RAG 系统及其挑战
检索增强生成的流行是有充分理由的。它允许 AI 系统通过结合信息检索和语言生成来回答问题。标准的 RAG 管道通过摄取数据、检索相关信息并使用它来生成响应来实现这一点。
然而,随着数据变得越来越复杂,查询也越来越复杂,传统的 RAG 系统可能会 面临限制。这就是语义分块发挥作用的地方。
理解语义组块
语义分块是一种基于内容和上下文将文本或数据划分为有意义的片段的方法,而 不是任意的字数或字符限制。
它通常是这样工作的:
1.内容分析:系统检查文档以了解其结构和内容。
2.智能分割:它根据语义一致性将内容分成块——完整的想法或独立的解释。
3.上下文嵌入:每个块在更广泛的文档中保留有关其上下文的信息。
这种方法有助于保留信息内的含义和关系,这对于准确检索和生成至关重要。
传统方法的局限性
传统的分块方法虽然计算效率很高,但也有一些缺点:
-它们可以将重要的概念拆分为多个块。
-他们经常很难在不同部门之间保持上下文。
-它们可能导致检索不完整或不连贯的信息。
这些限制可能会影响人工智能生成反应的准确性和相关性,特别是在处理复杂或 微妙的信息时。
语义分块实例:
考虑一个 AI 系统正在分析法律文件的场景。一个查询可能是:“总结某司版权侵权案中与合理使用相关的关键论点。”
传统系统可能返回:
1.带有案例介绍的大块,在论证中间切断。
2.另一大块来自合理使用讨论的中间部分,缺乏上下文。
3.与主要论点没有联系的结束语。
相比之下,使用语义分块的系统将:
1.识别关于合理使用论证的整个部分。
2.把相关的先例和例子和每个论点放在一起。
3.在整个模块中保持法律推理的逻辑流畅。
结果是一组信息,更好地保留了原始文档的连贯性和上下文,从而可以更准确、 更全面地回应。
另一个与香草方法比较的例子(数据是一篇学术论文):
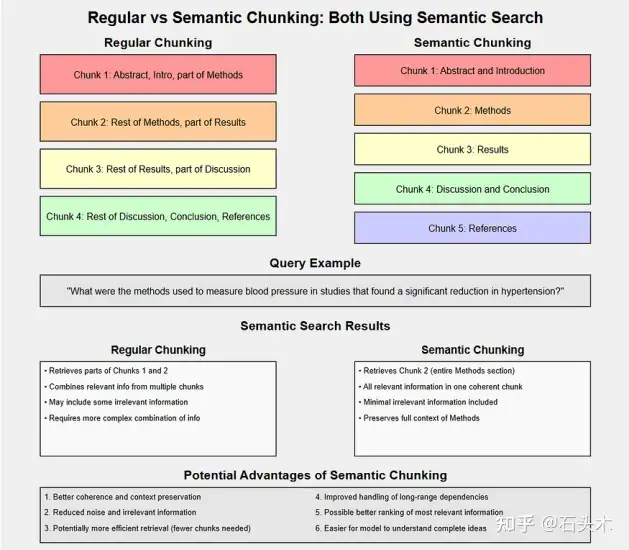
实现语义分块:方法
实现语义分块的几种方法显示出了希望:
1.llm 支持的分块处理:
-使用大型语言模型来识别语义边界。
-优点:适应不同的内容类型。
-缺点:计算量大。
2.基于规则的语义分割:
-对逻辑中断使用语言规则和启发式。
-优点:高效的结构化文档。
-缺点:内容风格多变,不够灵活。
3.混合方法:
-结合统计方法,机器学习和基于规则的系统。
-优点:平衡效率和适应性。
-缺点:实现起来比较复杂。
方法的选择取决于数据的性质、可用资源和特定需求等因素。
语义分块对 AI 系统的影响
将语义分块集成到 RAG 管道中提供了几个优势:
1.更好的语境保存:保持观点和论点的完整性。
2.改进的检索相关性:返回与查询意图更紧密一致的结果。
3.增强对复杂信息的处理能力:特别适用于长篇内容和复杂的主题。
4.提高 AI 响应的准确性:导致更连贯和全面的输出。
这些改进可以产生更可靠的 AI 系统,能够更精确地处理细微的查询。
挑战和未来方向
虽然语义分块提供了好处,但它也带来了挑战:
-计算需求:更复杂的分析可能需要额外的计算资源。
-领域适应:有效的分块策略可能因不同的领域和内容类型而异。
-平衡粒度:在不牺牲效率的情况下,找到保留意义的最佳块大小。
该领域不断发展,正在进行的研究领域包括:
-多模态语义分块:扩展到文本之外,以理解和分块其他媒体类型。
-动态分块系统:根据查询上下文和内容复杂性调整分块策略。
-与先进的 AI 模型集成:增强语义分块和前沿语言模型之间的协同作用。
标签:分块,AI,语义,信息检索,系统,上下文,方法 From: https://www.cnblogs.com/little-horse/p/18399216