617.合并二叉树
题意描述:
给你两棵二叉树:
root1和root2。想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
示例 1:
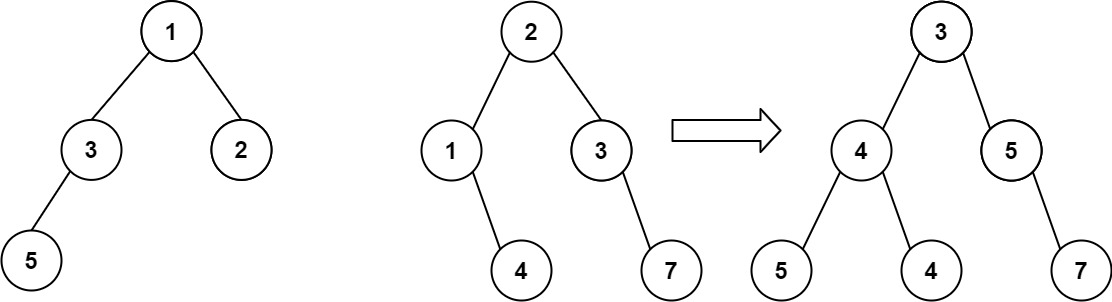
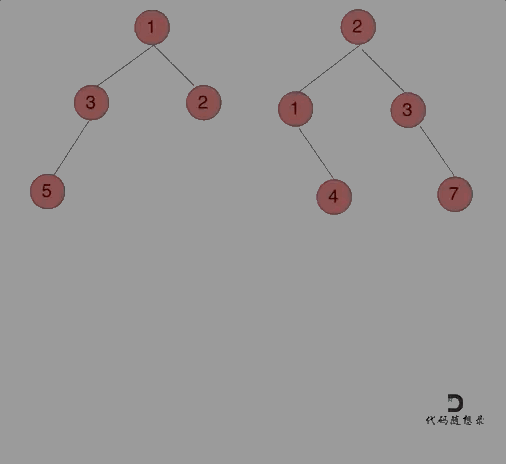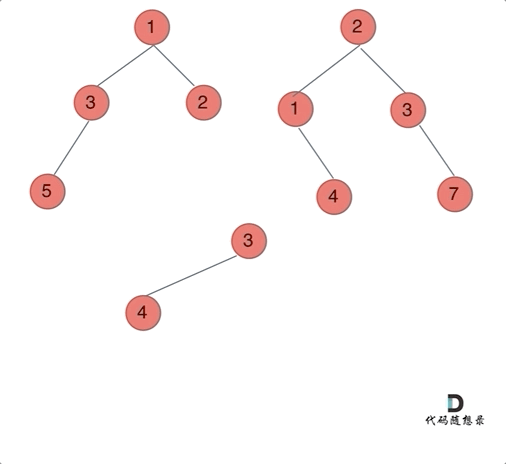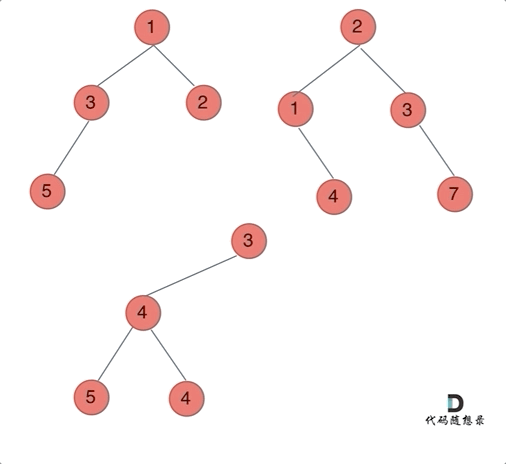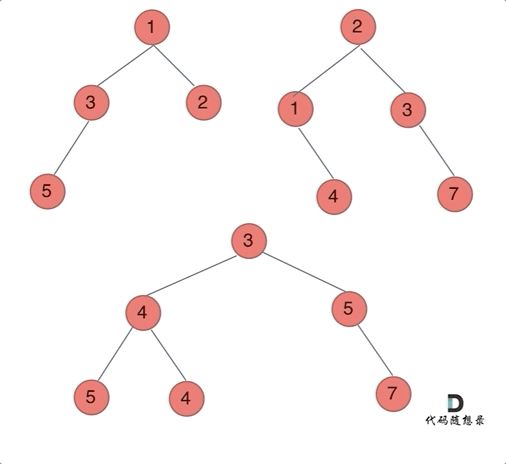
输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7] 输出:[3,4,5,5,4,null,7]示例 2:
输入:root1 = [1], root2 = [1,2] 输出:[2,2]提示:
- 两棵树中的节点数目在范围
[0, 2000]内-104 <= Node.val <= 104
思路:
相信这道题目很多同学疑惑的点是如何同时遍历两个二叉树呢?
其实和遍历一个树逻辑是一样的,只不过传入两个树的节点,同时操作。
递归
二叉树使用递归,就要想使用前中后哪种遍历方式?
本题使用哪种遍历都是可以的!
我们下面以前序遍历为例。
动画如下:
那么我们来按照递归三部曲来解决:
- 确定递归函数的参数和返回值:
首先要合入两个二叉树,那么参数至少是要传入两个二叉树的根节点,返回值就是合并之后二叉树的根节点。
代码如下:
TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) {
- 确定终止条件:
因为是传入了两个树,那么就有两个树遍历的节点
t1和t2,如果t1 == NULL了,两个树合并就应该是t2了(如果t2也为NULL也无所谓,合并之后就是NULL)。反过来如果
t2 == NULL,那么两个数合并就是t1(如果t1也为NULL也无所谓,合并之后就是NULL)。代码如下:
if (t1 == NULL) return t2; // 如果t1为空,合并之后就应该是t2 if (t2 == NULL) return t1; // 如果t2为空,合并之后就应该是t1
- 确定单层递归的逻辑:
单层递归的逻辑就比较好写了,这里我们重复利用一下
t1这个树,t1就是合并之后树的根节点(就是修改了原来树的结构)。那么单层递归中,就要把两棵树的元素加到一起。
t1->val += t2->val;接下来
t1的左子树是:合并t1左子树t2左子树之后的左子树。
t1的右子树:是 合并t1右子树t2右子树之后的右子树。最终
t1就是合并之后的根节点。代码如下:
t1->left = mergeTrees(t1->left, t2->left); t1->right = mergeTrees(t1->right, t2->right); return t1;此时前序遍历,完整代码就写出来了,如下:
class Solution { public: TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) { if (t1 == NULL) return t2; // 如果t1为空,合并之后就应该是t2 if (t2 == NULL) return t1; // 如果t2为空,合并之后就应该是t1 // 修改了t1的数值和结构 t1->val += t2->val; // 中 t1->left = mergeTrees(t1->left, t2->left); // 左 t1->right = mergeTrees(t1->right, t2->right); // 右 return t1; } };那么中序遍历也是可以的,代码如下:
class Solution { public: TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) { if (t1 == NULL) return t2; // 如果t1为空,合并之后就应该是t2 if (t2 == NULL) return t1; // 如果t2为空,合并之后就应该是t1 // 修改了t1的数值和结构 t1->left = mergeTrees(t1->left, t2->left); // 左 t1->val += t2->val; // 中 t1->right = mergeTrees(t1->right, t2->right); // 右 return t1; } };后序遍历依然可以,代码如下:
class Solution { public: TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) { if (t1 == NULL) return t2; // 如果t1为空,合并之后就应该是t2 if (t2 == NULL) return t1; // 如果t2为空,合并之后就应该是t1 // 修改了t1的数值和结构 t1->left = mergeTrees(t1->left, t2->left); // 左 t1->right = mergeTrees(t1->right, t2->right); // 右 t1->val += t2->val; // 中 return t1; } };但是前序遍历是最好理解的,我建议大家用前序遍历来做就OK。
如上的方法修改了
t1的结构,当然也可以不修改t1和t2的结构,重新定义一个树。不修改输入树的结构,前序遍历,代码如下:
class Solution { public: TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) { if (t1 == NULL) return t2; if (t2 == NULL) return t1; // 重新定义新的节点,不修改原有两个树的结构 TreeNode* root = new TreeNode(0); root->val = t1->val + t2->val; root->left = mergeTrees(t1->left, t2->left); root->right = mergeTrees(t1->right, t2->right); return root; } };迭代法
使用迭代法,如何同时处理两棵树呢?
思路我们在二叉树:我对称么? (opens new window)中的迭代法已经讲过一次了,求二叉树对称的时候就是把两个树的节点同时加入队列进行比较。
本题我们也使用
队列,模拟的层序遍历,代码如下:class Solution { public: TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) { if (t1 == NULL) return t2; if (t2 == NULL) return t1; queue<TreeNode*> que; que.push(t1); que.push(t2); while(!que.empty()) { TreeNode* node1 = que.front(); que.pop(); TreeNode* node2 = que.front(); que.pop(); // 此时两个节点一定不为空,val相加 node1->val += node2->val; // 如果两棵树左节点都不为空,加入队列 if (node1->left != NULL && node2->left != NULL) { que.push(node1->left); que.push(node2->left); } // 如果两棵树右节点都不为空,加入队列 if (node1->right != NULL && node2->right != NULL) { que.push(node1->right); que.push(node2->right); } // 当t1的左节点 为空 t2左节点不为空,就赋值过去 if (node1->left == NULL && node2->left != NULL) { node1->left = node2->left; } // 当t1的右节点 为空 t2右节点不为空,就赋值过去 if (node1->right == NULL && node2->right != NULL) { node1->right = node2->right; } } //因为最后返回t1,所以t1非空,t2空这种情况不用管,直接返回t1即可 return t1; } };拓展
当然也可以秀一波指针的操作,这是我写的野路子,大家就随便看看就行了,以防带跑偏了。
如下代码中,想要更改二叉树的值,应该传入指向指针的指针。
代码如下:(前序遍历)
class Solution { public: void process(TreeNode** t1, TreeNode** t2) { if ((*t1) == NULL && (*t2) == NULL) return; if ((*t1) != NULL && (*t2) != NULL) { (*t1)->val += (*t2)->val; } if ((*t1) == NULL && (*t2) != NULL) { *t1 = *t2; return; } if ((*t1) != NULL && (*t2) == NULL) { return; } process(&((*t1)->left), &((*t2)->left)); process(&((*t1)->right), &((*t2)->right)); } TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) { process(&t1, &t2); return t1; } };总结
合并二叉树,也是二叉树操作的经典题目,如果没有接触过的话,其实并不简单,因为我们习惯了操作一个二叉树,一起操作两个二叉树,还会有点懵懵的。
这不是我们第一次操作两棵二叉树了,在二叉树:我对称么? (opens new window)中也一起操作了两棵二叉树。
迭代法中,一般一起操作两个树都是使用队列模拟类似层序遍历,同时处理两个树的节点,这种方式最好理解,如果用模拟递归的思路的话,要复杂一些。
最后拓展中,我给了一个操作指针的野路子,大家随便看看就行了,如果学习C++的话,可以再去研究研究。
700.二叉搜索树中的搜索
题意描述:
给定二叉搜索树(
BST)的根节点root和一个整数值val。你需要在
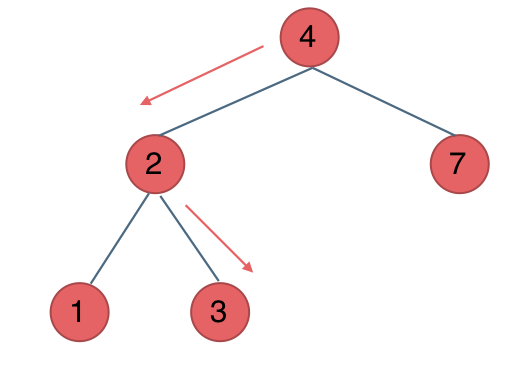
BST中找到节点值等于val的节点。 返回以该节点为根的子树。 如果节点不存在,则返回null。示例 1:
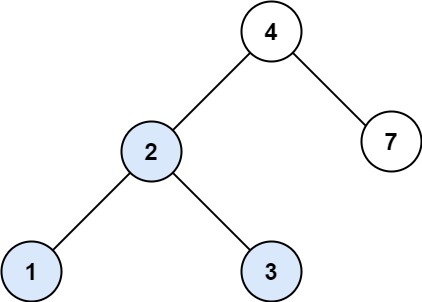
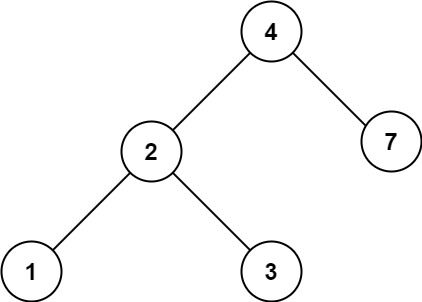
输入:root = [4,2,7,1,3], val = 2 输出:[2,1,3]示例 2:
输入:root = [4,2,7,1,3], val = 5 输出:[]提示:
- 树中节点数在
[1, 5000]范围内1 <= Node.val <= 107root是二叉搜索树1 <= val <= 107
思路:
二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
这就决定了,二叉搜索树,递归遍历和迭代遍历和普通二叉树都不一样。
本题,其实就是在二叉搜索树中搜索一个节点。那么我们来看看应该如何遍历。
递归法
- 确定递归函数的参数和返回值
递归函数的参数传入的就是根节点和要搜索的数值,返回的就是以这个搜索数值所在的节点。
代码如下:
TreeNode* searchBST(TreeNode* root, int val)
- 确定终止条件
如果root为空,或者找到这个数值了,就返回root节点。
if (root == NULL || root->val == val) return root;
- 确定单层递归的逻辑
看看二叉搜索树的单层递归逻辑有何不同。
因为二叉搜索树的节点是有序的,所以可以有方向的去搜索。
如果
root->val > val,搜索左子树,如果root->val < val,就搜索右子树,最后如果都没有搜索到,就返回NULL。代码如下:
TreeNode* result = NULL; if (root->val > val) result = searchBST(root->left, val); if (root->val < val) result = searchBST(root->right, val); return result;很多录友写递归函数的时候 习惯直接写
searchBST(root->left, val),却忘了 递归函数还有返回值。递归函数的返回值是什么? 是 左子树如果搜索到了val,要将该节点返回。 如果不用一个变量将其接住,那么返回值不就没了。
所以要
result = searchBST(root->left, val)。整体代码如下:
class Solution { public: TreeNode* searchBST(TreeNode* root, int val) { if (root == NULL || root->val == val) return root; TreeNode* result = NULL; if (root->val > val) result = searchBST(root->left, val); if (root->val < val) result = searchBST(root->right, val); return result; } };或者我们也可以这么写
class Solution { public: TreeNode* searchBST(TreeNode* root, int val) { if (root == NULL || root->val == val) return root; if (root->val > val) return searchBST(root->left, val); if (root->val < val) return searchBST(root->right, val); return NULL; } };迭代法
一提到二叉树遍历的迭代法,可能立刻想起使用
栈来模拟深度遍历,使用队列来模拟广度遍历。对于二叉搜索树可就不一样了,因为二叉搜索树的特殊性,也就是节点的有序性,可以不使用辅助栈或者队列就可以写出迭代法。
对于一般二叉树,递归过程中还有回溯的过程,例如走一个左方向的分支走到头了,那么要调头,在走右分支。
而对于二叉搜索树,不需要回溯的过程,因为节点的有序性就帮我们确定了搜索的方向。
例如要搜索元素为3的节点,我们不需要搜索其他节点,也不需要做回溯,查找的路径已经规划好了。
中间节点如果大于3就向左走,如果小于3就向右走,如图:
所以迭代法代码如下:
class Solution { public: TreeNode* searchBST(TreeNode* root, int val) { while (root != NULL) { if (root->val > val) root = root->left; else if (root->val < val) root = root->right; else return root; } return NULL; } };第一次看到了如此简单的迭代法,是不是感动的痛哭流涕,哭一会~
总结
本篇我们介绍了二叉搜索树的遍历方式,因为二叉搜索树的有序性,遍历的时候要比普通二叉树简单很多。
但是一些同学很容易忽略二叉搜索树的特性,所以写出遍历的代码就未必真的简单了。
所以针对二叉搜索树的题目,一样要利用其特性。
文中我依然给出递归和迭代两种方式,可以看出写法都非常简单,就是利用了二叉搜索树有序的特点。
98.验证二叉搜索树
题意描述:
给你一个二叉树的根节点
root,判断其是否是一个有效的二叉搜索树。有效 二叉搜索树定义如下:
- 节点的左子树只包含小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
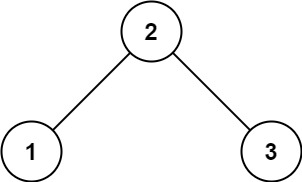
输入:root = [2,1,3] 输出:true示例 2:
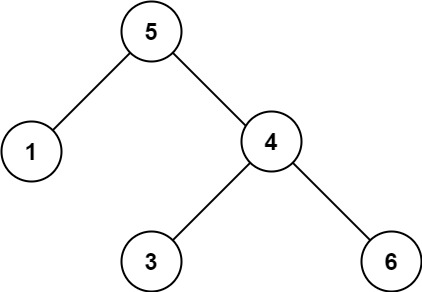
输入:root = [5,1,4,null,null,3,6] 输出:false 解释:根节点的值是 5 ,但是右子节点的值是 4 。提示:
- 树中节点数目范围在
[1, 104]内-231 <= Node.val <= 231 - 1
思路:
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
有了这个特性,验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。
递归法
可以递归中序遍历将二叉搜索树转变成一个数组,代码如下:
vector<int> vec; void traversal(TreeNode* root) { if (root == NULL) return; traversal(root->left); vec.push_back(root->val); // 将二叉搜索树转换为有序数组 traversal(root->right); }然后只要比较一下,这个数组是否是有序的,注意二叉搜索树中不能有重复元素。
traversal(root); for (int i = 1; i < vec.size(); i++) { // 注意要小于等于,搜索树里不能有相同元素 if (vec[i] <= vec[i - 1]) return false; } return true;整体代码如下:
class Solution { private: vector<int> vec; void traversal(TreeNode* root) { if (root == NULL) return; traversal(root->left); vec.push_back(root->val); // 将二叉搜索树转换为有序数组 traversal(root->right); } public: bool isValidBST(TreeNode* root) { vec.clear(); // 不加这句在leetcode上也可以过,但最好加上 traversal(root); for (int i = 1; i < vec.size(); i++) { // 注意要小于等于,搜索树里不能有相同元素 if (vec[i] <= vec[i - 1]) return false; } return true; } };以上代码中,我们把二叉树转变为数组来判断,是最直观的,但其实不用转变成数组,可以在递归遍历的过程中直接判断是否有序。
这道题目比较容易陷入两个陷阱:
- 陷阱1
不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了。
写出了类似这样的代码:
if (root->val > root->left->val && root->val < root->right->val) { return true; } else { return false; }我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。所以以上代码的判断逻辑是错误的。
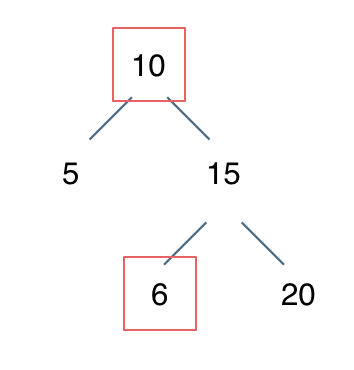
例如: [10,5,15,null,null,6,20] 这个case:
节点10大于左节点5,小于右节点15,但右子树里出现了一个6 这就不符合了!
- 陷阱2
样例中最小节点 可能是
int的最小值(- 2 ^ 31),如果这样使用最小的int来比较也是不行的。此时可以初始化比较元素为
longlong的最小值。问题可以进一步演进:如果样例中根节点的
val可能是longlong的最小值 又要怎么办呢?了解这些陷阱之后我们来看一下代码应该怎么写:
递归三部曲:
- 确定递归函数,返回值以及参数
要定义一个
longlong的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有int最小值,所以定义为longlong的类型,初始化为longlong最小值。注意递归函数要有
bool类型的返回值, 我们在二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值? (opens new window)中讲了,只有寻找某一条边(或者一个节点)的时候,递归函数会有bool类型的返回值。其实本题是同样的道理,我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
代码如下:
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值 bool isValidBST(TreeNode* root)
- 确定终止条件
如果是空节点 是不是二叉搜索树呢?
是的,二叉搜索树也可以为空!
代码如下:
if (root == NULL) return true;
- 确定单层递归的逻辑
中序遍历,一直更新
maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。代码如下:
bool left = isValidBST(root->left); // 左 // 中序遍历,验证遍历的元素是不是从小到大 if (maxVal < root->val) maxVal = root->val; // 中 else return false; bool right = isValidBST(root->right); // 右 return left && right;整体代码如下:
class Solution { public: long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值 bool isValidBST(TreeNode* root) { if (root == NULL) return true; bool left = isValidBST(root->left); // 中序遍历,验证遍历的元素是不是从小到大 if (maxVal < root->val) maxVal = root->val; else return false; bool right = isValidBST(root->right); return left && right; } };以上代码是因为后台数据有
int最小值测试用例,所以都把maxVal改成了longlong最小值。如果测试数据中有
longlong的最小值,怎么办?不可能在初始化一个更小的值了吧。 建议避免 初始化最小值,如下方法取到最左面节点的数值来比较。
代码如下:
class Solution { public: TreeNode* pre = NULL; // 用来记录前一个节点 bool isValidBST(TreeNode* root) { if (root == NULL) return true; bool left = isValidBST(root->left); if (pre != NULL && pre->val >= root->val) return false; pre = root; // 记录前一个节点 bool right = isValidBST(root->right); return left && right; } };最后这份代码看上去整洁一些,思路也清晰。
迭代法
迭代法中序遍历稍加改动就可以了,代码如下:
class Solution { public: bool isValidBST(TreeNode* root) { stack<TreeNode*> st; TreeNode* cur = root; TreeNode* pre = NULL; // 记录前一个节点 while (cur != NULL || !st.empty()) { if (cur != NULL) { st.push(cur); cur = cur->left; // 左 } else { cur = st.top(); // 中 st.pop(); if (pre != NULL && cur->val <= pre->val) return false; pre = cur; //保存前一个访问的结点 cur = cur->right; // 右 } } return true; } };这题不能用
queue作为容器,因为递归搜索的push与pop是对上一层处理,que不行总结
这道题目是一个简单题,但对于没接触过的同学还是有难度的。
所以初学者刚开始学习算法的时候,看到简单题目没有思路很正常,千万别怀疑自己智商,学习过程都是这样的,大家智商都差不多。
只要把基本类型的题目都做过,总结过之后,思路自然就开阔了,加油
标签:right,val,合并,二叉树,6.20,NULL,root,节点,left From: https://www.cnblogs.com/7dragonpig/p/18259587