标签: Diffusion bar 代码 frac sqrt alpha DDIM xt
DIFFUSION 系列笔记|DDIM 数学、思考与 ppdiffuser 代码探索 论文:DENOISING DIFFUSION IMPLICIT MODELS
参考 博客open in new window ; 参考 aistudio notebook 链接,其中包含详细的公式与代码探索: linkopen in new window
该文章主要对 DDIM 论文中的公式进行小白推导,同时笔者将使用 ppdiffuser 中的 DDIM 与 DDPM 探索两者之间的联系。读者能够对论文中的大部分公式如何得来,用在了什么地方有初步的了解。
本文将包括以下部分:
总结 DDIM。 Non-Markovian Forward Processes: 从 DDPM 出发,记录论文中公式推导 探索与思考: 验证当 η = 1 \eta=1 DDIM 的加速采样过程 DDIM 采样的确定性 INTERPOLATION IN DETERMINISTIC GENERATIVE PROCESSES DDIM 总览 不同于 DDPM 基于马尔可夫的 Forward Process,DDIM 提出了 NON-MARKOVIAN FForward Processes。(见 Forward Process) 基于这一假设,DDIM 推导出了相比于 DDPM 更快的采样过程。(见探索与思考 ) 相比于 DDPM,DDIM 的采样是确定的,即给定了同样的初始噪声 x t x_t x 0 x_0 探索与思考 ) DDIM 和 DDPM 的训练方法相同 ,因此在 DDPM 基础上加上 DDIM 采样方案即可。(见探索与思考 ) Forward process DDIM 论文中公式的符号与 DDPM 不相同,如 DDIM 论文中的 α \alpha α ˉ \bar\alpha α t \alpha_t α t α t − 1 \frac {\alpha_t}{\alpha_{t-1}} ( 1 ) − ( 5 ) (1)-(5)
以下我们统一采用 DDPM 中的符号进行标记。即 α ˉ t = α 1 α 2 . . . α t \bar\alpha_t = \alpha_1\alpha_2...\alpha_t
在 DDPM 笔记 扩散模型探索:DDPM 笔记与思考open in new window 中,我们总结了 DDPM 的采样公式推导过程为:
x t → m o d e l ϵ θ ( x t , t ) → P ( x t ∣ x 0 ) → P ( x 0 ∣ x t , ϵ θ ) x ^ 0 ( x t , ϵ θ ) → 推导 μ ( x t , x ^ 0 ) , β t → P ( x t − 1 ∣ x t , x 0 ) x ^ t − 1 x_t\xrightarrow{model} \epsilon_\theta(x_t,t) \xrightarrow {P(x_t|x_0)\rightarrow P(x_0|x_t,\epsilon_\theta)}\hat x_0(x_t, \epsilon_\theta) \\ \xrightarrow {\text{ 推导 }}\mu(x_t, \hat x_0),\beta_t\xrightarrow{P(x_{t-1}|x_t, x_0)}\hat x_{t-1}
而后我们用 x ^ t − 1 \hat x_{t-1} x t − 1 x_{t-1} p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) ( 7 ) (7)
q σ ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; α ˉ t − 1 x 0 + 1 − α ˉ t − 1 − σ t 2 x t − α ˉ t x 0 1 − α ˉ t , σ t 2 I ) (1) q_\sigma\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right)=\mathcal{N}\left(\mathbf{x}_{t-1} ; \sqrt{\bar\alpha_{t-1}} \mathbf{x}_0+\sqrt{1-\bar\alpha_{t-1}-\sigma_t^2} \frac{\mathbf{x}_t-\sqrt{\bar\alpha_t} \mathbf{x}_0}{\sqrt{1-\bar\alpha_t}}, \sigma_t^2 \mathbf{I}\right)\tag1
论文作者提到了 ( 1 ) (1)
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) , α ˉ t = ∏ T α t (2) q(x_t|x_0) =N (x_t; \sqrt {\bar \alpha_t} x_0, (1-\bar\alpha_t)I),\bar \alpha_t=\prod_T\alpha_t\tag 2
公式 ( 1 ) (1)
q ( x t ∣ x t − 1 , x 0 ) = q ( x t − 1 ∣ x t , x 0 ) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) (3) q(x_t|x_{t-1},x_0) = \frac{q(x_{t-1}|x_t,x_0)q(x_t|x_0)}{q(x_{t-1}|x_0)}\tag 3
推导得来。至于如何推导,生成扩散模型漫谈(四):DDIM = 高观点 DDPMopen in new window 中通过待定系数法给出了详细的解释,由于解释计算过程较长,此处就不展开介绍了。
根据 ( 1 ) (1) ( 9 ) (9)
x 0 = x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) α ˉ t (4) x_0 = \frac{\boldsymbol{x}_t-\sqrt{1-\bar\alpha_t} \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)}{\sqrt{\bar\alpha_t}}\tag 4
带入,我们能写出采样公式(即论文中的核心公式 ( 12 ) (12)
x t − 1 = α ˉ t − 1 ( x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) α ˉ t ) ⏟ " predicted x 0 " + 1 − α ˉ t − 1 − σ t 2 ⋅ ϵ θ ( t ) ( x t ) ⏟ "direction pointing to x t " + σ t ϵ t ⏟ random noise (5) \boldsymbol{x}_{t-1}=\sqrt{\bar\alpha_{t-1}} \underbrace{\left(\frac{\boldsymbol{x}_t-\sqrt{1-\bar\alpha_t} \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)}{\sqrt{\bar\alpha_t}}\right)}_{\text {" predicted } \boldsymbol{x}_0 \text { " }}+\underbrace{\sqrt{1-\bar\alpha_{t-1}-\sigma_t^2} \cdot \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)}_{\text {"direction pointing to } \boldsymbol{x}_t \text { " }}+\underbrace{\sigma_t \epsilon_t}_{\text {random noise }}\tag 5
其中,σ \sigma ( 16 ) (16)
σ t = η ( 1 − α ˉ t − 1 ) / ( 1 − α ˉ t ) 1 − α ˉ t / α ˉ t − 1 (6) \sigma_t =\eta \sqrt {(1-\bar\alpha_{t-1})/(1-\bar\alpha_t)} \sqrt{1-\bar\alpha_t/\bar\alpha_{t-1}}\tag 6
如果 η = 0 \eta = 0
论文中指出, 当 η = 1 \eta=1 。也就是说当 η = 1 \eta=1 ( 5 ) (5) ( 7 ) (7)
x ^ t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z where z = N ( 0 , I ) (7) \begin{aligned} \hat x_{t-1}&=\frac 1{\sqrt { \alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar\alpha_t}}\epsilon_\theta(x_t,t)) + \sigma_t z\\ &\text{where }z=N(0,I) \end{aligned}\tag 7
将 ( 6 ) (6) ( 1 ) (1) α ˉ t = ∏ T α t \bar \alpha_t=\prod_T\alpha_t
1 − α ˉ t − 1 − σ t 2 = 1 − α ˉ t − 1 1 − α ˉ t α t (8) \sqrt{1-\bar\alpha_{t-1}-\sigma_t^2} =\frac{1-\bar\alpha_{t-1}}{\sqrt{1-\bar\alpha_t}}\sqrt{\alpha_t} \tag 8
上式的推导过程 1 − α ˉ t 1 − α ˉ t 1 − α ˉ t − 1 − σ t 2 = [ ( 1 − α ˉ t − 1 − ( 1 − α ˉ t − 1 1 − α ˉ t ) ( 1 − α t ) ] ( 1 − α ˉ t ) 1 − α ˉ t = ( 1 − α ˉ t − 1 ) ( 1 − ( 1 − α ˉ t − 1 1 − α ˉ t ) ( 1 − α t ) ) ( 1 − α ˉ t − 1 ) 1 − α ˉ t = ( 1 − α ˉ t − 1 ) ( 1 − α ˉ t − 1 + α ˉ t α ˉ t − 1 ) 1 − α ˉ t = ( 1 − α ˉ t − 1 ) ( 1 − α ˉ t − 1 ) α ˉ t α ˉ t − 1 1 − α ˉ t = 1 − α ˉ t − 1 1 − α ˉ t α t \begin{aligned} \frac {\sqrt{1-\bar\alpha_t}}{\sqrt{1-\bar\alpha_t}} \sqrt{1-\bar\alpha_{t-1}-\sigma_t^2} &= \frac{\sqrt{[(1-\bar\alpha_{t-1}-(\frac{1-\bar\alpha_{t-1}}{1-\bar\alpha_t})(1-\alpha_t)](1-\bar\alpha_t)}}{\sqrt{1-\bar\alpha_t}}\\ &=\frac{\sqrt{(1-\bar\alpha_{t-1})(1-(\frac{1-\bar\alpha_{t-1}}{1-\bar\alpha_t})(1-\alpha_t))(1-\bar\alpha_{t-1})}}{\sqrt{1-\bar\alpha_t}} \\ &= \frac{\sqrt{(1-\bar\alpha_{t-1})(1-\bar\alpha_t-1+\frac{\bar\alpha_t}{\bar\alpha_{t-1}})}}{\sqrt{1-\bar\alpha_t}}\\ &= \frac{\sqrt{(1-\bar\alpha_{t-1})(1-\bar\alpha_{t-1})\frac{\bar\alpha_t}{\bar\alpha_{t-1}}}}{\sqrt{1-\bar\alpha_t}} \\&=\frac{1-\bar\alpha_{t-1}}{\sqrt{1-\bar\alpha_t}}\sqrt{\alpha_t} \end{aligned}
因此
x t − 1 = α ˉ t − 1 ( x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) α ˉ t ) ⏟ " predicted x 0 " + 1 − α ˉ t − 1 − σ t 2 ⋅ ϵ θ ( t ) ( x t ) ⏟ "direction pointing to x t " + σ t ϵ t ⏟ random noise = α ˉ t − 1 α ˉ t x t − α ˉ t − 1 α ˉ t 1 − α ˉ t ϵ θ ( t ) + 1 − α ˉ t − 1 1 − α ˉ t α t ϵ θ ( t ) + σ t ϵ t = 1 α t x t − 1 α t 1 − α ˉ t ( 1 − α ˉ t + ( 1 − α ˉ t − 1 ) α t ) ϵ θ ( t ) + σ t ϵ t = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( t ) ) + σ t ϵ t = 1 α t ( x t − β t 1 − α ˉ t ϵ θ ( t ) ) + σ t ϵ t (9) \begin{aligned} \boldsymbol{x}_{t-1}&=\sqrt{\bar\alpha_{t-1}} \underbrace{\left(\frac{\boldsymbol{x}_t-\sqrt{1-\bar\alpha_t} \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)}{\sqrt{\bar\alpha_t}}\right)}_{\text {" predicted } \boldsymbol{x}_0 \text { " }}+\underbrace{\sqrt{1-\bar\alpha_{t-1}-\sigma_t^2} \cdot \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)}_{\text {"direction pointing to } \boldsymbol{x}_t \text { " }}+\underbrace{\sigma_t \epsilon_t}_{\text {random noise }} \\&= \sqrt \frac{\bar\alpha_{t-1}}{\bar\alpha_t} x_t-\sqrt \frac{\bar\alpha_{t-1}}{\bar\alpha_t} \sqrt {1-\bar\alpha_t} \epsilon_\theta^{(t)} + \frac{1-\bar\alpha_{t-1}}{\sqrt{1-\bar\alpha_t}}\sqrt{\alpha_t} \epsilon_\theta^{(t)} + \sigma_t \epsilon_t \\&=\frac 1{\sqrt\alpha_t}x_t - \frac 1{\sqrt\alpha_t \sqrt{1-\bar\alpha_t}}\left(1-\bar\alpha_t+(1-\bar\alpha_{t-1})\alpha_t \right)\epsilon_\theta^{(t)} + \sigma_t \epsilon_t\\ &=\frac 1{\sqrt\alpha_t}\left(x_t - \frac{1-\alpha_t}{\sqrt{1-\bar\alpha_t}} \epsilon_\theta^{(t)} \right)+ \sigma_t \epsilon_t\\ &=\frac 1{\sqrt\alpha_t}\left(x_t - \frac{\beta_t}{\sqrt{1-\bar\alpha_t}} \epsilon_\theta^{(t)} \right)+ \sigma_t \epsilon_t \end{aligned} \tag 9
因此,根据推导,η = 1 \eta=1 η = 1 \eta=1
探索与思考 接下来将根据飞桨开源的 PaddleNLP/ppdiffusers,探索以下四个内容:
验证当 η = 1 \eta=1 DDIM 的加速采样过程 DDIM 采样的确定性 INTERPOLATION IN DETERMINISTIC GENERATIVE PROCESSES 读者可以在 Aistudio 上使用免费 GPU 体验以下的代码内容。链接:扩散模型探索:DDIM 笔记与思考open in new window
DDIM 与 DDPM 探索 验证当 η = 1 \eta=1
我们使用 DDPM 模型训练出来的 google/ddpm-celebahq-256 人像模型权重进行测试,根据上文的推导,当 η = 1 \eta=1 DDPMPipeline 加载模型权重 google/ddpm-celebahq-256 ,而后采用 DDIMScheduler() 进行图片采样,并将采样结果与 DDPMPipeline 原始输出对比。如下:
# DDPM 生成图片
pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
paddle.seed(33)
ddpm_output = pipe() # 原始 ddpm 输出
# 我们采用 DDPM 的训练结果,通过 DDIM Scheduler 来进行采样。
pipe.scheduler = DDIMScheduler()
# 设置与 DDPM 相同的采样结果,令 DDIM 采样过程中的 eta = 1.
paddle.seed(33)
ddim_output = pipe(num_inference_steps=1000, eta=1)
imgs = [ddpm_output.images[0], ddim_output.images[0]]
titles = ["ddpm", "ddim"]
compare_imgs(imgs, titles) # 该函数在 notebook_utils.py 声明
输出结果:
代码输出结果: DDPM 与 DDIM 采样下的图片对比 通过运行以上代码,我们可以看出 η = 1 \eta=1
计算机浮点数精度问题 Scheduler 采样过程中存在的 clip 操作导致偏差。 尝试去除 Clip 操作 Scheduler 采样过程中存在的 clip 操作导致偏差。Clip 操作对采样过程中生成的 x_0 预测结果进行了截断,尽管 DDPM, DDIM 均在预测完 x 0 x_0 x 0 x_0
将 clip 配置设置成 False 后, DDPM 与 DDIM(η = 1 \eta=1
pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
pipe.progress_bar = lambda x:x # uncomment to see progress bar
# 我们采用 DDPM 的训练结果,通过 DDIM Scheduler 来进行采样。
# print("Default setting for DDPM:\t",pipe.scheduler.config.clip_sample) # True
pipe.scheduler.config.clip_sample = False
paddle.seed(33)
ddpm_output = pipe()
pipe.scheduler = DDIMScheduler()
# print("Default setting for DDIM:\t",pipe.scheduler.config.clip_sample) # True
pipe.scheduler.config.clip_sample = False
paddle.seed(33)
ddim_output = pipe(num_inference_steps=1000, eta=1)
imgs = [ddpm_output.images[0], ddim_output.images[0]]
titles = ["DDPM no clip", "DDIM no clip"]
compare_imgs(imgs, titles)
可以验证得到 DDPM 与 DDIM 论文中提出的 η = 1 \eta=1
img DDIM 加速采样 论文附录 C 有对这一部分进行详细阐述。DDIM 优化时与 DDPM 一样,对噪声进行拟合,但 DDIM 提出了通过一个更短的 Forward Processes 过程,通过减少采样的步数,来加快采样速度:
从原先的采样序列 { 1 , . . . , T } \{1,...,T\} arange(1, 1000, 100))。抽取方式不固定。在生成时同样采用公式 ( 1 ) (1) t t α ˉ t \bar\alpha_t 1, 100, 200, ... 1000 中的第二个样本,则使用训练时候采用的 α ˉ 100 \bar\alpha_{100} alphas_cumprod α ˉ \bar\alpha alpha 参数 α t \alpha_t
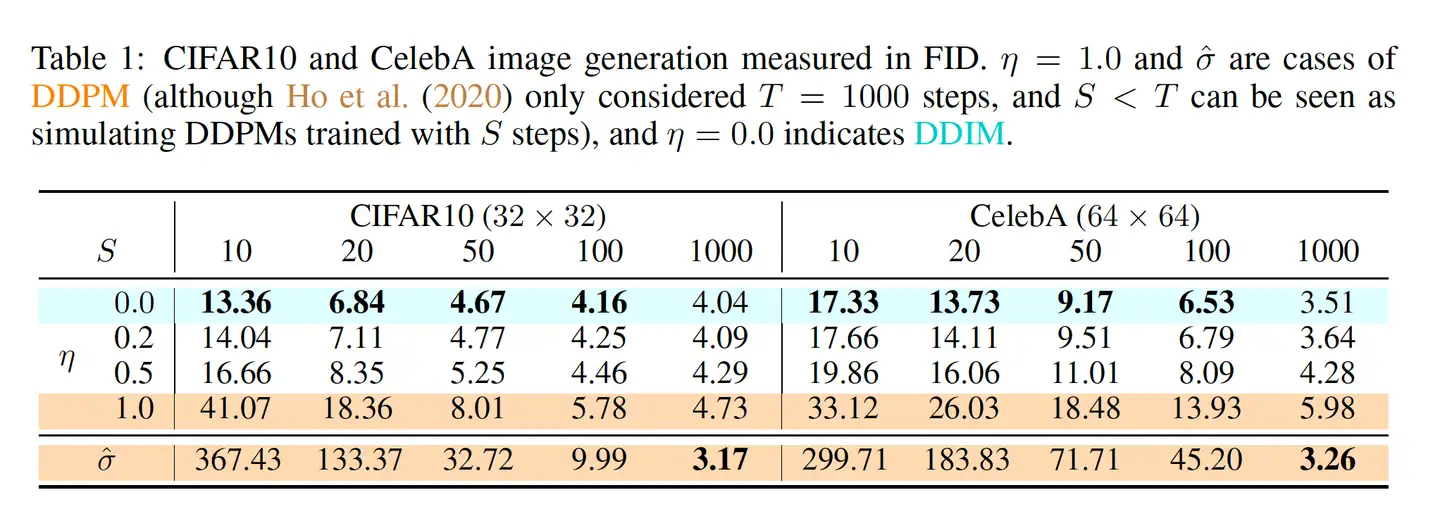
参考论文中的 Figure 3,在加速生成的情况下,η \eta η \eta
我们尝试对论文中提到的上述方法进行复现:
pipe.progress_bar = lambda x:x # cancel process bar
etas = [0, 0.4, 0.8]
steps = [10, 50, 100, 1000]
fig = plt.figure(figsize=(7, 7))
for i in range(len(etas)):
for j in range(len(steps)):
plt.subplot(len(etas), len(steps), j+i*len(steps) + 1)
paddle.seed(77)
sample1 = pipe(num_inference_steps=steps[j], eta=etas[i])
plt.imshow(sample1.images[0])
plt.axis("off")
plt.title(f"eta {etas[i]}|step {steps[j]}")
plt.show()
img 通过论文中的示例说明,以及上述实现结果可以发现几点:
η \eta 图片质量和风格差异 就越小。η \eta DDIM 采样的确定性 由于 DDIM 在生成过程中 η = 0 \eta=0 x t x_t
paddle.seed(77)
x_t = paddle.randn((1, 3, 256, 256))
paddle.seed(8)
sample1 = pipe(num_inference_steps=50,eta=0,x_t=x_t)
paddle.seed(9)
sample2 = pipe(num_inference_steps=50,eta=0,x_t=x_t)
compare_imgs([sample1.images[0], sample2.images[0]], ["sample(seed 8)", "sample(seed 9)"])
DDIM 采样的确定性 图像重建 在 DDIM 论文中,其作者提出了可以将一张原始图片 x 0 x_0 T T x T x_T ( 5 ) (5) ( 13 ) (13)
x t − Δ t α t − Δ t = x t α t + ( 1 − α t − Δ t α t − Δ t − 1 − α t α t ) ϵ θ ( t ) ( x t ) (10) \frac{\boldsymbol{x}_{t-\Delta t}}{\sqrt{\alpha_{t-\Delta t}}}=\frac{\boldsymbol{x}_t}{\sqrt{\alpha_t}}+\left(\sqrt{\frac{1-\alpha_{t-\Delta t}}{\alpha_{t-\Delta t}}}-\sqrt{\frac{1-\alpha_t}{\alpha_t}}\right) \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right) \tag {10}
大致推导过程 x t − 1 = α ˉ t − 1 ( x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) α ˉ t ) ⏟ " predicted x 0 " + 1 − α ˉ t − 1 − σ t 2 ⋅ ϵ θ ( t ) ( x t ) ⏟ "direction pointing to x t " + σ t ϵ t ⏟ random noise x t − 1 α ˉ t − 1 = x t α ˉ t − 1 − α ˉ t α ˉ t ϵ θ ( t ) + 1 − α ˉ t − 1 α ˉ t − 1 ϵ θ ( t ) ( x t ) 当 t 足够大时可以看做 x t − Δ t α ˉ t − Δ t = x t α ˉ t + ( 1 − α ˉ t − Δ t α ˉ t − Δ t − 1 − α ˉ t α ˉ t ) ϵ θ ( t ) ( x t ) \begin{aligned} \boldsymbol{x}_{t-1}&=\sqrt{\bar\alpha_{t-1}} \underbrace{\left(\frac{\boldsymbol{x}_t-\sqrt{1-\bar\alpha_t} \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)}{\sqrt{\bar\alpha_t}}\right)}_{\text {" predicted } \boldsymbol{x}_0 \text { " }}+\underbrace{\sqrt{1-\bar\alpha_{t-1}-\sigma_t^2} \cdot \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)}_{\text {"direction pointing to } \boldsymbol{x}_t \text { " }}+\underbrace{\sigma_t \epsilon_t}_{\text {random noise }} \\\frac{x_{t-1}}{\sqrt {\bar\alpha_{t-1}}}&= \frac {x_t}{\sqrt {\bar\alpha_t}} - \frac{\sqrt{1-\bar\alpha_t}}{\sqrt {\bar\alpha_t}}\epsilon_\theta^{(t)} + \frac{\sqrt {1-\bar\alpha_{t-1}}}{\sqrt {\bar\alpha_{t-1}}}\epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)\\ &\text {当 t 足够大时可以看做}\\\frac{\boldsymbol{x}_{t-\Delta t}}{\sqrt{\bar\alpha_{t-\Delta t}}} &=\frac {x_t}{\sqrt {\bar\alpha_t}} + \left(\sqrt{\frac{1-\bar\alpha_{t-\Delta t}}{\bar\alpha_{t-\Delta t}}}-\sqrt{\frac{1-\bar\alpha_t}{\bar\alpha_t}}\right) \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right) \end{aligned}
而后进行换元,令 σ = ( 1 − α ˉ / α ˉ ) , x ˉ = x / α ˉ \sigma=(\sqrt{1-\bar\alpha}/\sqrt{\bar\alpha}), \bar x = x/\sqrt{\bar\alpha}
d x ‾ ( t ) = ϵ θ ( t ) ( x ‾ ( t ) σ 2 + 1 ) d σ ( t ) (11) \mathrm{d} \overline{\boldsymbol{x}}(t)=\epsilon_\theta^{(t)}\left(\frac{\overline{\boldsymbol{x}}(t)}{\sqrt{\sigma^2+1}}\right) \mathrm{d} \sigma(t)\tag{11}
于是,基于这个 ODE 结果,能通过 x ˉ ( t ) + d x ˉ ( t ) \bar x({t}) + d\bar x(t) x ˉ ( t + 1 ) \bar x(t+1) x t + 1 x_{t+1}
根据 github - openai/improved-diffusionopen in new window ,其实现根据 ODE 反向采样的方式为:直接根据公式 ( 5 ) (5) t − 1 t-1 t + 1 t+1
x t + 1 = α ˉ t + 1 ( x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) α ˉ t ) ⏟ " predicted x 0 " + 1 − α ˉ t + 1 ⋅ ϵ θ ( t ) ( x t ) ⏟ "direction pointing to x t " + σ t ϵ t ⏟ random noise (12) \boldsymbol{x}_{t+1}=\sqrt{\bar\alpha_{t+1}} \underbrace{\left(\frac{\boldsymbol{x}_t-\sqrt{1-\bar\alpha_t} \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)}{\sqrt{\bar\alpha_t}}\right)}_{\text {" predicted } \boldsymbol{x}_0 \text { " }}+\underbrace{\sqrt{1-\bar\alpha_{t+1}} \cdot \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)}_{\text {"direction pointing to } \boldsymbol{x}_t \text { " }}+\underbrace{\sigma_t \epsilon_t}_{\text {random noise }}\tag{12}
而参考公式 ( 11 ) (11) ( 12 ) (12)
x t + Δ t α ˉ t + Δ t = x t α ˉ t + ( 1 − α ˉ t + Δ t α ˉ t + Δ t − 1 − α ˉ t α ˉ t ) ϵ θ ( t ) ( x t ) (13) \frac{\boldsymbol{x}_{t+\Delta t}}{\sqrt{\bar\alpha_{t+\Delta t}}} =\frac {x_t}{\sqrt {\bar\alpha_t}} + \left(\sqrt{\frac{1-\bar\alpha_{t+\Delta t}}{\bar\alpha_{t+\Delta t}}}-\sqrt{\frac{1-\bar\alpha_t}{\bar\alpha_t}}\right) \epsilon_\theta^{(t)}\left(\boldsymbol{x}_t\right)\tag {13}
以下我们尝试对自定义的输入图片进行反向采样(reverse sampling)和原图恢复,我们导入本地图片:
img 根据公式 12 编写反向采样过程。ppdiffusers 中不存在 reverse_sample 方案,因此我们根据本文中的公式 ( 12 ) (12) reverse_sample 过程,具体为:
def reverse_sample(self, model_output, x, t, prev_timestep):
"""
Sample x_{t+1} from the model and x_t using DDIM reverse ODE.
"""
alpha_bar_t_next = self.alphas_cumprod[t]
alpha_bar_t = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
inter = (
((1-alpha_bar_t_next)/alpha_bar_t_next)** (0.5)- \
((1-alpha_bar_t)/alpha_bar_t)** (0.5)
)
x_t_next = alpha_bar_t_next** (0.5) * (x/ (alpha_bar_t ** (0.5)) + \
(
model_output * inter
)
)
return x_t_next
而后进行不断的迭代采样与图片重建(具体的方式可以查看 扩散模型探索:DDIM 笔记与思考open in new window )。以下右图为根据原图进行反向 ODE 加噪后的结果,可以看出加噪后和电视没信号画面相当。以下左图为根据噪声图片采样得来的结果,基本上采样的结果还原了 90%以上原图的细节,不过还有如右上角部分的一些颜色没有被还原。
img 潜在的风格融合方式 通过两个能够生成不同图片的噪声 z 1 , z 2 z_1, z_2 x T x_T linkopen in new window 。首先我们选取两个不同的图片进行融合:
paddle.seed(77)
pipe.scheduler.config.clip_sample = False
z_0 = paddle.randn((1, 3, 256, 256))
sample1 = pipe(num_inference_steps=50,eta=0,x_t=z_0)
paddle.seed(2707)
z_1 = paddle.randn((1, 3, 256, 256))
sample2 = pipe(num_inference_steps=50,eta=0,x_t=z_1)
compare_imgs([sample1.images[0], sample2.images[0]], ["sample from z_0", "sample from z_1"])
输出结果:
img 以上选择 seed 为 77 和 2707 的噪声进行采样,他们的采样结果分别展示在上方。
以下参考 ermongroup/ddim/blob/main/runners/diffusion.pyopen in new window ,对噪声进行插值,方式大致为:
x t = sin ( ( 1 − α ) θ ) sin ( θ ) z 0 + s i n ( α θ ) sin ( θ ) z 1 , w h e r e θ = arccos ( ∑ z 1 z 0 ∣ ∣ z 1 ∣ ⋅ ∣ ∣ z 0 ∣ ∣ ) x_t = \frac {\sin\left((1-\alpha)\theta\right)}{\sin(\theta)}z_0 + \frac{sin(\alpha\theta)}{\sin(\theta)}z_1,\\where\ \theta=\arccos\left(\frac{\sum z_1z_0}{||z_1|·||z_0||}\right)
def slerp(z1, z2, alpha):
theta = torch.acos(torch.sum(z1 * z2) / (torch.norm(z1) * torch.norm(z2)))
return (
torch.sin((1 - alpha) * theta) / torch.sin(theta) * z1
+ torch.sin(alpha * theta) / torch.sin(theta) * z2
)
img 可以看出,当 α \alpha α = 0.4 , 0.5 , 0.6 \alpha=0.4,0.5,0.6
那根据前两节的阐述,我们可以实现一个小的 pipeline, 具备接受使用 DDIM 接受两张图片,而后输出一张两者风格融合之后的图片。
参考 Denoising Diffusion Implicit Modelsopen in new window
苏建林 - 生成扩散模型漫谈 系列笔记open in new window
小小将 - 扩散模型之 DDIMopen in new window
github - openai/improved-diffusionopen in new window
标签: Diffusion ,
bar ,
代码 ,
frac ,
sqrt ,
alpha ,
DDIM ,
xt
From: https://www.cnblogs.com/zhangxianrong/p/18326855