论文提出了包括渐进重参数化批归一化和简化线性注意力在内的新策略,以获取高效的
Transformer架构。在训练过程中逐步将LayerNorm替换为重参数化批归一化,以实现无损准确率,同时在推理阶段利用BatchNorm的高效优势。此外,论文设计了一种简化的线性注意力机制,其在计算成本较低的情况下达到了与其他线性注意力方法可比的性能。来源:晓飞的算法工程笔记 公众号
论文: SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization

Introduction
transformer架构最初引入用于自然语言处理任务,迅速成为语言模型领域的杰出模型。随着Vision Transformer(ViT)的引入,其影响力显著扩展,展示了基于transformer的架构的有效性和多样性。这些架构在与卷积神经网络(CNNs)相比,在各种视觉任务中表现出了竞争力的性能基准。由于其强大的性能,transformer已成为深度学习中的主流架构。然而,transformer架构的计算需求构成了一个重大挑战,这主要是由于其注意力机制的二次计算复杂性和LayerNorm组件在线统计计算的必要性。
许多工作致力于提升transformer架构的效率。有的方法试图通过限制自注意机制中token交互的范围来减少计算复杂度,例如降采样键和值矩阵、采用稀疏全局注意模式以及在较小的窗口内计算自注意力。与此同时,线性注意力作为一种替代策略出现,通过将注意力机制分解为线性计算成本来增强计算效率,然而,在效率和准确性之间取得良好平衡仍然是一个具有挑战性的任务。此外,由于LayerNorm在推理过程中额外的计算开销,一些探索尝试将BatchNorm(BN)替代transformer中的LayerNorm(LN),比如在前向网络的两个线性层之间添加一个BatchNorm层来稳定训练。然而,LayerNorm和BatchNorm的transformer之间仍存在性能差距。
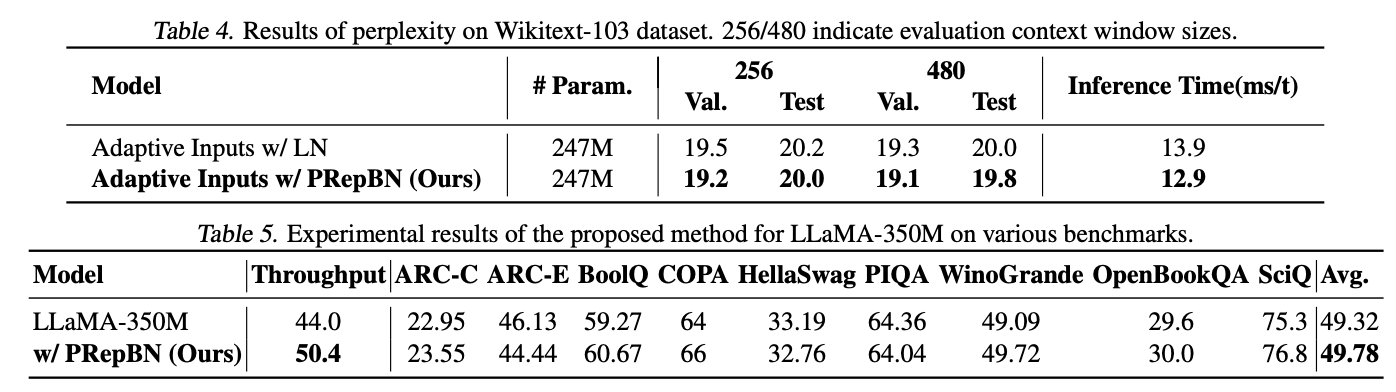
论文的重点是通过深入研究计算效率低下的模块,即归一化层和注意力模块,来获取高效的transformer架构。首先,论文探索了用BatchNorm替换LayerNorm以加速transformer的推理过程。BatchNorm可以降低推理延迟,但可能导致训练崩溃和性能下降,而LayerNorm可以稳定训练,但在推理过程中会增加额外的计算成本。因此,论文提出了一种渐进策略,通过使用超参数控制两种归一化层的比例,逐步将LayerNorm替换为BatchNorm。最初,transformer架构由LayerNorm主导,随着训练的进行逐渐过渡到纯BatchNorm。这种策略有效地减轻了训练崩溃的风险,并且在推理过程中不再需要计算统计信息。除了渐进策略外,论文还提出了一种新的BatchNorm重新参数化公式(RepBN),以增强训练稳定性和整体性能。

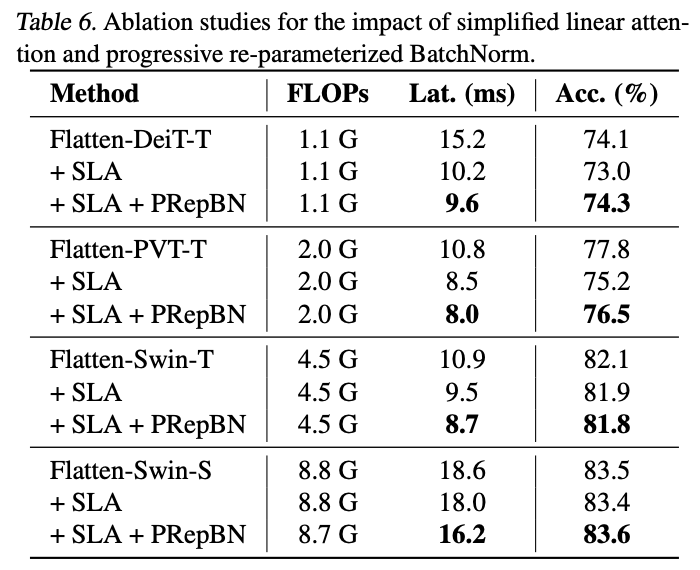
此外,注意力机制的计算成本对于高效的transformer架构至关重要,之前的方法在效率和准确性之间难以取得良好的平衡。因此,论文提出了一种简化的线性注意力(SLA)模块,该模块利用ReLU作为核函数,结合深度可分卷积来进行局部特征增强。这种注意力机制比之前的线性注意力更高效,而且能达到可比较的性能水平。
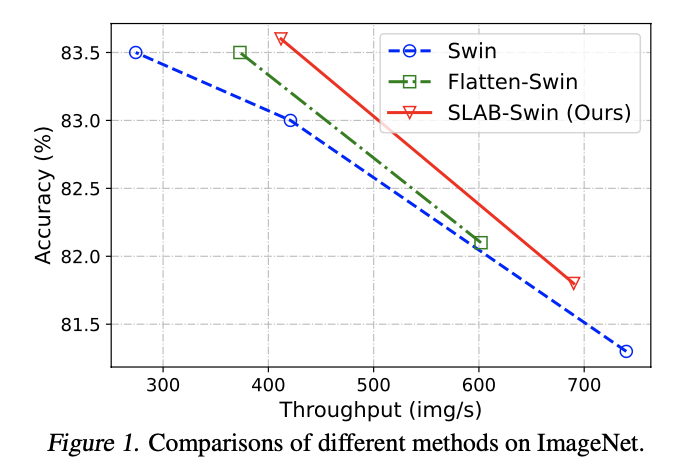
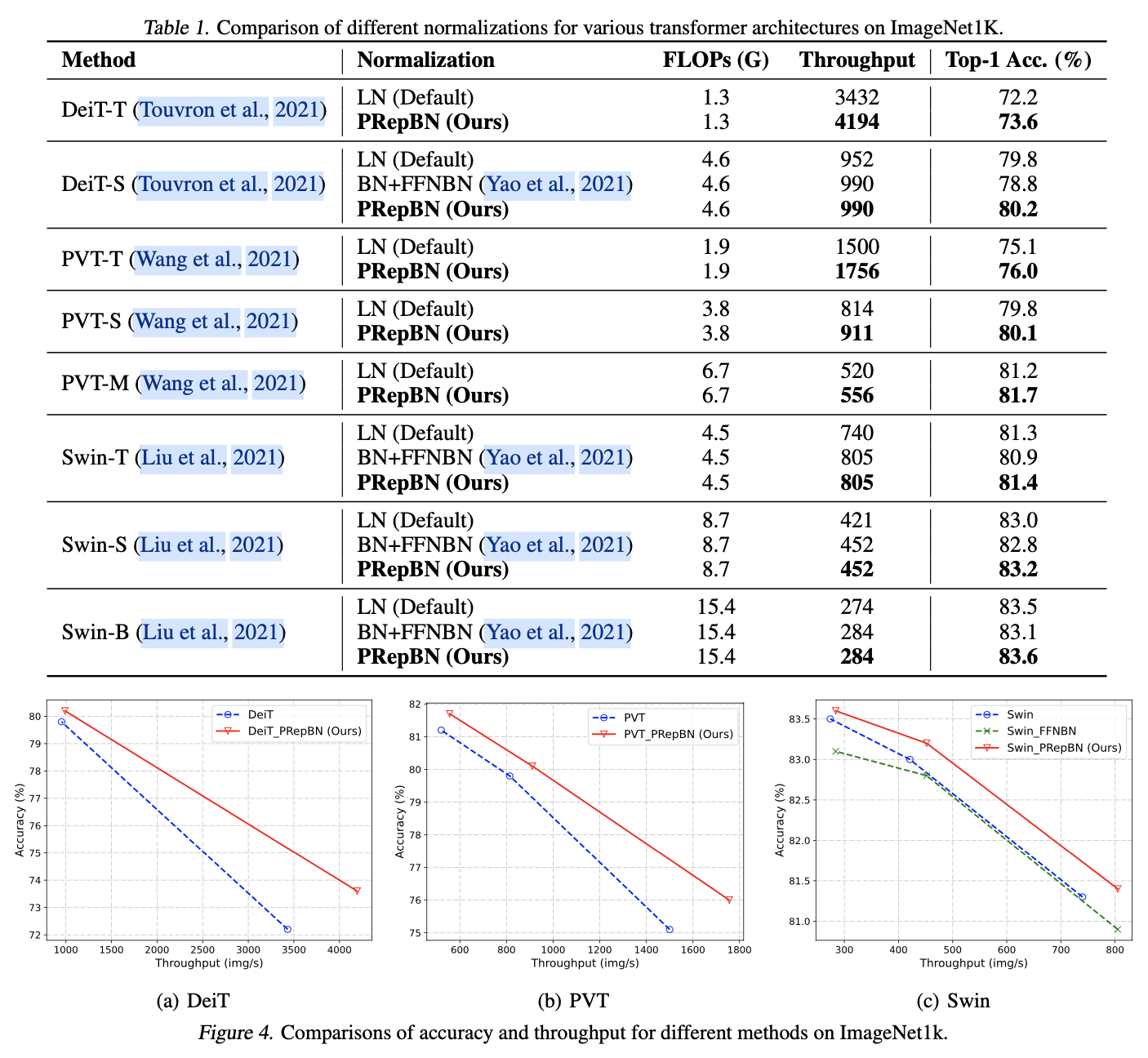
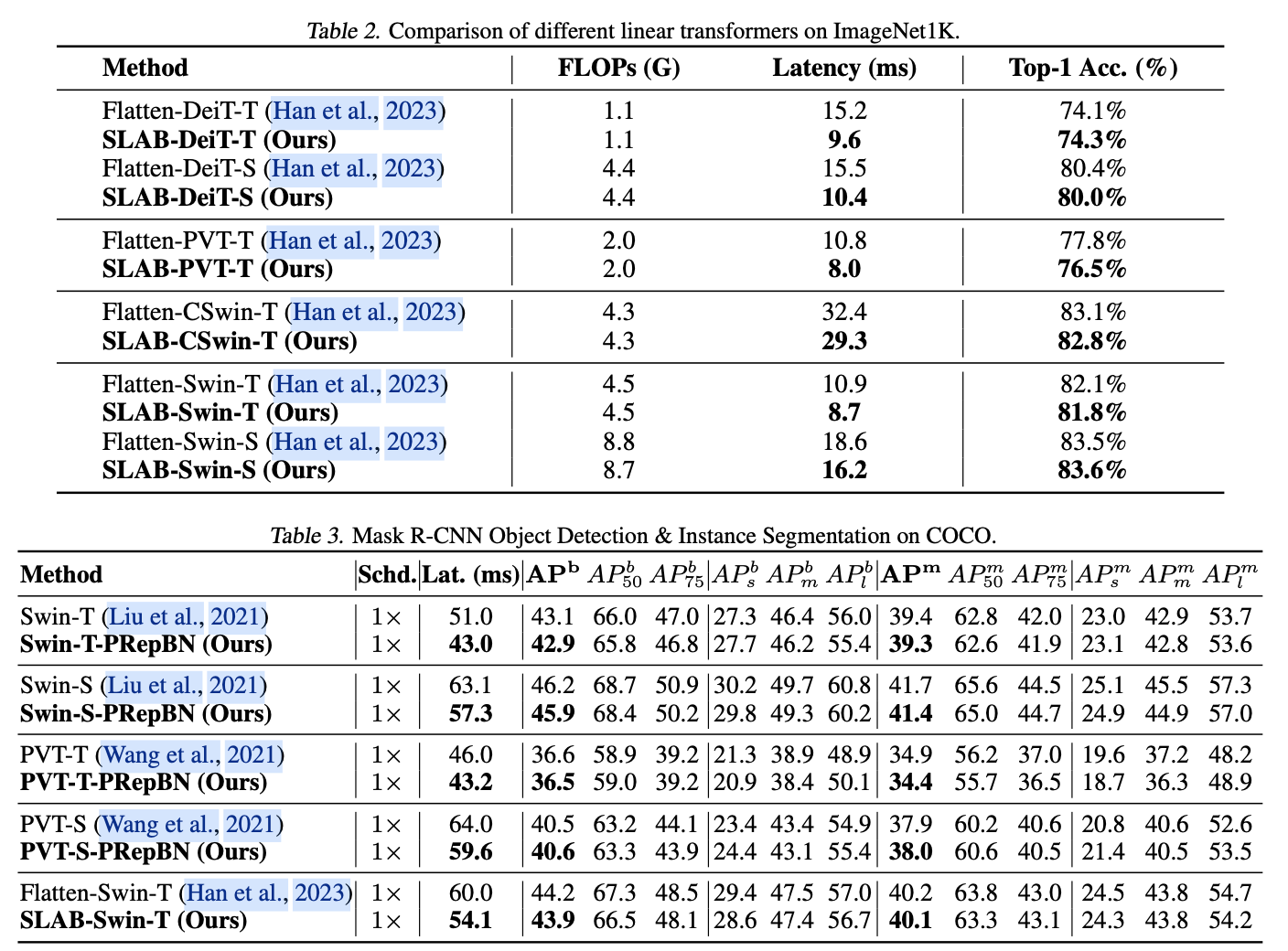
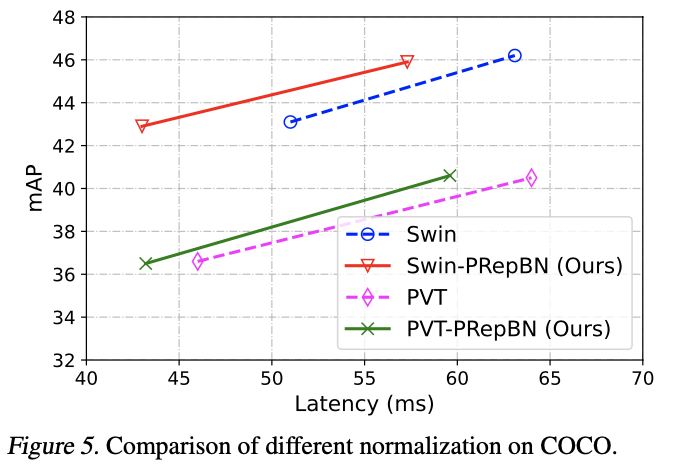
论文在各种架构和多个基准测试上广泛评估了提出的方法。渐进重新参数化的BatchNorm在图像分类和物体检测任务中表现出强大的性能,以更低的推理延迟获得类似的准确性。此外,结合渐进RepBN和简化线性注意力模块的SLAB transformer在提高计算效率的同时,与Flatten transformer相比达到了竞争性的准确性。例如,SLAB-Swin-S在ImageNet-1K上达到了83.6%的Top-1准确率,推理延迟为16.2毫秒,比Flatten-Swin-S的准确率高出0.1%,延迟则减少了2.4毫秒。论文还对提出的方法在语言建模任务上进行了评估,获得了可比较的性能和更低的推理延迟。
Preliminaries
给定输入为 \(N\) 个令牌的特征 \(X \in \mathbb{R}^{N \times C}\),其中 \(C\) 是特征维度,Transformer块的一般架构可以写成:
其中, \(\mathrm{Attn}(\cdot)\) 计算注意力分数, \(\mathrm{MLP}(\cdot)\) 表示多层感知机, \(\mathrm{Norm}(\cdot)\) 是归一化函数。在Transformer块的默认配置中, \(\mathrm{Norm}(\cdot)\) 通常是一个LayerNorm操作, \(\mathrm{Attn}(\cdot)\) 是基于softmax的注意力机制
注意力在Transformer中扮演着重要角色。将查询、键和值矩阵表示为 \(Q, K, V \in \mathbb{R}^{N \times C}\),softmax注意力首先计算查询和键之间的成对相似性。成对相似性计算导致与查询和键的数量 \(N\) 相关的二次计算复杂度 \(O(N^2C)\),使得Transformer在处理具有长序列输入的任务时计算成本昂贵。线性注意力旨在解耦softmax函数,通过适当的近似方法或者用其他核函数先计算 \(K^T V\),计算复杂度变为 \(O(NC^2)\),与查询和键的数量 \(N\) 线性相关。
然而,LayerNorm在推理过程中需要统计计算,因此占据了不可忽视的延迟部分。因此,论文探索利用BatchNorm来构建高效的Transformer模型,BatchNorm仅在训练过程中存在,并且可以与前置或顺序线性层合并。此外,注意力模块对于Transformer至关重要,而基于softmax的注意力机制由于其二次计算复杂度而在计算效率上存在问题。因此,论文提出了一种简单而高效的注意力形式,极大地减少了延迟,同时在各种视觉任务上保持了良好的性能。
Methods
论文专注于构建高效的Transformer模型,并提出了一系列策略,包括逐步替换LayerNorm(LN)为重新参数化的BatchNorm(BN)以及简化的线性注意力(SLA)模块。所提出的SLAB Transformer模型在与先前方法相比表现出了强大的性能,同时具备更高的计算效率。
Progressive Re-parameterized BatchNorm
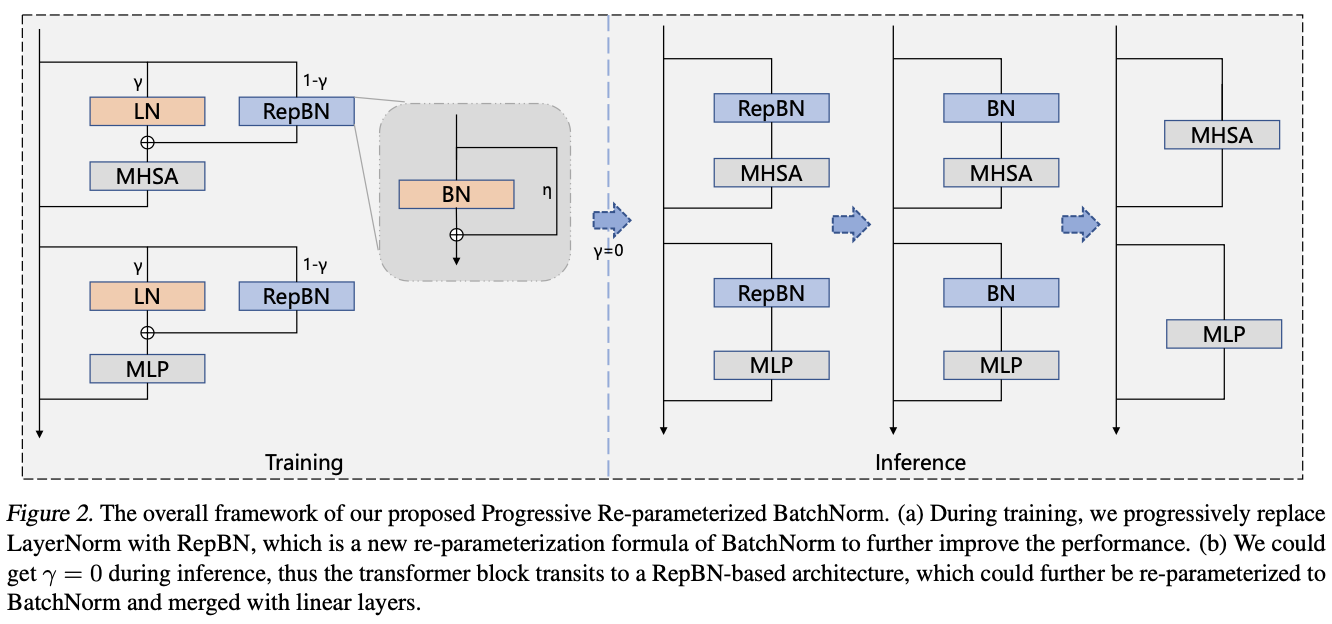
LayerNorm在训练和推理过程中都需要进行统计量计算,因此显著影响了Transformer的运行速度。相比之下,BatchNorm在推理过程中可以简单地与线性层合并,更适合于高效的架构设计。然而,直接在Transformer中使用BatchNorm会导致性能表现不佳。为此,论文提出在训练过程中逐步替换LayerNorm为BatchNorm,并且还提出了一种受Repvgg启发的新的BatchNorm重新参数化公式,以进一步提高性能,如图2所示。
-
Re-parameterized BatchNorm
RepBN公式如下:
其中, \(\eta\) 是一个可学习的参数,以端到端的方式联合训练。一旦训练完成,RepBN可以重新参数化为BatchNorm的一种规范形式。

根据引理4.1,RepBN输出的分布由 \(\alpha+\eta\sigma\) 和 \(\beta+\eta\mu\) 控制,分别对应于方差和均值。RepBN可以借助 \(\sigma\) 和 \(\mu\) 来恢复分布。
同时,当 \(\alpha=0, \beta=0\) 时,相当于跳过了BatchNorm。当 \(\eta=0\) 时,RepBN则退化为纯粹的BatchNorm。
-
Progressive LN \(\rightarrow\) RepBN
为了促进基于纯粹BN的Transformer模型的训练,论文建议在训练过程中逐步过渡从LN到RepBN,即
其中, \(\gamma\) 是一个超参数,用于控制不同归一化层的输出。通常,在训练初期LN主导架构时, \(\gamma=1\) ;在训练结束时,为了确保过渡到基于纯粹BN的Transformer, \(\gamma=0\)。我们采用了一个简单而有效的衰减策略来调整 \(\gamma\) 的值:
其中, \(T\) 表示使用LayerNorm进行训练的总步数, \(T_{cur}\) 表示当前的训练步数。这种渐进策略有助于减轻训练纯粹基于BN的Transformer的难度,从而在各种任务上实现强大的性能表现。
还有一些其他衰减策略可以逐渐减小 \(\gamma\) 的值,例如余弦衰减和阶梯衰减。从实验来看,线性策略是比较有效且简单的一种方法。
Simplified Linear Attention
注意力模块是Transformer网络中最重要的部分,通常表述为:
其中, \(W_Q, W_K, W_V \in \mathbb{R}^{C \times C}\) 将输入的标记投影到查询(query)、键(key)和值(value)张量。 \(\mathrm{Sim}(\cdot, \cdot)\) 表示相似性函数。对于注意力的原始形式,相似性函数是
这种基于softmax的注意力导致了较高的计算复杂度。近年来,有几种方法研究了使用线性注意力来避免softmax计算,从而提高Transformer的效率。然而,这些方法仍然存在相当复杂的设计,并且计算效率不够高。因此,论文提出了一种简化的线性注意力(SLA):
其中, \(DWC(\cdot)\) 表示深度可分离卷积(depth-wise convolution)。这是一种简单而高效的线性注意力方法,因为它通过先计算 \(K^T V\),享受了解耦的计算顺序,从而显著减少了复杂度。此外,该方法只使用了ReLU函数和深度可分离卷积,这两种操作在大多数硬件上都具有良好的计算效率。
这里的整体逻辑跟FLatten Transformer基本一样,只是将其提出聚焦函数替换为ReLU函数。这里的效率提升通过摘除softmax计算从而达到先计算 \(K^T V\) 实现的(公式7做下乘法结合律),ReLU(也有保证内积为正数的作用)和DWC是补充计算顺序改变带来的性能损失。
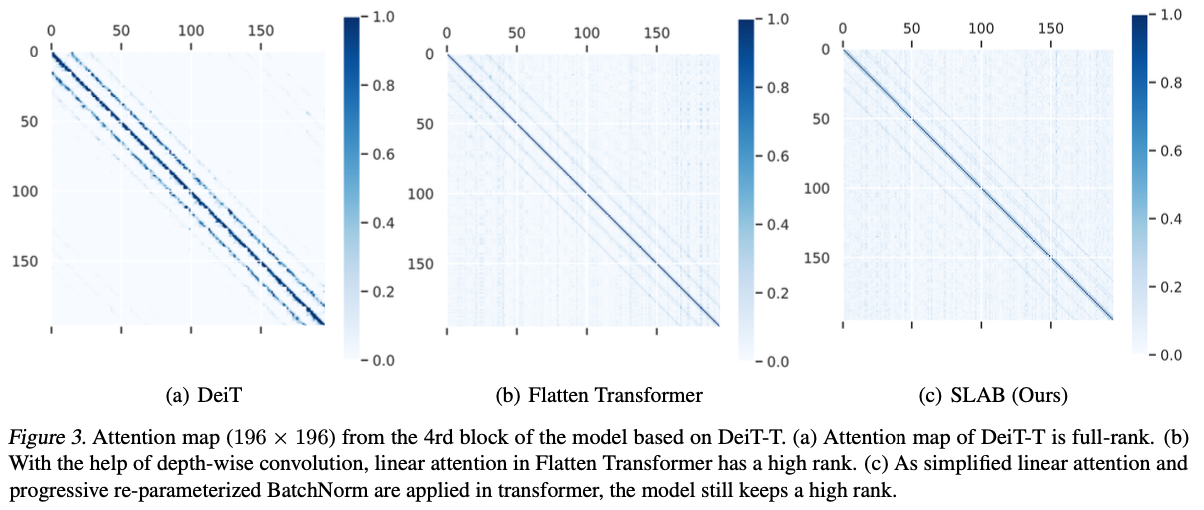
为了展示该方法仍然保持特征多样性,论文通过可视化注意力图表明了应用了渐进重新参数化批归一化和简化线性注意力(SLAB)策略的DeiT-T的效果,如图3所示。可以看出,论文提出的方法仍然保持了较高的排名,表明其在捕捉注意力信息方面具有良好的能力。
Experiments

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
