这是微软再5月刚刚发布的一篇论文提出了一种解码器-解码器架构YOCO,因为只缓存一次KV对,所以可以大量的节省内存。
以前的模型都是通过缓存先前计算的键/值向量,可以在当前生成步骤中重用它们。键值(KV)缓存避免了对每个词元再次编码的过程,这样可以大大提高了推理速度。
但是随着词元数量的增加,KV缓存占用了大量GPU内存,使得大型语言模型的推理受到内存限制。所以论文的作者改进了这一架构:
YOCO是为自回归建模而设计的,例如大型语言模型(llm)。所提出的解码器-解码器架构有两部分,即自解码器和交叉解码器,如下图所示
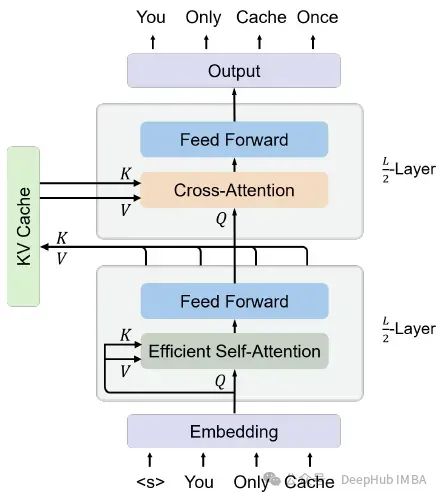
https://avoid.overfit.cn/post/90e0bd170644476cbccabb039e7105ae
标签:缓存,架构,YOCO,Cache,解码器,KV,Decoder From: https://www.cnblogs.com/deephub/p/18187624