嵌套集合模型(Nested set model)介绍
pilishen / 更新于5年前
本文翻译自维基百科Nested set model 此文档是 nestedset-无限分类正确姿势的扩展阅读
nested set model(嵌套集合模型)是一种在关系型数据库中表示nested sets(嵌套集合) 的特殊技术。[nested sets]通常指的是关系树或者层级关系。这个术语是由 Joe Celko清晰的提出来的,还有人使用不同的术语来描述这一技术。
诱因
该技术的出现解决了标准关系代数和关系演算以及基于它们的SQL操作不能直接在层次结构上表示所有期望操作的问题。层级可以用parent-child relation (父子关系)术语来表示 - Celko称之为 [adjacency list model],但是如果可以有任意的深度,这种模型不能用来展示类似的操作比如比较两个元素的层级或者确定一个元素是否位于另一个元素的子层级,当一个层级结构是固定的或者有固定的深度,这种操作必须通过每一层的 relational join (关系连接)来实现。但是这将很低效。这通常被称为物料清单问题。
通过切换到图形数据库,可以很容易地表达层次结构。另外在一些关系型数据库系统中存在并提供了这种关系模型的解决方案:
- 支持专门的层级结构数据类型,比如SQL的hierarchical query facility(层级查询工具)。
- 使用层级操作扩展关系型语言,比如 nested relational algebra。
- 使用transitive closure扩展关系型语言,比如SQL的CONNECT语句;这可以在parent-child relation 使用但是执行起来比较低效。
- 层级结构查询可以在支持循环且包裹关系的操作的语言中实现。比如 PL/SQL, T-SQL or a general-purpose programming language
当这些解决方案没被提供或不容易实现,就必须使用另一种方法
技术
嵌套集模型是根据树遍历来对节点进行编号,遍历会访问每个节点两次,按访问顺序分配数字,并在两次访问中都分配。这将为每个节点留下两个数字,它们作为节点两个属性存储。这使得查询变得高效:通过比较这些数字来获得层级结构关系。但是更新数据将需要给节点重新分配数字,因此变得低效。尽管很复杂但是可以通过不使用整数而是用有理数来改进更新速度。
例子
在衣服库存目录中,衣服可能会更加层级机构来分类:
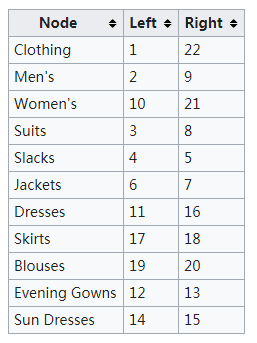
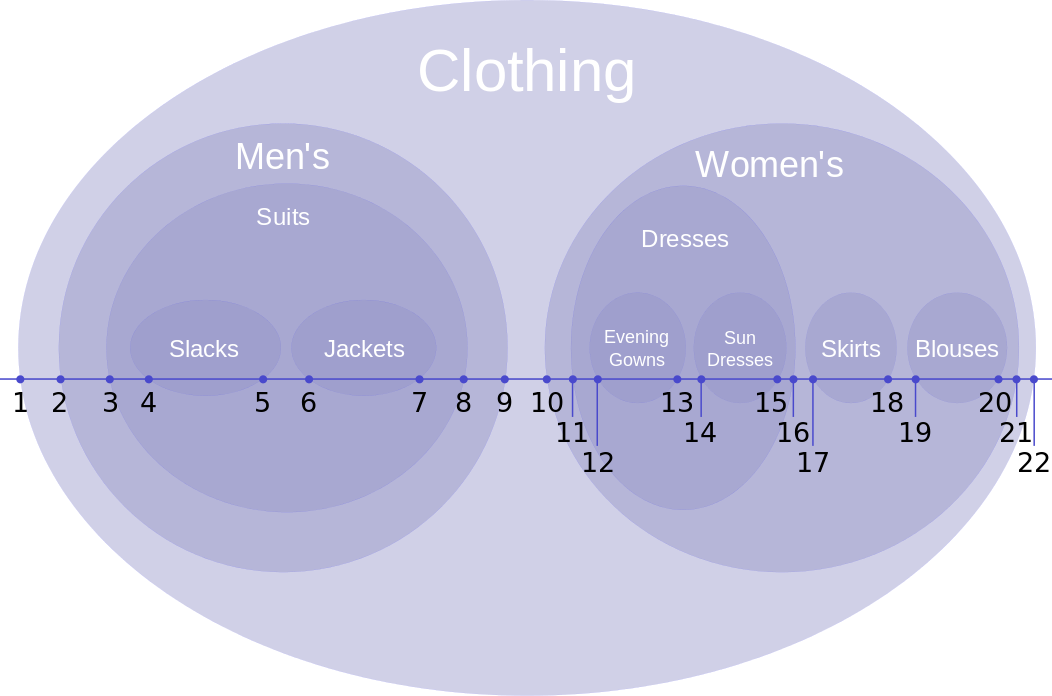
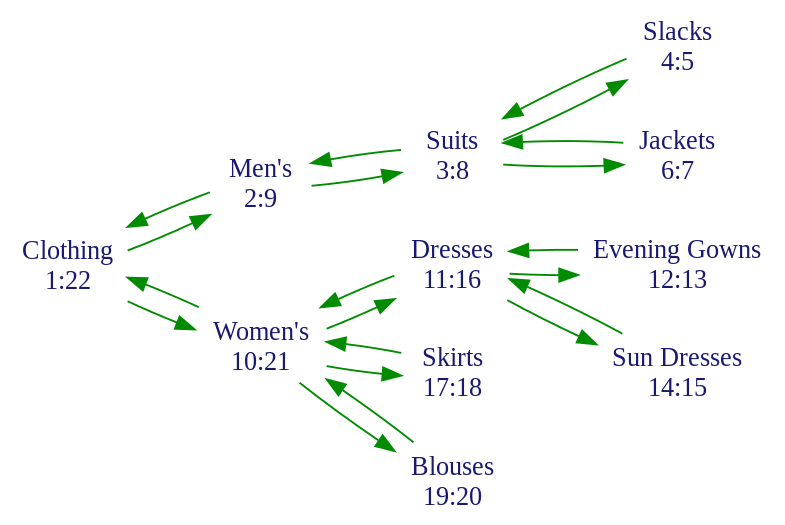
处于层级结构顶端的Clothing分类包含所有的子类,因此它的左值和右值分别赋值为1和22,后面的值即这里的22是展现的所有节点总数的两倍。下一层级包含Men's和Women's两子类,各自包含必须被计算在内的层级。每一层的节点都根据它们包含的子层级来给左值和右值赋值。如上表所示。
表现
使用nested sets 将比使用一个遍历adjacency list的储存过程更快,对于天生缺乏递归的查询结构也是更快的选择。比如MySQL.但是递归SQL查询语句也能提供类似“迅速查询后代”的语句并且在其他深度搜索查询是更快,所以也是对于提供这一功能的数据库的更快选择。例如 PostgreSQL,[5] Oracle,[6] and Microsoft SQL Server.[7]
缺点
The use case for a dynamic endless database tree hierarchy is rare. The Nested Set model is appropriate where the tree element and one or two attributes are the only data, but is a poor choice when more complex relational data exists for the elements in the tree. Given an arbitrary starting depth for a category of 'Vehicles' and a child of 'Cars' with a child of 'Mercedes', a foreign key table relationship must be established unless the tree table is naively non-normalized. Attributes of a newly created tree item may not share all attributes with a parent, child or even a sibling. If a foreign key table is established for a table of 'Plants' attributes, no integrity is given to the child attribute data of 'Trees' and its child 'Oak'. Therefore, in each case of an item inserted into the tree, a foreign key table of the item's attributes must be created for all but the most trivial of use cases. If the tree isn't expected to change often, a properly normalized hierarchy of attribute tables can be created in the initial design of a system, leading to simpler, more portable SQL statements; specifically ones that don't require an arbitrary number of runtime, programmatically created or deleted tables for changes to the tree. For more complex systems, hierarchy can be developed through relational models rather than an implicit numeric tree structure. Depth of an item is simply another attribute rather than the basis for an entire DB architecture. As stated in SQL Antipatterns:[8]
Nested Sets is a clever solution – maybe too clever. It also fails to support referential integrity. It’s best used when you need to query a tree more frequently than you need to modify the tree.[9]
The model doesn't allow for multiple parent categories. For example, an 'Oak' could be a child of 'Tree-Type', but also 'Wood-Type'. An additional tagging or taxonomy has to be established to accommodate this, again leading to a design more complex than a straightforward fixed model. Nested sets are very slow for inserts because it requires updating left and right domain values for all records in the table after the insert. This can cause a lot of database stress as many rows are rewritten and indexes rebuilt. However, if it is possible to store a forest of small trees in table instead of a single big tree, the overhead may be significantly reduced, since only one small tree must be updated. The nested interval model does not suffer from this problem, but is more complex to implement, and is not as well known. It still suffers from the relational foreign-key table problem. The nested interval model stores the position of the nodes as rational numbers expressed as quotients (n/d). [1]
变体
使用上面描述的nested set modal 在一些特定的树遍历操作上有性能限制。比如根据父节点查找直接子节点需要删选子树到一个指定的层级如下所示:
SELECT Child.Node, Child.Left, Child.Right
FROM Tree as Parent, Tree as Child
WHERE
Child.Left BETWEEN Parent.Left AND Parent.Right
AND NOT EXISTS ( -- No Middle Node
SELECT *
FROM Tree as Mid
WHERE Mid.Left BETWEEN Parent.Left AND Parent.Right
AND Child.Left BETWEEN Mid.Left AND Mid.Right
AND Mid.Node NOT IN (Parent.Node AND Child.Node)
)
AND Parent.Left = 1 -- Given Parent Node Left Index
或者:
SELECT DISTINCT Child.Node, Child.Left, Child.Right
FROM Tree as Child, Tree as Parent
WHERE Parent.Left < Child.Left AND Parent.Right > Child.Right -- associate Child Nodes with ancestors
GROUP BY Child.Node, Child.Left, Child.Right
HAVING max(Parent.Left) = 1 -- Subset for those with the given Parent Node as the nearest ancestor
当查询不止一层深度的子节点的时候,查询将更加的复杂,为了突破限制和简化遍历树,在模型上增加一个额外的字段来维护树内节点的深度:
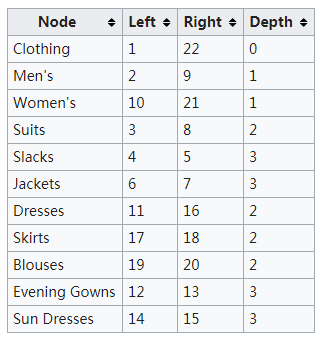
在这个模型中,找到指定父节点的紧跟直接子节点可以使用下面的SQL语句实现:
SELECT Child.Node, Child.Left, Child.Right
FROM Tree as Child, Tree as Parent
WHERE
Child.Depth = Parent.Depth + 1
AND Child.Left > Parent.Left
AND Child.Right < Parent.Right
AND Parent.Left = 1 -- Given Parent Node Left Index