文章目录
与传统神经网络的优化类似,通常使用批次梯度下降算法来进行模型参数的调优。同时,通过调整学习率以及优化器中的梯度修正策略,可以进一步提升训练的稳定性。为了防止模型对数据产生过度拟合,训练中还需要引入一系列正则化方法。
基于批次数据的训练
在大模型预训练中,通常将批次大小(Batch Size)设置为较大的数值,例如1M 到 4M 个词元,从而提高训练的稳定性和吞吐量。为了更好地训练大语言模型,现在很多工作都采用了动态批次调整策略,即在训练过程中逐渐增加批次大小,最终达到百万级别。例如,GPT-3 的批次大小从 32K 个词元逐渐增加到 3.2M个词元;PaLM-540B 的批次大小从 1M 个词元逐渐增加到 4M 个词元。相关研究表明,动态调整批次大小的策略可以有效地稳定大语言模型的训练过程 [33]。这是因为较小的批次对应反向传播的频率更高,训练早期可以使用少量的数据让模型的损失尽快下降;而较大的批次可以在后期让模型的损失下降地更加稳定,使模型更好地收敛。
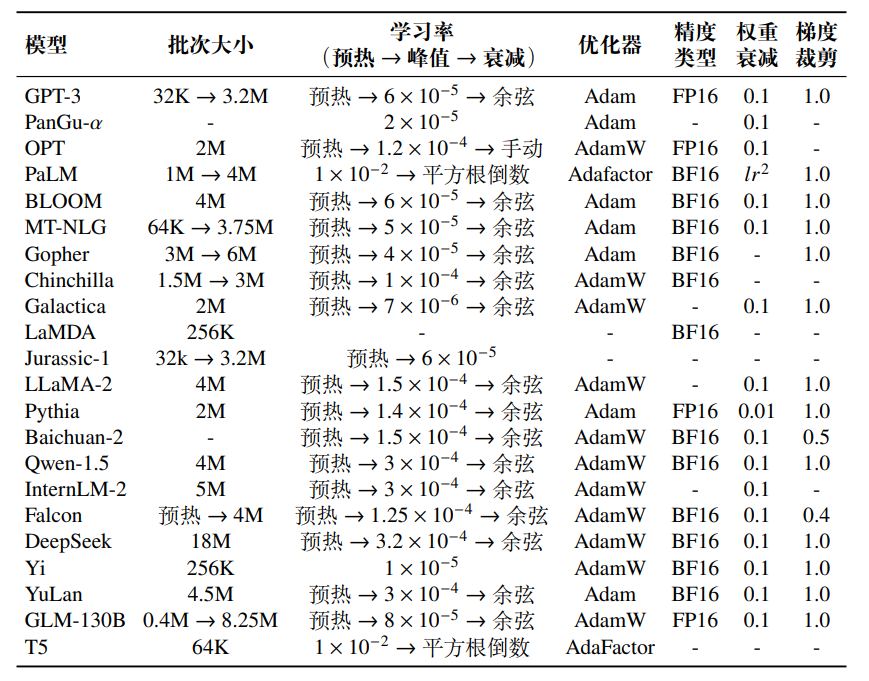
学习率
现有的大语言模型在预训练阶段通常采用相似的学习率调整策略,包括预热阶段和衰减阶段。预热阶段一般占整个训练步骤的 0.1% 至 0.5%,然后学习率便开始进行衰减。在模型训练的初始阶段,由于参数是随机初始化的&#
标签:训练,词元,批次,模型,学习,优化,参数设置 From: https://blog.csdn.net/weixin_43961909/article/details/140532526