Motivation & Abs
近年来,大语言模型在视觉方面取得了极大的进步,但其如何完成定位任务(如word grounding等)仍然不清楚。本文旨在设计一种模型能够将一系列点/边界框作为输入或者输出。当模型接受定位信息作为输入时,可以进行以定位为condition的captioning。当生成位置作为输出时,模型对LLM生成的每个输出单词的像素坐标进行回归,从而进行dense grounding。
Method
方法
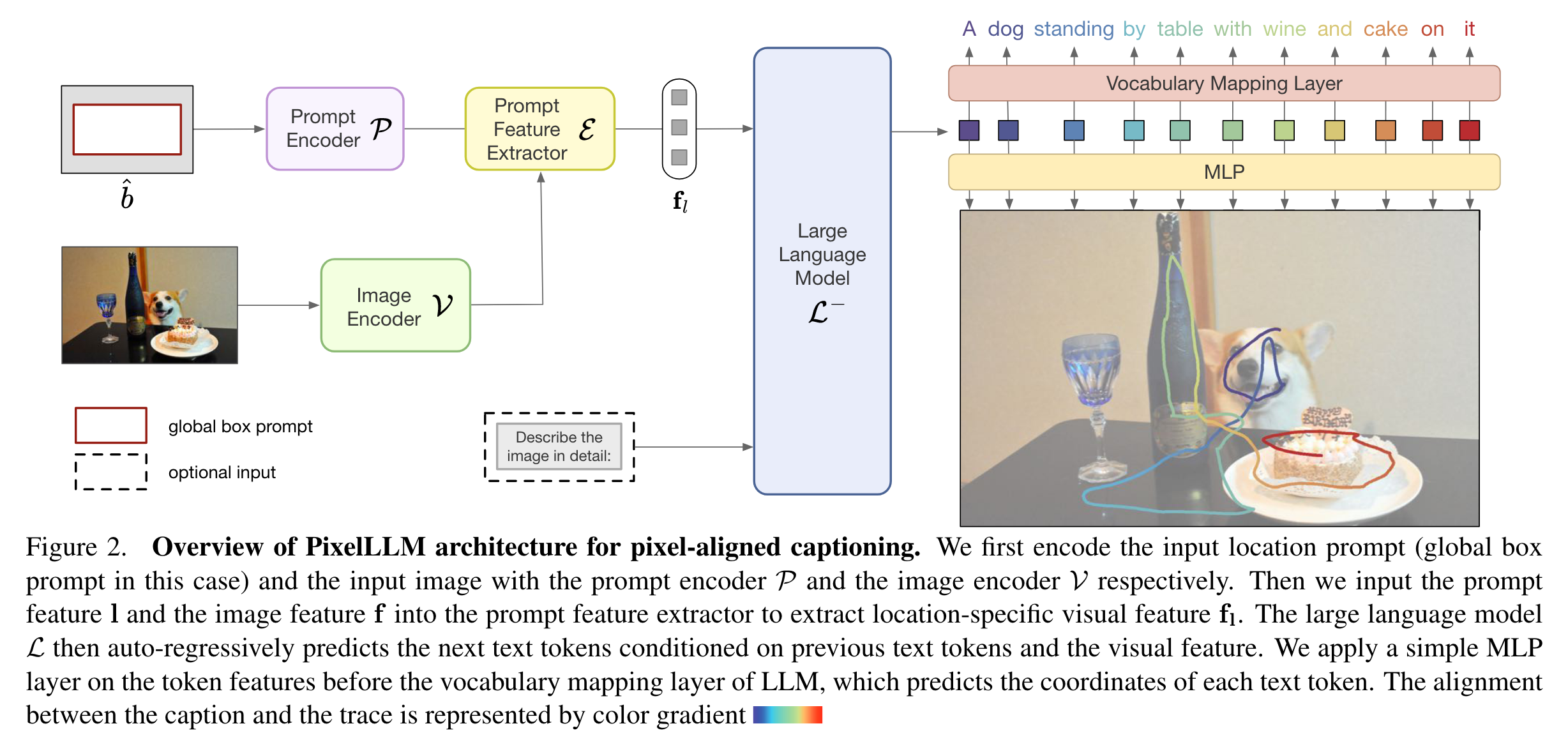
模型输入为图片以及prompt(可选),如果不指定prompt,默认的prompt为(0, 0, H, W)的box。在captioning的过程中,模型除了输出句子外,还需要输出与句子等长的点序列,每个点对应句子中的一个token。与之前的方法不同,本文方法不强制模型忽略非视觉token。
对于视觉端,首先将图像送入image encoder以及将prompt送入prompt encoder,得到图像特征\(\textbf{f}\)以及提示特征\(\mathcal{P}(b)\),之后使用prompt feature extractor \(\mathcal{E}\)得到prompt feature:
\[\textbf{f}_l=\mathcal{E}(\textbf{f},\mathcal{P}(b)) \]其中prompt feature extractor采用类似Q-Former的结构,通过可学习的query提取特征,整体作用类似ROIAlign。
在拿到location-specific的特征\(\textbf{f}_l\)后,我们可以将其送入语言模型在进行captioning,使用自回归的decoding方式:\(w_i=\mathcal{L}(\textbf{f}_l,\textbf{w}_{1:i-1})\)。语言模型的最后一个linear为vocabulary mapping layer,将语言空间的特征映射为词汇表的坐标:
\[w_i={\rm argmax}(\textbf{v}\cdot\mathcal{L}^-(\textbf{f}_l,\textbf{w}_{1:i-1})) \]因此为了得到与语言模型输出类似的定位信息,作者在vocabulary mapping layer旁添加了一个并行的mlp层,将特征映射为2维定位输出:
\[p_i={\rm MLP}(\mathcal{L}^-(\textbf{f}_l,\textbf{w}_{1:i-1})) \]额外添加的MLP并不会将梯度反传回语言模型,从而避免损害解码文本的能力。
训练
模型的训练在人类标注的captionlocation aligned数据集Localized Narrative上面进行。损失:
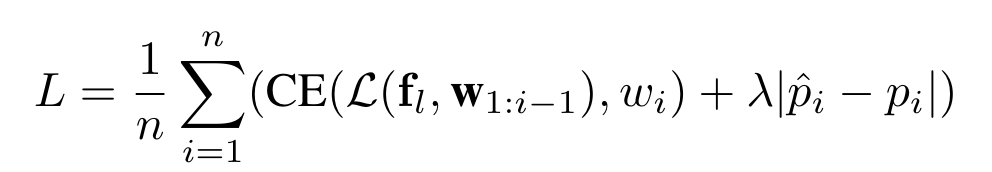
下游任务适配
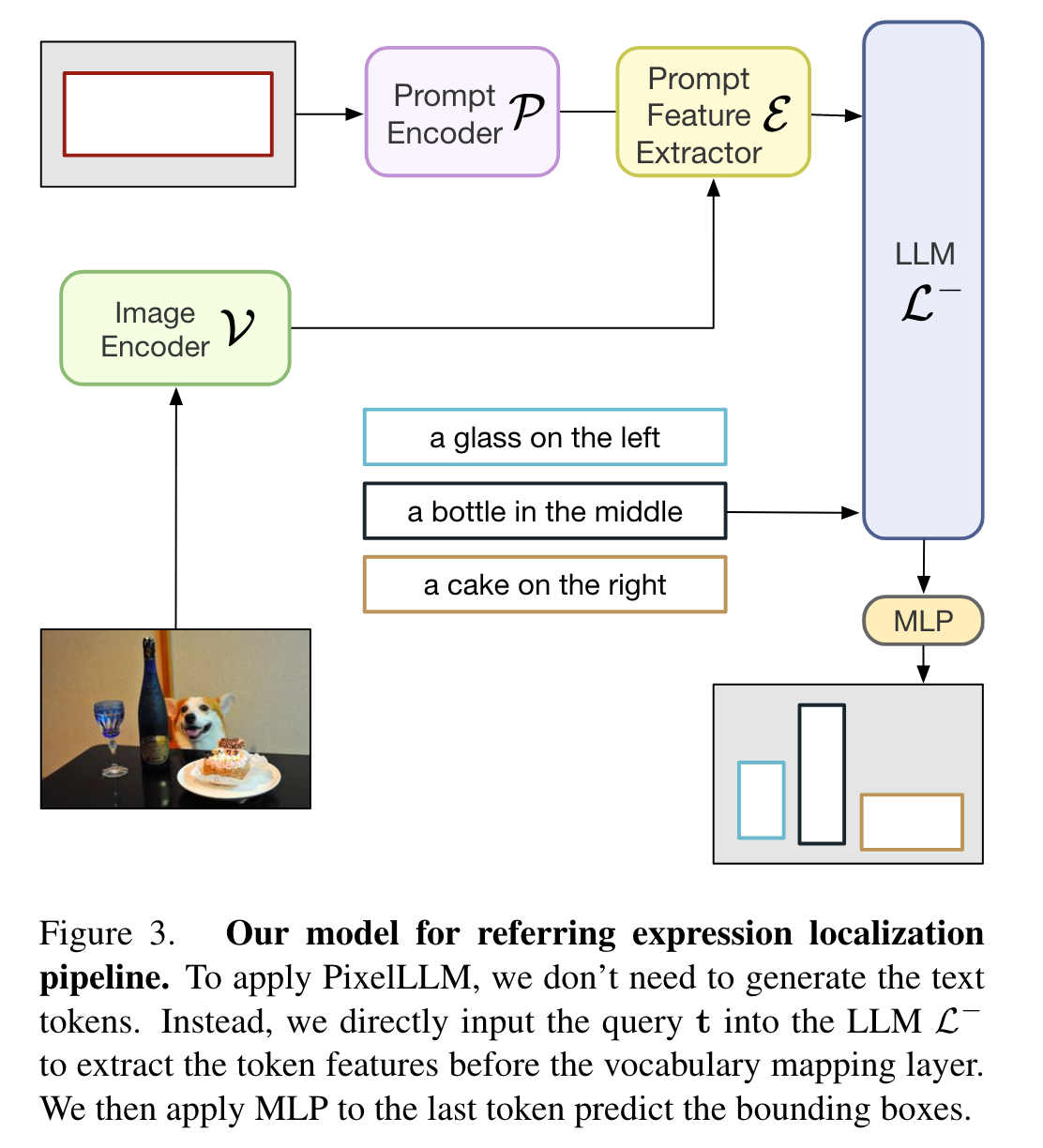
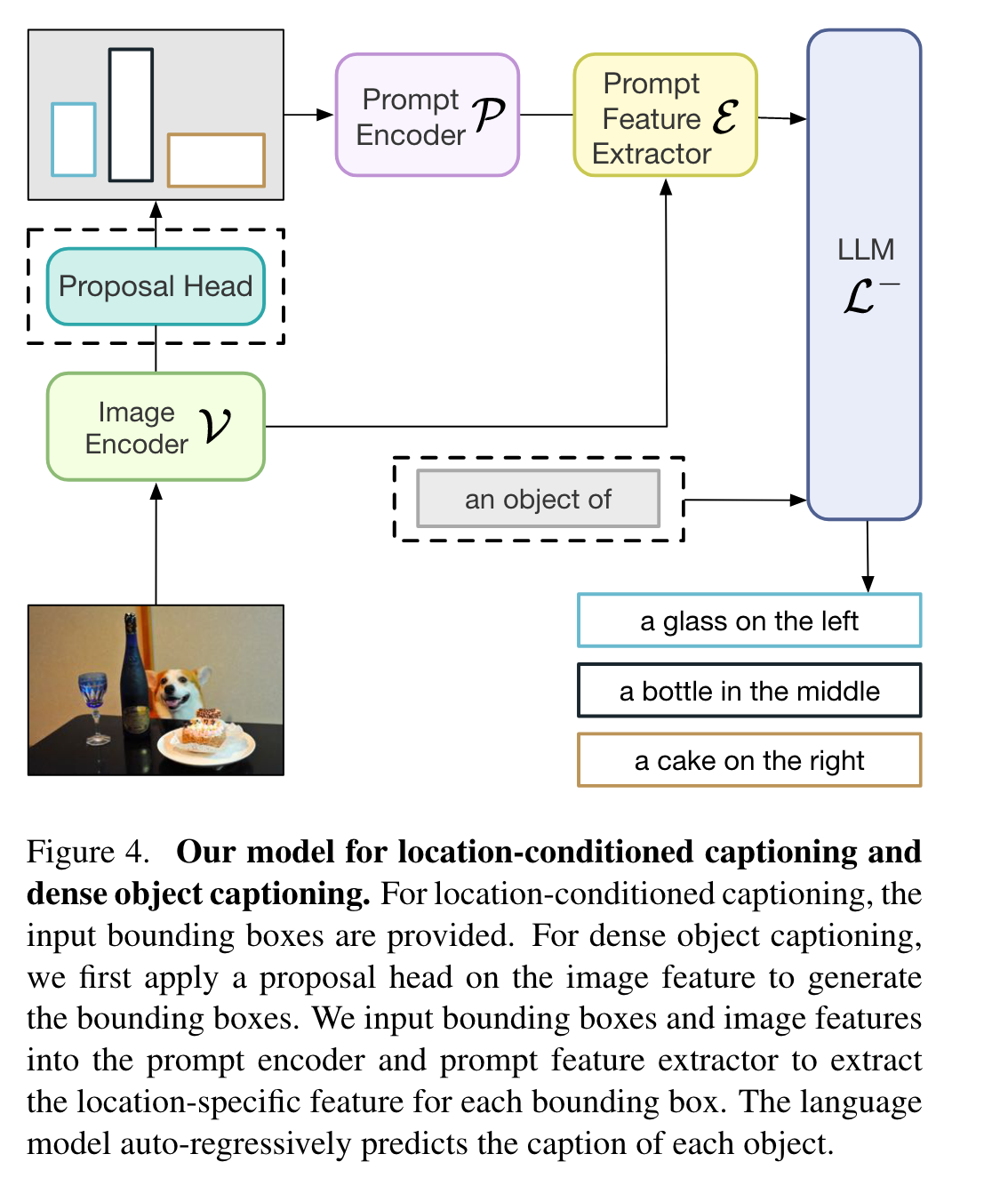
Referring localization and segmentation:虽然可以通过轨迹获得边界框,但这是次优的,因为轨迹边界不是严格的实例边界。因此,作者使用相同的回归 MLP 层训练模型在 <EOS> 标记处输出准确的对象边界框: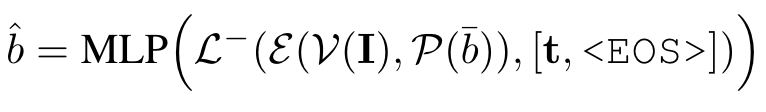
同时拿到边界框后,还能通过SAM进行分割。
其它下游任务可以参考原文。
实验
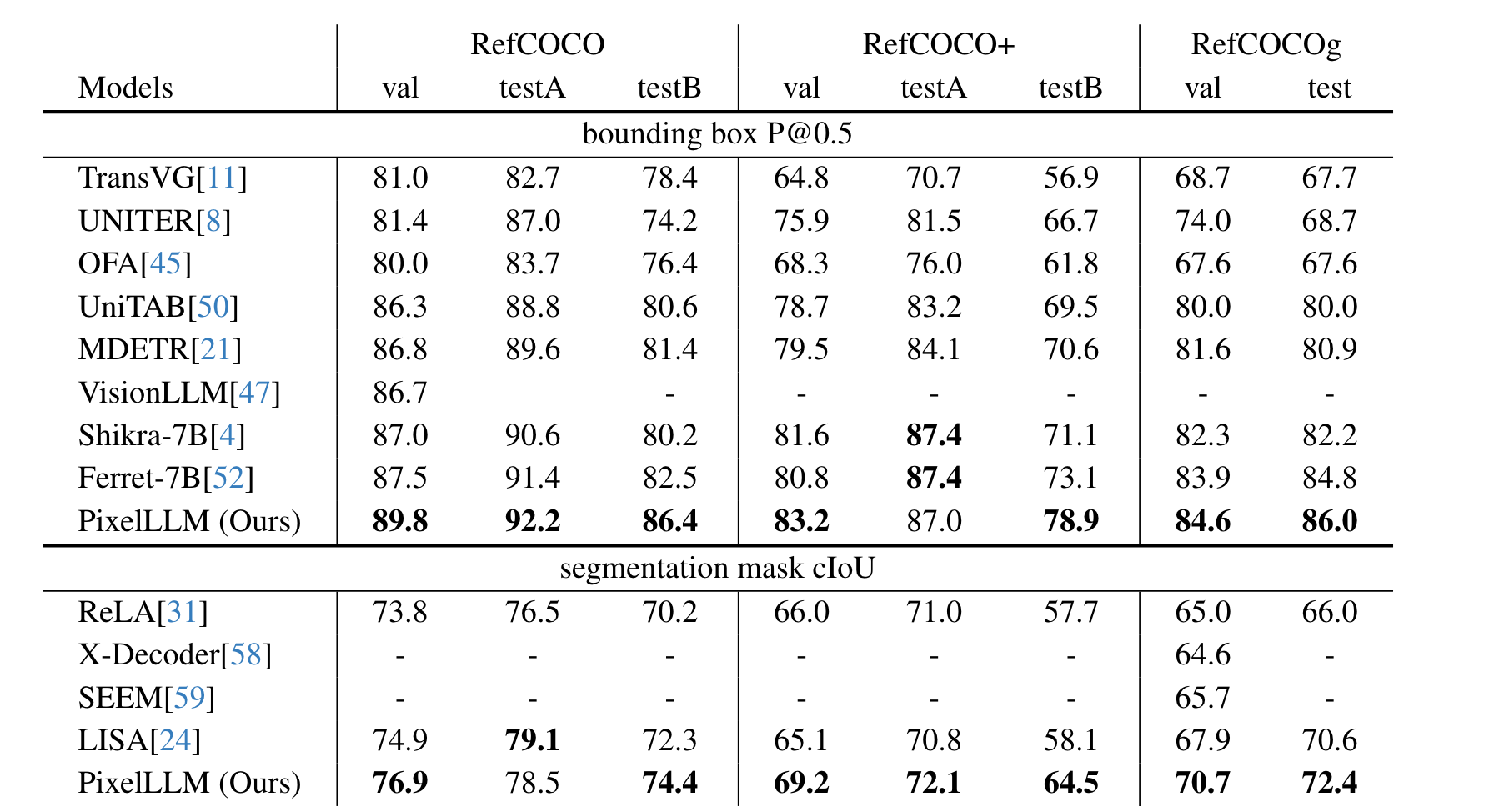
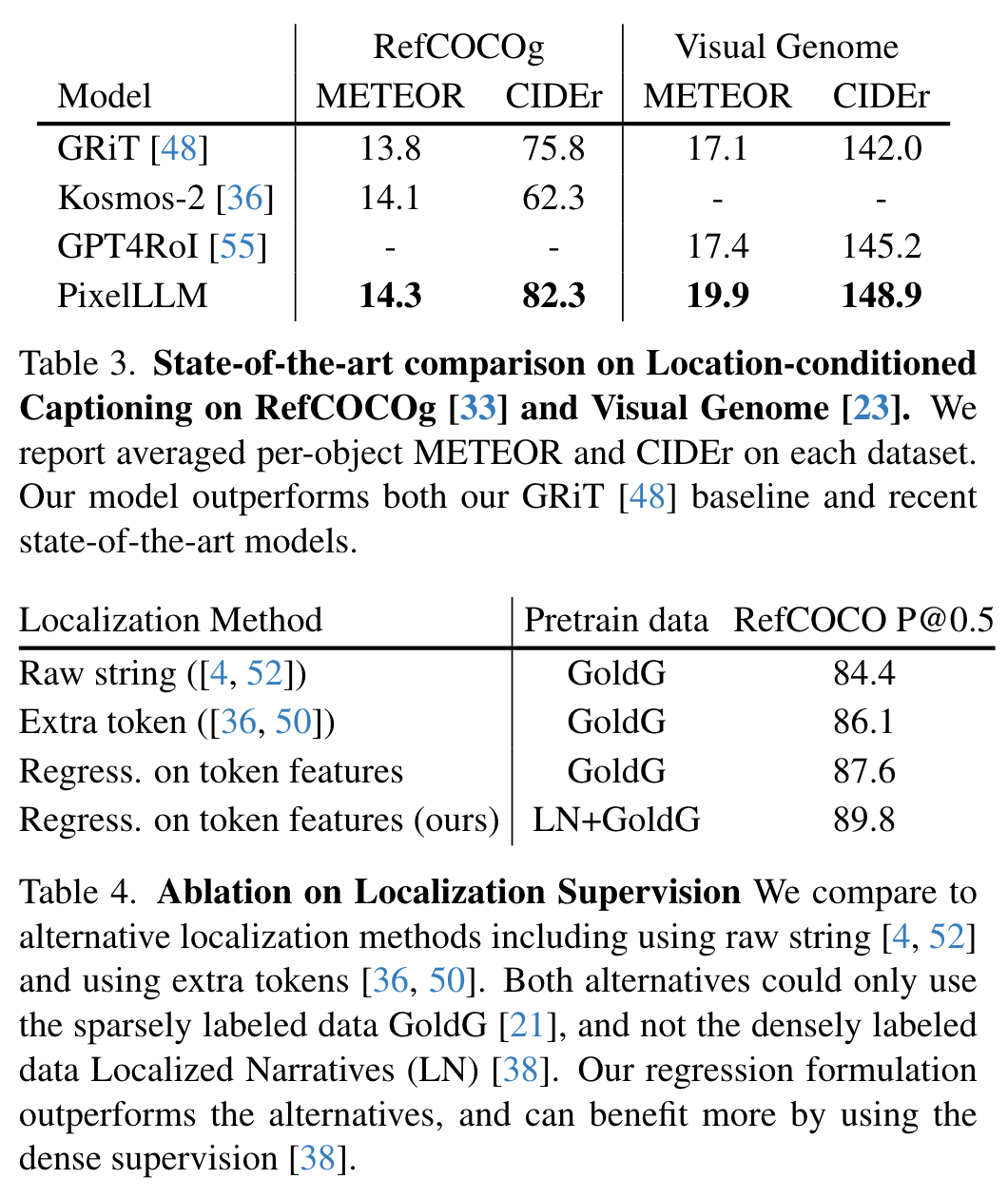
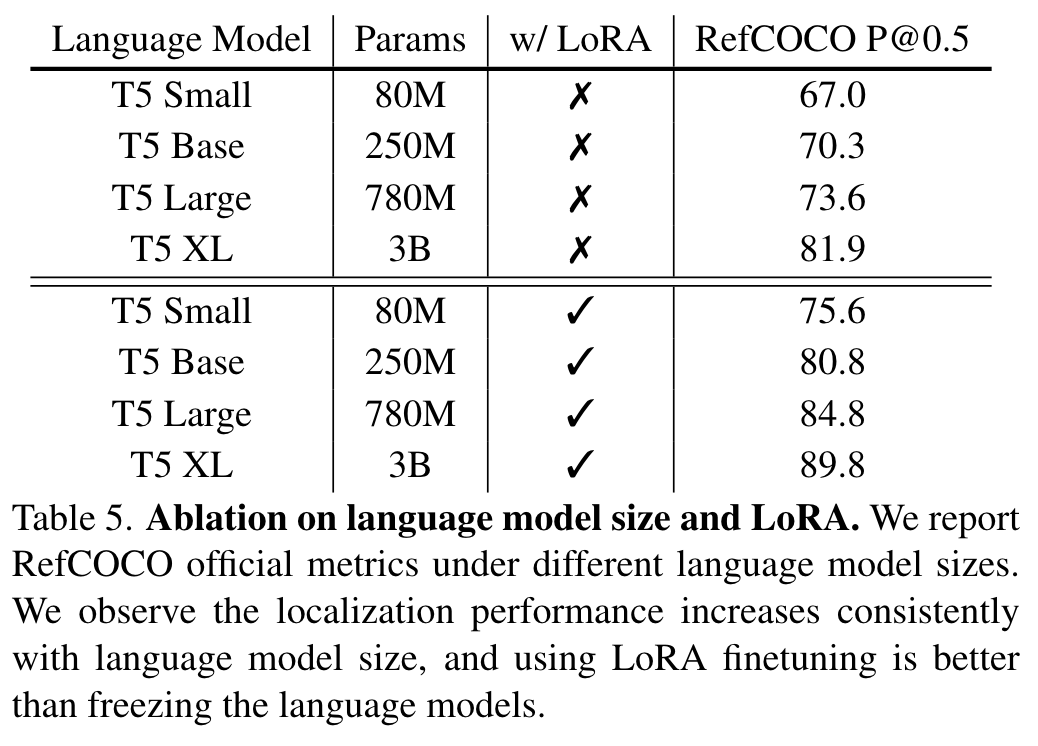 标签:输出,prompt,边界,Language,Models,模型,textbf,mathcal,Aligned
From: https://www.cnblogs.com/lipoicyclic/p/18337052
标签:输出,prompt,边界,Language,Models,模型,textbf,mathcal,Aligned
From: https://www.cnblogs.com/lipoicyclic/p/18337052