以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。
本节课程地址:21 卷积层里的多输入多输出通道【动手学深度学习v2】_哔哩哔哩_bilibili
本节教材地址:6.4. 多输入多输出通道 — 动手学深度学习 2.0.0 documentation (d2l.ai)
本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>channels.ipynb
多输入多输出通道
虽然我们在 6.1.4.1节 中描述了构成每个图像的多个通道和多层卷积层。例如彩色图像具有标准的RGB通道来代表红、绿和蓝。 但是到目前为止,我们仅展示了单个输入和单个输出通道的简化例子。 这使得我们可以将输入、卷积核和输出看作二维张量。
当我们添加通道时,我们的输入和隐藏的表示都变成了三维张量。例如,每个RGB输入图像具有 的形状。我们将这个大小为3的轴称为通道(channel)维度。本节将更深入地研究具有多输入和多输出通道的卷积核。
多输入通道
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。假设输入的通道数为 ,那么卷积核的输入通道数也需要为
。如果卷积核的窗口形状是
,那么当
时,我们可以把卷积核看作形状为
的二维张量。
然而,当 时,我们卷积核的每个输入通道将包含形状为
的张量。将这些张量
连结在一起可以得到形状为
的卷积核。由于输入和卷积核都有
个通道,我们可以对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和(将
的结果相加)得到二维张量。这是多通道输入和多输入通道卷积核之间进行二维互相关运算的结果。
在 图6.4.1 中,我们演示了一个具有两个输入通道的二维互相关运算的示例。阴影部分是第一个输出元素以及用于计算这个输出的输入和核张量元素: 。

多个输入通道:
- 输入
- 核
- 输出
为了加深理解,我们(实现一下多输入通道互相关运算)。 简而言之,我们所做的就是对每个通道执行互相关操作,然后将结果相加。
import torch
from d2l import torch as d2l
def corr2d_multi_in(X, K):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))我们可以构造与 :numref:fig_conv_multi_in中的值相对应的输入张量X和核张量K,以(验证互相关运算的输出)。
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
corr2d_multi_in(X, K)输出结果:
tensor([[ 56., 72.],
[104., 120.]])
多输出通道
到目前为止,不论有多少输入通道,我们还只有一个输出通道。然而,正如我们在 6.1.4.1节 中所讨论的,每一层有多个输出通道是至关重要的。在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。
用 和
分别表示输入和输出通道的数目,并让
和
为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为
的卷积核张量,这样卷积核的形状是
。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
多个输出通道:
- 可以有多个三维卷积核,每个核生成一个输出通道
- 输入
- 核
- 输出
如下所示,我们实现一个[计算多个通道的输出的互相关函数]。
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度(输出通道),每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)通过将核张量K与K+1(K中每个元素加1)和K+2连接起来,构造了一个具有3个输出通道的卷积核。
K = torch.stack((K, K + 1, K + 2), 0)
K.shape输出结果:
torch.Size([3, 2, 2, 2])
下面,我们对输入张量X与卷积核张量K执行互相关运算。现在的输出包含3个通道,第一个通道的结果与先前输入张量X和多输入单输出通道的结果一致。
corr2d_multi_in_out(X, K)输出结果:
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])
多个输入和输出通道用途:
- 每个输出通道可以识别特定模式
- 输入通道核识别并组合输入中的模式
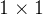 卷积层
卷积层
卷积,即
,看起来似乎没有多大意义。 毕竟,卷积的本质是有效提取相邻像素间的相关特征,而
卷积显然没有此作用。 尽管如此,
仍然十分流行,经常包含在复杂深层网络的设计中。下面,让我们详细地解读一下它的实际作用。
因为使用了最小窗口, 卷积失去了卷积层的特有能力——在高度和宽度维度上,识别相邻元素间相互作用的能力。 其实
卷积的唯一计算发生在通道上。
图6.4.2 展示了使用 卷积核与3个输入通道和2个输出通道的互相关计算。 这里输入和输出具有相同的高度和宽度,输出中的每个元素都是从输入图像中同一位置的元素的线性组合。 我们可以将
卷积层看作在每个像素位置应用的全连接层,以
个输入值转换为
个输出值。 因为这仍然是一个卷积层,所以跨像素的权重是一致的。 同时,
卷积层需要的权重维度为
,再额外加上一个偏置。
卷积层:
,不识别空间模式,只是融合通道。 相当于输入形状为
,权重为
的全连接层。

下面,我们使用全连接层实现 1×1 卷积。 请注意,我们需要对输入和输出的数据形状进行调整。
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))当执行 1×1 卷积运算时,上述函数相当于先前实现的互相关函数corr2d_multi_in_out。让我们用一些样本数据来验证这一点。
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
# 意味着1×1的卷积层相当于输入形状为c_i × n_hn_w,权重为c_o × c_i的全连接层二维卷积层
- 输入
- 核
- 偏差
- 输出
- 计算复杂度(浮点计算数FLOP)
(连乘)
令
则计算量为 1GFLOP
- 假设net有10层,1M样本,计算量为10PFlops
- 相当于CPU(0.15 TF/s)计算18h,GPU(12 TF/s)计算14分钟
小结
- 输出通道数是卷积层的超参数。
- 多输入多输出通道可以用来扩展卷积层的模型。
- 当以每像素为基础应用时,
卷积层相当于全连接层。
练习
1. 假设我们有两个卷积核,大小分别为 和
(中间没有非线性激活函数)。
1)证明运算可以用单次卷积来表示。
2)这个等效的单个卷积核的维数是多少呢?
3)反之亦然吗?
解:
1)不考虑通道、填充和步幅,证明如下:
输入 ,
核 ,
第一次卷积后的输出 ,
第二次卷积后的输出
也即,将卷积核设为 可以等价代替以上两个卷积核。
2)如上所述,等线的单个卷积核维数为 。
3)反之亦然,单个卷积核也可拆成两个卷积核等价表示。
2. 假设输入为 ,卷积核大小为
,填充为
,步幅为
。
1)前向传播的计算成本(乘法和加法)是多少?
2)内存占用是多少?
3)反向传播的内存占用是多少?
4)反向传播的计算成本是多少?
解:
1) 一次卷积的乘法操作数量是 , 加法操作数量是
,
卷积操作数量为 ,
因此,前向传播的计算成本(乘法和加法)为:
2) 前向传播的内存占用为输入、输出、权重和偏置参数量之和:
3) 反向传播为对权重和偏置求偏导,内存占用为权重和偏置参数量之和:
4) 推荐先看图示卷积神经网络反向传播原理:https://www.bilibili.com/video/BV1eP411D77M/?spm_id_from=333.337.search-card.all.click&vd_source=8dd6bc62e96dda5b38e6bd4149b70687
仅考虑权重求导:
一次偏导操作数量是 , 加法操作数量是
,
偏导操作数量为 ,
权重更新的操作数量为 ,
因此,反向传播的计算成本(乘法和加法)为:
3. 如果我们将输入通道 和输出通道
的数量加倍,计算数量会增加多少?如果我们把填充数量翻一番会怎么样?
解:
输入通道 和输出通道
的数量加倍,计算数量会增加到之前的4倍;
填充数量翻一番,计算数量增加
4. 如果卷积核的高度和宽度是 ,前向传播的计算复杂度是多少?
解:
卷积核的高度和宽度是 时,前向传播的计算复杂度是
5. 本节最后一个示例中的变量Y1和Y2是否完全相同?为什么?
解:
不完全相同,因为浮点数计算有误差,代码如下:
Y1 == Y2输出结果:
tensor([[[False, True, False],
[ True, True, True],
[ True, True, True]],
[[ True, True, True],
[ True, True, True],
[ True, True, True]]])
6. 当卷积窗口不是 1×1 时,如何使用矩阵乘法实现卷积?
解:
方法与6.2练习第3题一样,代码如下:
def corr2d_matmul(X, K):
h, w = K.shape
# 将输入X中每次与卷积核做互相关运算的元素展平成一行
# X_reshaped的每一行元素均为与卷积核做互相关的元素
X_reshaped = torch.zeros((X.shape[0] - h + 1)*(X.shape[1] - w + 1), h*w)
k = 0
for i in range(X.shape[0] - h + 1):
for j in range(X.shape[1] - w + 1):
X_reshaped[k,:] = X[i:i + h, j:j + w].reshape(1,-1)
k += 1
# 将卷积核K转为列向量,并与X_reshaped做矩阵乘法,再reshape成输出尺寸即可
Y = X_reshaped@K.view(-1)
return Y.reshape(X.shape[0] - h + 1, X.shape[1] - w + 1)
def corr2d_matmul_multi_in(X, K):
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
corr2d_matmul_multi_in(X, K)输出结果:
tensor([[ 56., 72.],
[104., 120.]])