随着预训练视觉模型的兴起,目前流行的视觉微调方法是完全微调。由于微调只专注于拟合下游训练集,因此存在知识遗忘的问题。论文提出了基于权值回滚的微调方法
OLOR(One step Learning, One step Review),把权值回滚项合并到优化器的权值更新项中。这保证了上下游模型权值范围的一致性,有效减少知识遗忘并增强微调性能。此外,论文还提出了逐层惩罚,采用惩罚衰减和多样化衰减率来调整不同层的权值回滚级别,以适应不同的下游任务。通过对图像分类、对象检测、语义分割和实例分割等各种任务的广泛实验,证明了OLOR的普遍适用性和最先进的性能来源:晓飞的算法工程笔记 公众号
论文: One Step Learning, One Step Review

Introduction
随着深度学习技术的快速发展,大量的大规模图像数据集已经建立,产生了许多有前途的预训练视觉模型。这些预训练模型可以通过迁移学习和微调技术有效地解决相关但不同的视觉任务。基本的微调方法是线性探测和完全微调。
- 在线性探测中,预训练模型的主干被冻结,仅训练特定于下游任务的头部。然而,这种方法通常会限制预训练主干的性能。
- 另一方面,完全微调涉及直接训练整个网络,但这通常会导致知识遗忘。
为了进行有效的微调,许多研究提出了不同的方法:
- 基于重放机制的方法需要在学习新任务的同时对存储的上游样本子集进行再训练,效率相当低。
EWC提出了一种基于正则化的微调方法,使用Fisher信息矩阵来确定权值参数的重要性。这有助于调整上游和下游任务之间的参数,减少遗忘。L2-SP使用L2惩罚来限制参数的更新,解决微调过程中的知识遗忘问题。然而,它与自适应优化器不兼容,这可能会产生错误的正则化方向。- 参数隔离方法为下游任务的不同网络模型和任务创建新的分支或模块。但它引入了额外的新训练参数,需要一定的训练技巧,并且通用性低于排练方法。
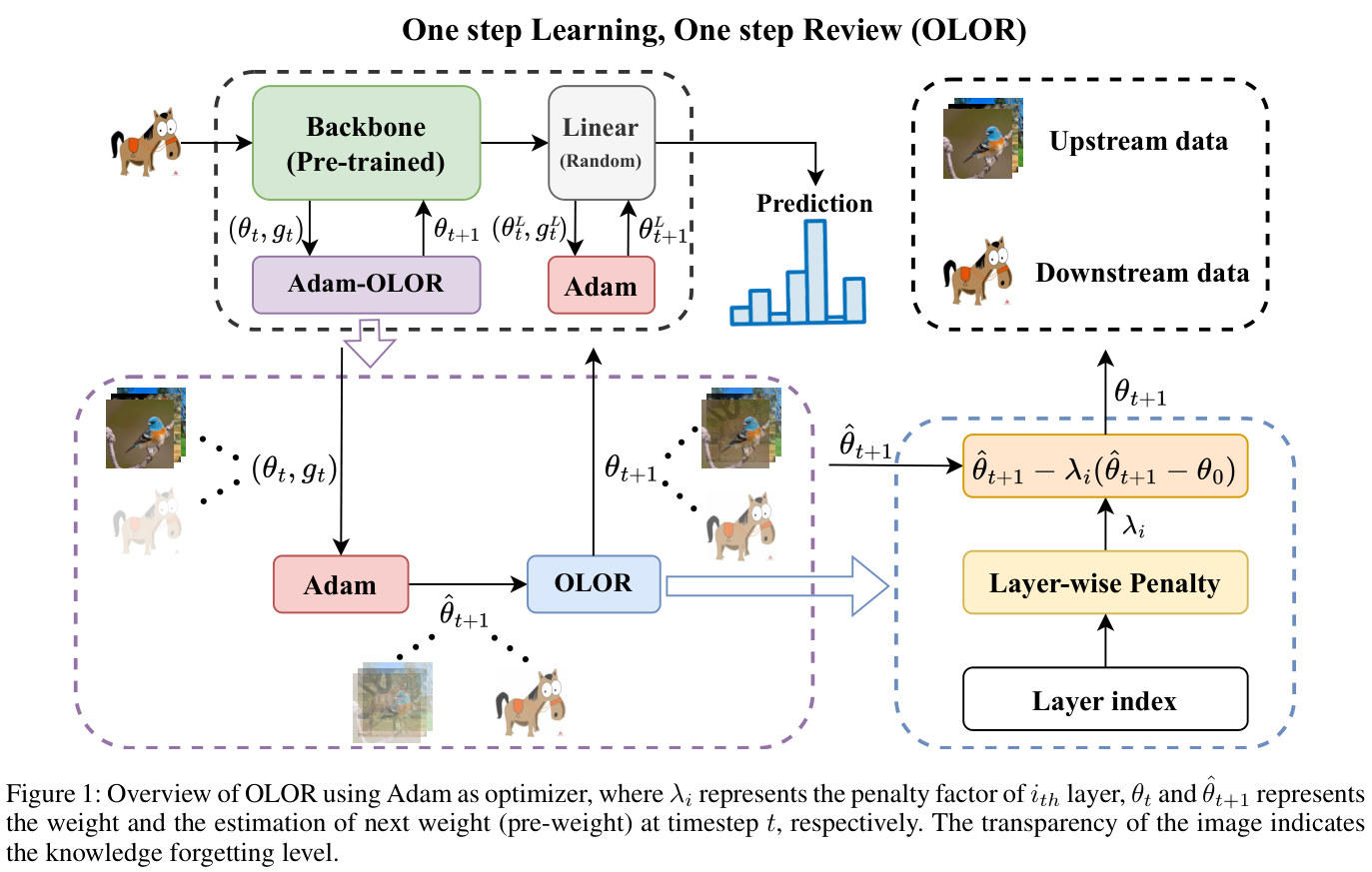
在本文中,论文提出了一种结合优化器来解决知识遗忘的新颖微调方法,称为OLOR(One step Learning, One step Review)。具体来说,OLOR在微调阶段将权值回滚项引入到权值更新项中,使模型在学习下游任务的同时逐渐逼近预训练的权值。这个过程避免了延迟缺陷,并使上下游模型的权值更加相似。此外,还设计了逐层惩罚,利用惩罚衰减和多样化衰减率来调整各层的权值回滚水平。惩罚衰减将特征金字塔与迁移学习相结合,对与颜色、纹理等浅层特征相关的浅层给予更显着的权值回滚力度,对与语义信息等深层特征相关的深层给予更小的权值回滚力度。具有逐层惩罚的OLOR使模型的每一层都可以根据其需要进行更新,从而更好地提取广义特征。最后,OLOR合并到优化器中,引入的额外计算开销可以忽略不计。与Adam和SGD等流行优化器配合良好,满足各种条件下的特定需求。
论文主要贡献总结如下:
- 提出了新颖的微调方法
OLOR,与优化器合作解决知识遗忘问题,从而提高微调性能。 - 设计的权值回滚通过将当前梯度纳入惩罚项,避免延迟缺陷,从而修正惩罚目标,平滑回滚过程。
- 提出逐层惩罚,采用惩罚衰减和多样化衰减率来调整层的权值回滚级别,以适应不同的下游任务。
- 所提出的方法在广泛的下游任务上实现了最先进的性能,包括不同类型的图像分类、不同的预训练模型以及图像检测和分割。
Method


Previous Regularization Mechanisms Have a Delay Defect
OLOR的实现受到L2正则化和权值衰减的启发,这是用于正则化模型参数的常用方法。然而,论文的研究结果表明它们的有效性与最初的预期并不相符。
在经典SGD优化器的场景下,L2正则化可以被视为等价于权值衰减,其定义如下:
其中 \({\theta}_{t}\) 表示迭代 \(t\) 时的模型权值,\({\theta}_{t-1}\) 是前一次迭代的相应权值, \(\lambda\) 是正则化因子(权重衰减强度) \({\eta}_{t}\) 是迭代时的学习率,\(g_{t}\) 是在迭代 \(t\) 时根据损失函数计算得出的当前批量的梯度。权值衰减通过将前一次迭代获得的权值推向 0 来对其进行惩罚。
然而,在实践中,\(\mathrm{lim}_{\lambda\to1}\theta_{t}=-\eta_{t}g_{t}\),权值往往会被推向当前梯度的负值而不是 0,行为与最初的期望不同。此外,与不应用权值衰减相比,应用权值衰减实际上会增加当前权值:
\[(\theta_{t-1}-\eta_{t}g_{t}-\lambda\theta_{t-1})^{2}>(\theta_{t-1}-\eta_{t}g_{t})^{2}, \quad\quad (2) \]简化为:
\[\begin{cases} {{\eta g_{t}>(1-\frac{\lambda}{2})\theta_{t-1},}}&{{\mathrm{if}\,\theta_{t-1}>0,}} \\ {{\eta g_{t}<(1-\frac{\lambda}{2})\theta_{t-1},}}&{{\mathrm{if}\,\theta_{t-1}<0,}} \end{cases} \] 如果 \(\eta\)、\(g_t\)、\(\lambda\) 和 \(\theta_{t-1}\) 处于上述条件下,使用权值衰减将使当前权重远离 0,这与目标相反。同样,衰减效应的问题也存在于其他正则化机制中,例如L1正则化、L2-SP等方法。
Weight Rollback
权值回滚是一种实时正则化方法,紧密跟踪每个权值的更新步骤,使当前模型权值更接近预先训练的权值以进行知识回顾(knowledge review)。
具体来说,第一步是通过梯度计算预权值 \(\theta_{\mathrm{pre}}\):
\[\theta_{\mathrm{pre}}=\theta_{t-1}-\eta_{t}g_{t}, \quad\quad (3) \]其中 \(\theta_{t-1}\) 表示前一步的模型权值,\({\eta}_{t}\) 是当前步的学习率,\(g_t\) 表示当前梯度。随后,\(\theta_{\mathrm{pre}}\) 和预训练权值 \(\theta_{0}\) 之间的差异 \(\Delta d\) 计算如下:
\[\Delta d=\theta_{p r e}-\theta_{0}. \quad\quad (4) \]最后,权值更新过程加入了 \(\Delta d\),从而得到调整后的模型权值 \({\theta}_{t}\) :
\[\theta_{t}=\theta_{t-1}-\eta_{t}g_{t}-\lambda\Delta d. \quad\quad (5) \]通过代入公式 3 和公式 4 到等式 5,可得到:
\[\theta_{t}=(1-\lambda)(\theta_{t-1}-\eta_{t}g_{t})+\lambda\theta_{0}. \quad\quad (6) \]公式 6 确保 \(\mathrm{lim}_{\lambda\rightarrow1}\theta_{t}=\theta_{0}\),符合论文的期望并防止异常情况。此外,由于梯度 \(g_t\) 也受到惩罚,可能也有助于减轻梯度爆炸。
综上所述,权值回滚技术可以缓和每一步 \({\theta}_{t}\) 和 \(\theta_{0}\) 之间的偏差,从而减轻对当前任务的过度拟合和对前一个任务的知识遗忘。
Layer-Wise Penalty
-
Penalty Decay
对于深度学习神经网络,每一层都可以被概念化为处理其输入的函数。给定层索引 \(i\),该过程可以描述如下:
\[{x}_{i+1}=f_{i}(x_{i}^{*}), \quad\quad (7) \]其中 \(f_{i}\) 代表 \({i}_{th}\) 层。令 \({x}_{i}^{u}\) 表示上游任务中 \(f_{i}\) 的输入,分布为 \(q_{i}\bigl(x_{i}^{u}\bigr)\),\({x}_{i}^{d}\) 表示下游任务中 \(f_{i}\) 的输入,分布为 \(p_{i}\left(x_{i}^{\tilde{d}}\right)\)。因为 \(q_{i}\bigl(x_{i}^{u}\bigr)\) 总是与 \(p_{i}\left(x_{i}^{\tilde{d}}\right)\) 不同,所以先解冻所有层以确保 \(f_i\) 将有充足的更新来更好地处理此差距。
在图像特征提取的研究中,普遍的理解是浅层主要负责捕获颜色、纹理和形状等表面特征。相比之下,更深的层专注于提取更深刻的特征,例如语义信息。这意味着浅层与数据的分布密切相关,而深层则与特定任务的目标更加一致。
迁移学习的一个基本假设是 \(q_{i}\bigl(x_{i}^{u}\bigr)\) 与 \(p_{i}\left(x_{i}^{\tilde{d}}\right)\) 具有一定程度的相似性。因此,浅层往往在预训练和微调阶段表现出相似性。此外,与较深的层相比,浅层需要的更新较少。
基于这些观察,论文提出了一种用于权值回滚的分层惩罚衰减机制。随着层深度的增加,逐渐降低回滚级别,鼓励浅层在下游任务中提取更通用的特征,同时保留整体模型容量。对于 \(i\) 层,惩罚因子 \(\lambda_{i}\) 的计算如下:
\[\lambda_{i}=\iota_{2}+(1-\frac{i}{n})(\iota_{1}-\iota_{2}), \quad\quad (8) \]其中 \(n\) 表示预训练模型中的总层数,\({\iota_{1}\) 和 \({\iota_{2}\)分别表示最大和最小回滚级别。
-
Diversified Decay Rate
在各种下游任务中,训练目标通常与上游任务表现出不同程度的差异。为了适应这种可变性,论文通过向权值回滚值引入幂指数 \(\gamma\) 来调整层之间的惩罚衰减率,具体为:
\[1\,-\,{\frac{i}{n}}\,\longrightarrow\,\left(1\,-\,{\frac{i}{n}}\right)^{\gamma}. \quad\quad(9) \]这种动态调整有助于减轻不同层的 \(q_{i}\bigl(x_{i}^{u}\bigr)\) 与 \(p_{i}\left(x_{i}^{\tilde{d}}\right)\) 之间的相似性由于固定衰减速率而产生的偏差。因此,惩罚衰减变得更具适应性和通用性,满足各种下游规定的一系列任务的要求。
Experiments
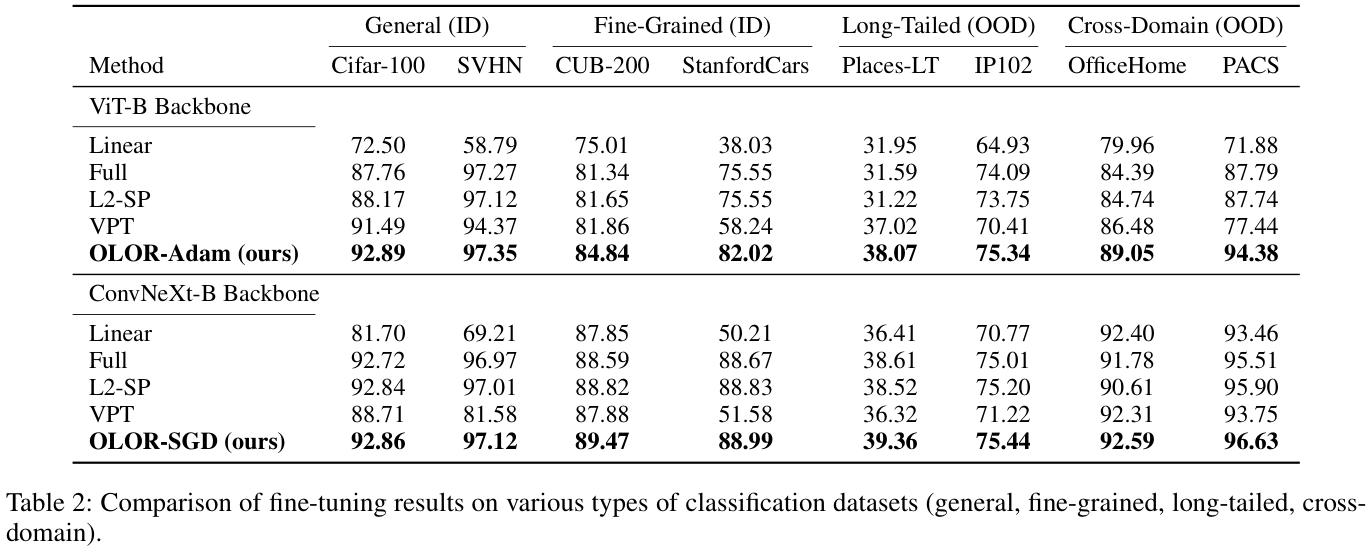
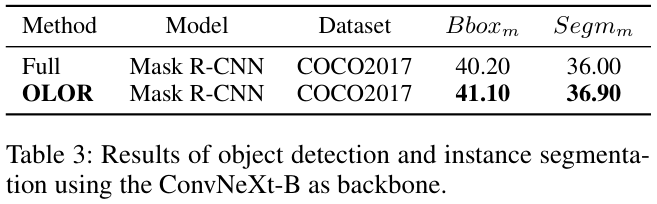
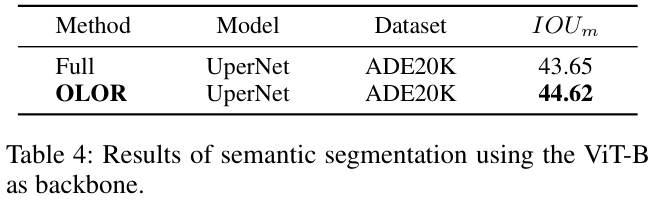
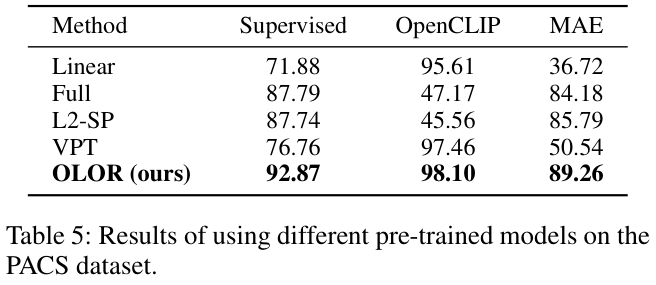
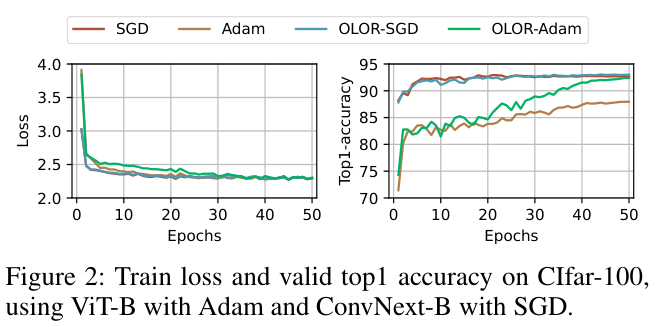
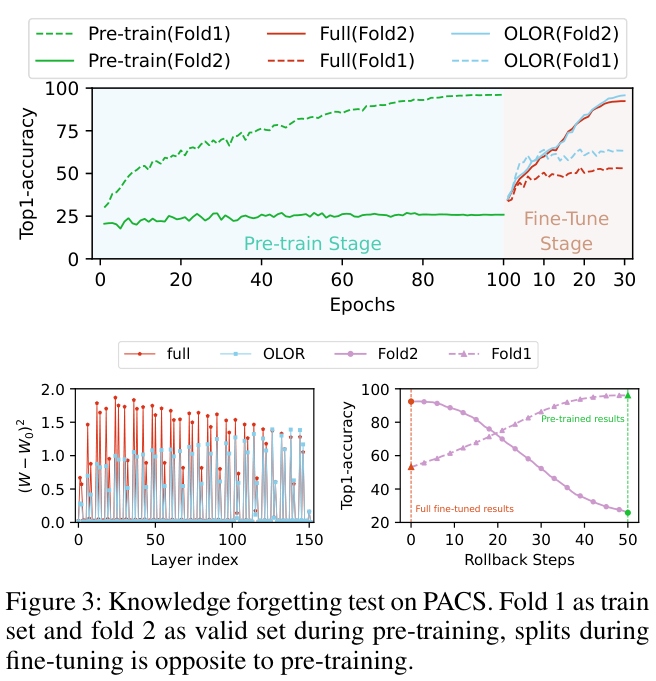
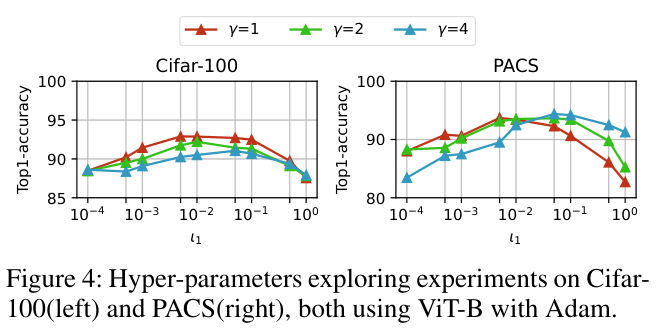
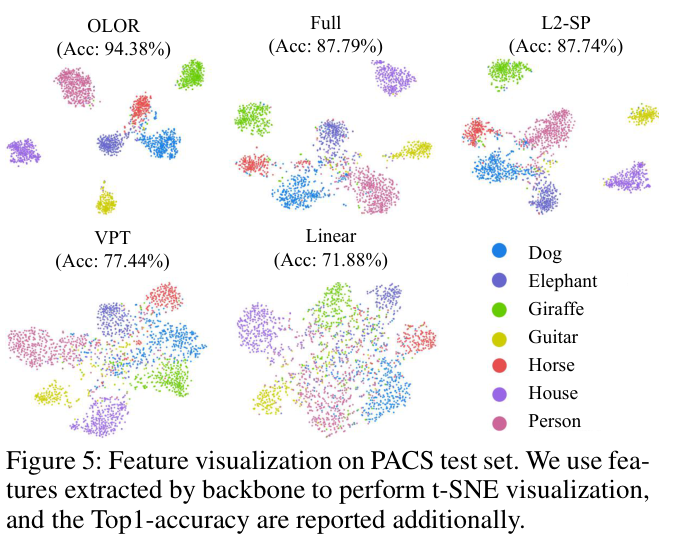
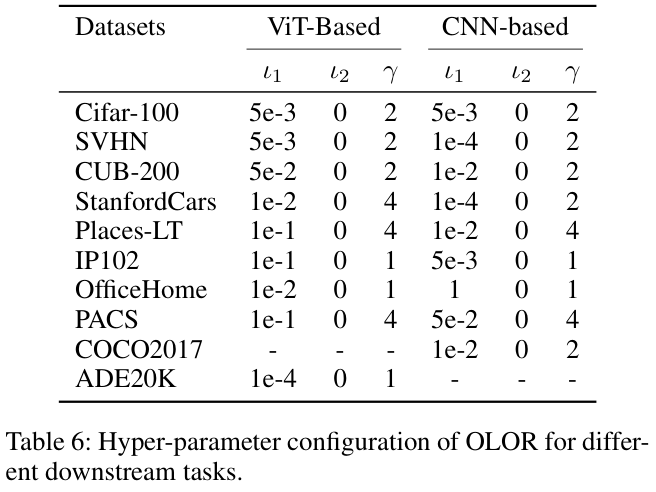

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
