上一篇文章我们提到,查全率和查准率是一对矛盾的度量,那在实际的应用中怎么选取一个合适的值去平衡这两个度量,这里我们介绍三种方法,这个值就叫做最优阈值。
1.方法一:选择平衡点
我们看下图


如图一中所示,Threshold就是阈值,Precision就是查准率,Recall就是查全率,我们看到,阈值为零的时候查准率和查全率相等。第二个图展示的是在不同机器学习模型下的查准率和查全率的一个变换,模型不同,平衡点的位置也往往不相同,这个方法没什么难理解的,就是选择两个值相等的点作为最优阈值。
2.方法二: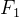 度量
度量
先看公式:
度量其实就是查全率和查准率的一个调和平均,为啥需要弄这个东西当作最优阈值的确定方法呢?我们从以下几个方面来说明:
-
平衡性:
-
对不均衡数据敏感:在正负样本不均衡的情况下,
-
单一指标:
-
适用性:在信息检索和自然语言处理等领域,
但是,度量是平衡两个度量的,那假如说我们现在只重视其中一个度量,那该怎么办嘞?这个时候就要引出我们的加权
度量。
2.方法三:加权 度量
先看公式:
这个其实也很好理解,举个例子,假如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯 ,此时查全率更重要。能让我们表达出对查全率和查准率的不同偏好。
其中时查全率有更大影响;
时查准率有更大影响。
时就是
啦。当然,这里面的
都是大于零哦。
ok,这篇文章就分享到这里啦,欢迎小伙伴们批评指正~(图片知识来源于西瓜书,网络)
标签:阈值,模型,通俗易懂,查全率,最优,查准率,方法,度量 From: https://blog.csdn.net/qq_64411728/article/details/139548948