你好呀,我是歪歪。 前几天遇到一个生产问题,同一个数据在数据库里面被插入了两次,导致后续处理出现了一些问题。 当时我们首先检讨了自己,没有做好幂等校验。甚至还发现了一个低级错误:对应的表,针对订单号,这个业务上具有唯一属性的字段,连唯一索引都没有加。如果加了唯一索引,也不至于出现落库两次的情况。 然后拿着数据去问上游系统,为什么会出现同一个订单发起了两次的这种异常场景。 上游系统一听到我们的描述,立马就站出来解释:不可能,在没有人工介入的情况下,同一个单子,我们绝对不可能发送两次。在开发的过程中,我们还特意注意了这个场景。 但是我是不相信他们的“鬼话”,我更觉得这就是他们的一个 BUG。 既然争执不下了,那就拿事实说话。 日志就是事实。 于是我们一起查询了日志,最后的结果就更加奇怪了。 调用方确实只有一次调用日志。 但是我们接收方却收到了两次请求。 通过图片也能看出来,我们之间是通过 MQ 异步交互的。 所以,自然而然的就把目光放到 MQ 上。 我们使用的 MQ 是一个叫做 SofaMQ 的玩意,比较冷门,但是有蚂蚁金服背书。 在官方文档的“常见问题”部分,有这样的描述: 这句话你仔细品一下:可以保证消息不丢失,但是无法保证消息不重复。 言外之意是不是就是在说:为了保证消息不丢失,在我拿不准你到底有没有消费成功的情况下,我有可能针对的同一个消息再次发送。 再次发送,那不就是一个消息会被消费多次吗? 不就是我们遇到的这个问题吗? 然后我突然想起了一个曾经学过的东西:at least once。 在 MQTT 协议中,给出了三种传递消息时能够提供的服务质量标准,这三种服务质量从低到高依次是: 同时,在“消息幂等”部分,也特别进行了强调: https://help.aliyun.com/document_detail/146983.html 为了防止消息重复消费导致业务处理异常,有必要根据业务上的唯一 Key 对消息做幂等处理。 虽然我用的这个玩意是一个冷门的 MQ ,但是这个问题和具体使用的哪个 MQ 关系不大,常见的 RabbitM、RocketMQ、Kafka 都有类似的问题,都需要消费端做好幂等处理。 本文就基于这个问题,来讨论一下,在“消息可能重复消费”这个场景下,有没有啥好的解决方案。 前面说了,要处理消息重复消费的场景,最核心的逻辑是需要实现幂等机制。 幂等,这个概念大家应该是比较清晰了。 举个具体的例子。 比如在支付场景下,消费者消费扣款消息,对一笔订单执行扣款操作,扣款金额为 100 元。 如果因各种原因导致扣款消息重复投递,比如简单的一个场景,消费者接受到“扣款金额为 100 元”这个信息,完成消费,还没来得及告诉 MQ,“老哥,这个消息我已经收到了”,就重启了。 站在 MQ 的角度,没有收到回执,就代表这个消息并没有消费成功,基于“必须保证消息不丢失的指导思想”,它就会继续投递。 所以消费者会重复消费这个扣款消息。 但是,最终的业务结果是只扣款一次,扣费 100 元,且用户的扣款记录中对应的订单只有一条扣款流水,不会多次扣除费用。 那么这次扣款操作是符合要求的,整个消费过程实现了消费幂等。 在要求幂等的场景中,我们要找到一个抓手。 比如在这个案例里面,扣款一般来说都会对应一个业务上的唯一流水号,这个业务上的唯一流水号,就是抓手,我们可以基于这个流水号来做幂等。 最常规的方案就是在这个字段上加唯一索引,然后出现重复投递时,落库的时候会抛出主键冲突的异常。 不要觉得重复投递是一个小概率事件,就不上心了。我们敲代码的,不就是要多考虑这些正常流程之外的“小概率事件”吗,只写正常流程,谁都会写。 根据官方的说法,消息重复会发生在这些场景中: 还是顺着前面扣款的例子说。 收到消息之后,我们第一步一般来说是保存信息到数据库。 save(扣款信息); 现在我们要做幂等,已经找到了扣款唯一流水号这个抓手,那我们的代码应该怎么写呢? 先查询,再判断,最后保存。 这个方案,在一般的情况下,能达到幂等的效果。 但是,由于是三步,在并发场景下,立马就扛不住了。 而且,消息重复投递的场景,本来就是在极短的时间内产生的两条信息。 所以,上面这个方案会出现什么场景呢? 两个请求,在 select(扣款唯一流水号) 的时候都没有查询到数据,击穿了校验逻辑,然后两个请求就都会去落库。 这个时候怎么办呢? 很简单,前面说了,在扣款唯一流水号上加唯一索引,即使两个请求都去落库,但是由于有唯一索引,一定只会落一笔数据到数据库。 另外一个怎么办? 抛出唯一索引冲突的异常,在程序里面通过捕获这个异常来控制流程上的后续运转。 这个方案,很常见,很常用,实话实说我们用的就是这个方案。 但是既然已经有唯一索引了,那是不是前面的 select 都显得没啥卵用了? 我们要从辩证的角度去看待这个问题。 所以,是,也不是。 是的原因是因为前面这一层 select 相当于过滤层,能在一些非并发的场景下让程序不抛出唯一索引冲突的异常,显得更加优雅。 不是的原因是因为优雅的程度还不够高,毕竟是通过“异常”来控制了程序的走向。 有没有不抛出异常的方案呢? 也有,也很简单,上锁就行了: 扣款信息 = select(扣款唯一流水号);//select *** for update 这样确实能保证不抛出唯一索引冲突的异常,但是关键是一旦涉及到上锁,性能就拉胯了,为了解决这个偶发的问题,牺牲了接口的性能,这个路线就走的有点远了。 所以,上锁也不够优雅。 什么是真正的优雅? 我也不知道,但是我试图去思考一个相对优雅的方案。 首先,我觉得上面的方案,不管是唯一索引,还是上锁,不够优雅的原因是因为,它们都是在基于业务表搞事情。 业务表干得事儿,应该就是业务上的事儿。 那我问你:消息重复投递,需要保持幂等,这个属于业务上的事儿吗? 我认为是不属于的,这是属于技术上的事情,任何业务都是可能遇到的。只不过,在前面的方案里面,我们想借用业务表的能力,来帮我们做一个它可以做,但是本来不该它做的事情。 首先,我们必须要在这一点上达成一致,不然后面的论述就不能展开了。 如果你不这样认为,那么你可以不用往下看。 我想到的方案是什么呢? 我相信你听过这样一句话:计算机领域中的所有问题都可以通过增加一个中间层来解决。 所以,我也想着抽一层。 我还是需要数据库通过唯一索引来帮我保证只有一条数据被成功落库,所以我想着抽一个专门的表出来,比如叫做消息消费记录表。 只要数据插入了这个表,就代表消息被消费了。后续即使重发,也不会插入成功。 那么怎么来保证这个机制呢? 前面提到的抓手又可以用上了:业务唯一流水号。 这个消息消费记录表里面最重要的一个字段,可以叫做“消息唯一标识”,并且作为唯一索引。 这里的这个“消息唯一标识”就是对应业务唯一流水号。 如果你要基于这个表来实现消息幂等,那么你必须具备这样的一个业务唯一流水号,当重复的时候,还是会抛出主键冲突异常。 我知道着听起来就像是脱裤子放屁。 但是,你想想,这个表是完全脱离于业务的存在。 在前面的解决方案中,你要问别人,你有没有一张业务表来做这个事情。 在现在的方案中,你会给别人说,我这里有一个解决方案,你只需要执行我给你的 SQL,生成一张消息消费记录表就行。 这张表是完全独立于业务的存在,它只是为了解决消息重复投递这个共性问题。 从你问别人要,到别人按照你说的做,就这么轻轻的抽一小层,攻守易形了啊,朋友。 它是一种通用的解决方案,一种策略,甚至可以叫做一个框架。 现在,我们可以给它取一个新的名字。 比如:一种基于数据库唯一索引实现消息幂等的解决方案。 或者:一种分布式系统中数据唯一性的保障策略。 再或者:一个由数据库约束驱动的消息幂等保护性框架。 好,现在我们有了这么一个“高大上”的通用解决方案了。 到底怎么用呢? 名字很厉害,但是用起来其实也就那么回事儿。 回到前面转账的例子,很简单: 这样,消息防重,由消息消费记录表来保证。 业务表,不感知“消息是否重复”的场景。 看起来似乎是优雅了那么一点点。 但是,同时带来了另外一个问题。 又回到了之前“先校验,再保持”的非原子性的逻辑。 我们想想一个极端场景,如果保存数据到消息消费记录表成功,还没来得及 save(扣款信息) ,服务重启了,怎么办? 其实换句话说,这两个信息需要保持一致性。 所以可以加入事务嘛,把这两步绑定到一起: 这样,如果保存数据到消息消费记录表成功,还没来得及 save(扣款信息) ,服务重启,事务回滚,消息消费记录表就不会真的插入成功。 而 MQ 没有收到这个消息的回执,也会再次进行投递。 由于消息消费记录表里没有这个数据,所以会再次进行消费。 在上面的这个过程中,MQ 再次投递,是为了 at least once。 而我们引入了消息消费记录表,通过唯一索引来保证不重复消费,这个玩意加上 at least once,在业界有另外一个叫法:
exactly-only。 现在,我们通过引入事务来解决了“非原子性”的问题,但是又带来另外一个问题:事务。 一般来说,大家都是能不使用事务的地方就尽量不使用事务,通过最终一致性来保证数据的完整性。 那现在有没有不基于事务的解决方案呢? 我想到的是可以在消息消费记录表里面再引入一个“状态字段”,这个字段有三个取值:未消费、消费中、消费完成。 通过维护状态的流转,来代替事务的逻辑。 这个思路来源于我实习的时候,给老师做外包项目。当时我是真的不知道 Spring 的事务怎么用,但是我知道结合当时我开发的业务场景,一个数据的状态很重要,处理之前把数据的状态修改了,但是如果出了异常,应该把状态给它恢复回去。 于是我手动写了这样的一坨代码,四处散落在我写的模块里面。 后来一个师兄看了我的代码,提出了应该用事务来保证这样的逻辑,并给我做了演示,我才去了解了事务相关的东西。 但是有一说一,我后来也思考了,在我那个特定的业务场景下,通过状态的流转,确实是可以代替事务的存在的。 好,回到我们现在的这个场景中。 一个消息过来的时候,首先根据唯一消息标识获取对应的数据。 如果没有获取到,就初始化为“未消费”状态落库,然后去执行具体的业务逻辑。在业务逻辑执行之前,把状态修改为“消费中”,然后在执行完成之后,把状态修改为“消费完成”。 如果这个消息被重新投递了,那么根据唯一消息标识就能获取到对应的数据,接着检查这个消息的状态。如果是“消费完成”,直接就丢掉。 但是上面的描述只是描述了最简单的场景,一些复杂场景下状态的流转和判断应该怎么做,我确实还没想好。 所以就当是个课后习题吧,你去推一推,看看用状态流转代替事务的方式是否能成功落地。 学会了记得回来教我。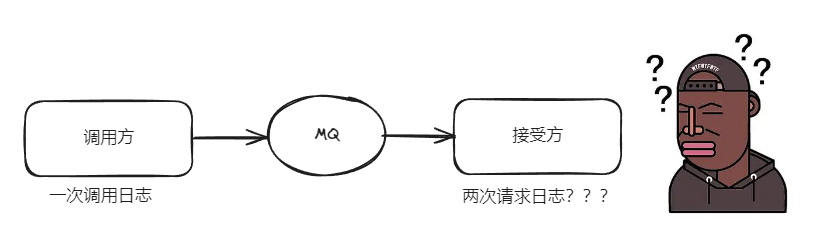


举个例子

搞搞具体方案
扣款信息 = select(扣款唯一流水号);
if(扣款信息 == null){
save(扣款信息);
}

思考一波

if(保存数据到消息消费记录表){//出现主键冲突就返回false
save(扣款信息);
}开启事务;
if(保存数据到消息消费记录表){//出现主键冲突就返回false
save(扣款信息);
}
提交事务;