一、背景
部门中一核心应用,因为各种原因其依赖的MySQL数据库一直处于高水位运行,无论是硬件资源,还是磁盘使用率或者QPS等都处于较高水位,急需在大促前完成对应的治理,降低各项指标,以保障在大促期间平稳运行,以期更好的支撑前端业务。
二、基本情况
2.1、数据库
目前该数据库是一主两从,且都是零售的物理机,运行多年已都是过保机器。同时因为CPU和磁盘较大,已无同规格的物理机可以增加一个从库。同时其中一个从库的内存减半且磁盘还是机械盘,出故障风险极高且IO性能低导致查询偏慢,出现过多次因性能问题切到另一个从库的情况。
以下是其3台机器的硬件资源信息,MySQL版本、部署机房和硬件配置情况。其中135机器硬盘容量128T是统计显示有误,可以认为也是16T。因为磁盘做了RAID0,因此实际容量在7T左右。
| 域名 | 主/从 | CPU | 内存 | 容量 | 机房 | DISK(/export)使用率(%) | Memory使用率(%) | 数据库版本 | |
| 1x.x.x.36 | xxx_m.mysql.jddb.com | 主 | 64 | 256G | 16T | 汇天云端机房 | 66.3% | 87.7% | 5.5.14 |
| 1x.x.x.73 | xxx_sb.mysql.jddb.com | 从 | 64 | 256G | 16T | 汇天云端机房 | 66.6% | 85.2% | 5.5.14 |
| 1x.x.x.135 | xxx_sa.mysql.jddb.com | 从 | 64 | 128G | 128T | 廊坊机房 | 76.5% | 57.2% | 5.5.14 |
2.2、磁盘空间
截止到2月底,各数据库磁盘空间占用情况如下:
| IP | 主从 | 使用大小(G) | 已用比例(%) | 剩余空间(G) | 周增长量(G) | 预计报警(d) | 预计可用(d) | binlog(G) | 日志(G) |
| 1x.x.x.36 | M | 5017 | 69 | 2151 | 9 | 617.1 | 1735.8 | 159.45543 | 6 |
| 1x.x.x.73 | S | 5017 | 71 | 2151 | 14.8 | 333.2 | 1012.7 | 158.52228 | 1 |
| 1x.x.x.135 | S | 5017 | 4 | 129000 | 14.4 | 2986 | 8958 | 158.13548 | 0 |
从上表咱们可以看出,各数据库的磁盘空间占用已处于较高水位,急需需要治理,通过结转或删除数据来降低磁盘占用比例。
2.3、表空间
数据库存在大表其中一个原因是多条业务线共用一个应用,同时代码层面抽象的部分不够抽象,扩展部分又不容易扩展,导致数据都糅合和一起。
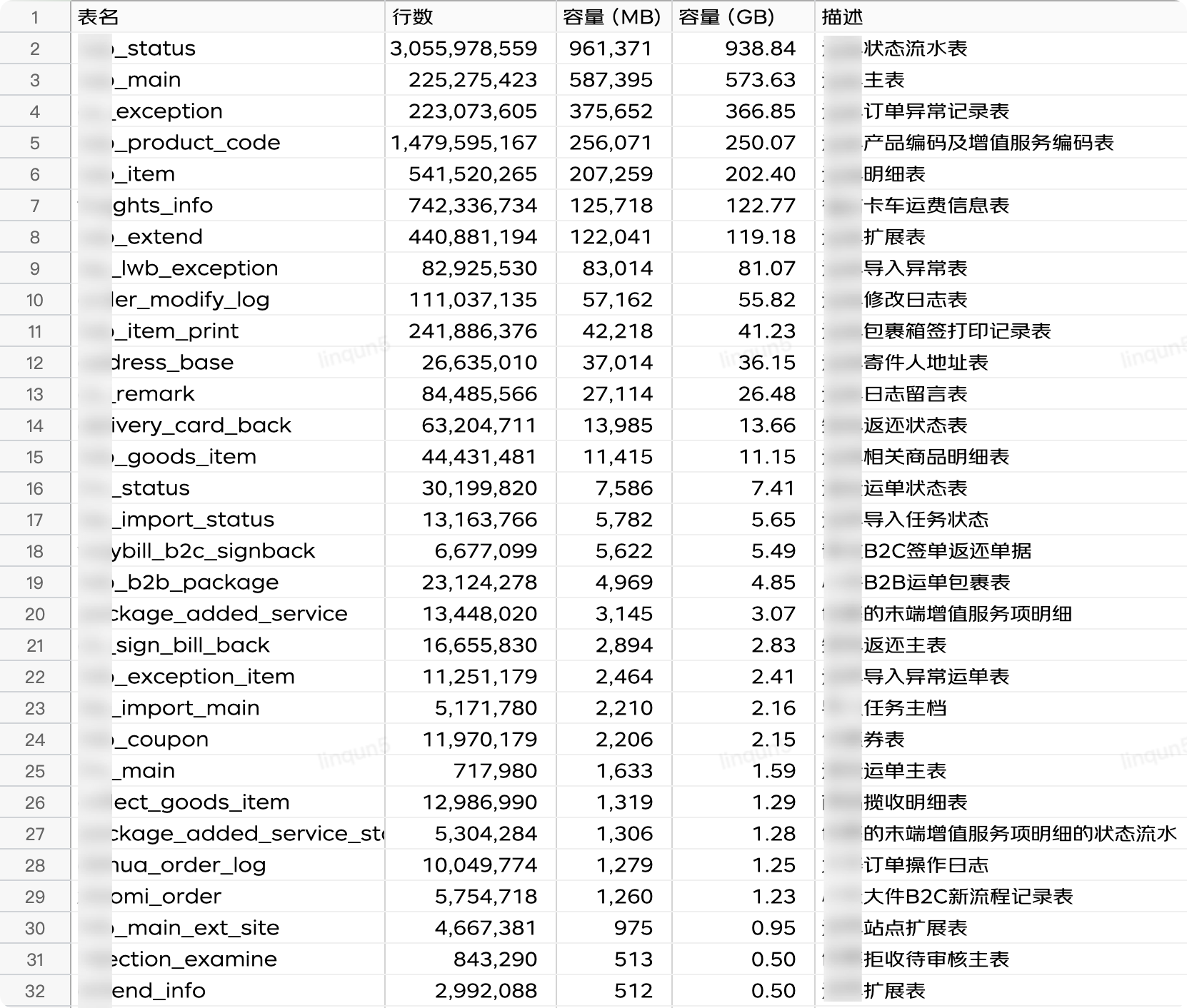
以下是所有的表空间占用情况,可以明显看到大部分的表数据量都在千万行以上,特别是前7张表的表空间占用都在100个G以上,数据行数也都在亿级以上,最多的是status表,30亿行数据,典型的大库大表。
2.4、QPS情况
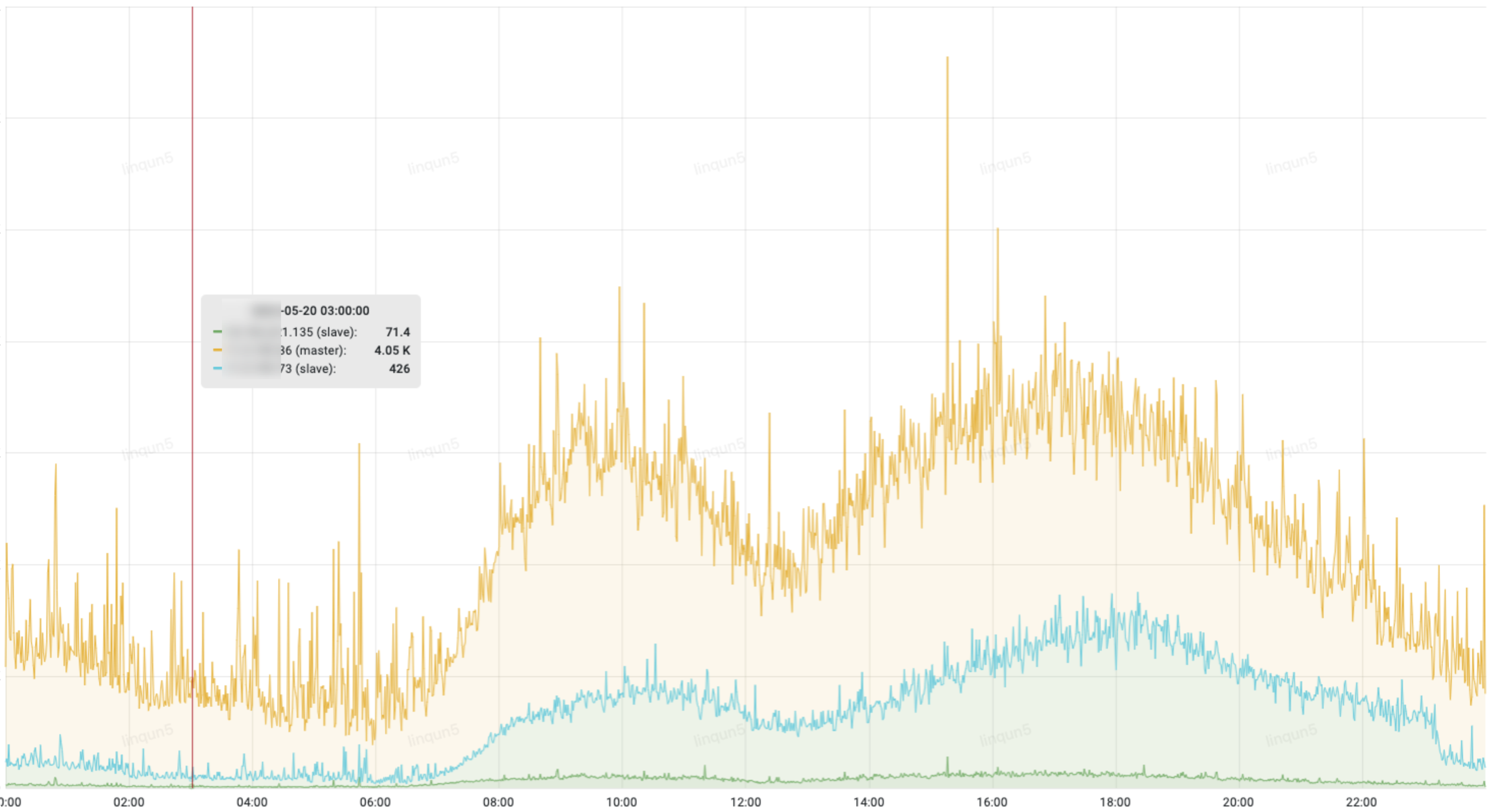
黄色的为主库的QPS,可以看出主库的查询量远大于从库,由于各种原因,应用代码里只有少部分的查询是走的从库,急需将部分流量大的查询接口从主库切到从库去查询;
2.5、慢SQL
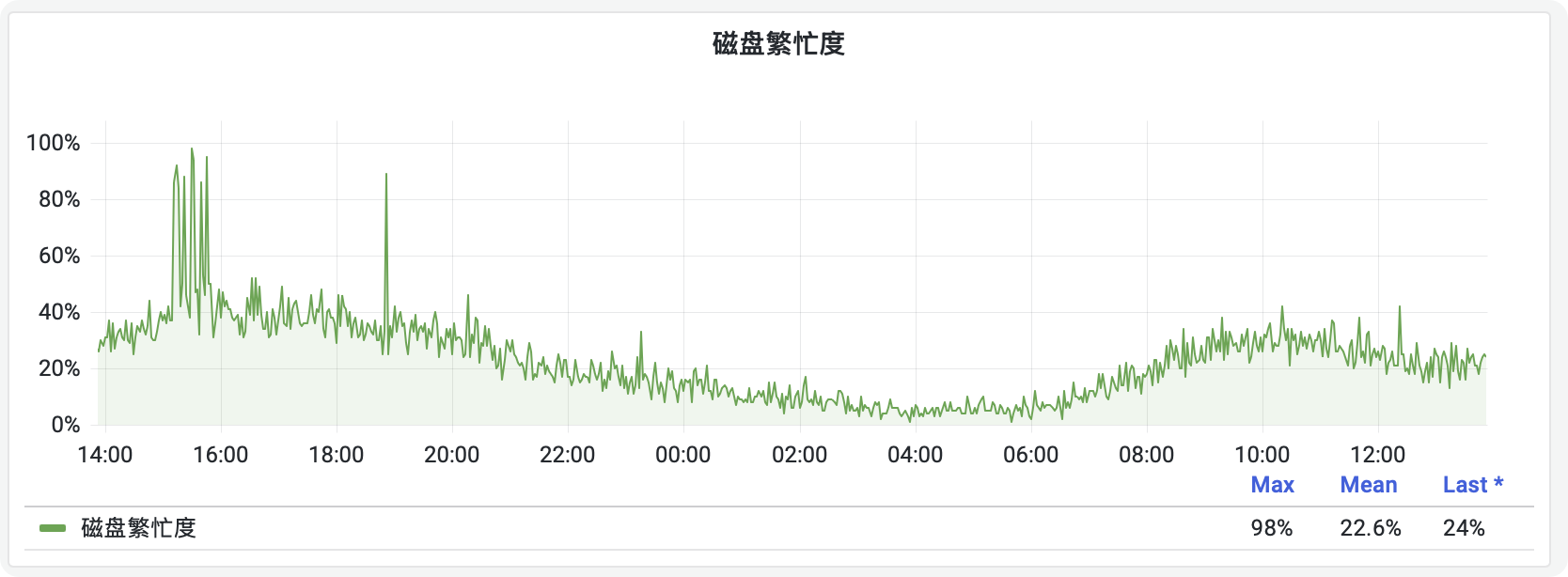
不论是主库还是从库,都有偶发的慢SQL查询,引发磁盘繁忙,影响系统稳定性。
三、治理目标
1.数据结转,降低磁盘使用率,处较低水位运行。治理目标:将表空间占用大于100G的7张表(xxx_status、xxx_main、xxx_exception、xxx_product_code、xxx_item、freights_info、xxx_extend)先进行集中结转,保留一年数据后进行常态化结转,按天结转,将数据量保持在365天;
1.降低主库QPS,保障主库安全。治理目标:将主库的高频查询切换到从库查询,使主库白天QPS降低30%,近一个月上午峰值平均在20k,下午峰值平均在25k;治理的目标为:上午峰值15k,下午峰值18k;
1.慢SQL治理,避免导致磁盘繁忙而影响整体业务。治理目标:10s以上的彻底消除;5s以上的,消除80%;1s以上的消除60%;底数是过去一个月(1s以上慢sql);
四、治理方案
4.1、大表数据结转
根据这7张表的业务属性不同,结转的类型也不相同;比如对于历史数据无意义的,可以将历史数据直接删除,比如xxx_exception;另外一类是纯历史数据,比如流水数据xxx_status表,结转方式是同步大数据平台后就可以删除;最后是业务主数据,是需要同步大数据平台和需要结转至历史库的,比如main、item和extend表等;
| 表名 | 表空间GB | 索引空间GB | 大数据 | 结转类型 | 开始值 | 完成值 |
| xxx_status | 991.65 | 265.29 | 是 | 删除 | 2020-04-30 01:00:00 | 2022-01-01 |
| xxx_main | 611.80 | 149.91 | 是 | 结转 | 2021-09-30 | 2022-01-01 |
| xxx_exception | 382.80 | 24.65 | 否 | 删除 | 2018-05-16 20:30:04 | 2022-01-01 |
| xxx_product_code | 244.18 | 61.54 | 是 | 删除 | 23亿 | |
| xxx_item | 208.66 | 85.46 | 是 | 结转 | 2016-12-29 13:20:33 | 2022-01-01 |
| xxx_freights_info | 128.78 | 109.03 | 是 | 结转 | 2018-11-29 13:26:00 | |
| xxx_extend | 127.36 | 26.07 | 是 | 结转 | 2019-03-29 14:30:00 | 2022-01-01 |
以下的统计表格是在同步大数据平台后集中删除和结转的空间释放情况,在1个月内对数据量在1亿以上并且占用空间在100G以上的7张大表进行了删除和结转后删除,使数据在保留365天的业务承诺时间范围内,降低了470G(10%)的磁盘空间占用;
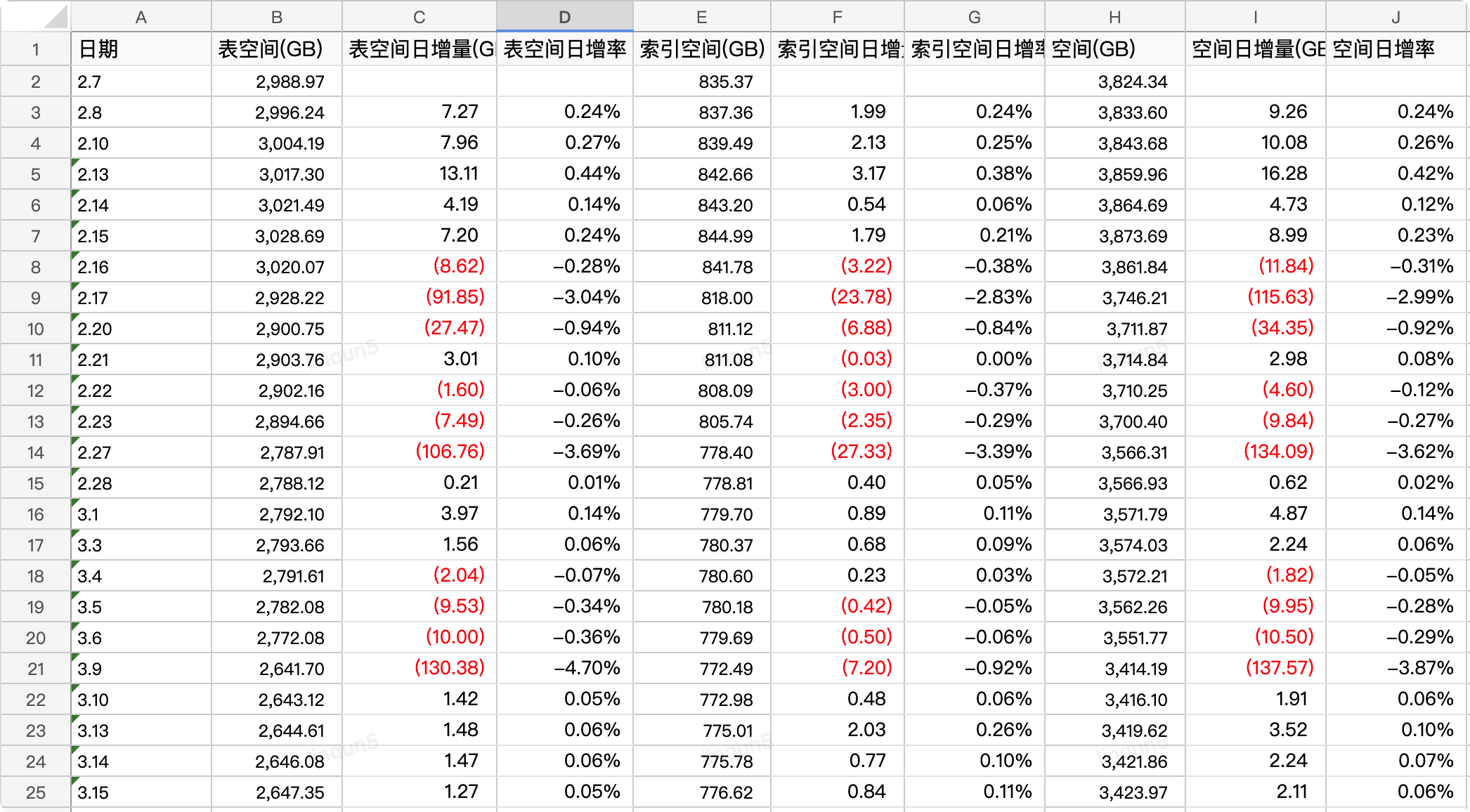
PS:红色数字部分为负值,也就是磁盘的释放空间。
4.2、拦截无参数查询
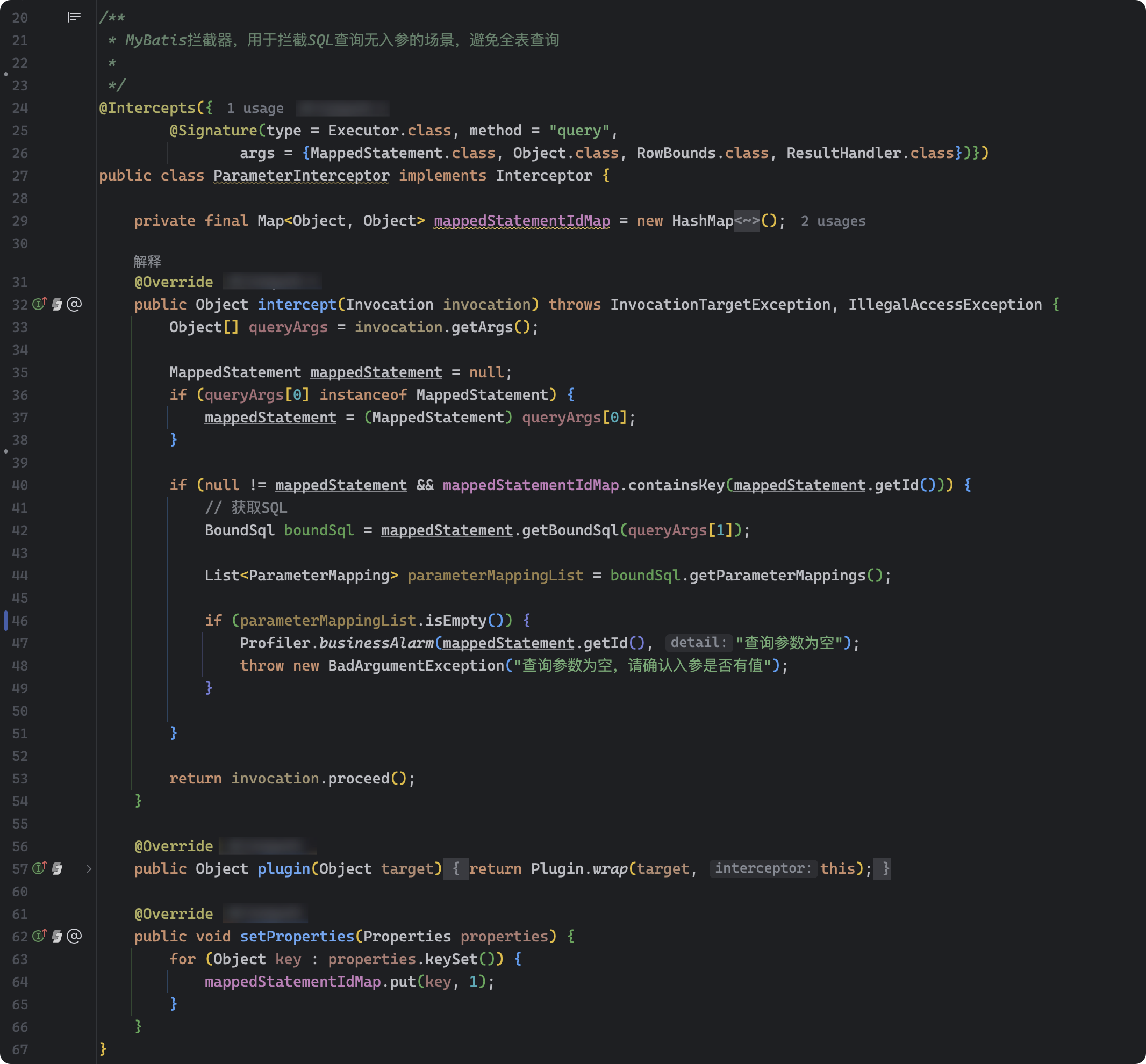
运单主档查询偶发会有无任何参数的查询,引发严重慢SQL,造成数据库磁盘繁忙度严重飚高,极大地影响了其他业务操作,而由于入口众多和交叉调用,如果在入口做参数校验工作量及风险都比较大,所以采用MyBatis的插件机制在dao层做拦截,直接拒绝掉无参数的查询,上线后就再没有出现过因无参查询而出现慢SQL而导致的磁盘繁忙情况;
mybatis-config.xml里的plugin配置:

ParameterInterceptor关键代码如下:
源代码如下:
import org.apache.ibatis.executor.Executor;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.mapping.ParameterMapping;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import java.lang.reflect.InvocationTargetException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* MyBatis拦截器,用于拦截SQL查询无入参的场景,避免全表查询
*
*/
@Intercepts({
@Signature(type = Executor.class, method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})})
public class ParameterInterceptor implements Interceptor {
private final Map<Object, Object> mappedStatementIdMap = new HashMap<Object, Object>();
@Override
public Object intercept(Invocation invocation) throws InvocationTargetException, IllegalAccessException {
Object[] queryArgs = invocation.getArgs();
MappedStatement mappedStatement = null;
if (queryArgs[0] instanceof MappedStatement) {
mappedStatement = (MappedStatement) queryArgs[0];
}
if (null != mappedStatement && mappedStatementIdMap.containsKey(mappedStatement.getId())){// 获取SQLBoundSql boundSql = mappedStatement.getBoundSql(queryArgs[1]);List<ParameterMapping> parameterMappingList = boundSql.getParameterMappings();if(parameterMappingList.isEmpty()){Profiler.businessAlarm(mappedStatement.getId(),"查询参数为空");thrownewBadArgumentException("查询参数为空,请确认入参是否有值");}}return invocation.proceed();}@OverridepublicObjectplugin(Object target){returnPlugin.wrap(target,this);}@OverridepublicvoidsetProperties(Properties properties){for(Object key : properties.keySet()){
mappedStatementIdMap.put(key,1);}}}4.3、查询切从库
主库QPS高峰期达30k/s,长期处于高位运行,需要梳理出TOP10的查接口来切从库查询,而应用中接口众多,无法逐个接口查各接口的调用量,可以利用JSF的filter功能结合UMP业务监控来统计provider的调用次数,再通过Python程序获取统计数据生产统计报表。
JSF的配置文件新增filter
<jsf:filter id="callFilter" ref="jsfInvokeFilter"/>JsfInvokeFilter的代码:
import com.jd.jsf.gd.filter.AbstractFilter;
import com.jd.jsf.gd.msg.RequestMessage;
import com.jd.jsf.gd.msg.ResponseMessage;
import com.jd.jsf.gd.util.RpcContext;
import com.jd.ump.profiler.proxy.Profiler;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
/**
* JSF filter
* JSF服务的调用次数统计
*/
@Component
public class JsfInvokeFilter extends AbstractFilter {
/**
* 按API接口统计方法调用量 - 业务监控KEY
*/
private static final String API_PROVIDER_METHOD_COUNT_KEY = "api.jsf.provider.method.count.key";
private static final String API_CONSUMER_METHOD_COUNT_KEY = "api.jsf.consumer.method.count.key";
@Override
public ResponseMessage invoke(RequestMessage requestMessage) {
String key;
if (RpcContext.getContext().isProviderSide()) {
key = API_PROVIDER_METHOD_COUNT_KEY;
} else {
key = API_CONSUMER_METHOD_COUNT_KEY;
}
String method = requestMessage.getClassName() + "." + requestMessage.getMethodName();
Map<String, String> tags = new HashMap<String, String>(2);
tags.put("bMark", method);
tags.put("bCount", "1");
Profiler.sourceDataByStr(key, tags);
return getNext().invoke(requestMessage);
}
}业务监控点列表
明细项

Python脚本
import os
import openpyxl
import json
import requests
from cookies import Cookie
import time
headers = {
'Cookie': Cookie,
'Content-Type': 'application/json',
'token': '******',
'erp': '******'
}
def get_jsf(start_time, end_time):
url = 'http://xxx.taishan.jd.com/api/xxx/xxx/xxx/'
body = {}
params = {'startTime': start_time,
'endTime': end_time,
'endPointKey': 'api.jsf.provider.method.count.key',
'quickTime': int((end_time - start_time) / 1000),
'markFlag': 'true',
'markLimit': 500}
res = requests.post(url=url, data=json.dumps(body), params=params, headers=headers)
print('url: ', res.request.url) # 查看发送的url
# print('response: ', res.text) # 返回请求结果
res_json = json.loads(res.text)
title = ['序号', 'jsf key', '次数', '占比%', '峰值', '次/秒', '峰值时间']
i = 0
keys = {}
marks = res_json['response_data']['marks']
for mark in marks:
keys.setdefault(mark, [0, 0, 0, ''])
data =[]
records = res_json['response_data']['monitorData']print(len(records))for key, value in records.items():
count =0
max_val =0
max_time =''for val in value:
v = val['value']
count += v
if v > max_val:
max_val = v
max_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(val['dateTime']/1000)))
keys[key]=[count, max_val,int(max_val /1200), max_time]
key_list =sorted(keys.items(), key=lambda x: x[1], reverse=True)# print(key_list)
all_count = key_list[0][1][0]for key in key_list:
values =[i, key[0], key[1][0],str(round(key[1][0]/ all_count *100,2))+'%', key[1][1], key[1][2], key[1][3]]
data.append(values)
i +=1## # print(data)#
path =r"/Users/xxx/Documents/治理/QPS治理/"
os.chdir(path)# 修改工作路径
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title ='JSF接口调用次数统计'
sheet.append(title)for record in data:
sheet.append(record)
workbook.save('JSF接口调用次数统计-'+str(start_time /1000)+'-'+str(end_time /1000)+'.xlsx')defchange_time(dt):# 转换成时间数组
time_array = time.strptime(dt,"%Y-%m-%d %H:%M:%S")# 转换成时间戳
timestamp = time.mktime(time_array)returnint(timestamp *1000)if __name__ =='__main__':
start_time ='2024-03-06 12:20:00'
end_time ='2024-03-07 12:20:00'
get_jsf(change_time(start_time), change_time(end_time))Cookie的代码如下:
Cookie = '*****'

分析Top10接口的切从库方案:
| 序号 | 接口 | 日调用量 | 占比% | 次/秒 | 涉及到的表 | 是否可以切从库 | 切从库方案 |
| 0 | 总调用量 | 69787485 | 100.0% | 1114 | |||
| 1 | com.jd.xxx.service.xxx.getLwbMainAndRelatedInfoByLwbNo | 35366937 | 50.68% | 747 | lxxx_main xxx_goods_item extend_info xxx_extend | 是 | 单查询,在Service层加注解走从库查询 |
| 2 | com.jd.xxx.service.xxx.getLwbMainByLwbNo | 12212805 | 17.5% | 235 | xxx_main xxx_main_ext_coldchain xxx_product_code xxx_extend | 是 | 有很多地方引用这个方法,切从库需要新增API接口,在Service新增的方法上加走从库注解 |
| 3 | com.jd.xxx.open.xxx.getLwbMainPartByLwbNo | 4138702 | 5.93% | 102 | xxx_main | 是 | 在Service层加注解走从库查询 |
| 4 | com.jd.xxx.open.xxx.gotoB2BSWbMainAllTrack | 3929935 | 5.63% | 70 | xxx_main 两次 xxx_main_ext_coldchain | 是 | 在Service层加注解走从库查询 |
| 5 | com.jd.xxx.btp.taskfunnel.handler.Handler.doFilter | 2206697 | 3.16% | 37 | 否 | 接单框架(实现方法太多) | |
| 6 | com.jd.xxx.service.xxx.findLwbMainByCondition | 1435493 | 2.06% | 32 | xxx_main 列表查询 xxx_item 是否查明细 package_added_service package_added_service_item 取旧服务 xxx_pay_main xxx_extend xxx_product_code xxx_main_ext_coldchain | 是 | 有很多地方引用这个方法,切从库需要新增API接口,在Service新增的方法上加走从库注解 |
| 7 | com.jd.xxx.open.OmsOrientedService.queryWayBillByLwbNo | 1059754 | 1.52% | 33 | xxx_main freights_info xxx_enquiry_main xxx_status 两次 xxx_b2b_box_item xxx_coupon 两次 xxx_extend 积分 | 是 | 在Service层加注解走从库查询 |
| 8 | com.jd.xxx.open.SellerOrientedService.getFreightsInfoFromTable | 1008603 | 1.45% | 66 | xxx_main xxx_b2b_package xxx_extend xxx_product_code xxx_main_ext_coldchain xxx_main_ext_site freights_info fee_detail xxx_b2b_box_item | 是 | 在Service层加注解走从库查询 |
| 9 | com.jd.xxx.service.xxx.getLwbMain | 817341 | 1.17% | 24 | xxx_main xxx_b2b_package xxx_extend xxx_product_code xxx_main_ext_coldchain xxx_main_ext_site | 是 | 有很多地方引用这个方法,切从库需要新增API接口,在Service新增的方法上加走从库注解 |
| 10 | com.jd.xxx.open.OmsOrientedService.getWayBillSettleMode | 730328 | 1.05% | 18 | 无数据库查询 |
通过优化读操作切换至从库查询,降低了主库30%的QPS流量,白天峰值从25k降低到17.5k;
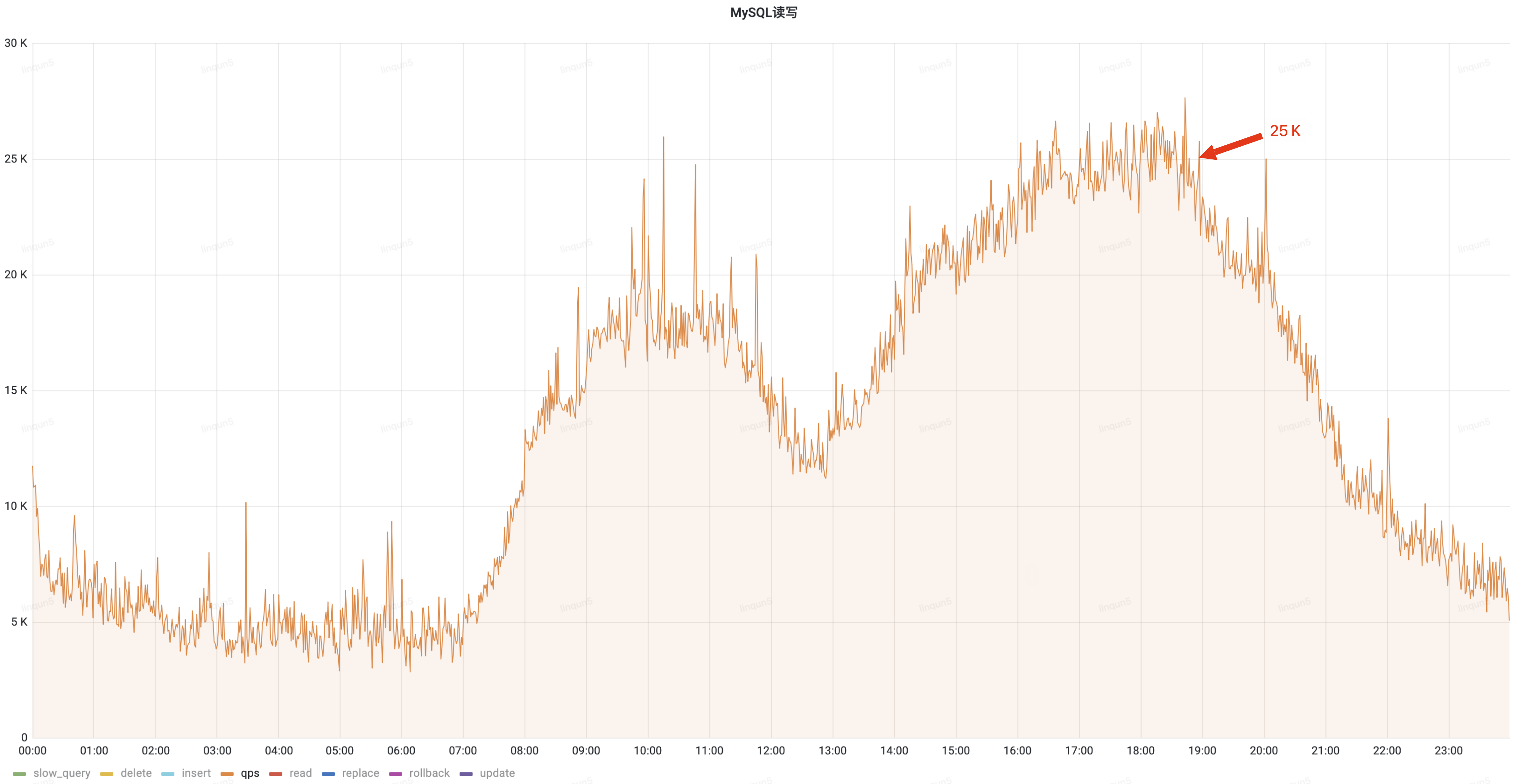
治理前QPS(峰值25k)
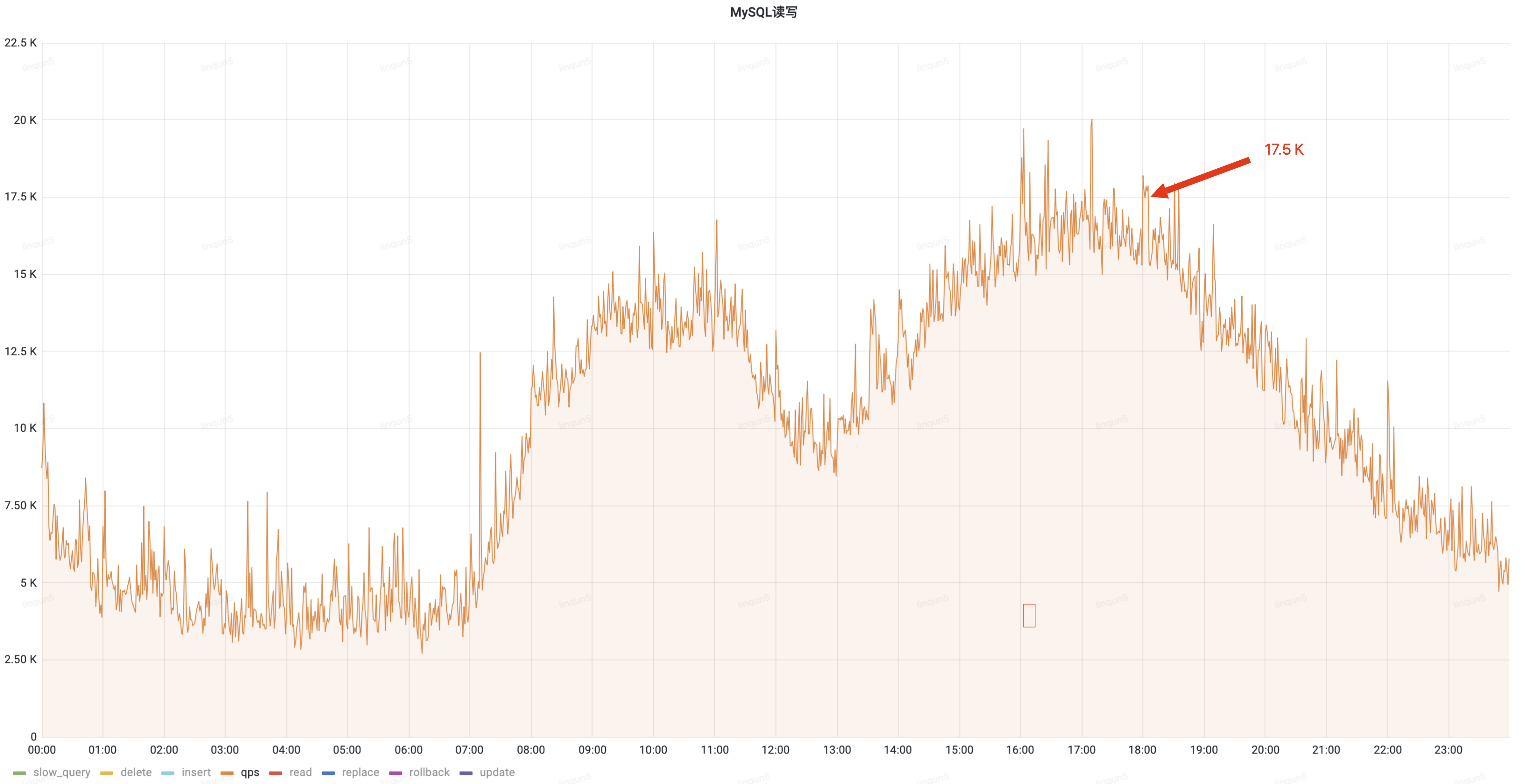
治理后QPS(峰值17.5k)
4.4、慢SQL治理
通过对慢SQL设定有针对性的治理,成功地彻底消除10s以上的慢SQL;5s以上的,消除80%;1s以上的消除60%。
关于慢SQL的治理不过多介绍,采用的都是通用分析和治理方法,有很多的文章都有介绍。需要注意的是在治理过程中要做好灰度,完全验证后再全量上线运行。
五、写在最后
可能有同学会想到分库分表,一个是在规划中提前部署分库分表,一个是现在使用分库分表技术进行治理;关于前一个问题由于时间久远咱们不做过多讨论,关于未使用分库分表进行治理的原因是业务规划的问题,目前此应用业务较为稳定,如采用分库分表治理动作比较大风险较高,ROI不高,故以上治理方案以稳定为主降低风险为辅。
还有一个治理方案是迁云,利用云计算的弹性及快速恢复等特性降低来运行风险,因为业务的不可中断性,此方案必须是在线迁移,涉及双数据库从双写到双读,再到单读,最后单写,还有数据一致性检查和同步等,成本较高。同时云数据库未能有如此大的磁盘容量和CPU核数,所以此方案需要结合分库分表方案同时进行,更增加了成本和风险,但此方案目前是在计划中的,如业务有较大幅度增长,以上治理也已无法满足时,将采用迁云加分库分表,且分库和分表是分期进行推进。
六、探讨
大家在日常及大促中有其他好的治理方案的话,欢迎发在评论区一起探讨。
标签:从库,大库,xxx,治理,key,time,import,main,大表 From: https://www.cnblogs.com/Jcloud/p/18316259