Supervised Machine Learning Regression and Classification
第一周
1.1 机器学习定义
1.2 监督学习

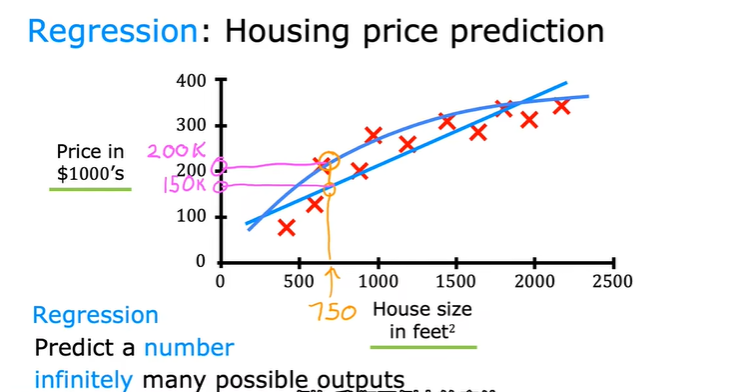
1.2.1回归
在输入输出学习后,然后输入一个没有见过的x输出相应的y
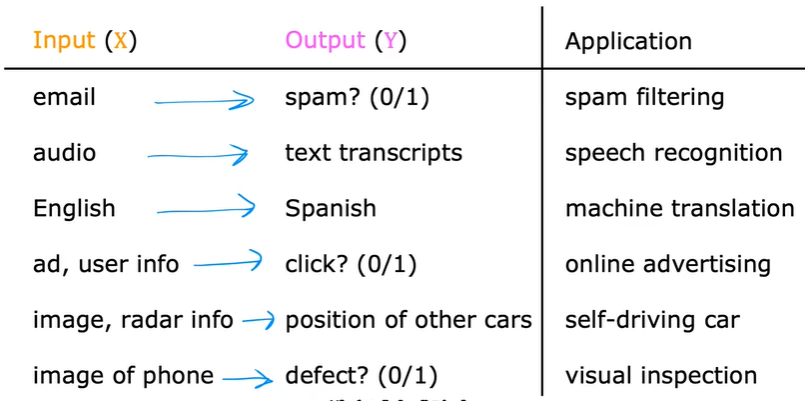
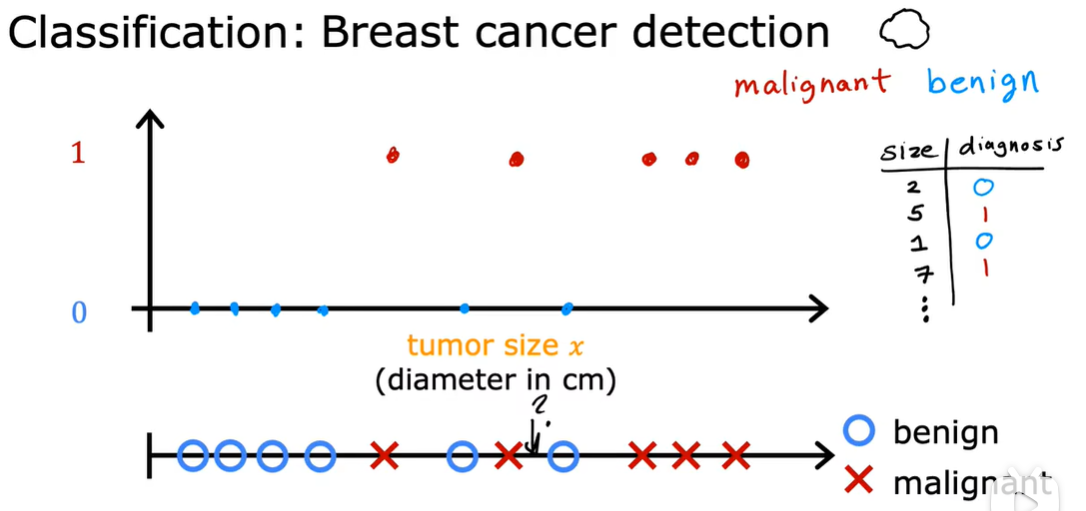
1.2.2 classification
有多个输出
1.3 无监督学习
数据仅仅带有输入x,但不输出标签y,算法需要找到数据中的某种结构。
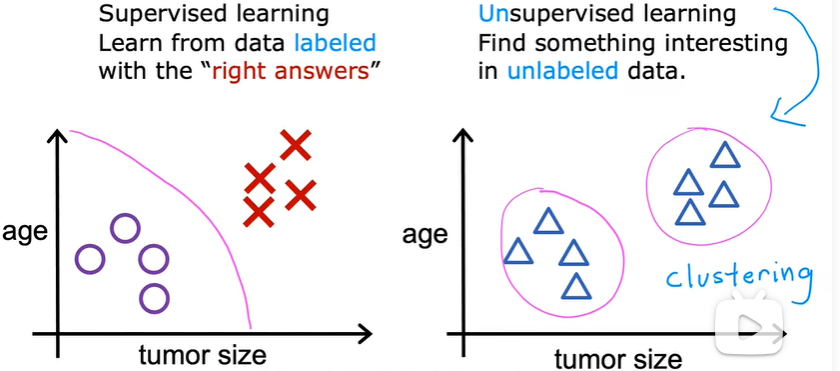
clustering:将相似的数据点组合在一起
anomaly detection:用于检测异常事件
dimensionality reduction:降维 可以压缩大数据集
2.1 线性回归模型
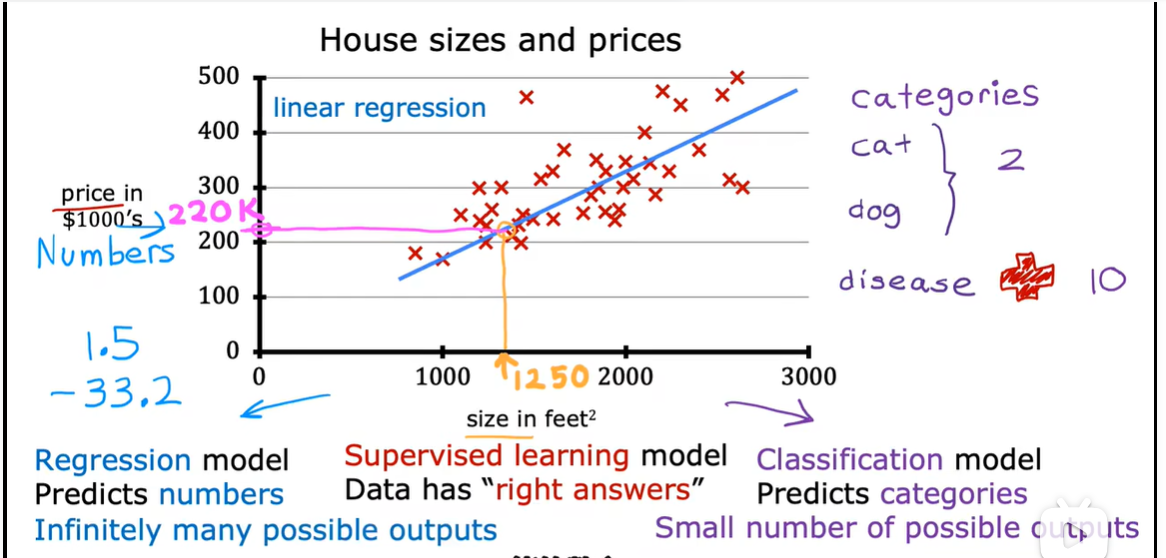

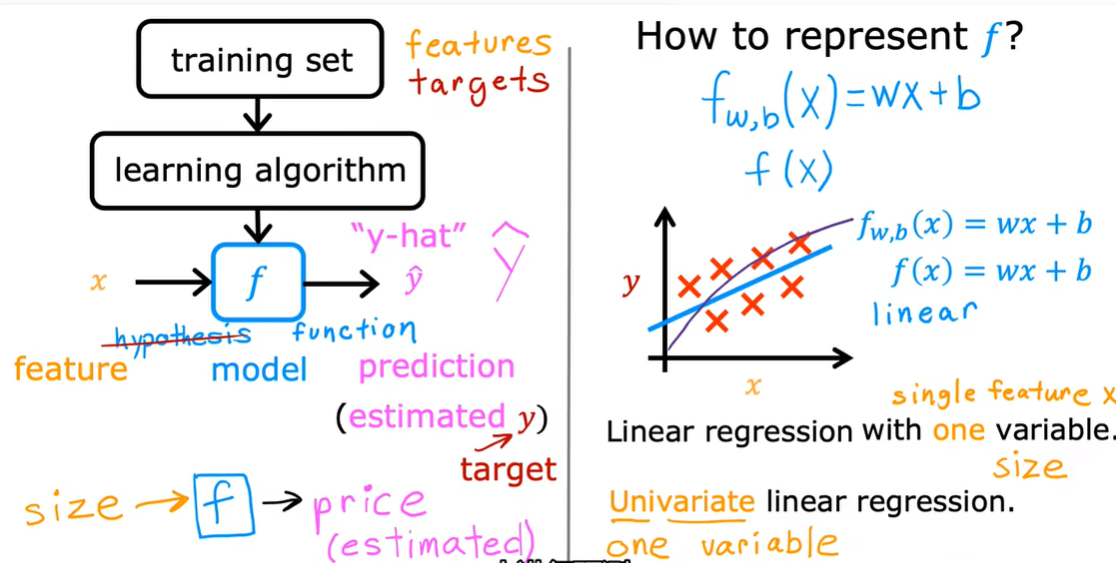
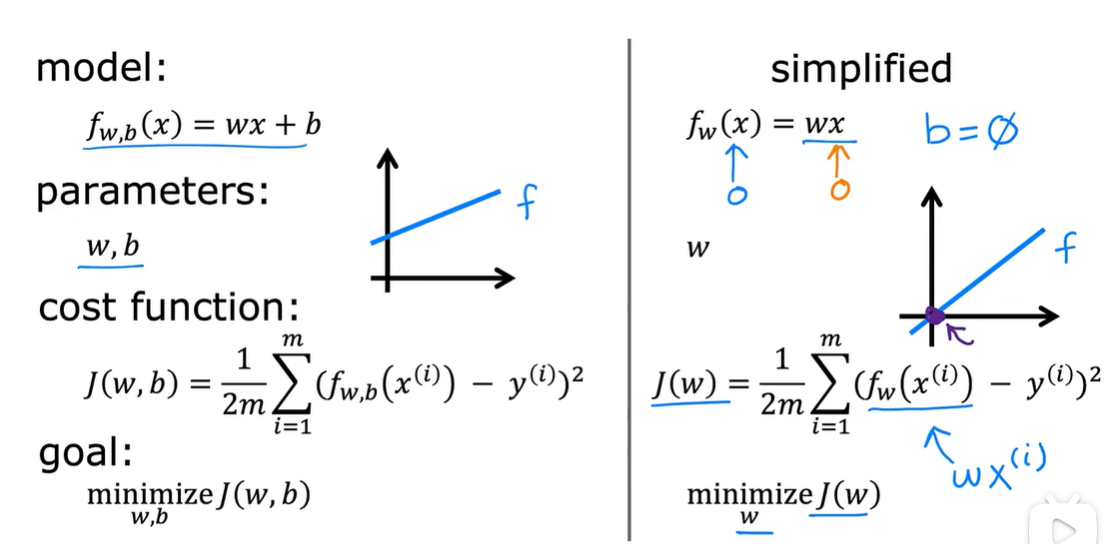
2.2 代价函数公式

2.3 理解代价函数
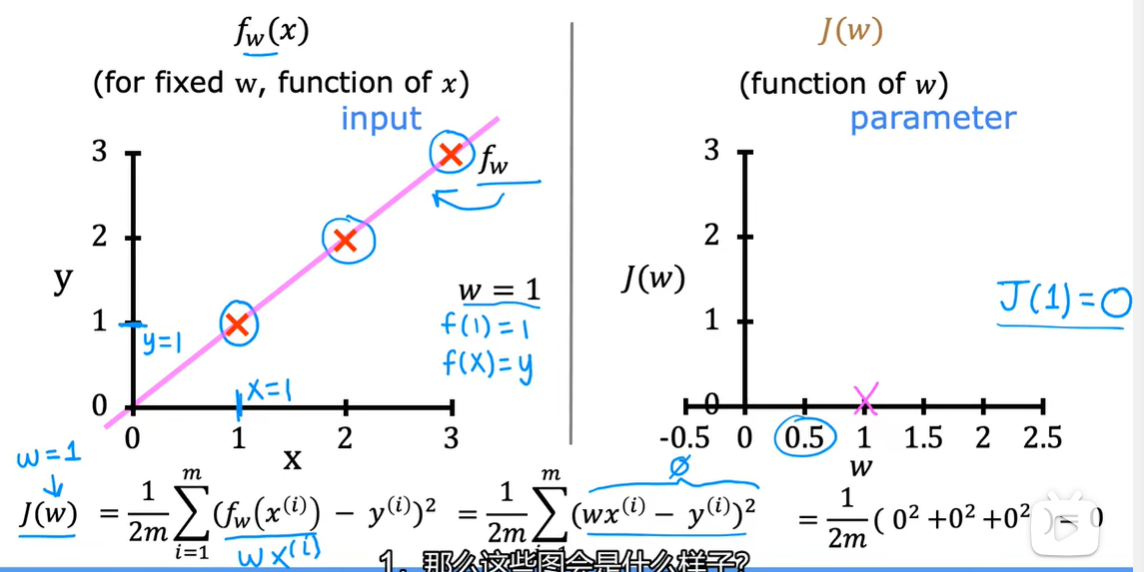
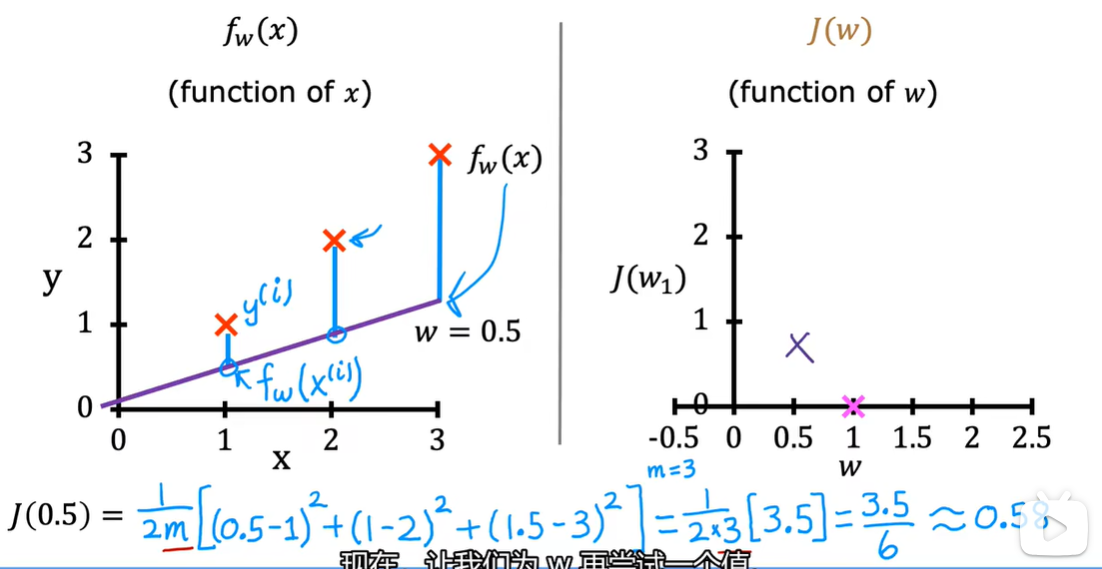
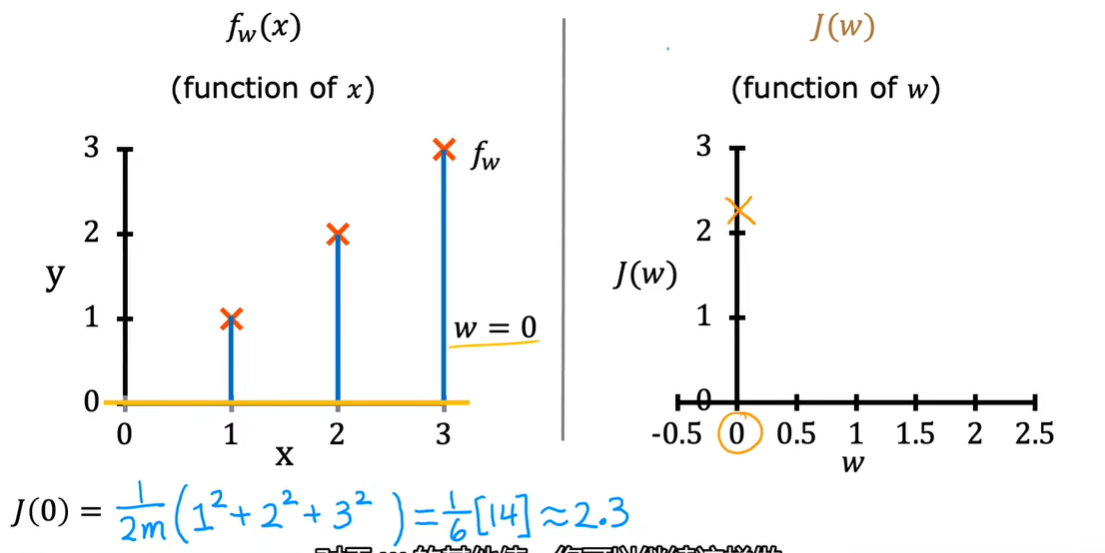
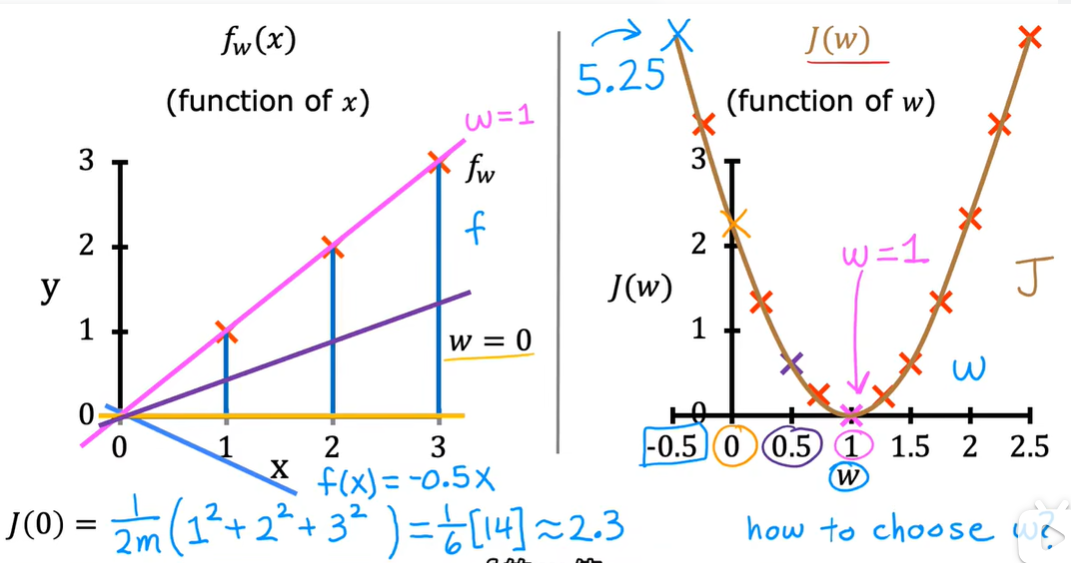
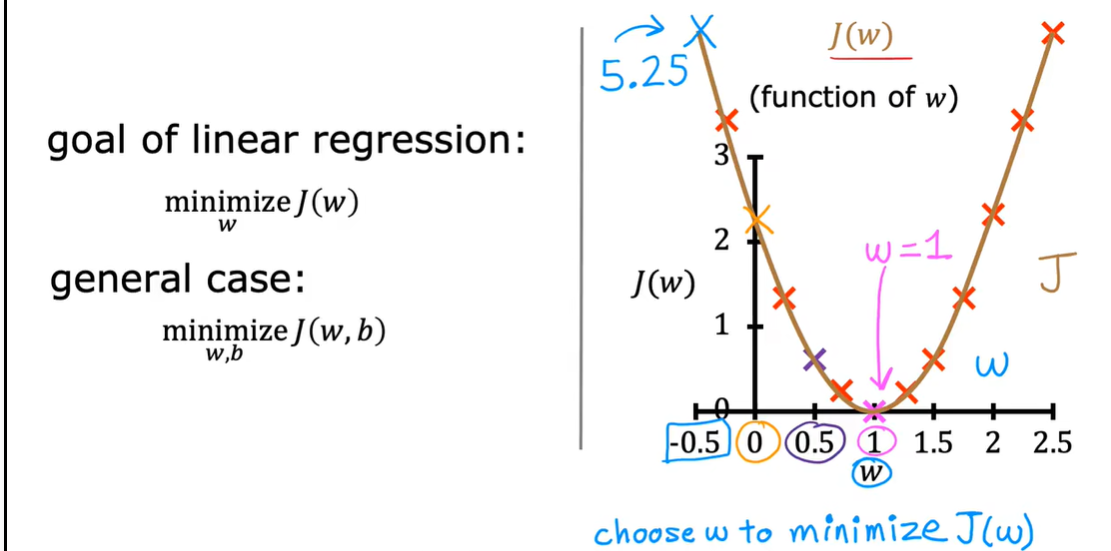
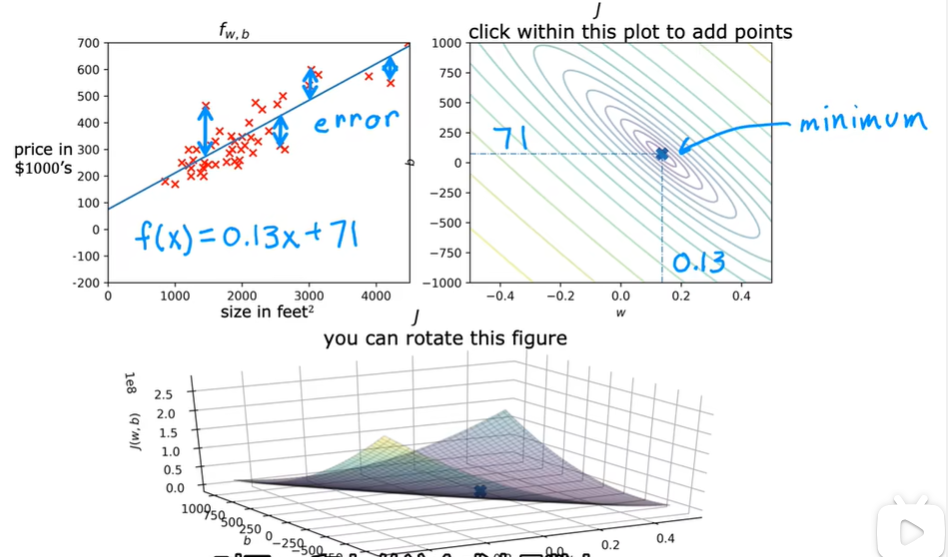
2.4 代价函数可视化
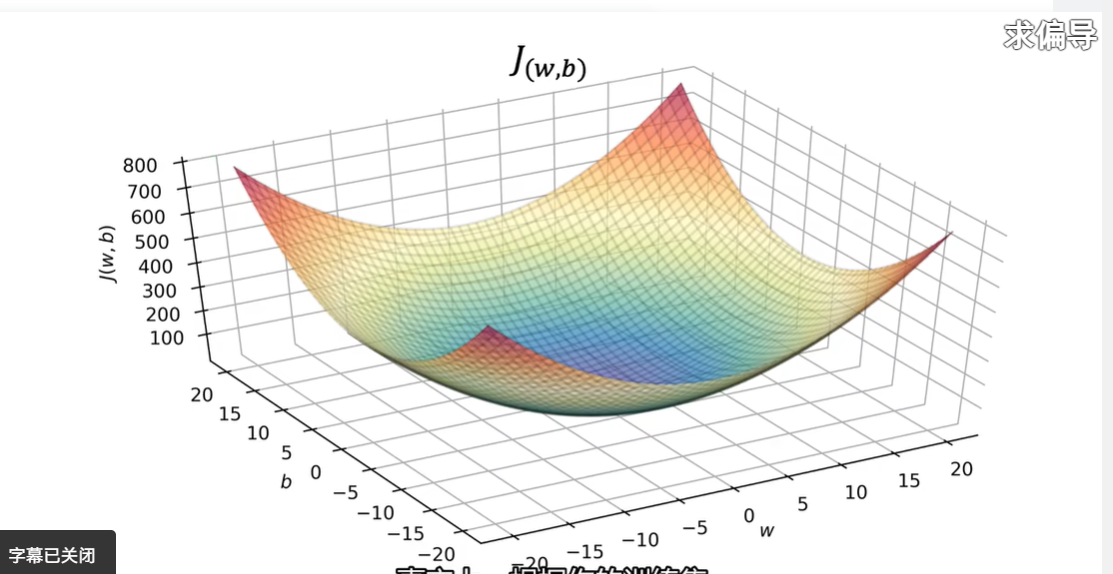
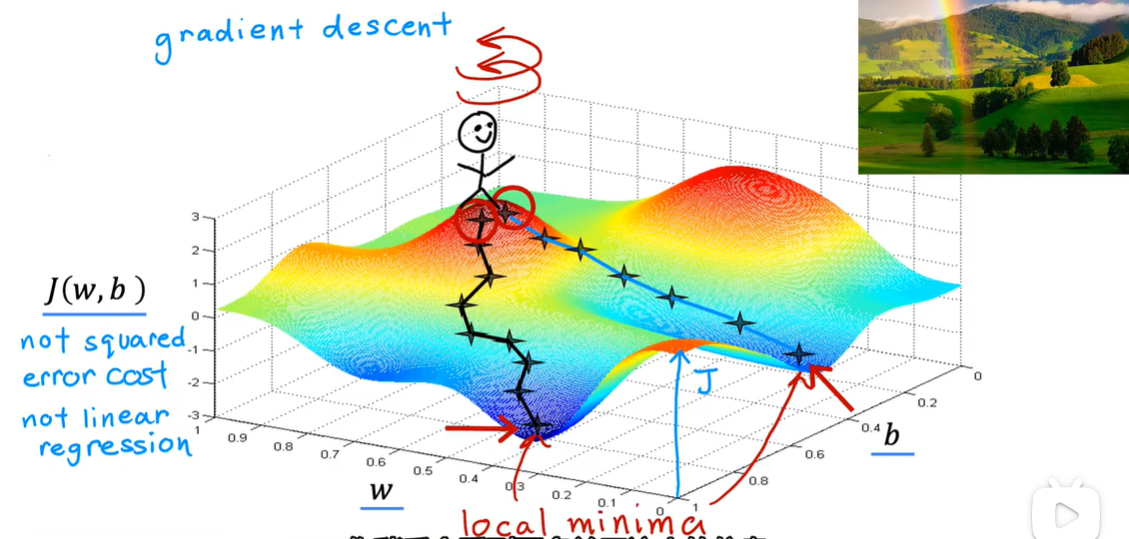
3.1 梯度下降
最小化成本函数j

3.2梯度下降的实现
α成为learning rate
如果非常大的话,表示一个非常激进的梯度下降过程

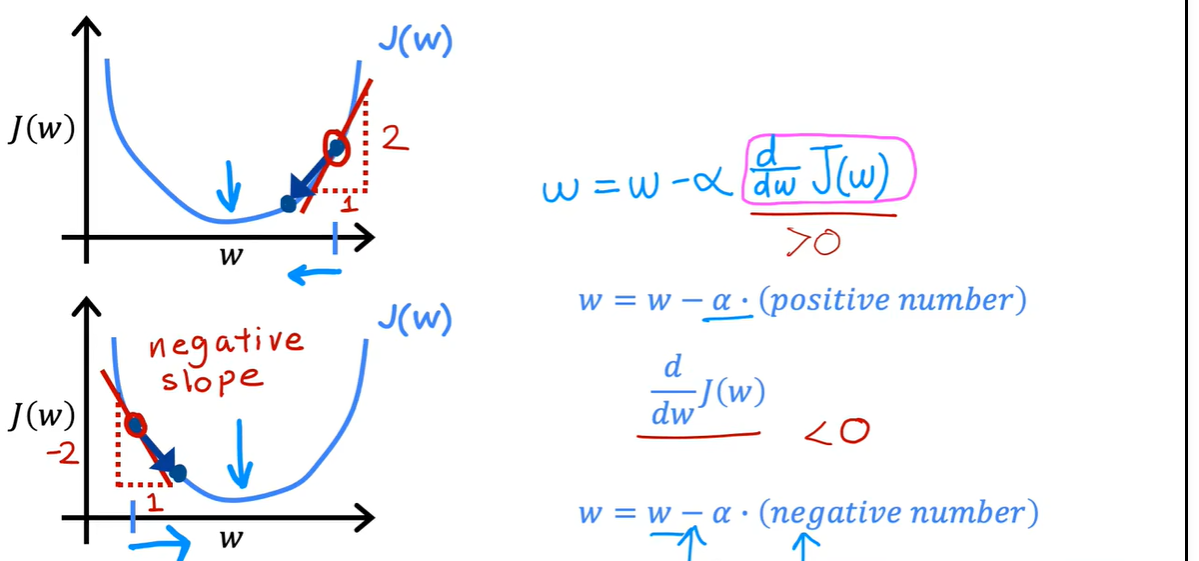
3.3 学习率
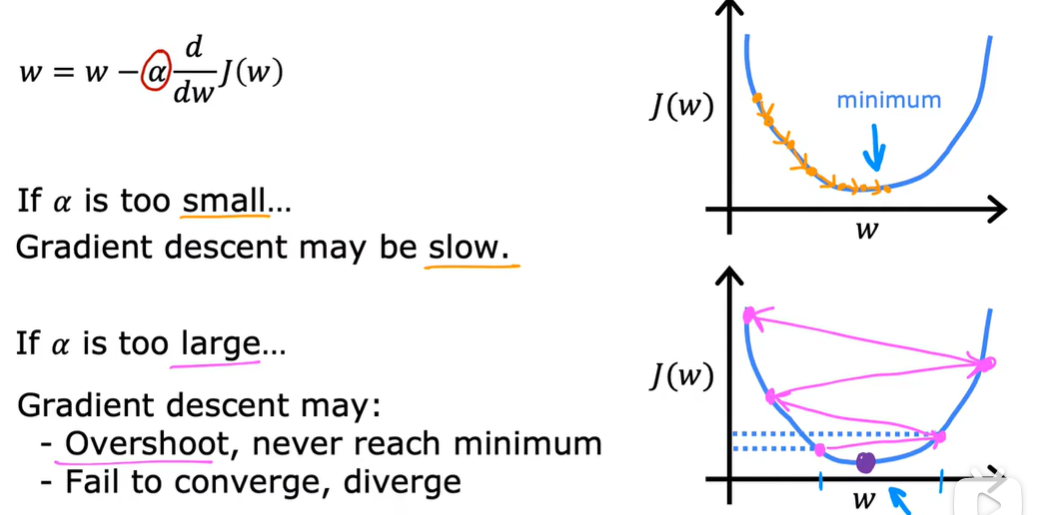
到达了最小值之后,这个导数变为0,不会更改,保持这个结果。
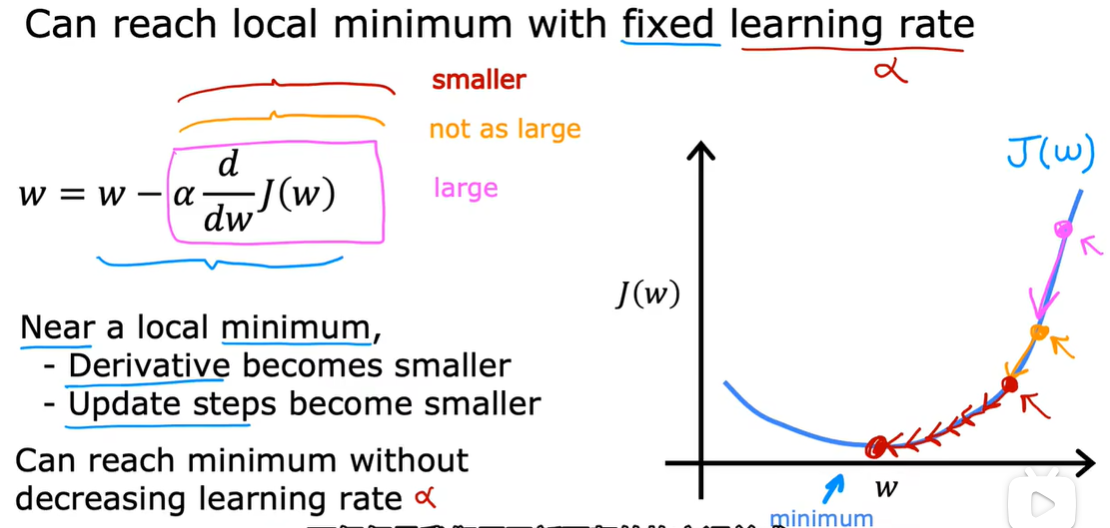
3.4 用于线性回归的梯度下降
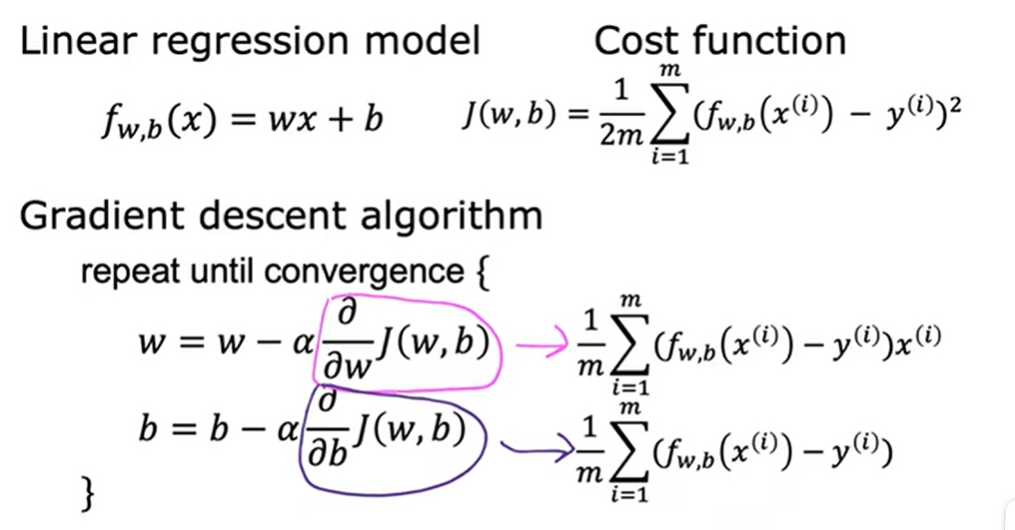
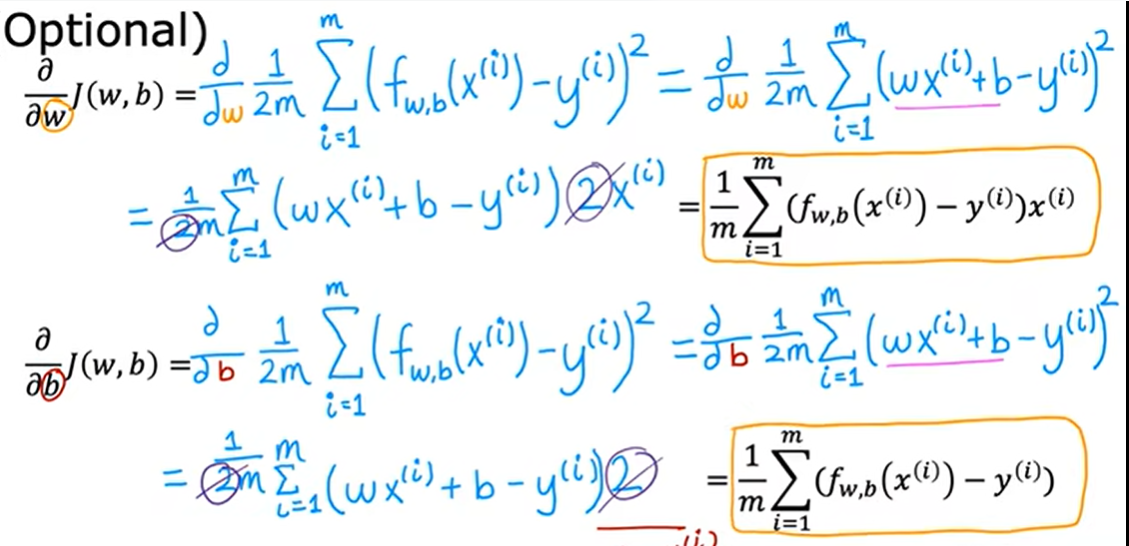

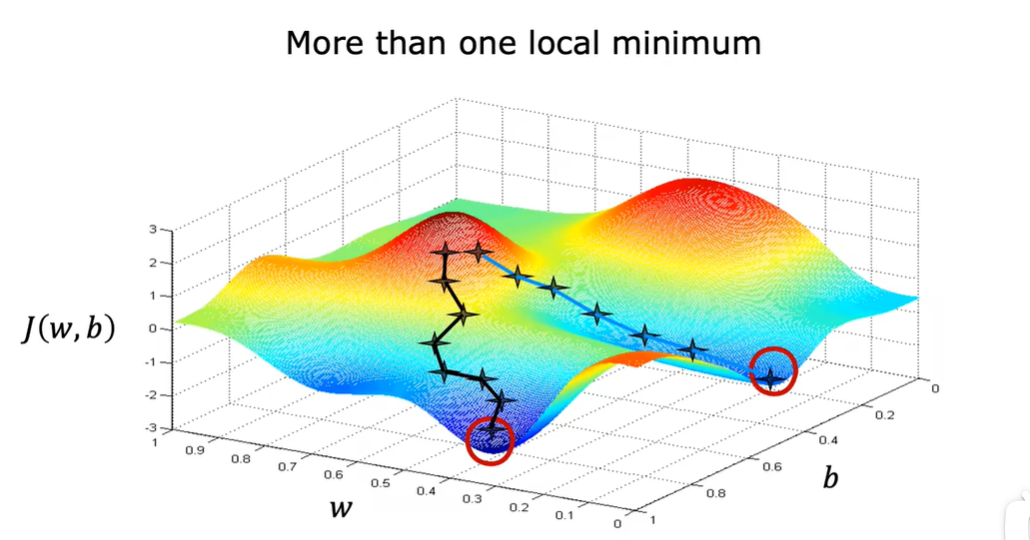
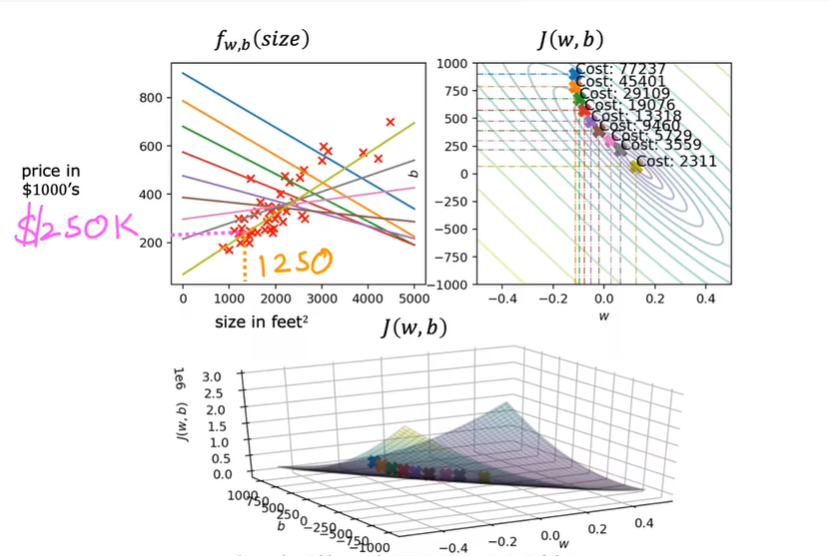

第二周
1.1 多维特征
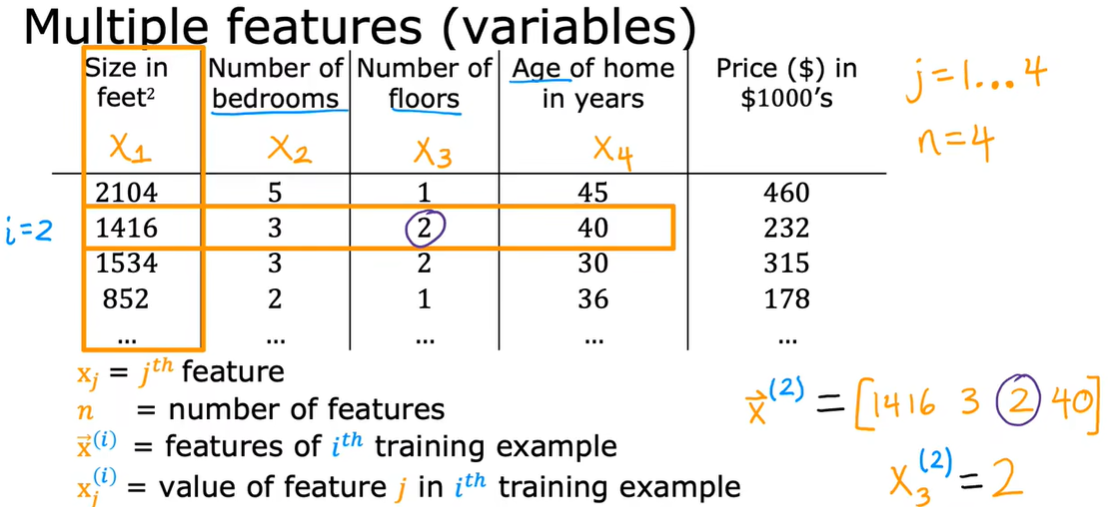
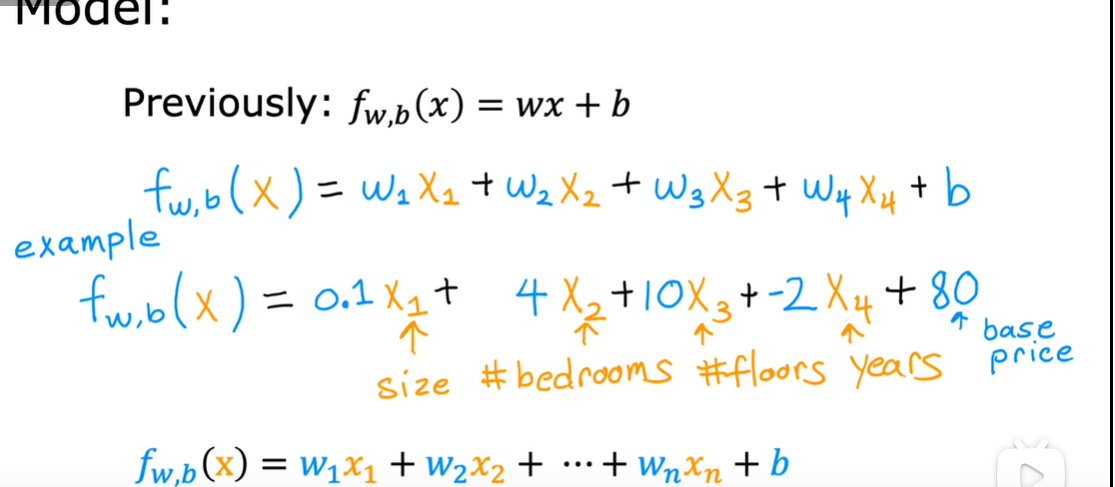
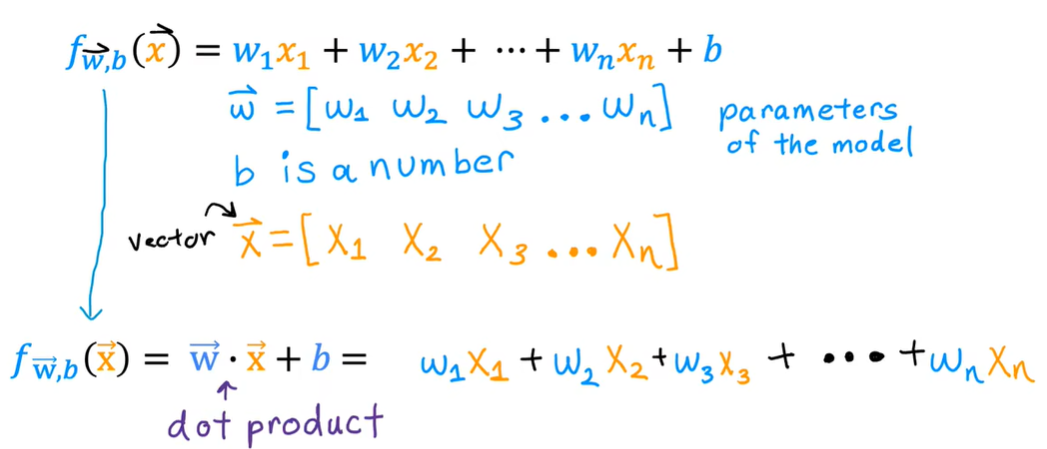
1.2向量化


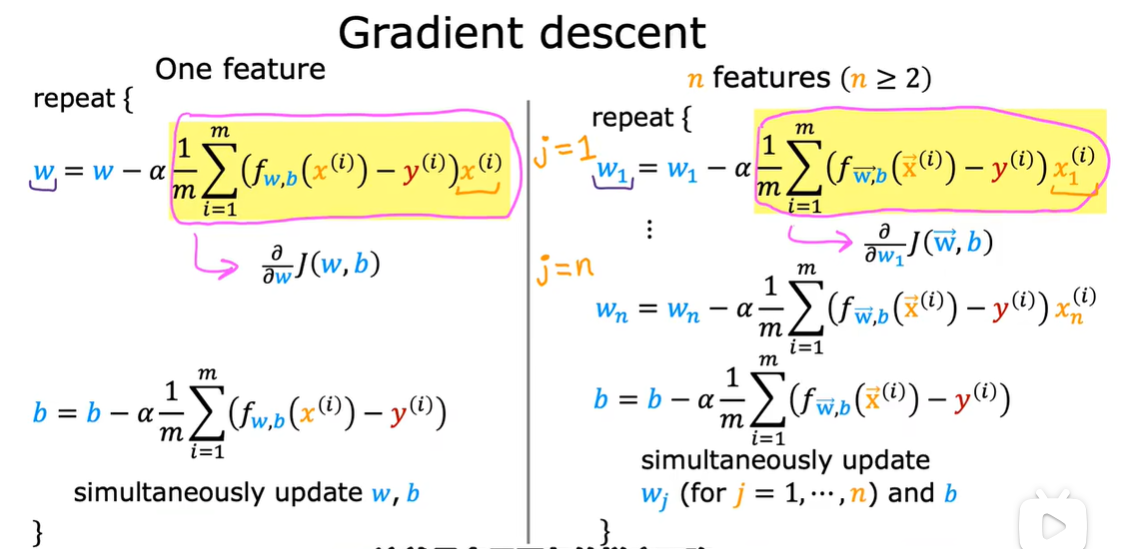
1.3 用于多元线性回归的梯度下降法

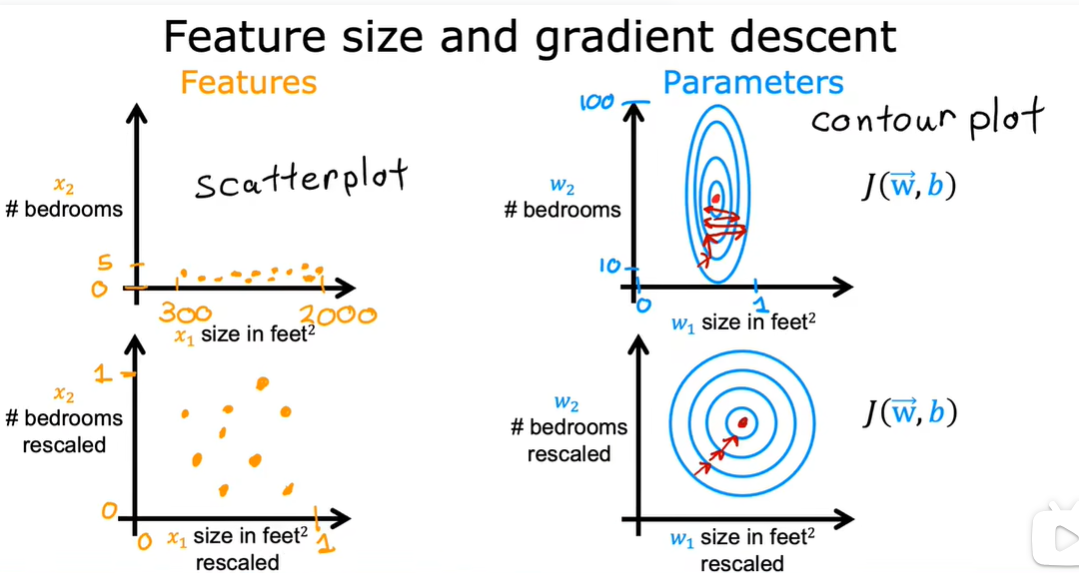
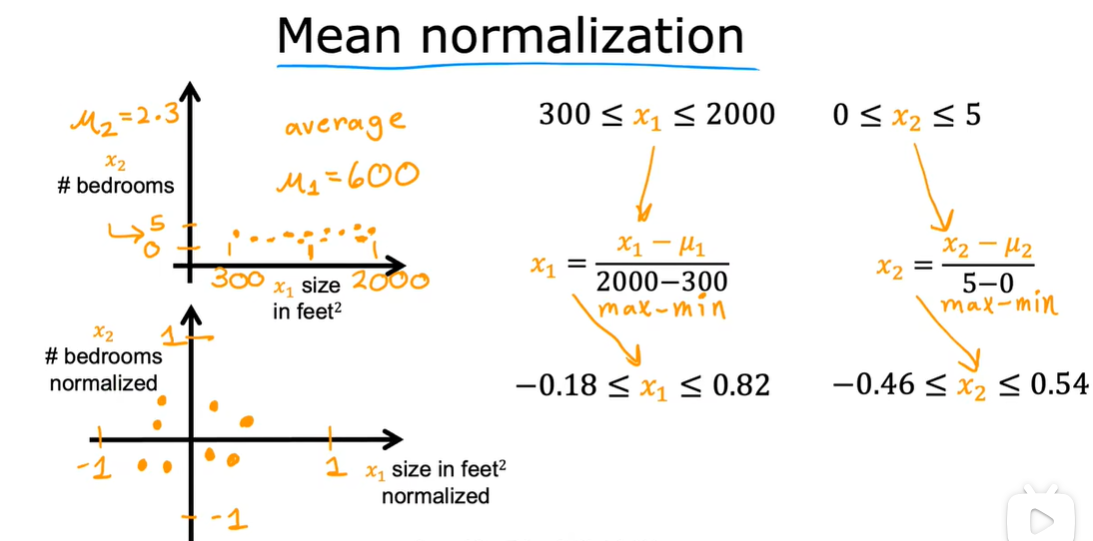
2.1 特征缩放

对训练数据进行处理,关键是重新标度x1和x2


2.2 判断梯度下降是否收敛

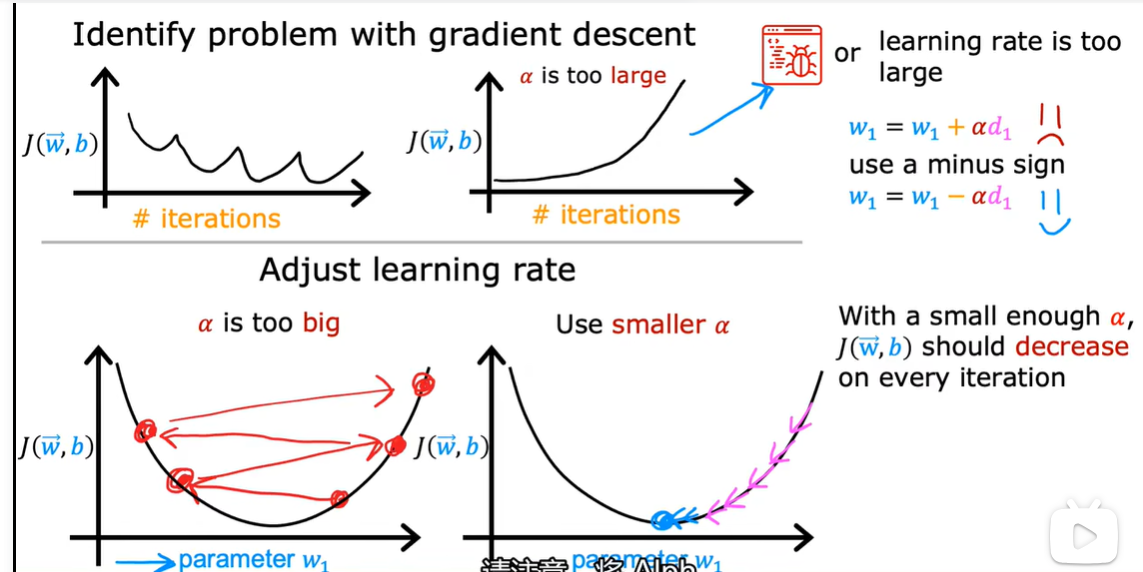
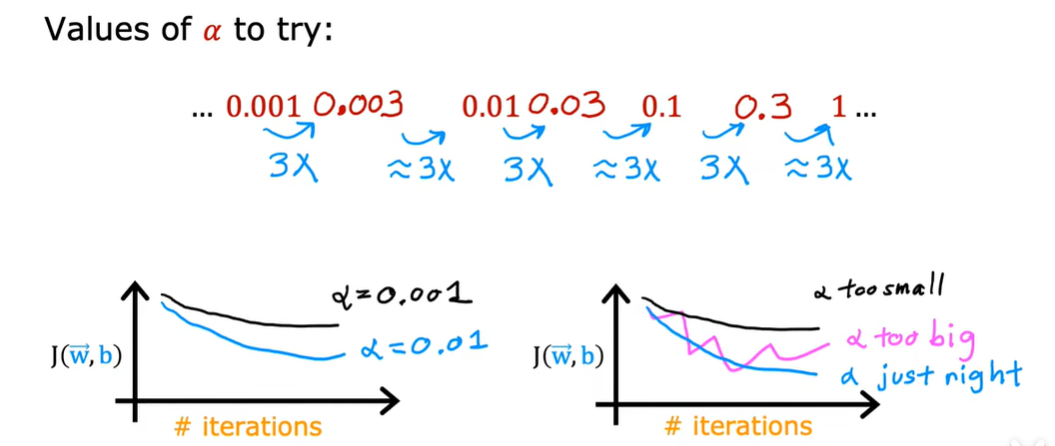
2.3 如何设置学习率
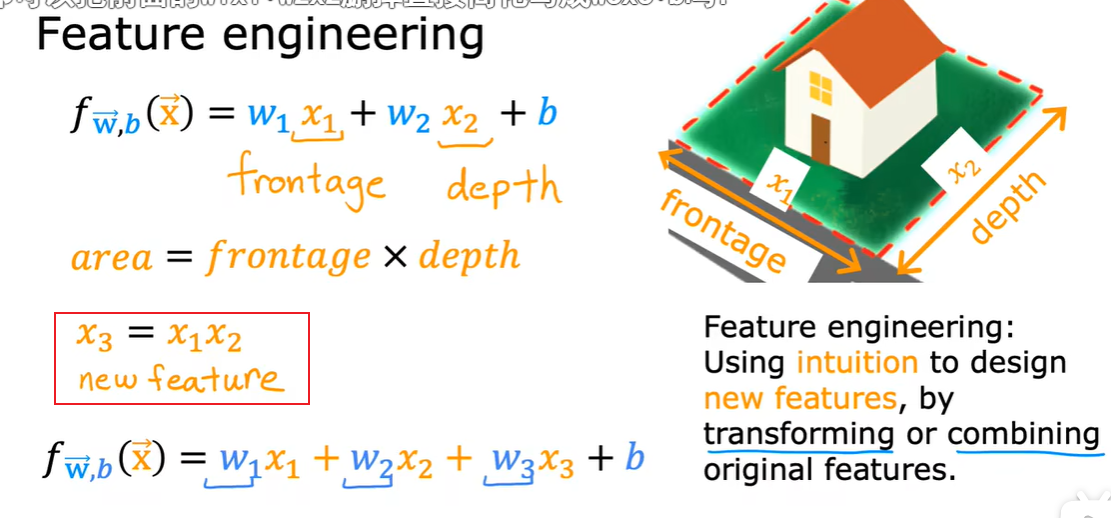
2.4 特征工程
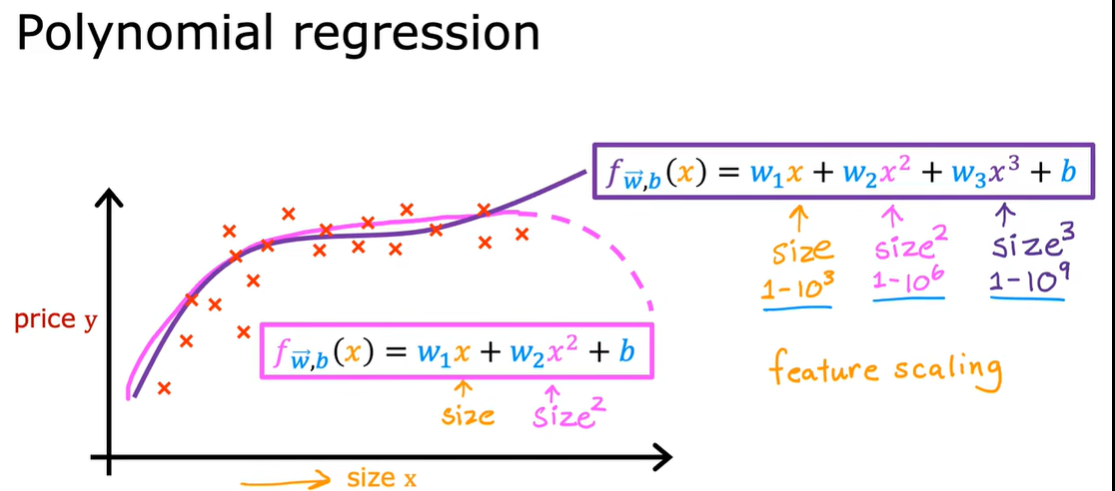
2.5 多项式回归
第三周
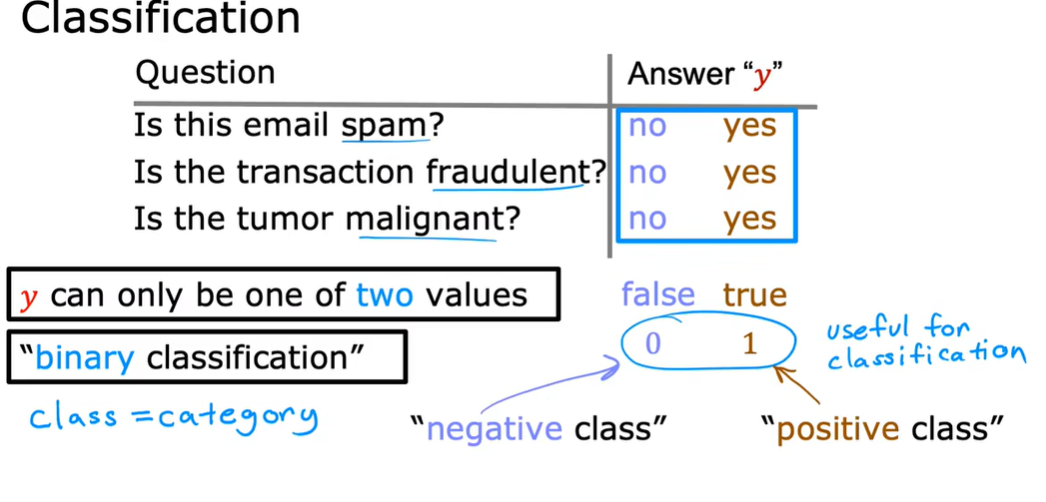
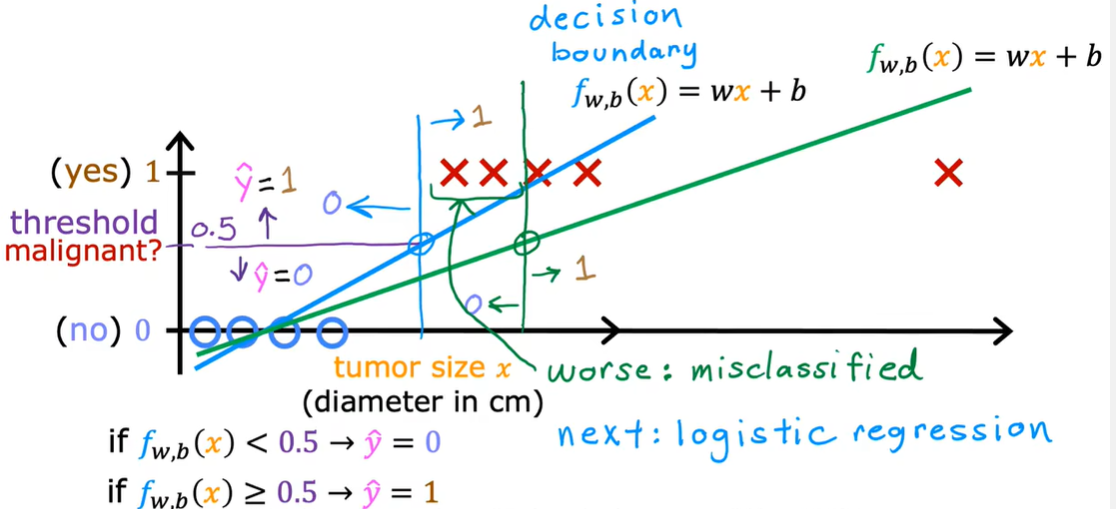
1.1 logistic regression
可用作classification ,实际上是用作解决输出标签
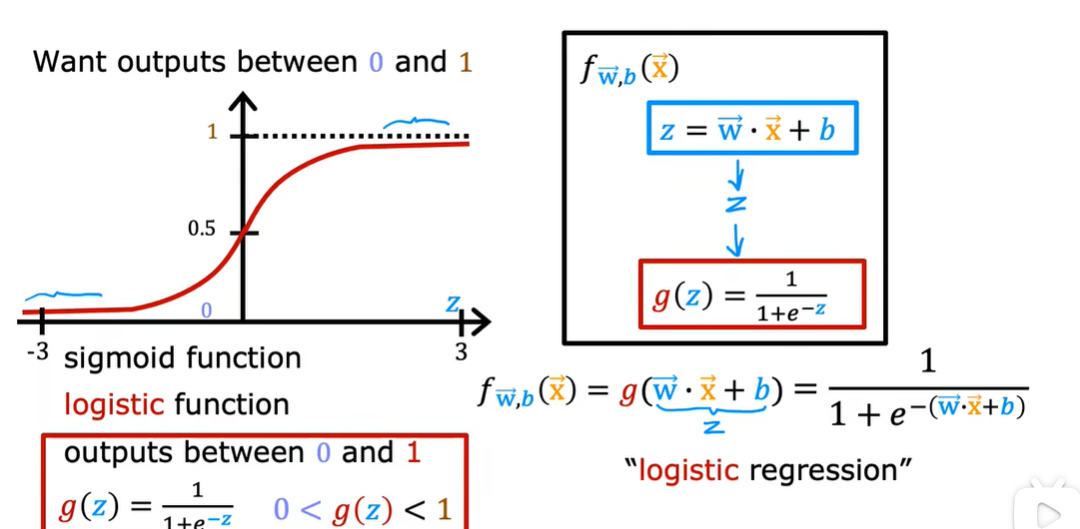

1.2 决策边界

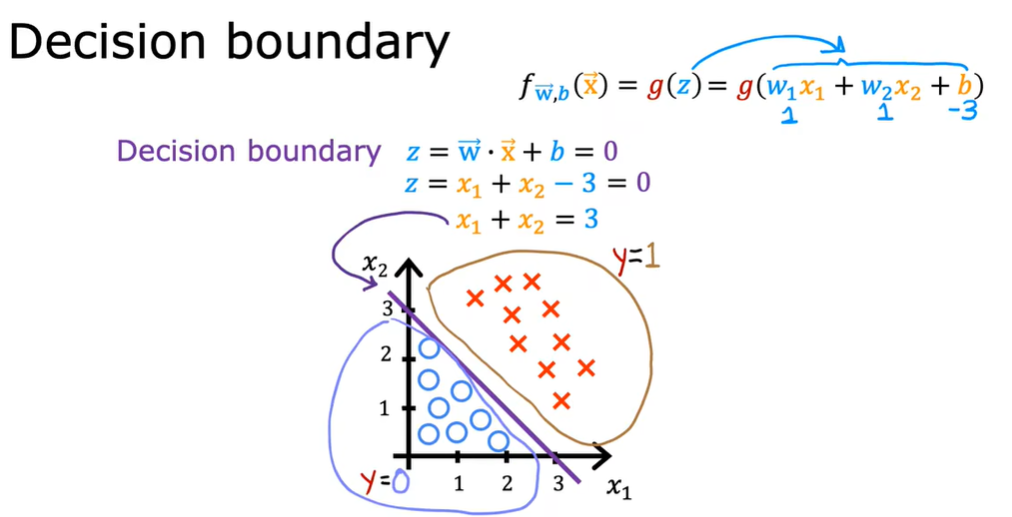

叉号表示y类等于1,小圆圈表示y类等于0

1.3 逻辑回归中的代价函数
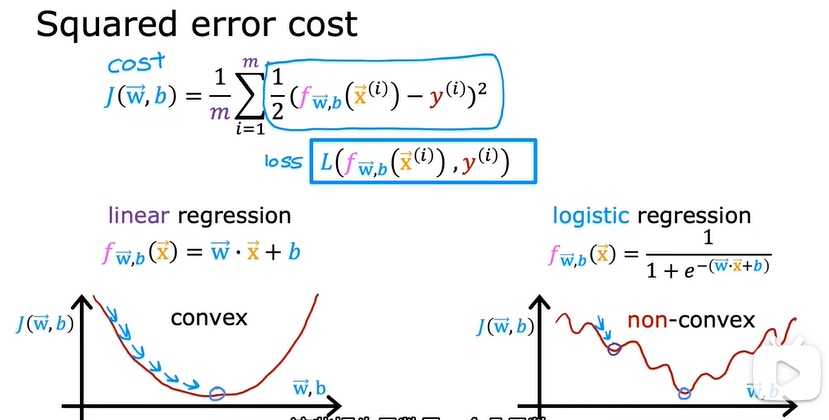
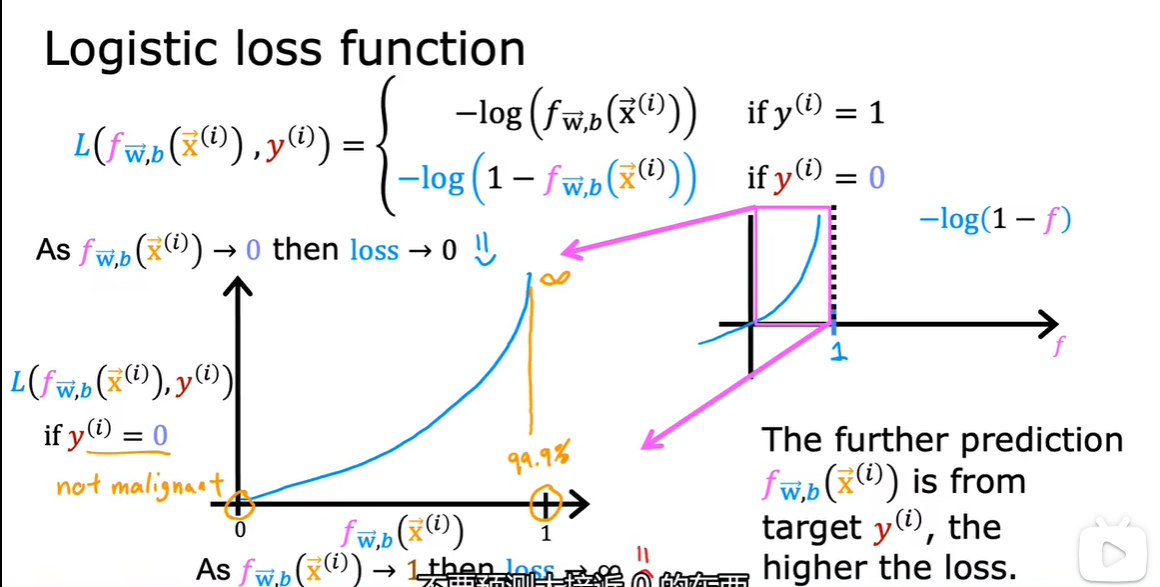
平方误差成本函数不适用于逻辑回归
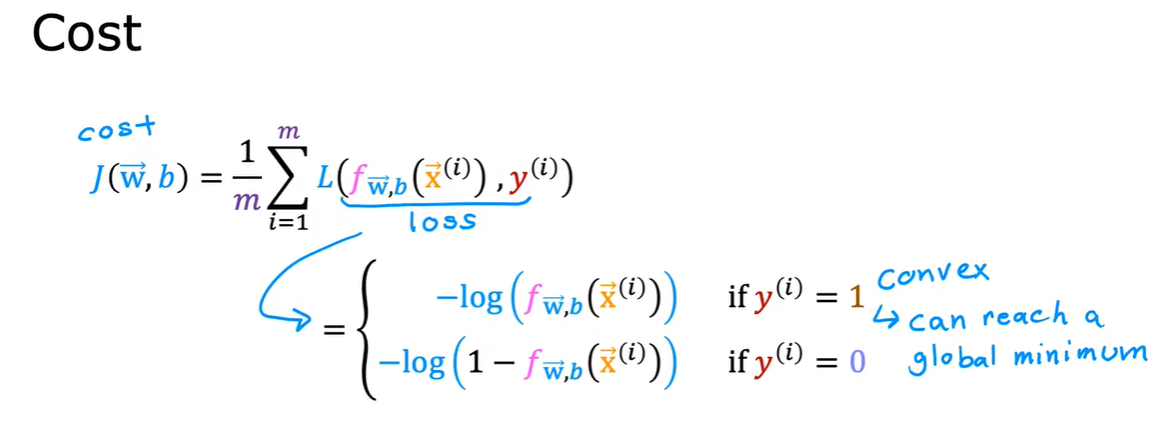
1.4 简化逻辑回归代价函数


1.5 实现梯度下降
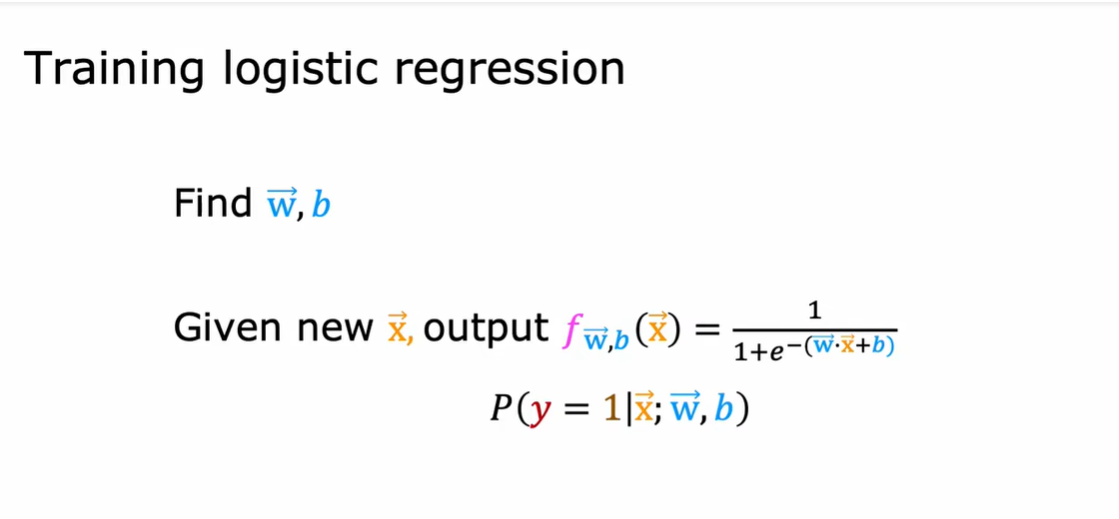

线性回归与逻辑回归
1.6 过拟合问题 overfitting
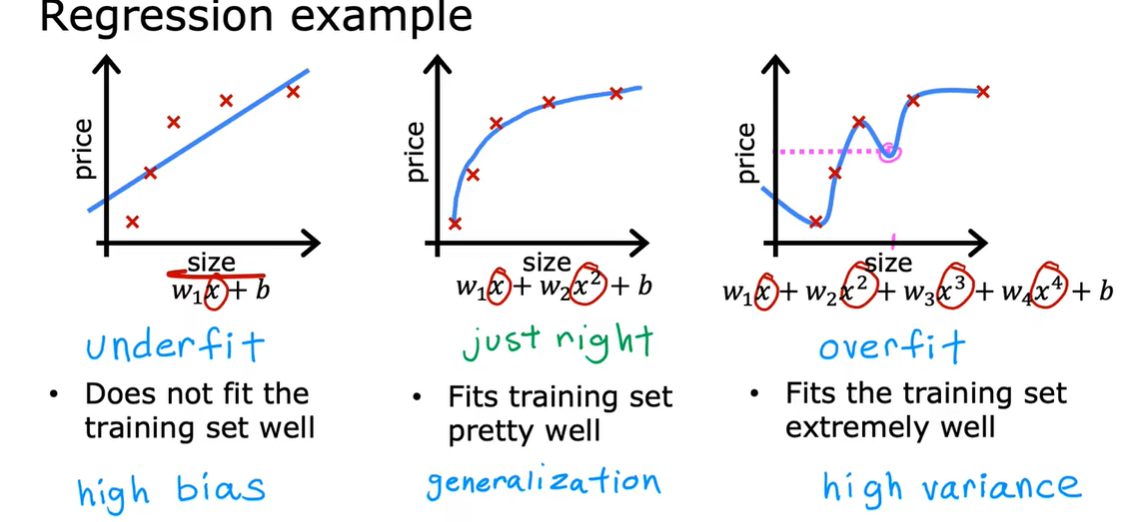
generalization 泛化 准确预测出从来没有见过的案例的能力
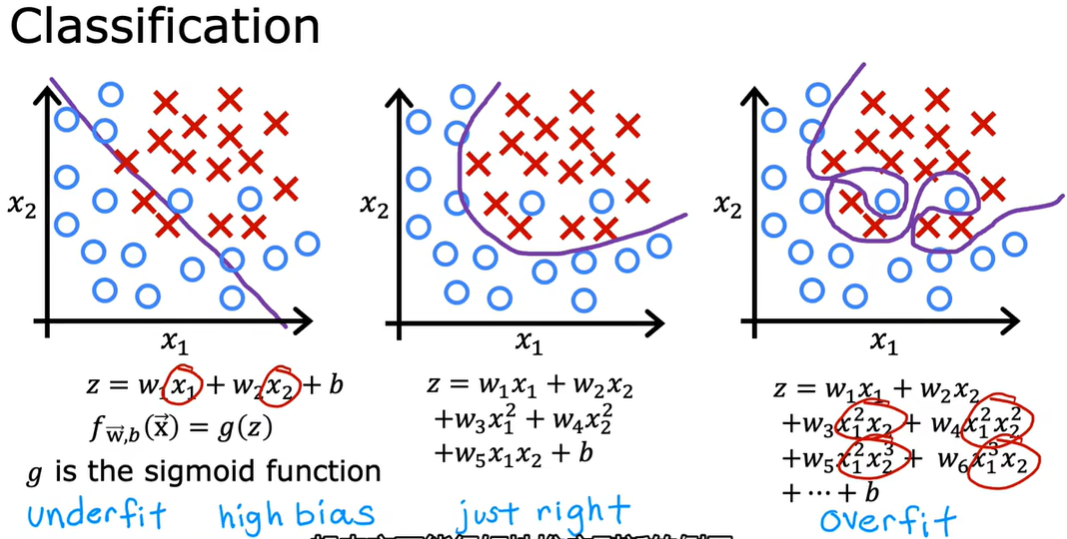
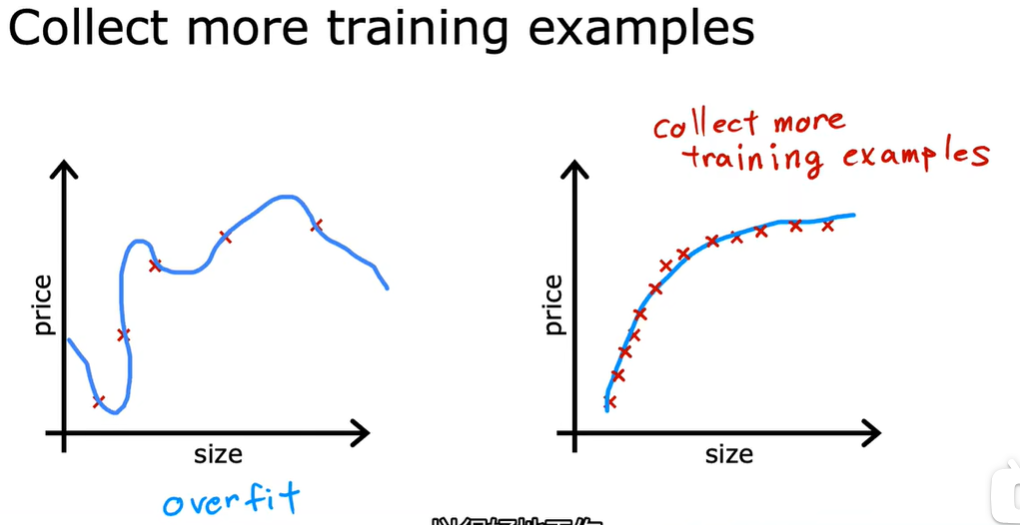
1.7 解决过拟合问题
收集更多的训练数据
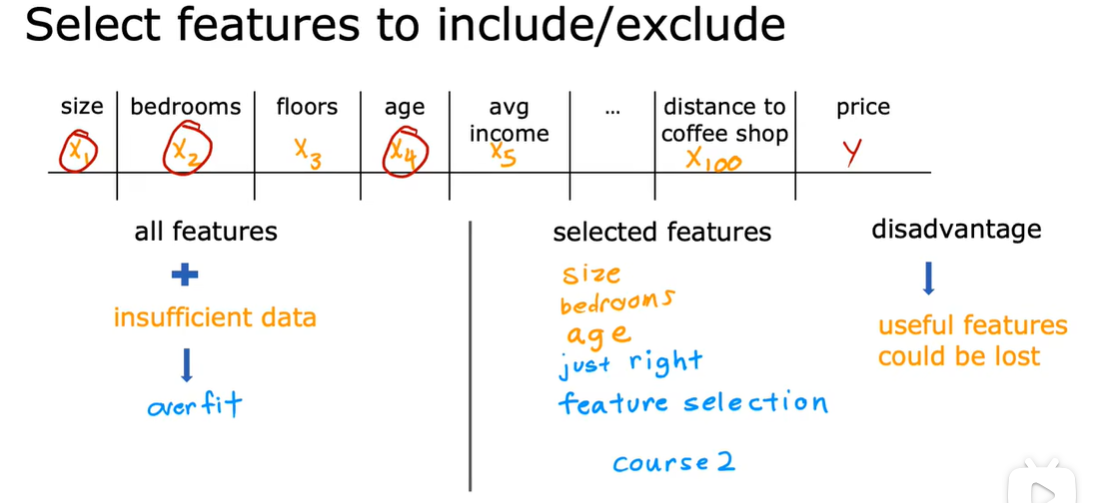
特征选择
正则化:缩小参数而不必将参数设置为0
可以保留所有的特征
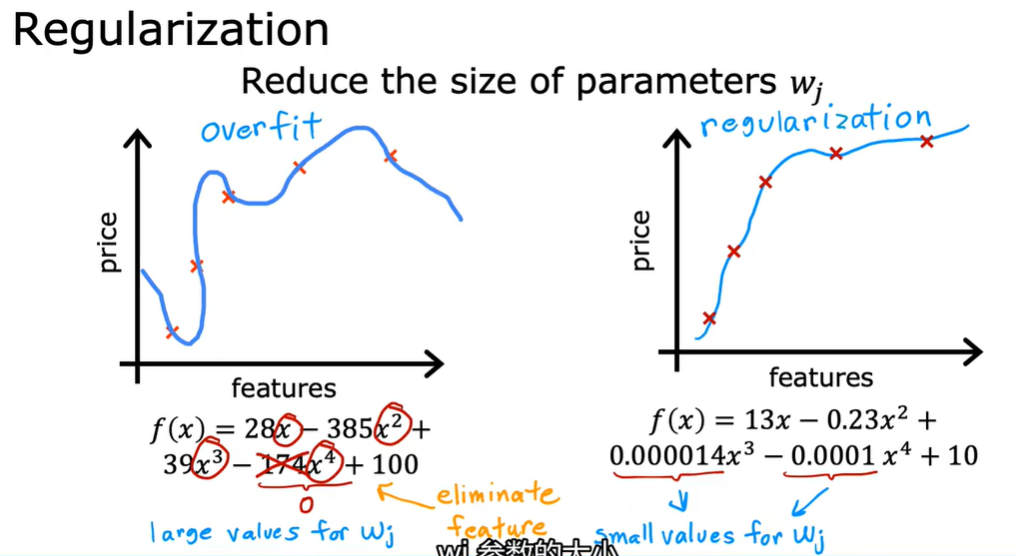
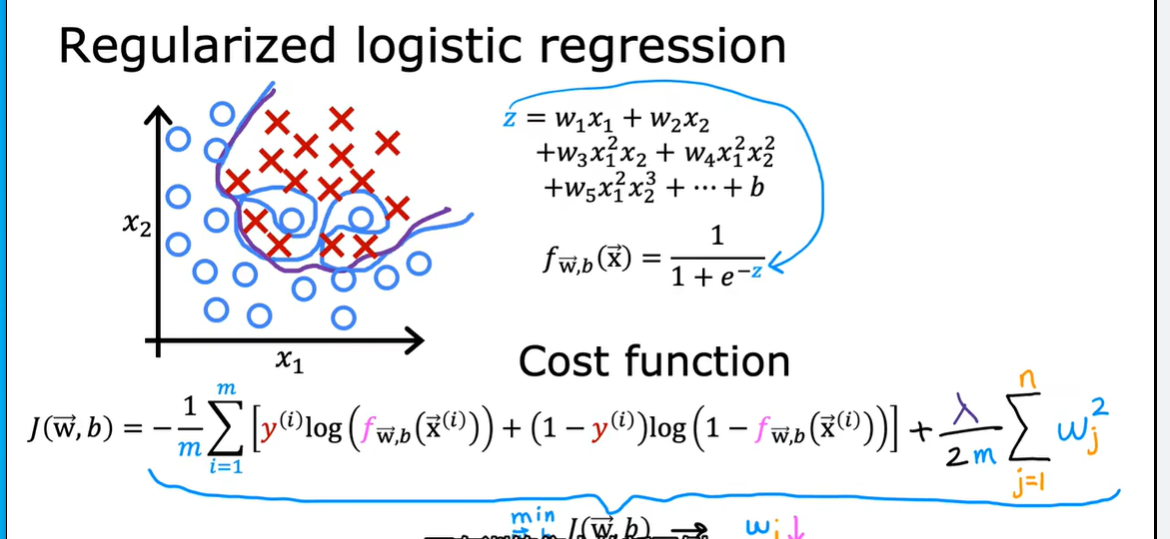
1.8 正则化
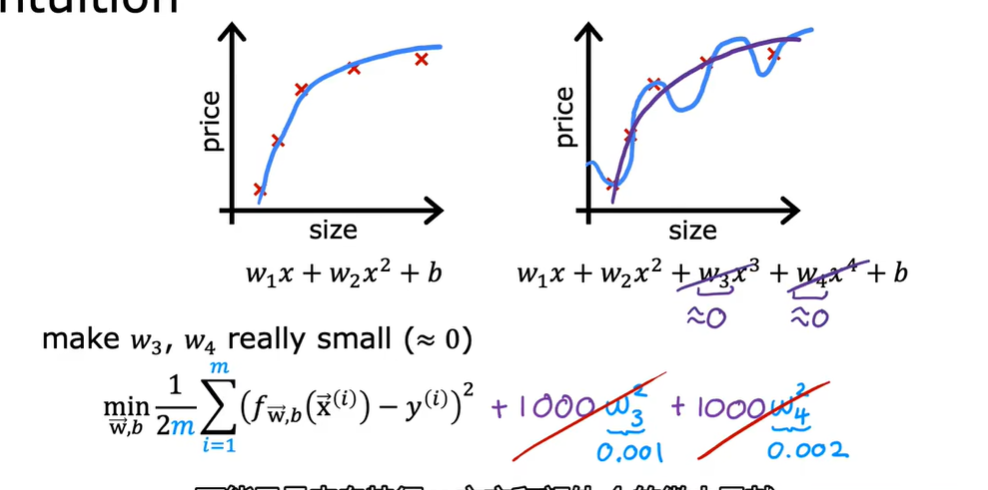
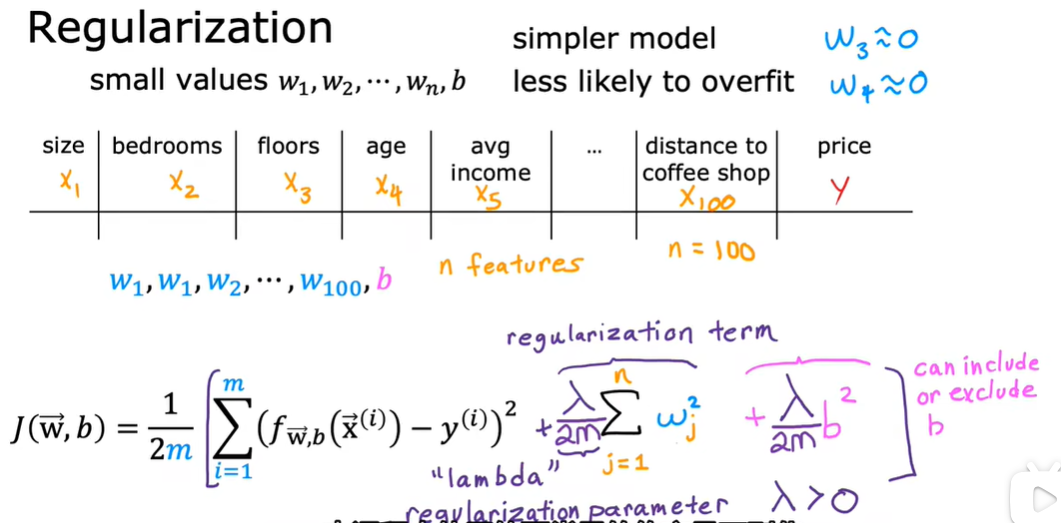
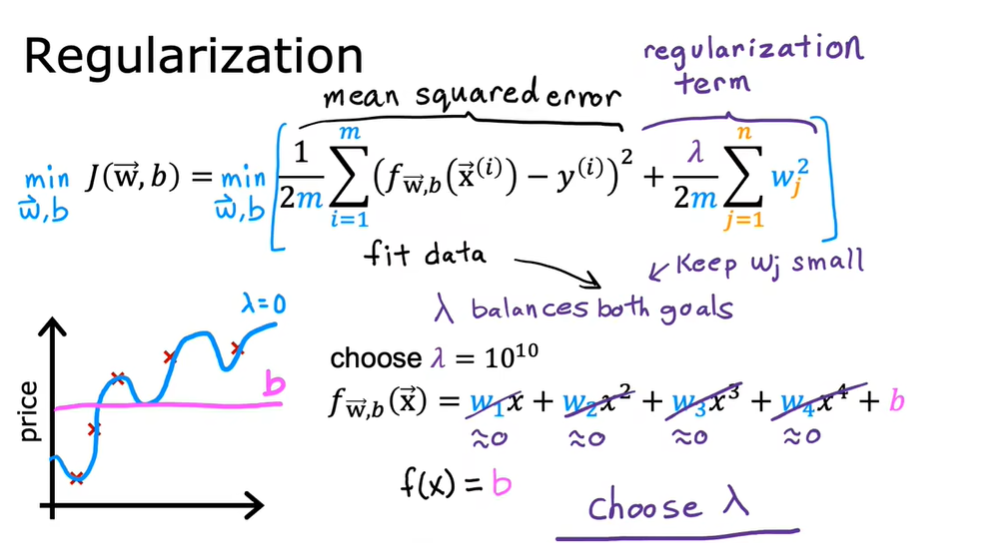
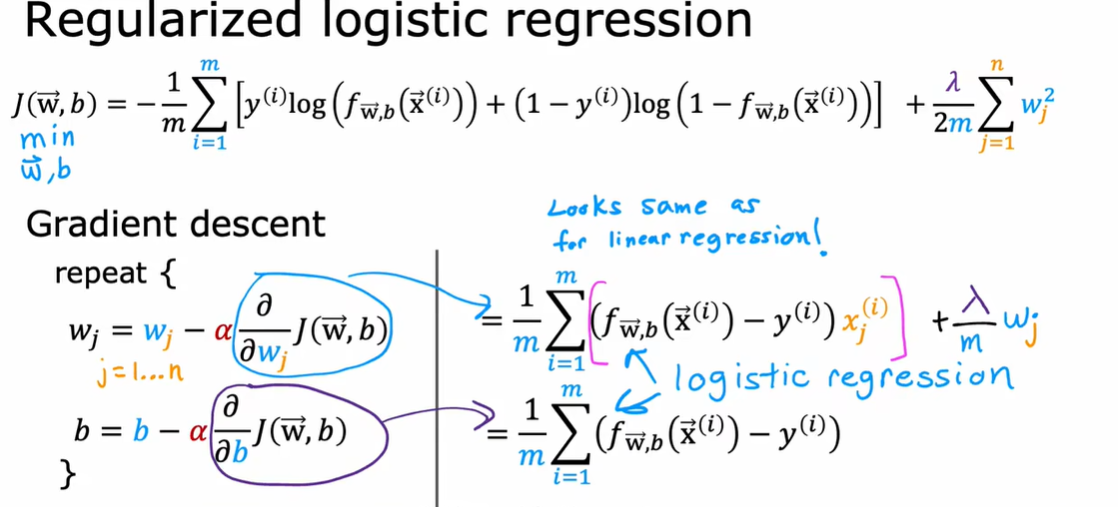
1.9 用于线性回归的正则方法



去掉求和符号是因为我们是对Wj求偏导,除了Wj那项其他都消除了
1.10 用于逻辑回归的正则方法