一、背景
测试小伙伴们在2023年保障了团队线上系统0问题,这简直就是一项了不起的壮举!这得益于咱们测试组同事对工作的细致投入、风险把控、以及严格遵循流程规范进行测试用例评审、自动化建设、联调推动、回归验证、常态化压测、大促高保真压测、引流回放等多重保险策略工作。尤其是测试团队在流量录制回放方面的实践经验非常丰富,还贡献了不少文档,简直是测试界的大佬啊!
本文从研发的的视角去看待流量回放这个问题,或许也能提供一些有趣的观点呢。
文档内容说的不一定对,欢迎专业的测试大佬鞭打我的思维火花!这样对我来说也是成长。
二、流量回放
从系统稳定性角度出发,任何需求我都会跟小组团队强烈要求一点,不要影响线上既有功能,做好DUCC开关快速止血。(太多的COE报告历史经验教训都是因为上线某功能B最终导致之前功能A出问题,比如修改了公共的某些方法等)那如何保障不影响线上既有功能呢,自动化测试是一方面,但流量回放比对才是最佳的方式。
流量回放原理其实就是录制线上真实的流量,到预发引流环境进行回放,对比生产和预发环境录入接口的子调用、响应差异去定位代码问题。流量回放用例的创建成本很低,使得每次迭代全量回归有了理论基础。优点是业务代码零侵入、真实链路调用、多场景、数据可查、结果diff比对、问题定位精准,提前发现问题。风险是操作不慎可能导致线上问题,比如依赖的下游接口流量暴涨,或者写操作导致线上脏数据,最终影响业务
三、流量录制
流量来源哪里?肯定是线上真实流量靠谱,可以包含实时的流量也可包含历史流量(离线录制的流量),或者人为造的测试流量(造的流量也是参考线上历史流量有价值的)
其实流量录制核心关心的是录制的流量够不够,是否能覆盖这次代码改动牵扯的业务场景。
1、流量规则
流量过滤:
R2支持过滤规则设置,通过可视化配置:支持字段级过滤规则配置,仅录制符合规则的流量。或者自定义脚本:当过滤规则较为复杂时,可使用自定脚本,编写过滤代码。
流量去重:
有时R2可能录制到非常多的相同流量,如果某些系统不需要的话,可能造成后续回放耗时较长和问题排查效率低下。需要思考如何能在保证接口覆盖率的情况下尽可能减少相同流量的数量。通过这种机制在一些场景大幅度减少了录制流量数量,提高了流量的使用效率。当然大部分场景是不需要去重的,如果需要去重流量不清楚现在R2是否可以通过自定义脚本支持(比如根据10个入参其中的8个入参来判断重复的逻辑)。
2、场景覆盖度
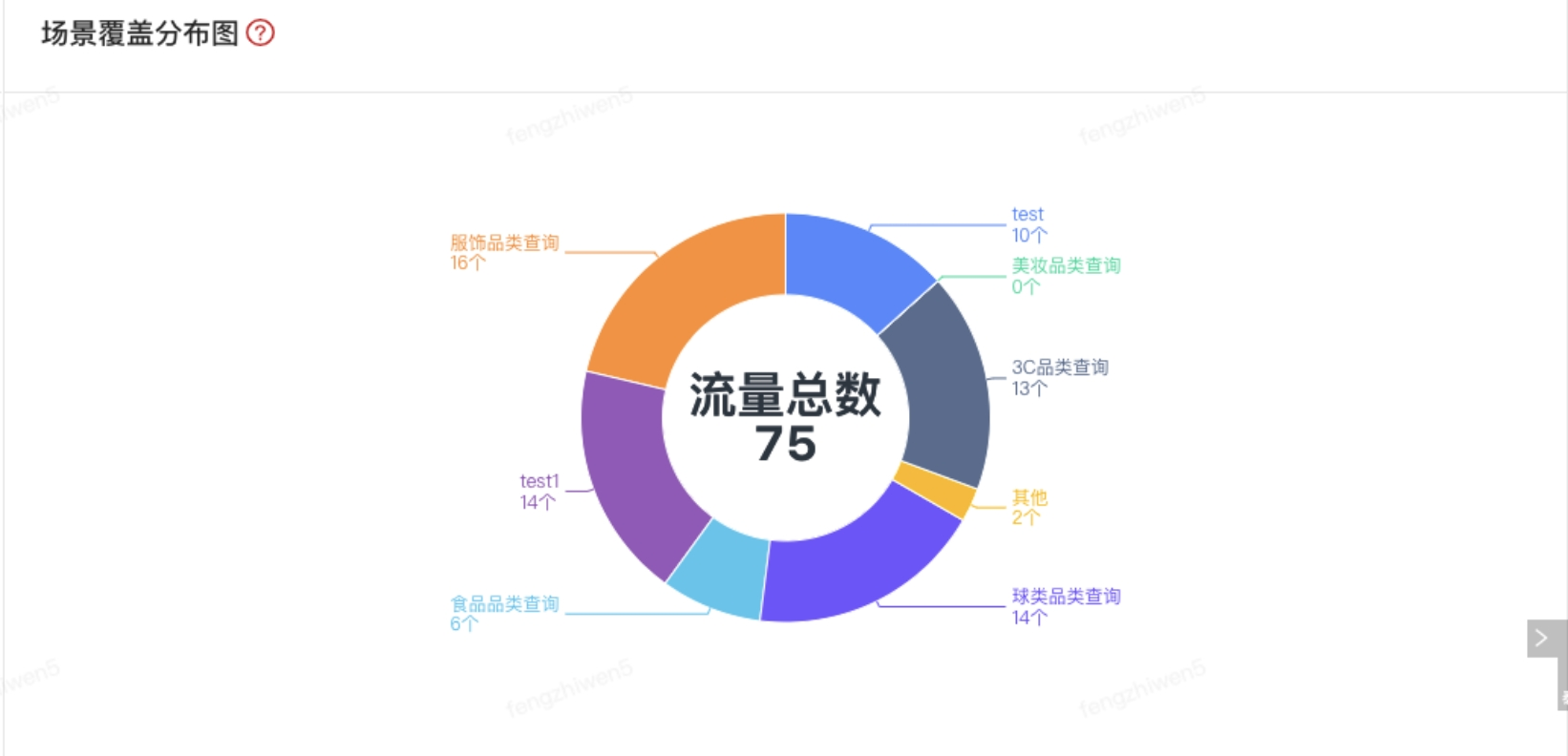
为了使用户了解录制到流量的覆盖程度,如:是否存在场景缺失?是否存在我们不知道的场景等,R2特此开发录制场景覆盖度功能,帮你更了解你的生产流量。
案例:
比如Promise社区团购业务只有晚上20点后才会有这种特殊的业务,故需要思考你本次回放的代码是否需要覆盖该场景,则需要录制回放晚上20点后流量。
所以流量录制回放多久合适?是2小时、4小时还是多久,评判标准就是场景覆盖度。
3、大促&春节特殊场景流量
为什么要单独谈一下大促&春节特殊场景的流量,比如Promise很多场景是只有大促才会有的,比如预售场景。这部分流量日常根本获取不到,就算你录制回放线上1个月流量也是无用的。这样的特殊场景流量用于日常回放非常有价值。尤其是改了大促场景需求或者大促前上线了N个需求,可能影响到大促特殊场景功能正确性。那具体如何做呢?我想到的如下思路:
1.是不是可以通过R2的流量录制,通过入参过滤获取这部分特殊场景流量,但需要思考不影响大促当天线上系统性能。并且要求接口入参可以区分哪些是大促特殊场景的流量。 2.如果接口依赖很多下游,这需要思考,他们的结果mock保留起来 或者其他方式 3.或者根据logbook日志找出大促特殊场景的业务 入参、出参等等。然后人为整理流量,但这耗时耗力。当然因为时间久远,大促特殊场景的流量我们核心是需要入参,当时的出参结果可能价值不大,因为现在跑结果可能就是不一样,当然具体因系统而定。
四、回放
回放分离线DIFF和实时DIFF。实时DIFF适合业务场景时效性比较强,例如:计费、活动等类型的场景。这些场景因为时效性,不能使用流量录制来进行 Diff 测试。实时 Diff 恰好可以帮助我们进行此类场景 diff 测试。但如果对时间特别敏感的,实时 Diff也是会存在回放失败率。 为了能实现将 回放时间 倒回到 录制时间,不知道现在R2是否支持,可将录制时间戳传递给服务(比如System.currentTimeMillis() 这种native方法,动态修改方法体的字节码,代理掉业务对该方法的调用,动态替换为R2事先定义的获取时间方法从而保证时间替换。)
流量回放一般牵扯读接口、读写接口、写接口。
1、读接口回放
对只读接口进行不mock的回放能够在上线前的最后阶段进行一次兜底的回归校验。但需要注意的是,当前是只读的接口难以保证后续的变更不会引入写操作。
案例:
Promise时效域-下传控制 之前一直是只读接口,在2023年期间上线了门店产能占用写逻辑,但团队有次线上流量回放忘了这个写的新功能,导致占用线上产能了(唯一幸运点的是占用产能波次跟线上是一致,不会导致产能波次占用错误)
临时解决方案:
团队制定规则,如果读接口变成读写,则需要去Ducc引流环境把对应写功能的开关关闭,同理发送MQ同理也是通过开关关闭。并且每次回放前都进行人工校验写链路,但这能不能做到 或者效率也是个问题,暂时未想到更好的方法。
2、写接口回放
1.在流量回放中,读接口和写接口回放的方式有很大不同。事实上,这不只是流量回放的特点。即使是传统接口自动化测试,读接口和写接口的测试策略也是有很大不同的。 2.读接口和写接口的不同,在于读接口没有副作用,而写接口有副作用。写接口的副作用通常体现在会对被测系统产生脏数据上。 3.写接口需要注意可能操作不慎导致回放的接口中调用产生脏数据,影响业务。 4.如果写接口,mock的意义不大,如果不操作线上写,可以搭建一套UAT引流回放写的环境,可链路的某些服务或者组件依赖可以mock,当然里面可能比较复杂,比如数据的操作,mysql,redis等UAT环节。结果比对不是简单的diff比对。则应该是去看具体关键数据、log日志等去验证结果。如果接口返回的数据依赖于数据库或其他外部系统,那么在真实调用时可能会出现数据不一致的问题,导致测试结果不准确。 5.跟上面搭建的UAT引流环境类似。参考军演全链路压测,通过修改录制的流量数据,通过修改入参,传递forcebot标识,代码识别到forcebot标识,走对应军演影子环境。数据线上有mysql影子库,Redis等影子环境,写操作是直接写到影子里。

JSF接口MOCK失败

3、读写接口回放
读写接口分为读和写。核心是偏读,内部部分逻辑是写,针对这,读遵循上面的原则即可,写可以采用如下方式
1.通过Mock方式返回,不会真实操作写动作,不会污染应用数据。R2支持各种中间件Mock,不详细讲解。 2.通过DUCC开关关闭写的逻辑。案例:比如Promise上面说的产能占用逻辑&发送MQ就是通过DUCC开关关闭该逻辑。

4、是否应该Mock回放
1.Mock回放与接口是否读写操作并没有直接的联系。只是日常习惯写接口mock,读用线上真实。但对于读接口,既可以使用Mock回放,也可以不使用Mock回放;而对于写接口,同样可以选择使用Mock回放或不使用Mock回放 2.Mock回放与非Mock回放之间的本质区别在于:Mock回放是一种白盒测试方法,而非Mock回放则是一种黑盒测试方法。5、回放覆盖率统计
我们是否已经全面录制了流量?回放测试是否存在代码盲区?如何证明我们的测试足够全面?或许你也曾有过这样的疑虑。为了解决这个问题,R2支持离线回放代码覆盖率。覆盖率统计回放,即流量回放的同时,支持被测代码覆盖率统计,并生成覆盖率报告。

五、Diff结果比对
1.制定灵活的回放结果比对策略,减轻排错成本:比如忽略哪些字段,核心关注哪些出参,需要对API接口的出入参及业务非常熟悉,需要制定合理的对比策略,根据场景的不同,灵活采用关键字段对比、结构对比等策略。 2.有些Diff比对不一致,只能分别去查看logbook日志寻找原因,有些是因为回放的时候业务修改了配置导致,有些是真正的bug问题,则需要及时修复然后再次引流回放。 3.有些需求改了逻辑,需要的就是Diff不一样,这时候流量回放的目的不是为了比对,而是用线上流量丰富测试用例,让测试更加精准。
我是研发,是一个测试小白,文章内容可能有些不完全准确,希望通过您的指正和建议来不断完善和改进。
标签:场景,浅谈,回放,录制,R2,流量,接口,Mock From: https://www.cnblogs.com/Jcloud/p/18298564