulary 的 Size 是一樣的,你就先想好說你的 Decoder 輸出的單位是什麼,假設我們今天做的是中文的語音辨識,我們 Decoder 輸出的是中文,那你這邊的 Vocabulary 的 Size 啊可能就是中文的方塊字的數目,那不同的字典給你的數字可能是不一樣的,常用的中文的方塊字大概兩 三千個,一般人呢可能認得的四 五千個
每一個中文的字都會對應到一個數值,那因為在產生這個向量之前啊你通常會先跑一個 Softmax,它這個向量裡面的值
全部加起來總和會是 1
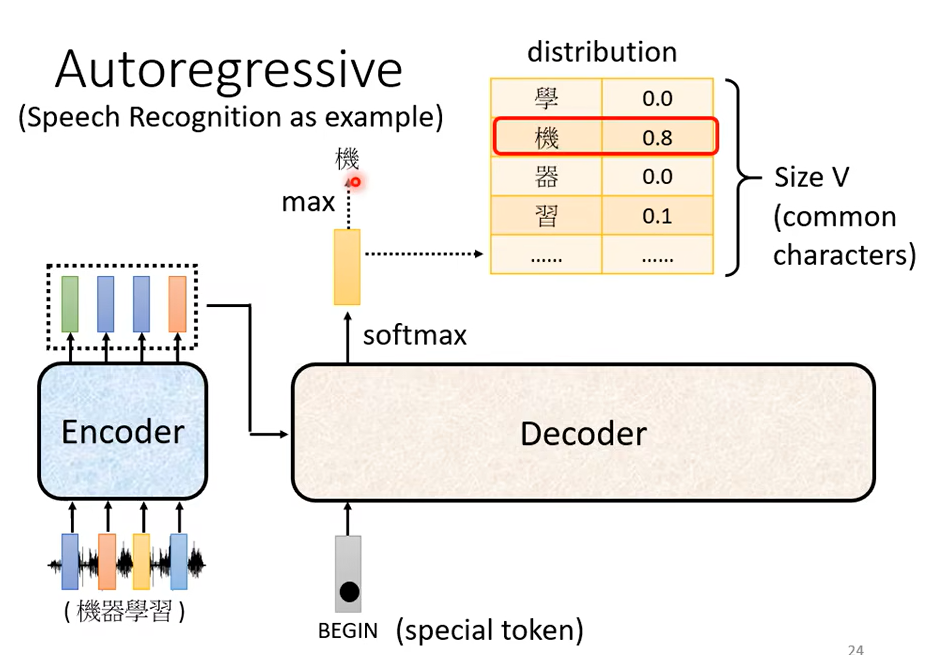
那在這個例子裡面,機的分數最高,所以機就當做是這個 Decoder 第一個輸出
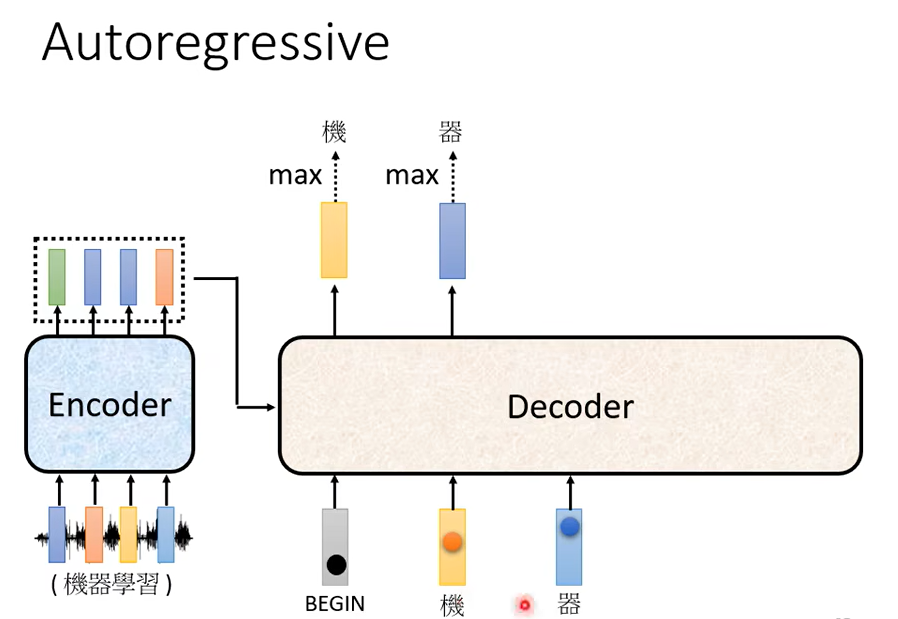
你把機當做是 Decoder 新的 Input,原來 Decoder 的 Input只有 BEGIN 這個特別的符號,現在它除了 BEGIN 以外它還有機作為它的 Input。
那 Decoder 接下來會拿器當作輸入,然後現在 Decoder 看到了 BEGIN看到了機 看到了器,那它接下來呢還要再決定接下來要輸出什麼
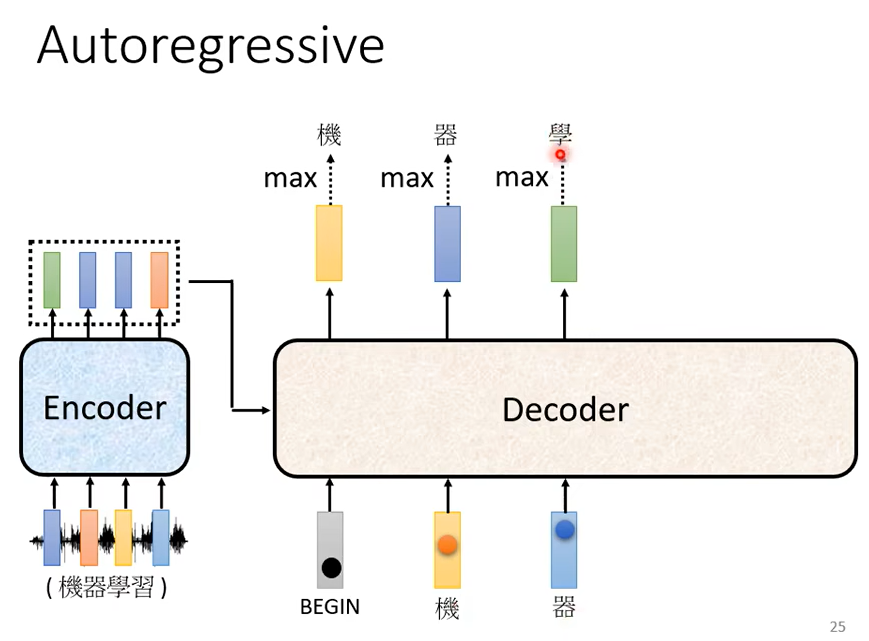
那它可能就输出学,
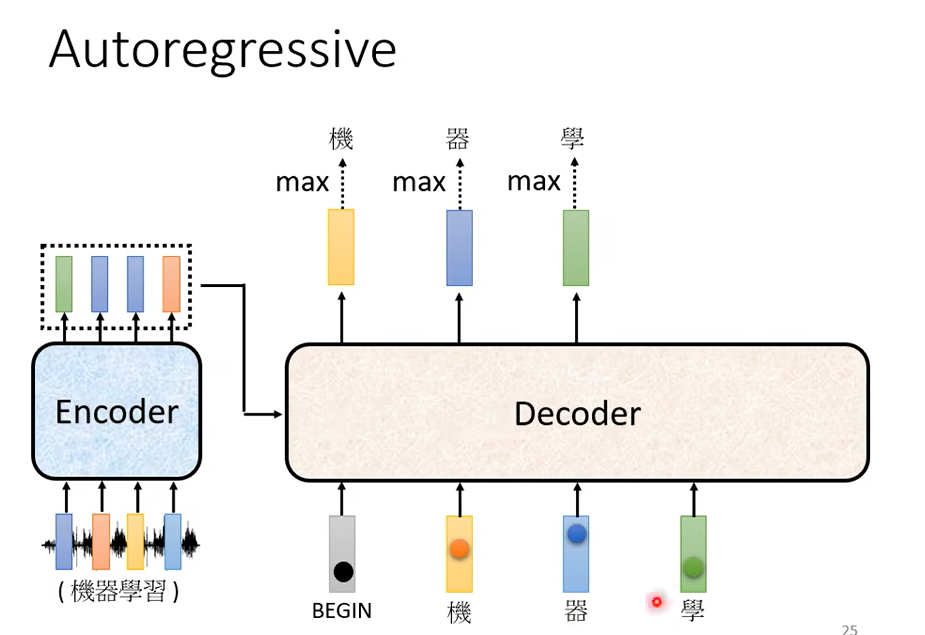
機器輸出學以後,學會再被當作輸入,所以現在 Decode 它看到了 BEGIN 機 器還有學,Encoder 這邊其實也有輸入啦
我們等一下再講 Encoder 的輸入,Decoder 是怎麼處理的。所以 Decoder 看到 Encoder 這邊的輸入,看到機 看到器 看到學
決定接下來要輸出習。
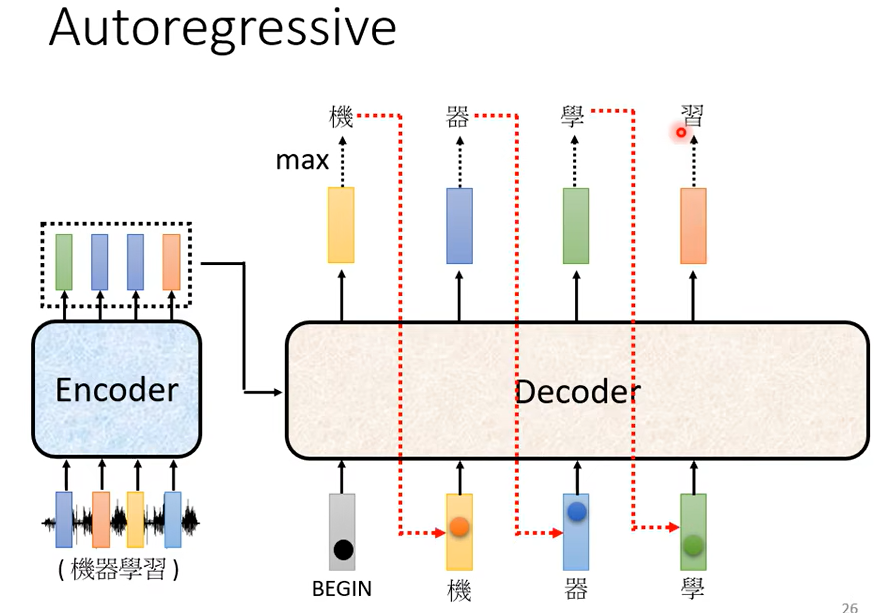
它會輸出一個向量,這個向量裡面習這個中文字的分數最高的,所以它就輸出習。
Decoder 會把自己的輸出當做接下來的輸入,那如果今天 Decoder 有語音辨識的錯誤,它把機器的器辨識錯成天氣的氣,那接下來 Decoder 就會看到錯誤的辨識結果,那你可能會覺得說讓 Decoder 看到錯誤的輸入,再被 Decoder 自己吃進去會不會造成問題呢,會不會造成 Error Propagation 的問題呢,所謂 Error Propagation 的問題就是一步錯 步步錯這樣。有可能,那這個等一下我們最後會稍微講一下這個問題要怎麼處理。
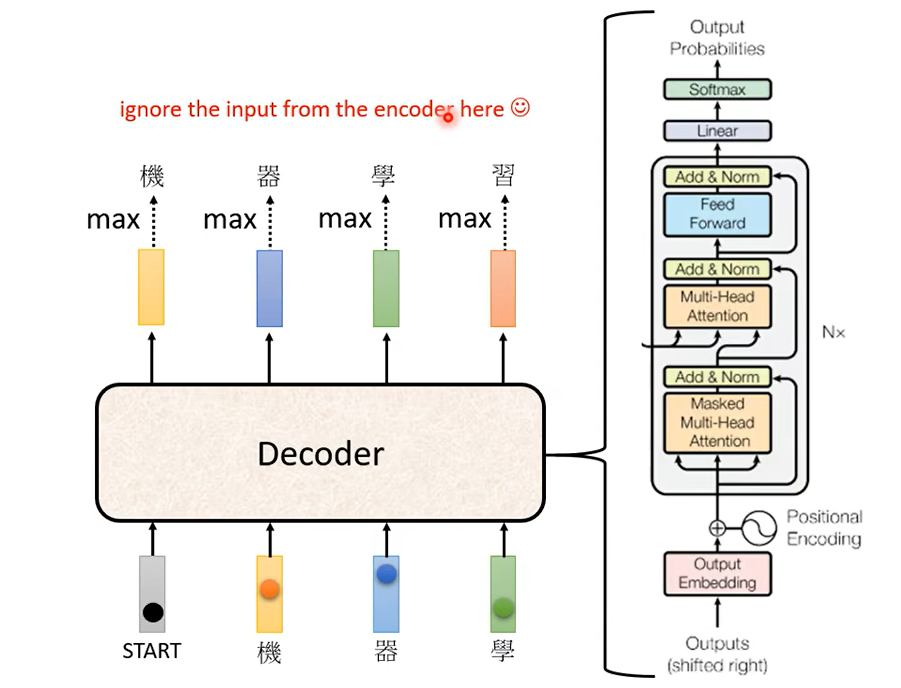
在 Transformer 裡面Decoder 的結構呢長得是這個樣子的,看起來有點複雜,比 Encoder 還稍微複雜一點。把Incoder和Decoder放在一起
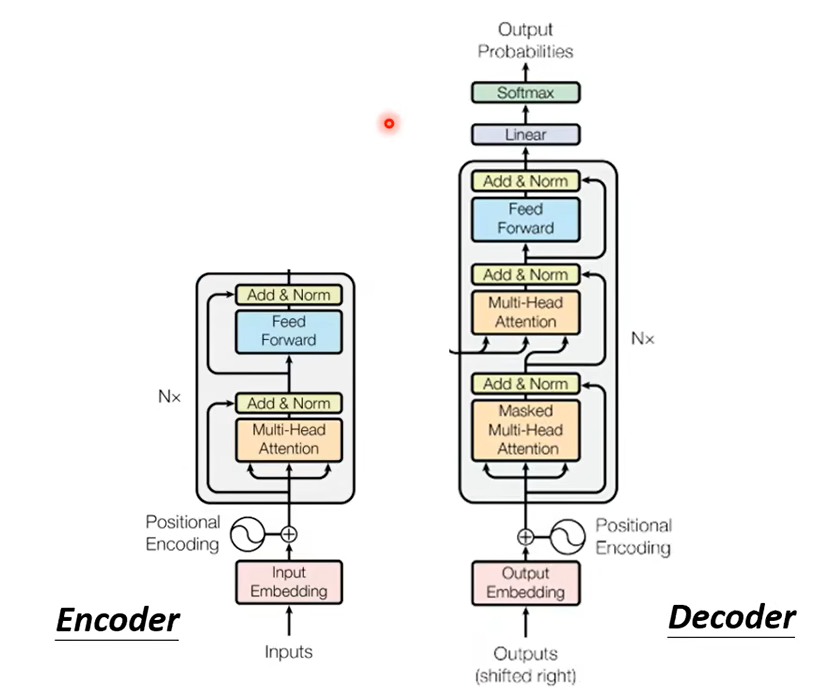
稍微比較一下它們之間的差異,你會發現說如果我們把 Decoder 中間這一塊,把它蓋起來,其實 Encoder 跟 Decoder並沒有那麼大的差別。
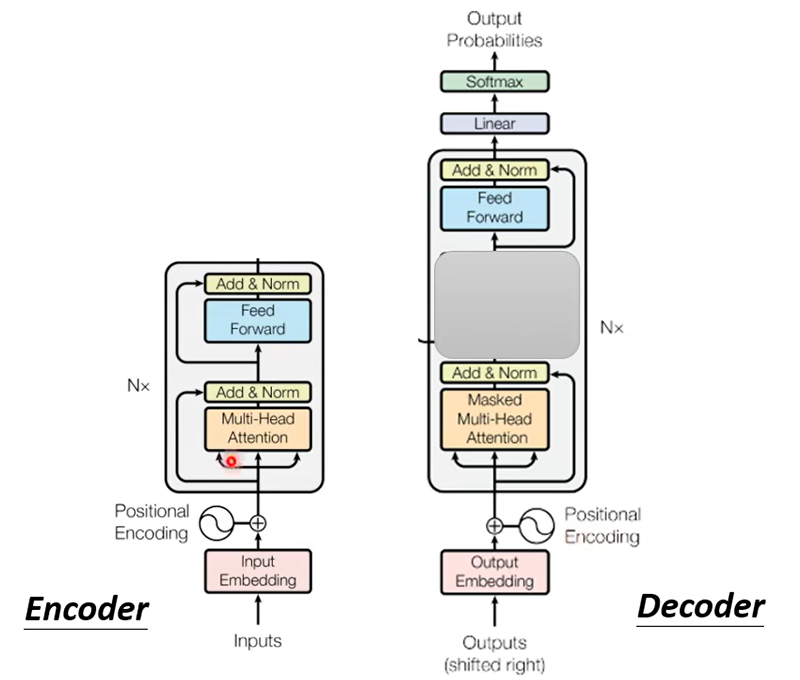
那這邊有一個稍微不一樣的地方,是在 Decoder 這邊Multi-Head Attention 這一個 Block 上面還加了一個 Masked,這個 Masked 是什麼意思呢
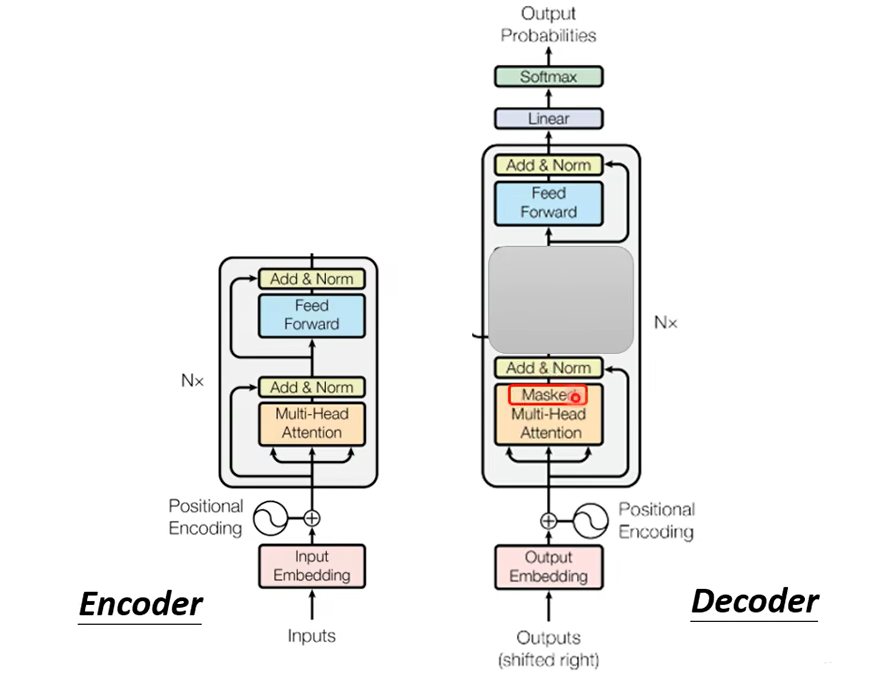
這是我們原來的 Self-Attention
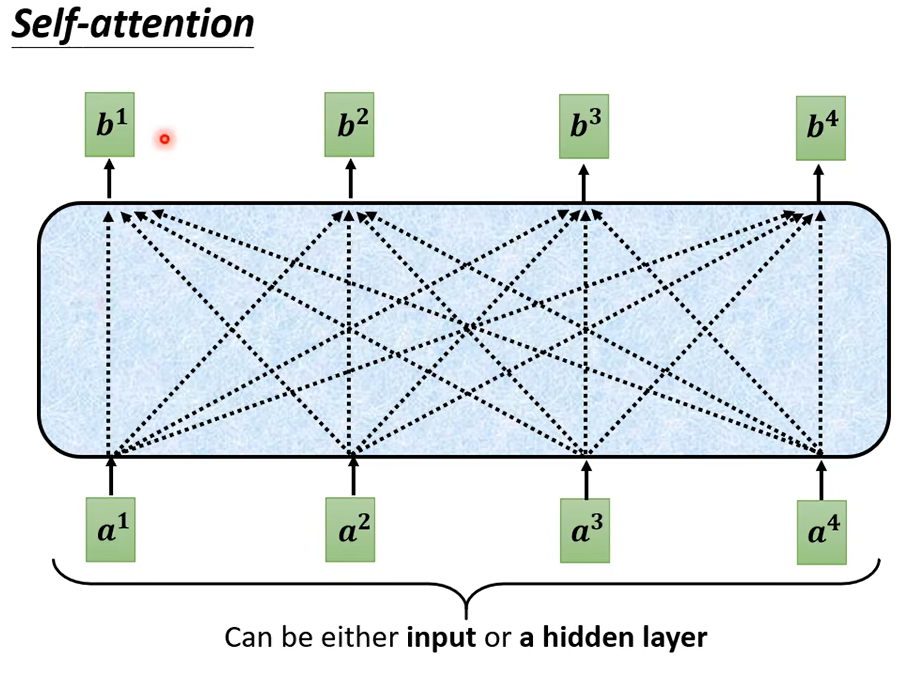
Input 一排 Vector,Output 另外一排 Vector,這一排 Vector 每一個輸出都要看過完整的 Input 以後才做決定,所以輸出 b1 的時候
其實是根據 a1 到 a4 所有的資訊去輸出 b1。
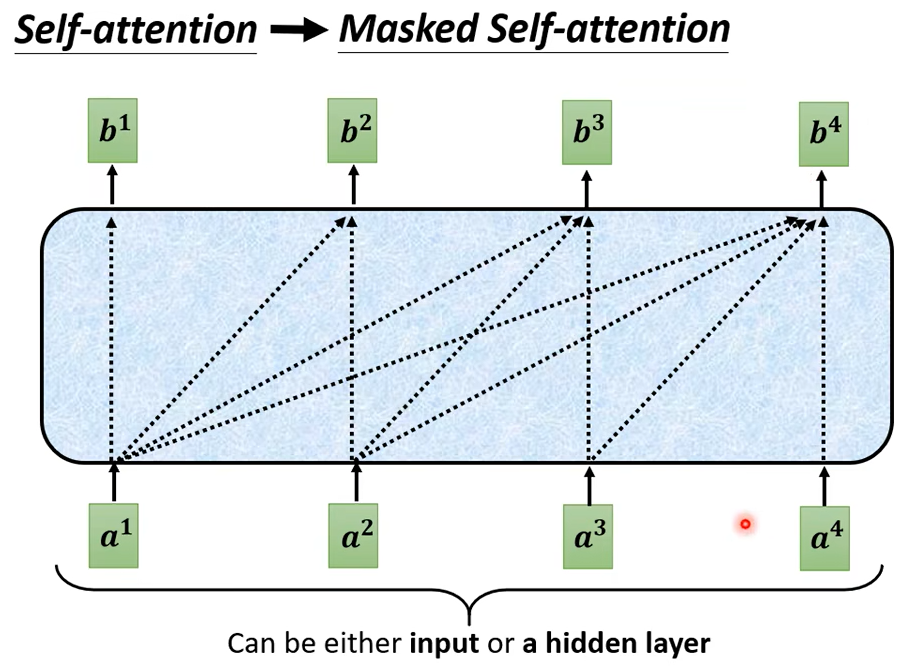
當我們把 Self-Attention轉成 Masked Attention 的時候它的不同點在哪裡,它的不同點是現在我們不能再看右邊的部分,也就是產生 b1 的時候我們只能考慮 a1 的資訊,你不能夠再考慮 a2 a3 a4,產生 b2 的時候你只能考慮 a1 a2 的資訊不能再考慮 a3 a4 的資訊,產生 b3 的時候你就不能考慮 a4 的資訊,產生 b4 的時候你可以用整個 Input Sequence 的資訊
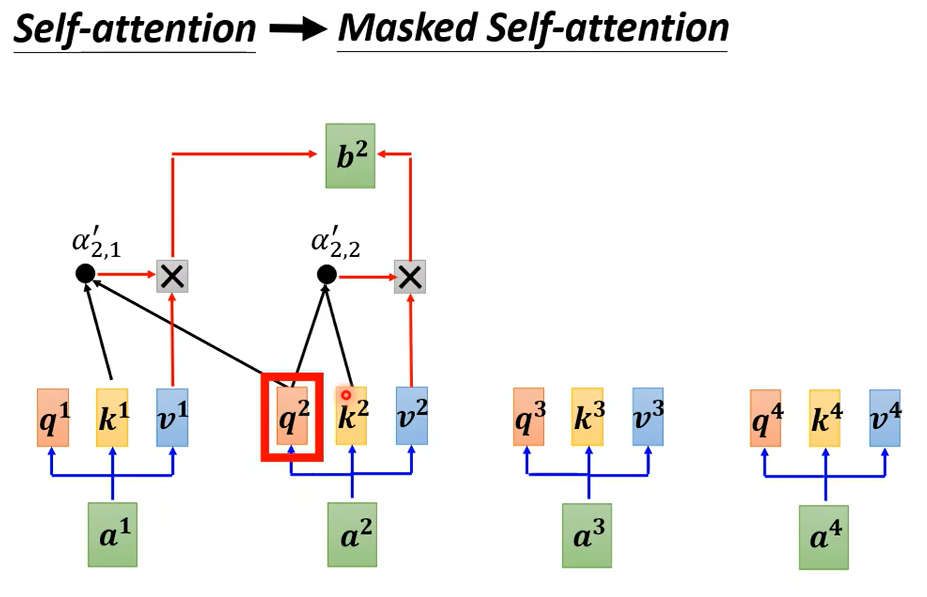
講得更具體一點你做的事情是這樣,當我們要產生 b2 的時候,我們只拿 b2 的 Query去跟第一個位置的 Key和第二個位置的 Key去計算 Attention,第三個位置跟第四個位置就不管它。
為什麼需要加 Masked 呢,這件事情其實非常地直覺。你想想看我們一開始 Decoder 的運作方式,它是一個一個輸出,它的輸出是一個一個產生的,所以是先有 a1 再有 a2再有 a3 再有 a4,這跟原來的 Self-Attention 不一樣,原來的 Self-Attention,a1 跟 a4 是一次整個輸進去你的 Model 裡面的。
還有一個非常關鍵的問題,這個關鍵的問題是Decoder 必須自己決定輸出的 Sequence 的長度,可是到底輸出的 Sequence 的長度應該是多少呢
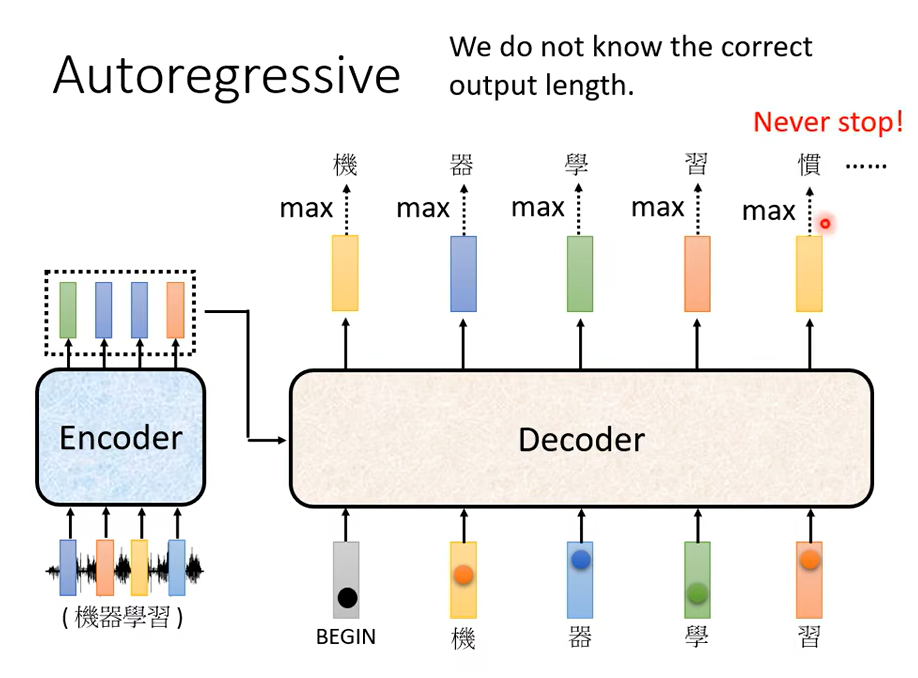
但在我們目前的這整個 Decoder的這個運作的機制裡面,機器不知道它什麼時候應該停下來,它產生完習以後,它還可以繼續重複一模一樣的 Process,就把習呢當做輸入,然後也許 Decoder 呢就會接一個慣,然後接下來呢就一直持續下去永遠都不會停下來
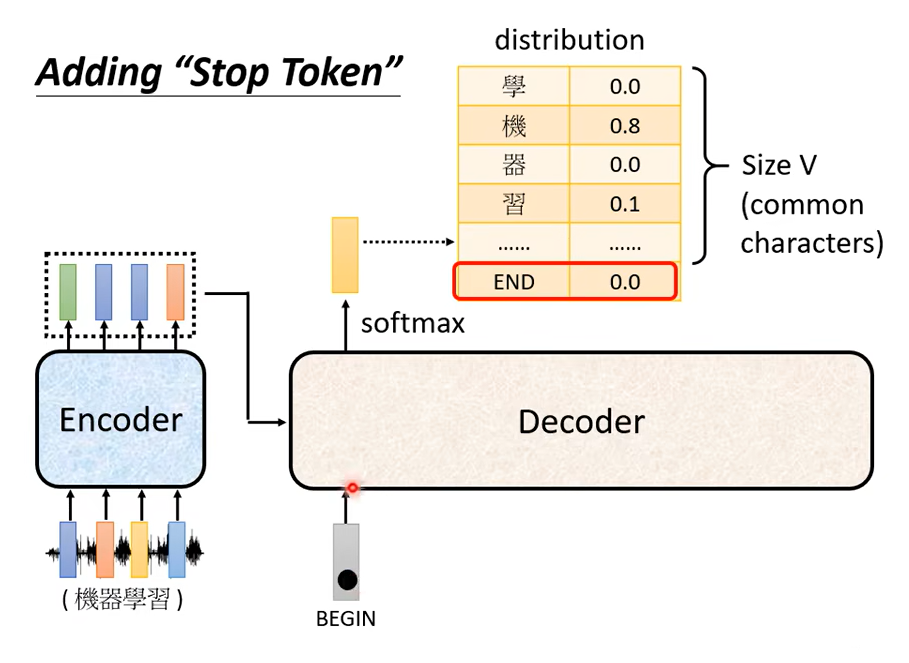
所以你要特別準備一個特別的符號,這個符號,用 END 來表示這個特殊的符號,所以除了所有中文的方塊字,還有 BEGIN 以外你還要準備一個特殊的符號。
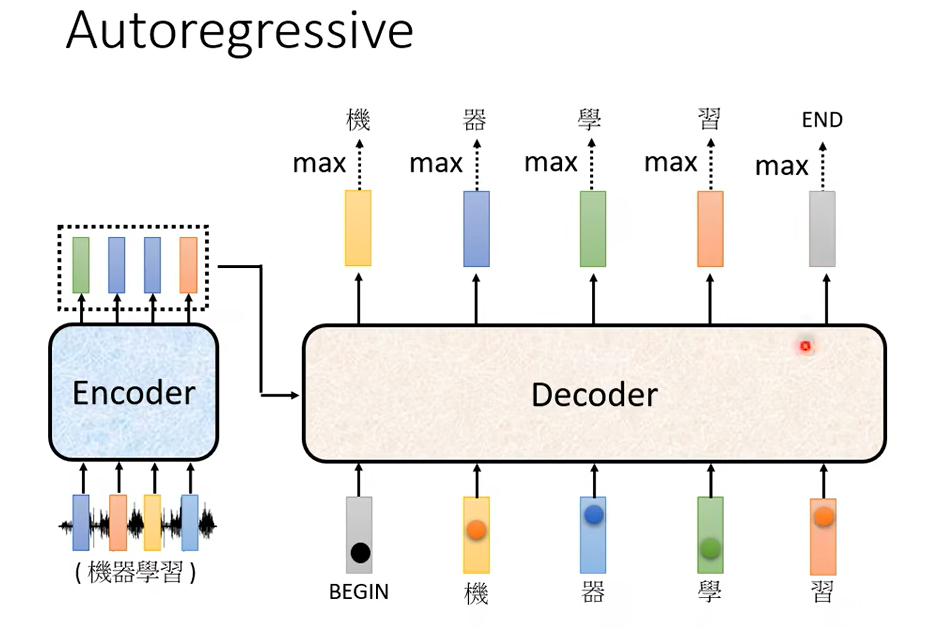
所以現在呢這樣 Decoder 它可以輸出 END 這個符號,那我們期待說當今天呢產生完習以後,再把習當作 Decoder 的輸入以後Decoder 就要能夠輸出END。
之前说过那 Decoder 呢 其實有兩種,下面介绍另外一种
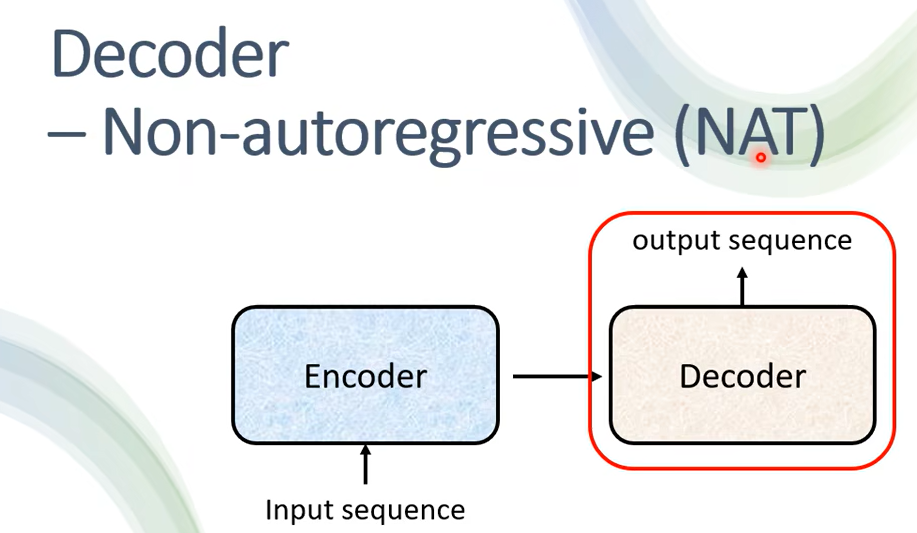
Non-Autoregressive 的 Model 是怎麼運作的呢,假設我們現在產生是中文的句子,它不是一次產生一個字,它是一次把整個句子都產生出來。
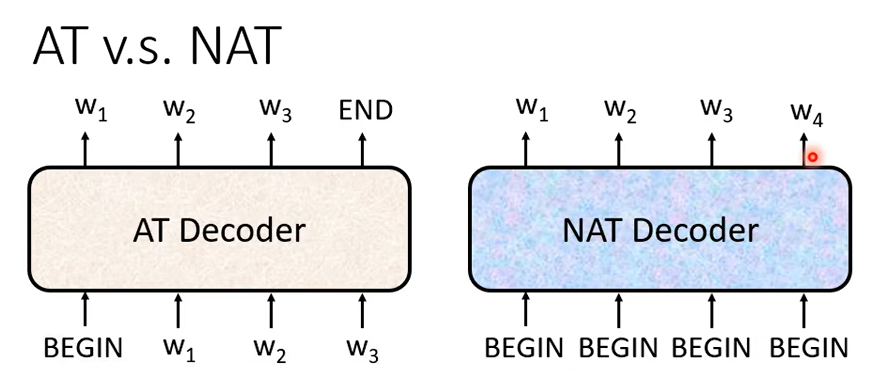
你丟給它 4 個 BEGIN 的 Token,它就產生 4 個中文的字,變成一個句子就結束了,所以它只要一個步驟就可以完成句子的生成。這邊你可能會問一個問題,剛才不是說不知道要有多輸出的長度應該是多少嗎,那我們這邊怎麼知道 BEGIN 要放多少個當做 NAT Decoder 的输入呢
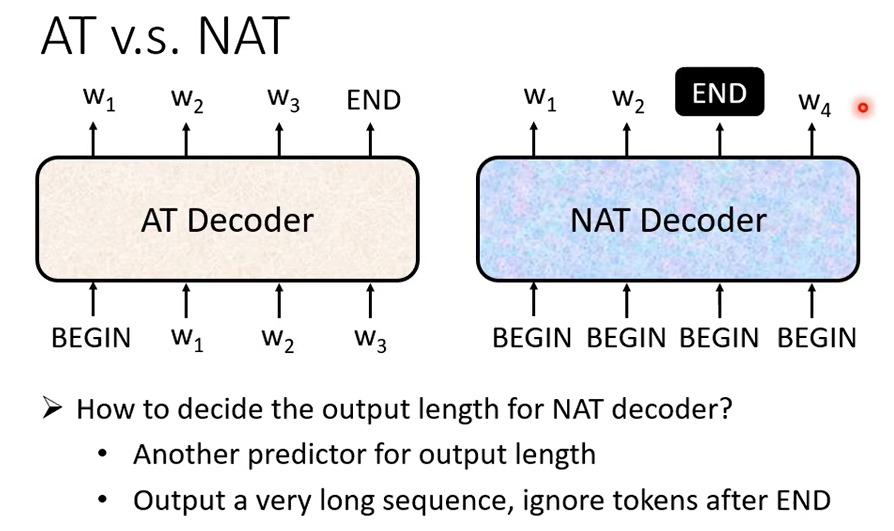
這件事沒有辦法很自然的知道,沒有辦法很直接的知道,所以有幾個做法,一個做法是你另外扔一個 Classifier,這個 Classifier 呢它吃 Encoder 的 Input,然後輸出是一個數字,這個數字代表 Decoder 應該要輸出的長度。
另一種可能做法就是你就不管三七二十一給它一堆 BEGIN 的 Token,你就假設說你現在輸出的句子的長度絕對不會超過 300 個字,你就假設一個句子長度的上限,然後 BEGIN 呢你就給它 300 個 BEGIN,然後就會輸出 300 個字,你再看看說什麼地方輸出 END,輸出 END 右邊的就當做它沒有輸出就結束了。
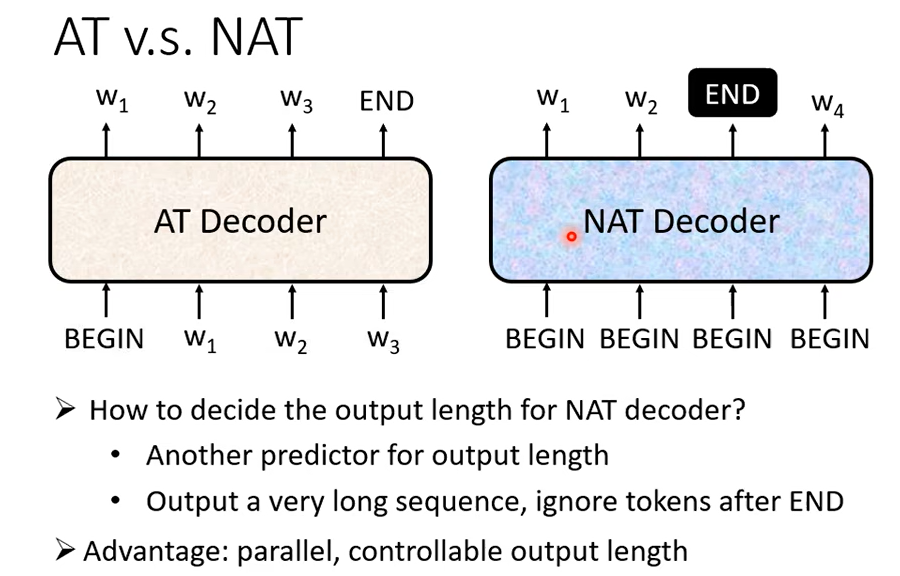
那 NAT 的 Decoder,它有什麼樣的好處呢,它第一個好處是平行化,這個 AT 的 Decoder它在輸出它的句子的時候是一個一個字產生的,所以你有你的假設要輸出長度一百個字的句子,那你就需要做一百次的 Decode,但是 NAT 的 Decoder 不是這樣,不管句子的長度如何,都是一個步驟就產生出完整的句子,所以在速度上NAT 的 Decoder 它會跑得比AT 的 Decoder 要快。
那你可以想像說這個 NAT Decoder 的想法顯然是在由這個 Transformer 以後,有這種 Self-Attention 的 Decoder 以後才有的,因為以前如果你是用那個 LSTM用 RNN 的話,那你就算給它一排 BEGIN它也沒有辦法同時產生全部的輸出,它的輸出還是一個一個產生的,所以在沒有這個 Self-Attention 之前只有 RNN只有 LSTM 的時候根本就不會有人想要做什麼 NAT 的 Decoder。
NAT 的 Decoder 還有另外一個好處就是,你比較能夠控制它輸出的長度,舉語音合成為例好了,其實在語音合成裡面NAT 的 Decoder 算是非常常用的,它並不是一個什麼稀罕 罕見的招數
比如語音合成,今天你都可以用Sequence To Sequence 的模型來做,那最知名的呢是一個叫做 Tacotron 的模型,它是 AT 的 Decoder
有另外一個模型叫 FastSpeech,它是 NAT 的 Decoder。那 NAT 的 Decoder 有一個好處就是你可以控制你輸出的長度,你可能有一個 Classifier決定 NAT 的 Decoder 應該輸出的長度,那如果在做語音合成的時候假設你現在突然想要讓你的系統講快一點加速,那你就把那個 Classifier 的 Output 除以二,它講話速度就變兩倍快,然後如果你想要這個講話放慢速度,那你就把那個 Classifier 輸出的那個長度啊它 Predict 出來的長度乘兩倍,那你的這個 Decoder 呢說話的速度就變兩倍慢,所以你可以如果有這種 NAT 的 Decoder,你就比較有機會去控制你的 Decoder 輸出的長度應該是多少,你就可以做種種的變化。
那為什麼 NAT 的 Decoder最近是一個熱門的研究主題呢,它之所以是一個熱門研究主題就是它雖然表面上看起來有種種的厲害之處,尤其是平行化是它最大的優勢,但是 NAT 的 Decoder 呢它的 Performance往往都不如 AT 的 Decoder。
所以發現有很多很多的研究試圖讓NAT 的 Decoder 的 Performance 越來越好,試圖去逼近 AT 的 Decoder,不過今天你要讓 NAT 的 Decoder跟 AT 的 Decoder Performance 一樣好你必須要用非常多的 Trick 才能夠辦到, AT 的 Decoder 隨便 Train 一下,NAT 的 Decoder 你要花很多力氣才有可能跟 AT 的 Performance 差不多。
為什麼 NAT 的 Decoder Performance 不好呢,有一個問題我們今天就不細講了,叫做 Multi-Modality 的問題,那如果你想要這個深入了解 NAT,看一下下面的课

那接下來我們就要講Encoder 跟 Decoder它們中間是怎麼傳遞資訊的了,也就是我們要講剛才我們刻意把它遮起來的那一塊,那如果你仔細觀察這一塊的話這塊呢叫做 Cross Attention
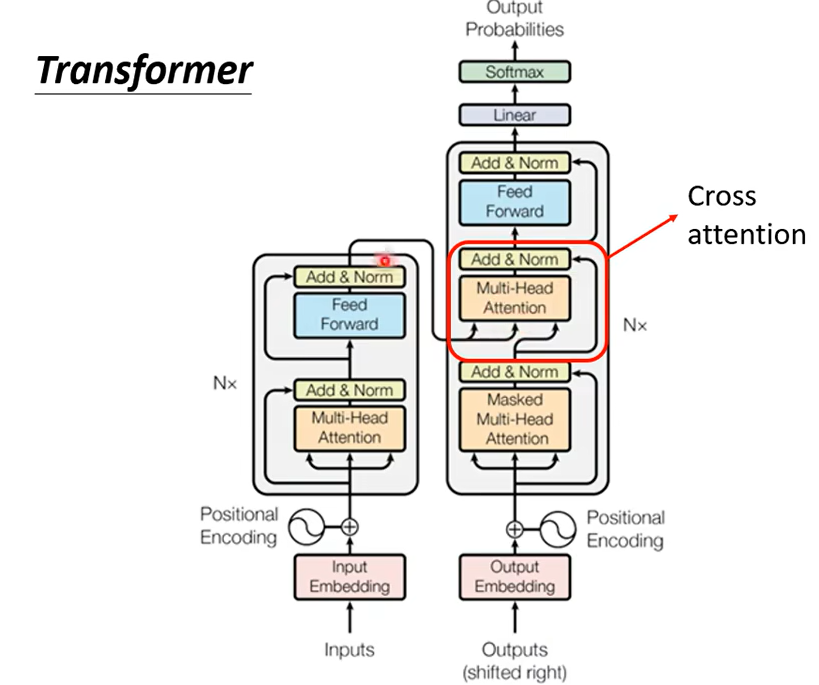
它是連接 Encoder 跟 Decoder 之間的橋樑,那這一塊裡面啊你會發現有兩個輸入來自於 Encoder,Encoder 提供兩個箭,頭然後 Decoder 提供了一個箭頭,所以從左邊這兩個箭頭,Decoder 可以讀到 Encoder 的輸出。那這個模組實際上是怎麼運作的呢
那我們就實際把它運作的過程跟大家展示一下
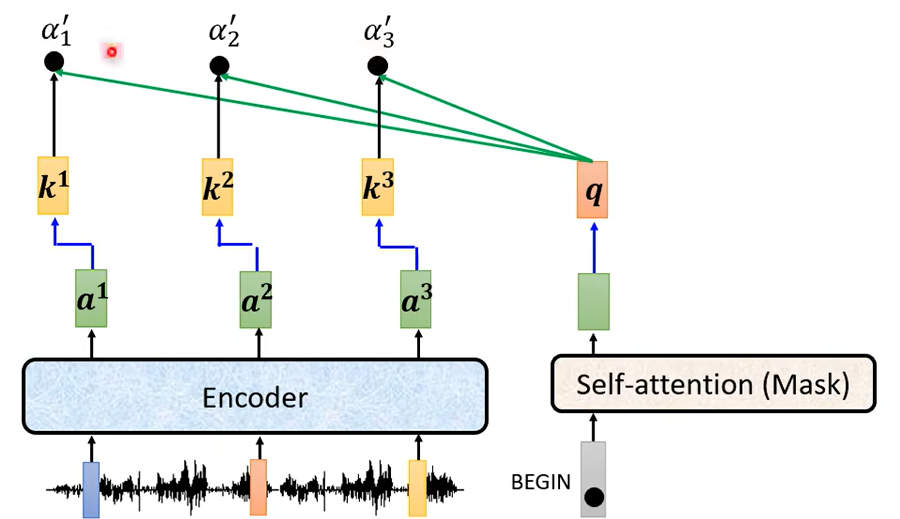
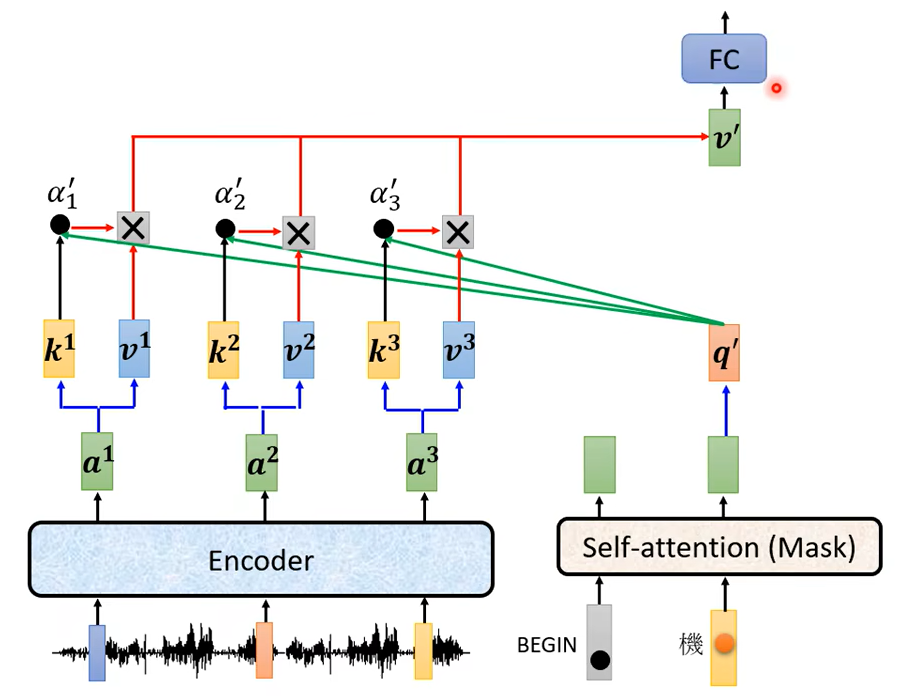
好 這個是你的 Encoder,輸入一排向量,輸出一排向量,我們叫它 a1 a2 a3接下來呢 輪到你的 Decoder,你的 Decoder 呢會先吃 BEGIN 這個 Special 的 Token,那 BEGIN 這個 Special 的 Token 讀進來以後你可能會經過 Self-Attention,這個 Self-Attention 是有做 Mask 的,然後得到一個向量,就是 Self-Attention 就算是有做 Mask還是一樣輸入多少長度的向量輸出就是多少向量,所以輸入一個向量 輸出一個向量,然後接下來把這個向量呢乘上一個矩陣做一個 Transform得到一個 Query 叫做 q,然後這邊的 a1 a2 a3 呢也都產生 Key,Key1 Key2 Key3那把這個 q 跟 k1 k2 k3去計算 Attention 的分數,得到 \(a1^{\prime} a2^{\prime} a3^{\prime}\)(你可能一樣會做 Softmax把它稍微做一下 Normalization所以我這邊加一個 '代表它可能是做過 Normalization)
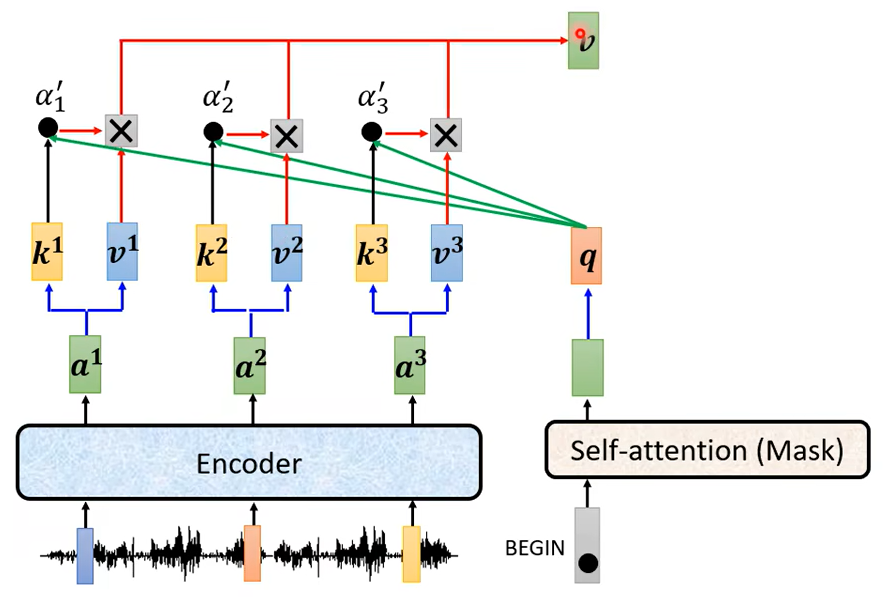
接下來再把\(a1^{\prime} a2^{\prime} a3^{\prime}\)就乘上 v1 v2 v3,再把它 Weighted Sum 加起來會得到 v
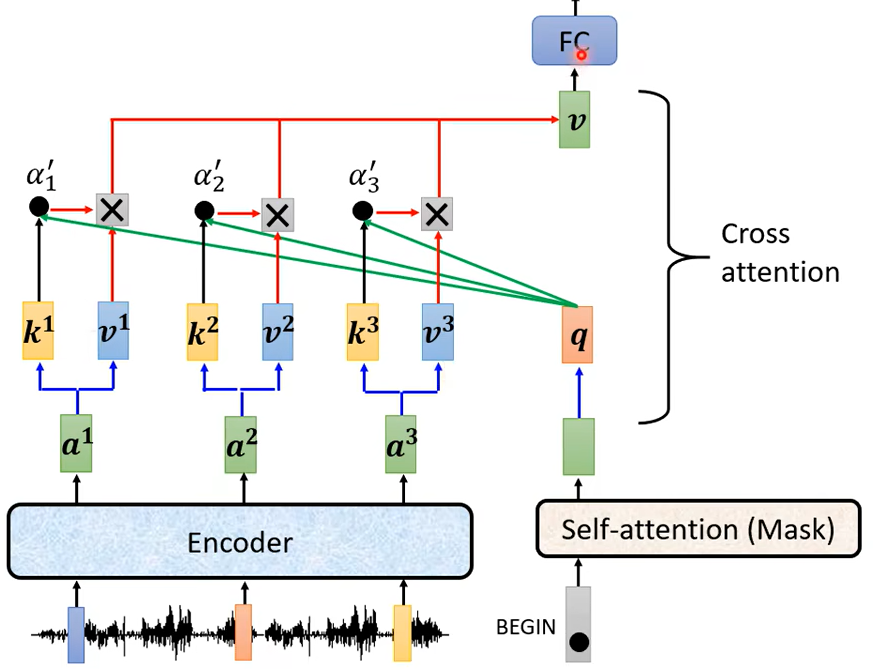
那這個步驟就是 q 來自於 Decoderk, 跟 v 來自於 Encoder,這個步驟就叫做 Cross Attention,所以 Decoder 就是憑藉著產生一個 q,去 Encoder 這邊抽取資訊出來當做接下來的 Decoder 的Fully-Connected 的 Network 的 Input,好 那這個就是 Cross Attention 運作的過程。
假设第一個這個中文的字產生一個機,接下來的運作也是一模一樣的
那這邊有一個實際的文獻上的 Cross Attention它所做的事情的效果展示,不過我這邊要稍微說明一下,這個圖並不是來自於 Transformer。這篇 Paper 它的 Title 叫做Listen, Attend And Spell,是比較早使用 Sequence To Sequence Model成功做語音辨識的一篇文章,它發表在 ICASS 2016
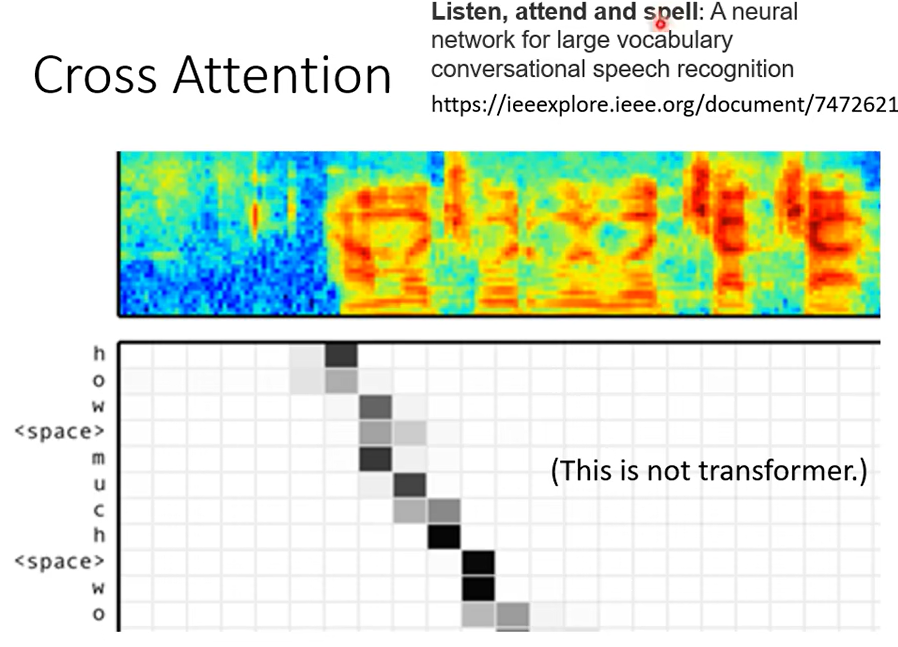
它展現的 Sequence To Sequence Model其實沒有贏過 State Of The Art(就是當時最好的語音辨識系統)但是只差一點點而已,所以讓大家覺得說Sequence To Sequence 用在語音辨識上似乎是有潛力的, 那時候的 Encoder 跟 Decoder 都是用 LSTM,不過那個時候就已經有 Cross Attention這樣子的機制了,所以在有 Transformer 之前其實就已經有 Cross Attention 這樣的機制,只是沒有 Self-Attention 的機制,所以是先有 Cross Attention後來才有 Self-Attention。
然後我特別放這個圖是想要跟你讓你想可以比較容易想像這個 Cross Attention 是怎麼運作的,上面這一段是聲音訊號是機器的輸入,那聲音訊號輸入給這個 Encoder 的時候它是用一排向量來表示,Decoder 一次只吐一個英文的字母,所以它會吐 h 吐 o 吐 w就代表 how那如果它已經到一個詞彙的邊界它會自動吐出空白,空白當做是一個特殊的字母來處理。
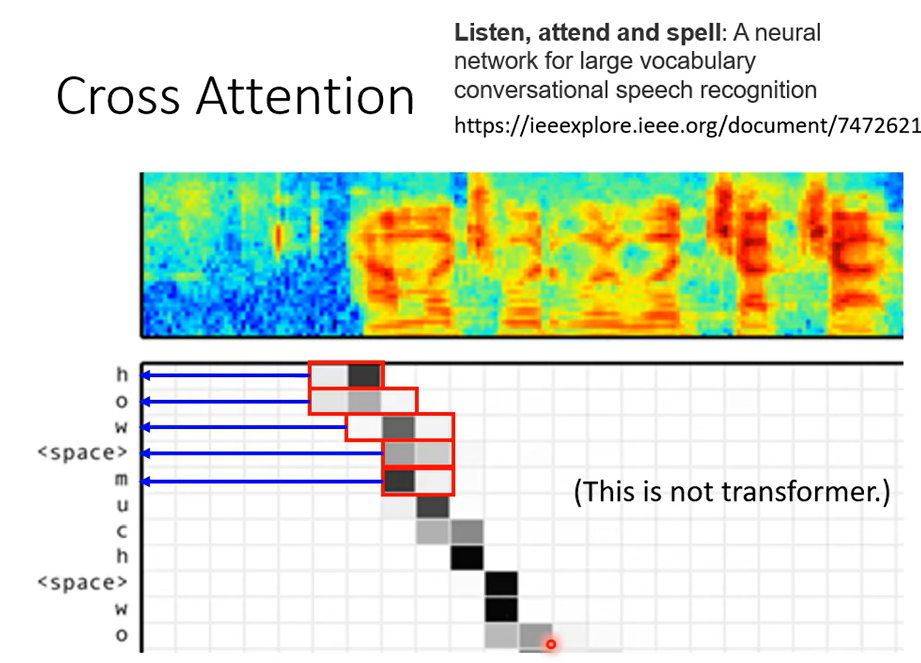
那這邊這個值是什麼呢(图中的方块),這個值就是 Attention 的分數,所以當你要產生這個 H 的時候,在產生這個 H 之前你的 Decoder 會去對 Encoder 的輸出做 Attention,顏色越深就代表說那個 Attention 的那個分數啊α 的值越大,所以你會發現說它產生 h 的時候它就是聽到這個地方有 h 的聲音,所以產生 h,那接下來再往右移一點產生 o,再往右移一點產生 w,然後接下來呢Attend 在這個地方產生 Space,然後 Attend 在這個地方產生 m,那你會看到說這個Attention 的這個 Weight是由左上到右下移動的,那跟你想像 Attention 應該運作的機制很像
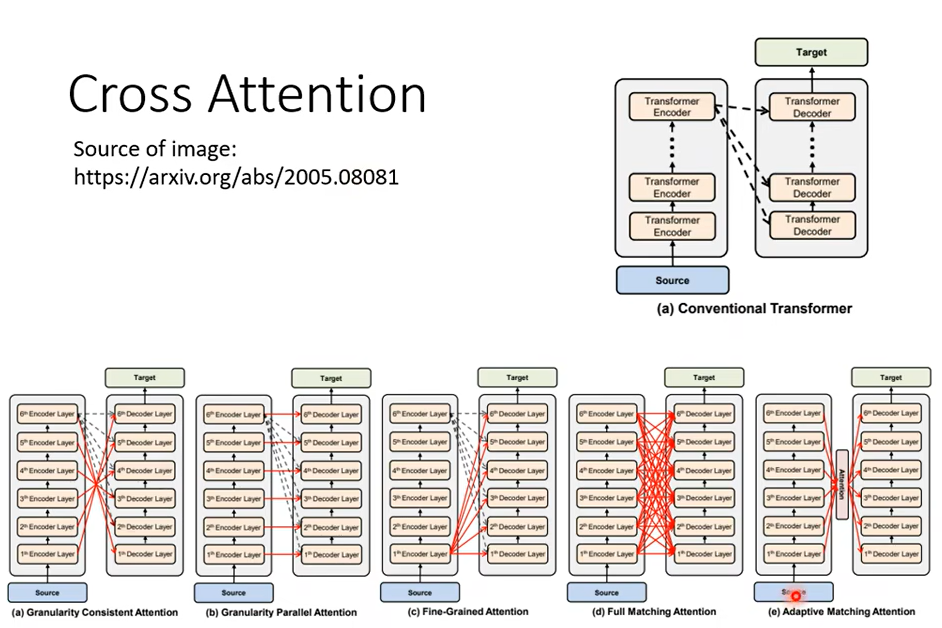
那講到這邊也許有同學會問說那這個 Encoder 有很多層啊,Decoder 也有很多層啊,從剛才的講解裡面好像聽起來這個 Decoder 不管哪一層都是拿 Encoder 的最後一層的輸出,這樣對嗎,對,在原始 Paper 裡面的實做是這樣子,那一定要這樣嗎,不一定要這樣,你永遠可以自己兜一些新的想法,所以我這邊就是引用一篇論文告訴你說也有人嘗試不同的 Cross Attension 的方式。
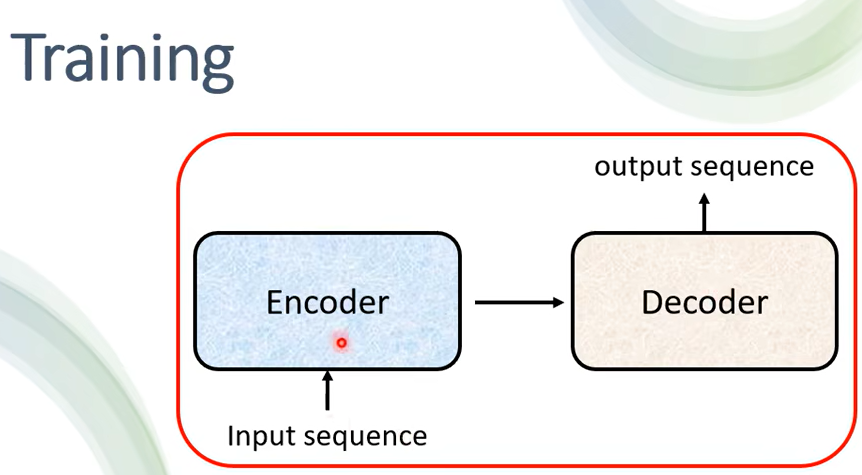
那最後呢我們就要講訓練這件事了,我們已經講了 Encoder,講了 Decoder,講了 Encoder Decoder 怎麼互動的,你已經清楚說 Input 一個 Sequence是怎麼得到最終的輸出,那接下來就進入訓練的部分。
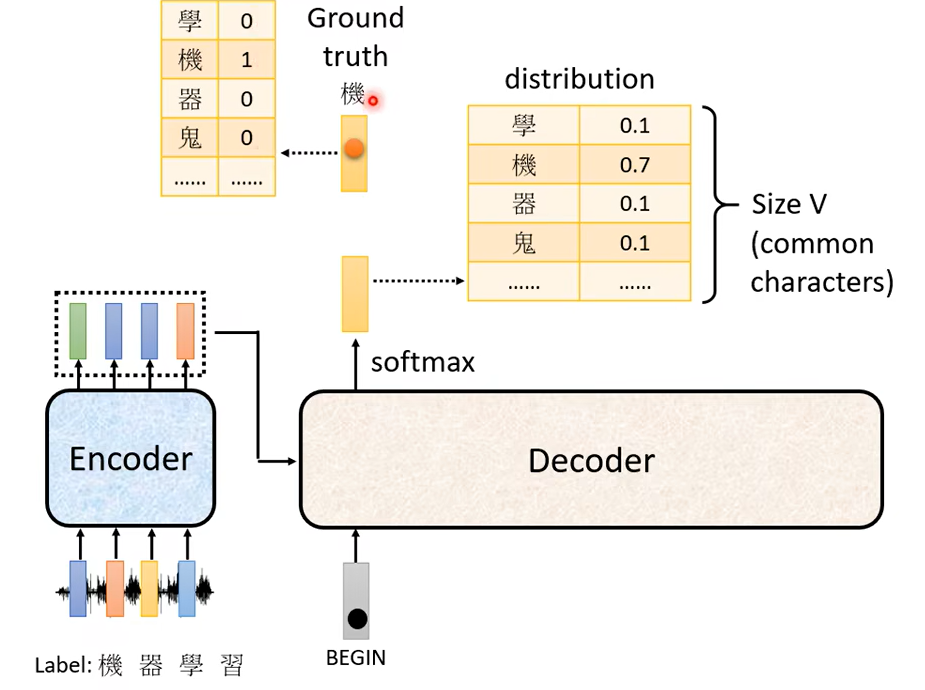
你要蒐集一大堆的聲音訊號,每一句聲音訊號都要有工讀生來聽打一下,打出說它的這個對應的詞彙是什麼,工讀生聽這段是機器學習
他就把機器學習四個字打出來,已經知道說輸入這段聲音訊號第一個應該要輸出的中文字是機,所以今天當我們把 BEGIN丟給這個 Encoder 的時候它第一個輸出應該要跟機越接近越好,什麼叫跟機越接近越好呢,機這個字會被表示成一個 One-Hot 的 Vector,在這個 Vector 裡面只有機對應的那個維度是 1其他都是 0這是正確答案。
那我們的 Decoder它的輸出是一個 Distribution,是一個機率的分布,我們會希望這一個機率的分布跟這個 One-Hot 的 Vector 越接近越好,所以你會去計算這個 Ground Truth跟這個 Distribution 它們之間的 Cross Entropy,然後我們希望這個 Cross Entropy 的值越小越好。
那你可能會發現說這件事情跟分類很像,沒錯 它就跟分類很像。你可以想成每一次 Decoder 在產生一個中文字的時候其實就是做了一次分類的問題,中文字假設有四千個,那就是做有四千個類別的分類的問題啦
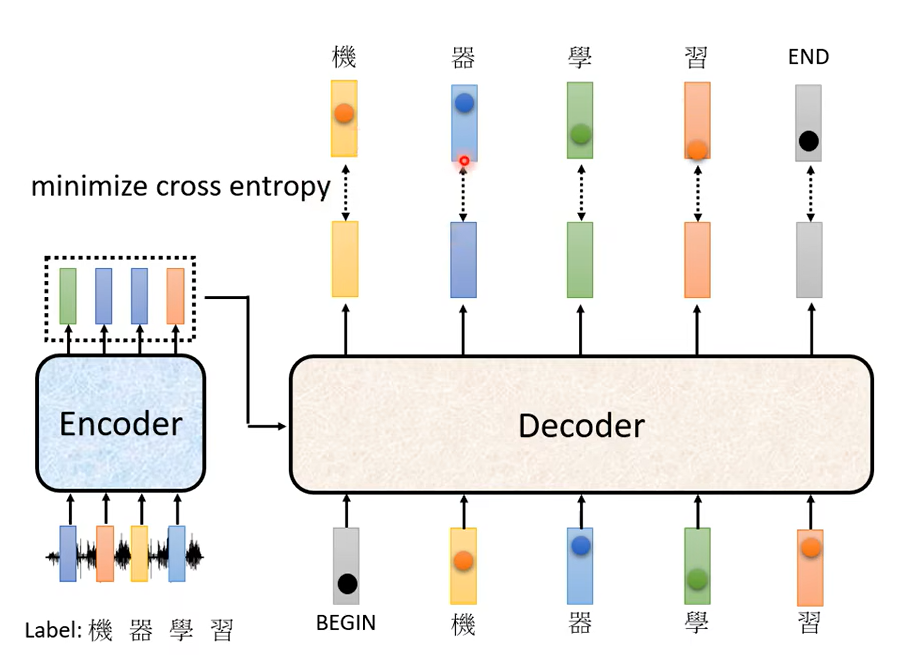
在訓練的時候,每一個輸出都會有一個 Cross Entropy,每一個輸出跟 One-Hot Vector(跟它對應的正確答案)都有一個 Cross Entropy,我們要希望所有的 Cross Entropy 的總和最小越小越好
這邊做了四次分類的問題,我們希望這些分類的問題它總合起來的 Cross Entropy 越小越好。别忘了最終第五個位置輸出了END,
應該跟END的 One-Hot Vector的 Cross Entropy 越小越好。
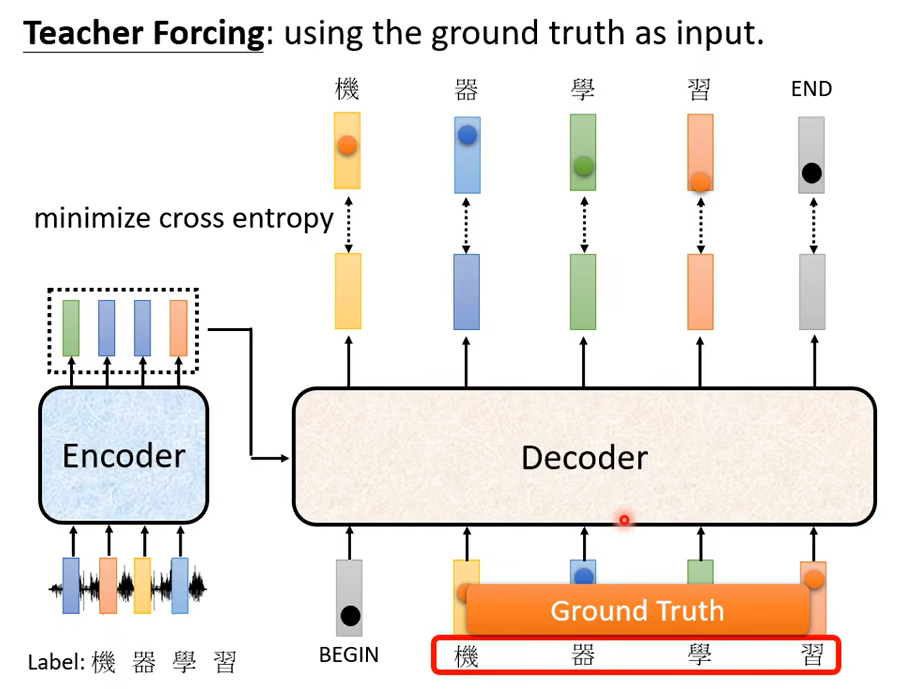
还有需要注意的一点就是,训练的时候你把 Ground Truth 給它。
這個訓練的時候Decoder 有偷看到正確答案了,但是測試的時候顯然沒有正確答案可以給 Decoder 看,這中間顯然有一個 Mismatch
對 這中間有一個 Mismatch,那等一下我們會有一頁投影片的說明有什麼樣可能的解決方式。
就是要講訓練 Transformer 但不侷限於 Transformer ,訓練這種 Sequence To Sequence Model 的一些 Tips
第一個 Tips 是 Copy Mechanism,在我們剛才的討論裡面我們都要求 Decoder 自己產生輸出,但是對很多任務而言也許 Decoder 沒有必要自己創造輸出,它需要做的事情也許是從輸入的東西裡面複製一些東西出來,那我們有沒有辦法讓 Decoder 複製從輸入複製一些東西出來呢,其實是有辦法。

一個例子是做聊天機器人,舉例來說人對機器說 你好 我是庫洛洛,然後機器應該回什麼呢,機器應該回答說庫洛洛你好 很高興認識你,那對機器來說它其實沒有必要創造庫洛洛這個詞彙,這對機器來說一定會是一個非常怪異的詞彙,所以它可能很難在訓練資料裡面,可能一次也沒有出現過,所以它不太可能正確地產生這段句子出來。
假設今天機器它在學的時候,它學到的並不是它要產生庫洛洛這三個中文字,它學到的是看到輸入的時候說我是某某某,就直接把某某某不管這邊是什麼複製出來,說某某某你好,那這樣子機器的訓練顯然會比較容易,它顯然比較有可能得到正確的結果。

舉另外一個例子,小傑不能用念能力了,机器可能會回答說,你所謂的不能用念能力是什麼意思,對機器來說它要去複述這一段它聽不懂的話,它不需要從頭去創造這一段文字,它要學的也許是從使用者人的輸入去 Copy 一些詞彙當做它的輸出。
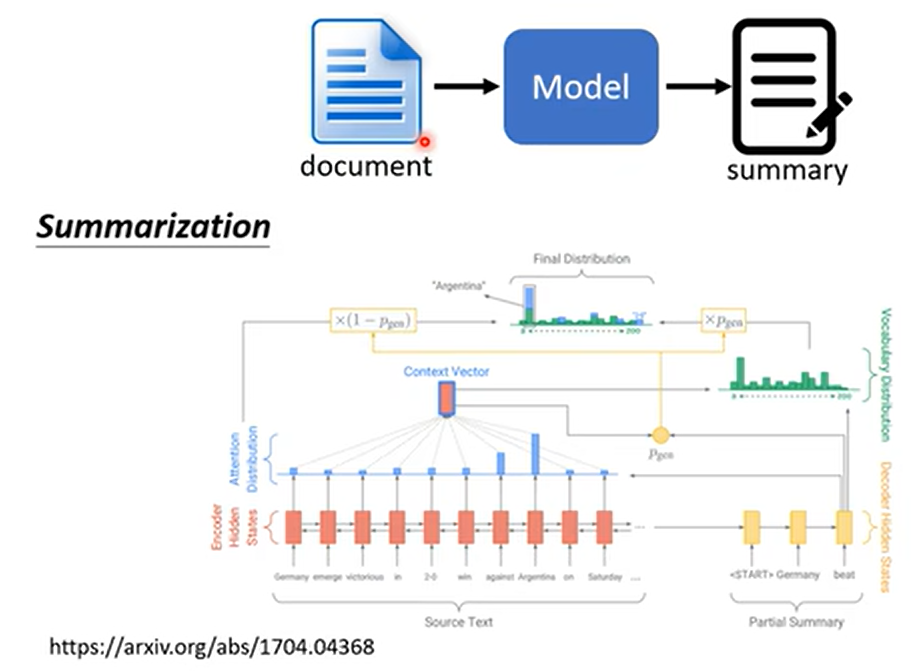
或者是在做摘要的時候,你可能更需要 Copy 這樣子的技能,所謂的摘要就是你要訓練一個模型,然後這個模型去讀一篇文章然後產生這篇文章的摘要,那這個任務完全是有辦法做的,就是蒐集大量的文章,那每一篇文章都有人寫的摘要,然後你就訓練一個Sequence-To-Sequence 的 Model就結束了,你要做這樣的任務只有一點點的資料是做不起來的。有的同學收集個幾萬篇文章,然後訓練一個這樣的
Sequence-To-Sequence Model,發現結果有點差,然後來問我為什麼,這時候我就告訴你說,你要訓練這種,你要叫機器說合理的句子,通常這個百萬篇文章是需要的

那 Sequence-To-Sequence Model有沒有辦法做到這件事呢,那簡單來說就是有,那我們就不會細講,最早有從輸入複製東西的能力的模型叫做 Pointer Network。
因為你知道機器就是一個黑盒子,有時候它裡面學到什麼東西你實在是搞不清楚,那有時候它會犯非常低級的錯誤,什麼樣低級的錯誤呢,這邊就舉一個真實的低級錯誤的例子,這邊舉的例子是語音合成。
你完全可以就是訓練一個Sequence-To-Sequence 的 Model,大家都很熟,Transformer 就是一個例子,你就蒐集很多的文字跟聲音訊號的對應關係,然後接下來告訴你的Sequence-To-Sequence Model 說看到這段中文的句子你就輸出這段聲音,然後就沒有然後,就硬 Train 一發就結束了

舉例來說我叫機器連說 4 次發財,看看它會怎麼講,我輸入的發財是明明是同樣的詞彙只是重複 4 次,機器居然自己有一些抑揚頓挫
你說它為什麼有抑揚頓挫,它怎麼學到這件事,不知道,它自己訓練出來就是這個樣子。讓它講 1 次發財,發現怎麼沒有唸發,為什麼
,就是不知道為什麼這樣子,就是你這個 Sequence-To-Sequence Model。有時候 Train 出來就是會產生莫名其妙的結果,也許在訓練資料裡面這種非常短的句子很少,所以機器它根本沒有辦法處不知道要怎麼處理這種非常短的句子,你叫它唸發財它把發省略掉只唸財
所以怎麼辦呢,因為我們剛才發現說機器居然漏字了,輸入有一些東西它居然沒有看到,我們能不能夠強迫它一定要把輸入的每一個東西通通看過呢,這個是有可能的這招就叫做 Guided Attention
Guided Attention它最適合的是語音辨識 語音合成這種任務,你其實很難接受說你講一句話,辨識出來居然有一段機器沒聽到,或語音合成你輸入一段文字,語音合出來居然有一段沒有唸到。比如說 Chat Bar或者是 Summary可能就沒有那麼嚴格,因為對一個 Chat Bar 來說,輸入後一句話它就回一句話,它到底有沒有把整句話看完,其實你 Somehow 也不在乎你其實也搞不清楚。
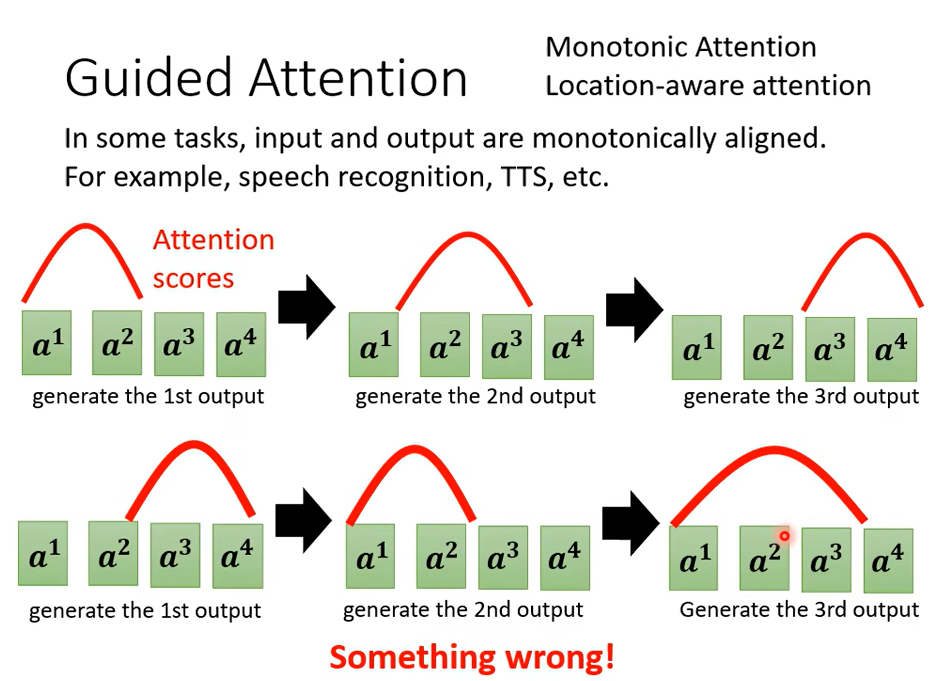
Guiding Attention 要做的事情就是要求,我們要去這個 Guide去領導這個 Attention 的過程。
要求機器它在做 Attention 的時候是有固定的方式的,舉例來說對語音合成或者是語音辨識來說,我們想像中的 Attention應該就是由左向右, 在這個例子裡面我們用紅色的這個曲線來代表 Attention 的分數,這個越高就代表 Attention 的值越大,那如果今天不管是做語音辨識還是語音合成,我們以語音合成為例好了,那你的輸入就是一串文字,那你在合成聲音的時候顯然是由左唸到右,所以機器應該是最左邊輸入的詞彙產生聲音,再看中間的詞彙產生聲音,再看右邊的詞彙產生聲音,如果你今天在做語音合成的時候你發現機器Attention是顛三倒四的,它先看最後面,接下來再看前面,那再胡亂看整個句子,那顯然有些是做錯了,顯然有些是Something is wrong有些是做錯了,那顯然這樣子的 Attention 是有問題的,你在做語音合成的時候你顯然沒有辦法合出好的結果。
所以 Guiding Attention 要做的事情就是強迫 Attention 有一個固定的樣貌,那如果你對這個問題本身就已經有理解,知道說語音合成 TTS 這樣的問題,你的 Attention 的分數Attention 的位置都應該由左向右,那不如就直接把這個限制放進你的 Training 裡面, 要求機器學到 Attention就應該要由左向右。
怎么做到呢,可以去了解一下Monotonic Attention和Location-aware attention
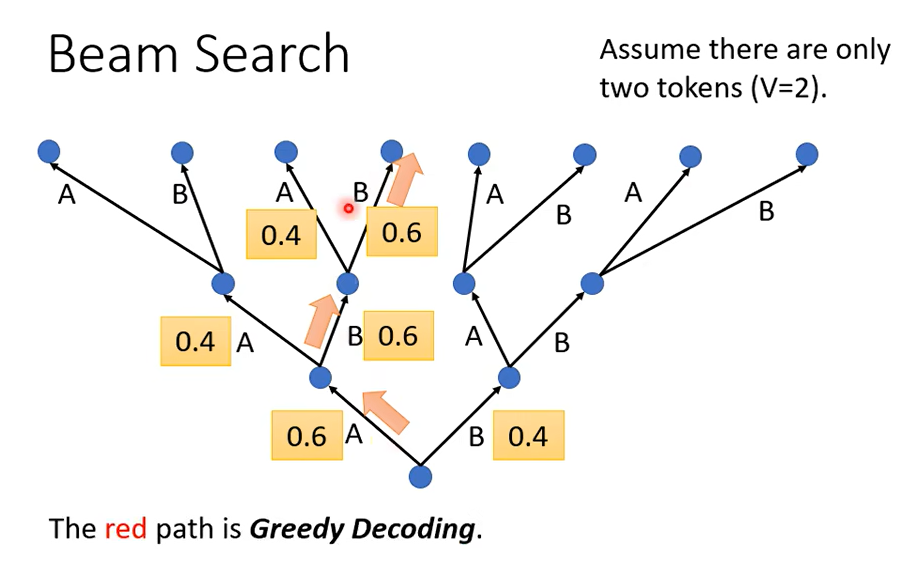
按照我们之前介绍的,每次都输出可能性最高的那个,那像這樣子每次找分數最高的那個 Token,每次找分數最高的那個字來當做輸出,這件事情叫做Greedy Decoding,但是 Greedy Decoding一定是更好的方法嗎
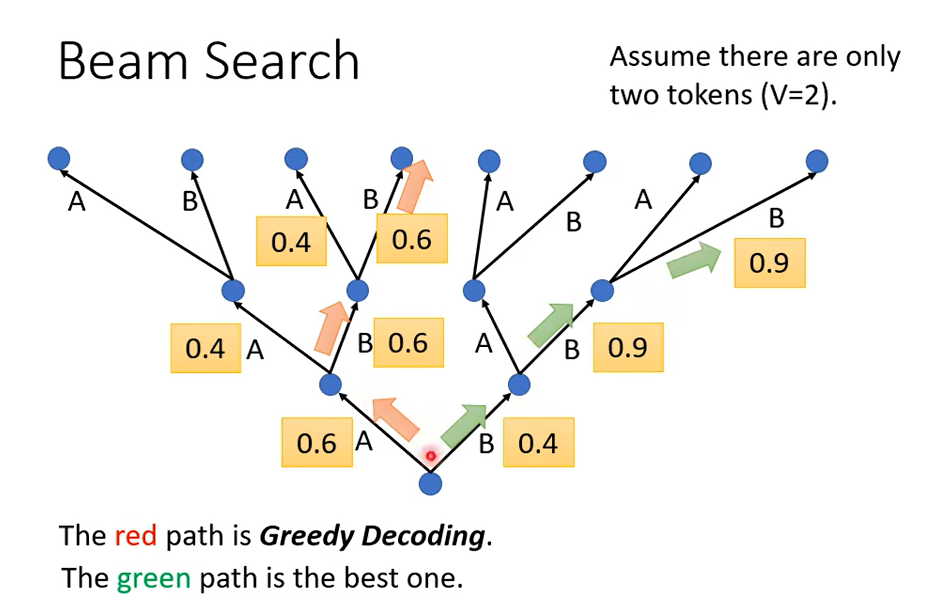
先稍微捨棄一點東西,比如說第一步雖然 B 是 0.4,但我們就先選 0.4 這個 B,然後接下來我們選了 B 以後,也許接下來的 B 的可能性就大增就變成 0.9,然後接下來第三個步驟B 的可能性也是 0.9,如果你比較紅色的這一條路跟綠色這條路的話,你會發現說綠色這一條路雖然一開始第一個步驟你選了一個比較差的輸出,但是接下來的結果是好的。
如果我們要怎麼找到這個最好的綠色這一條路呢,也許一個可能是爆搜所有可能的路徑,但問題是我們實際上並沒有辦法爆搜所有可能的路徑,因為實際上每一個轉捩點可以的選擇太多了,如果是在對中文而言,我們中文有 4000 個字,所以這個樹每一個地方分叉都是 4000 個可能的路徑。
有一個演算法叫做 Beam Search,它用比較有效的方法找一個 Approximate,关于这一点看我之前的文章Beam Search
那這個 Beam Search 這個技術到底有沒有用呢,有趣的事就是,它有時候有用有時候沒有用,你會看到有些文獻告訴你說Beam Search 是一個很爛的東西,怎麼說呢,比如舉例來說這篇 Paper 叫做The Curious Case Of Neural Text Degeneration

那這個任務要做的事情是Sentence Completion,也就是機器先讀一段句子,接下來它要把這個句子的後半段把它完成,你給它一則新聞或者是一個故事的前半部,它自己發揮它的想像創造力把這個文章把故事的後半部把它寫完
在這篇文章裡面一開頭就告訴你說,Beam Search 有問題,如果你用 Beam Search 的話會發現說機器不斷講重複的話,它不斷開始陷入無窮迴圈不斷說重複的話,那如果你今天不是用 Beam Search有加一些隨機性,雖然結果不一定完全好但是看起來至少是比較正常的句子。
所以有趣的事情是,有時候對 Decorder 來說沒有找出分數最高的路反而結果是比較好的。
這個時候你又覺得亂亂的 對不對,就是剛才前一頁投影片才說要找出分數最高的路,現在又突然又找又要講說找出分數最高的路不見得比較好,到底是怎麼回事呢,那其實這個就是要看你的任務的本身的特性,就假設一個任務它的答案非常地明確,舉例來說什麼叫答案非常明確呢,比如說語音辨識,說一句話辨識的結果就只有一個可能,就那一串文字就是你唯一可能的正確答案,並沒有什麼模糊的地帶,我覺得對這種任務而言通常 Beam Search 就會比較有幫助,那什麼樣的任務Beam Search 比較沒有幫助呢,就是你需要機器發揮一點創造力的時候,這時候 Beam Search 就比較沒有幫助,舉例來說,在這邊的 Sentence Completion給你一個句子給你故事的前半部,後半部有無窮多可能的發展方式,那這種需要有一些創造力的有不是只有一個答案的任務,往往會比較需要在 Decoder 裡面加入隨機性
還有另外一個 Decoder也非常需要隨機性的任務,叫做語音合成,因為我們實驗室一開始想要用這個Sequence-To-Sequence 的 Model做語音合成的時候,有很長一段時間都做不起來都合不出聲音來,有一次有一個 Google 的人來 Visit我們實驗室,我們就拿這個問題來跟他請教,然後他就說你們不知道在做 TTS 的時候Decoder 要加 Noise 嗎,這聽起來很神奇,這個完全違背正常的 Machine Learning 會做的想法,你知道在 Machine Learning有時候你在訓練的時候會加 Noise,你就想像說我們在訓練的時候我們會加上一些雜訊,讓我們在訓練的時候機器看過更多不同的可能性,在訓練的時候會比較強健,比較能夠對抗它在測試的時候沒有看過的狀況,那沒有人會傻到說你在測試的時候居然還要加一些雜訊,那你不是把測試的狀況弄得更困難,不是結果會更差嗎。
但 TTS 神奇的地方是測試的時候,模型訓練好以後測試的時候你要加入一些雜訊合出來的聲音才會好,這樣非常的神奇,你用正常的 Decode 的方法產生出來的聲音就有點像是機關槍那樣根本聽不太出來是人聲,你要產生出比較好的聲音居然是需要一些隨機性的,所以這也是一個非常神奇的地方,有時候我們其實期待 Decorder 有隨機性反而會得到比較好的結果

這也許就呼應了一個英文的諺語,就是要接受沒有事情是完美的,那真正的美也許就在不完美之中,對於 TTS 或 Sentence Completion 來說Decoder 找出最好的結果不見得是人類覺得最好的結果,反而是奇怪的結果,那你加入一些隨機性結果反而會是比較好的
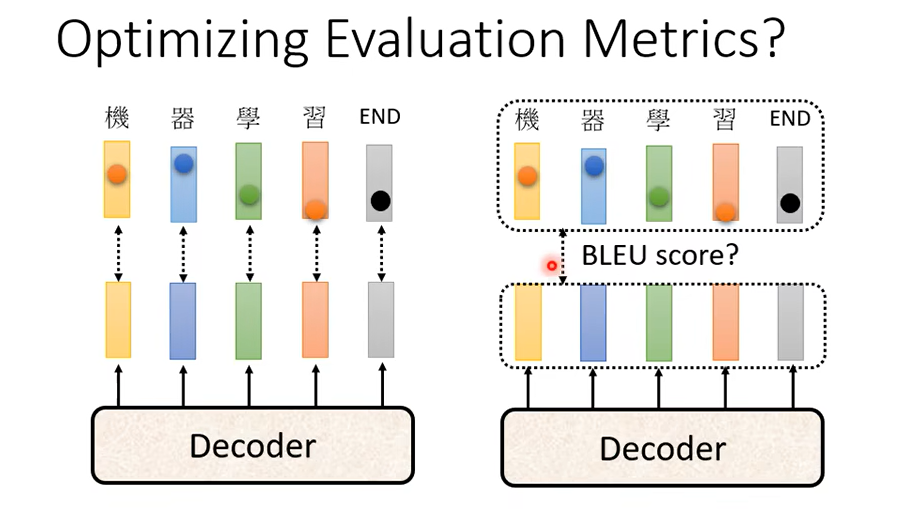
我們評估的標準用的是BLEU Score,那 BLEU Score 要怎麼量呢,BLEU Score 是你的 Decoder先產生一個完整的句子以後再去跟正確的答案一整句做比較,我們是拿兩個句子之間做比較才算出 BLEU Score,但我們在訓練的時候顯然不是這樣訓練,這邊每一個詞彙是分開考慮的訓練的時候,Minimize Cross Entropy真的可以 Maximize BLEU Score 嗎,不一定因為這兩個根本就是它們可能有一點點的關聯,但它們又沒有那麼直接相關,它們根本就是兩個不同的數值,所以我們 Minimize Cross Entropy不見得可以讓 BLEU Score 比較大
我們訓練的時候是看 Cross Entropy,但是我們實際上你作業真正評估的時候看的是 BLEU Score
那接下來有人就會想說,那我們能不能在 Training 的時候就考慮 BLEU Score 呢,我們能不能夠訓練的時候就說我的 Loss 就是BLEU Score 乘一個負號。但是這件事實際上沒有那麼容易,你當然可以把 BLEU Score當做你訓練的時候你要最大化的一個目標,但是 BLEU Score 本身很複雜,它是不能微分的,你把它當做你的 Loss你根本不知道你要怎麼算
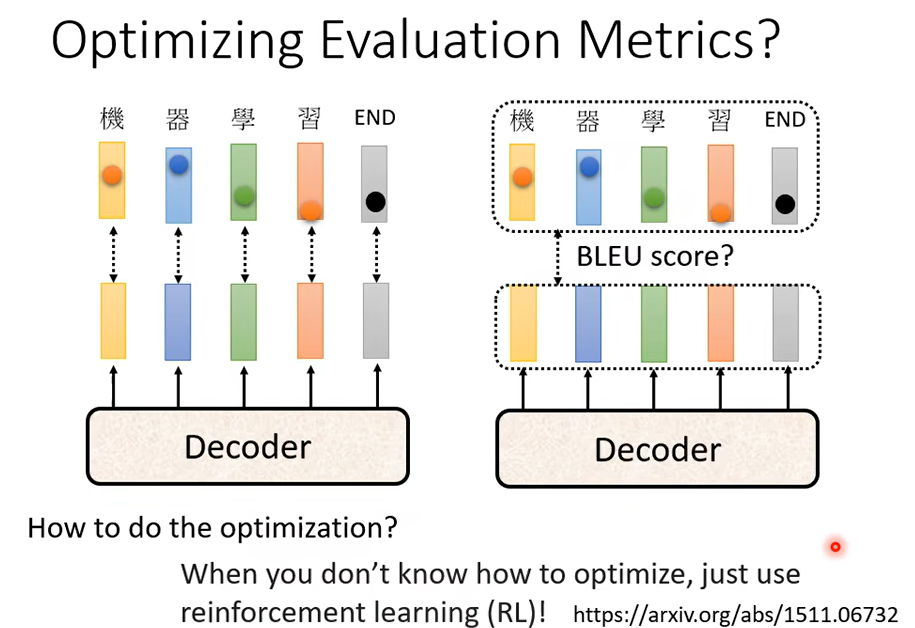
遇到你在 Optimization 無法解決的問題,用 RL 硬 Train 一發就對了,這樣遇到你無法 Optimize 的 Loss Function把它當做是 RL 的 Reward,把你的 Decoder 當做是 Agent,它當作是 RLReinforcement Learning 的問題硬做其實也是有可能可以做的,那有人真的這樣試過嗎,有人真的這樣試過,我把 Reference 列在這邊給大家參考。當然這是一個比較難的做法
那我們要講到我們剛才反覆提到的問題了,就是訓練跟測試居然是不一致的,測試的時候Decoder 看到的是自己的輸出,所以測試的時候Decoder 會看到一些錯誤的東西,但是在訓練的時候Decoder 看到的是完全正確的,那這個不一致的現象叫做Exposure Bias
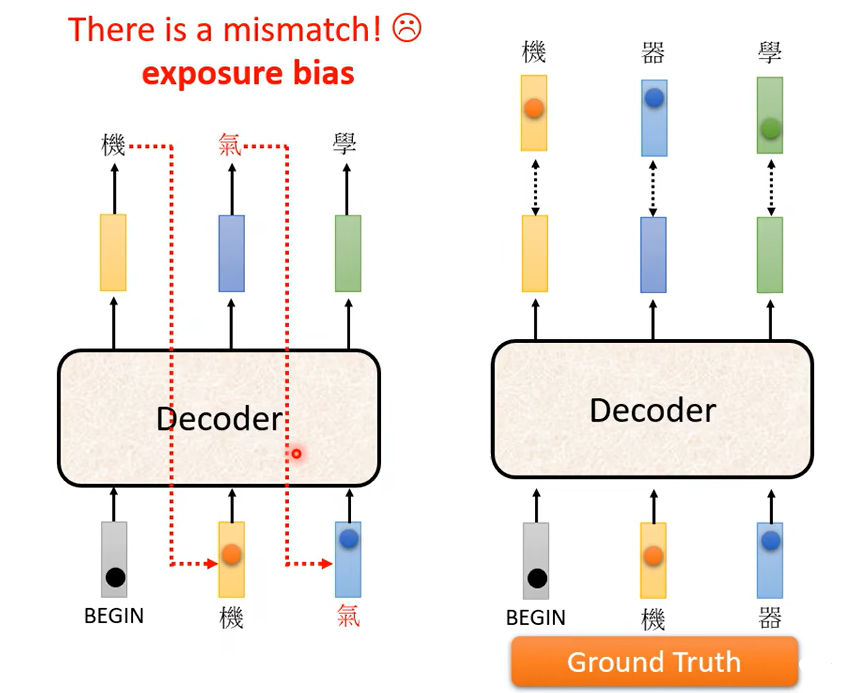
那假設 Decoder 在訓練的時候永遠只看過正確的東西,那在測試的時候你只要有一個錯,那就會一步錯 步步錯,因為對 Decoder 來說它從來沒有看過錯的東西,它看到錯的東西會非常的驚奇,然後接下來它產生的結果可能都會錯掉
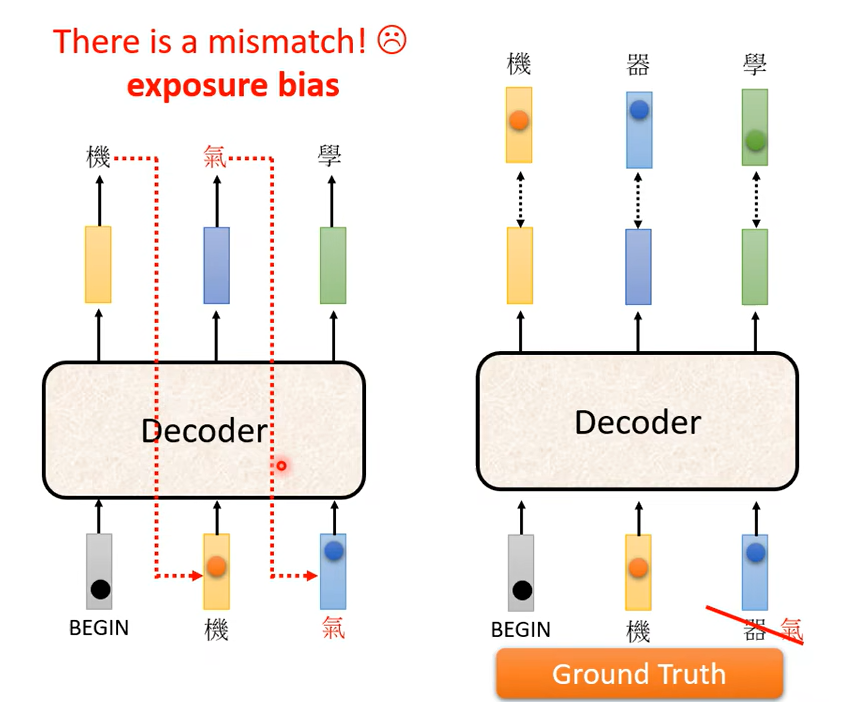
所以要怎麼解決這個問題呢,有一個可以的思考的方向是給 Decoder 的輸入加一些錯誤的東西,就這麼直覺,你不要給 Decoder 都是正確的答案,偶爾給它一些錯的東西它反而會學得更好。
這一招叫做Scheduled Sampling
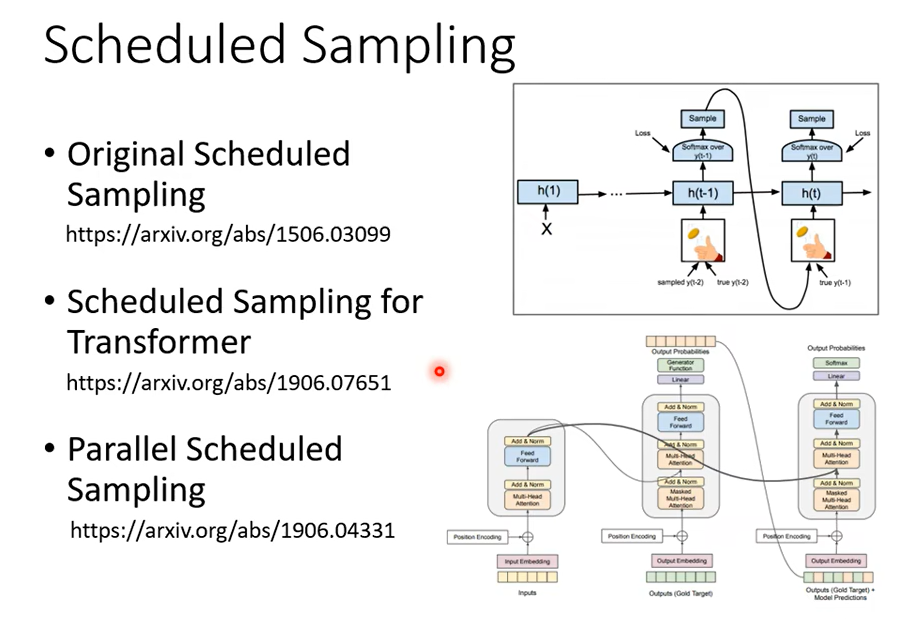
Scheduled Sampling 其實很早就有了,這個是 15 年的 Paper,很早就有 Scheduled Sampling,在還沒有 Transformer只有 LSTM 的時候就已經有 Scheduled Sampling,但是 Scheduled Sampling 這一招它其實會傷害到Transformer 的平行化的能力,那細節可以再自己去了解一下,所以對 Transformer 來說它的 Scheduled Sampling另有招數跟傳統的招數,跟原來最早提在這個 LSTM上被提出來的招數也不太一樣,那我把一些 Reference 的列在這邊給大家參考。
好 那以上我們就講完了Transformer 和種種的訓練技巧,我們已經講完了 Encoder,講完了 Decoder,也講完了它們中間的關係,也講了怎麼訓練也講了總總的 Tip
标签:我們,transformer,一個,李宏毅,這個,笔记,輸出,Decoder,時候 From: https://www.cnblogs.com/cork/p/18414636