CPU上的快速多维矩阵乘法(草稿)
Numpy可以在大约8毫秒内将4核Intel CPU上的两个1024x1024矩阵相乘。考虑到这归结为18 FLOPS/核心/周期,一个周期需要三分之一纳秒,这是非常快的。Numpy使用高度优化的BLAS实现来实现这一点。BLAS是Basic Linear Algebra子程序的缩写。这些库提供快速实现,例如矩阵乘法或点积。它们有时针对一个特定的(系列)CPU进行定制,如英特尔的MKL或苹果的加速CPU。然而,OpenBLAS等非供应商特定的实现也是可用的。使用普通C++重建大致相似的性能有多难?
def MMM(A, B)
C = np.zeros((A.n_rows, B.n_columns))
for row in range(A.n_rows):
for col in range(B.n_columns):
for inner in range(A.n_inner):
C[row, col] = C[row, col] + A[row, inner] * B[inner, col]
return C
这将导致N(=行)*N(=列)*N(=点积)*2(多+加)=2N³FLOP。
 在物理机器上运行
在Numpy中,我们示例的代码如下:
x = np.random.randn(1024, 1024).astype(np.float32)
y = np.random.randn(1024, 1024).astype(np.float32)
start = time.time_ns()
z = np.dot(x, y)
end = time.time_ns() - start
当我在配备英特尔i7-6700(四核Haswell CPU)的专用服务器上运行此程序时,需要8毫秒。
总流量:20亿。
总内存(LOAD):使用fp32时为8MB。
总周期:8ms x 3.4GHz=2700万
在2015年发布的硬件上,这是18个FLOPS/核心/周期,或约250GFLOP/s。太多了!
单个核心如何在一个周期内完成18次浮点运算?
在我的Haswell服务器上,Numpy使用英特尔的BLAS MKL实现。我们特别关心SGEMM函数是如何实现的,这是矩阵乘法所需的函数。SGEMM是单精度通用矩阵倍数的缩写。GEMM执行此计算:C=α*A*B+β*C。A、B、C是矩阵,α、β是标量。在二进制文件中,有多个SGEMM实现,每个实现都特定于英特尔的一种微体系结构:例如SGEMM_kernel_HASWELL、SGEMM_ernel_SANDYBRIDGE…在运行时,BLAS库将使用cpuid指令查询处理器的详细信息,然后调用合适的函数。
仔细查看相关的sgem_kernel_HASWELL,速度来自使用矢量化。矢量化/SMD指令一次对矢量输入的所有条目执行相同的指令:FMAFMA代表融合多加。这意味着执行A=A+B*C,但使用单个(融合)指令。有时这也被称为MAC(乘法累加)。指令,在我的特定情况下是VFMADD指令。它在三个256位长的YMM寄存器上运行,计算(YMM1*YMM2)+YMM3,并将结果存储在YMM3中。这允许CPU在一条指令中执行16个单精度浮点运算。检查Agner Fog的指令表和uops.info,VFMADD有一个吞吐量。令人困惑的是,这是互惠吞吐量,即同一线程中一系列同类独立指令的每条指令的平均时钟周期数。0.5个周期。这意味着我们的理论上限应该是每个周期2个VFMADD指令,或32个FLOPS/周期。
延迟延迟这里是启动指令和使结果可用于其他指令之间的循环数。在5个周期中,这意味着我们需要找到10*16个可以独立调度的FLOPS,因为之前的指令的结果在启动后只有5个周期可用。在编写优化代码时,这将是一个考虑因素:将足够多的独立操作分组,以便CPU可以一次调度所有操作,充分利用其指令级并行性(ILP)功能。
综上所述,英特尔的BLAS库实现了18 FLOPS/核/周期,其中理论上限为32 FLOPS/核心/周期。相当狂野!实际上,实现速度更快,因为我们还测量了一些Python开销和启动OpenMP线程池的时间。
请注意,即使矩阵没有那么大,我们已经很强地计算了界限。从RAM加载8MB可能需要200μs,假设多线程、SIMD内存访问的内存带宽为40GB/s。来自优秀餐巾纸数学项目的数字。。如果矩阵变大,我们的计算量就会变大,因为我们对2n²的负载执行2n³FLOPS。
试图从头开始重现这种表现
为了破坏结果,我们最终将实现一个执行9个FLOPS/core/循环的实现,但仅适用于特定大小的矩阵。本文的目标不是编写一个有竞争力的BLAS实现,而是学习常见的性能优化。相比之下,OpenBlas中的MMM实现是手写汇编的约7K LOC。
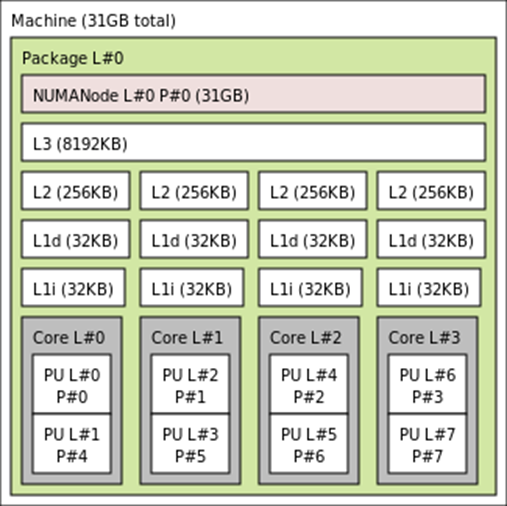
我在专用服务器上的3.40GHz四核Intel i7-6700 CPU上运行此程序。它具有每核32KiB的L1d缓存、每核256KiB的L2缓存和共享的8MB L3缓存。用lstopo可视化:
我使用的编译器是clang v14.0。基准测试是通过谷歌基准测试完成的。
在物理机器上运行
在Numpy中,我们示例的代码如下:
x = np.random.randn(1024, 1024).astype(np.float32)
y = np.random.randn(1024, 1024).astype(np.float32)
start = time.time_ns()
z = np.dot(x, y)
end = time.time_ns() - start
当我在配备英特尔i7-6700(四核Haswell CPU)的专用服务器上运行此程序时,需要8毫秒。
总流量:20亿。
总内存(LOAD):使用fp32时为8MB。
总周期:8ms x 3.4GHz=2700万
在2015年发布的硬件上,这是18个FLOPS/核心/周期,或约250GFLOP/s。太多了!
单个核心如何在一个周期内完成18次浮点运算?
在我的Haswell服务器上,Numpy使用英特尔的BLAS MKL实现。我们特别关心SGEMM函数是如何实现的,这是矩阵乘法所需的函数。SGEMM是单精度通用矩阵倍数的缩写。GEMM执行此计算:C=α*A*B+β*C。A、B、C是矩阵,α、β是标量。在二进制文件中,有多个SGEMM实现,每个实现都特定于英特尔的一种微体系结构:例如SGEMM_kernel_HASWELL、SGEMM_ernel_SANDYBRIDGE…在运行时,BLAS库将使用cpuid指令查询处理器的详细信息,然后调用合适的函数。
仔细查看相关的sgem_kernel_HASWELL,速度来自使用矢量化。矢量化/SMD指令一次对矢量输入的所有条目执行相同的指令:FMAFMA代表融合多加。这意味着执行A=A+B*C,但使用单个(融合)指令。有时这也被称为MAC(乘法累加)。指令,在我的特定情况下是VFMADD指令。它在三个256位长的YMM寄存器上运行,计算(YMM1*YMM2)+YMM3,并将结果存储在YMM3中。这允许CPU在一条指令中执行16个单精度浮点运算。检查Agner Fog的指令表和uops.info,VFMADD有一个吞吐量。令人困惑的是,这是互惠吞吐量,即同一线程中一系列同类独立指令的每条指令的平均时钟周期数。0.5个周期。这意味着我们的理论上限应该是每个周期2个VFMADD指令,或32个FLOPS/周期。
延迟延迟这里是启动指令和使结果可用于其他指令之间的循环数。在5个周期中,这意味着我们需要找到10*16个可以独立调度的FLOPS,因为之前的指令的结果在启动后只有5个周期可用。在编写优化代码时,这将是一个考虑因素:将足够多的独立操作分组,以便CPU可以一次调度所有操作,充分利用其指令级并行性(ILP)功能。
综上所述,英特尔的BLAS库实现了18 FLOPS/核/周期,其中理论上限为32 FLOPS/核心/周期。相当狂野!实际上,实现速度更快,因为我们还测量了一些Python开销和启动OpenMP线程池的时间。
请注意,即使矩阵没有那么大,我们已经很强地计算了界限。从RAM加载8MB可能需要200μs,假设多线程、SIMD内存访问的内存带宽为40GB/s。来自优秀餐巾纸数学项目的数字。。如果矩阵变大,我们的计算量就会变大,因为我们对2n²的负载执行2n³FLOPS。
试图从头开始重现这种表现
为了破坏结果,我们最终将实现一个执行9个FLOPS/core/循环的实现,但仅适用于特定大小的矩阵。本文的目标不是编写一个有竞争力的BLAS实现,而是学习常见的性能优化。相比之下,OpenBlas中的MMM实现是手写汇编的约7K LOC。
我在专用服务器上的3.40GHz四核Intel i7-6700 CPU上运行此程序。它具有每核32KiB的L1d缓存、每核256KiB的L2缓存和共享的8MB L3缓存。用lstopo可视化:
我使用的编译器是clang v14.0。基准测试是通过谷歌基准测试完成的。
 添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
| 执行 |
时间 (ms) |
|
初步实施 (RCI) |
4481 |
|
朴素实现 (RCI) + 编译器标志 |
1621 |
|
初步实施 (RCI) + 标志+寄存器累计 |
1512 |
|
缓存感知循环重新排序 (RIC) |
89 |
|
循环重新排序 (RIC) + L1 tiling on I |
70 |
|
循环重排序 (RIC) + I上的L1平铺 + R&C上的多线程 |
16 |
| Numpy (MKL) | 8 |