重学 KMP 小记
前言
KMP 这个东西赛时用到的几率很小(虽然圣人说概率不小、也不是很大),但是如果一旦考字符串类的题又极可能考匹配问题。当时掌握得也是一知半解,所以现在来重学来了。
情境引入
现实中我们会遇到类似的问题:
给你一篇报道,让你找一找这篇报道中有没有出现某个人的名字。
形式化地,可以说:
给你文本串 \(S\),和模式串 \(T\),判断 \(T\) 是否为 \(S\) 的子串。
这个问题我们暴力地想,可以用两个指针 \(i\),\(j\) 分别表明现在匹配到 \(S\),\(T\) 的哪个位置了(\(0\le i< len_S\),\(0\leq j<len_T\))。如果 \(S_i\neq T_j\),则 \(i\leftarrow i-j+1\)、\(j\leftarrow 0\)。相当于是推翻重来。
有没有优美一点的算法呢?答案是有的,就是我们的主角——KMP。
算法概要
我们在暴力的时候,如果一旦失配,模式串的指针 \(j\) 就又从头开始,这显然是非常浪费的。所以我们如果想降低时间复杂度,就要从这里入手。
首先我们定义一个数组 \(next_i\),其满足:\(S_{[0,next_i-1]}=S_{[i-next_i,i]}\)。\(S_{[l,r]}\) 表示 \(S_l,S_{l+1},\dots,S_{r}\) 组成的子串。当然这个 \(next_i\) 有很多种情况,我们储存的是子串最长的情况。说白了这两部分子串就是 \(S_{[0,i]}\) 的最长公共前后缀。
特别地,\(next_0=-1\)。
接下来就可以引入 KMP 了,算法流程如下:
- 如果 \(S_i\) 与 \(T_{j+1}\) 匹配成功,即相同,就 \(i\leftarrow i+1\),\(j\leftarrow j+1\),继续匹配。
- 如果失配,则令 \(i\) 不动,\(j\leftarrow next_j\)。这意味着 \(S\) 不变,将整个 \(T\) 向右移动了 \(j-next_j\) 位。这个值肯定是大于等于 \(1\) 的。
这样就没了。
现在来分析一下这个 KMP 是怎么减少浪费的。
当 \(T\) 匹配到 \(j\) 位时,说明前面都是和 \(S\) 相同的。如果此时失配了,暴力的思想是相当于直接把 \(T\) 向右平移一位,然后重新比较。这样显然没有前途。KMP 是怎么做的呢?KMP 的思想是:“既然我这个 \(T_{[0,j]}\) 里可能有公共前后缀,如果有的话,为什么我不直接把 \(T\) 向右平移至这个最长公共前后缀相同的部分呢?”。
画个草图理解一下:
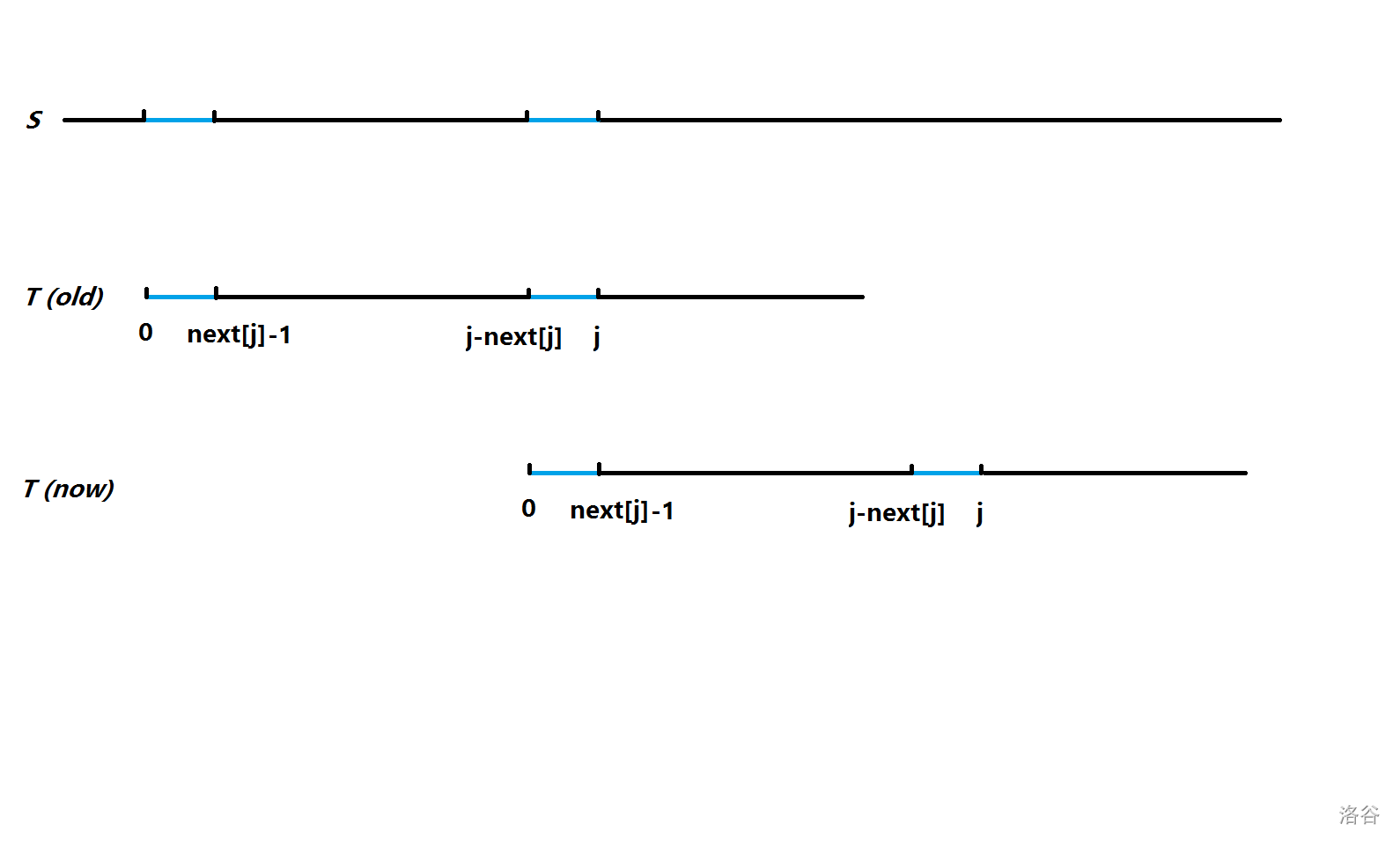
图中蓝色的部分都相同。
如何预处理 \(next_i\) 数组
考虑递推。现假设 \(next_{[0,i-1]}\) 的元素都已求出。
算法过程就很简单了:
- 如果
str[i]==str[next[i-1]+1],则next[i]=next[i-1]+1。 - 否则判断
str[i]与str[next[next[i-1]]+1]是否相等。 - 再否则,判断
str[i]与str[next[next[next[i-1]]]+1]是否相等。 - 回环往复,直至相等或 \(next\) 的值为 \(0\) 为止。
void getnxt()
{
int j=0;
for(int i=2;i<=m;i++)
{
while(j&&b[j+1]!=b[i])
j=nxt[j];
if(b[j+1]==b[i])
j++;
nxt[i]=j;
}
}
例题展现
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int MAXN=1e6+5;
int n,m;
char a[MAXN];
char b[MAXN];
int nxt[MAXN];
void getnxt()
{
int j=0;
for(int i=2;i<=m;i++)
{
while(j&&b[j+1]!=b[i])
j=nxt[j];
if(b[j+1]==b[i])
j++;
nxt[i]=j;
}
}
void kmp()
{
for(int i=1,j=0;i<=n;i++)
{
while(j&&a[i]!=b[j+1])
j=nxt[j];
if(b[j+1]==a[i])
j++;
if(j==m)
{
printf("%lld\n",i-m+1);
j=nxt[j];
}
}
}
signed main()
{
scanf("%s%s",a+1,b+1);
n=strlen(a+1),m=strlen(b+1);
getnxt();
kmp();
for(int i=1;i<=m;i++)
printf("%lld ",nxt[i]);
return 0;
}